Key words
연속형 데이터, RNN(순환 신경망), LSTM & GRU, Attention
1. 언어 모델이란?
- 오늘 배운 것의 주제는 제목에서와 같이 뭐다?
Language Modeling이다. 이 점을 유의해서 앞으로 펼쳐지는 내용을 머릿속에 그림으로 그려보자. - 먼저, 언어 모델이란 무엇일까? 언어 모델이란 문장과 같은 단어 시퀀스에서 각 단어의 확률을 계산하는 모델이다. 어제 배운
Word2Vec도 언어 모델 중의 하나라고 보면 된다. - 예를 들어
C-Bow에서 "I am a student"라는 문장이 만들어질 확률은 아래와 같이 조건부 확률의 곱으로 표현할 수 있다.
이 언어모델의 큰 stream을 보면 통계적 언어 모델과 신경망 언어모델로 나뉜다.
통계적 언어모델(Statistical Language Model, SLM)
- 신경망 모델의 등장 이전에 주로 사용되던 전통적인 접근 방식이다. 이름 그대로 통계적 방식으로 접근하는 걸 생각하면 되는데, 위의 문장으로 예를 들어보자.
- 여기서 를 구한다고 할 때, 전체 말뭉치가 100개고 그 중 I로 시작하는 문장이 10개라면? = 10%가 된다. 그렇다면 는? 만약 전체 말뭉치가 100개고 그 중 'I am'으로 시작하는 문장이 1개라면? = 1%가 된다. 이런 식으로 각각의 조건부 확률을 구해 다 곱하면 "I am a student"라는 문장이 나올 확률을 구할 수 있게 되는 것이다.
- 자, 언어 모델이 이런 식으로 학습을 한다고 했을 때 한계점이 보일 것이다. 통계적 언어 모델은 횟수 기반으로 확률을 계산하기 때문에 희소성(Sparsity) 문제를 가지고 있다.
- 무슨 말이냐면, 만약 "I studied this section ..." 문장에서 ... 에 3 times, 4 times, 5 times까지 학습을 했다고 했다고 해도 만약 6 times를 학습한 적이 없다면 이 모델은 절대 "I studied this section 6 times"라는 문장을 만들어낼 수가 없게 된다. 왜냐하면 위에서 조건부확률을 구했던 것처럼 표현해보면 이 되기 때문이다. 즉, 말뭉치에 등장하지 않으면 다양한 문장을 만들어낼 수 없는 한계를 희소성 문제라고 생각하면 된다.
- 참고 - 더 공부해볼만한 것
N-gram(통계적 언어 모델 고도화 방법 중 하나),Back-off/Smoothing(희소 문제 해결을 위한 방법론 중 하나)
신경망 언어 모델 (Neural Langauge Model)
- 신경망 언어 모델은 이전에 배운 것처럼 임베딩 벡터를 사용하기 때문에 말뭉치에 등장하지 않아도 문법적, 의미적으로 유사한 단어가 선택될 수 있어 보다 다양한 문장을 만들어내게 된다.
- 처음에 통계적 언어 모델만 사용하던 연구자들이 이 신경망 모델을 적용해보고 난 다음에 얼마나 놀랐으려나..!
2. 순환 신경망 (RNN, Recurrent Neural Network)
오늘의 메인 주제다. 진짜 어려워서 너어--무 고생했고 여기 적는 것 외에도 보충 공부 필요함.
- RNN에 대해서 알아보기 전에 잘 기억해야할 아주 핵심적인 단어가 있다. 그건 바로
연속형 데이터 (Sequential Data)이다. 연속형 데이터 (Sequential Data)의 정의는 '어떤 순서로 오느냐에 따라서 단위의 의미가 달라지는 데이터'를 말한다. 예를들어 언어로 이루어진 문장 등이 가장 대표적인 것 같고(한국어는 좀 덜하긴 하지만 라틴계열 문자는 순서에 따라 동사가 명사가 되기도 하는 등 의미가 달라지는 경우가 많음), 시계열로 이루어진 주가 데이터도 예시로 보았다.- RNN은 이 연속형 데이터를 잘 처리하기 위해 고안된 신경망 모델이다!! 1 Of 연속형 데이터 = Language이니까 오늘 주제와 연관해서 쉽게 생각해보면, 언어 데이터를 잘 다루기 위해 만들어진 거라고 기억해도 될 것 같다.
- 김성범 교수님의 이 영상에서 RNN에 대해서 잘 설명해주고 있으니 잘 기억이 안날 때 잘 참고하도록 하자. 교수님 짱!
