Key words
인공신경망, 딥러닝, 퍼셉트론(perceptron), XOR 문제, 입력층(input layer)/은닉층(hidden layer)/출력층(output layer), 활성화 함수(activation funcion), tensorflow, Keras(케라스)
1. 딥러닝이란?
Section4 - DeepLearning의 첫 날이었다. 약간 섹션 introudction 같은 날이었다.
- 가장 먼저 Warm-up 영상에서는 인공신경망/딥러닝의 역사와 발전에 대해서 쭉 보았다. 나중에 다시 필요하다면 저 영상을 한 번 더 보자.
- 한마디로 요약하면, 단층 퍼셉트론을 들고 나왔다가 XOR GATE 문제로 한 방 얻어맞고 힘든 시기를 보냈으나 이후 다층 퍼셉트론(= layer를 deep하게 쌓는다) 도입으로 부활했다고 할 수 있다. (다층 퍼셉트론 개념이 늦게 나왔다기보단 이론을 구현할 수 있는 환경의 뒷받침에 시간이 걸렸다고 보는게 맞을 것 같다)
- 참고로 딥러닝은 우리의 뇌가 작동하는 방식을 따온 것이라고 한다. 그래서 인공신경망! 그럼 왜 인공신경망이라고 안 하고 딥러닝이라고 하냐면, 웜업영상에 의하면, 예전에 인공신경망이라고 나와서 뚜들겨 맞아가지고 이름 바꾼 거라고도 한다.
진짜 그럴라나..
- 잠깐, 여기서 퍼셉트론(perceptron)이란?
신경망을 이루는 가장 기본 단위이다. 퍼셉트론은 다수의 신호를 받아 하나의 신호를 출력하는 구조다. 이 이미지가 기억에 도움이 될 듯.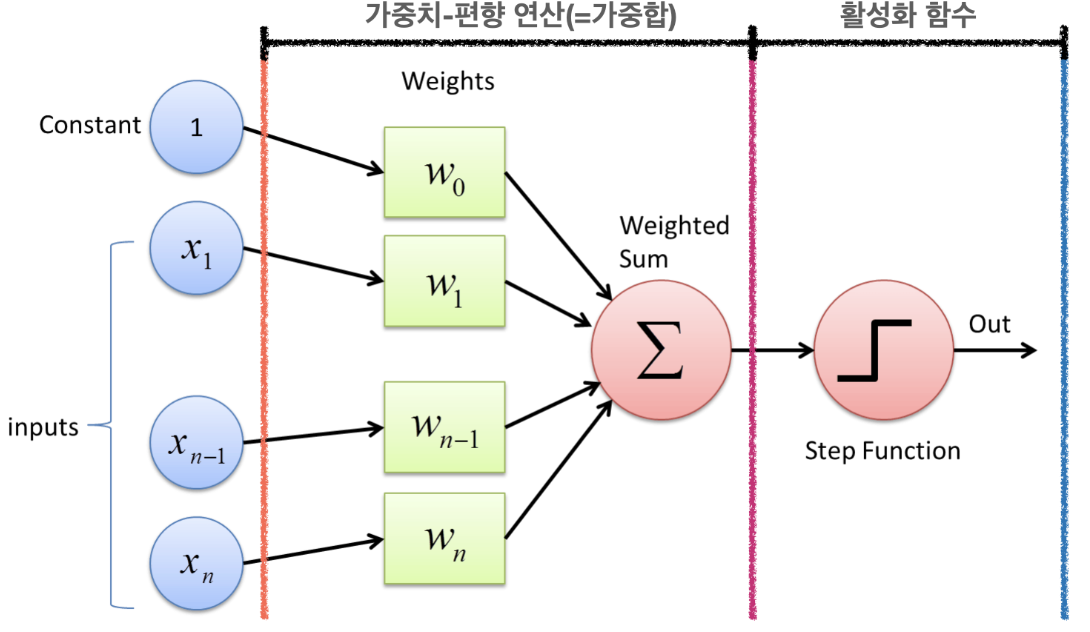
오늘 헷갈렸던게 있는데 퍼셉트론은 layer가 아니라 node를 말하는거다! 기억해!=> 수정) 단층 퍼셉트론/다층 퍼셉트론이라고 부르는 걸 보면 노드와 퍼셉트론이 같다고 보기는 무리가 있을 것 같다.뉴런=노드는 맞다.가중치-편향 연산에서는 입력된 신호에 각각의 가중치가 곱해져 합해진다. 그리고 이게 활성화함수를 거쳐 output으로 나오게 된다. flow 잘 기억해둬야 해~!!- (참고로 input layer의 contant(상수)는 편향이라고 한다. 섹션2에서 했던 편향과는 다른 의미이다. 예를 들어 치킨을 먹을까 밥을 먹을까를 고르는 문제에서 여러 입력값이 있을 수 있는데(점심에 기름진 걸 먹었는지 등), 이때 만약 이 사람이 치킨 알러지가 있다면? 그런 느낌이다.)
