Key words
분산표현(Distributed Representation), Word2Vec, 분포가설(Distribution hypothesis), 임베딩(embedding)
지난 노트에서는 벡터화를 하는 2가지 방법 중 Counter-based Representation에 대해 배웠었는데, 오늘은 나머지 방법인 Distributed Representation에 대해 배우고 실습까지 해보았다.
1. Distributed Representation 이란?
분포가설(Distribution hypothesis)이란 쉽게 말해 비슷한 위치에서 등장한 단어는 비슷한 의미를 가진다는 것이다. 유유상종이라고 할 수 있겠다.- 예를 들어,
I found good stores.,I found beautiful stores.이 두 문장에서good,beautiful은 주변에 분포한 단어가 유사하기 때문에 비슷한 의미를 지닐 것이다~ 라고 하는 것이다.
- 예를 들어,
분산 표현(Distributed representation)은 이 분포가설에 기반하여 주변 단어 분포를 기준으로 단어의 벡터 표현을 결정하는 것을 말한다.
본격적으로 이 분산 표현을 배우기 전에 이전에 배웠던 원핫인코딩을 다시 짚고 넘어갔다.
- 원핫인코딩은 이전에 배웠던 것처럼 범주형 변수를 숫자로(정확히는 벡터로) 바꿔주는 방법이었다. 즉, 우리가 벡터화를 해야겠다~ 라고 할 때 가장 쉬운 방법으로 이 원핫인코딩을 사용할 수 있다는 말이다.
- 예를 들어,
I am a student라는 문장이 있다면, 아래와 같이 원핫인코딩을 하는 것이다.I: [1 0 0 0]am: [0 1 0 0]a: [0 0 1 0]student: [0 0 0 1]
- (위처럼 구현하는 코드 오늘 봤는데 신기하니 적어둔다.)
sent = "I am a student"
word_lst = sent.split()
word_dict = {}
for idx, word in enumerate(word_lst):
vec = [0 for _ in range(len(word_lst))] # 단어 길이만큼 [0, 0, 0, 0] 을 만들고
vec[idx] = 1 # for loop에 의해 단어 순서대로 1을 매기겠단 뜻.
word_dict[word] = vec
print(word_dict)- 근데 이 원핫인코딩을 통해 벡터화를 했을 때 아주 치명적인 단점이 있다. 그건 바로 단어 간 유사도를 측정할 수 없다는 것이다.
- 왜냐? 단어 간 유사도를 측정할 때 보통
코사인 유사도(cosine similarity)를 쓰는데, 이렇게 원핫인코딩을 통해 벡터화를 하면 두 단어의 내적은 항상 0이 되기 때문에 유사도 자체를 측정할 수 없게 된다. 코사인 유사도 구하는 수식은 참고.
- 왜냐? 단어 간 유사도를 측정할 때 보통
- 또한 데이터가 많을수록 쓸데없이 0이 지나치게 많아진다는 단점(연산도 오래걸림)도 있기 때문에, 적절한 상황이 아니라면 원핫인코딩 대신 더 나은 방법을 찾아야할 상황에 처하게 되는 것이다.
그래서 이 원핫인코딩의 단점을 해결하기 위해 나온게 바로 임베딩(Embedding)이다!!!
(왜 나왔는지 항상 흐름을 생각하자구~)
2. 임베딩(Embedding) - Word2Vec
- 임베딩이란 단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내는 것을 말한다. (이 개념은 딥러닝에서 자주 쓰이니 잘 기억해두라고 한다)
- 임베딩을 거친 단어 벡터는 원핫 인코딩과는 다른 형태의 값을 가진다. 예를 들어,
[0.04227, -0.0033, 0.1607, -0.0236, ...]와 같이 벡터 내의 각 요소가 연속적인 값을 가지게 된다.- (원핫인코딩은 희소표현, 임베딩은 밀집표현이라고 부르기도 한다.)
- 오늘 써본
Word2Vec은 이 임베딩의 가장 널리 알려진 방법이다.