RNN의 기본 구조는 아래와 같다.

- 위 그림의 화살표는 아래와 같다. 3번째 항목은 기존 신경망 모델에서는 없었던 개념이다.
- 입력 벡터가 은닉층에 들어가는 것을 나타내는 화살표 ( 𝑊ℎ𝑥 )
- 은닉층로부터 출력 벡터가 생성되는 것을 나타내는 화살표 ( 𝑊𝑜ℎ,𝑏𝑜 )
- 은닉층에서 나와 다시 은닉층으로 입력되는 것을 나타내는 화살표. (𝑊ℎℎ,𝑏ℎ)
- 즉, RNN은 이전 시점의 정보들을 반영하여 더 정확한 예측을 하기 위해 활용해보자! 는 아이디어에서 출발했다. 위 그림을 보면 은닉층의 벡터(은닉 벡터) 가 다음 은닉층에 전달되는 것을 볼 수 있다. 이게 RNN의 핵심이다!!
- 어떻게 에 를 합성한다는 거지? 김성범 교수님 영상에서 이 수식을 보니 생각해보기 편했고, 핵심을 잘 담고 있다는 생각이 들었다.
- = + (bias는 수식에 넣지 않음)
- =
- = tanh, = softmax
- (위 수식에서 볼 수 있듯 가중치는 2개가 있다. 각각 입력 x를 h로 변환하기 위한 와 RNN의 은닉층의 출력을 다음 h로 변환해주는 이다. 주의할 것은 각 시점마다의 이 파라미터는 동일한 값이라는 것이다. 학습을 거치며 업데이트 되는 값이지 한 학습 내에서 계속 변하는 값이 아니라는 말이다!)
- 위 식에서는 𝑡-1, 𝑡만 표현했지만 그 과정이 쭉 있다고 생각해보면, 𝑡시점에 생성되는 hidden-state 벡터인 ℎ𝑡 는 해당 시점까지 입력된 벡터 𝑥1,𝑥2,⋯,𝑥𝑡−1,𝑥𝑡 의 정보를 모두 가지고 있게 되는 것이다. 연속형 데이터가 순서대로 입력되더라도 순서 정보를 모두 기억하기 때문에 연속형 데이터를 다룰 때 RNN을 많이 사용한다고 한다.
RNN의 종류
아래와 같이 다양한 형태의 RNN이 있다.
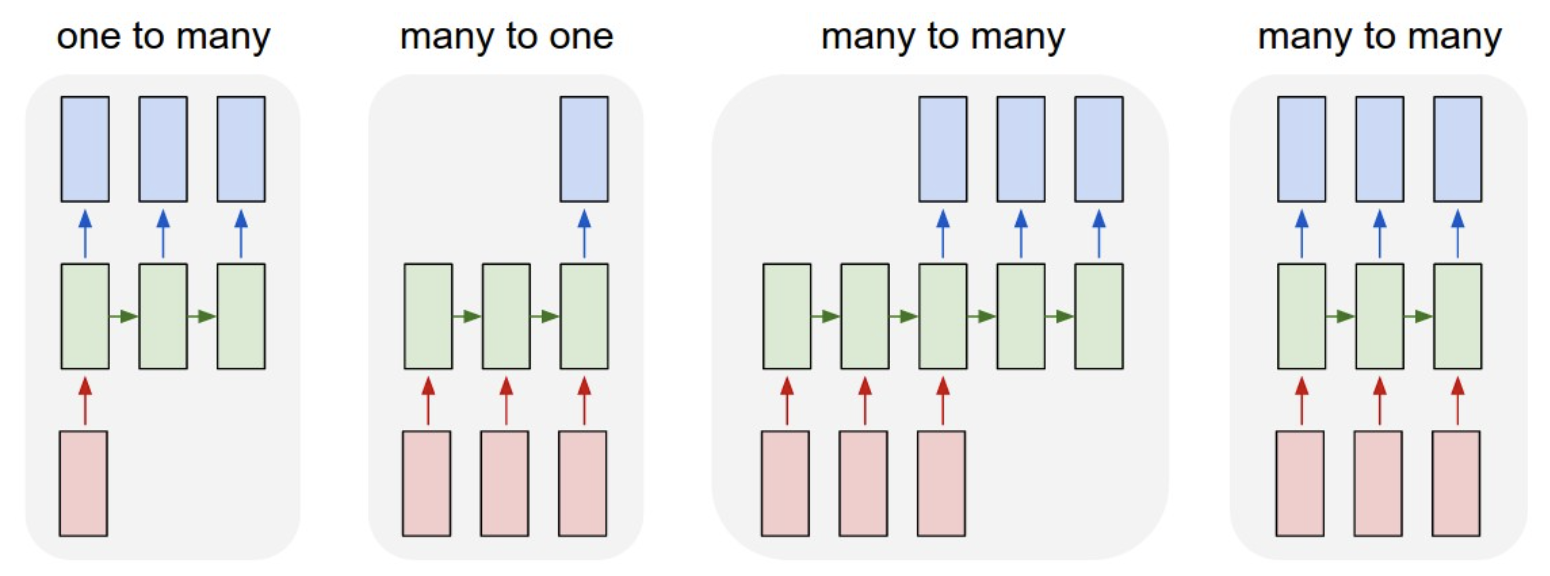
- 결과값을 언제 몇개를 뱉느냐에 따라 대강 어떤 목적으로 사용하는 모델인지는 구분이 될 수도 있을 것이다. 순서대로 예시는 다음과 같다.
