Key words
자연어 처리(자연어 이해, 자연어 생성), 벡터화, SpaCy, 토큰화, 불용어, 통계적 트리밍, 어간추추출, 표제어 추출, Counter-based Representation(Bag of words - TF / TF-IDF, 코사인 유사도
NOTE
각 과정마다 파이썬으로 어떻게 구현하는지 다 적으면 너무 길어져서 개념은 가능한 설명만 남기려고 했다. 상세한 코드가 궁금하면실습한 것부분을 보면 된다.
1. 자연어 처리란?
- 오늘은 자연어 처리(Natural Language Processing)에 대해 배웠다. 이전 회사에서부터 계속 말만 들어왔지 내가 직접 해보게 되다니..! 감개가 무량하다고 할 수 있겠다.
- 자연어란 우리가 그냥 일상적으로 쓰는 언어라고 생각하면 된다. 자연어 처리란 이런 자연어를 컴퓨터로 처리하는 기술을 말한다. (반대로 파이썬 등의 컴퓨터 언어 같이 인위적으로 만든 언어는 인공어라고 한다.)
- 자연어 처리로 할 수 있는 건 아래와 같다.
- 외우려고 하지 말고 '아~ 이런게 있구나! 나중에 이런 걸 내가 할 수 있겠구나!'라고 이해하기만 하면 된다.
자연어 이해(NLU, NL Understanding)- 분류(Classification): 기사분류/감성분석(P or N)
- 자연어 추론(NL Inferenct)
- 기계 독해(MRC), 질의응답(QnA)
- 품사 태깅(Pos tagging), 개체명 인식(Named Entity Recognition)
- 추출 요약: 문서 내 가장 잘 요약하는 부분 찾아내기. 우리가 형광펜 치는 것과 같음.
자연어 생성(NLG, NL Generation)- 텍스트 생성: ex- 뉴스기사 생성하기
NLU + NLG: 둘이 같이 쓰이는 것.- 기계번역, 생성요약(Absractive Summerization), Chatbot
- 이해도 해야하고, 그걸 바탕으로 글도 만들어내야 한다는 의미로 생각하면 된다.
자연어 처리의 개념에 대해선 그리 어렵지 않았다. 그러면 이제부터 본격적으로 자연어 처리 작업을 하기 위해 무엇을 해야하는지 프로세스 순서에 맞게 설명을 이어가겠다. 지금부터가 시작이다.
2. 텍스트 전처리 (Text Preprocessing)
텍스트 데이터를 전처리하는 건 자연어처리의 시작이자 절반 이상을 차지하는 중요한 과정이라고 한다.
- 지금까지 전처리하며 해왔던 것과 같이 텍스트 데이터를 다룰 때에는 데이터를 충분히 이리보고 저리보면서 어떤 특이사항이 있는지 파악하는 습관을 가지도록 하자! 급하다고 바로 뛰어들 생각하지 말고!
- 전처리를 하는 이유는 차원의 저주를 피하기 위해서다. 이따 보겠지만 횟수 기반의 벡터화를 하면 말뭉치에 존재하는 단어의 종류가 데이터셋의 특성이 된다. 즉, 차원이 기하급수적으로 늘어나면 차원에 저주에 빠지기 때문에 같은/비슷한 단어는 묶고, 필요없는 단어는 없애는 등의 전처리를 해주는 것이다.
- 이따가
벡터화(Vectorize)에 대해서 말할건데, 컴퓨터가 이해할 수 있도록 벡터화를 해주기 전에 이 텍스트 전처리를 해주는 거다. 머릿속에 그림 잘 그려놔야 나중에 안 헷갈린다!! - 자연어 처리를 시작하며 새로운 용어가 많이 나왔는데, 몇개 정리만 해두고 넘어가자.
- 말뭉치(Corpus) : 특정한 목적을 가지고 수집한 텍스트 데이터
- 문서(Document) : 문장(Sentence)들의 집합
- 문장(Sentence) : 여러 개의 토큰(단어, 형태소 등)으로 구성된 문자열. 마침표, 느낌표 등의 기호로 구분
- 어휘집합(Vocabulary) : 코퍼스에 있는 모든 문서, 문장을 토큰화한 후 중복을 제거한 토큰의 집합
- 토큰(Token): 최소 의미를 갖는 단위. 이따 문장을
토큰화할건데, 해보면 어떤 의미인지 알 수 있다.
