앙상블(Ensemble)
앙상블 학습은 여러 개의 모델을 생성하고, 예측을 합성하면서 정확한 예측을 하는 방법
단일 모델을 사용하는 것이 아니라 여러가지 모델을 합성하는 방식이다.
앙상블에는 보팅, 배깅, 부스팅 추가로 스택킹의 방식이 있지만 강의에선 배깅과 부스팅의 설명만 들었으니 먼저 배깅과 부스팅에 대한 내용을 정리하면서 복습 후 나머지 두 가지를 추가로 작성할까한다.
배깅(Bootstrap AGGregatING, Bagging)
RandomForest
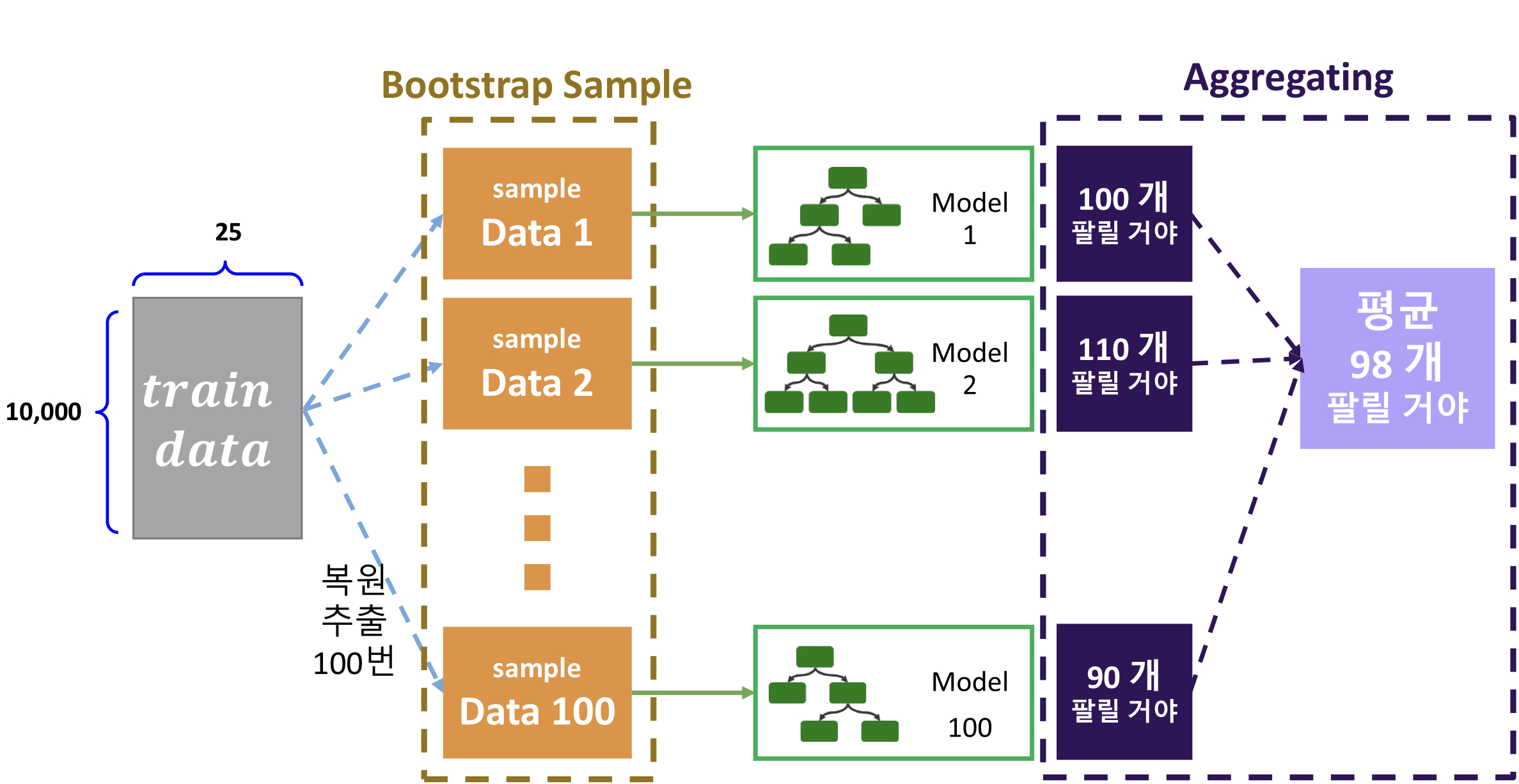
대표적인 배깅 방식으로 랜덤 포레스트 알고리즘을 들 수 있다.
랜덤 포레스트 알고리즘에는 2가지 랜덤 샘플링(Bootstrap)과 집계(Aggregating)가 사용된다.