Word2Vec
Word2Vec은 특정 단어 양 옆에 있는 두 단어(window size = 2)의 관계를 활용하기 때문에 분포 가설을 잘 반영하고 있다고 한다.- (이 window size는 조정이 가능하다. 해당 영상에서 아주 잘 설명하고 있으니 나중에 다시 한 번 더 보자)
Word2Vec에는CBoW와Skip-gram의 2가지 방법이 있다. 각각 무엇인지 우선 아래 그림을 보자.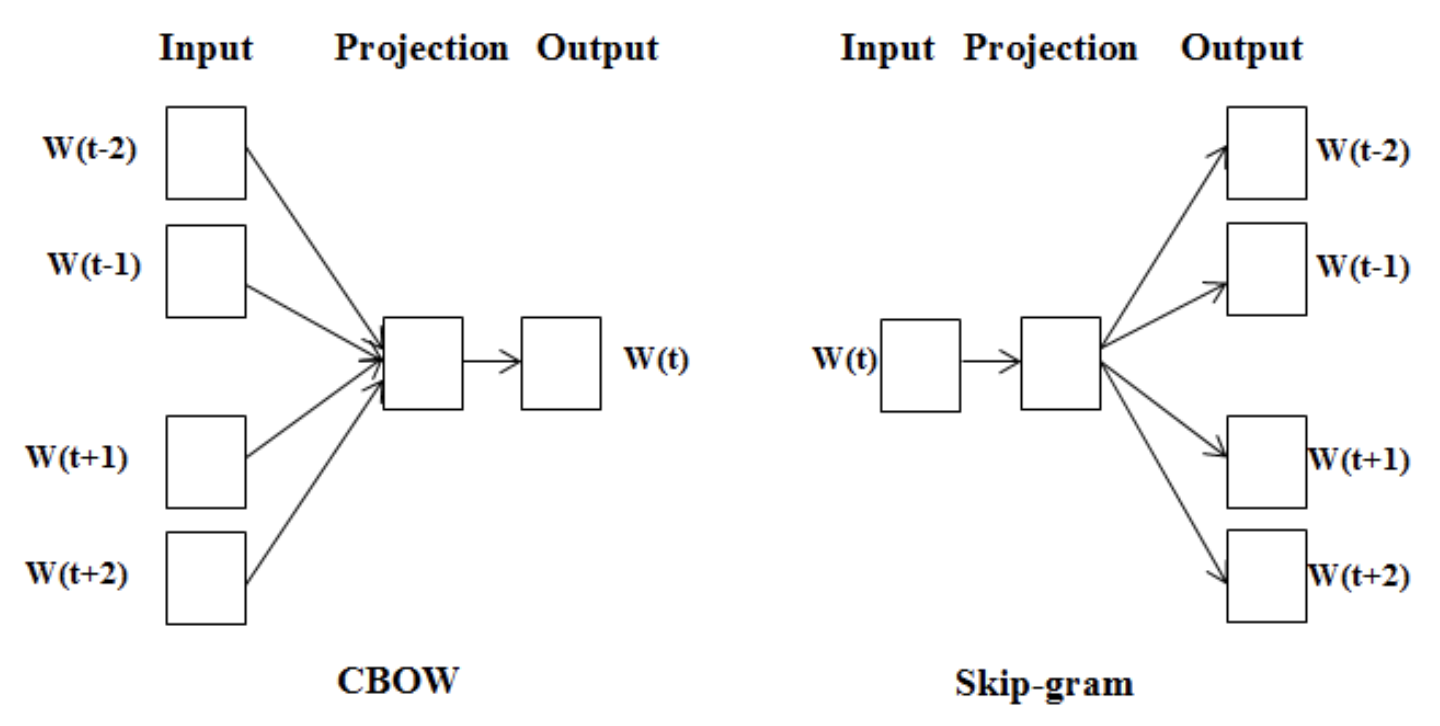
CBoW: 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델.Skip-gram: 중심 단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델.
- 오늘 강의 노트에서는 다음 문장을 통해 예시를 들었다.
어머님 나 는 별 하나 에 아름다운 말 한마디 씩 불러 봅니다- CBoW 를 사용하면 주변 단어들을 통해
__를 예측한다!- “… 나 는 [ -- ] 하나 에 … “
- “… 는 별 [ ---- ] 에 아름다운 …”
- “… 별 하나 [ -- ] 아름다운 말 …”
- “… 하나 에 [ -------- ] 말 한마디 …”
- Skip-gram 을 사용하는 경우 한 단어를 가지고 주변의
__들을 예측한다.- “… [ -- ][ -- ] 별 [ ---- ][ -- ] …”
- “… [ -- ][ -- ] 하나 [ -- ][ -------- ] …”
- “… [ -- ][ ---- ] 에 [ -------- ][ -- ] …”
- “… [ ---- ][ -- ] 아름다운 [ -- ][ ------ ] …”
- CBoW 를 사용하면 주변 단어들을 통해
- 언뜻보면 여러 정보를 활용하는 CBoW가 성능이 더 좋을 것 같지만, 역전파 관점에서보면 일반적으로는 Skip-Gram이 더 좋다고 한다.
- 역전파 관점이라? 내 언어로 정리해보면, Input data는 학습 과정에서 수정이 안되는 데이터기 때문에 Input에 딱 하나의 데이터만 들어간 Skip-gram을 쓸 때 역전파 과정에서 더 많은 학습이 이루어질 수 있는 것이다.
- 물론 skip-gram이 그만큼 더 오래걸리기 때문에 역시 이것도 사바사에 맞게 골라서 쓰면 될 것 같다.
- 그럼 좀 더 자세히 모델의 구조를 살펴보도록 하자.