오늘 텍스트 전처리를 하며 다양한 걸 해보게 되었는데 간단히 요약하면 아래와 같다. 이거 잘 기억해!!!
토큰화(tokenize), 대소문자 통일(
lower()등), 정규표현식을 사용해 필요없는 부분 제거, 불용어(Stop Words) 처리, 통계적 트리밍(Trimming), 어간추출(Stemming), 표제어 추출(Lemmatization)
아이고 많다 많아! 몇개만 좀 더 자세히 보자.
정규표현식(Regular Expression)- 구두점, 특수문자 등 필요없는 부분을 제거하기 위해 이 정규표현식을 사용한다. 영대문자만 남기고 싶다거나, 숫자만 남기고 싶다거나 할 때도 사용할 수 있다.
- 정규표현식은 파이썬 활용에 날개를 달아줄 수 있는 무기기도 하지만, 동시에 상당히 까다롭기 때문에 기본적인 것만 계속 해보며 익숙해지되 나머지는 그때그때 필요한 상황에 맞게 익히는 걸 추천한다고 한다.
- 오늘 주요하게 썼던 하나만 간단히 적어둔다.
# 정규표현식 패키지 import
import re
# 정규식 지정
regex = r"[^a-zA-Z0-9 ]"
'''
참고로 ^는 not을 의미한다. 영소문자, 영대문자, 숫자0-9, 공백이 아닌 것(not)은 다 변경하겠는 표현이다.
'''
# 정규식을 적용할 문자열 할당하기
test_str = "(Natural Language Processing) is easy!, AI!\n"
# 해당되는 패턴의 문자를 어떤 문자로 바꿀 지를 지정하기
subst = "" # 없애겠다는 것
result = re.sub(regex, subst, test_str)
result # => Natural Language Processing is easy AICounter클래스- 각 단어별로 몇개나 있는지 알려면 어떻게 해야할까? 그때 이 Counter를 쓰면 된다.
- Counter 클래스는 요소의 값을 key, 요소의 갯수를 value 로 하는 딕셔너리를 반환한다.
.update메서드를 사용하면 각 행에 적용되는 결과를 업데이트 할 수 있다.- 이후
.most_common메서드를 적용하여 상위 n개 결과를 리스트 형태로 출력할 수 있다. - 백마디 말보단 코드로 보자.
from collections import Counter
# Counter 객체 생성
word_counts = Counter()
'''
- Counter 객체는 리스트 요소의 값과 요소의 갯수를 카운트 하여 저장하고 있는다.
- 카운터 객체는 .update 메소드로 계속 업데이트 가능합니다.
'''
# 토큰화된 각 리뷰 리스트를 카운터 객체에 업데이트하기
df['tokens'].apply(lambda x: word_counts.update(x))
'''
토큰으로 쪼개져 있는(= 단어)걸 하나씩 꺼내서 Counter 객체에 업데이트 하면 같은 단어는 계속 카운트가 올라가며 저장되어 있는거라고 생각하면 된다.
'''
# Top_10 보기
word_counts.most_common(10)SpaCy- 문서 구성요소를 다양한 구조에 나누어 저장하지 않고 요소를 색인화하여 검색 정보를 간단히 저장하는 라이브러리이다.
- 오늘은 주로 이 라이브러리를 사용해 토큰화했다. 이것도 간단히 예시 남겨준다. 헷갈리기 딱 좋아보임.
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("en_core_web_sm")
tokenizer = Tokenizer(nlp.vocab)
tokens = []
for doc in tokenizer.pipe(df['reviews.text']): #데이터프레임의 분석할 열이다.
doc_tokens = [re.sub(r"[^a-z0-9]", "", token.text.lower()) for token in doc]
tokens.append(doc_tokens)
df['tokens'] = tokens
df['tokens'].head()
- 아, 이렇게 토큰화한거를 단어별 count 등을 한 데이터프레임으로 가공한 다음에
squarify라는 시각화 라이브러리 이용하면 아래와 같이도 표현할 수 있다. 신기했다!
import squarify
import matplotlib.pyplot as plt
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()
불용어(Stop Words) 처리- 불용어란 the, and, i와 같이 문장(ex. 제품 리뷰)을 이해하는데 그다지 도움지 안되는 단어를 말한다. 이런 건 없애줘야 차원을 줄일 수 있겠지.
