Key words
Segmentation(Semantic/Instance Segmentation, UpSampling), 객체 탐지/인식(Object Detection/Recognition)
오늘이 Warm-up 영상.
- 스탠포드 강의 영상인데, 8:31 ~ 32:44을 보고 Segmentation의 개념과 Upsampling에 대해 보았다. 설명이 clear해서 보기 좋았음.
- 오늘 노트에서는 Upsampling에 대해 Transpose Convolution만 다뤘는데, 이 영상에서는 Unpooling과 Max Unpooling에 대해서도 알아볼 수 있었다. 그리고 Transpose Convolution의 작동 구조에 대해서도 더 상세히 알아볼 수 있어서 좋았다.
1. Segmentation
시작하기에 앞서 오늘 배운 것의 의미에 대해서 강조해보고 싶다.
- 지난 금요일에 배운 CNN은 하나의 사진 > 하나의 레이블로 예측하는데 사용했다면, 오늘 배우는 Segmentation의 의미는 하나의 사진 내에 있는 각 요소들을 여러 레이블로 구분할 수 있다는 점에 있다. 이 점을 기억하고 앞으로 펼쳐질 내용을 보는 것이 중요하다고 생각한다.
Segmentation(분할)이란?
- 위에서 언급한 것과 같이, 하나의 이미지에서 같은 의미를 지니고 있는 부분을 구분하는 task를 말한다. 마케팅할 때 흔히 고객 특성에 맞게 segmentation한다고 할 때의 의미와 같이 생각해도 될 것 같다.

- 즉, 기억해야할 것은 이 segmentaion은 최소 분류 단위로 pixel 단위에서 레이블을 예측한다는 것이다. 그래야 이미지 내부의 각 요소를 구분할 수 있겠지! 이전에 이미지 단위로 레이블을 예측하던 것에서 더 깊이가 생긴 것이다. (이전에는 사진을 보고 개인지 고양인지 맞추는 것이었음)
- 이렇게!
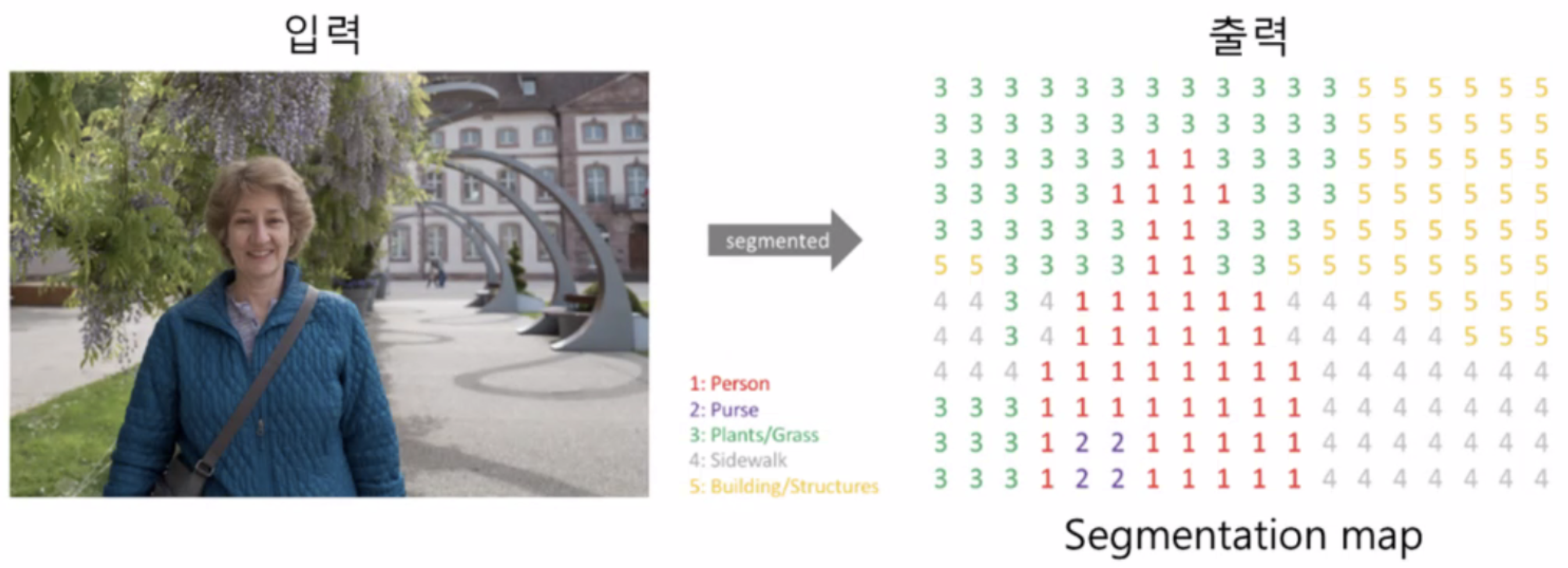
- 이렇게!
이 segmentaion에는 두 가지 종류가 있다. 어떻게 다른지는 아래 이미지를 보면 확 이해가 갈 것이다. 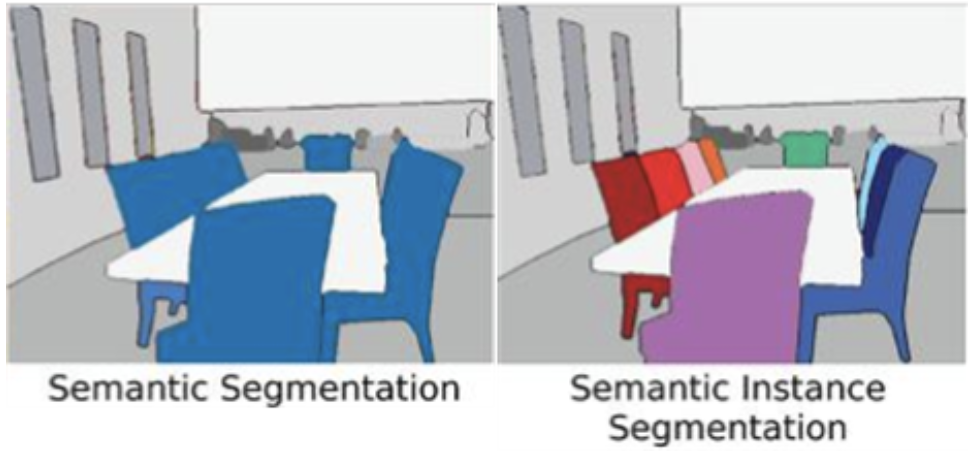
내 언어로 표현해보자면,
Semantic Segmentation: 의미적으로 같다면(=같은 레이블이라면) 동일하게 라벨링 한다.(Semantic) Instance Segmentation: 의미적으로 같아도 객체가 다른 경우 다르게 라벨링 한다.
이 중 오늘은 대표적인 Semantic Segmentation 모델인 FNN, U-Net에 대해서 공부해보았다.
2. FNN과 U-net
[FNN (Fully Convolutional Networks)]
- FNN의 핵심은 CNN 모델을 쓰되, 분류기 역할을 하던 완전 연결 신경망(Fully Connected Layer)을 합성곱 층(Convolutional Layer)으로 대체했다는 것에 있다.
- 무슨 말이냐면, CNN의 구조를 떠올려보면, 특성추출 부분에서 분류기로 넘어갈 때 데이터를 신경망에 넣을 수 있도록 Flatten해주었었는데, 이렇게 되면 뭐다? 이미지의 위치 정보가 무시된다는 것이다~
- 즉, 이미지를 segmentation 하기 위해선 픽셀 단위로 어디에 뭐가 있는지 위치 정보를 알고 있는게 중요할텐데, 그렇기 때문에 CNN의 특성추출 파트는 그대로 사용하되 분류 부분만 바꿔서 이미지 segmentaion에 활용하는 것이다.
