Key words
UTC/KST, ISO 8601, Scheduling, APScheduler, 부호화(Encoding), 복호화(=역부호화, Decoding), Pickle/피클링
오늘은 배운 내용과 실습해본 내용을 병기하겠다.
1. Time (UTC, KST, Timestamp)
- 오늘 첫 개념으로는
시간에 대해서 배웠다. 갑자기 왜 시간에 대해서 다루었을까? 아래와 같이 '시간'을 주의해야 하는 상황이 있기 때문이다.- 서비스에서 시간을 이용하는 경우
- 시간을 저장하는 경우
- 여러 노드에서 시간을 발생시키는 경우
- 이 중 오늘은 첫 번째
서비스에서 시간을 이용하는 경우에 대해서 주로 다루었다. 이 예시로 이전에 해봤던 github, tweepy API 문서를 보았는데, 보고 나니 그 필요성에 대해 이해하는데 도움이 되었다. 각각 아래와 같은 내용이 있다. - 즉, 내가 만약 _특정 시점 이후_에 작성된 게시물 등의 정보만을 가져오고 싶다면 이 '시간'을 이용해야 하는데, 이 기준이나 표현 형식은 API마다 다 다를 수 있기 때문에 잘 알아보고 세팅해야 한다는 것이다.
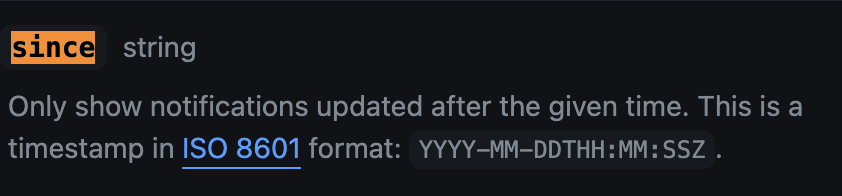

UTC / ISO 8601
- 우리는 어느 지역을 기준으로 시간을 사용할 수 있을까? 그 시간을 컴퓨터에서는 어떻게 표현할 수 있을까? 이 질문에 대한 답을 알 수 있는 이야기가 바로
UTC,ISO 8601이다. - UTC란?
- UTC는 영국 그리니치 천문대를 기준으로 시차를 규정한 것을 말한다. 흔히 들어본 GMT(Greenwich Mean Time)랑 같은 것으로 생각해도 된다고 한다.
- UTC는 시차를 규정하기 때문에 지역별 시차를 표현할 때는 다음과 같이 표현할 수 있다고 한다.
UTC±0# 기준UTC±[hh]:[mm]:[ss]UTC±[hh]:[mm]UTC±[hh]- +-가 영국 기준으로 어떤 방향인지는 흔히 우리가 계산하는 시차 생각하면 된다. 예를 들어 우리나라는
UTC+9로 할 수 있겠지.
- 터미널에
$ date -u치면 UTC 시간 볼 수 있다.
- KST는 Korea Standard Time으로 터미널에
$ date쳐보면 KST 기준 현재 시간을 확인할 수 있다. - ISO 8601이란?
- 정의는
날짜와 시간과 관련된 데이터 교환을 다루는 국제 표준이다. - 타임존을 통해 어디를 기준으로 시간을 사용할지는 정했는데, 이제 문제는 그 시간을 어떤 형식으로 표현할 것이냐이다.
- 예를 들어, 누구는
22-01-01로 하고, 누구는2022-01-01로 하고, 누구는2022-1-1로 하는 등 차이가 나면 각각의 서비스를 개발하고 배포하는 엔지니어에게는 굉장한 혼란이 오게 된다. - 따라서 우리 날짜/시간을 이러이러하게 표기합시다~라고 하기 위해 만들어진 국제 표준이라고 생각하면 된다
- 근데 문제는 이게 하나의 형식으로 지정되어 있지 않다고 한다.