- SpaCy에서 기본적으로 불용어를 제공하고 있고, 원하는 단어를 추가해줄 수도 있다. 추가해서 쓰는건 이따 실습 코드에 있으니 볼 것.
통계적 트리밍(Trimming)- 이건 쉽게 생각해 통계적으로 너어무 자주나타나거나 너어무 드물게 나타나는 토큰을 제거해버리는 걸 말한다. 너무 자주 나타난다는 건 변별력이 없다는 거고 너무 드물게 나타난다는 건 또 의미있는 정보를 주지 못하니까. 불용어 처리하고 이것도 한 번 본다~로 생각하자. (참고로 오늘 실습때는 트리밍을 하진 않음)
어간 추출(stemming) / 표제어 추출(Lemmatization)
이건 중요하니까 문단 구분을 좀 해서 적어둬야겠다.
- battery와 batteries는 같은 단어지만 토큰화를 해도 다른 단어로 취급된다. 이런 걸 같은 토큰으로 인식하도록 해주는 게 차원을 줄이기 위해 중요하겠지. 이럴 때는 **어간 추출, 표제어 추출을 통해 정규화(Normalization)하는 과정이 필요하다.
어간 추출(stemming)- 어간 추출은 'ing', 'ed', 's' 등과 같은, 단어의 앞/뒷부분을 단순히 제거한다.
- 예를 들어 wolves > wolv 까지만!
- SpaCy에서는 어간 추출을 제공하지 않아서 nltk 라이브러를 사용해야 한다.
from nltk.stem import PorterStemmer
ps = PorterStemmer()
words = ["wolf", "wolves"]
for word in words:
print(ps.stem(word)) #=> wolf wolv표제어 추출(Lemmatization)- 표제어 추출은 단어를 기본 사전형 형태인 Lemma로 변환한다. 그래서 어간추출보다 좀 더 복잡하고 시간이 오래 걸린다.
- 예를 들어 복수형은 단수형으로, am은 be로 바뀌는 식이다. 아까 위에서 wolves가 어간 추출을 하면 wolv였지만, 표제어추출을 거치면 wolf가 된다.
- 이건 SpaCy에서 지원한다.
lem = "The social wolf. Wolves are complex."
nlp = spacy.load("en_core_web_sm")
doc = nlp(lem)
for token in doc:
print(token.text, token.lemma_, sep=" ")
'''
[출력 결과]
The the
social social
wolf wolf
. .
Wolves wolf
are be
complex complex
. .
'''자, 지금까지 벡터화를 하기 전 데이터 전처리를 할 때 무엇을 하는지에 대해서 적어봤다. 내용이 너무 많아 헷갈릴 것 같긴 한데,, 그래도 무작정 외우려고 하기보단 내가 자연어 처리 프로젝트 와중에 있다고 생각하고 보면 좀 더 각 과정들의 필요성과 의미가 잘 기억될 것이다.
3. 벡터화(Vectorize)
- 자연어 그대로를 컴퓨터는 이해할 수 없기 때문에, 컴퓨터가 이해할 수 있도록 벡터로 만들어주는 과정을 벡터화하고 한다.
- 당연하겠지만, 자연어를 어떻게 벡터화해주느냐에 따라 자연어 처리 모델의 성능이 달라질 수 있다고 한다.
- 벡터화된 문서는
문서-단어 행렬(DTM, Document-Term Matrix)의 형태로 나타내진다. 아래와 같다고 생각하면 된다.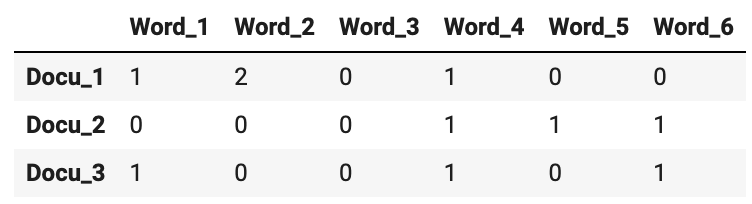
- 자연어 벡터화의 방법은 아래 2가지가 있다.