- 이미지를 받아 이미지를 설명하는 문장 만들기, 감성분석(긍정/부정), 기계번역(위 그림과 같은 구조를 Seq2Seq라고 함), 비디오 프레임별 분류하기
그 외 참고
- tanh(하이퍼볼릭 탄젠트)를 쓰는 이유는 만약 ReLu를 쓰면 양수일 때 그 값을 그대로 뱉기 때문에 그대로 다음으로 넘어가면 넘어갈수록 값이 너무 커져서 기울기 폭발이 일어날 수 있기 때문이라고 한다. sigmoid를 안 쓰는 이유는 sigmoid보다 tanh가 좀 더 기울기 소실문제에서 견고하기 때문이라고 한다.(이건 tanh, sigmoid 미분 그래프의 범위를 찾아보면 바로 이해할 수 있다. sigmoid는 0~0.25 사이의 값을 가지기 때문에 상대적으로 더 작은 값들이 계속 곱해지다보면 소실 문제가 일어날 수 있다는 뜻임.)
- RNN을 파이썬으로 구현하면 아래와 같다. 참고차 넣어둠!
import numpy as np
class RNN:
"""
RNN을 파이썬 코드로 구현한 클래스입니다.
Args:
x: 입력되는 벡터
h_prev: 이전 시점의 은닉 상태 벡터(hidden state vector)
Wx: 입력 벡터(x)에 곱해지는 가중치
Wh: 은닉 상태 벡터(h_prev)에 곱해지는 가중치
b: 편향(bias)
"""
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] # 가중치 초기화
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.matmul(h_prev, Wh) + np.matmul(x, Wx) + b # 해당 부분을 수식과 비교해봅시다.
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next일단 RNN에 대해선 이 정도로 다루고 넘어가도록 하자.
3. LSTM / GRU
LSTM(Long-Short Term Memory, 장단기 기억망)은 RNN의 단점을 보완하기 위해 나온 모델이다. 그럼 RNN의 무슨 문제가 있다는 것일까?
- RNN의 단점
- 병렬화(Parrelization) 불가능: 연속형 데이터를 받아 순차적으로 데이터를 처리하다보니 GPU 연산의 장점인 병렬연산이 불가능하다. (즉, 전체 작업 속도가 느릴 수 밖에 없다는 것)
- 기울기 폭발(Exploding Gradient), 기울기 소실(Vanishing Gradient) 문제: 위에서 잠시 언급했지만 역전파 과정에서 tanh의 미분값이 계속 곱해지게 되는데, 이 과정에서 1 미만의 작은 숫자들이 계-속 곱해지다보면 기울기 소실 문제가 발생할 수 있다. (즉, 시퀀스 앞쪽으로 갈수록 역전파 정보가 제대로 전달될 수 없단 뜻이다.)
기울기 정보의 크기가 문제라면 "기울기 정보의 크기를 적절하게 조정하여 줄 수 있다면 문제를 해결할 수 있지 않을까?"라는 아이디어에서 나온 것이 바로 LSTM이라고 할 수 있다.
- 참고로 요즘엔 RNN이라고 하면 대부분 LSTM이나 GRU를 말하고, 오히려 기본적인 RNN을 Vanilla RNN이라고 별칭한다고 한다. 나도 앞으로는 RNN하면 그냥 LSTM이라고 디폴트로 생각하면 될 듯.