- 아래 이미지는 FNN의 구조를 도식화한 것이다.
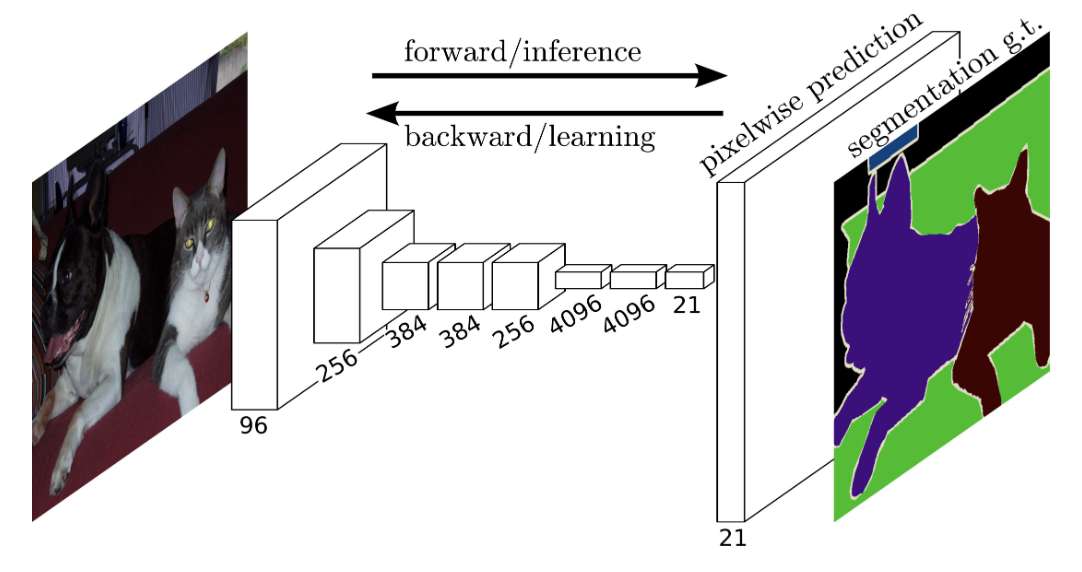
- 위 그림을 보면 일반적인 CNN처럼 특성추출 단계에서 Pooling을 하며 사이즈가 줄어들다가 마지막
Pixelwise prediction부분에 크기가 확 커지는 걸 볼 수 있다. 이 부분이 바로 기존의 CNN 분류기를 대체한 합성곱 층이다! - 여기서 나오는 것이 바로 UpSampling 개념이다!! 오늘 배우는 것의 핵심!
- 아래 슬라이드는 위 웜업 영상에서 가져온 것인데 특성 추출 과정을 거쳐 업샘플링을 하며 이미지 세그멘테이션을 하는 과정을 보여주고 있다.
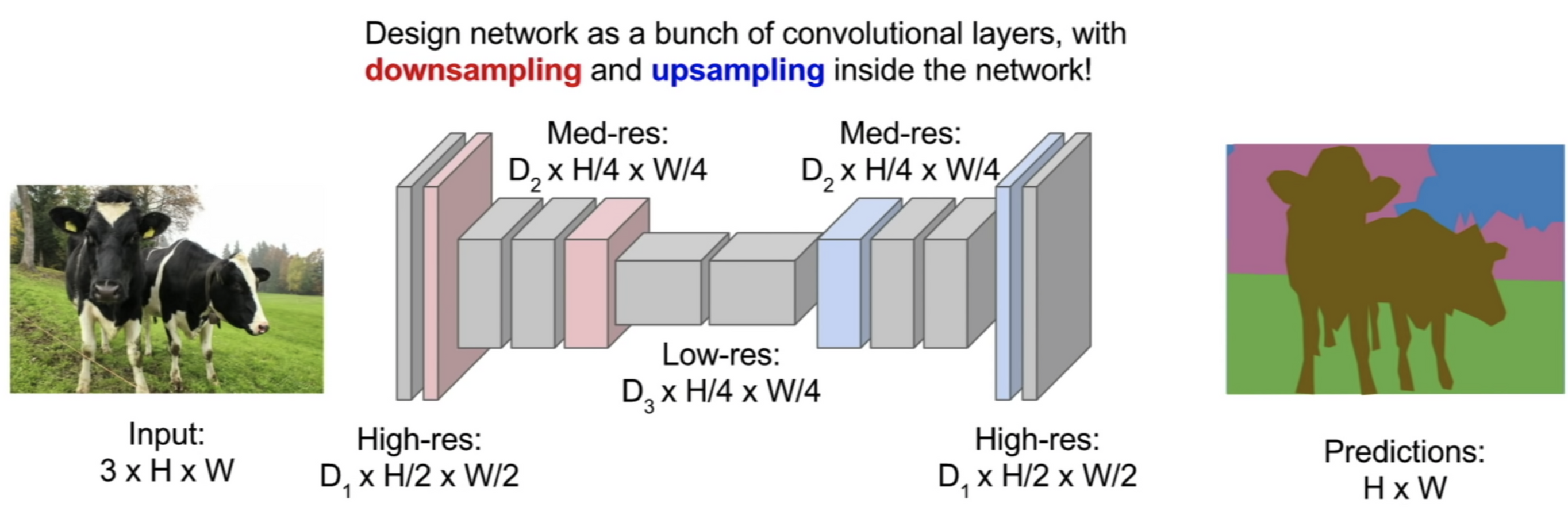
- 쉽게 생각하면 특성 추출을 하며 사이즈를 줄이는 걸 DownSampling, 픽셀 단위의 이미지 분류를 위해 사이즈를 다시 키우는 걸 UpSampling이라고 생각하면 된다. (웜업 영상에서는 Pooling하여 사이즈 줄이는 것의 반대라고 하여 Unpooling이라고도 하는 듯)
- 아래 슬라이드는 위 웜업 영상에서 가져온 것인데 특성 추출 과정을 거쳐 업샘플링을 하며 이미지 세그멘테이션을 하는 과정을 보여주고 있다.
- 앞서 말했다시피 Upsampling의 기법에는 Max Unpooling 등이 있지만 오늘은 Transpose Covoltion에 대해서 다뤄보았다.