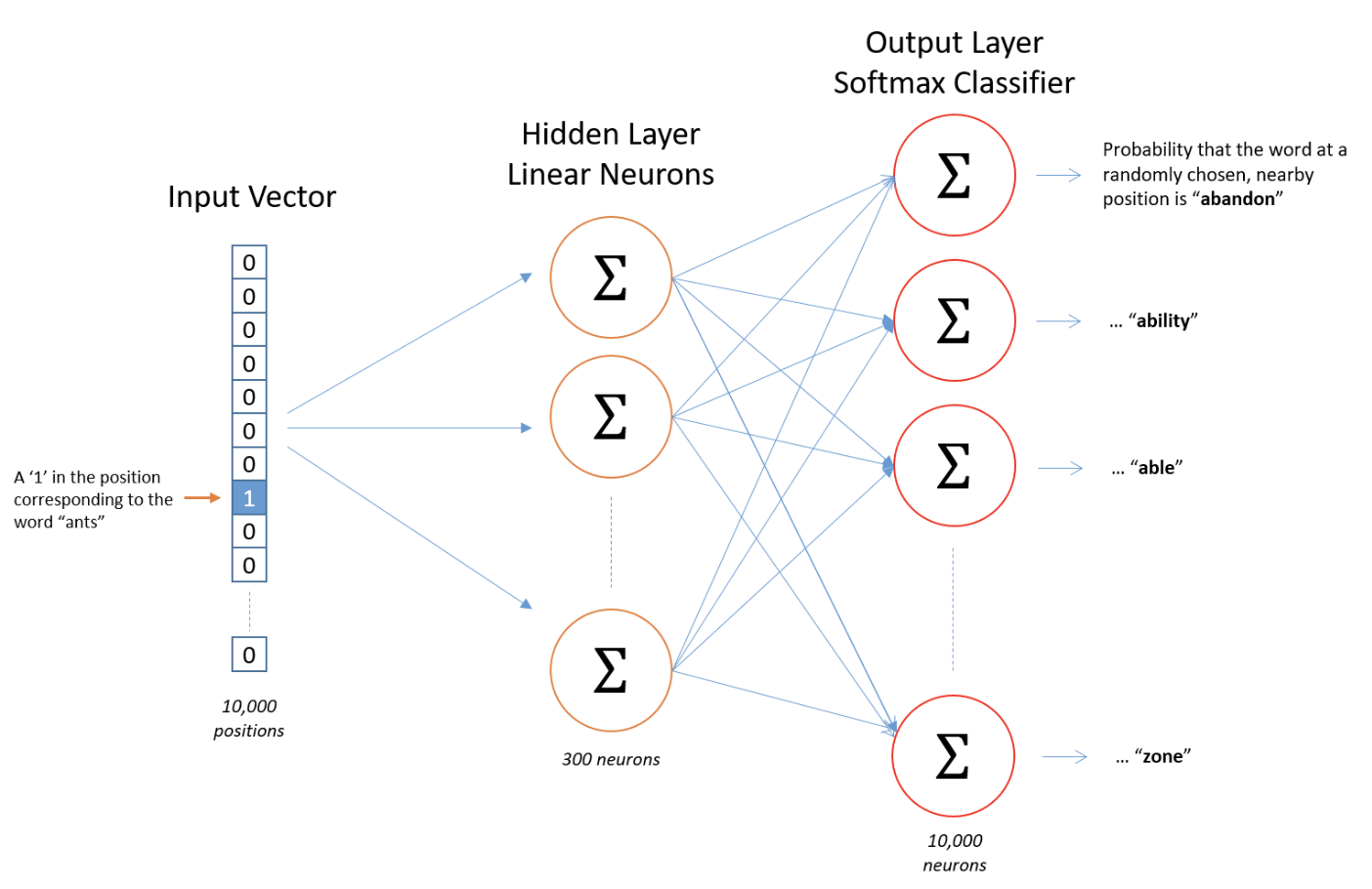
- 자, 이 모델은 10,000개의 단어에 대해 300차원의 임베딩 벡터를 구하는 것이다. 처음 봤을 때 이것도 헷갈렸다. 그림을 잘 살펴봐야 한다.
- 여기서 300차원이란? 아까 임베딩 벡터의 형태는
[0.04227, -0.0033, 0.1607, -0.0236, ...]식으로 되어있다고 했는데, 안의 요소가 300개라는 것이다. 아까 원핫인코딩 얘기를 했는데, 원핫인코딩은 단어의 수만큼 차원이 늘어날 수밖에 없는데 임베딩은 조절할 수 있는 장점이 있는 것이다. 이 말 참고하자.차원 역시 사용자의 지정입니다. 일반적으로 목적에 맞게 입력 단어의 수보다 적게 지정을 해줍니다(256, 512, 1024 등) - 인풋 데이터를 그림에서는 원핫인코딩으로 넣어줬는데 오늘 실습할 때는 또 다른 방법으로 해봤다. 이건 실습 부분에서 보면 됨.
- 실습을 하며 지난 주에 배웠던 것과 대체 뭐가 다른가 처음에 매우 헷갈렸는데, 은닉층에 임베딩 벡터가 가중치 행렬로 들어가고, 인풋 데이터가 이 가중치 행렬을 지나가며 단어를 분류하는 것으로 생각하면 될 것 같다.