LSTM의 구조
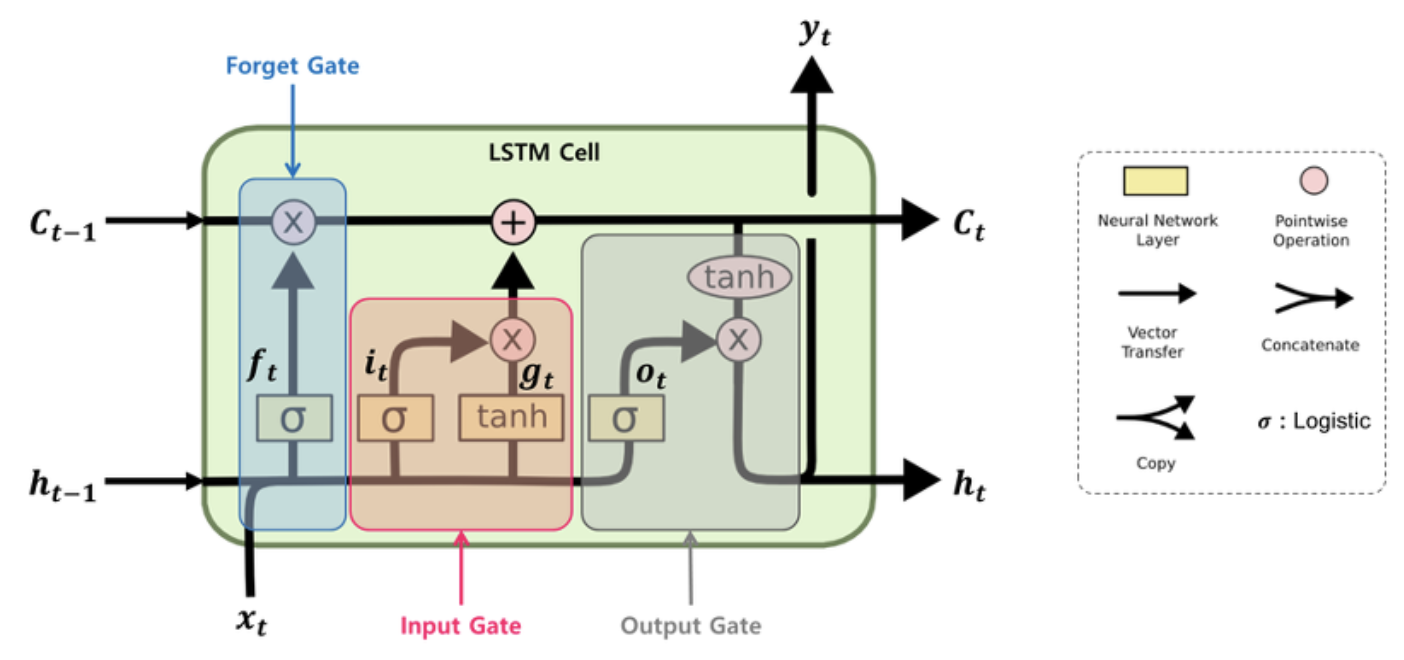
- 위는 LSTM 셀 하나의 구조이다.
(후.. 정신 바짝 차려야 한다..)기존 RNN에는 없던 'Gate'라는게 추가된 것을 볼 수 있다. 각각의 의미는 다음과 같다.- Forget Gate (): 과거 정보를 얼마나 유지할 것인가?
- Input Gate () : 새로 입력된 정보는 얼마만큼 활용할 것인가?
- Output Gate () : 두 정보를 계산하여 나온 출력 정보를 얼마만큼 넘겨줄 것인가?
- 아주 잘 기억해야할 것은 cell-state가 추가되었다는 것이다. 이 cell-state는 역전파 과정에서 활성화 함수를 거치지 않아 정보 손실이 없기 때문에 뒷쪽 시퀀스의 정보에 비중을 결정할 수 있으면서 동시에 앞쪽 시퀀스의 정보를 완전히 잃지 않을 수 있다고 한다.
- 구체적으로 각각 어떻게 작동하는지는 내용을 많이 찾아봤는데 복잡해서 완전히 이해하기가 어려웠다. 오늘은 우선 크게 크게 의미 위주로만 기억하도록 하고, 조만간 공부노트에서 파보기로 하자.
