Collaborative filtering
- content based filtering과 달리, 많은 사용자들로부터 얻은 기호정보에 따라 사용자들의 관심사들을 자동적으로 예측하게 해주는 방법
- 본 강의에서는 Collaborative filtering의 특성인 feature를 자동으로 학습하는 알고리즘에 대해 설명합니다.
등장배경
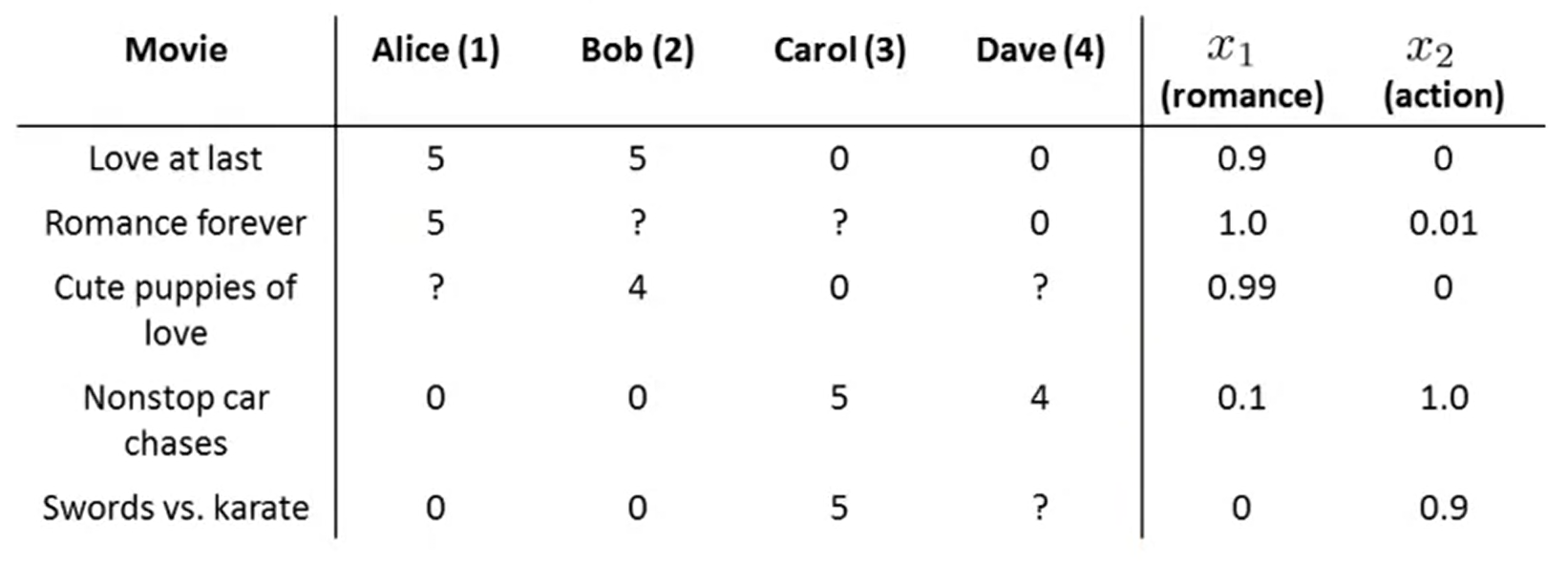
- 위의 그림에서 4명의 이용자와 5개의 영화, 그리고 2개의 feature(romance, action이 있음)
- 실질적으로 feature에 대한 수치화된 정보를 얻는 것은, 이용자들이 영화를 다 보고 설문을 남기는 방법 등으로 라벨링이 필요함(이 영화는 얼마나 로맨틱했나요? 등의 질문)
-> 굉장히 어려운 작업
개념
- 그러므로, feature 값들을 모른다고 가정해 보자.
이 때 각 개인의 값들을 가정해 보자.

- 로맨틱 선호하는 이용자는 , 액션을 선호하는 이용자는 로 된 벡터를 가정
- 벡터 연산의 결과에 의해 각각 feature , 값을 학습
- 그 결과로 , 의 연산 결과값이 5, ,의 연산 결과값이 0 인 것으로 미루어 보았을 때 feature가 높은 값을 가질 것이라고 예측할 수 있음(낭만적인 영화라고 볼 수 있음)
- 수식적으로 살펴 보면 , , 임을 유추할 수 있다.
그리고 이 될 것.
일반화한 식
하나의 feature에 대한 계산식

-
각 명의 이용자에 대한 선호도 정보가 담긴 parameter 가정
-
각 개의 feature에 대하여 학습을 통해 값을 예측
-
: j 번째 이용자가 남긴 평점 r(i,j)에 대해 iterate(j = 1,2,3)
-
= 예측한 평점
-
= 실제로 남긴 평점
-
나머지는 Regularization
여러 개의 feature를 아래와 같이 학습

업데이트 순서
guess -> -> -> ->...

- 합친 알고리즘
- 이 방법대로면,
사라지고 x의 차원은 n+1 이 아닌, n이 됨 ()
optimization

-
x와 랜덤값으로 초기화
- 이유는 symmetry breaking해서 다른 특징값으로 학습되도록 함이 목적
-
gradient를 이용하여 최소화
Reference
- Andrew Ng's ML - Collaborative filtering :
https://www.coursera.org/learn/machine-learning/lecture/f26nH/collaborative-filtering-algorithm

romantic ai developer