Key words
합성곱 신경망(Convolutional Neural Network), 패딩(Padding), 풀링(Pooling), 전이 학습(Transfer Learning), 이미지 증강(Image Argumentation)
1. 합성곱 신경망(Convolutional Neural Network, CNN)
지난 스프린트는 자연어 처리에 대해서 배웠다면 이번 스프린트는 이미지 처리에 대해 배우는 시간이다.
- CNN이 이미지 처리에서 주목을 받기 시작한 건 2012년에 경진대회에서 CNN을 적용해 우승을 한 이후부터라고 한다. (AlexNet)
(딥러닝 공부하다보면 정말 생각보다 얼마 안된 것들이 많아 놀랄 때가 많다. 나는 막 군대가서 어리버리하고 있을때 세상은 이렇게나 크게 변하고 있었다니) - 그럼 왜 CNN이 이미지 처리에서 주목을 받게 되었을까? 그건 바로, 이미지는 위치에 맞는 공간적인 특성을 가지고 있는데, CNN이 이를 잘 살려주기 때문이다. 일반적인 MLP(다층 퍼셉트론)은 데이터를 Flatten에서 신경망에서 연산되기 때문에 이런 공간적인 특성을 살리지 못하는 한계를 지니고 있던 것이다.
- 여기서 공간적인 특성을 지니고 있다고 함은 가로 세로를 동시에 같이 봐야 이미지 대상(object)이 무엇인지 알 수 있다는 뜻이라고 한다. (ex. 새 이미지를 볼 때 딱 점 하나만 보면 그게 새인지 뭔지 알 수 없음)
그럼 어떻게 공간적인 특성을 잘 보존할 수 있다는걸까? CNN의 구조를 보도록 하자.
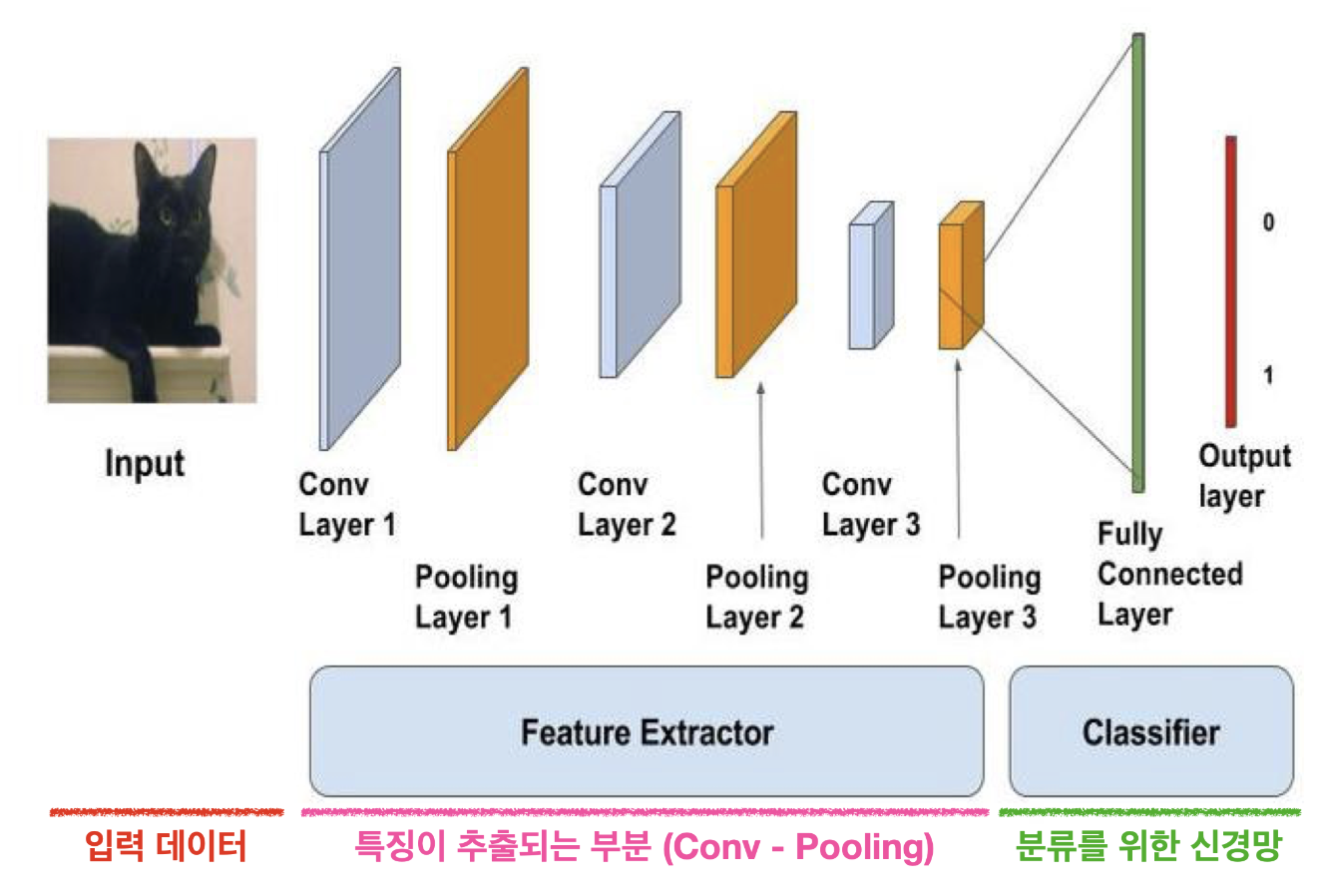
1. Convolution Layer
-
합성곱 층에서는 합성곱 필터(Convolution Filter)가 슬라이딩(Sliding)하며 이미지 부분부분의 특징을 읽어나간다. 이 합성곱 층을 지나며 내가 보는 이미지가 어떻게 수치화되는지 보는게 굉장히 신기했다.