- 참고: 역전파 과정 레퍼런스
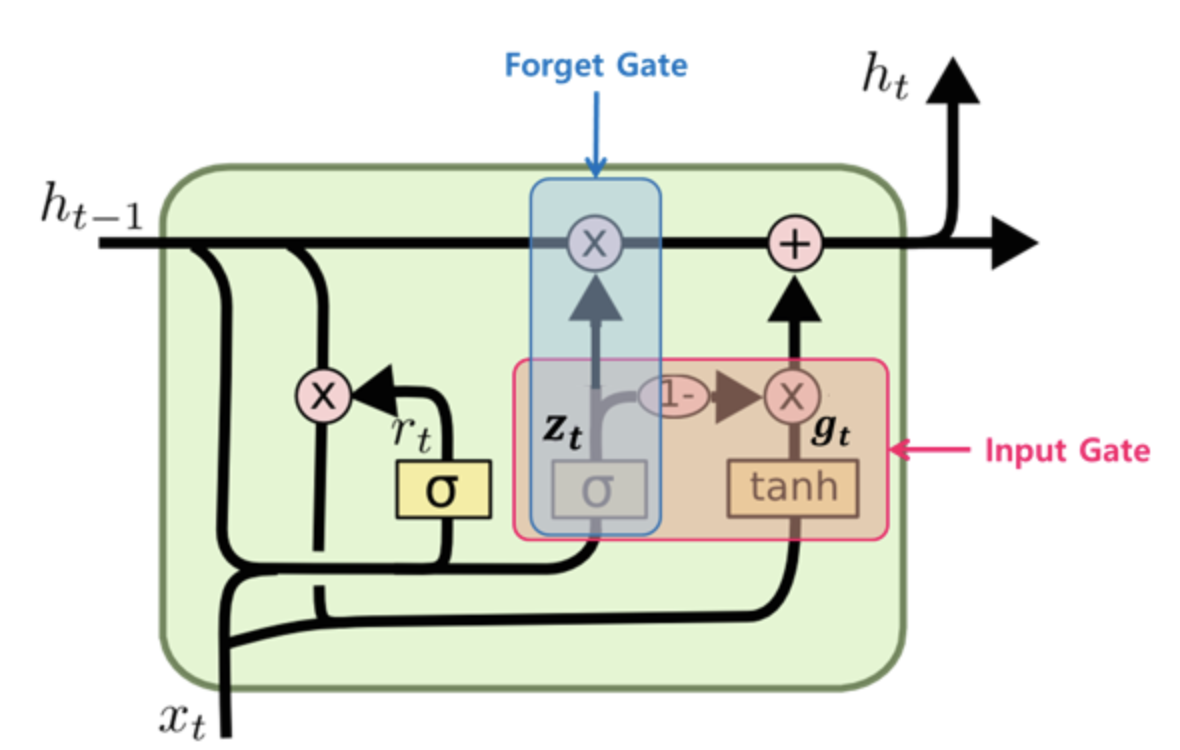
GRU
- GRU(Gated Recurrent Unit)는 LSTM의 간소화버전인데, 요즘에는 거의 LSTM을 쓴다고 하니 여기는 그 구조 이미지만 남겨두고 넘어간다.
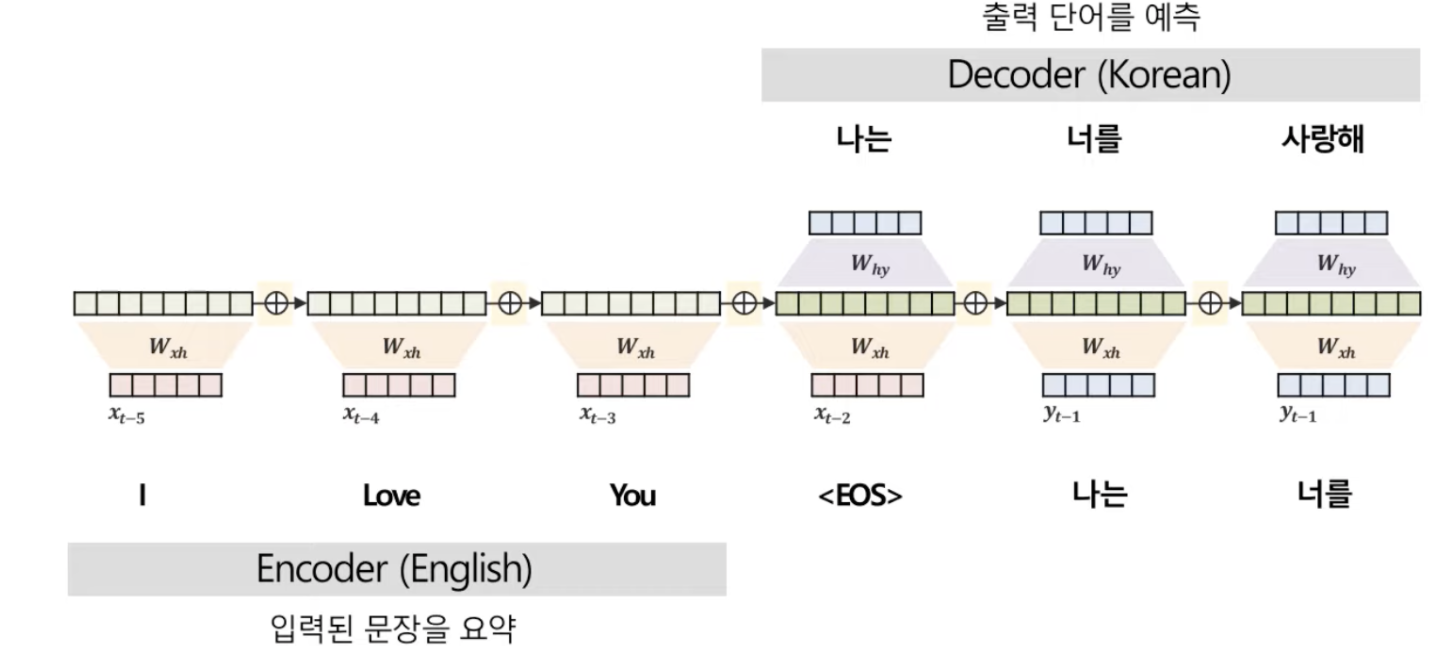
4. Attention 어텐션
- 기계번역에서 아주아주아주아주아주 중요한 개념인 어텐션에 대해서도 다뤄보았다. 전에 읽었던 책에서 attention 개념을 처음 제안한게 한국인 교수님으로 봤었는데 괜히 혼자 내적친밀감 들고 막 그랬다. 암튼 기계번역에 쓰이는 거라는 걸 기억해!! 아래 그림 깔고 다음을 보면 된다.!!!
- 어텐션 개념은 역시 RNN의 단점을 보완하기 위해 나왔다. 그럼 RNN에 어떤 단점이 있다는 걸까?
- 그건 바로 기울기 소실로부터 나타나는 장기 의존성(Long-term dependency) 문제이다. 즉, RNN의 구조를 보면 앞의 정보가 뒤로 순차적으로 전달되는데, 문장이 길어진다면??? 당연히 시퀀스 맨 앞쪽에 위치하는 코튼의 정보를 상당부분 잃어버릴 수 밖에 없는 것이다.
- 이 문제를 어떻게 해결했을까? 기존 구조의 문제는 decoder가 단어를 예측할 때, encoder의 마지막 은닉층의 정보(= Context Vector)만을 활용하기 때문에 어떤 단어로 번역해야할지 각각 예측할 때, 원래 문장에서 더 중요한 단어에 집중할 수가 없다는 것이었다.
- 그래서 나온 대안은 바로 1) 매 시점 정보를 참고하고, 2) 더 중요한 단어에 집중하자라는 것이다.
- 그럼 중요도는 어떻게 계산할까? 가장 간단한 유사도 측정은 바로 내적이다! 이걸 포함하여 어텐션이 디코더에 적용되는 과정은 다음과 같다.
