요약
질병별 통계 정보를 사용한 조회 연산을 위해 뷰, Data JPA를 각각 활용하여 로직을 만들었고, 이를 테스트하여 Data JPA가 60% 이상 효율적이라는 결과를 얻었음.
상황
개발중인 프로젝트는 사용자들의 질병정보를 테이블에 저장한다.
로직에 사용한 테이블
-
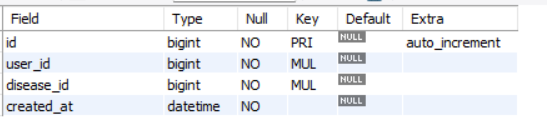
Diseases

-
User_diseases
-
Courses
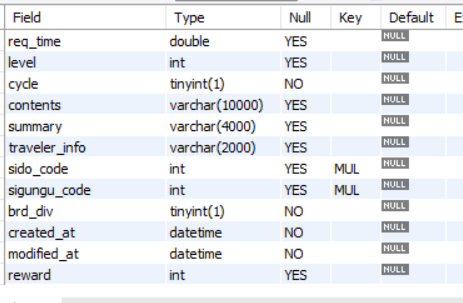
-
Visited_courses
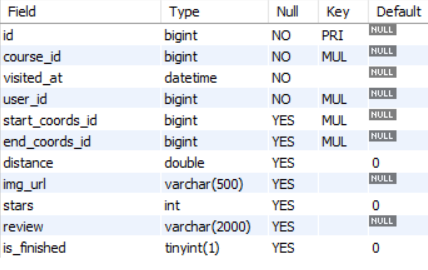
이번에 구현하고자 한 연산은 다음과 같다.
어떤 사용자가 보유한 질병 별로 평균 별점이 상위인 코스 5개 이하를 출력한다.
생각한 구현 방안은 총 3개였다.
- PL/SQL (스토어드 프로시저)를 사용한다.
- View를 정의하여 쿼리한다.
- Data JPA로 직접 구현한다.(연관관계 X, JPQL X, QueryDSL X)
적용해본 방법은 2, 3번이다. 선택 이유는 다음과 같다.
- PL/SQL, JDBC, JPQL 등은 SQL에 지나치게 종속된다.
- 구현이 복잡하고 쿼리가 길어도 구조적으로 사용할 수 있어야 한다.
뷰를 사용하면 여러 테이블에 직접 접근할 필요가 없다. 리포지토리로 접근이 가능하다.
단, 통계 정보를 얻기 위한 뷰 정의는 불필요한 조인을 너무 많이 수반한다.
Data JPA를 사용하는 방법은 조인이 없이 개별 쿼리들만으로 로직을 구현할 수 있다.
단, 코드가 길고 복잡해진다.
구현
제 1안 : 뷰를 이용한 조회
뷰를 정의한 SQL은 다음과 같다.
create or replace view disease_course_stat as
with d_c_tbl as (
select d.id as `disease_id`, c.id as `course_id`
from (diseases d cross join courses c) order by d.id),
ud_v_tbl as (
select disease_id, course_id, v.stars, v.review
from user_diseases ud
join visited_courses v using(user_id)
order by disease_id asc)
select dc.disease_id, dc.course_id, avg(uv.stars) as `avg_stars`, count(uv.review) as `review_count`, count(*) as `visitation_count`
from d_c_tbl dc
left outer join ud_v_tbl uv
on (dc.disease_id = uv.disease_id and dc.course_id = uv.course_id)
where uv.stars is not null
group by dc.disease_id, dc.course_id
order by dc.disease_id;CTE를 사용하여 정의했으며 굉장히 길고 복잡하다.
그리고 이를 사용한 주요 비즈니스 로직 코드는 다음과 같다.