- 이 그림도 좀 기억해두자. 일반적으로 은닉층(hidden layer)이 2-3개 이상이면 딥러닝이라고 부른다고 한다. 레이어가 많을수록 무조건 좋은 건 아니고 역시 사바사라고 한다.
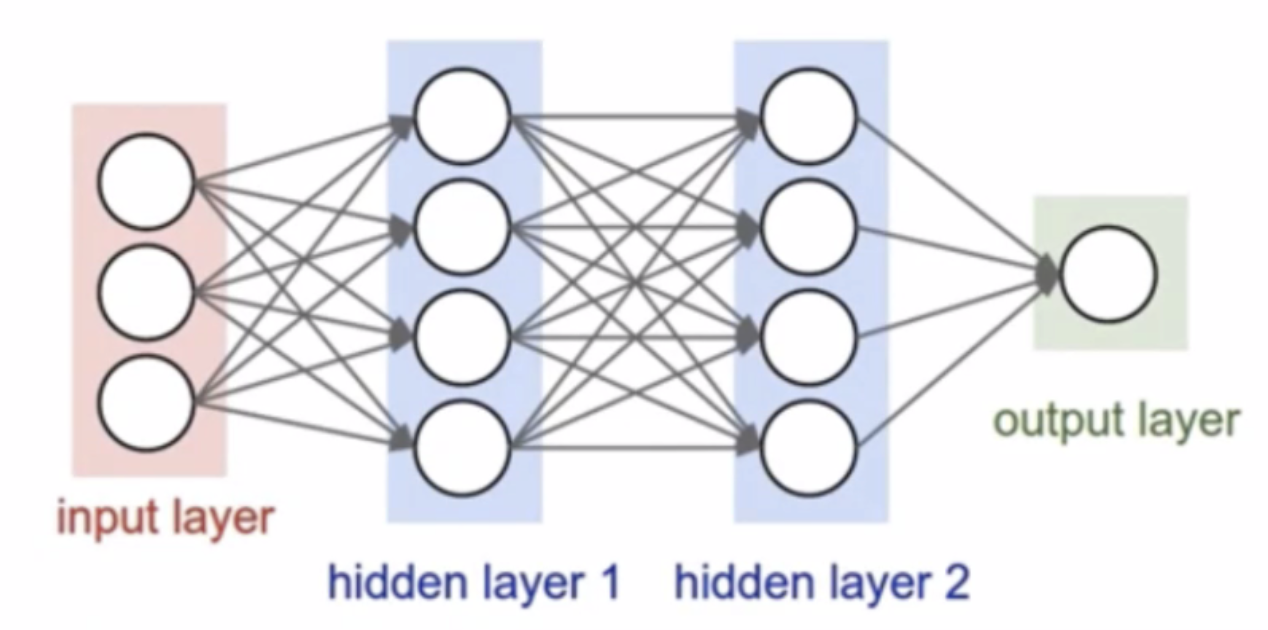
- 마지막으로 오늘 세션 초반부터 강조한 딥러닝을 바라볼 때 우리가 가져야할 마인드셋이 있었다. 그건 바로
정답은 없다.는 것이다. 뭐 어떤 기술을 쓰고, 층을 몇 개를 쌓아야 좋고 그런 정해진 게 없다는 얘기다. 그래서인지 오늘 실습 때도 정답을 요구하기보단 과정 후의 결과만 받고 끝났던 것 같다. (앞으로도 이런 식일듯?) 아무튼 이 마인드셋 기억해두자.