- 데이터(Train data, Row) 샘플링
- 전체 학습용 데이터 셋을 무작위로 추출
- 변수(Feature, Column) 샘플링
- Tree에서 가지를 나눌 때(Split) 기준이 되는 변수(Feature)를 랜덤하게 선정
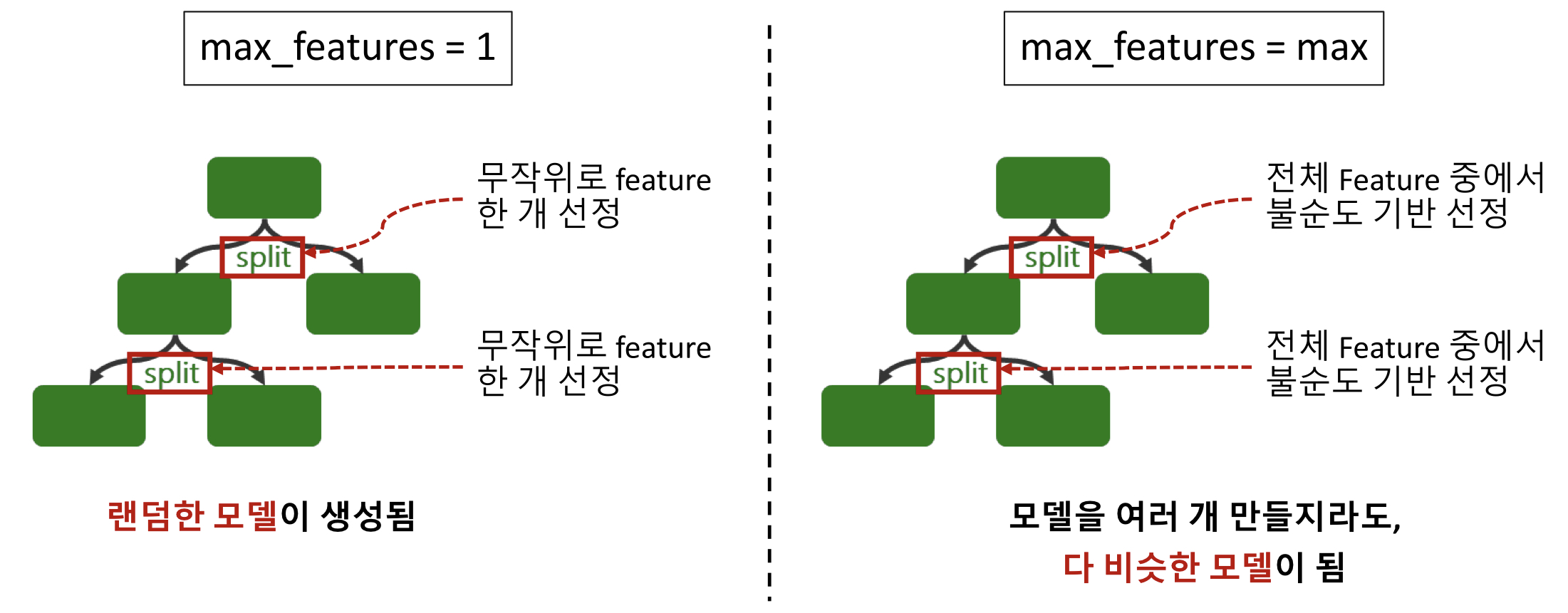
1. 무작위로 선정된 n개의 변수 (하이퍼파라미터: max_features)
2. 정보전달량이 가장 높은 변수 선정- 랜덤하게 생성된 n개의 의사 결정 나무(Decision Tree)에서 예측한 값을 집계
- 회귀 모델 : 예측 값의 평균 값 반환
- 분류 모델 : 다수결 투표 후 분류 값 예측
- 랜덤하게 생성된 n개의 의사결정나무 (하이퍼파라미터: n_estimators)회귀 모델의 경우 평균값을 사용하고, 분류 모델의 경우 과반수 투표를 통해 결과를 집계한다.