@Override
public List<DiseaseAndCourses> queryCoursesForDiseasesOf(Long userId, RecommendationCriteria criteria) {
List<DiseaseAndCourses> result = new ArrayList<>();
List<UserDisease> diseases = userDiseaseQueryService.queryUserDiseases(userId);
for(UserDisease disease : diseases) {
result.add(this.queryCoursesForDisease(disease.getDiseaseId(), criteria));
}
return result;
}
@Override
public DiseaseAndCourses queryCoursesForDisease(Long diseaseId, RecommendationCriteria criteria) {
List<DiseaseCourseStat> stats = diseaseCourseStatQueryService.queryDiseaseCourseStatFor(diseaseId);
if(stats.isEmpty()) return null;
stats.sort(criteria.comparator());
DiseaseAndCourses result = new DiseaseAndCourses();
result.setDiseaseCode(diseaseId);
List<RecommendedCourseSummary> courses = new ArrayList<>();
for(int i = 0; i < Math.min(5, stats.size()); i++) {
courses.add(new RecommendedCourseSummary(
courseRepository.findById(stats.get(i).getCourseId()).orElseThrow(() -> new IllegalArgumentException("존재하지 않는 코스 아이디로 조회를 시도했습니다.")),
(int)Math.round(stats.get(i).getAvgStars()),
stats.get(i).getReviewCount().intValue(),
stats.get(i).getVisitationCount()
)
);
}
result.setCourses(courses);
return result;
}queryCoursesForDiseasesOf()메서드로 userId와 미리 정의된 비교자만 넘겨주면 알아서 처리해준다. Data JPA 엔티티와 리포지토리를 그대로 활용할 수 있기 때문에 간결하게 코드를 작성할 수 있다.
제 2안 : Data JPA만 사용한 구현
@Override
public List<DiseaseAndCourses> queryCoursesForDiseaseOfBrutal(Long userId, RecommendationCriteria criteria) {
List<DiseaseAndCourses> result = new ArrayList<>();
// 유저와 같은 질병을 가진 사람들의 아이디를 모아본다.
// 사용자의 질병 코드를 읽어옴
Set<Long> userDisease = new HashSet<>(
userDiseaseQueryService.queryUserDiseases(userId)
.stream()
.map(UserDisease::getDiseaseId).toList());
// 사용자와 같은 질병 코드를 가진 userID를 검색함.
for(Long diseaseId : userDisease) { // 질병 하나당 한 번씩 수행함.
Set<Long> sameDiseaseUsers = new HashSet<>();
sameDiseaseUsers.add(userId);
sameDiseaseUsers.addAll(userDiseaseQueryService.queryUsersHavingDisease(diseaseId)
.stream().map(UserDisease::getUserId).toList());
// 현재 질병 id를 가진 사람들의 방문 코스 정보 모으기
List<VisitedCourse> vcourses = visitedCourseQueryService.queryVisitedCourses(userId);
for(Long sampledId : sameDiseaseUsers) {
vcourses.addAll(visitedCourseQueryService.queryVisitedCourses(sampledId));
}
// 통계정보를 저장해야 하니까..
Map<Long, List<VisitedCourse>> mapForCourses = new HashMap<>();
for(VisitedCourse course : vcourses) {
Long courseId = course.getCourseId();
if(!mapForCourses.containsKey(courseId)) {
mapForCourses.put(courseId, new ArrayList<>());
}
mapForCourses.get(courseId).add(course);
}
// 이제 코스 번호별로 통계 정보를 만들어야 함.
List<CourseTempStat> courseRanking = new ArrayList<>();
for(Long courseId : mapForCourses.keySet()) {
List<VisitedCourse> list = mapForCourses.get(courseId);
Double avg = list.stream().collect(Collectors.averagingDouble(VisitedCourse::getStars));
CourseTempStat stat = new CourseTempStat(courseId, avg);
courseRanking.add(stat);
}
courseRanking.sort((i, j) -> j.avgStars().compareTo(i.avgStars()));
DiseaseAndCourses summary = new DiseaseAndCourses();
summary.setDiseaseCode(diseaseId);
summary.setCourses(new ArrayList<RecommendedCourseSummary>());
for(int i = 0; i < Math.min(5, courseRanking.size()); i++) {
summary.getCourses().add(
new RecommendedCourseSummary(
courseRepository.findById(courseRanking.get(i).courseId())
.orElseThrow(() -> new IllegalArgumentException("지병 별 코스 추천(자바로 처리) : 해당 코스가 없습니다.")),
(int)Math.round(courseRanking.get(i).avgStars()), 0, 0L
)
);
}
result.add(summary);
}
return result;
}
record CourseTempStat(Long courseId, Double avgStars) {};로직이 길고 내부에서 하는 작업이 많아졌다. 메서드를 여러개로 분할하여야 겠으나 시험적으로 개발해본 메서드라 리팩터링은 나중에 해보도록 하겠다.
