csl313.log
로그인
csl313.log
로그인
Spark
StarLim
·
2024년 7월 15일
팔로우
0
Databricks
데이터 엔지니어
목록 보기
2/6
먼저 클러스터를 만들어야 한다.
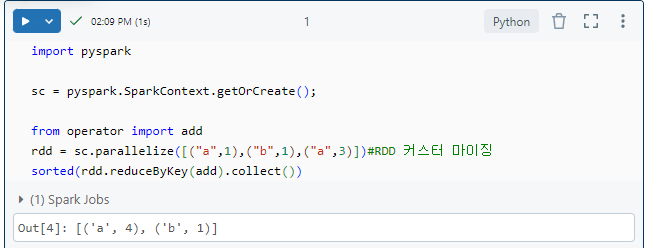
이후 Spark rdd를 통해서 커스터 마이징을 해봤습니다.
reducedBykey: key별로 value를 merger하는 것
StarLim
안녕하세요 반가워요
팔로우
이전 포스트
Airflow
다음 포스트
DBFS
0개의 댓글
댓글 작성