Modular Rag
Modular RAG : Transforming RAG System into LEGO-like Reconfigurable Frameworks
INTRODUCTION
LLM은 뛰어난 성능을 보여주지만, 여전히 환각 문제나 정보 업데이트 지연과 같은 여러 과제에 직면해 있다. RAG는 외부 지식베이스에 접근함으로써 LLM에 중요한 문맥 정보를 제공하거나, 지식 집약적 작업에서 성능을 크게 향상시킨다.
RAG의 초기 단계에서는, 핵심 구조가 indexing, retrieval, generation으로 구성되며, 이를 Niave RAG라고 한다. 그러나 작업의 복잡성과 응용 요구가 증가함에 따라, Niave RAG의 한계가 점점 뚜렷해지고 있다.
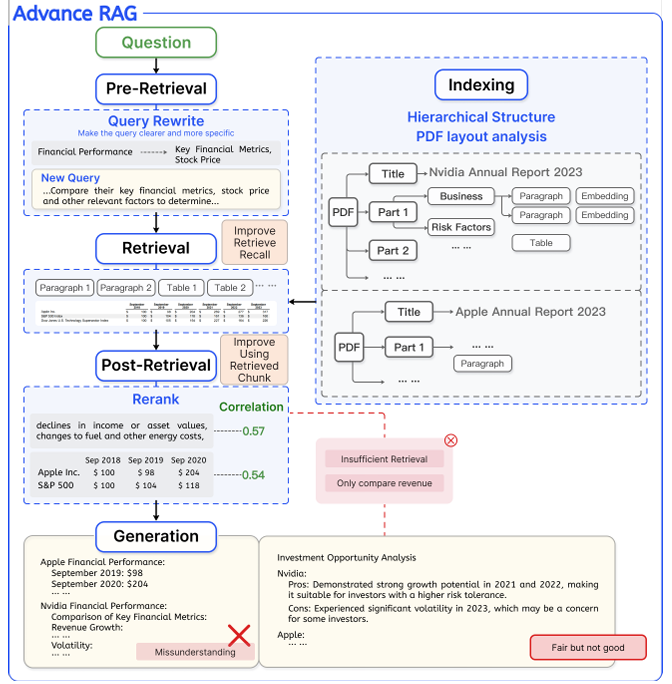
Naive RAG는 단순히 chunk 간 유사도에 의존하므로 복잡한 질의나 변동성이 큰 chunk를 다루는 데 있어 성능이 저하된다.
Naive RAG 주요 문제
1. 질의에 대한 얕은 이해
질의와 문서 chunk 간의 의미적 유사성이 항상 높은 일관성을 가지지 않음. 단순한 유사도 계산에만 의존하는 검색 방식은 질의와 문서 간 관계를 깊이 있게 탐색하지 못함
2. 검색 결과의 중복 및 잡음 문제
검색된 모든 청크를 그대로 LLM에 입력하는 것은 항상 바람직하지 않음. 과도한 중복 정보나 잡음은 LLM이 핵심 정보를 식별하는 데 방해가 되며, 환각을 생성할 가능성을 높임
이러한 한계를 극복하고자 Advanced RAG는 검색 단계의 최적화에 집중하며, 검색 효율을 높이고 검색된 청크의 활용도를 강화하는 것을 목표로 한다.
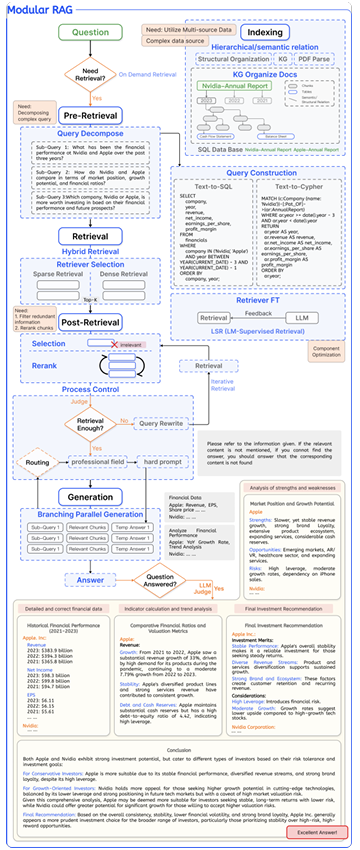
하지만 Advanced RAG가 실용성을 개선했음에도 불구하고, 실제 응용 요구와는 여전히 차이가 존재한다. 한편으로는 RAG 기술이 발전하면서 사용자 기대가 높아지고, 요구 사항이 다양해지며, 응용 환경이 더욱 복잡해지고 있다.
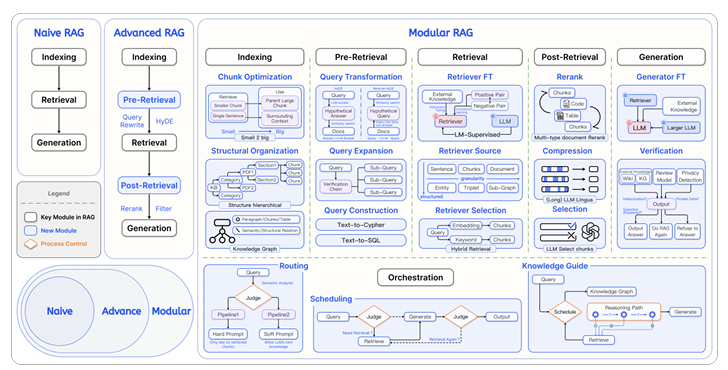
위와 같이, 더 정확하고 효율적인 작업 수행을 위해 최신 RAG 시스템은 점점 더 복잡한 기능들을 통합하고 있다.