부스팅(Boosting)
- 여러 개의 트리 모델을 결합해서 오차를 줄이는 방식
- 모델(tree)의 개수에 따라 성능이 달라짐
Gradient Boost
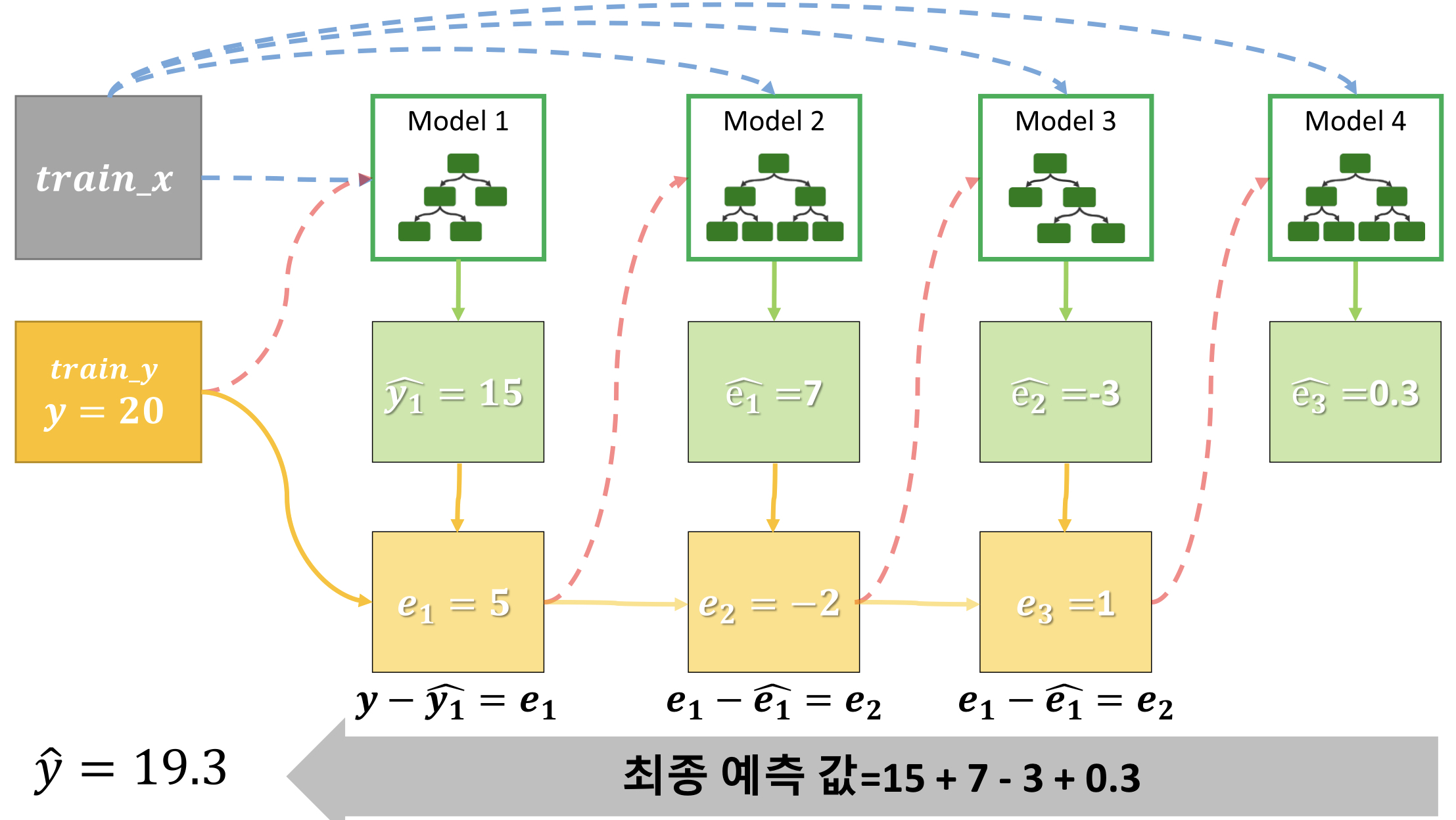
이전에 생성한 모델과 실제 값의 오차 만큼을 해결하기 위한 모델을 반복 생성하여 오차를 줄여나가는 방식. 대표적으로 XGBoost와 LightGBM 등이 있지만 XGBoost만 설명한다.
부스팅 방식은 순차적으로 모델을 생성-예측-생성(오차 수정)-예측을 반복하므로 속도가 느리다.
XGBoost
하이퍼파라미터
- learning_rate: 가중치 비율
- max_depth: Tree 모델의 depth 제한
- n_estimators: 모델의 생성 횟수(iteration 횟수)
- subsample: 샘플링 비율
- colsample_bytree: 모델 생성 시 사용되는 변수(feature)의 비율
부스팅 - XGB의 원리와 장단점
- 여러 개의 Tree를 순차적으로 생성하여 예측
- 오차를 줄이는 방식으로 모델(Tree)를 반복 생성한다.
- 학습 데이터 셋에 대해 오차를 줄이는 방향으로 학습을 진행하는 만큼
-> 속도가 느리다 : 순차적으로 학습함
-> 과적합 위험이 있음 : 학습 데이터를 기준으로 오차를 줄여나가는 학습을 함

기술을 공부하는 기술자