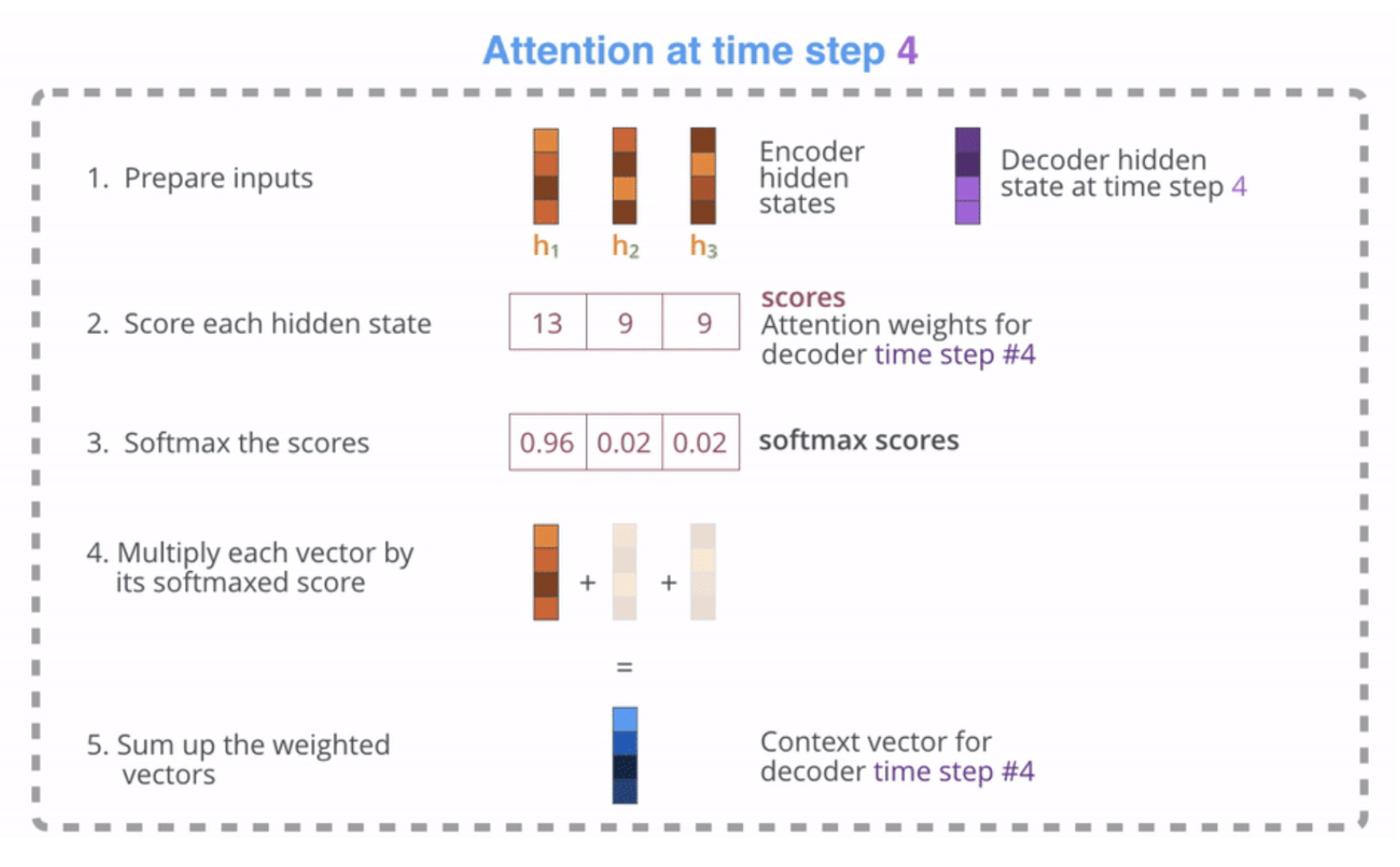
- 저기 Decoder의 hidden vector는 내가 번역할 단어라고 생각해도 된다.
- 먼저, '나는'을 번역하기 위해 해당 부분의 hidden-state vector를 준비한다. 그리고 'I', 'Love', 'You' 각각의 hidden-state vector와 내적을 통해 score를 계산한다.
- 이 score를 그대로 쓰면 정확한 비교가 어려우니까 softmax함수를 취해 0-1사이의 확률 값으로 변환해준다.
- 이 각각의 확률값에 아까 준비했던 'I', 'Love', 'You' 각각의hidden-state vector를 곱한다. 그걸 표현한게 위 4번 그림이다. 이 벡터들을 모두 더해 하나의 Context vector를 만든다.
- 최종적으로 이렇게 나온 context vector와 디코더의 히든 스테이트 벡터를 활용해(곱하기) 출력 단어를 결정한다.
- 위 과정을 디코더의 각 스텝마다 반복하며 번역을 진행한다.
자, 기존 RNN처럼 하나의 context vector를 사용하는게 아니라 각 단어마다 이렇게 어떤 단어에 집중할지를 결정하기 때문에, 시퀀스의 앞에 위치했다고 하더라도 토큰 정보가 소실되지 않아 번역 성능이 좋아진 것이다.
오늘은 간단히 적었지만 어텐션 개념에 대해 잘 알고 싶다면 위 김성범 교수님 영상을 한 번 보는 걸 추천한다.
5. 실습한 것
오늘은 코치님이 개념만 잘 챙겨가면 되고 코드는 나중에 이해해도 된다고 수차례 강조했었다. 오늘 실습은 그런 의미에서 간단했음. 실제로 LSTM 적용하려면 layer에 하나만 쌓으면 됐음!