2. 활성화 함수의 종류
기본이 되는 활성화 함수(Activation function)로는 계단 함수(step function), 시그모이드 함수(sigmoid funcion), ReLU 함수, 소프트맥스 함수(Softmax funtion)이 있다.
-
계단 함수: 가장 간단한 형태의 활성화 함수로 임계값을 넘기면 1, 아니면 0을 출력하는 함수다. (아래 이미지에서 임계값은 0이다)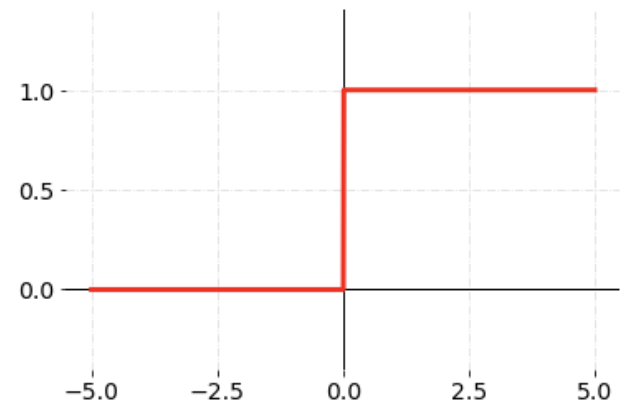
-
시그모이드 함수: 이건 로지스틱 회귀할 때 봤던 거라 익숙. 아직 잘은 모르겠지만, 신경망이 경사하강법을 통해 학습하기 위해서는 미분을 해야하는데, 앞서 봤던 계단 함수는 임계점에서는 미분이 불가능하고 나머지에선 0이 된다고 한다. 이런 문제를 해결할 수 있는게 이 시그모이드 함수다. 임계값보다 작은 부분은 0에 가까워지고, 큰 부분은 1에 가까워진다. -
ReLU 함수: 신경망 발전에 큰 공헌을 한 함수라고 한다. 역시나 아직 정확히는 이해할 수 없지만, 시그모이드 함수를 중복해서 사용하면기울기 소실문제가 발생하는데, 이를 해결할 수 있는 함수이다. 양의 값이 입력되면 그 값을 그대로, 음의 값이 입력되면 0을 출력한다. 그래프 기억해두자.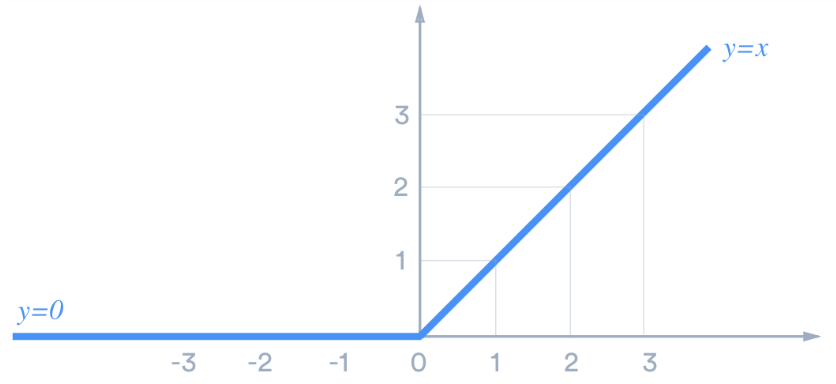
-
소프트맥스 함수: 다중 분류 문제에 쓰는 활성화 함수다. 다중 분류에 쓸 수 있도록 시그모이드 함수를 일반화한 것이다~ 정도만 일단 알고 넘어가도 될 것 같다. 가중합 값을 이 함수에 통과시키면 클래스의 합이 1인 확률값으로 변환해준다. -
활성화 함수는 여러개중 어떻게 골라야 하나요?- 대부분 보면 다중분류는 softmax 사용하고, 이중분류는 sigmoid 사용하고, 회귀는 연산된 값이 그대로 나와야하므로 활성화함수를 사용하지 않는다고 한다.
3. 논리 게이트
나중에 까먹기 딱 좋을 듯! 핵심만 정리해둔다. 오늘 배운 것 중 엄청나게 막 중요하건 아니라고 했지만, 그래도 이런 논리 생각해보는 건 재밌다.