프로세스 설계 측면에서도, 현재 RAG 시스템은 기존의 선형적인 "검색-생성" 구조를 넘어섰다. 더 풍부한 문맥을 얻기 위해 iterative retrieval, 복잡한 질의를 처리하기 위해 recursive retrieval, 그리고 전체적인 자율성과 유연성을 제공하는 adaptive retrieval을 활용하고 있다. 이러한 유연성은 RAG 시스템의 표현력과 적응성을 크게 향상시키지만, 동시에 워크플로우의 구성과 스케줄링을 더욱 복잡하게 만들어 시스템 설계에 새로운 도전을 제기한다.
RAG가 직면한 과제는 다음과 같다
- 복잡합 데이터소스 통합
RAG는 더 이상 단일 비정형 텍스트 데이터에 국한되지 않고, 표와 같은 반정형 데이터나 지식 그래프와 같은 구조화된 데이터까지 포함한다.- 시스템 해석 가능성, 제어성, 유지보수성에 대한 요구 증가
시스템이 복잡해질수록 유지보수와 디버깅이 어려워지고, 문제가 발생했을 때 최적화가 필요한 구성 요소를 빠르게 찾는 것이 중요해진다.- 구성 요소 선택 및 최적화 문제
RAG 시스템에는 더 많은 신경망이 포함되며, 작업 요구와 자원 환경에 맞는 적절한 구성 요소 선택이 필요하다. 또한 여러 구성 요소 간의 협업을 통해 전체 성능을 높이는 것이 중요하다.- 워크플로우 구성 및 스케줄링 문제
구성 요소는 특정 순서로 실행되거나, 조건에 따라 병렬 처리되거나, LLM의 판단에 따라 실행될 수 있다.
이러한 복잡성 증가에 따른 설계, 관리, 유지보수 문제를 해결하고, 다양한 요구를충족하기 위해 Modular RAG 아키텍처를 제안한다. Modular RAG는 여러 개의 독립적이면서도 긴밀히 협력하는 모듈로 구성되며, 각 모듈은 특정 기능이나 작업을 담당한다.
- 상위 계층 : RAG의 주요 단계를 독립적인 모듈로 구성하고, 전체 프로세스를 제어하는 오케스트레이션 모듈 포함
- 중간 계층 : 각 모듈 내의 서브모듈로 기능을 세분화
- 하위 계층 : 실제 연산 단위인 오퍼레이터
FRAMEWORK AND NOTATION
질의 가 주어졌을 때, Naive RAG 시스템은 세 가지 핵심 구성 요소로 이루어진다.
| Notation | Description |
|---|---|
| original query | |
| output of LLM | |
| chunk 로 구성된 문서 검색 저장소 | |
| Retriever, 질의 를 기반으로 에서 유사한 chunk를 찾음 | |
| RAG flow | |
| RAG flow pattern | |
| 질의 확장 함수 | |
| 질의 변환 함수 | |
| 청크 압축 함수 | |
| 청크 선택 함수 | |
| 라우팅 함수 | |
| 모듈형 RAG에서의 모듈 | |
| 모듈 내의 특정 연산자 |
Indexing
문선 집합 이 주어진다 (는 chunk를 의미한다). indexing은 각 문서 조각을 임베딩 모델 을 통해 벡터로 변환한 뒤, 이를 벡터 데이터베이스에 저장하는 과정이다.
Retrieval
query도 동일한 방식으로 벡터로 변환한 뒤, 문서들과의 유사도를 계산하여 가장 비슷한 상위 k개의 문서를 선택한다.
는 질문과 관련있는 top-k개의 문서들만 모아놓은 집합이다. 유사도 계산은 dot product 또는 cosine similarity를 사용한다.
는 질문 벡터, 는 문서 벡터이다.
Generation
검색된 문서 chunks과 질문을 함께 LLM에 입력하여 최종 답변을 생성한다.
- : stands for concatenation
RAG가 발전하면서 다양한 기능들이 추가 되었고, 이를 모듈 구조로 나눈다. Modular RAG는 3 단계 구조로 구성된다.
L1 Module
core process in RAG systme
L2 Sub-Module
functional modules in module
L3 Operator
specific functional implementation in a module or sub-module
Modular RAG는 다음과 같이 표현된다
모듈과 연산자 간의 배열은 RAG Flow 을 구성하며, 는 모듈 파라미터들의 집합을 의미한다. 모듈형 RAG 흐름은 하위 함수들의 그래프로 분해될 수 있다.
가장 단순한 경우, 그래프는 linear chain의 형태를 가진다.
MODULE AND OPERATOR
여섯 개의 주요 모듈을 정의하면 다음과 같다. Indexing, Pre-retrieval, Retrieval,Post-retrieval, Generation, Orchestration
A. Indexing
문서를 관리 가능한 크기인 chunk로 분할하는 과정이며, 시스템을 구성하는 데 있어 핵심적인 단계이다. 인덱싱은 세 가지 주요 문제에 직면한다.
- Imcomplete content representation
chunk의 의미 정보는 분할 방식에 영향을 받으며, 이로 인해 긴 문맥 내의 중요한 정보가 손실되거나 묻힐 수 있다. - Inaccurate chunk similarity search
데이터 양이 증가함에 따라 검색에서의 노이즈가 증가하고, 잘못된 데이터와 매칭되는 경우가 많아져 검색 시스템이 불안정해질 수 있다. - Unclear reference trajectory
검색된 chunk는 다양한 문서에서 추출될 수 있으며, 출처 정보가 부족하여 서로 다른 주제를 가진 chunk들이 혼합될 수 있다.
1) Chunk Optimization
chunk의 크기와 chunk 간 중첩은 RAG system의 전체 성능에 중요한 영향을 미친다. 주어진 chunk 에 대해, 청크 크기 , 중첩은 로 표현된다.
큰 chunk는 더 많은 문맥 정보를 포함할 수 있지만, 노이즈 증가와 처리 비용 증가를 초래한다. 작은 chunk는 문맥 정보가 부족할 수 있지만 노이즈가 적다.
Sliding Window
슬라이딩 윈도우 방식은 중첩된 chunk를 활용하여 의미적 연결을 강화하지만, 문맥 크기 제어가 부정확하고 문장 단위로 잘릴 수 있으며 의미적 고려가 부족한 한계가 있다.