다음 링크는 LSTM을 사용하여 Spam 메시지 분류를 수행한 캐글 노트북입니다. => Link
위 노트북에서 사용한 코드를 참고하여
캐글 데이터셋인 Women's E-Commerce Clothing Reviews 를 분류해 보세요.
- 분류에 사용될 텍스트 데이터 :
Review Text열을 사용합니다.- 레이블(label) 데이터 :
Recommended IND열을 사용합니다.
[데이터 전처리]
(여러 열에 있던 것 통합해서 넣어두겠음)
np.random.seed(42)
tf.random.set_seed(42)
df = pd.read_csv('Womens Clothing E-Commerce Reviews.csv')
# 필요한 열만 남기기
feature = 'Review Text'
target = 'Recommended IND'
df = df[[feature, target]]
# 결측치 확인
print('feature 결측치 확인', df[feature].isna().sum())
# 결측치 드랍
df = df.dropna(axis = 0)
print('\nfeature 결측치 재확인', df[feature].isna().sum())
print('target 결측치 확인', df[target].isna().sum())2)텍스트 분류를 수행해주세요.
- 데이터셋 split시 test_size의 비율은 20%로,
random_state = 42로 설정합니다.- Tokenizer의
num_words=3000으로 설정합니다.- pad_sequence의
maxlen=400으로 설정합니다.- 학습 시, 파라미터는
batch_size=128, epochs=10, validation_split=0.2로 설정합니다.- EarlyStopping을 적용합니다. 파라미터는
monitor='val_loss',min_delta=0.0001, patience=3로 설정합니다.- evaluate 했을 때의 loss와 accuarcy를 [loss, acc] 형태로 입력해주세요. Ex) [0.4321, 0.8765]
[텍스트 분류를 수행]
# train, test split
train, test = train_test_split(df, test_size=0.2, random_state = 42)
X_train, X_test = train[feature], test[feature]
y_train, y_test = train[target], test[target]
print('train shape', X_train.shape, y_train.shape,'\ntest shape', X_test.shape, y_test.shape) # (18788,) (18788,) / (4698,) (4698,)
# 문제에서 주어진 파라미터
num_words = 3000 # for Tokenizer
maxlen = 400 # for pad_sequence
batch_size=128
epochs=10
validation_split=0.2 # for modeling
monitor='val_loss'
min_delta=0.0001
patience=3 # for early_stopping
# Tokenize - X_train
tokenizer = Tokenizer(num_words = num_words)
tokenizer.fit_on_texts(X_train)
'''
[오류 기록]
위 'tokenizer.fit_on_texts(X_train)'을 돌렸을 때 "AttributeError: 'float' object has no attribute 'lower'" 오류가 났다.
다시 데이터 전처리 단계로 돌아가서 결측값이 있는지 확인해보았더니 있었고 제거처리 후 제대로 작동하였다. 전처리 단계에서 결측치 확인하는 것 잊지 말자.
'''
X_train = tokenizer.texts_to_sequences(X_train)
# pad_sequence - X_train
X_train = sequence.pad_sequences(X_train, maxlen = maxlen)
print(X_train)
print('\n\n maxlen 잘 적용되었는지 확인 => len(padded[0]) ==', len(X_train[0])) # checked.
[모델링, 평가]
# 모델링
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(num_words, 300 , input_length = maxlen),
tf.keras.layers.LSTM(64),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=validation_split, callbacks=[EarlyStopping(monitor=monitor,min_delta=min_delta, patience = patience)])
# validation_split reference https://vision-ai.tistory.com/entry/%EB%94%A5%EB%9F%AC%EB%8B%9D%EC%9D%98-%EB%AA%A8%EB%8D%B8-%EC%84%B1%EB%8A%A5-%ED%8F%89%EA%B0%80-1-Keras%EC%9D%98-validationsplit-%EC%9D%B4%EC%9A%A9%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
# evaluate
X_test = tokenizer.texts_to_sequences(X_test)
X_test = sequence.pad_sequences(X_test, maxlen = maxlen)
model.evaluate(X_test, y_test) # loss: 0.3033 - accuracy: 0.8836 // # 전에 early_stopping 실습할 때 model.fit에 X_test, y_test 직접 넣고 베스트 모델 찾아서 하는 것보다 이렇게 하는게 성능이 더 좋네..?6. 그 외
Feeling
- 오늘 정말 완전 멘붕,., 지금까지는 아무리 어려워도 보통은 저녁 즈음 되면 머릿속에서 정리가 다 되었었는데, 안된다고 느낀게 오늘이 처음인 것 같다.
- 추가 공부가 절실하다..