-
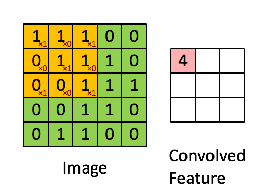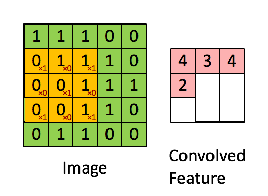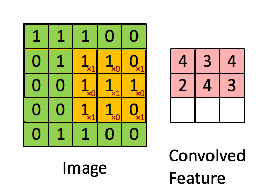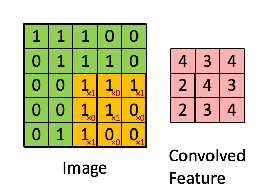
아래 이미지는 한 번의 합성곱이 이루어지는 과정을 보여준다. 아래
Weight라고 되어있는 부분이 필터다. 이미지 데이터와 이 필터의 각 요소끼리 곱해서 다 더해 하나의 수치로 바꿔주게 된다.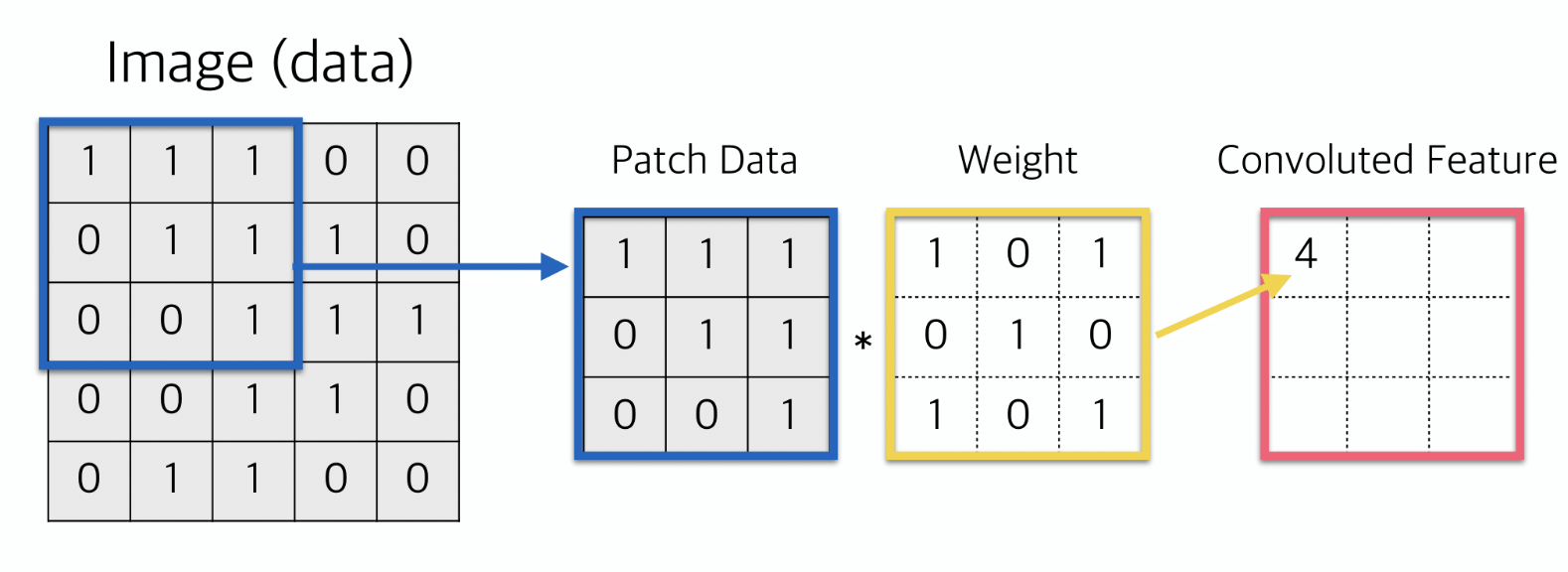
- (Keras에서는 Kernel이라고도 하고 Weight라고도 한다고 한다.
필터=커널=가중치는 같은 말로 혼용된다고 하니 기억해두자.) - 참고로 이미지 데이터란? 보통은 255X255로 이루어져있고, 컬러 이미지 같은 경우 여기에 RGB 3채널이 붙는다. (255,255,3) 이렇게 이미지 데이터 shape이 나옴.

- (Keras에서는 Kernel이라고도 하고 Weight라고도 한다고 한다.
-
아래 gif를 보면 노란색으로 표시된 필터가 이미지의 각 부분을 훑으면서 오른쪽에 새로운 feature map을 만드는 걸 볼 수 있다. 이렇게 이미지 전체를 훑으며 합성곱을 하여 feature map을 만들기 때문에, 이미지의 공간적인 특성을 잘 보존할 수 있다고 하는거다!
2. 패딩 (Padding)
- 패딩은 자연어 처리할 때
pad_sequence를 통해 써봤던 적이 있다. 이미지에 패딩을 한다는 건 이미지 외부에 특정한 값으로 둘러쌓는다는 의미다. 자연어 처리할 때와 마찬가지로 의미를 가지지 않는0을 보통 넣는다고 한다. (이걸 zero-padding이라고 부른다.) - 거두절미하고 아래는 패딩된 이미지가 합성곱층을 지나는 걸 표현하고 있다.

- 그럼 왜 패딩을 해주는걸까? 이게 중요하다. 바로 바로~ 패딩을 하면 정보의 손실을 줄일 수 있다는 것이 가장 주요한 이유다.
- 이게 무슨 말이냐면, 위 움짤을 보면 원래 이미지 데이터(패딩 안쪽!)의 크기와 커널을 거쳐 나온 피쳐 맵의 크기가 똑같은 걸 볼 수 있을 것이다. 반면 패딩을 거치치 않았다면 원래보다 더 작은 3X3 매트릭스가 나왔을 것이다. 행렬의 사이즈가 줄어든다는 건 그만큼 정보의 손실이 일어날 수 있다는 거잖아! 그런 의미다.
- 그리고 패딩을 하면 외곽부분의 정보를 좀 더 살려줄 수 있다는 의미도 있다. 위 움짤에서 좌상단 모서리에 있는 '60'이 패딩을 안해주면 한 번만 결과에 반영되지만 패딩을 하면서 여러 번 특성이 담기게 되는 걸 볼 수 있을 것이다.