Metadata Attachment
청크에 페이지 번호, 파일 이름, 작성자, 타임스탬프, 요약, 관련 질문 등의 메타데이터를 추가할 수 있다. 이는 필터링 기반 검색을 가능하게 한다.
Small-to-Big
검색용 chunk와 생성용 chunk를 분리한다. 작은 chunk는 검색 정확도를 높이고, 큰 chunk는 더 많은 문맥을 제공한다.
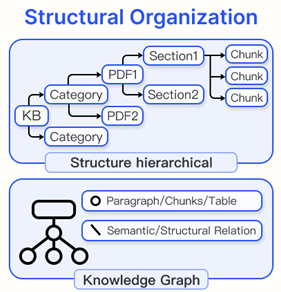
2) Structure Organization
정보 검색 기능을 향상시키는 효과적인 방법 중 하나는 문서에 계층 구조를 부여한느 것이다.
Hierarchical Index
문서 구조에서 노드는 부모-자식 관계로 구성되며, 각 노드에는 chunk와 요약 정보가 저장된다. 이를 통해 빠른 데이터 탐색이 가능하고, 적절한 chunk 선택을 돕는다.
KG Index
지식 그래프를 활용하여 문서를 구조화하면 개념 간 관계를 명확히 하고 검색 정확도를 향상시킨다.
B. Pre-retrieval
Naive RAG의 주요 문제 중 하나는 사용자 질의를 그대로 사용하는 것이다. 이때문에 발생하는 문제는 다음과 같다
1. 부정확한 query
2. 언어적 복잡성과 모호성
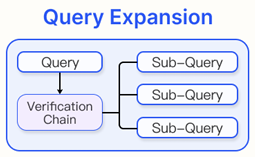
1) Query Expansion

단일 query를 여러 query로 확장하여 더 풍부한 정보를 제공한다
Multi-Query
LLM을 활용한 프롬프트 엔지니어링을 통해 질의를 확장하며, 병렬 실행을 가능하게 한다. 하지만 이 접근 방식은 사용자의 원래 의도를 희석할 수 있으므로, 원래 query에 대해 더 높은 가중치를 부여하도록 지시할 수 있다.
Sub-Query
복잡한 문제를 분해하고 계획함으로써 여러 하위 문제를 생성한다.
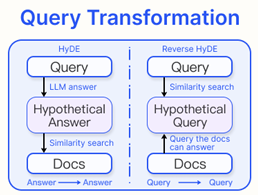
2) Query Transformation
사용자의 원래 query 대신 변환된 query를 기반으로 검색 및 생성을 수행한다.
Rewrite
원래 query가 검색에 충분하지 않을 경우, LLM을 사용하여 query를 재작성할 수 있다.
HyDE
query와 답변 간의 의미적 간극을 줄이기 위해, query를 직접 검색하는 대신 가상의 문서(가정된 답변)을 생성하여 이를 기반으로 검색을 수행한다. 이는 답변 간의 유사도에 집중한다. reverse HyDE는 각 chunk에 대해 가상의 query를 생성하고 query 간 유사도를 기반으로 검색을 수행한다.
Step-back Prompting
원래 query를 더 높은 수준의 개념적 질문으로 추상화한다. step-back 질문과 질의를 모두 사용하여 검색을 수행하고, 그 결과를 결합하여 언어 모델의 답변을 완성한다.
3) Query Construction
구조화된 데이터를 처리하기 위해 query를 다른 형태로 변환한다. 이는 query를 다른 query 언어로 변환하여 다양한 데이터 소스에 접근하는 것을 의미한다.
e.g SQL, Cypher 등
C. Retrieval
강력한 임베딩 모델을 활용하므로써, query와 텍스트를 latent space에서 효율적으로 표현할 수 있으며, 이는 질문과 문서 간의 의미적 유사성을 형성하는 데 도움을 주어 검색 성능을 향상시킨다. 해결해야할 주요 고려 사항은 검색 효율성, 품질, 그리고 작업, 데이터, 모델 간의 alignment이다.
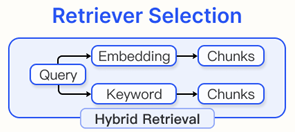
1) Retriever Selection
Sparse Retriever
통계적 방법을 사용하여 query와 문서를 sparse vector로 변환한다. 이 방법은 non-zero에만 집중하여 대규모 데이터셋을 효율적으로 처리할 수 있다. 그러나 복잡한 의미를 표현하는 데 있어서는 dense vector보다 성능이 떨어질 수 있다.
Dense Retriever
pretrained language model을 사용하여 query와 문서를 dense vector로 표현한다. 계산 비용과 저장 비용이 더 높지만, 더 복잡한 의미 정보를 표현할 수 있다.
Hybrid Retriever
sparse retriever와 dense retriever를 동시에 사용하는 방식이다.
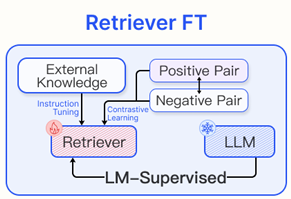
2) Retriever Fine-tuning
의료, 법률 등과 같이 전문 용어가 풍부한 분야에서는 문맥이 사전학습된 데이터와 크게 다를 수 있다.
Supervised Fine-Tuning
라벨이 있는 도메인 데이터를 기반으로 검색 모델을 미세 조정하는 방법은 일반적으로 contrastive learning을 사용한다. 이는 양성 샘플간 거리는 줄이고, 음성 샘플 간 거리는 늘리는 방식이다.
는 i번째 query에 해당하는 양성 문서, 는 여러 개의 음성 샘플. 는 전체 query의 수, 은 음성 샘플 수, 은 fine-tuning 데이터셋을 의미한다.
LM-supervised Retriever (LSR)
RAG 과정에서 언어 모델이 생성한 결과를 사용하여 임베딩 모델을 fine-tuning한다.