- 다른 말로는 TF-IDF는 문서 전체를 벡터화하는거고 임베딩 벡터는 단어를 벡터화하고 그걸 이용해서 텍스트를 분류하는 차이가 있다고 한다.
- (참고로 이 분류기는 은닉층이 단 하나이기 때문에 딥러닝이라고 부르지는 않고 그냥 신경망을 써서 자연어를 처리하는 것으로 생각하면 된다고 한다.)
- 그럼 Word2Vec을 거치면 어떤 결과라 리턴되는걸까? 아래 그림과 같이 신경망 내부에 있는 10000×300 크기의 가중치 행렬에 의해서
10000개 단어에 대한 300차원의 벡터가 생성되게 된다. (잘 모르겠으면 이따 실습코드 돌려본 거 보면 알 거다.)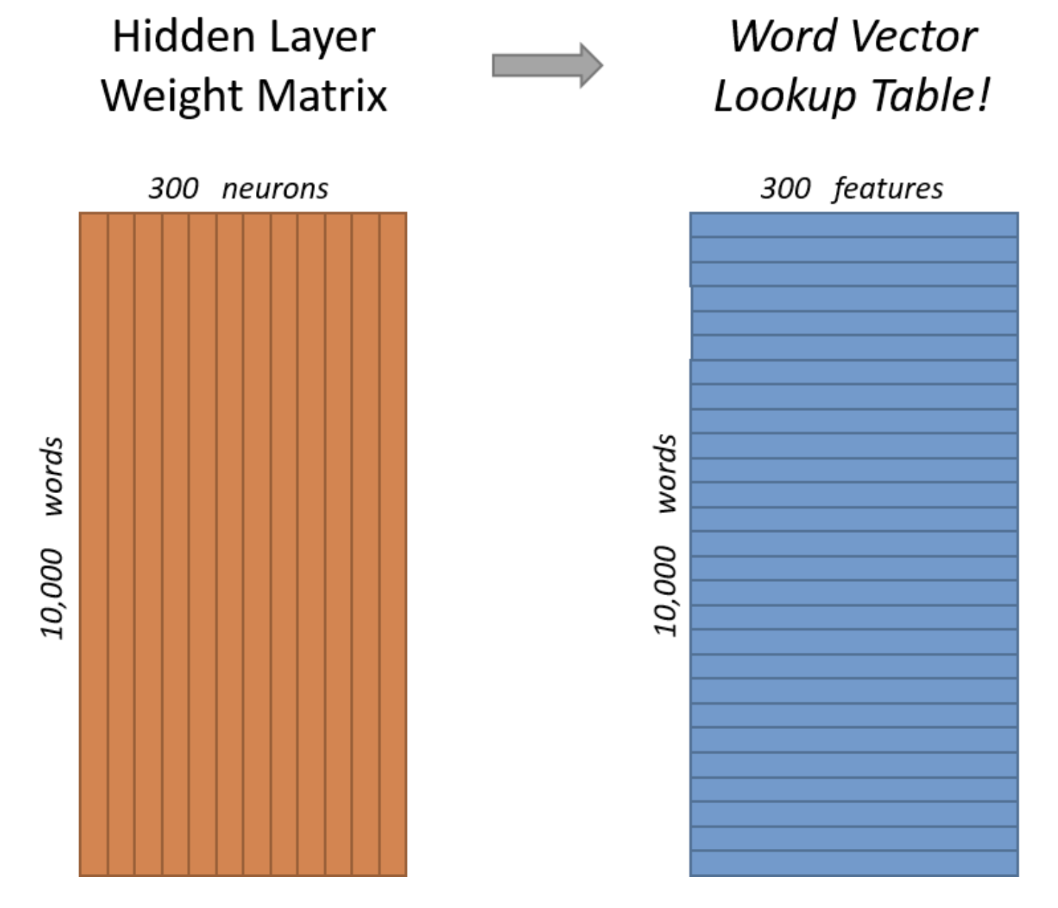
- (룩업테이블 오늘 뭔지 헷갈렸어서 들었던 예시 하나 더)
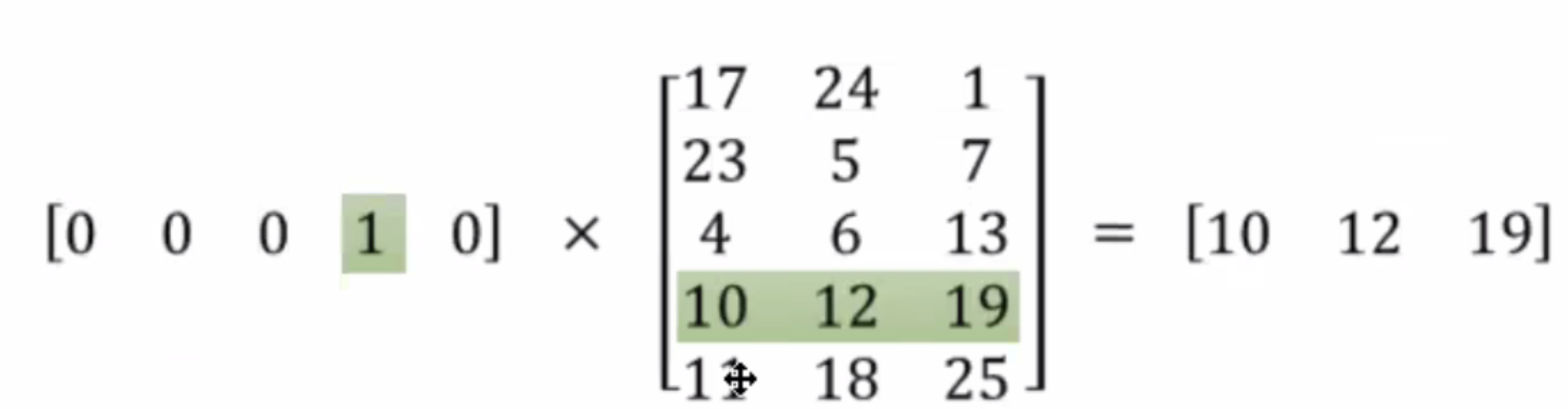