3. 스트라이드 (strides)
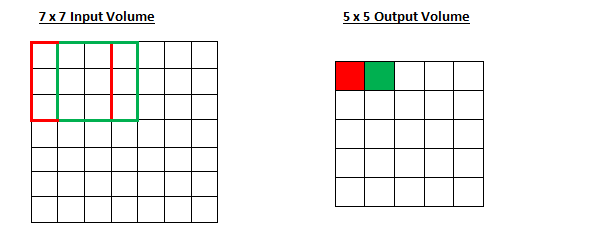
- 스트라이드는 보폭이다. 쉽게 생각하면 커널이 얼마 간의 보폭을 두고 이동할 건지 결정하는 것이다. 위 움짤에서는 strides = 1이다. 한 칸 간격으로 이동하니까.
- Stride = 1
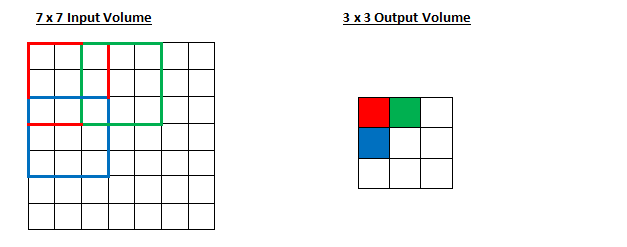
 Stride = 2
Stride = 2
- 아래 수식은 참고로만 알아두자. 출력되는 피쳐 맵 사이즈 알 수 있는 거임. (왜 2p인지 궁금했었는데 패딩을 하면 양쪽에 사이즈가 추가되니까 그런거였음)
필터 크기(Filter size), 패딩(Padding), 스트라이드(Stride)에 따른 Feature map 크기 변화
: 입력되는 이미지의 크기(=피처 수)
: 출력되는 이미지의 크기(=피처 수)
: 합성곱에 사용되는 커널(=필터)의 크기
: 합성곱에 적용한 패딩 값
: 합성곱에 적용한 스트라이드 값
4. 풀링 (Pooling)
- 자, 지금까지의 흐름을 간단히 정리해보자. 이미지 데이터가 stride에 맞게 합성곱 층을 거치면서 하나의 매트릭스가 나왔겠지!
- Pooling은 가로, 세로 방향의 공간을 줄이기 위한 목적으로 사용한다. 무슨 말이냐고? 아래 그림을 보면 이해할 수 있을 것이다.
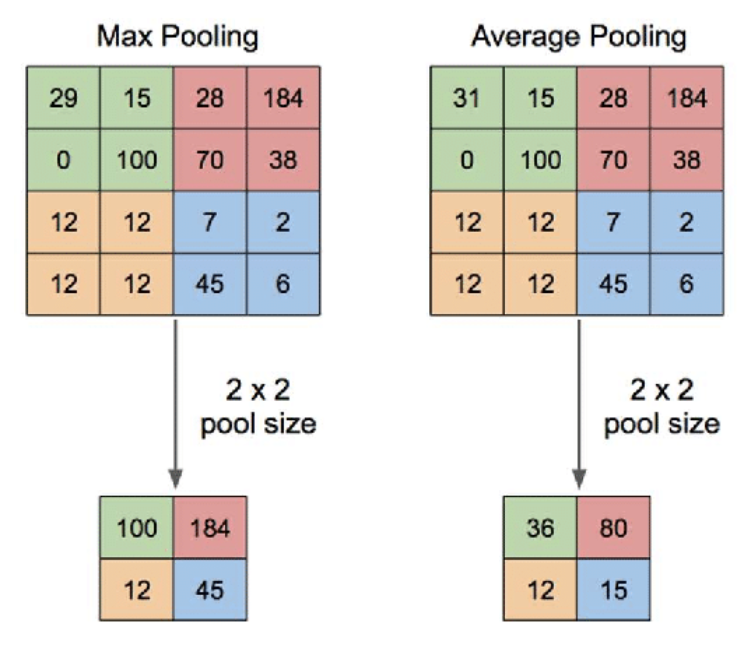
- Pool size는 원래 매트릭스를 훑는 크기를 말하는거지 풀링된 후 아웃풋된 매트릭스의 크기를 말하는게 아니다!! 이거 헷갈렸었음.
- 대표적으로는 위 그림처럼 max값을 가져오는
Max Pooling과 평균 값을 가져오는Average Pooling이 있다. 일반적으로 이미지를 처리할 때에는 각 부분의 특징을 최대로 보존하기 위해서 Max Pooling을 사용한다고 한다. - 왜 풀링을 하는지는 노트에 나와있지 않아서 따로 찾아봤는데 input size가 줄어드는만큼 파라미터의 수도 줄어들며 과적합을 방지하는 효과를 노리는거라고 한다. 차원축소하는 거랑 같은 의미로 생각해도 될 듯.
- 풀링 층은 학습해야 할 가중치가 없으며 채널 수(ex. RGB)가 변하지 않는다는 특징을 가지고 있다.
5. 완전 연결 신경망(Fully Connected Layer)
- 이건 이전부터 써왔던 그 신경망 생각하면 된다. 마지막 Pooling layer를 거쳐 나온 매트릭스를 flatten 해주고 신경망에 통과시키는 분류기라고 생각하면 된다. 헷갈린다면 아래 실습 부분의 코드를 보면 이해가 갈 것이다.
마지막으로, CNN의 학습은 Convolution 층에 있는 Filter의 가중치에서 이루어진다는 점 기억! 처음에는 필터의 가중치가 랜덤하게 지정되어 시작하고, 역전파를 통해 이 가중치가 갱신된다는 뜻이다.
- (당연히 fully connected layer의 가중치/편향도 학습되는거겠지?!)
코드로 구현하는 건 생각보다 쉽다. Keras에서 제공하는 라이브러리를 사용하면 된다. 아래 코드는 예시로 넣어둔다.