는 입력 문맥 와 query 가 주어졌을 때 정답 를 생성할 확률을 의미하며, 는 하이퍼파라미터이다. 즉, LLM이 만든 답이 "정답과 얼마나 가까운지"를 평가한다.
Adapter
대형 retriever를 직접 fine-tuning하는 것은 비용이 많이 들 수 있다. 이 경우 adapter 모듈을 추가하고 이를 fine-tuning하는 방식으로 비용을 줄일 수 있다. 또한 adapter를 추가하면 특정 downstream task에 대한 alignment를 더욱 향상시킬 수 있다.
D. Post-retrieval
검색된 모든 chunk를 그대로 LLM에 입력하는 것은 최적의 선택이 아니다. chunk에 대한 후처리는 문맥 정보를 더 효과적으로 활용하는 데 도움을 줄 수 있다. 주요 문제는 다음과 같다.
- Lost in the middel
LLM은 긴 텍스트에서 시작 부분이나 끝 부분만 기억하고 중간 부분은 잊어버리는 경향이 있다. - Noise/anti-fact chunks
노이즈가 많거나 사실과 모순되는 문서가 검색될 경우 최종 생성 결과에 영향을 미칠 수 있다. - Context Window
많은 관련 정보를 검색하더라도, 대형 모델의 입력 길이 제한으로 인해 모든 내용을 포함할 수 없다.
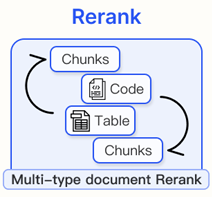
1. Rerank
검색된 chunk의 내용이나 길이를 변경하지 않고 재정렬하여, 더 중요한 문서 chunk가 잘 드러나도록 한다. 검색된 집합 와 재정렬 방법 가 주어졌을 때, 재정렬된 집합은 다음과 같다.
Rule-base rerank
특정 규칙에 따라 지표를 계산하고 chunk를 재정렬한다. 대표적인 지표로는 diversity와 relevance,그리고 MRR(Maximal Marginal Relevance)가 있다. 핵심 아이디어는 중복을 줄이고 결과의 다양성을 높이는 것이다.
Model-base rerank
언어 모델을 사용하여 문서 chunk를 재정렬하며, 일반적으로 query와 chunk 간의 관련성을 기반으로 한다.
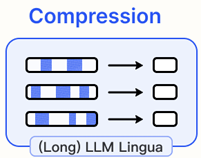
2. Compression
RAG 과정에서 가장 큰 오해 중 하나는 가능한 많은 관련 문서를 검색하여 이를 모두 이어 붙여 긴 프롬프트를 만드는 것이 좋다는 것이다. 그러나 과도한 문맥은 더 많은 노이즈를 유입하여 LLM이 핵심 정보를 인식하는 능력을 저하시킬 수 있다. 이를 해결하기 위한 일반적인 방법은 검색된 내용을 압축하고 선택하는 것이다.
LLMLingua
정렬되고 학습된 소형 언어 모델을 활용하여 프롬프트에서 중요하지 않은 토큰을 탐지하고 제거한다. 그 결과 인간에게는 이해하기 어렵지만 LLM은 잘 이해할 수 있는 형태로 변환된다. 이는 추가적인 LLM 학습 없이도 언어의 완전성과 압축 비율을 균형 있게 유지하면서 프롬프트를 압축할 수 있는 직접적이고 실용적인 방법이다.
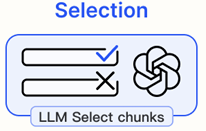
3. Selection
관련 없는 chunk를 직접 제거한다.
은 삭제 연산 함수이며, 는 문서 가 특정 조건을 만족하는지를 나타내는 조건식이다. 만약 문서 가 를 만족하면 삭제되고, 를 만족하는 문서만 유지된다.
Selective Context
입력 문맥에서 중복된 내용을 식별하고 제거함으로써 입력을 정제하고, 언어 모델의 추론 효율을 향상 시킨다. 실제로 기본 언어 모델이 self-information을 기반으로 어휘 단위의 정보량을 평가한다. 정보량이 높은 내용만 유지함으로써, 다양한 응용에서 성능을 저하시키지 않으면서 더 간결하고 효율적인 텍스트 표현을 제공한다. 그러나 압축된 내용 간의 상호 의존성과 목표 언어 모델과 프롬프트 압축에 사용된 소형 언어 모델 간의 정렬 문제는 고려하지 못한다.
LLM-Critique
최종 답변을 생성하기 전에 LLM이 검색된 내용을 평가하도록 하는 것. 이를 통해 LLM은 관련성이 낮은 문서를 걸러낼 수 있다.
Generation
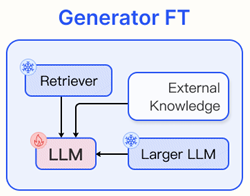
1) Generator Fine-tuning
시나리오와 데이터 특성에 맞춘 목표 지향적인 fine-tuning은 더 나은 결과를 가져올 수 있다.
Instruction-Tuning
특정 도메인에서 LLM이 데이터가 부족한 경우, 미세조정을 통해 추가적인 지식을 제공할 수 있다. 일반적인 fine-tuning 데이터셋을 초기 단계로 사용할 수도 있다. 또한 fine-tuning의 또 다른 장점은 모델의 입력과 출력을 조정할 수 있다는 점이다.
Reinforcement learning
LLM의 출력이 인간 또는 retriever의 preference와 일치하도록 정렬하는 것도 하나의 방법이다.
Dual Fine-tuning
generator과 retriever를 동시에 fine-tuning하여 두 구성 요소의 preference를 일치시키는 방법이다.
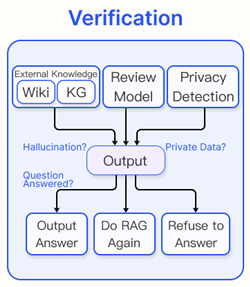
2) Verification
RAG는 LLM이 생성한 답변의 신뢰성을 향상시키지만, 많은 경우 환각 발생 확률을 최소화할 필요가 있다. 따라서 추가적인 검증 모듈을 통해 요구 기준을 충족하지 못하는 응답을 필터링할 수 있다.