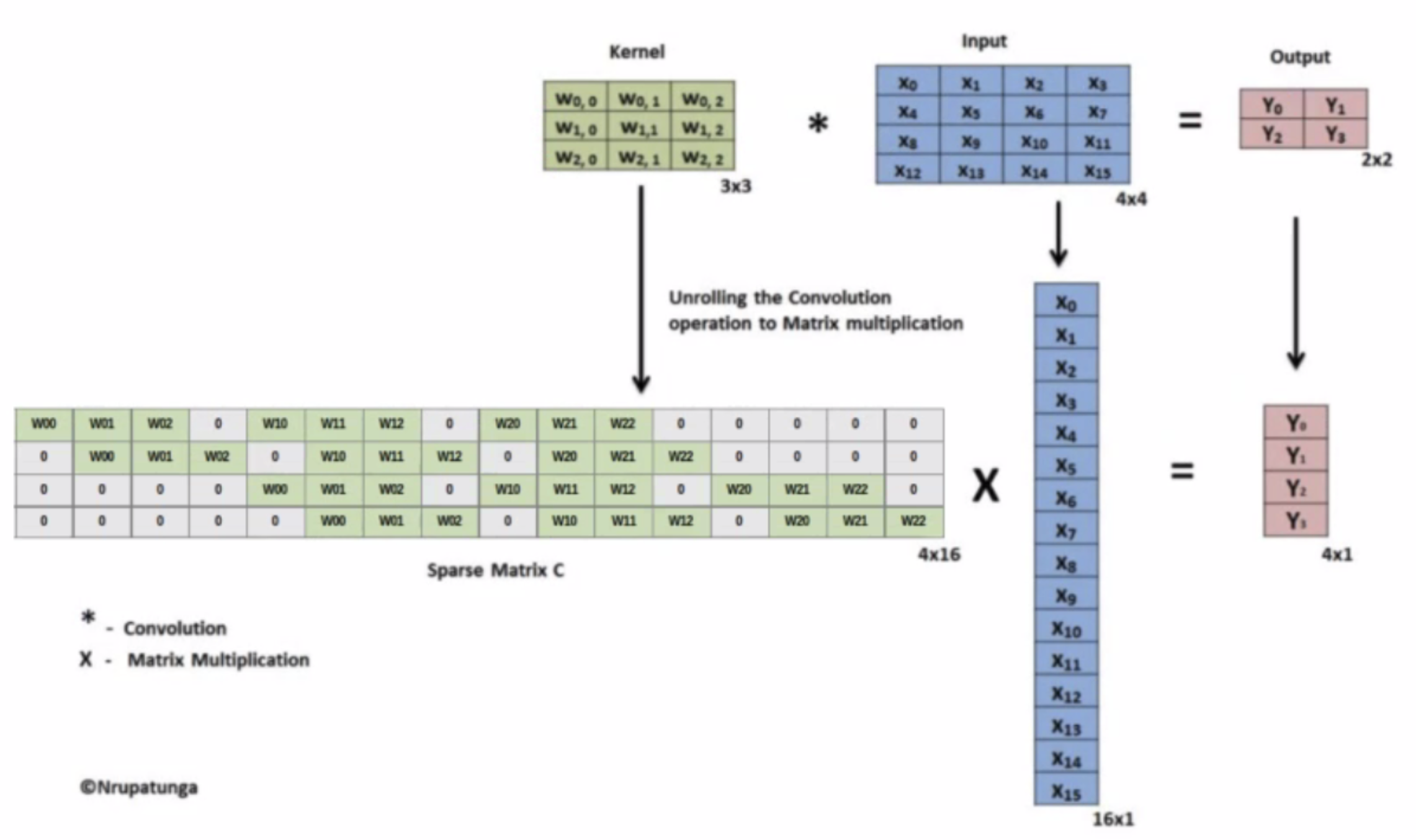
- Transpose Covoltion은 쉽게 생각하면 Convolution의 반대라고 생각하면 된다. 아래 이미지처럼 그냥 딱 생각하면 된다.
- Covolution
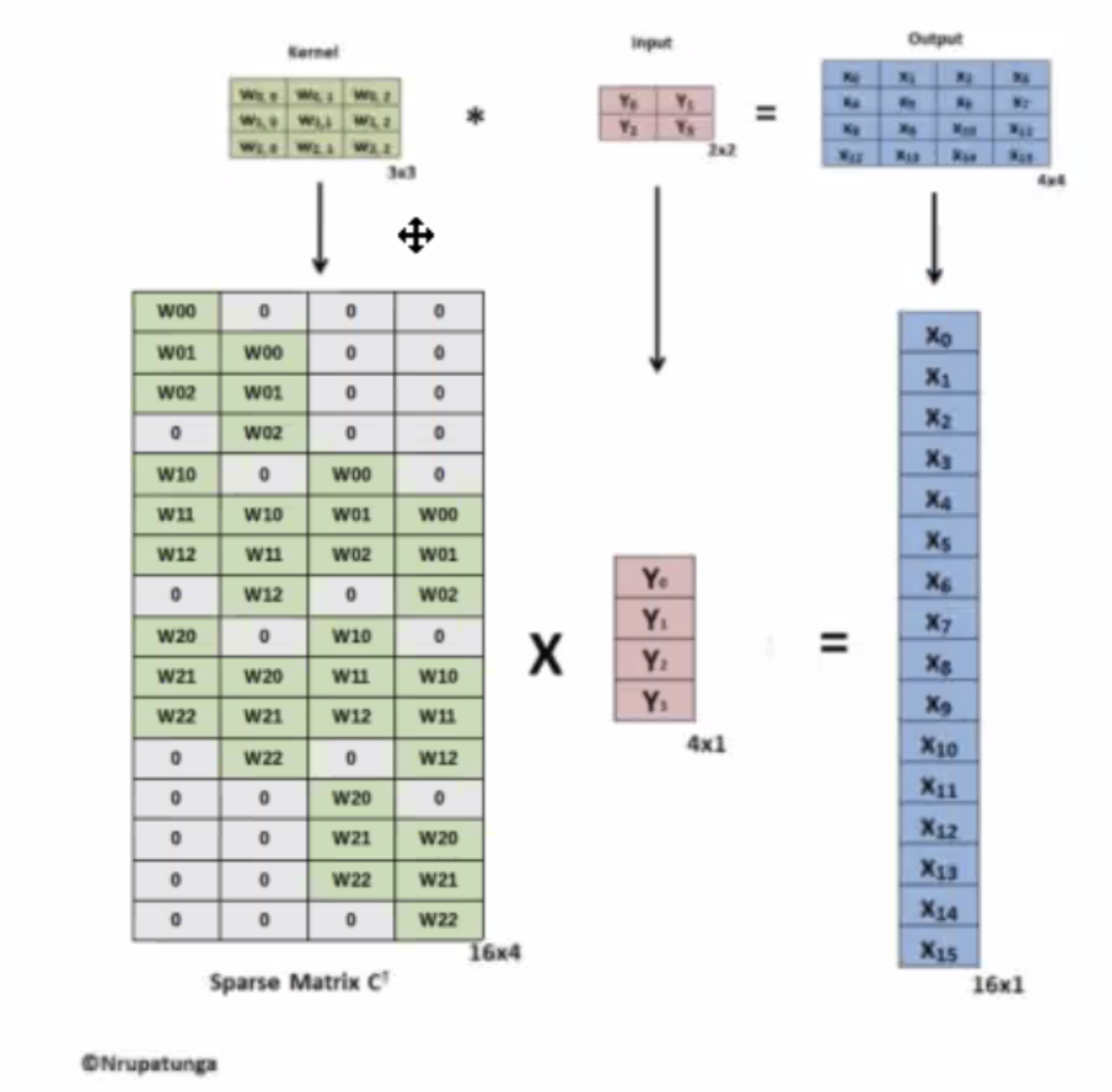
- Transpose Convolution
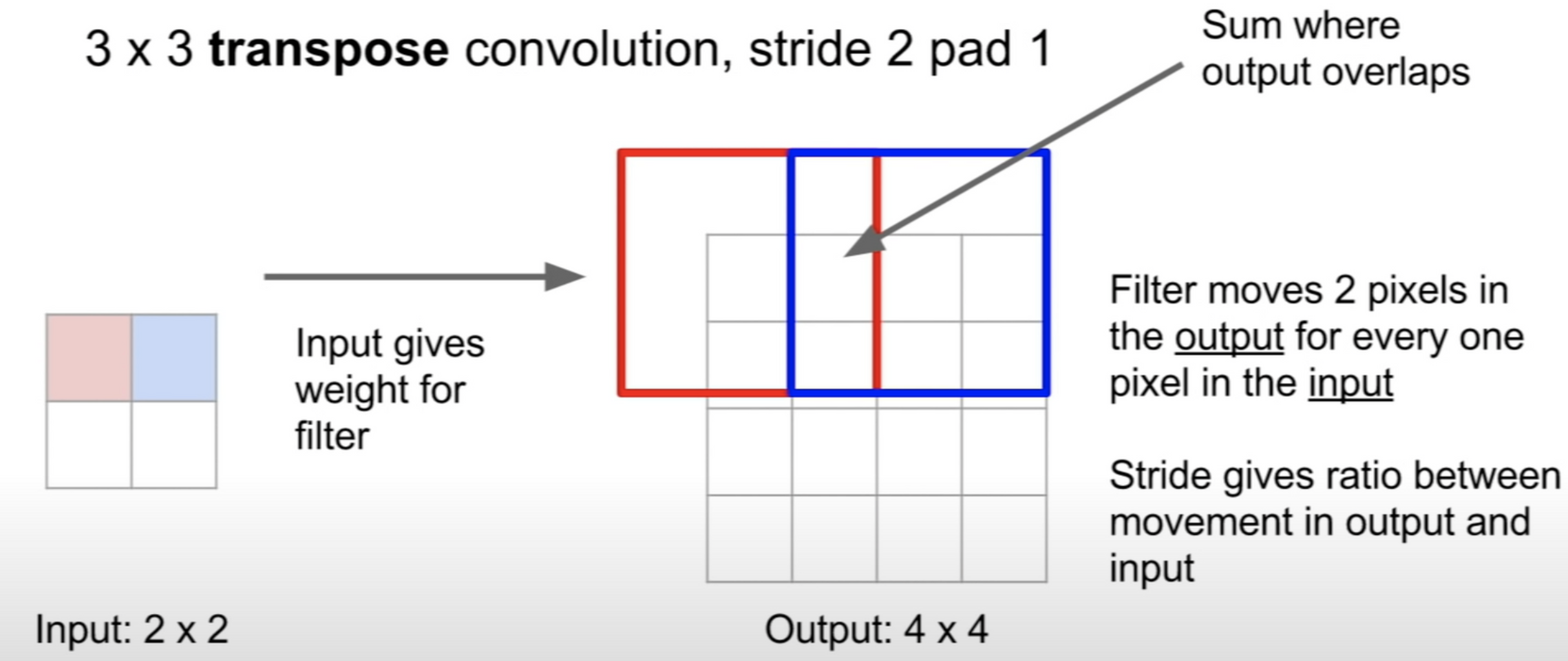
- 아래 gif는 2X2 이미지가 입력되었을 때 3X3 필터를 통해 Transpose Covoltion되는 과정을 보여주고 있다.

- 근데 이렇게만 보고 넘어가면 안된다! 필터가 훑으면서 이전에 훑은 곳과 Overlap되는 부분은 두 계산 값을 더한다는거 기억!