(근데 그럴거면 이 표준이 무슨 의미가 있는겨..?)아무튼 그래서 위에서 github, tweepy API 문서 봤던 것처럼, 우리한테는 이런 형식으로 시간 넘겨줘~ 라고 확인하는게 중요한 것이다.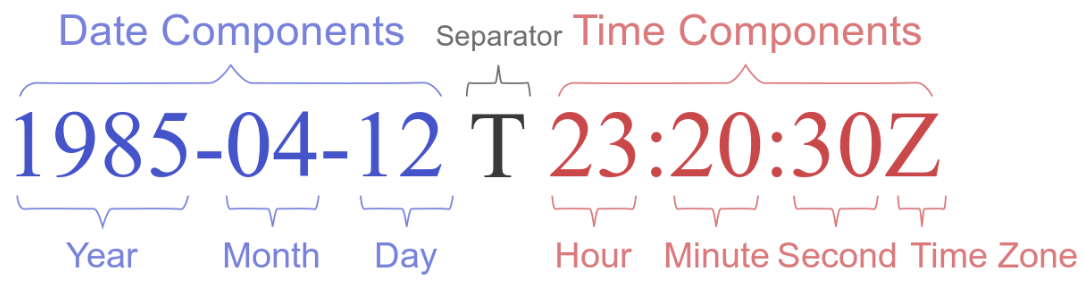
- 정의는
date +%s와 Unix Time- 지금 터미널에
$ date +%s를 치면1655713934이 나오는데, 이 시간은 Unix Time 혹은 Epoch Time 이라고 부른다. - Unix Time은 영국 기준 1970년 1월 1일 0시 0분 0초를 기준으로 시간이 표현된다.
- 예를 들어, 지금
1655713934는 이 유닉스 타임을 기준으로 1655713934초 지났다는 걸 말한다.
- 예를 들어, 지금
- Unix Time은 이렇게 사람이 시간을 바로 알기에는 직관성이 떨어진다. 그래서 Unix time은 절대적인 시간을 표현하려고 할 때 사용되지는 않고, 주로 특정 시간과 특정 시간 간의 차이를 표현하려고 할 때 사용된다고 한다. (= 시간 자체보다 시간을 이용한 연산에 활용!)
- 지금 터미널에
내가 무심코 써온 이 시간이라는 것에도 참 많은 히스토리가 있다는 게 참 신기한 일인 것 같다.
2. Scheduling / APScheduler
스케쥴링은 내가 지정한 작업을 정해진 시간에 맞춰 진행되도록 하는 것이라고 생각하면 될 것 같다.
- 예를 들어,
- 매일 15시에 일런 머스크의 트윗을 스크래이핑 해서 데이터를 수집하는 작업을 수행하라.
- 부하가 제일 적은 매일 새벽 4시에 회원, 주문 정보를 동기화해서 우리 DB에 저장하는 작업을 수행하라.
이전 회사에서 새벽으로 데이터 동기화 예약 걸어두는 거 많이 했었는데 딱 그거 생각하면 될 것 같다!! 예에~
APScheduler는 파이썬 라이브러리로 어플리케이션 딴에서 스케쥴링을 조정하는 방식이다. 오늘은 이 라이브러리를 통해 스케쥴링 하는 것에 대해서 배웠다.
- 공식문서 참고~ (항상 공식문서 보는 습관을 들이자!!)
- 참고
APScheduler말고 훨~~씬 더 많이 쓰이는Cron이라는게 있는데, 이건 unix 기반으로 운영체제 딴에서 동작한다고 함. 그래서 많은 문제점도 발견되고 있다고 함. 필요시 더 찾아보기.APScheduler는 파이썬 라이브러리이기 때문에 스케쥴러가 제대로 동작하기 위해서는 파이썬이 늘 켜져있어야 한다. 즉, 컴퓨터가 24시간 돌아가도록 해야할 수도 있단 말이다. 이럴 때 쓸 수 있는게 뭐다~? 지난 주에 배운AWS EC2를 이용하면 거기서 24시간 돌아가는 컴퓨터를 빌릴 수 있다~~
- 설치:
$ pip install apscheduler - 코드 작성은 크게 다음과 같은 순서로 기억하면 된다.