Knowledge-base verification
외부 지식을 통해 LLM이 생성한 응답을 직접 검증하는 방법이다. 먼저 응답에서특정 문장이나 triplet을 추출한 후, Wikipedia나 특정 지식 그래프와 같은 검증된 지식 베이스에서 관련 근거를 검색한다. 이후 각 문장을 해당 근거와 비교하여, 그 문장이 지지되는지, 반박되는지, 또는 정보가 충분하지 않은지를 판단한다.
Model-based verification
소형 언어 모델을 사용하여 LLM이 생성한 응답을 검증하는 방법이다.
Orchestration
RAG 프로세스를 제어하는 모듈을 의미한다. 전통적인 고정된 프로세스의 경직된 접근 방식과 달리, 현재 RAG는 중요한 지점에서 의사결정을 수행하고 이전 결과에 따라 다음 단계를 동적으로 선택한다. 이러한 적응적이고 모듈화된 능력은 모듈형 RAG의 특징이다.
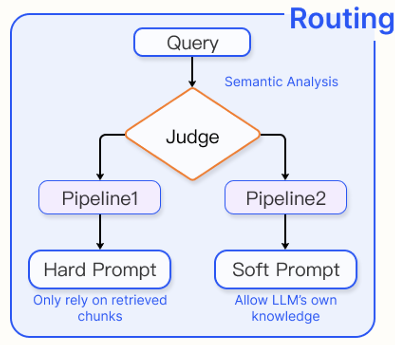
1) Routing
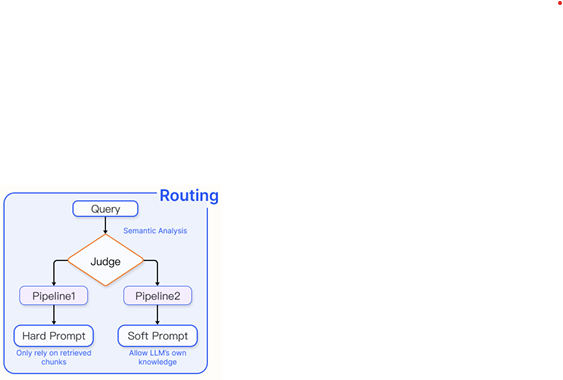
다양한 query에 대응하여, RAG 시스템은 서로 다른 시나리오에 맞춰진 특정 파이프라인으로 라우팅된다. 이는 다양한 상황을 처리할 수 있는 유연한 RAG 아키텍처에서 필수적인 기능이다. 어떤 모듈이 사용될지를 결정하기 위해서는 모델의 입력이나 추가적인 메타데이터를 기반으로 한 의사결정 메커니즘이 필요하다. 서로 다른 프롬프트나 구성 요소에 따라 서로 다른 경로가 사용된다.
이러한 메커니즘은 으로 표현되는 함수에 의해 수행되며, 각 모듈에 점수 를 할당한다. 이 점수는 활성화될 모듈의 부분 집합을 결정한다.
Metadata routing
query에서 핵심 용어나 개체를 추출하고, 이러한 키워드와 chunk 내 메타데이터를 활용한 필터링 과정을 통해 라우팅 파라미터를 정제한다. 특정 RAG 흐름 에 대해, 사전에 정의된 라우팅 키워드 집합은 로 표현된다. 질의 에서 식별된 키워드는 로 표시된다. 질의 에 대한 매칭 과정은 다음과 같은 키 점수식으로 계산된다.
이 식은 사전 정의된 키워드와 query에서 추출된 키워드 간의 겹치는 정도를 계산하고, 이를 의 크기로 정규화한다. 최종적으로 query 에 대해 가장 적합한 흐름은 다음과 같이 결정된다
Semantic routing
query의 의미 정보를 기반으로 서로 다른 모듈로 라우팅한다. 사전에 정의된 의도 집합이 주어졌을 때, 질의 에 대한 의도 확률은 다음과 같다
특정 RAG 흐름으로의 라우팅은 다음의 의미 점수에 의해 결정된다
Hybrid Routing
의미 기반 분석과 메타데이터 기반 접근을 결합하여 query 라우팅을 개선할 수 있으며, 다음과 같이 정의된다.
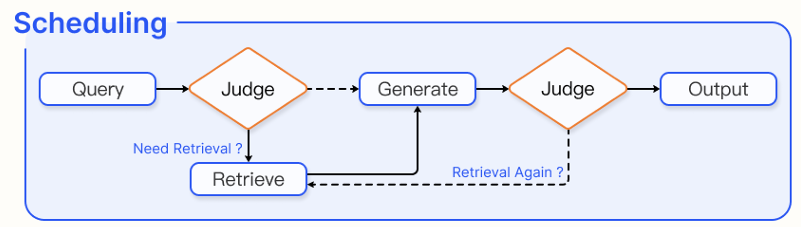
2) Scheduling
외부 데이터 검색이 필요한 중요한 시점을 식별하고, 생성된 응답의 적절성을 평가하며, 추가적인 탐색이 필요한지를 결정하는 데 중요한 역할을 한다.
Rule judge
다음 단계는 미리 정의된 규칙 집합에 의해 결정된다. 시스템은 생성된 답변의 품질을 점수로 평가하며, 이 점수가 특정 임계값을 초과하는지에 따라 계속 진행할지 여부를 결정한다. 이는 개별 토큰의 신뢰도와 관련되며, 다음과 같이 정의된다.
는 임시 답변을 의미하고, 는 언어 모델의 출력이다. 가 채택되기 위해서는 해당 문장의 모든 토큰 확률이 임계값 이상이어야 한다. 그렇지 않으면 새로운 답변을 다시 생성한다.
LLM judge
LLM이 독립적으로 다음 행동을 결정한다.