등장 횟수 기반의 단어 표현(Count-based Representation): 단어가 문서(혹은 문장)에 등장하는 횟수를 기반으로 벡터화하는 방법Bag-of-Words (CounterVectorizer)TF-IDF (TfidfVectorizer)
분포 기반의 단어 표현(Distributed Representation): 타겟 단어 주변에 있는 단어를 기반으로 벡터화하는 방법Word2Vec(CBoW, Skip-gram)fastText
난 오늘 이 중 Count-based Representation)에 대해 배웠다.
Bag-of-Words(BoW) - TF(Term Frequency)- BoW는 가장 단순한 벡터화 방법 중 하나이다. 문서(or 문장)에서 문법이나 단어의 순서 등은 무시하고 단어들의 빈도만 고려하여 백터화한다.
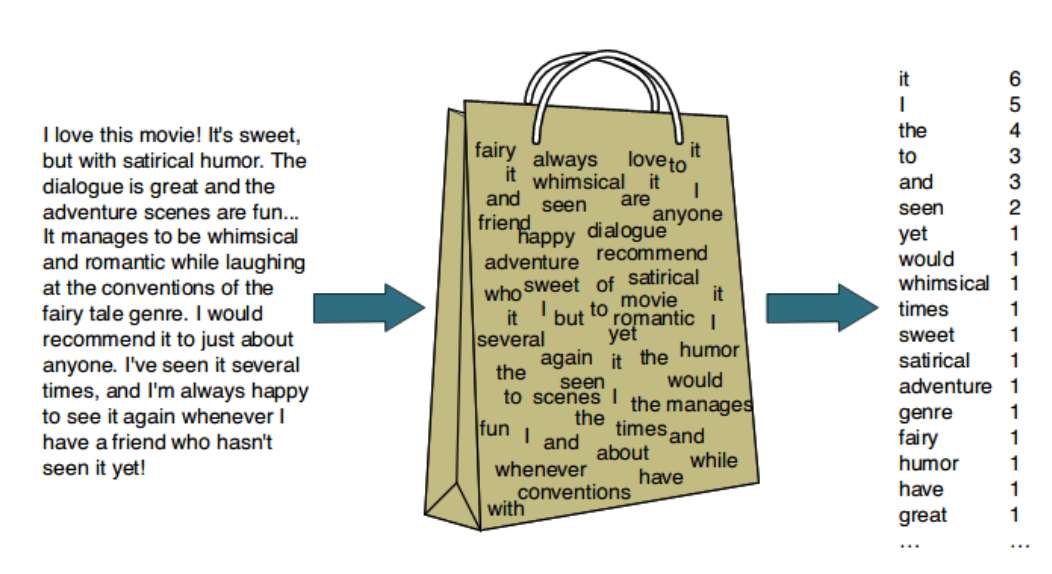
- 사이킷런(Scikit-learn, Sklearn) 의
CounterVectorizer를 사용하면 TF 방식으로 문서를 벡터화 할 수 있다. - 적용하는 코드는 너무 길어서 옮겨두진 못하겠고,, 필요시 찾아보자.
- BoW는 가장 단순한 벡터화 방법 중 하나이다. 문서(or 문장)에서 문법이나 단어의 순서 등은 무시하고 단어들의 빈도만 고려하여 백터화한다.
Bag-of-Words(BoW) - TF-IDF(Term Frequency-Inverse Document Frequency)- 다른 문서에 잘 등장하지 않는 단어라면 해당 문서를 대표할 수 있는 단어가 될 수 있겠다는 아이디어 아래 나온 TF-IDF는 다른 문서에 적게 등장하는 단어에 가중치를 두는 방법이다.
- TF-IDF의 수식은
TF(w)*IDF(w)인데 IDF(w)의 수식은 다음과 같다.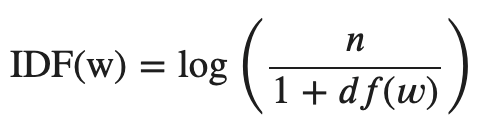
- n = 분류 대상이 되는 모든 문서의 수 / df(w) = 단어 W가 들어있는 문서의 수다.
