회귀 모델 (선형 회귀, 로지스틱 회귀)
AIC와 BIC
선형 모델링에서 많은 변수의 채택은 다중공선성의 문제가 발생할 가능성이 높아지기 때문에 선형 모델을 선택할 때 모델의 복잡도 또한 모델링을 할 때 고려해야한다.
모델이 Train Set을 잘 설명할 수 있으면서 모델에 대한 과적합이 되지 않도록 주의해야한다.
선형 모델링 적합도와 독립 변수(feature)가 필요 이상으로 채택되는 것을 방지하도록 설계된 통계량은 AIC와 BIC가 있다.
- 두 통계량 모두 값이 작을수록 좋은은 모델
- 예측을 위해선 AIC, 데이터의 분포나 변수 증감에 민감한 데이터를 다룰 때는 BIC가 적합하다는 의견이 있음
변수 선택법(전진선택법, 후진소거법)
통계량(데이터 예측에 적합한 AIC 선택)
- 전진 선택법
- AIC 값이 가장 작은 독립변수(feature)를 선택하여 모델 회귀 모델 생성
- 남은 변수 중에서 AIC 값이 가장 작은 모델을 생성하는 변수를 선택
- 단, 앞의 모델의 AIC 보다 작아야함.
- 후진 소거법
- 전진 소거법의 반대로 진행
- 가장 AIC감소가 낮은 변수부터 제거
Hyperparameter 튜닝
KNN, SVM, Decision Tree(의사결정나무) 모델 등 모델링에 사용되는 변수를 직접 통제하는 모델의 성능 튜닝방법
튜닝하는 방법에 왕도나 정답이 없기 때문에 사용자의 많은 지식과 경험, 다양한 시도가 중요하다.
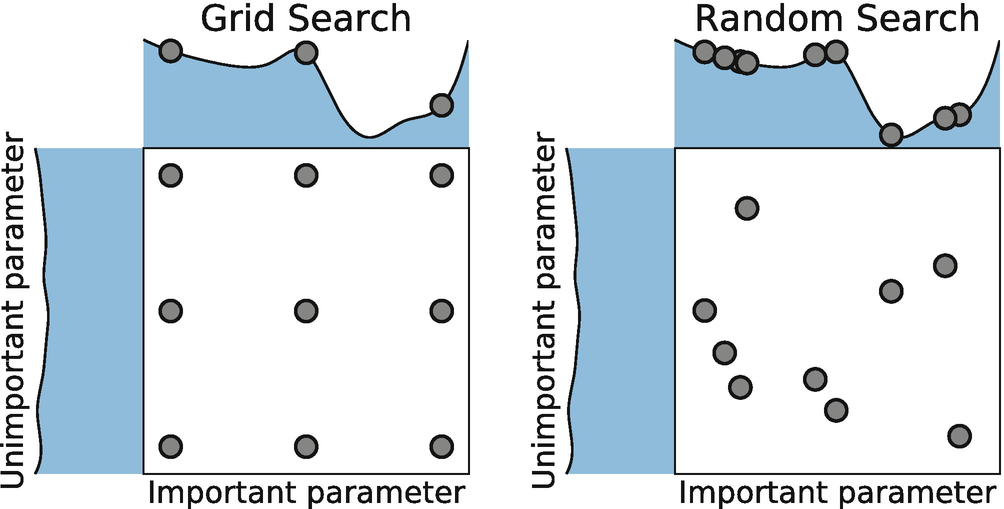
Grid Search
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
GridSearch(estimator = KNeighborsClassifier(),
# 하이퍼파라미터 튜닝을 하기 위한 머신러닝 모델 선택
param_grid = {'n_neighbors': range(2, 10, 2),
'metric': ['euclidean', manhattan']},
# 탐색 범위(Scope)와 간격(Step)을 정하는 부분
n_jobs=None
# 멀티 코어 프로세서의 경우 병렬 처리 여부 None = 1개 사용, -1 = 전체 사용
scoring=None,
# 성능 측정 방식, 기본은 estimator의 accuracy_score
cv=None)
# K-fold CV 값
- 값의 범위(Scope)를 지정, 일정한 간격(Step)으로 모든 경우의 수를 탐색, 가장 성능이 좋은 값을 선택
- 범위(Scope)를 넓게, 간격(Step)을 좁게 설정할 수록 최고의 성능을 찾을 가능성이 높아지지만 시간이 오래걸림
- 일반적으로 넓은 범위와 큰 간격으로 탐색 후 범위를 좁혀 나가는 방식으로 시간을 아낄 수 있다.
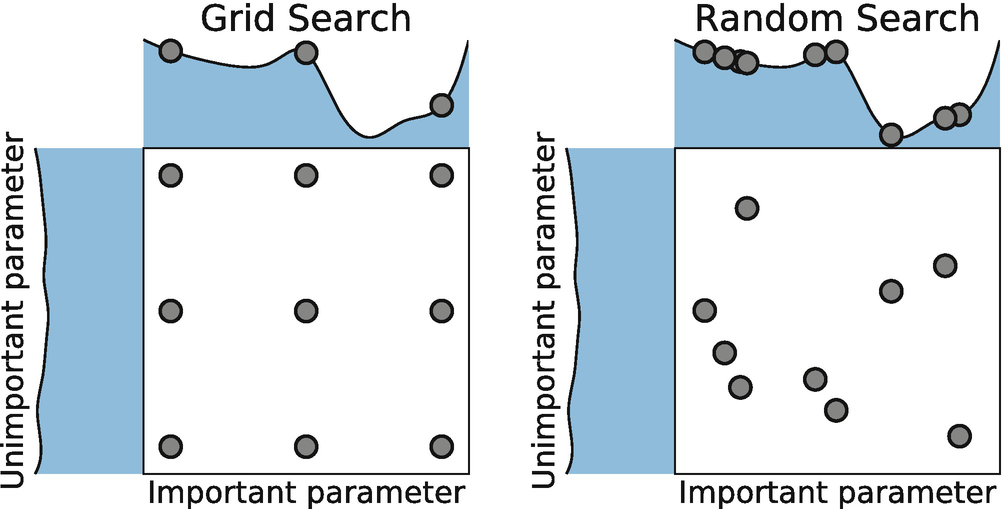
Random Search
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RandomizedSearchCV
RandomSearch(estimator = KNeighborsClassifier(),
param_distributions = {'n_neighbors': range(2, 10),
'metric': ['euclidean', manhattan']},
n_iter=10,
# 랜덤 샘플링 횟수
scoring=None,
# 성능 측정방식, 기본 값은 accuracy_score
n_jobs=None,
# 병렬 처리 여부, None = 1, -1 = 모든 코어 사용
cv=None)
# K-fold CV값- 값의 범위(Scope)를 지정, N번의 시도 횟수(Sampling)를 지정한다.
- 범위(Scope) 내의 랜덤한 값을 정하여 N회 시도한다.
- 가장 성능이 좋은 값을 선택한다.
튜닝시 주의 사항
- Train Set에 대한 파라미터의 조정이기 때문에 실제 데이터와 환경에서 성능이 변할 수 있음.
(과대적합, Overfitting) - 훈련 데이터를 완벽하게 예측하는 모델을 만드는 것이 목적이 아니기 때문에 적절한 복잡도의 모델을 생성, 적절한 예측력을 얻을 정도로 튜닝한다.
참고
[ML]Hyperparameter tuning 기법의 3가지(GridSearch, RandomSearch, Bayesian Optimization)

기술을 공부하는 기술자