1. LLM의 in-context learning 능력을 활용하여 프롬프트 엔지니어링을 통해 판단을 수행
2. fine-tuning을 통해 LLM이 특정 토큰을 생성하여 특정 동작을 트리거하도록 하는 것
Knowledge-guided scheduling
지식 그래프를 활용하여 검색과 생성 과정을 제어한다. 질문과 관련된 정보를 지식 그래프에서 추출하고 추론 체인을 구성한다. 이 체인은 논리적으로 연결된 노드들의 집합으로, 문제 해결에 필요한 핵심 정보를 포함한다. 이 체인의 정보를 기반으로 검색과 생성이 각각 수행된다.
3) Fusion
여러 파이프라인을 탐색하여 검색 범위를 확장하거나 다양성을 높일 필요가 있다. 따라서 여러 branch가 생성된 이후, 융합 모듈은 정보를 효과적으로 결합하여 일관되고 포괄적인 응답을 생성한다.
LLM Fusion
여러 분기 결과를 통합하는 가장 간단한 방법은 LLM의 강력한 분석 능력을 활용하는 것이다. 하지만 긴 답변이 LLM의 컨텍스트 제한을 초과하는 경우 문제가 발생할 수 있다. 이를 해결하기 위해 각 분기의 결과를 먼저 요약하고 핵심 정보를 추출한 뒤 LLM에 입력하는 방식이 일반적으로 사용된다.
Weighted ensemble
여러 분기에서 생성된 토큰들의 가중치를 기반으로 최종 결과를 선택하는 방법
가중치 는 문서 와 query 간의 유사도 점수에 의해 결정된다.
RAG FLOW AND LOW PATTERN
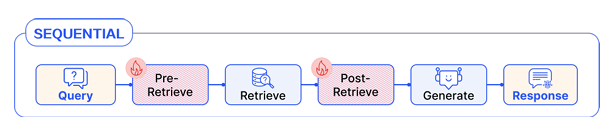
Linear Pattern
선형 RAG Flow Pattern은 주로 pre-retrieval, retrieval, post-retrieval, generation 모듈로 구성된다. pre-retrieval, post-retrieval이 없는 경우 Naive RAG 패러다임을 따른다.
일반적인 선형 RAG flow는 pre-retrieval에서 질의 변환 모듈을 포함하고, post-retrieval 단계에서는 rerank를 활용한다.
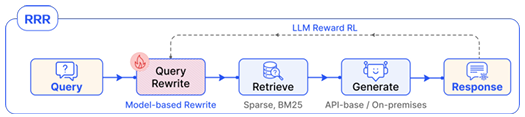
Rewrite-Retrieve-Read(RRR)은 대표적인 선형 구조이다.
질의 재작성 모듈 는 fine-tuning된 작은 학습 가능한 LM이며, 강화학습 맥락에서 rewritor의 최적화는 Markov decision process로 공식화된다. 이때 LLM의 최종 출력이 reward로 사용된다.
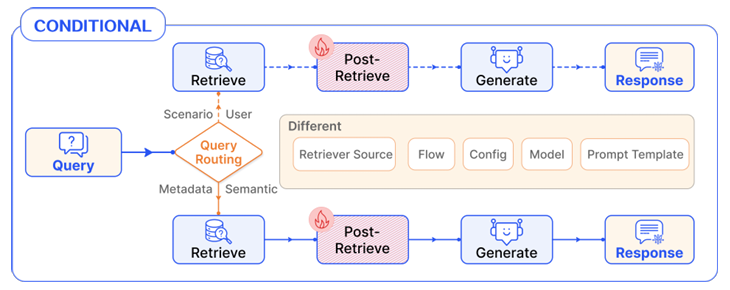
Conditional Pattern
서로 다른 조건에 따라 서로 다른 RAG 파이프라인을 선택한다. 일반적으로 파이프라인 선택은 flow에서 다음 모듈을 결정하는 routing 모듈을 통해 수행된다.
는 라우팅 함수 에 기반하여 흐름이 모듈 또는 로 이동할 수 있음을 의미한다.
파이프라인 선택은 질문의 성격에 따라 결정되며, 특정 시나리오에 맞는 서로 다른 흐름으로 분기된다.
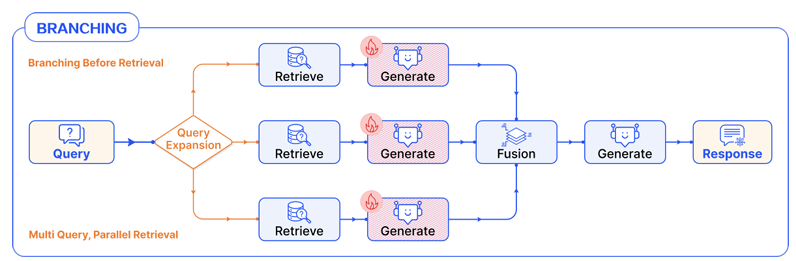
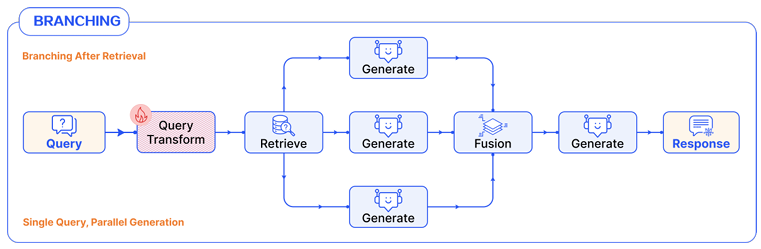
Branching

RAG flow 시스템은 여러 개의 병렬로 실행되는 분기를 가질 수 있으며, 이는 일반적으로 생성 결과의 다양성을 높이기 위함이다. 모듈 에서 여러 분기 가 생성된다고 가정하자.