- 분모에 1을 더한 건 단어가 없을 경우 0으로 나누어지는 걸 막기 위해서라고 한다. 왜 log를 취해주는 지 궁금하면 Zipf's law에 대해서 찾아보라고 한다.
- 사이킷런(Scikit-learn, Sklearn) 의
TfidfVectorizer를 사용하면 TF-IDF 벡터화도 사용할 수 있다.
4. 실습한 것
코드의 활용을 잘 기억하자. 내가 적은 건 아무래도 내 흐름대로 진행되었기 때문에 일반화하기에는 좀 덜 깔끔할 수도 있다. (실제로 오늘 노트에서는 함수 만들어서 전처리 벡터화까지 한번에 했지만 나는 다 쪼개서 직접 했다) 하지만 각 흐름과 구현을 이해하고 있다면 나중에 써먹는데 큰 문제는 없을 것이다.
[오늘 분석할 것]
- indeed.com 에서 Data Scientist 키워드로 Job descrition을 찾아 스크래핑한 데이터를 이용해 과제를 진행해 보겠습니다.
Data_Scienties.csv파일에는 1300여개의 Data Scientist job description 정보가 담겨 있습니다.
데이터 전처리
[중복행 제거]
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/indeed/Data_Scientist.csv')
# title, company, description 에 해당하는 Column만 남기기
df = df[['title', 'company', 'description']]
print('중복행 제거 전', df.shape)
# 중복행 제거
df = df.drop_duplicates(ignore_index=True) # 인덱스 재설정 / 레퍼런스 https://mizykk.tistory.com/93
print('중복행 제거 후', df.shape)
df.head()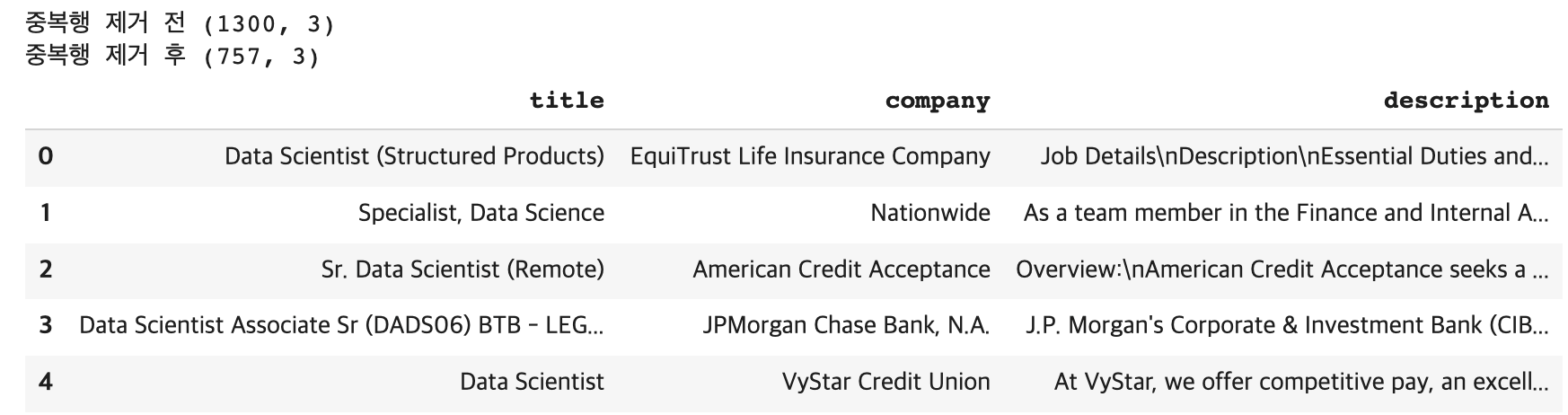
[토큰 정제하기]
- 문항 1) 대문자를 소문자로 변경하는 함수를 입력하세요.
- 문항 2) 정규 표현식을 사용하여 re 라이브러리에서 알파벳 소문자, 숫자만 받을 수 있는 코드를 작성하세요.