# 모델 설계
model = Sequential()
model.add(Conv2D(32, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(Flatten())
model.add(Dense(128, activation='relu')) # 여기부터 Fully Connected Layer
model.add(Dense(10, activation='softmax')) # 출력층 설계
# 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#모델 학습
model.fit(X_train, y_train,
batch_size=128,
validation_data=(X_val, y_val),
epochs=10)
# 평가
model.evaluate(X_test, y_test, verbose=2)- 설명을 좀 보충하면, 맨 처음 Conv layer에서는 3,3 사이즈의 필터가 32개 도는 것이다. 만약 RGB 데이터라면? 모든 필터에 있는 가중치의 갯수는 이 되는거다. 아래 이미지는 참고. (이미지 출처)
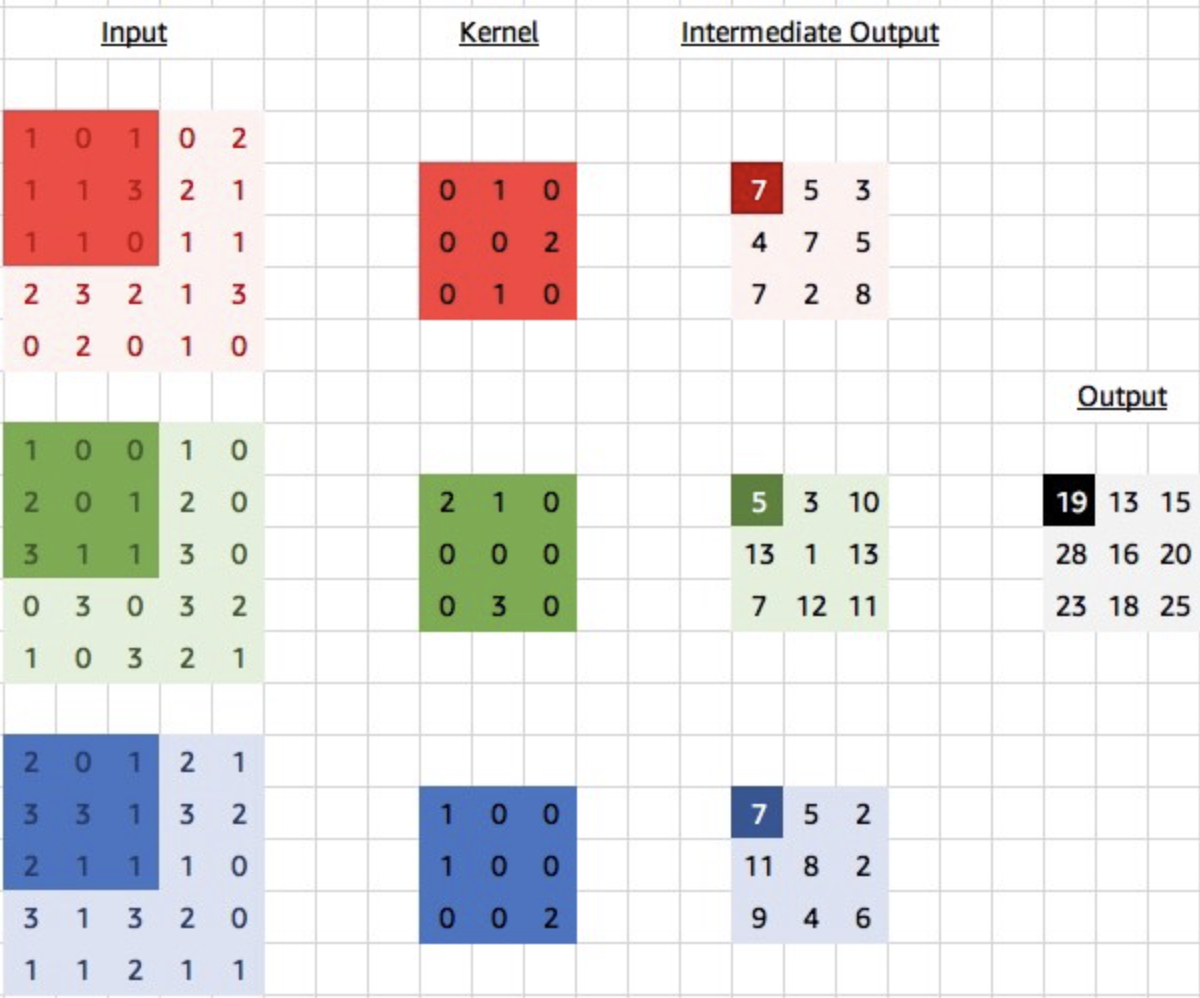
- (용어를 정확히 해보면 3개의 커널이 하나의 필터가 되는거다!)
2. 전이 학습 (Transfer Learning)
- 전이 학습이란 쉽게 말해 대량의 데이터를 통해 훈련된
사전 학습 모델(Pre-trained Model)을 가져와 사용하는 것을 말한다. 거인의 어깨에 올라서서 더 넓은 세상을 바라보라는 말로 대표된다. - 모델 전체를 가져다가 그대로 쓸 것인지, 아니면 일부만 가져올 것인지 고를 수 있다. 일반적으론
Conv-Pooling파트의 가중치(필터)만 그대로 가져와 사용하고, 분류기 역할을 하는완전 연결 신경망부분은 추가로 설계하여 사용한다고 한다. 내가 지금 풀어야할 문제가 사전학습 모델이 만들어질 때의 문제와 같지 않으니 그런 것으로 이해하면 될 것 같다. - 아래 그림이 사전학습모델 중 완전 연결 신경만 부분만 커스텀해서 사용하는걸 표현하고 있다. 이 전이학습을 실제로 어떻게 할 수 있는지에 대한 코드는 이따 실습한 부분에서 확인해보면 된다.