AND GATE: 입력 신호가 모두 1(True)일 때 1(True)을 출력.NAND: Not AND 의 줄임말로 AND GATE의 결과의 반대를 출력.OR GATE: 입력 신호 중 하나만 1(True)이라도 1(True)을 출력.XOR GATE: 배타적 논리합(Exclusive-OR)이라고도 불리며, 입력 신호가 다를 경우 1(True)을 출력합니다.- 오늘 퀴즈 중에 아래 이미지의 x1, x2 입력값을 보고 XOR 게이트를 표현하는 문제가 있었다. (정답은
AND(NAND(x1, x2), OR(x1, x2))이다) 아래는 내가 풀때 적었던 거다. 지금 생각하면 역순으로 와도 됐을 듯 싶다.
- 글만 보고 헷갈릴 수 있으니
AND GATE그림 하나 놔둔다.
4. 인공신경망이란?
앞서 딥러닝 부분에서 다 언급하긴 했는데, 나중에 다시 보고 정리가 안될까 우려되어 따로 파트를 빼서 다시 정리해둔다,
- 인공신경망은 실제 신경계를 모사해서 만든 계산 모델이다. Neural Net이라고도 부른다. (참 신기하단 말이야.. 어제 커리어톡에 와주신 데싸 연사분도 의과학에서 인간신경계 연구로 박사학위 받으신 분이었다.)
신경망에는 입력층, 은닉층,출력층이 있다.
입력층: 데이터셋이 입력되는 층으로 입력되는 데이터셋의 특성(Feature)에 따라 입력층 노드의 수가 결정된다. (코드 쓸 때 잘 적어야 함) / 신경망의 깊이(층수)를 셀 때 입력층은 포함하지 않는다.은닉층: 연산이 이루어지는 단계고, 사용자가 볼 수 없어 은닉층이라고 불린다. (블랙박스 모델 생각하면 되려나..) 위에서 말한 것처럼 일반적으로 2-3개 이상이 은닉층을 가진 신경망을 딥러닝이라고 부른다고 한다.출력층: 은닉층 연산을 마친 값이 출력되는 층이다. 풀어야할 문제에 따라 이 출력층을 잘 구성하는게 매우 중요하다!!!!!!- 이진 분류(Binary Classification) : 활성화 함수로는 시그모이드(Sigmoid) 함수를 사용하며 출력층의 노드 수는 1로 설정한다. 출력되는 값이 0과 1 사이의 확률값이 되도록 한다.
- 다중 분류(Multi-class Classification) : 활성화 함수로는 소프트맥스(Softmax) 함수를 사용하며 출력층의 노드 수는 레이블의 클래스(Class) 수와 동일하게 설정한다.
- 회귀(Regression) : 일반적으로는 활성화 함수를 지정해주지 않으며(예측한 값이 변하지 말고 그대로 나와야하니까!!) 출력층의 노드 수는 출력값의 특성(Feature) 수와 동일하게 설정한다. (예. 단순히 하나의 수를 예측하는 문제라면 1로 해주면 된다고 함)
여기서 내 질문이 있었다.
왜 이진분류 문제에서는 출력층의 노드 수가 1이고, 다중분류 문제에서는 출력층의 노드 수를 클래스 수와 동일하게 하는지 궁금합니다. 출력층이 노드 수는 결국 나올 수 있는 경우의 수라고 이해했는데요. 그렇다면 좀 애매한 표현이긴 하지만, 이진분류는 ‘맞다/아니다’의 어떤 ‘하나의 상태’를 말하기 때문이고, 다중 분류는 하나의 상태라기보단 ‘여러 옵션 중 어떤 하나의 값' 을 고르는 것이기 때문이라고 생각해도 될까요?
- 출력함수로 걸러서 최종 결과가 나온다는 걸 생각하지 못 했었다. 답변을 듣고는 이해가 잘 갔다.
- 이진분류로 예를 들면, 1일 확률이 0.7이면 출력함수 겹쳐서 1로 나오는 거고. 다중분류는 아래와 같이.. 재밌었다.