스케쥴러 선언하기 → 스케쥴러에 Job 선언하기 → 스케쥴러 시작하기
하나씩 살펴보자
[Step1. 스케쥴러 선언하기]
APScheduler에서는 다양한 스케쥴러를 선언해서 사용할 수 있다. 그 목적에 따라 쓸 수 있는 게 다양하게 있다.- 스케쥴러가 프로그램의 목적이 되는 경우:
BlockingScheduler - 다른 어플리케이션을 실행하는 게 주목적이고 스케쥴러는 부가 기능으로만 실행하는 경우
BackgroundSchedulerAsyncIOScheduleGeventSchedulerTornadoSchedulerTwistedSchedulerQtScheduler
- 스케쥴러가 프로그램의 목적이 되는 경우:
- 오늘은
BlockingScheduler만 써봤다. - 선언하기
from apscheduler.schedulers.blocking import BlockingScheduler
# UTC+0 기반으로 실행하려면 Timezone 에 매개변수를 선언 후 사용
scheduler = BlockingScheduler({'apscheduler.timezone':'UTC'})
# KST 기반으로 실행하는 방법
#scheduler = BlockingScheduler({'apscheduler.timezone':'Asia/seoul'})- (타임존 설정하는 것 잘 기억해두자.)
[Step2. 스케쥴러 Job 선언하기]
- 오늘은 세션과 동일하게 5초마다 특정 함수가 계속 실행되도록 해볼 것이다.
- 다음과 같은 함수를 작성했다.
from apscheduler.schedulers.blocking import BlockingScheduler
#스케쥴러 선언하기
scheduler = BlockingScheduler({'apscheduler.timezone':'UTC'})
#스케쥴러 job 선언하기
def hello():
print('Hola Mundo')
scheduler.add_job(func=hello, trigger='interval',seconds=5)- (나중에 필요하면 몇 번째 작업이 도는지 변수 값으 넣어서 print 되도록도 해보는 등 다양하게 변주할 수 있을 것 같다. )
- 자, 이제 job을 추가한다.
from apscheduler.schedulers.blocking import BlockingScheduler
#스케쥴러 선언하기
scheduler = BlockingScheduler({'apscheduler.timezone':'UTC'})
#스케쥴러 job 선언하기
def hello():
print('Hola Mundo')
scheduler.add_job(func=hello, trigger='interval',seconds=5)[Step3. 스케쥴러 시작하기]
scheduler.start()만 추가해주면 된다.
이제 파일을 실행해보면, 아래와 같이 5초마다 한번 씩 hello 함수에서 작성한 것이 출력되게 된다. 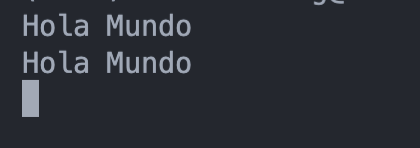
음.. 이번 프로젝트 때 어디까지 쓰게 될지는 모르겠지만 회사에 가면 주로 부하가 없는 시간 대를 많이 골라 작업하는 일이 많은텐데 그때 요긴하게 써먹을 수 있을 것 같다.
3. 객체 부호화 (Object Encoding)
- Encoding, Decoding의 활용성에 대해서는 딱 이 질문 하나로 확 이해가 되었다.
두다님, 저번에 머신러닝 모델 만든 거 저한테 전달 좀 해주세요. - 이럴 때 내가 쓴 코드랑 데이터 그대로 다 넘겨줄 순 없다! 그 사람이 받아서 그럼 내가 10시간 걸린 모델 학습 그대로 다시 해야 돼? 노노~~ Object Encoding, 즉 모델 객체만 인코딩해서 넘겨주면 그 사람은 모델을 바로 사용할 수 있게 된다.
- 객체는 크게 두 가지로 나뉘어 있다. 이에 따라 용어가 달라진다.
- 인메모리 방식
- 파이썬 코드가 실행되고 있는 메모리 안에서 표현되는 방식
- 쉽게 생각해 어디 파일로 저장하는 그게 아니라 내부에서 변수로 지정되어 사용되는 것 생각하면 될듯?