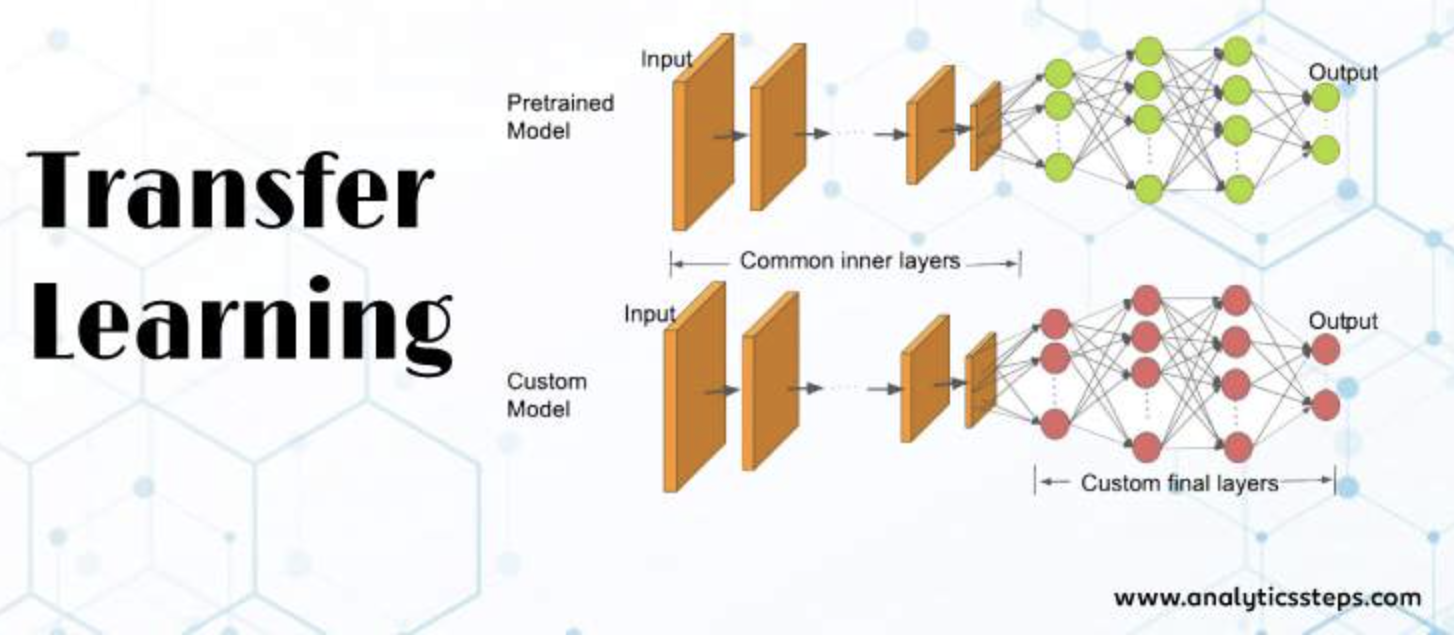
주요 사전학습 모델로는 VGG, GoogleNet(inception), ResNet이 있다.
- 지금 당장 해당 모델의 구조를 다 외울 필요는 없다고 했고, 모델의 이름 정도만 알고 넘어가도 된다고 했다. 하지만 간략히 특징은 적어둬야지.
- VGG는 층을 깊게 쌓은거고, GoogleNet은 층을 깊게 쌓으니까 성능이 좋다는 얘기를 듣고 '그래? 그럼 넓게도 쌓아보자'해서 나온거고, ResNet은 층을 너무 깊이 쌓으니까 성능이 오히려 떨어지네! 기울기 소실 문제를 해결해 봐야겠어!라고 해서 나온거다. 이런 흐름으로 이해하면 된다.
- 참고로 VGG의 컨셉은 3X3 사이즈의 필터를 쓰되 층을 깊게 쌓았다 는 것이다.
- 층을 깊게 하면 적은 파라미터로도 높은 수준의 표현력을 달성할 수 있다고 한다.
- 한 개의 합성곱 층에서 5×5 크기의 필터를 사용하여 하나의 출력값을 낼 때에는 5×5=25 개의 파라미터가 필요하지만, 3×3 필터를 사용하여 2층으로 쌓으면 3×3×2=18 개의 파라미터만으로도 같은 크기의 공간을 표현할 수 있게 되기 때문. 이 차이는 층을 더 깊게 쌓거나 가운데 풀링층을 넣게 되면 더욱 커진다고 한다.
- 참고로 ResNet이 기울기 소실 문제 해결을 위해
Residual Connection(=Skipped Connection)을 적용했는데, 아래 그림과 같이 layer를 통과한 후 자기 자신의 값을 더해주는 것이다. 이렇게 되면 역전파 과정에서 1이 더해지면서(자기 자신은 미분하면 1이므로) 지나치게 작은 값으로 곱해져 기울기가 소실되는 문제를 어느 정도 방지하려는 컨셉이다. f(x)와 x의 차원이 같아야 한다.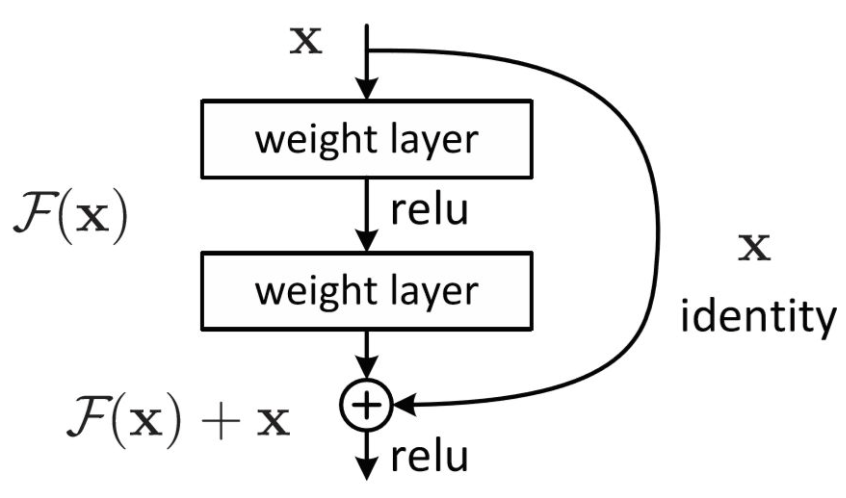
3. 이미지 증강 (Image Argumentation)
- 이미지 증강은 노트에서 거어어의 다루지 않고 이런게 있다 정도로만 터치하고 넘어갔다.
- 이미지 증강이란 모델이 이미지를 더 잘 분류할 수 있도록 훈련 이미지를 비정상적으로 변형하여 모델에 추가 학습을 하도록 하는 것을 말한다. 예를 들어, 이미지를 자르고, 뒤집고, 회전시키고, 색상을 변경하여 학습시키는 것이다.