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("en_core_web_sm")
tokenizer = Tokenizer(nlp.vocab)
# 함수 만들기 (3개 칼럼 해줘야 하니까 편의상)
def to_token(df_col):
tokens = []
for doc in tokenizer.pipe(df_col):
doc_tokens = [re.sub(r"[^a-z0-9]", "", token.text.lower()) for token in doc]
tokens.append(doc_tokens)
return tokens
# 토큰화 하기
df['title'] = to_token(df['title'])
df['company'] = to_token(df['company'])
df['description'] = to_token(df['description'])
df.tail()
#근데 tl;dr의 토큰화가 'tl', 'dr'이 아니라 'tldr'이 되는지 궁금하다. 아마도 tokenizer 기준에 ;, : 등의 특수문자는 알아서 분리 단위로 인식하지 않도록 되어있는듯?
# 토큰 리스트에 공백값 들어가 있는 것 없애자. (ex - [tldr, , spring, is, accelerating, the, discov...]) // 의미없는 값이라 굳이 필요 없어보이긴 하지만 연습삼아 해보기.
def remove_value(list):
list = [v for v in list if v] # 레퍼런스 https://jinmay.github.io/2019/06/30/python/python-how-to-delete-empty-string-in-list/
return list
df['title'] = df['title'].apply(lambda x: remove_value(x))
df['company'] = df['company'].apply(lambda x: remove_value(x))
df['description'] = df['description'].apply(lambda x: remove_value(x))
df.tail() # 깔끔! 속이 편해졌다.
[정제한 토큰 시각화]
- Top 10 토큰을 프린트 합니다.
- 토큰의 수, 빈도 순위, 존재 문서 수, 비율 등 정보를 계산합니다.
- 토큰 순위에 따른 퍼센트 누적 분포 그래프를 시각화합니다.
# 세 칼럼에 각각 있는 토큰 리스트 한 곳에 모으기 (token 기준)
all_tokens = []
for doc in df['title']:
for v in doc:
all_tokens.append(v)
for doc in df['company']:
for v in doc:
all_tokens.append(v)
for doc in df['description']:
for v in doc:
all_tokens.append(v)
print('토큰 총 갯수 = ', len(all_tokens), '\n')
# 데이터 프레임으로 만들기
all_tokens_df = pd.DataFrame(all_tokens, columns = ['token'])
# 단어별 전체 카운트
from collections import Counter
word_counts = Counter()
all_tokens_df.apply(lambda x: word_counts.update(x))
word_counts.most_common(10) # Top10# 세 칼럼에 각각 있는 토큰 리스트 한 곳에 모으기 (doc 기준)
all_tokens_doc = []
for doc in df['title']:
all_tokens_doc.append(doc)
for doc in df['company']:
all_tokens_doc.append(doc)
for doc in df['description']:
all_tokens_doc.append(doc)
print('doc 총 갯수 = ', len(all_tokens_doc), '\n')
# 데이터 프레임으로 만들기
all_tokens_doc_df = pd.DataFrame([all_tokens_doc]).T.rename(columns = {0:'docs'})
# 단어별 존재하는 문장 카운트
word_doc_counts = Counter()
for doc in all_tokens_doc:
word_doc_counts.update(set(doc))
# 참고로 이렇게 해보려고 했는데 잘 안되서 걍 for문 돌림 - all_tokens_doc.apply(lambda x: word_doc_counts.update(set(x)))
word_doc_counts.most_common(10)## 토큰의 수, 빈도 순위, 존재 문서 수, 비율 등 정보 계산. (여기선 한번만 작업할 거니 함수 따로 안 만들고 위 셀에서 진행한 것 가지고 활용) ##