테스트
테스트 명세
| 항목 | 내용 |
|---|---|
| 테스트명 | 질병 top 코스 조회 호출 테스트 |
| 테스트 환경 | intelliJ 2024-03-06 커뮤니티, JDK 1.7 amazon corretto, JUnit 5 |
| 선행 조건 | visited_courses, users, user_diseases 테이블에 더미 데이터 삽입 |
| 수행 내용 | 약 1000회에 걸쳐 1 ~ 5번 유저의 질병별 Top 코스를 조회 |
| 후행 조건 | 더미 데이터 삭제, Top 코스 리스트가 반환됨 |
| 측정 대상 | 실행 시간(ms), 메모리 사용량(Byte) |
테스트 코드
@Nested
class LoadTester{
@Autowired
private CourseQueryService courseQueryService;
@Test
@Transactional
@Sql("/sql/disease_course_test.sql")
public void 질병_코스_호출_테스트_뷰() {
Runtime runtime = Runtime.getRuntime();
runtime.gc(); // GC 유도
long beforeUsedMem = runtime.totalMemory() - runtime.freeMemory();
long start = System.currentTimeMillis();
for(int i = 0; i < 1000; i++) {
for(long u = 1l; u <= 5l; u++) {
List<DiseaseAndCourses> diseaseAndCourses = courseQueryService.queryCoursesForDiseasesOf(u,
CourseQueryService.RecommendationCriteria.STARS);
}
}
// execution time : 459205
long afterUsedMem = runtime.totalMemory() - runtime.freeMemory();
long end = System.currentTimeMillis();
System.out.println("execution time : " + (end - start) + " ms");
System.out.println("used memory : " + (afterUsedMem - beforeUsedMem) + " bytes");
// execution time : 409308 ms
// used memory : 15160528 bytes
}
@Test
@Transactional
@Sql("/sql/disease_course_test.sql")
public void 질병_코스_호출_테스트_자바() {
Runtime runtime = Runtime.getRuntime();
runtime.gc(); // GC 유도
long beforeUsedMem = runtime.totalMemory() - runtime.freeMemory();
long start = System.currentTimeMillis();
for(int i = 0; i < 1000; i++) {
for(long u = 1l; u <= 5l; u++) {
List<DiseaseAndCourses> diseaseAndCourses = courseQueryService.queryCoursesForDiseaseOfBrutal(u,
CourseQueryService.RecommendationCriteria.STARS);
}
}
// execution time : 459205
// execution time : 137262
long afterUsedMem = runtime.totalMemory() - runtime.freeMemory();
long end = System.currentTimeMillis();
System.out.println("execution time : " + (end - start) + " ms");
System.out.println("used memory : " + (afterUsedMem - beforeUsedMem) + " bytes");
// execution time : 139455 ms
// used memory : 5909088 bytes
}
}테스트 결과
| 테스트 케이스 | 항목 | 결과 |
|---|---|---|
| 뷰를 활용 | 실행 시간 | 약 4500000ms |
| 뷰를 활용 | 메모리 사용량 | 약 14.5MB 사용 |
| Data JPA만 활용 | 실행 시간 | 약 1350000ms |
| Data JPA만 활용 | 메모리 사용량 | 약 5MB 사용 |
실행시간, 메모리 사용량에 대하여 Data JPA 사용이 60% 이상 개선된 효과를 보인다.
피드백
뷰를 사용한 방식은 코드의 간결성이 높아지고 보다 객체지향적인 코드 작성이 가능하다. 하지만 이로인해 발생하는 비용이 크다. 연관관계를 맺지 않고 오직 find 연산만 사용하여 Data JPA로 구현하는 편이 3배 이상 성능이 좋기에 굳이 DB 개체를 활용할 필요는 없는 것 같다.
이렇게 큰 성능차이가 발생하는 이유는 뷰에 대한 쿼리가 발생할 때마다 과하게 많은 조인 연산이 발생하기 때문으로 추측된다. 열심히 구현한 것 치고 아쉽지만, 거의 대부분의 조인 결과는 활용되지 않기 때문에 지나치게 큰 오버헤드가 존재한다. 따라서 Data JPA를 활용한 방안을 이용해야 할 것이다.