- 여기서 300차원이란? 아까 임베딩 벡터의 형태는
- Word2Vec의 계산량을 줄이기 위한 기법으로
Sub-sampling,Negative-sampling등이 있다고 하는데, 이것에 대해서는 나중에 한 번 알아보자. - Word2Vec으로 임베딩한 벡터 시각화
- 텍스트를 수치로 바꾸면 할 수 있는게 뭐다? 연산이 가능할 것이고 차원에 배열하는 시각화가 가능하다! Word2Vec으로 임베딩한 벡터도 마찬가지이다. 임베딩 벡터는 단어 간의 의미적, 문법적 관계도 잘 표현할 수 있다.
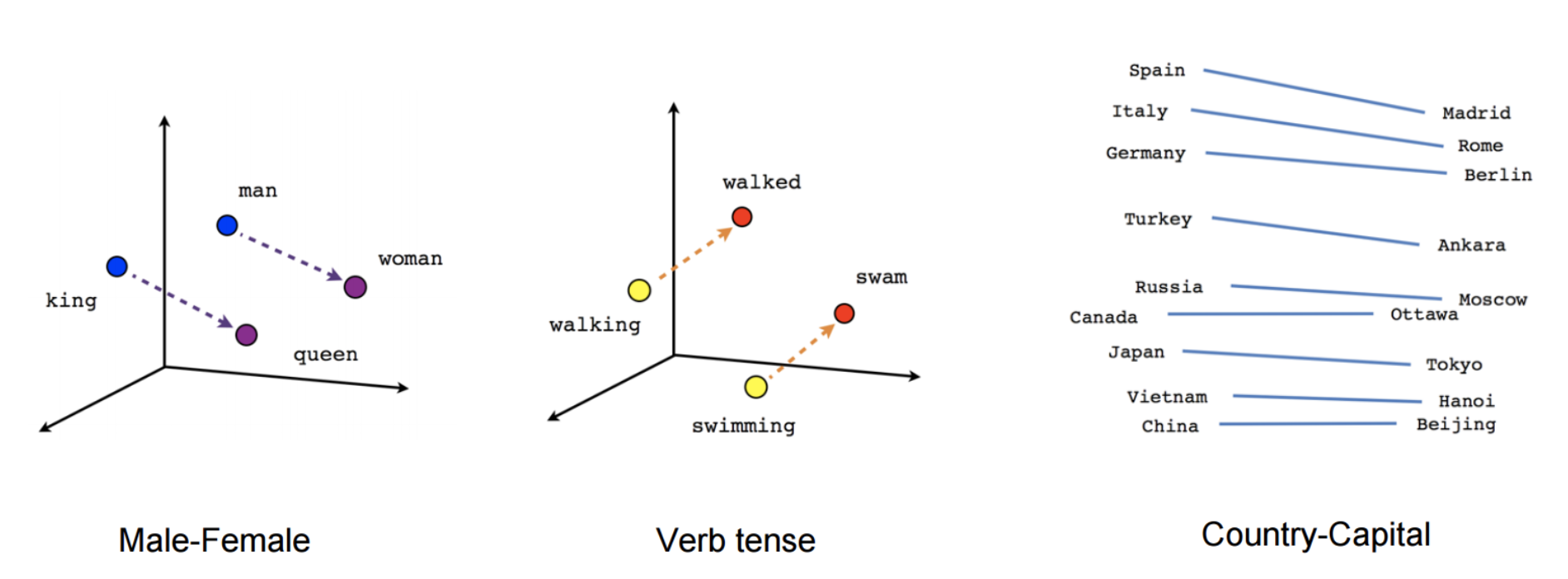
King+Woman-man을 하면queen을 뽑아낼 수 있는데 왜 그 결과를 낼 수 있는지는 위 그림을 보면서 생각해보니 더 잘 이해가 되었다.- 코드로는 아래와 같이 표현할 수 있음.
