[https://light-tree.tistory.com/133]
📌(full) Batch Gradient Descent
- 전체 학습 데이터의 gradient를 평균내어 GD의 매번의 step마다 적용
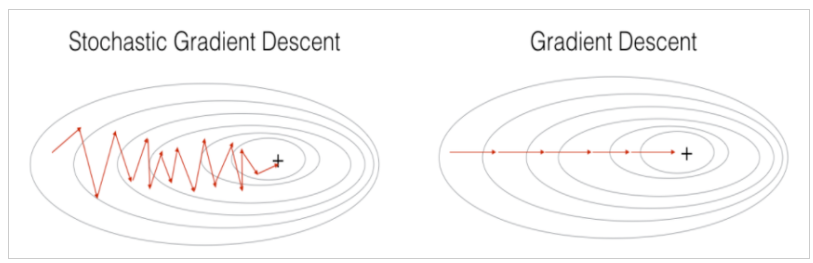
📌Stochastic Gradient Descent
- 데이터셋이 매우 큰경우, 매번 전체 학습 데이터를 연산하는 것은 메모리 사용량이 늘어나는 일임
- 하나의 데이터를 골라 인공신경망에 학습시킴
- full batch 와는 다르게 확률론적, 불확실성의 개념 도입
optimization의 loop는 아래와 같다.
- Take an example
- Feed it to Neural Network
- Calculate it’s gradient
- Use the gradient we calculated in step 3 to update the weights
- Repeat steps 1–4 for all the examples in training dataset
🧐SGD 장점
- SGD는 빠른속도로 수렴
- SGD는 local optima에 빠질 위험이 적음 . (fluctuate)
📌mini-Batch Gradient Descent
- 위 두 방법의 절충안
- 전체 학습 데이터를 minibatch로 나누어, GD 진행
optimization 의 loop 는 아래와 같다.
- Pick a mini-batch (하나의 데이터가 아닌)
- Feed it to Neural Network
- Calculate the mean gradient of the mini-batch (batch GD의 특성 적용)
- Use the mean gradient we calculated in step 3 to update the weights
- Repeat steps 1–4 for the mini-batches we created
🧐minibatch GD 장점
- SGD에 비해 local optima에 빠질 위험이 줄어듦
- 병렬처리에 유리(batch를 나누니까)
- Batch GD보다 메모리 사용을 절약할 수 있음
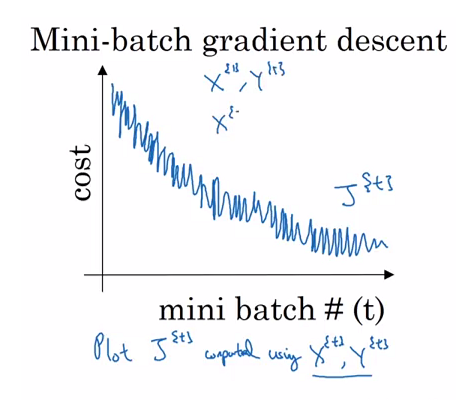
minibatch GD와 SGD는 최적화가 진행되면서 fluctuating 곡선을 보임 (매번 다른 gradient 평균을 적용하여 최적화를 진행하기 때문)
[ https://stats.stackexchange.com/questions/310734/why-is-the-mini-batch-gradient-descents-cost-function-graph-noisy]

romantic ai developer