- 예를 들면 이렇게! 위 웜업영상 보면 이에 대해서 잘 설명해주니 필요하면 참고하자.
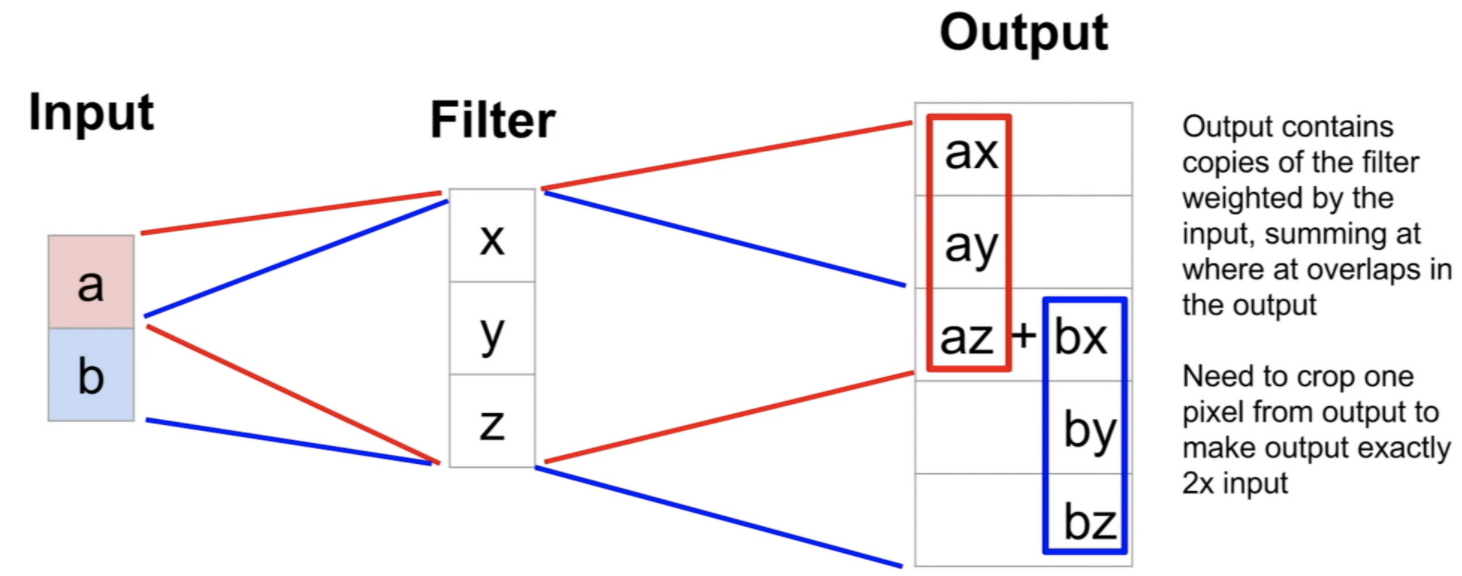
- 참고로 Transpose Covolution은
UpCovolution,Fractionally strided Convolution,Backward strided Convolution등으로도 부른다고 한다.
- Covolution
이렇게 Input > Down Sampling(Covolution) > Up Sampling(Transpose Covolution) > Output 순서로 이루어진다는 걸 기억하면 된다.