- 왜 이렇게 할까? 만약 똑바로 서있는 사람의 모습만 모델이 계속 학습을 해왔다고 해보자. 그럼 만약 사람이 거꾸로 천장에 매달려있다면? 모델은 그런 모습을 처음 봤기 때문에 제대로 인식하지 못할 확률이 올라가기 때문이다. 만약 이미지 증강을 통해 여러 상태의 object를 학습했다면 더욱 robust한 모델을 만들 수 있는 것이다.
- 그리고 실습할 때 찾아보며 알게된 바로는, 학습 이미지 데이터가 충분하지 않을 때 이렇게 이미지 증강을 이용하여 데이터 양을 늘릴 때도 사용된다고 하는 것 같다.
- 이것도 실제 코드에 대해선 실습 부분에 레퍼런스 달아두었으니 필요할 때 찾아보면 된다.
4. 실습한 것
Assignment 1
Sobel Filter를 이용해 실제 Convolution(합성곱) 연산이 일어날 때, 이미지가 어떻게 변화하는지 시각화해보겠습니다.
(Colab에서 이미지 업로드하는 부분은 생략한다. 과제가 아닌 부분도 신기한 코드가 많아서 여기 옮겨두니 참고.)
[3 채널의 컬러 이미지를 gray scale로 변형]
def rgb2gray(rgb):
r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return grayfig, axes = plt.subplots(1, 2, figsize=(5, 10))
img = plt.imread('2521.jpg')
gray_img = rgb2gray(img)
print("Color Img Shape : ", img.shape)
print("GrayScale Img Shape :", gray_img.shape)
axes[0].imshow(img)
axes[1].imshow(gray_img, 'gray') # 엄청 신기하다;;
[수직선과 수평선을 detect하는 Sobel Filter를 이용해 합성곱 연산을 진행하겠습니다]
sobel_vertical = np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
sobel_horizontal = np.array([[1, 2, 1],
[0, 0, 0],
[-1, -2, -1]])문제 1-1
다음은 Convolution 연산을 진행하는 함수입니다. 각각의 빈칸을 채워주세요
1. 빈칸 A, B : 컨볼루션 연산의 최종 output의 height, width를 구해주세요
2. 빈칸 C, D: val_H, val_W는 filter가 최대한으로 갈 수 있는 index입니다.
3. 빈칸 E : filter와 image 간 convolution 연산을 진행해주세요
- TIP : filter * img 형태로 원소별 곱셈을 진행하고, numpy에서 제공하는 sum 메소드를 사용할 수 있습니다.
def convolve2D(image, filter, padding=0, strides=1):
filter_H, filter_W = filter.shape[0], filter.shape[1]
img_H, img_W = image.shape[0], image.shape[1] # 위에서 작업한 gray_img (이해를 돕기 위함) shape = (340, 600)
# Convolution 연산의 출력값인 특성맵 shape
output_H = int((img_H+2*padding-filter_H/strides)+1) # A
output_W = int((img_W+2*padding-filter_W/strides)+1) # B
output = np.zeros((output_H, output_W))
# Padding 적용하기
if padding != 0:
padded_img = np.zeros((image.shape[0] + padding*2, image.shape[1] + padding*2)) # 이 함수에서 'padding'의 의미는 각 셀에 들어가는 숫자 자체가 아니라 몇 겹으로 둘러쌓을건지를 말하는 거인듯? np.zeros로 값은 0을 넣는다는게 정해져 있으니까.
padded_img[int(padding):int(-1 * padding), int(padding):int(-1 * padding)] = image # => 패딩으로 둘러싼 부분 빼고 가운데 이미지 크기만큼만 이렇게 0으로 표현해둔 것임. (헷갈리면 a = np.zeros((10,10)) a[1:-1,1:-1] 해보면 됨.)
else:
padded_img = image
padded_img_H, padded_img_W = padded_img.shape[0], padded_img.shape[1] # 문제에는 없었지만 아래 val_h, val_w를 구할 때 필요하여 추가한 행.
val_H = padded_img_H - (filter_H - 1) # C - 필터로 패딩된 이미지 최대 몇번 지날 수 있는가 말하는 것이다. 헷갈린다면 10개 블록을 2개씩 나누며 훑는다고 생각해보면 된다. 왜 (filter_H - 1)을 해주는지도 간단히 실험해보면 알 수 있다.
val_W = padded_img_W - (filter_W - 1) # D
for h in range(0, val_H, strides):
for w in range(0, val_W, strides):
output[h, w] = (filter*padded_img[h:h+filter_H, w:w+filter_W]).sum() # E - 필터가 돌면서 피쳐맵 만드는 과정을 머릿속으로 생각하면서 이 코드를 보면 이해하기 더 쉽다. / array 인덱싱 레퍼런스 https://m.blog.naver.com/hsj2864/220831822625
return output
vertical_output = convolve2D(gray_img, sobel_vertical)
horizontal_output = convolve2D(gray_img, sobel_horizontal)
fig, axes = plt.subplots(1, 2, figsize=(10, 20))
axes[0].imshow(vertical_output, 'gray')
axes[0].set_title('Vertical Sobel Filter')
axes[1].imshow(horizontal_output, 'gray')
axes[1].set_title('Horizontal Sobel Filter')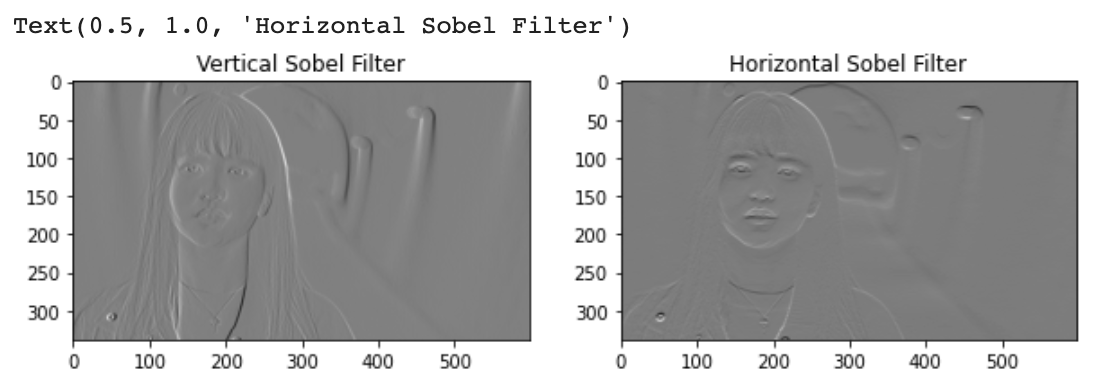
- 확실히 라이브러리 그냥 가져다 쓰는 것보다 함수를 뜯어보고 적어보고 하다보니 프로세스 이해하는데 많은 도움이 되었다.