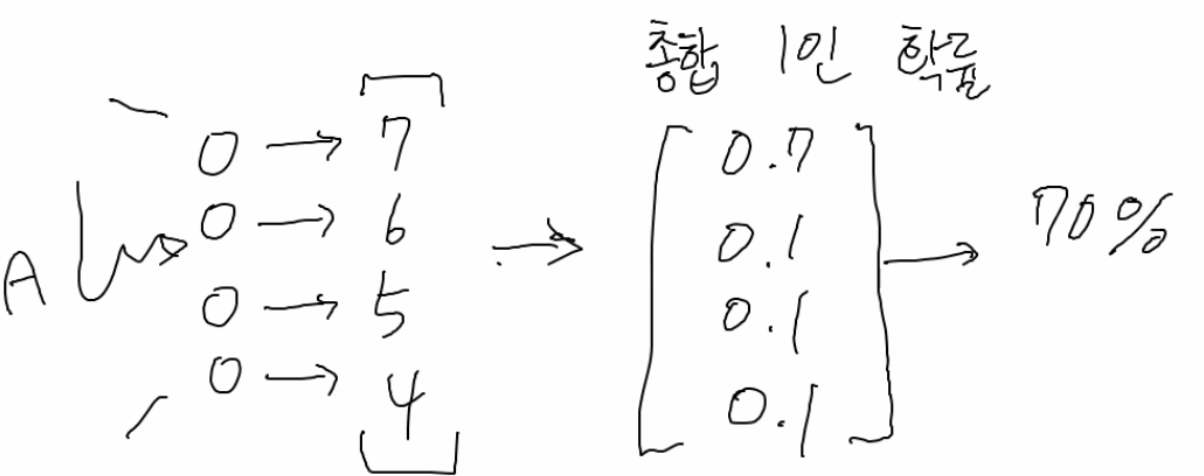
- 이진분류로 예를 들면, 1일 확률이 0.7이면 출력함수 겹쳐서 1로 나오는 거고. 다중분류는 아래와 같이.. 재밌었다.
5. 실습한 것
오늘은 퀴즈도 풀고 실습도 했는데 다 옮겨두지는 않을거고, 코드도 필요한 것만 옮겨둔다.
- 입력 데이터 샘플과 Features : 1077 샘플 x 69 Features (변수)
- 데이터 label: 다운증후군 (1), 정상군 (2)
=> 신경망 모델과 일반 머신러닝 모델 두 개를 만들어보고 성능을 비교해본다.
- 신경망 모델 만드는 것 자체는 어렵지 않았다. (세션 때 꽃 이진 분류와 0-9 손글씨 이미지 분류를 신경망 모델 만들어서 하는 걸 봤었어서..!) keras 코드 잘 쓰면 되는거니까 문제 없을 거고, 대신 좋은 성능을 어떻게 만드느냐가 더 중요해질 듯?
- 머신러닝 모델은 랜덤포레스트 기본으로 돌렸는데 괜히 성능이 너무 좋게 나와서 의아했다.
신경망 모델
(데이터 읽어오는 단계 생략)
#---풀기 전에 훈련, 검증 데이터 나눠두기---#
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df, df_label, test_size=0.2, random_state=42)
y_train = y_train.values.ravel()
y_test = y_test.values.ravel() # array로 변환 - 참고 https://stackoverflow.com/questions/34165731/a-column-vector-y-was-passed-when-a-1d-array-was-expected
X_train.shape, X_test.shape, y_train.shape, y_test.shape # 확인 완료
--
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='sgd',
loss='binary_crossentropy',
metrics=['accuracy'])
#참고로 optimize, loss에 대해서는 앞으로 알게될 거니까 오늘은 이런게 있다 정도만 알고 있으면 된다고 했다.
model.fit(X_train, y_train, epochs=30) # 학습 30번 반복. epoch도 역시 다음 노트 때 배울거라고 했다.