[U-net]
- U-net은 segmentation을 위한 대표적인 모델 중 하나라고 한다. 오늘 배운 것중에 제일 헷갈리는 친구였다. 구조를 도식화한 아래 이미지를 한 번 보자. 왜 이름이
U-net인지 알 수 있을 것이다.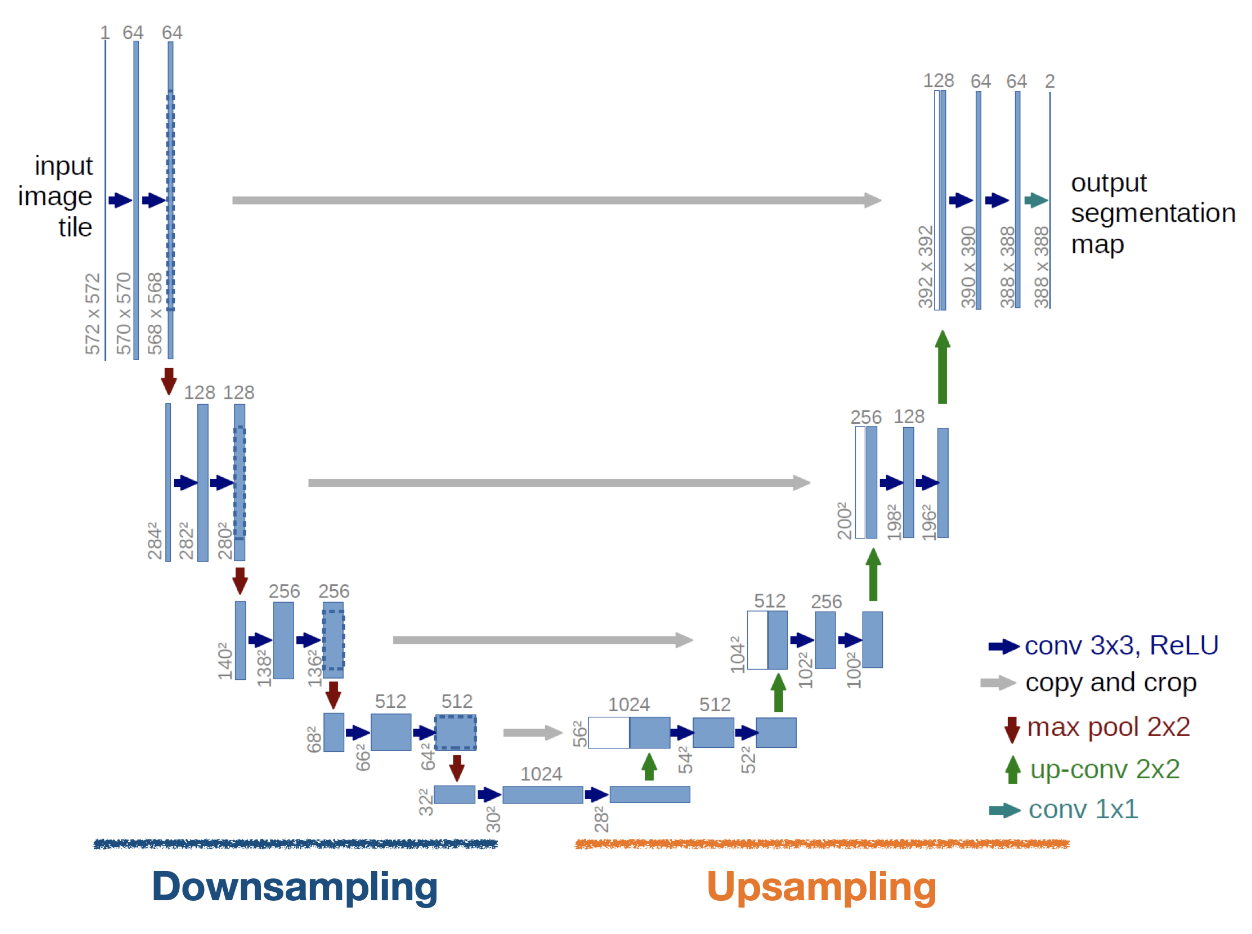
- U-net도 Down Sampling과 Up Sampling 파트가 있다.
- 참고로 각각인코더/디코더,수축경로/확장경로,Contracting Path/Expanding Path라고도 부른다고 함.
- U-net에서 중요한 건 아래 두 가지다.- Upsampling에서는 Convolution과 Transpose Convolution을 거치면서 원본 이미지와 비슷한 크기로 복원한다.
- Upsampling에서는 Downsampling 출력으로 나왔던 Feature map 을 적당한 크기로 잘라서 붙여준 뒤 추가 데이터로 사용한다. 위 그림에서 보면
Copy and Crop이라고 되어 있는 부분이다. 이건Skipped/Shortcut Connection이라고도 부른다. 이 개념은 이전에 배웠고 적어뒀기 때문에 의미는 기록 생략!- 여기서 Copy and Crop의 의미, 원본 이미지가 다운샘플링을 통해 크기를 줄였는데 그걸 다시 강제로 크게 키운다면 화질이 자글자글 깨지겠지! 그래서 원본 이미지의 가운데 부분을 떼어다가 자글자글 아웃풋에 적용해서 테두리의 선명도를 올린다 정도의 의미로 들었다. 선명한 위치 정보를 추가해준다!
- U-net의 디테일한 구조에 대해선 오늘 코드 실습 부분에서 자세히 알 수 있으므로 거기서 마저 적어두도록 하겠다.
- 참고로 위 이미지에서 업샘플링 다운샘플링에서 사이즈 다른거 볼 수 있는데, 이건 논문에서 convolution 거치면서 사이즈 작아지는거 방지하려고 미러링을 통해 사이즈를 늘려서 데이터를 넣었기 때문이라고 함. 오늘 실습 보면 그냥 똑같이 넣었음.
- U-net 모델에서는 패딩을 하지 않기 때문에 모서리의 정보가 잘리는 문제가 있지만 논문에서는 패딩을 하지 않는 이유에 대해 명확히 밝히지 않았다고 함. 세포 이미지를 다뤘던 도메인 특성이 담겨 있는 듯. 우리는 어차피 U-net을 그대로 가져다 쓰는 것이 아니라 구조만 차용하는 것이기 때문에 우리는 그냥 패딩을 하면 된다고 함.
3. 객체 탐지, 인식(Object Detection, Recognition)
- 용어 정리부터 하고 가자.
- 객체 탐지(Object Detection): 객체의 존재여부(+위치) 확인
- 객체 인식(Object Recognition): 객체가 무엇인지 확인.
- 하지만 일반적으로 객체 탐지 모델이라고 하면 Recognition 기능까지 수행하는 모델을 말한다고 한다.
- 객체 탐지/인식은 아래와 같은거 하는거다!
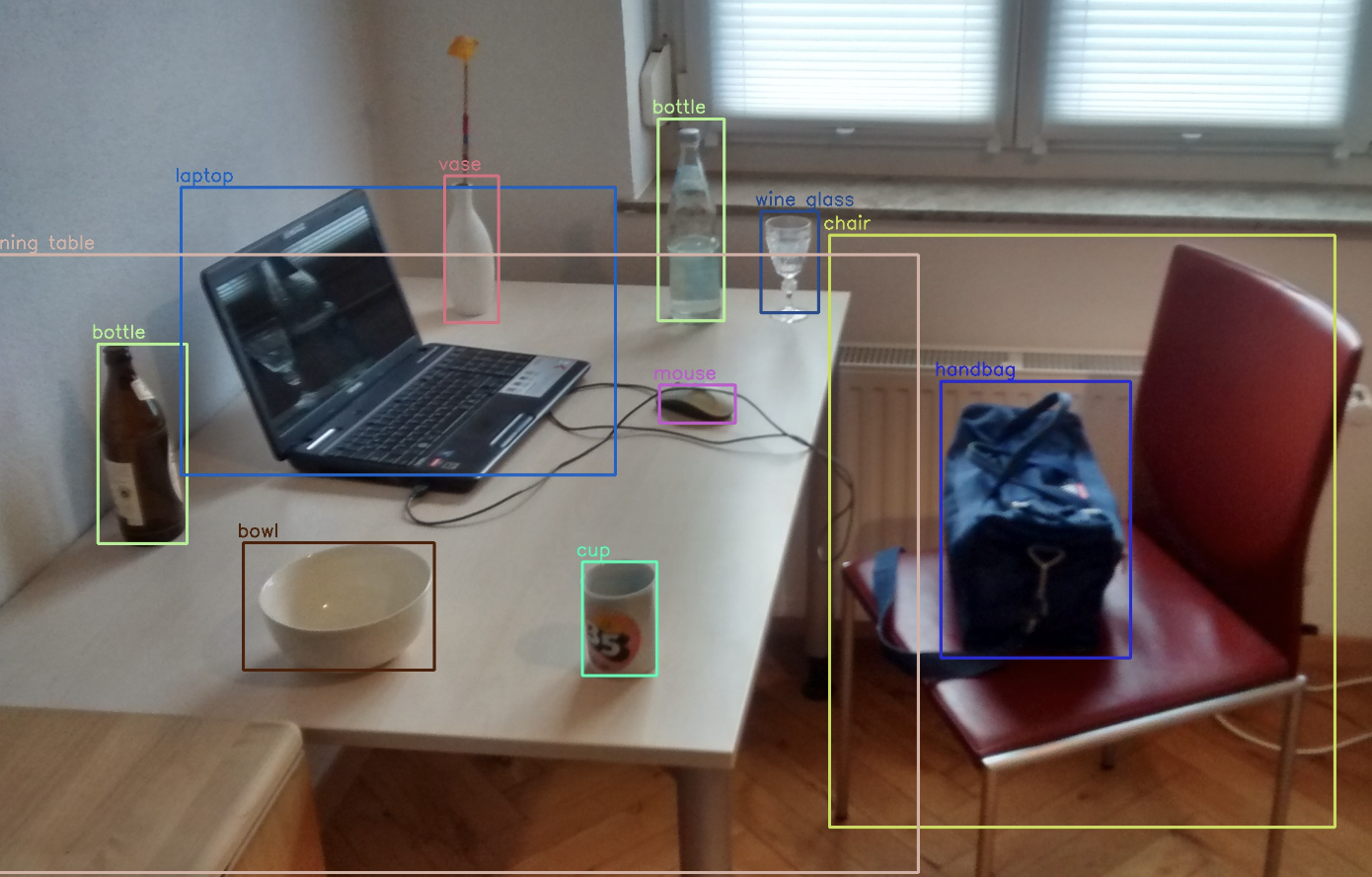
- 저기서 네모박스를
Bounding Box라고 부르는데, 이 박스를 그린 후 그 안에 있는 게 뭔지 레이블을 분류하게 된다!