- 참고로 이 실습과 관련하여 아래 질문을 했었다.
- "오늘 코딩 과제 1번을 하다 궁금한건데, 컨볼루젼을 할 때 vertical_output, horizontal_output을 각각 뽑아서 비교하는데, 수직선과 수평선을 detect하는 소벨 필터를 사용한다는 것의 의미가 뭔가요? 따라하긴 하는데 그 의미가 뭔지 파악하기가 어렵습니다ㅠ"
- 받은 답변은 아래와 같다.
- 소벨필터는 말 그대로 수평과 수직 기준으로, 즉 픽셀과 픽셀 간의 관계를 찾아내는 거라고 함. 좌우 간의 픽셀의 관계를 찾으면 호라이젠탈, 버티컬은 위 아래로.
- 픽셀값이 갑자기 바뀌면 물체가 탐지될 가능성이 높아진다. 이걸 이용하는거고. 그냥 필터 종류 중의 하나라고 생각하면 된다고 함. 이 정도만 알고 넘어가면 된다고 함.
- 추가 질문과 답: 그럼 실제로 모델에 소벨 필터 사용할 때는 수직과 수평 행렬 중에 하나를 골라서 적용하는건가요?
- 실제 모델에서는 둘다 적용해보면서 더 결과가 높은 것으로 학습이 될 거라고 함. 여하간 둘이 한 뭉치로 동시에 적용되는 건 아니구나.
문제 1-2
빈칸 A에서 max pooling을 진행해주세요
- TIP : numpy에서는 max 값을 구해주는 np.max가 존재합니다
def maxPooling2D(image, pool_size=2, strides=2): # pool_size랑 stride랑 같다는 것 기억하자! 이전처럼 겹쳐서 이동하는게 아니라 하나 보고 풀사이즈만큼 옆으로 가서 봐서 최대값 잡는게 맥스 풀링이니까!
img_H, img_W = image.shape[0], image.shape[1]
valid_H, valid_W = img_H - (pool_size - 1), img_W - (pool_size - 1) # 위에서 val_H, val_W 구했던 거랑 원리는 똑같음. 필터 크기 대신 풀 사이즈가 들어간 것만 다름.
pooled = []
for h in range(0, valid_H, strides):
pooled_ = []
for w in range(0, valid_W, strides):
pooled_.append(np.max(image[h:h+pool_size, w:w+pool_size])) # A / 이 부분도 4X4 > 2X2로 풀링하는 그림 생각하면서 과정을 이해하려고 해야 더 쉽다. 하나씩 꺼내온다고 생각해!
pooled.append(pooled_)
return pooled# 공부 -- 근데 위 함수에서 append하는게 어떻게 2X2 매트릭스가 되는거지? => 함수 뜯어서 돌려보자.
image = vertical_output
pool_size=2
strides=2
img_H, img_W = image.shape[0], image.shape[1]
valid_H, valid_W = img_H - (pool_size - 1), img_W - (pool_size - 1)
pooled = []
for h in range(0, valid_H, strides):
pooled_ = []
for w in range(0, valid_W, strides):
pooled_.append(np.max(image[h:h+pool_size, w:w+pool_size]))
pooled.append(pooled_)
len(pooled) # 169
a = np.array(pooled)
a.shape # (169, 299) # 아, 내가 풀링을 4x4에 2X2를 해서 2x2 행렬이 나온다고 풀링을 하면 풀링 차원 그대로 아웃풋이 나온다고 잘못 생각했었구나.. 338 / 2 = 169 오케이!vertical_maxpool_output = maxPooling2D(vertical_output)
horizontal_maxpool_output = maxPooling2D(horizontal_output)
fig, axes = plt.subplots(1, 2, figsize=(10, 20))
axes[0].imshow(vertical_maxpool_output, 'gray')
axes[0].set_title('Vertical Sobel Filter After MaxPooling')
axes[1].imshow(horizontal_maxpool_output, 'gray')
axes[1].set_title('Horizontal Sobel Filter After MaxPooling')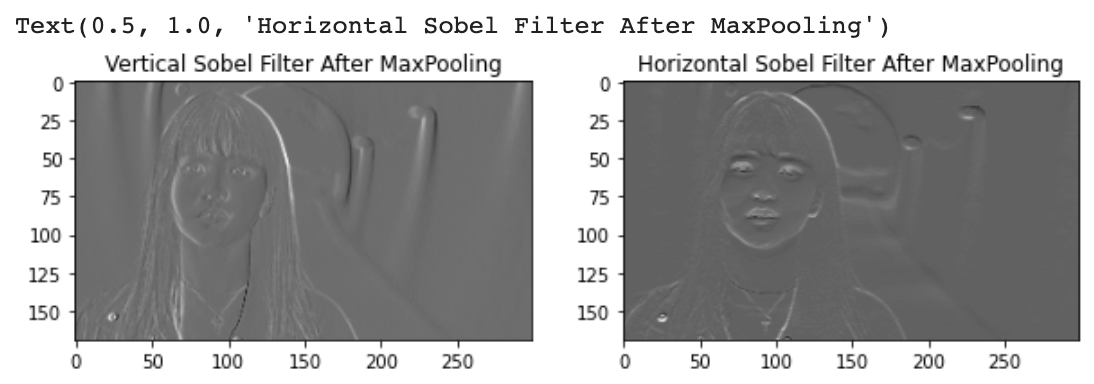
Assignment 2
케라스를 이용한 바이너리 이미지 분류 모델에 3가지 CNN 모델을 적용하여 보는 과제입니다. (데이터 다운로드)
- 산의 이미지(./data/mountin/)와 숲의 이미지(./data/forest/)를 분류하는 문제입니다.
산을 Positive (1)로, 숲 이미지를 Negative(0)로 레이블링 하여줍니다.