각 분기 에 대해, 동일하거나 서로 다른 RAG 프로세스가 실행될 수 있으며, 여러 처리 모듈 를 거쳐 분기 출력 결과 를 얻는다. 여러 분기의 결과는 aggregation function을 통해 결합되어 중간 출력 결과를 생성한다. 그러나 aggregation이 반드시 RAG 흐름의 끝을 의미하는 것은 아니며, 이후 다른 모듈들과 계속 연결될 수 있다. .
여러 모델의 응답을 결합한 후, 검증 모듈을 추가로 통화할 수 있다. 따라서 전체 분기 패턴은 다음과 같다.
분기 구조를 가진 RAG 흐름은 조건 패턴과 달리 여러 분기가 동시에 실행된다는 점에서 차이가 있다. 조건 패턴은 여러 선택지 중 하나를 선택하는 반면, 분기 패턴은 여러 경로를 병렬로 수행한다.
Pre-Retrieval Branching
query 를 모듈을 통해 여러 하위 query 로 확장한다. 각 하위 query 는 를 통해 관련 문서를 검색하여 문서 집합 를 형성한다. 이후 각 하위 query와 해당 문서들은 생성 모듈 로 전달되어 답변 집합를 생성한다. 최종적으로 모든 결과는 병합 모듈 를 통해 결합되어 최종 결과 를 생성한다.
Post-Retrieval Branching
단일 query 로부터 시작하여 를 통해 여러 문서 chunk를 검색하고 문서 집합 를 얻는다. 각 문서 는 생성 모듈 에 의해 독립적으로 처리되어 결과 집합 를 생성한다. 이후 이 결과들은 병합 모듈 를 통해 결합되어 최종 결과 를 생성한다.
여기서 는 각 문서 에 대해 생성된 결과들의 집합이다.
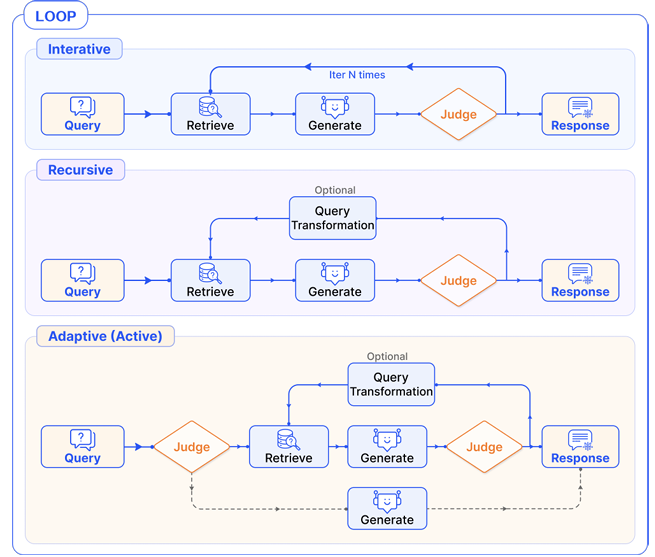
Loop Pattern

루프 구조를 가진 RAG 흐름은 Modular RAG의 중요한 특징으로, 검색과 생성 단계가 상호 의존적으로 이루어진다. 일반적으로 흐름 제어를 위한 스케줄링 모듈을 포함한다. 모듈형 RAG 시스템은 방향 그래프 로 추상화할 수 있으며, 여기서 는 시스템 내 다양한 모듈 를 나타내는 정점들의 집합이고, 는 모듈 간의 제어 흐름 또는 데이터 흐름을 나타내는 간선들의 집합이다. 정점의 순서 이 존재하여 이 에 도달할 수 있다면, 이 RAG 시스템은 루프를 형성한다.
만약 가 의 후속 모듈이고, 가 judge 모듈을 통해 또는 이전 모듈 로 돌아갈지를 결정한다면, 이는 다음과 같이 표현된다. 여기서 는 의 이전 모듈이다.
만약 가 로 돌아간다면, 이는 다음과 같이 표현된다.
만약 Judge 모듈이 어떤 이전 모듈로도 돌아가지 않도록 결정한다면, 이는 다음과 같이 표현된다.
Iterative retrieval
일정 횟수 동안 검색, 생성, 다시 검색을 반복하여 이전 결과를 활용해서 점점 답을 개선한다
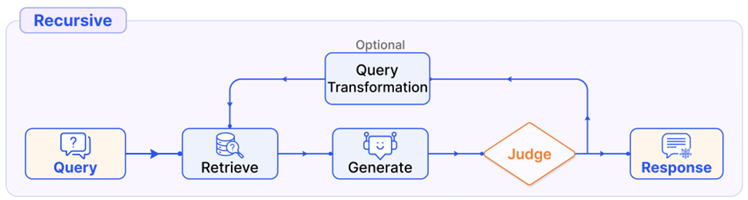
Recursive retrieval
이전 단계에 대한 명확한 의존성을 가지며, 검색을 점진적으로 깊게 확장한다. 일반적으로 트리 구조를 따르며, 재귀 종료를 위한 명확한 종료 조건이 존재한다. RAG 시스템에서 재귀적 검색은 보통 질의 변환을 포함하며, 각 검색 단계마다 새롭게 재작성된 query를 사용한다.
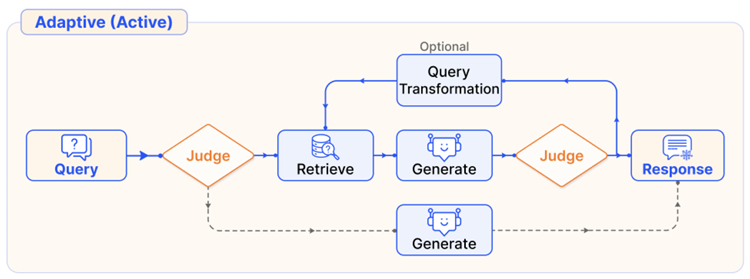
Adaptive retrieval
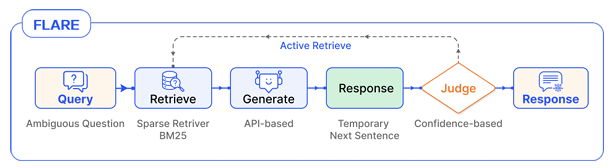
RAG 시스템은 검색 시점을 능동적으로 결정하고, 언제 전체 과정을 종료하여 최종 결과를 생성할지를 판단할 수 있다. 판단 기준에 따라, prompt 기반 방식과 Tuning 기반 방식으로 나눌 수 있다.