# word & counts 먼저 데이터프레임으로 만들기
word_n_counts = zip(word_counts.keys(), word_counts.values()) # zip() 레퍼런스 https://ooyoung.tistory.com/60
wc = pd.DataFrame(word_n_counts, columns = ['word', 'counts'])
# rank 칼럼 추가
wc['rank'] = wc['counts'].rank(method = 'first', ascending = False).astype(int) #rank() 레퍼런스 https://rfriend.tistory.com/461
# 전체 대비 비율 칼럼 추가
len_total = len(all_tokens)
wc['percent'] = wc['counts'].apply(lambda x: x / len_total)
# 누적 비율 칼럼 추가하기 전 rank 별로 소팅하기
wc = wc.sort_values(by='rank')
# 누적 비율 칼럼 추가
wc['cul_percent'] = wc['percent'].cumsum() # cumsum() 레퍼런스 https://runebook.dev/ko/docs/numpy/reference/generated/numpy.cumsum
wc.head(10)
## word_in_docs 등 더 넣을 수 있는 건 굳이 지금 안 넣겠다.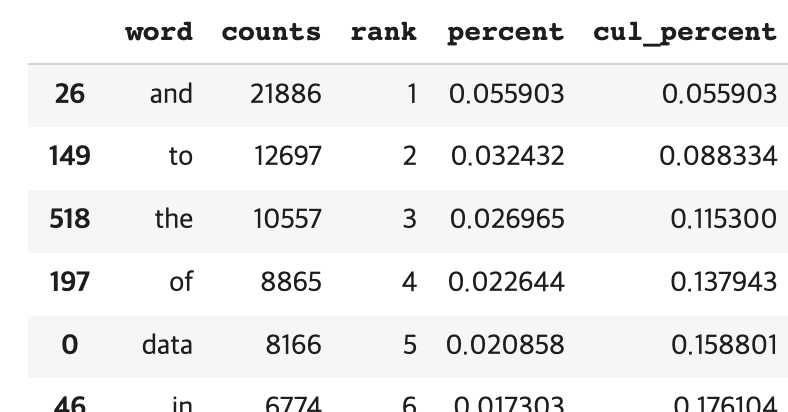
# 누적 비율 시각화
import seaborn as sns
sns.lineplot(x='rank', y='cul_percent', data=wc);
# => 여기까지 해본 소감 - 이번이야 함수 안 만들고 이렇게 단계별로 해보며 원리 이해하기 좋았음. 여러 번 작업해야하면 함수 만들어서 하는게 1000000만배 낫겠다. 
[불용어 처리]
- 문항 4) 기본 불용어 사전에 두 단어("data", "work")를 추가하는 코드를 사용해주세요.
- 문항 5) 불용어를 제거하고 난 뒤 토큰 순위 10개의 단어를 입력하세요.
# 기본 불용어 사전에 두 단어("data", "work")를 추가
STOP_WORDS = nlp.Defaults.stop_words.union(['data', 'work'])
all_tokens_df.head(10) # 아까 단어별로 데이터프레임 만들어두었던 것. 여기서 STOP_WORDS에 있는 단어는 빼줄거다.
# 토큰 정제하기
tokens_not_stop_words = []
for v in all_tokens_df['token']:
if v not in STOP_WORDS:
tokens_not_stop_words.append(v)
tokens_not_stop_words_df = pd.DataFrame(tokens_not_stop_words, columns = ['token'])
tokens_not_stop_words_df.head(10)
# 단어별 전체 카운트
word_counts2 = Counter()
tokens_not_stop_words_df.apply(lambda x: word_counts2.update(x))
word_counts2.most_common(10) # Top10[Lemmatization]
- 문항 6) Lemmatization을 진행한 뒤 상위 10개 단어를 입력하세요.
# 불용어 제거된 위에꺼 그대로 가져다 써서 해볼건데, 그러면 일반 스트링이가 lemma_를 적용 못함. 적절한 조치를 해서 사용할 것이다. (AttributeError: 'str' object has no attribute 'lemma_')
def get_lemmas(text):
lemmas = []
doc = nlp(text) #이게 그 조치임.
for v in doc:
lemmas.append(v.lemma_)
return lemmas[0]
tokens_not_stop_words_df['lemma'] = tokens_not_stop_words_df['token'].apply(get_lemmas)
tokens_not_stop_words_df.head(10)
# Top10
lemma_df = pd.DataFrame(tokens_not_stop_words_df['lemma'], columns = ['lemma'])
word_counts4 = Counter()
lemma_df.apply(lambda x: word_counts4.update(x))
word_counts4.most_common(10) # Top10유사한 문서 찾기
TfidfVectorizer를 이용해 각 문서들을 벡터화 한 후 KNN 모델을 만들고, 내가 원하는job description을 질의해 가장 가까운 검색 결과들을 가져오고 분석합니다.