- 이 문제는 크게 두 가지인데, 1) 사전학습 모델을 통해 전이학습을 하는 것, 2) 내가 CNN 모델 만들어보기이다.
- 근데 모델링 자체보다 위 데이터 다운받은 다음에 데이터화 하는게 더 어려웠다ㅎ 그래도 재밌었다!
전이학습
[이미지 데이터 불러오기]
from keras.preprocessing.image import ImageDataGenerator
'''
메모)
- 파라미터 공식문서 참고 https://keras.io/ko/preprocessing/image/ (설명 잘 되어있음. 이것만 봐도 될 듯.)
- 그 외 레퍼런스 https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=baek2sm&logNo=221400912923
'''
# train_data
train_data_gen = ImageDataGenerator(rescale=1./255) # 정규화만 해서 불러온다. 여기 파라미터를 조정함에 따라 이미지 증강 효과도 볼 수 있는 듯 하다.
train_data_generator = train_data_gen.flow_from_directory('/content/drive/MyDrive/mountainForest/train', target_size = (256,256), batch_size = 32, class_mode = 'binary')
'''
- target_size에는 이미지 크기 넣으면 됨(256,256)이 디폴트긴 함. 크기 낮추는 쪽으로 이미지 조정해 가져올 수 있다는 의미로 생각하면 될 듯.
- batch_size = 이미지 데이터 원본 소스에서 한 번에 얼마만큼의 이미지 데이터를 가져올 것인지. (32가 디폴트임)
'''
# 이미지 잘 넘어왔는지 확인해보기
X_train, y_train = train_data_generator.next() # 위 생성된 것들 중 하나만 가져오겠다는 뜻이다. 그러니 아래 shape보면 알겠지만 배치사이즈만큼만 보이는 거임. 실제 모델에는 generator를 통해 생성된 배치들이 차례로 들어가며 학습이 이루어진다.
print(X_train.shape, y_train.shape)
plt.imshow(X_train[0])
# 라벨링 제대로 되었는지 확인하기
print('Train data label =', train_data_generator.class_indices)
#=> Train data label = {'forest': 0, 'mountain': 1}# Test_data
# train_data
test_data_gen = ImageDataGenerator(rescale=1./255) # 정규화만 해서 불러온다. 여기 파라미터를 조정함에 따라 이미지 증강 효과도 볼 수 있는 듯 하다.
test_data_generator = train_data_gen.flow_from_directory('/content/drive/MyDrive/mountainForest/validation', target_size = (256,256), batch_size = 32, class_mode = 'binary')
# 잘 넘어왔는지 체크
X_test, y_test = test_data_generator.next()
print(X_test.shape, y_test.shape)
print('Test data label =', train_data_generator.class_indices)
plt.imshow(X_test[0]) #=> 위와 같이 잘 떴음[모델링(전이학습)]
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
pre_trained_model = ResNet50(weights='imagenet', include_top=False) # include_top을 False로 하여 신경망층은 제외하고 가져옴.
# 시드 고정
np.random.seed(42)
tf.random.set_seed(42)
# 가져온 모델 layer의 가중치를 내 데이터로 새롭게 학습시키지 말아라.
for layer in pre_trained_model.layers:
layer.trainable = False
# 모델 설계하기 (squential로 안 쌓고 이렇게도 표현할 수 있구나). # 참고 https://www.tensorflow.org/tutorials/images/transfer_learning?hl=ko
x = pre_trained_model.output
x = GlobalAveragePooling2D()(x) # 데이터 Shape을 (None, None, None, 2048) 에서 (None, 2048)로 변화시켜주는 역할을 한다.
x = Dense(1024, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x) # 출력층 설계 부분
model = Model(pre_trained_model.input, predictions)
# 모델 컴파일
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# fit
model.fit(train_data_generator, batch_size=128, epochs=3)
# evaluate
model.evaluate(test_data_generator) # loss: 0.6188 - accuracy: 0.6564- 다 제출하고 다른 동기들 코드 살펴보니까 전이학습하니 나같이 저렇게 낮은 스코어가 나오지 않던데.. 내가 본 동기들 코드는 다 이미지 데이터 불러올 때 이미지 증강 처리까지 하던데 그 영향 때문인 것 같다.
- 아무튼
ImageDataGenerator파라미터 조절하면 이미지 증강 쓸 수 있다는 것도 기억하자.
CNN 모델 만들어보기
- 난 정말 간단하게만 만들었다. 성능이 잘 나와서 깜짝 놀랐다.
# 모델 설계
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
model = Sequential()
model.add(Conv2D(32, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 참고로 이진분류 문제에서 softmax로 잘못 지정하면 'ValueError: `logits` and `labels` must have the same shape, received ((None, 10) vs (None, 1))' 이런 오류를 만나게 된다.
# 모델 컴파일
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 학습
model.fit(train_data_generator,
batch_size=128,
epochs=3)
# evaluate
model.evaluate(test_data_generator) # loss: 0.2079 - accuracy: 0.9436 뭐야 얘가 훨씬 좋음5. 그 외
- 추가 학습 자료 (아직 못 본 것)
- 왜 CNN이 이미지 처리할 때 성능이 좋을까? 글
- EfficientNet 논문 리뷰 / MobileNet 논문 리뷰
- 이미지 증강 코드 구현은 필요할 때 레퍼런스 노트 참고하기.
Feeling
- 오늘은 이미지 처리 새로운 스프린트가 시작한 날이었다. 지난 스프린트 때 RNN, LSTM, 트랜스포머에 미리 뚜드려 맞았더니 그래도 오늘은 괜찮았던 것 같다.
- 실습할 때 이미지 데이터 불러오는게 어려워서 좀 당황했지만 여하간 실제로 이미지가 처리되는 과정을 보니까 너무 신기했다. 유툽 같은 곳에서 이런 기술 이용해서 서비스로 구현하는 것들 보면서 부러워만 했던 내가 실제로 이런 걸 해보게 되다니..ㅎㅎ 감개가 무량하다고 할 수 있다.
- 근데 생각해보니 이번 섹션 시간이 너무너무 빨리간다. 벌써 스프린트3고 이제 다음 주면 프로젝트 시작이라니..!! 끝까지 정신 바짝 차려야겠다.