Prompt-base
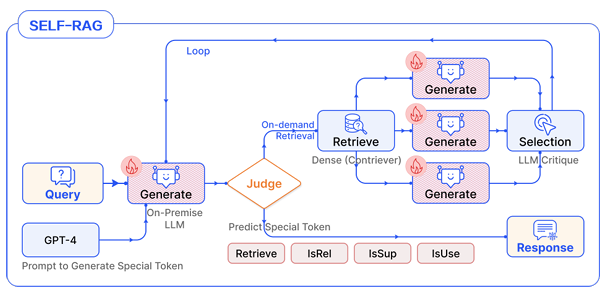
프롬프트 엔지니어링을 통해 LLM의 흐름을 제어하는 방식
Tuning-base
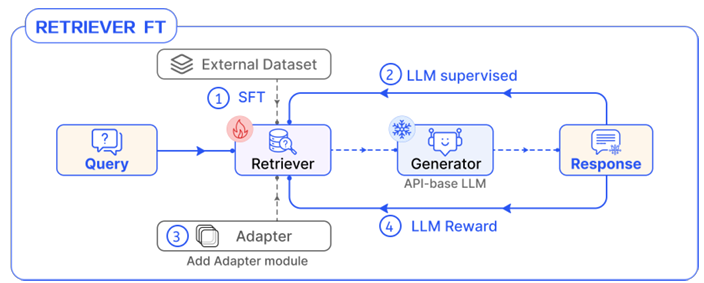
LLM을 fine-tuning하여 특정 토큰을 생성하도록 함으로써 검색이나 생성을 트리거하는 방식.
Tuning Pattern
RAG는 점점 더 다양한 LLM 기술과 결합되면서 발전하고 있으며, Modular RAG에서는 여러 구성 요소가 학습 가능한 언어 모델로 이루어진다. 이러한 구성 요소들은 미세조정을 통해 성능을 향상시킬 수 있을 뿐만 아니라, 전체 RAG 흐름과의 호환성도 최적화할 수 있다.
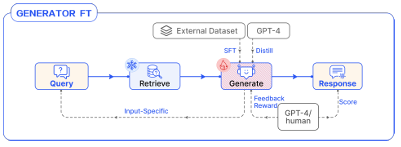
Retriever FT
가장 기본적인 방법은 지도 학습 기반의 직접 미세조정으로, 검색에 특화된 데이터셋을 구축하여 dense retriever를 학습시키는 것이다. 이는 공개된 검색 데이터셋을 활용하거나 특정 도메인에 맞는 데이터를 직접 구축하여 수행할 수 있다. 또한 API 기반 임베딩 모델의 경우 직접적인 미세조정이 어려울 수 있는데, 이때는 adapter 모듈을 추가하여 데이터 표현력을 강화하고 다운스트림 작업과의 정렬을 개선할 수 있다. 또 다른 방법으로는 LLM이 생성한 결과를 감독 신호로 활용하는 LM-supervised Retrieval(LSR)이 있으며, 더 나아가 LLM의 출력 결과를 보상으로 사용하는 강화학습 방식도 존재한다. 이 경우 검색 과정은 생성 기반의 마코프 체인 형태로 구성되어, 검색기와 생성기의 정렬을 강화한다.
Generator FT
LLM의 답변 생성 능력을 향상시키기 위한 방법이다. 가장 일반적인 방식은 외부 데이터셋을 활용한 지도 학습 기반 미세조정으로, 이를 통해 모델에 추가적인 지식을 제공하거나 입력 및 출력 형식을 원하는 방식으로 조정할 수 있다. 또한 사람이나 LLM의 평가를 기반으로 한 강화학습도 활용될 수 있으며, 이를 통해 생성 결과가 더 높은 품질과 선호도를 갖도록 조정할 수 있다
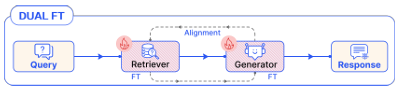
Dual FT
RAG 시스템의 특징적인 접근 방식으로, 검색기와 생성기를 동시에 미세조정하는 것이다. 이 방식의 핵심은 두 구성 요소 간의 협업과 정렬을 최적화하는 데 있다.
Summary
| 구분 | 방법 | 설명 | 핵심 특징 |
|---|---|---|---|
| 기능 모듈 | Pre-retrieval | 검색 전에 질의를 수정, 확장, 분해 | 검색 정확도 향상 |
| 기능 모듈 | Retrieval | 관련 문서를 검색 (Sparse, Dense, Hybrid) | 의미 기반 / 키워드 기반 검색 |
| 기능 모듈 | Post-retrieval | 검색된 문서를 정제 (rerank, compression, selection) | 노이즈 제거, 핵심 정보 강조 |
| 기능 모듈 | Generation | LLM을 사용해 답변 생성 | 문맥 기반 자연어 생성 |
| 기능 모듈 | Orchestration | 전체 흐름 제어 및 의사결정 | 조건 분기, 반복, 경로 선택 |
| 흐름 패턴 | Linear | 순차적 처리 구조 | 가장 단순, 빠름 |
| 흐름 패턴 | Conditional | 조건에 따라 다른 파이프라인 선택 | 상황별 맞춤 처리 |
| 흐름 패턴 | Branching | 여러 경로 병렬 실행 후 결합 | 다양성 증가, 성능 향상 |
| 흐름 패턴 | Loop | 반복 구조 (Iterative, Recursive, Adaptive) | 점진적 개선, 복잡 문제 해결 |
| 흐름 패턴 | Tuning | 모델 미세조정 (Retriever, Generator, Dual) | 성능 최적화 |