- 저기서 네모박스를
- 그럼 이런 모델의 성능은 어떻게 측정할까? 그때 나오는게 바로
IoU(Intersection over Union)이다.- 이 그림보면 바로 이해갈 듯.
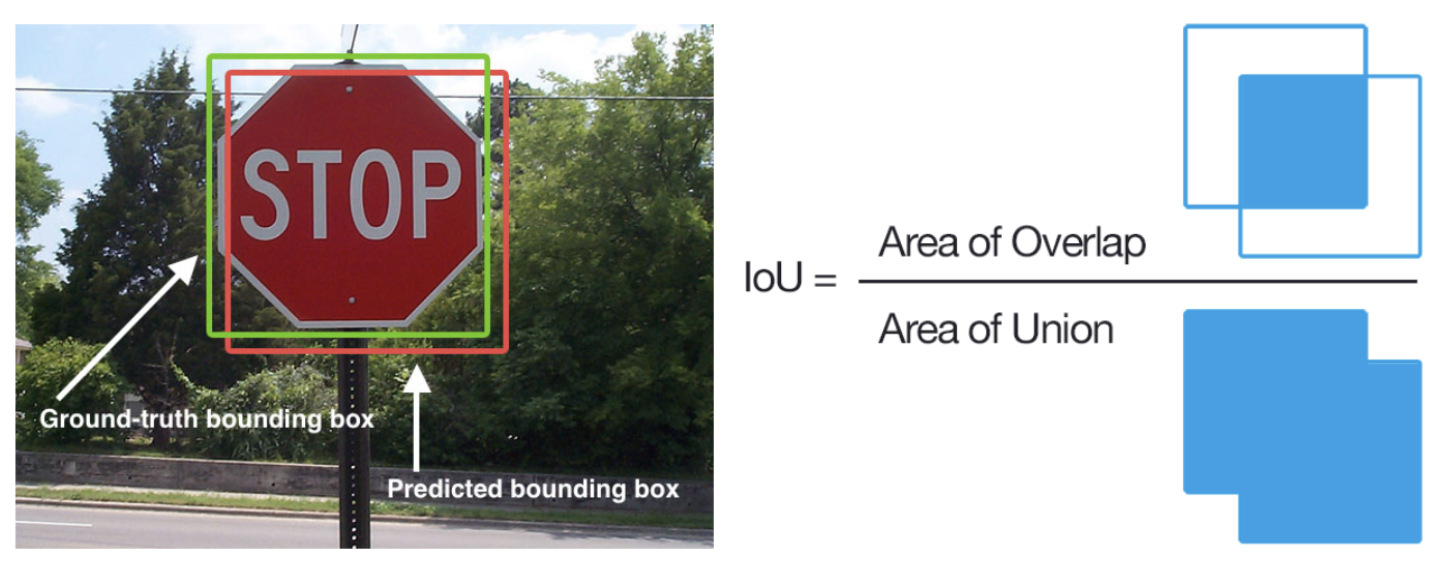
- 모델이 예측한 바운딩 박스 영역과 실제 바운딩 박스 영역이 얼마나 잘 겹치는지를 보는 것이다. 이렇게 되면 바운딩 박스가 지나치게 크게 잡히는 문제도 해결할 수 있다. (예를 들어 위 왼쪽 사진에서 그냥 이미지 크기만한 바운딩 박스 그려도 스탑 싸인을 감싸고 있는 거긴 하지만 우리가 원하는 건 그게 아니잖아!)
- 이 그림보면 바로 이해갈 듯.
[대표적인 객체 탐지 모델]
- 대표적으로 객체 탐지 모델은 아래와 같이 발전해왔다고 한다.
 엄청 많다.
엄청 많다. - 어떤 단계를 거쳐 분류가 진행되는지에 따라 2-stage 방식과 1-stage 방식으로 나눌 수 있는데, 오늘은 세부적인 코드보다는 개념만 살펴봤다.
- 2-stage 방식
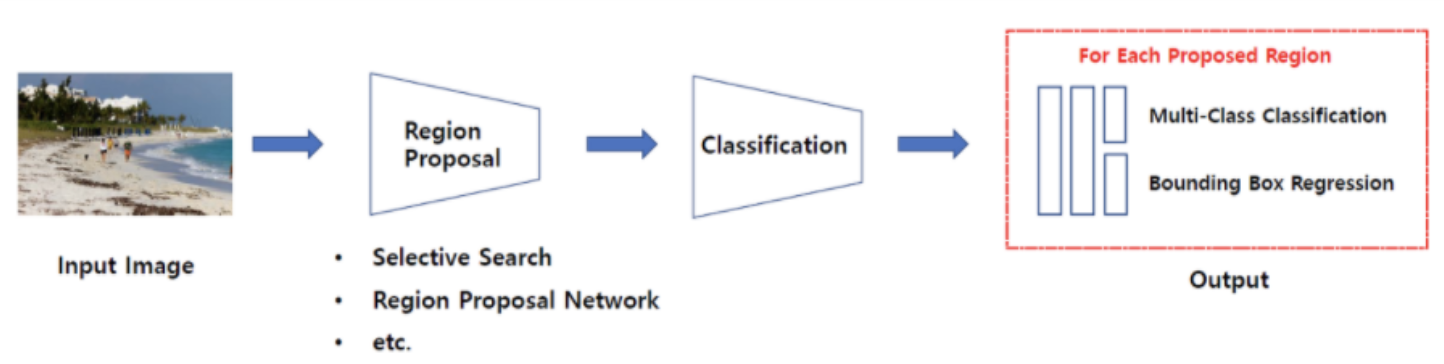
일련의 알고리즘을 통해 객체가 있을 만한 곳을 추천받은(Region Proposal) 뒤에 추천받은 Region, 즉 RoI(Region of Interest)에 대해 분류를 수행하는 방식입니다.라고 하는데 이것만 들어선 잘 이해가 안 갔고,- 대표적인 2-stage 방식 모델로는 R-CNN 계열(R-CNN, Fast R-CNN, Faster R-CNN 등)이 있다고 하는데 이 작동 순서에 대해서 적어본다.
