Sound Classification - 1) PANNs
0

PANNs : Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition 리뷰
CV와 NLP에서 Large-scale dataset을 활용한 Pretrained 모델이 좋은 일반화 성능을 보임. 그러나, Audio분야에선 관련 연구가 제한적. 이런 문제를 Audio 분야에서 해결하고자 Large-scale Audioset을 활용한 Pretrained 모델을 제안.
1. Introduction
- CV : ImageNet dataset을 활용한 여러 Image Classification system이 존재
- NLP : Wikipedia와 같은 large-scale 기반 데이터셋으로 여러 language model이 존재
- Audio : AudioSet - 527개의 클래스로 구분된 약 5,000시간 이상의 데이터셋이 존재하나, Pretrained CNN모델로 추출된 embedding features에 관한 다수 연구가 존재. 이렇게 pre-extracted embedding features를 이용한 시스템은, audio recordings와 같은 테스크에 optimal하지 않을 수 있다.
그러므로, raw AudioSet을 활용해, 다양한 분야의 audio 문제를 해결하도록 transferred가능한 모델을 제안.
2. Audio Tagging Systems
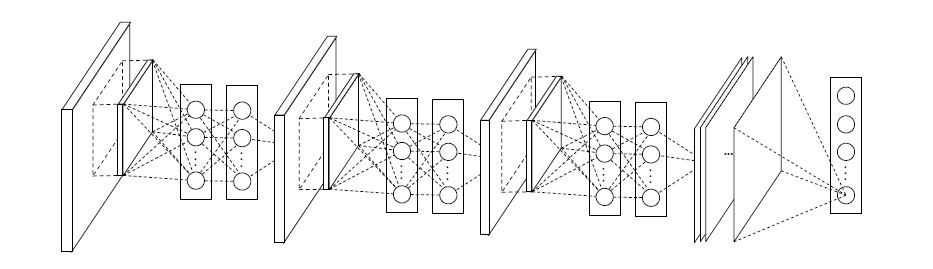 Network-In-Network 구조
Network-In-Network 구조
# 모델의 성능의 좋다, 나쁘다는 '비교'의 대상이 있어야 함.
# 해당 논문에선 여러 비교 대상이 되는 여러 모델을 제작하고 제안된 모델과 성능 비교를 함.
1) Conventional CNNs
- 일반적이 CNN 구조 : CNN + BN + ReLU xN > FC
2) ResNets
- ResBlocks 구조 : ResBlocks or BottlenectBlocks > Global Pooling > FC 구조
3) MobileNet
- MobileNet 구조 : MobileNet Blocks > GlobalPooling > FC 구조
4) One-dimensional CNNs
- LeeNet형태를 residual blocks 형태로 대체한 구조
3. Wavegram-CNN Systems
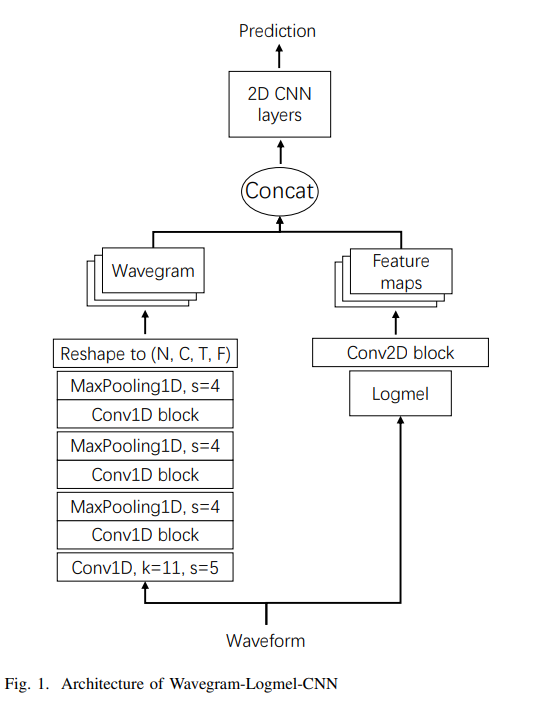 Wavegram--Logmel-CNN systems
Wavegram--Logmel-CNN systems
-
Left Side - 시간도메인
1. Conv1D, k=11, s=5 : Waveform의 input size를 줄여, 메모리 사용을 낮추는 효과
2. Conv1D block with polling : 특징추출 및 다운샘플링 -
Right side - log-mel spectrogram
1. Logmel : Waveform을 Log-mel spectrogram으로 변형
2. Conv2D block : 특징 추출 -
이 두 output [ 시간-도메인(wavegram)과 log-mel spectrogram ]을 결합하고, CNN block으로 특징을 추출해 예측에 이용
4. Data Processing
- Data Balancing : AudioSet의 데이터 불균형문제로 인해, 미니 배치의 클래스를 대략적으로 균등하게 샘플링
- Data augmentation
A. Mixup - augment a dataset by interpolating both the input and target of two audio clipsB. SpecAugment - frequency masking and time masking.
5. Result
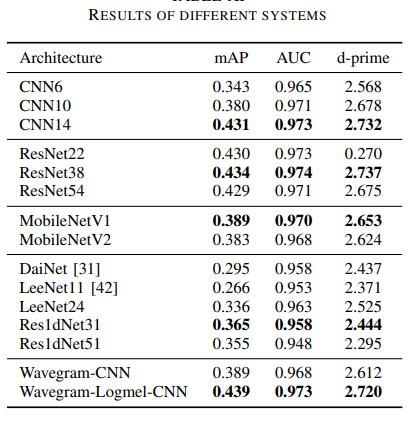 Results of different systems
Results of different systems
- 위 결과와 같이 Wavegram-Logmel-CNN이 우수한 성능을 나타냄.
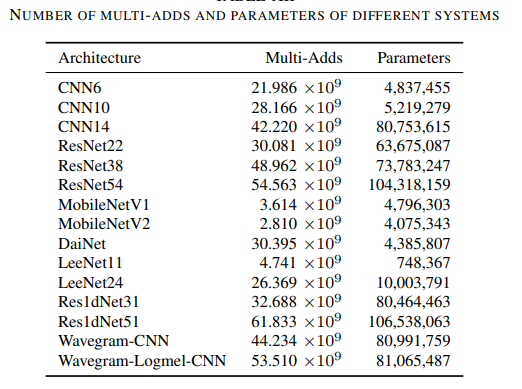 Number of Multi-adds and parameters of different systems
Number of Multi-adds and parameters of different systems

Idea to code