model.evaluate(X_test, y_test, verbose=2)5. 그 외
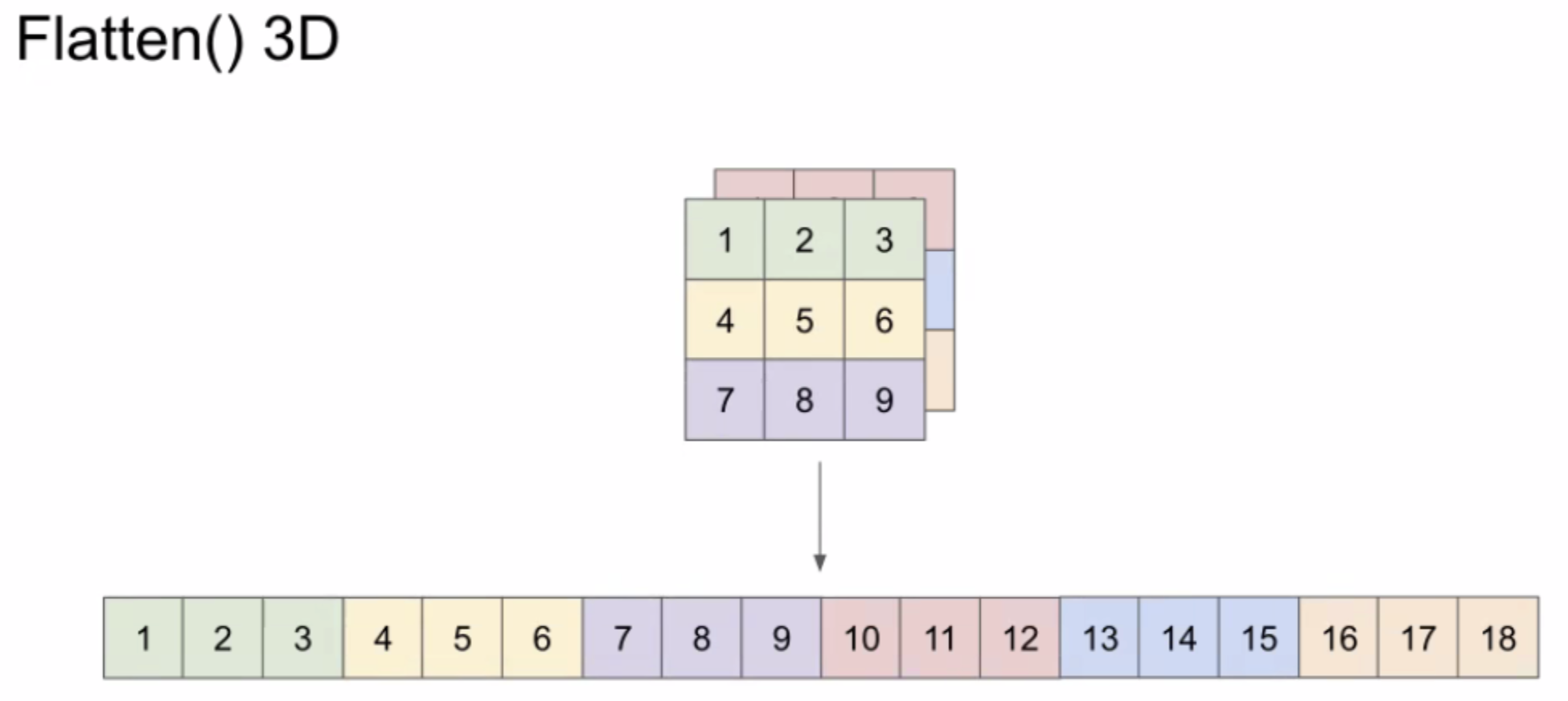
- 0-9 손글씨 이미지 분류 문제에서 이미지가 28px*28px 이라서 flatten 하는 부분이 있었다. flatten 3D는 아래같이 하는거라고 생각하면 되는데, 이렇게 하는 이유는 신경망 모델이 데이터를 받을 때 array형태여야 하기 때문이라고 한다. 다시 만나게 될 거 같다.
데이터 탐색을 시작하기 전에 데이터셋에 결측치가 있는지, 각 column의 데이터 타입이 무엇인지 확인하는 습관을 갖도록 합시다.=> 잊지 말자 제발!!!
Feeling
- 오늘은 딥러닝 세션 첫 날이었다. 금요일이라서 그런지 큰 긴장은 안 하고 시작했는데 바로 함수 같은 수학 얘기가 나와서 참으로 심란했다ㅋㅋㅋㅋ 지난 달 데이터 엔지니어링 파트에서는 그래도 수학은 안 나와서 괜찮았는데 말이다.
- 아무튼 그만큼 내가 개인적으로 수학 공부도 하고 보충하는게 중요할 것 같다. 앞으로 한 달 잘 해보자~!!!