- 바이트열 방식
- 데이터를 파일에 쓰거나, 네트워크에서 전송되기 위한 표현 방식
- 인메모리 방식
- 그에 따른 용어
인메모리 방식 -> 바이트열 방식- 부호화, 인코딩, 마샬링, 직렬화, 피클링
- (쉽게 말해 내가 만든 모델을 파일로 바꾸는 거)
바이트열 방식 -> 인메모리 방식
- 복호화, 디코딩, 언마샬링, 역직렬화, 역피클링- (쉽게 말해 파일 받은 사람이 모델 쓸 수 있게 그 파일 다시 푸는 거)
이 인코딩, 디코딩에 Pickle을 사용하면 된다!!!
- Pickle에 대해선 이 코드 예시 좋은 듯. 어떻게 인코딩하고 디코딩되고 하는지 위주로 코드를 봐라.
import pickle
my_list = ['a', 'b', 'c']
# Encoding
with open("data.pickle", "wb") as file: #참고로 data.pkl로 해도 된다고 함. 바이트형으로 넘기기 때문에 'wb'임!!
pickle.dump(my_list, file) #파일로 던지기 때문에 dump다. 인메모리면 dumps. 이건 json이랑 동일함.
# 이렇게 하면 data.pickle이라는 파일이 생겨서 다른 사람에게 그 파일을 전달해주면 된다.
# Decoding - data.pickle 파일 받은 사람이 푸는 것
with open('data.pickle', 'rb') as read_file: # 바이트형이기 때문에 'rb'임!!
data = pickle.read(read_file)
print(data) # => ['a', 'b', 'c']- 참고
- 머신러닝 모델 넘길 때는 뭘 넘겨야 하냐? 하면
model = LinearRegression()처럼 이model을 넘겨주면 되는거야~ 대신 디코딩할 때load()함수를 사용함.
- 머신러닝 모델 넘길 때는 뭘 넘겨야 하냐? 하면
import pickle
model = None
with open('model.pkl','rb') as pickle_file:
model = pickle.load(pickle_file)
X_test = [[4000]]
y_pred = model.predict(X_test)
print(f'{X_test[0][0]} sqft GrLivArea를 가지는 주택의 예상 가격은 ${int(y_pred)} 입니다.')
[Json 데이터 인코딩/디코딩하기]
- 기본 매커니즘은 동일하다. 디테일만 조금 다름.
# 인코딩
data = {
"first_value": {
"name": "odee",
"album": "ZIPLOC"
}
}
import json
# json으로 부호화한 뒤, 객체에 읽을 때
json_data = json.dumps(data)
# json으로 부호화한 뒤, 파일에 쓸 때
with open('json_file.json','w') as json_file:
json.dump(data,json_file)# 디코딩
import json
str_1 = None
with open('json_file1.json','r') as json_file:
str_1 = json.load(json_file)
print(str_1)- 참고
- json 라이브러리는 항상 str로 객체를 생성함. (그래서
wb,rb가 아니라 그냥w,r인 것이다) - 디코딩하고 프린트한
str_1의 타입은 딕셔너리다.
- json 라이브러리는 항상 str로 객체를 생성함. (그래서
- json 데이터 인코딩, 디코딩의 활용 의미는
웹에서 받은 Json 데이터를 받아 딕셔너리로 확인하거나, 딕셔너리 데이터를 Json으로 변환한 뒤 웹 API로 전달할 수 있는 것으로 기억해두자! - Json, pickle은 파이썬에서 많이 쓰는 인코딩 방식이고 데이터 엔지니어링을 더 할수록 이외에도
마샬,struct,AVRO등 다양한 방식이 존재한다고 한다. 지금까지 사용한 csv, json, pickle이 문제점이 많은 데이터 형식임에도 많이 쓰이는 건 편리하기 때문이라고 함. 나중에 다시 마주칠 일이 있겠지..?
Feeling
- Section3의 마지막 노트가 끝났다. 벌써 3주가 지나갔다니.. 어째 Section2 때보다 시간이 더 빨리 간 것 같기도 하다.
- 섹션3 프로젝트 얘기를 듣는데 아직 감이 잘 안와서 걱정이 앞선다. 뭐 프로젝트 오티 듣고 하면 어떻게든 잘 되겠지! 아직 닥치지 않은 일 미리 걱정부터 하지 말자.
- 이번 섹션 배우느라 고생 많았고, 내일 스챌이랑 프로젝트까지 끝까지 잘 마무리 해보자! 아자아자!

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.