- R-CNN 계열은 이미지가 주어지면 일단 그 이미지를 최대한 세분화해서 쪼개! -> Greedy 알고리즘을 통해 쪼개놓은 걸 덩어리로 좀 묶어! -> 바운딩 박스 그려봐! -> 다시 Greedy 알고리즘을 통해 더 묶어봐! > 바운딩 박스 그려봐! -> ... 라고 한다.
- 듣기만 해도 노가다의 느낌이 물씬나는데 실제로도 속도가 느린 모델이라고 한다.
- 1-stage 방식
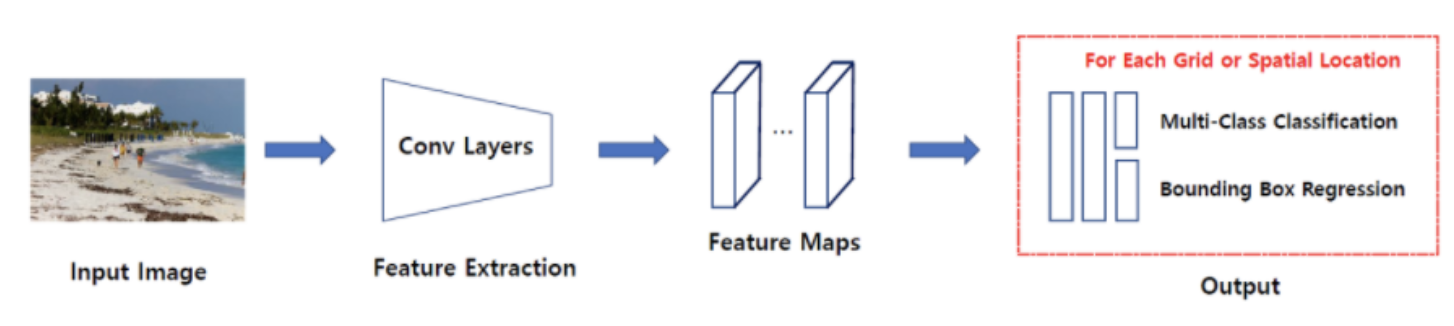
- 2-stage 방식처럼 특정 영역을 추천 받지 않는다. 그냥 입력 이미지를 Grid로 나눈 후, 바운딩 박스를 그리고 해당 공간에 객체가 있을 확률을 계산하며 분류를 수행하는 방식이다. 대표적으로는
SSD(Single Shot multibox Detector)계열과YOLO(You Only Look Once!)가 있다.
- 2-stage 방식처럼 특정 영역을 추천 받지 않는다. 그냥 입력 이미지를 Grid로 나눈 후, 바운딩 박스를 그리고 해당 공간에 객체가 있을 확률을 계산하며 분류를 수행하는 방식이다. 대표적으로는
여하간 이 둘에 대해서는 이 분야에 가야할 때 파보는 걸로..! 오늘은 일단 이런게 있구나 정도로 기억하자!
4. 실습한 것
Lecture Note에 구성되어 있는 U-Net모델에서 baseline 모델을 MobilenetV2가 아닌 Vgg16을 사용하겠습니다.
또한, 업샘플러 부분을 pix2pix가 아닌 직접,Conv2DTranspose를 사용해 구현하고 Sequential API가 아닌 함수형 API를 이용해보겠습니다.
U-Net을 구성하기 위해서는 vgg16 모델에서 다운샘플링할 때 꺼내온 5개의 레이어와 업샘플링할 때 레이어의 결과값의 형태가 같아야 합니다.
U-Net을 구성하기 위해 알맞은 A, B, C, D를 입력하세요.
- 오늘 노트에서 기억할 점은 U-net의 구조를 차용할 때, 즉 업샘플링과 다운샘플링을 할 때 다른 모델의 구조 일부를 가져다가 쓸 수 있다는 점이다. 신기하지 않은가!!
img_shape = (128, 128, 3)
# Down-Sampling
base_model = tf.keras.applications.VGG16(input_shape=img_shape, include_top=False) # include_top을 False로 해서 Unet의 인코더 부분만 이 모델을 통해 구현하겠다는 의미 기억하기!
down_stack=tf.keras.Model(inputs=[base_model.input],
outputs=[
base_model.get_layer(name='block5_conv3').output, # 뭘까 궁금해서 출력해봄. => shape=(None, 8, 8, 512)
base_model.get_layer(name='block4_conv3').output, # => shape=(None, 16, 16, 512)
base_model.get_layer(name='block3_conv3').output, # => shape=(None, 32, 32, 256)
base_model.get_layer(name='block2_conv2').output, # => shape=(None, 64, 64, 128)
base_model.get_layer(name='block1_conv2').output # => shape=(None, 128, 128, 64)
]) # => down_stack = model이라는 점 기억!
'''
[궁금증]
layer name='block5_conv3'으로 지정하고 output 뽑으면 알아서 shape이 정해져 있는데, 모델 내에 우리가 가져다 쓸 수 있는 layer들이 정해져있는 건가?
VGG16은 구조적으로 정해져있는 모델이니 그 요소를 뽑아온다는 의미로 생각하면 되려나..? => 질문 예정.
'''
down_stack.trainable = False
i=tf.keras.Input(shape=img_shape)
out, out1, out2, out3, out4 = down_stack(i) # => out부터 차례로 shape=(None, 8, 8, 512), (None, 16, 16, 512) ...
# Up-Sampling하며 쌓아가기. (이걸 함수형 API라고 부르는거였구나)
A = 512 # A
B = 256 # B
C = 128 # C
D = 64 # D
'''
[기록]
upsampling은 downsampling의 반대이므로 그런 과정으로 넣어야할 순서를 생각하면 될 것 같다.
예를 들어,
A. downsampling의 마지막 블록이 (8,8, 512)였던 것을 (16,16, 512)로 늘린다.
B. (16,16,512)였던 것을 (32, 32, 256)으로 크기를 늘린다. (사이즈를 2배 늘리면서 채널이 1/2된 것으로 이해했는데 맞을 듯..? 이건 질문 드려볼 예정.)
참고로 Output shape 뽑을 때 'None' 나오는 건 bath_size가 variable 하다는 뜻. 모델 fit할 때 batch_size 직접 지정해주니 이렇게 모델 설계 단계에서는 직접 지정 안하는 것으로 이해하면 될 것 같다.
이 자료 참고할 것. https://stackoverflow.com/questions/47240348/what-is-the-meaning-of-the-none-in-model-summary-of-keras
'''
out = tf.keras.layers.Conv2DTranspose(A, 3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out1]) # concat. 왜 out과 out1이 더해지는지는 unet 구조 이미지 생각해보면 된다. out이 맨 아래 결과였는데 그걸 한번 올린게 바로 윗줄 Out이고 그러면 인코더의 out1과 같은 레벨이 되는거지!
out = tf.keras.layers.Conv2DTranspose(B, 3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out2])
out = tf.keras.layers.Conv2DTranspose(C, 3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out3])
out = tf.keras.layers.Conv2DTranspose(D, 3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out4])
out = tf.keras.layers.Conv2D(3, 3, activation='lelu', padding='same') (out)
out = tf.keras.layers.Dense(3,activation='softmax')(out)
# Final
unet_model = tf.keras.Model(inputs=[i], outputs=[out])- model summary는 참고!