print(wv.most_similar(positive=['king', 'women'], negative=['men'], topn=1)) # [('queen', 0.6525818109512329)]
print(wv.most_similar(positive=['walking', 'swam'], negative=['walked'], topn=1)) # [('swimming', 0.7448815703392029)]- 참고로
.doesnt_match메소드를 이용하면 가장 관련이 없는 단어도 찾을 수 있다. 짱 신기함.
print(wv.doesnt_match(['fire', 'water', 'land', 'sea', 'air', 'car'])) # car3. gensim 패키지로 Word2Vec 써보기
gensim은 Word2Vec 으로 사전학습된 임베딩 벡터를 쉽게 사용해볼 수 있는 패키지이다. 오늘은 각 단어별로 임베딩 벡터를 다 구하는 과정까지는 하지 않았고 이미 구글에서 만들어놓은 것을 가져다가 썼다.- 이 임베딩 벡터를 가져다가 코사인 유사도를 통해 유사한 단어를 찾아낼 수 있는데, 그 활용은 실습 코드에서 참고하도록 하자.
- 중요!!! 참고로 이 단어 집합에 없는 단어를 검색하면 Keyerrorr가 뜬다. 즉,
Word2Vec은 단어 집합에 지정하지 않은 단어는 벡터화 할 수 없다는 단점이 있다. 이 문제를OOV(Out-Of-Vocabulary)문제라고 한다.- 이 OOV 문제를 해결하기 위해 나온게 FastText라는게 있는데 이건 나중에 따로 공부해야 한다.
4. 실습한 것
캐글의 SMS Spam dataset 에 사전 학습된 Word2Vec 임베딩 벡터를 적용하여 분류해봅시다. 세션 노트에 있었던 단어 임베딩 벡터를 평균내어 분류하는 방법을 적용해봅시다.
-
참고로 위 문제에서 말한
단어 임베딩 벡터를 평균내어 분류하는 방법은 다음과 같다. 노트에 있던 내용을 인용한다.예를 들어, "I am a student"라는 문장을 구성하는 단어의 임베딩 벡터가 아래와 같다고 해보겠습니다.
이 때, "I am a student"라는 문장을 분류하기 위해서 최종적으로 아래 벡터를 사용합니다.
-
각 요소별로 벡터간 단순평균을 낸 것이다. 생각보다 성능이 좋아 기준모델로 많이 사용한다고 한다. 왜 이렇게가 가능한지는 아까
한국-서울+도쿄 = 일본이 나올 수 있는 공간 상의 시각화를 잘 생각해보면 이해가 갈 것이다.
[준비]
!pip install gensim --upgrade # 코랩같은 경우 최신 버전이 아니어서 업그레이드 진행하고 해줬음.
--
import gensim
gensim.__version__ # 4.2.0
--
# 단어집 가져오기
import gensim.downloader as api
wv = api.load('word2vec-google-news-300')
--
# index 0-5에 어떤 단어가 있는지 살펴보기
for idx, word in enumerate(wv.index_to_key): #=> enumerate() index도 함께 반환해줘서 활용 가능한 메서드.
if idx == 5:
break
print(f"word #{idx}/{len(wv.index_to_key)} is '{word}'") #총 3,000,000개의 단어가 있구나!
# 차원 수 확인해보기
vec_king = wv['data']
print('\n벡터 차원수 = ', vec_king.shape)
[word2vec을 이용해 구한 'data'와 'science' 임베딩 값의 코사인 유사도 구하기]
from sklearn.metrics.pairwise import cosine_similarity
'''
vec_data = wv['data']
vec_science = wv['science']
print("'data'와 'science'의 코사인 유사도 = ",cosine_similarity(vec_data, vec_science))
# 위와 같이 돌렸을 때 아래와 같은 오류가 리턴됨.
"ValueError: Expected 2D array, got 1D array instead: Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample."
# 이런 오류가 발생하는 이유는, skit-learn에서는 모든 인풋 'x'가 2d array로 들어올 것으로 기대하기 때문이라고 한다. (출처 - https://datamasters.co.kr/55)
이 경우 벡터값을 reshape 하고 코사인 유사도를 계산하면 된다. (# reshape() 레퍼런스: https://jimmy-ai.tistory.com/99)
vec_data = wv['data'].reshape(1,-1)
vec_science = wv['science'].reshape(1,-1)
# 혹은 더 간단하게는 아래와 같이 해도 작동한다.
vec_data = wv[['data']]
vec_science = wv[['science']]
# 넘파이 array의 차원에 대해서 헷갈린다면 https://datascienceschool.net/01%20python/03.01%20%EB%84%98%ED%8C%8C%EC%9D%B4%20%EB%B0%B0%EC%97%B4.html 를 참고하자.