[TfidfVectorizer]
- 문항 9) 88번 index의
job description와 5개의 가장 유사한job description이 있는 index를 입력하세요.- 답은 88번 인덱스를 포함합니다.
max_features = 3000으로 설정합니다.- [88, 90, 91, 93, 94] 형태로 답을 입력해주세요
# 위에서 중복행 제거, 소문자 변환, 정규표현식까지는 반영한 데이터 사용해볼 것이다.
df_des = pd.DataFrame(df['description'], columns = ['description'])
df_des['description'] = df_des['description'].apply(lambda x: " ".join(v for v in x)) # 레퍼런스 https://codechacha.com/ko/python-convert-list-to-string/
df_des# TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(stop_words=STOP_WORDS, max_features=3000) #STOP_WORDS는 위에서 지정했던거랑 동일하게.
dtm_tfidf = tfidf_vect.fit_transform(df_des['description'])
dtm_tfidf = pd.DataFrame(dtm_tfidf.todense(), columns=tfidf_vect.get_feature_names())
dtm_tfidf # 숫자가 들어가 있넹 으음..
# KNN
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=5, algorithm='kd_tree')
nn.fit(dtm_tfidf)
# 88번 인덱스와 유사한 것 5개 찾기
nn.kneighbors([dtm_tfidf.iloc[88]]) #[88, 40, 121, 240, 68]TF-IDF 이용한 텍스트 분류 진행하기
- TF-IDF를 이용해 문장 혹은 문서를 벡터화한 경우, 이 벡터값을 이용해 문서 분류 태스크를 진행할 수 있습니다.
- 현재 다루고 있는 데이터셋에는 label이 존재하지 않으므로, title 컬럼에 "Senior"가 있는지 없는지 여부를 통해 Senior 직무 여부를 분류하는 작업을 진행해보겠습니다.
[준비]
- title 컬럼에 "Senior" 문자열이 있으면 1, 없으면 0인 "Senior"라는 새로운 컬럼을 생성해주세요.
# 다시 df 중복행 제거한 것만 불러와서 해보자.
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/indeed/Data_Scientist.csv')
# title, company, description 에 해당하는 Column만 남기기
df = df[['title', 'company', 'description']]
# 중복행 제거
df = df.drop_duplicates(ignore_index=True)
# 조건에 따라 추가
df['senior'] = df['title'].apply(lambda x: 1 if 'Senior' in x else 0)
#확인
df['senior'].value_counts() # 참고로 내가 앞에서 lower로 다 바꾼 df로 봤을 때는 senior가 98개였음. 원래 df에 senior 3개가 있었겠다.
[분류기 생성]
- 문항 8) sklearn의
train_test_split을 통해 train 데이터와 valid 데이터로 나눈 후,sklearn의DecisionTreeClassifier를 이용해 분류를 진행해주세요. - 단, x값은 위에서 학습한 dtm_tfidf를 그대로 이용해주세요. train_test_split과 DecisionTreeClassifier의 random_state을 42로 고정하고, test_size는 0.1로 설정해주세요.
- 학습을 완료한 후, test 데이터에 대한 예측을 진행하고 label 1에 대한 precision과 recall 값을 적어주세요
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
X_train, X_test, y_train, y_test = train_test_split(dtm_tfidf, df['senior'].values, test_size=0.1, random_state=42)
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred))
# 디스크립션으로 이 업무가 시니어 업무인지 아닌지를 예측한다..? 
5. 그 외
- 오늘 apply 함수 안에 Lambda로 함수 돌리는거 자주 써봐서 잘 이해할 수 있었고 다음부터 요긴하게 써먹을 수 있을 듯. 뿌--듯.
Feeling
- 코드에 치이고 수많은 새로운 개념의 파도에 치인 날이었다. 나중에 이 많은 걸 다 기억할 수 있을까? 하는 걱정도 들어서 오늘 TIL은 최대한 자세히 기록해두려고 했다. 잘 한건지는 모르겠다.
- 말로만 듣던 자연어처리를 내가 이렇게 직접해보다니 뿌듯했다.
- 그리고 코드 이해하고 뿌시는게 그냥 개념만 배우는 것보다는 더 재밌는 것 같다.