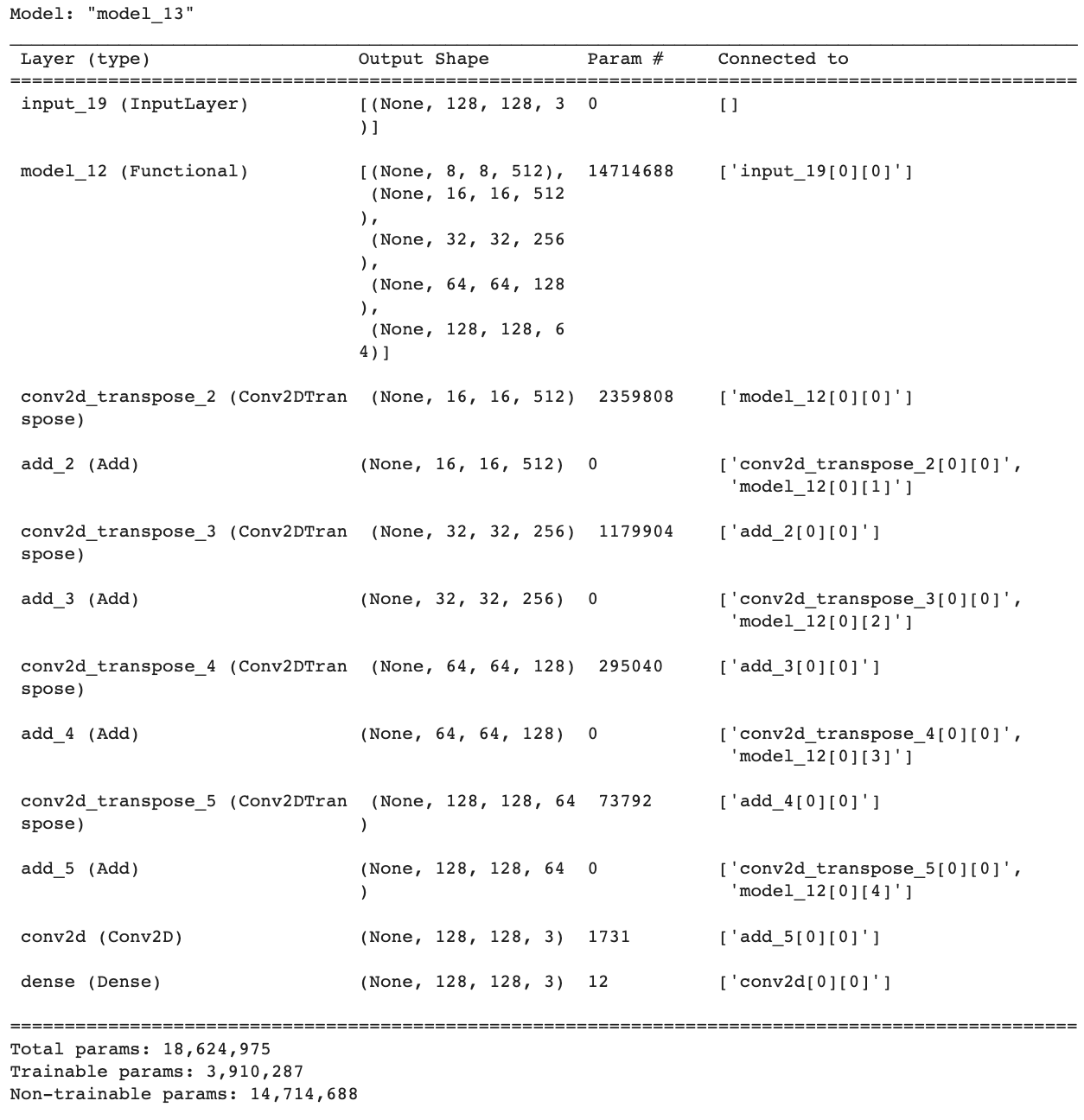
위 실습을 하며 질문했던 것과 받은 답을 내 언어로 정리한 것은 아래와 같다.
- 사이즈가 (None, 128, 128, 3)에서 (None, 128, 128, 64)가 된다는 의미가 정확히 뭔지 궁금합니다. 그리고 다시 (None, 64, 64, 128 )가 된다는 것두요. 채널이 RGB 3개에서 64개의 레이블로 늘어난다는 의미인가요?
- 원래 RGB 데이터 다룰 때 3개의 커널(=하나의 필터)로 하나의 피쳐맵을 냈었는데, 필터 개수 정할 수 있었잖아. (금요일에 봤던 그림!) 만약 32개 필터를 쓰기로 했다면 피쳐맵이 32개가 나오는 거다. 그러면 (128, 128, 32)처럼 되는거임. 그걸 다시 (64, …)로 돌렸다면 32개의 커널을 가진 필터 64개가 돌면서 64개의 피쳐맵을 뱉게 되는거임.
- 유넷 모델의 summary를 보면 shape이 (None, 128, 128, 3) 이런 식으로 나오는데 여기서 None은 bath_size가 variable하다는 의미로 알고 있습니다. model을 fit 할 떄 batch_size를 지정해주기 때문에 모델 설계에서는 이렇게 두는건가요?
- 이 대답은 정답이 70% 정도 맞다고 함. 여기서 None은 데이터의 갯수다. 모델 설계할 때는 틀만 짜두는거니까 None으로 나오는거라고 함.
- 코딩과제 다운샘플링할 때 layer 이름을 'block5_conv3' 등으로 지정하는데 output 출력해보면 shape이 (None, 8, 8, 512)식으로 그냥 나오더라고요. 다운샘플링 때 쓰는 모델 내에 저희가 가져다 쓸 수 있는 Layer 이름과 output이 정해져있는건가요?
- 맞다고 함. VGG 모델의 특정 레이어를 뽑아서 쓰는거다. VGG 모델 서머리 돌려보면 다 확인할 수 있다고 함.
- 추가 질문) 근데 저렇게까지 VGG 레이어마다의 쉐입 확인해서 코드에 넣을거면 그냥 제가 원하는 쉐입만 output에 직접 입력하는게 더 간단하지 않나요?
- 더 편한대로 하면 된다고 함. 내 생각에는 그냥 이렇게 일부 모델 구조 가져다가 쓸 수 있다는거 배우는 의미가 있는 듯?
Feeling
- 오늘은 U-net 빼고는 이해하기 어려운 내용은 없었다. 근데 U-net도 실습할 때 코드 뜯어보면서 보니 어느 정도 이해는 간 것 같아 다행이다.
- 시간이 정말 너무 빠르다. 이제 벌써 2일만 더 하면 스챌이고 섹션4 프로젝트라니.. 이번 딥러닝 섹션은 유난히 더 빨리 가는 것 같다. 정신 바짝 차려야지.
- 이번 섹션의 공통된 점이라고 느끼는게, 하루하루 배우는 것들이 정말 어려운 내용인데 너무 깊이 들어가지는 않고 쓱쓱 분야별로 치고 나가며, 어떠어떠한 것들이 있구나~를 보여주고 맛본다는 의미가 다른 섹션에 비해 더 큰 것 같다는 것이다. 즉, 내가 어떤 분야에 관심이 있는지 알아보고 나중에 그 분야에 들어가야겠다고 생각하면 진짜 몰입하며 파봐야한다는 것이다. 나에겐 그런 것이 어떤게 있을까? 딥러닝 엔지니어로 갈 수 있을까? 가고 싶을까? 고민고민!