'''
vec_data = wv[['data']]
vec_science = wv[['science']]
print("'data'와 'science'의 코사인 유사도 = ", cosine_similarity(vec_data, vec_science)) # 'data'와 'science'의 코사인 유사도 = [[0.1575913]][필요한 패키지 업로드]
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.preprocessing import sequence
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.preprocessing.text import Tokenizer텍스트 분류문제
[데이터 전처리]
- 데이터셋을 데이터프레임으로 읽어옵니다
encoding = 'latin-1'을 사용합니다.- 필요없는 열(column)을 삭제합니다.
- LabelEncoder를 사용하여 label 전처리를 해줍니다.
from google.colab import files
# 데이터셋 출처 - https://www.kaggle.com/datasets/uciml/sms-spam-collection-dataset
file = files.upload()
df = pd.read_csv('spam.csv', encoding='latin-1')# v1, v2 칼럼만 남기고 나머지 drop
df.drop(columns=['Unnamed: 2','Unnamed: 3','Unnamed: 4'], inplace= True)
df.head()
# checking label counts
print(df['v1'].value_counts()) # => ham 4825, spam 747
# label encoding
encoder = LabelEncoder()
df.encoded = encoder.fit_transform(df['v1'])
# df 변경
df['v1'] = df.encoded # ham=0, spam=1
df.head()
[텍스트 분류 실행]
- 데이터셋 split시 test_size의 비율은 15%로,
random_state = 42로 설정합니다.- Tokenizer의
num_words = 1000으로 설정합니다.- pad_sequence의
maxlen=150으로 설정합니다.- 학습 시, 파라미터는
batch_size=64, epochs=10, validation_split=0.2로 설정합니다.- evaluate 했을 때의 loss와 accuarcy를 [loss, acc] 형태로 입력해주세요. Ex) [0.4321, 0.8765]
np.random.seed(42)
tf.random.set_seed(42)
## 참고 - 여기서 텍스트 분류를 진행한다고 함은 v2를 보고 spam인지를 알 수 있는 분류기를 만들고자 하는 것이다. ##
# train, test data split
train, test = train_test_split(df, test_size=0.15, random_state = 42)
'''
# 타겟 분포 불균형해서 'stratify=df['v1']' 넣어봤더니 아래 word_index 갯수가 달라짐. 왜 그렇지?
아, 문제와 해설에서는 안한 걸로 가정하고 random_state 걸었으니까 당연한거긴 하네.
'''
print('df shape = ', df.shape) # (5572, 2)
print('\ntrain shape = ', train.shape, '\ntest shape = ', test.shape) # train shape= (4736, 2), test shape= (836, 2)
# X,y dataset
feature = 'v2'
target = 'v1'
X_train = train[feature]
X_test = test[feature]
y_train = train[target]
y_test = test[target]# 피쳐 문장
sentences = [v for v in X_train]
# 토큰화 (레퍼런스 https://wikidocs.net/31766 / https://codetorial.net/tensorflow/natural_language_processing_in_tensorflow_01.html)
tokenizer = Tokenizer(num_words = 1000) # 빈도가 많은 순으로 999개의 단어만 사용하겠다는 뜻. (num_words는 0부터 카운트되기 때문)
tokenizer.fit_on_texts(sentences) # 입력한 텍스트로부터 단어 빈도수가 높은 순으로 낮은 정수 인덱스를 부여함.
word_index = tokenizer.word_index
#print(word_index) # fit_on_texts 인덱스 부여 확인
print(len(word_index)) # => 상위 1000개의 단어만 나오는게 아니라 왜 그렇지? 싶어서 찾아봄. 실제 적용은 texts_to_sequences를 사용할 때 된다고 함.
# text_to_sequences
sentences_encoded = tokenizer.texts_to_sequences(sentences)
#print('\n', tokenizer.texts_to_sequences(sentences)) # => 여기 출력된 걸 보면 빈도 순 999개 초과된 것은 제거되어 출력되는 것을 확인할 수 있다. 이건 위의 'num_words='을 조절하면서 결과를 봐보면 더 잘 알 수 있음.# pad_sequence (=> 입력데이터 문장길이가 다르기 때문에 이를 임의로 맞춰주는 작업을 말함. 자세한 의미는 레퍼런스 참고.)
'''
레퍼런스 : http://www.nextobe.com/2020/05/14/%EA%B0%80%EB%B3%80-%EA%B8%B8%EC%9D%B4-%EC%9E%85%EB%A0%A5-%EC%8B%9C%ED%80%80%EC%8A%A4%EC%97%90-%EB%8C%80%ED%95%9C-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%A4%80%EB%B9%84/)
https://wikidocs.net/83544
'''
maxlen = 150
padded = pad_sequences(sentences_encoded, maxlen = maxlen)
print(padded)
print('\n\n maxlen 잘 적용되었는지 확인 => len(padded[0]) ==', len(padded[0])) # 150, 제대로 적용되었다. 디폴트로 앞에 0이 추가되며 뒤에 추가하고 싶다면 padding='post' 를 넣어주면 된다.
print('\n참고 - padded 데이터 수 = ', len(padded),'개') # 4736개, X_train 데이터 수와 동일한 것 확인.
# 임베딩 벡터 가중치 행렬 만들기
'''
아 앞에 wv쓰는게 Load 해왔던게 지금 각 단어별로 임베딩 벡터값 불러와서 쓰려고 했던거구나~ 이렇게 생각하면 전체적인 그림차이가 지난 번이랑 다른게 느껴지네.
아 오늘은 단어별로 임베딩 벡터 직접하지 않고 이미 학습된 거 가져온다는 의미가 이거였어!! 오케이!
'''
vocab_size = len(tokenizer.word_index) + 1
'''
# 근데 이번에는 노트와 다르게 num_words를 1000개로 제한했으니 1000으로 맞춰도 되지 않나? 일단 주석처리 해놓고 넘어가기.
=> 질문해서 답변 받음. 가중치행렬에서는 뭐가 상위 1000개일지 모르는 상태니까 일단 전체 토큰 수를 기준으로 임베딩 벡터 가중치 행렬을 만들어둔다는 말이라고 함. 쉽게 생각하면 직관적으로 이해될 거야!
# +1 한 이유는 패딩 때문인데 위에서 패딩할 때 길이 맞추기 위해서 임의로 '0'을 추가했으니까 그것까지 포함하려는 것으로 이해하면 됨.
'''
#기본 매트릭스 생성
embedding_matrix = np.zeros((vocab_size, 300)) # 300차원.
print(np.shape(embedding_matrix)) # => (8186, 300)
# 각 단어별 벡터를 찾기 위한 함수 작성
def get_vector(word):
"""
입력 단어가 vocab 에 있는 단어일 경우 임베딩 벡터를 반환
Args:
word: 입력 단어 -> str
"""
if word in wv:
return wv[word]
else:
return None
# 가중치 행렬에 적용
for word, i in tokenizer.word_index.items():
temp = get_vector(word)
if temp is not None:
embedding_matrix[i] = temp
#print('\n\n가중치 행렬\n',embedding_matrix)# 모델링
X_train = padded
y_train = np.array(y_train)
model = Sequential()
model.add(Embedding(vocab_size, 300, weights=[embedding_matrix], input_length=maxlen, trainable=False)) #embedding 레퍼런스 https://runebook.dev/ko/docs/tensorflow/keras/layers/embedding
model.add(GlobalAveragePooling1D()) # 입력되는 단어 벡터의 평균을 구하는 층이라고 생각하면 된다. (각 단어 벡터의 평균을 내서 특징을 잡는거라고 생각하면 됨)
model.add(Dense(1, activation='sigmoid')) #이진분류 문제이므로
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
model.fit(X_train, y_train, batch_size=64, epochs=10, validation_split=0.2)# test data evaluate
test_sentences = [v for v in X_test]
X_test_encoded = tokenizer.texts_to_sequences(test_sentences)
X_test=pad_sequences(X_test_encoded, maxlen=maxlen)
y_test=np.array(y_test)
model.evaluate(X_test, y_test) # loss: 0.4714 - acc: 0.8660[Word2Vec에서의 OOV 문제]
def get_vector(word): """ 해당 word가 word2vec에 있는 단어일 경우 임베딩 벡터를 반환 """ if word in wv: return wv[word] else: return None for word, i in tokenizer.word_index.items(): temp = get_vector(word) if temp is not None: embedding_matrix[i] = tempLecture Note에 있는 위의 코드를 변형하여, OOV 개수를 확인해주세요.
- tokenizer는 위에서 활용한 tokenizer를 그대로 사용하겠습니다.
- Tip : dictionary를 활용하거나, Counter를 활용해보세요.
# 위 함수를 통해 wv에 있는 단어인지 검색하고 없으면 return none을 했었는데 이걸 어딘가에 적절히 저장하도록 하면 oov 개수 파악은 쉽게 가능할 듯.
def get_vector2(word):
"""
해당 word가 word2vec에 있는 단어일 경우 임베딩 벡터를 반환
"""
if word in wv:
return wv[word]
else:
return word # word를 리턴해서 가지고 있도록 하자. 나중에 어떤 단어가 oov인지도 확인 가능할테니 유용할 듯.
# oov 갯수 저장할 곳
oov = []
for word, i in tokenizer.word_index.items():
temp = get_vector2(word)
if type(temp) == str:
oov.append(temp)
print(len(oov)) # 2419
#print(oov) 리스트 확인도 가능Feeling
- 오늘 가장 헷갈렸던 건 실습을 하다보니 지난 주 금요일에 했던 빈도 기반 표현이랑 대체 뭐가 다른 건지였다. 그래서 전체적인 큰 틀의 그림을 그리는게 힘들었다. 근데 은닉층에서 임베딩 벡터 가중치 행렬이 반영된다는 것을 알고 나니 뭔가 막힌게 쑥 뚫린 듯한 기분이어서 좋았다.
- 까먹지 않도록 복습 잘 해야지.. 모자란 공부도 더 해야된다..
