복습문제
1. 아래 데이터에서 hello world만 추출하세요
[data]
data = """
<head>
<title>hello world</title>
</head>
"""
[답변]
import re
p = re.compile("(?<=>).*(?=<)")
p.search(data).group()
2. 0~35로 구성된 66빙고판을 만들고
1) 짝수만 출력하세요
[답변]
import numpy as np
a = np.array(range(36)).reshape((6, 6))
a[:,[0, 2, 4]]
2) 1~99까지의 값으로 3차원 3행을 가지는 array를 만들어주세요
[답변]
a = np.array(range(1, 100)).reshape(3, 3, -1)
a
3. 3행 3열과 5행 6열의 값은 1, 나머지는 0으로 채워진 10by10 배열을 만들어주세요
[답변]
import numpy as np
a = np.zeros((10, 10))
a[[3, 5], [3, 6]] = 1
a
4. 모든 원소가 3인 10x10 배열을 만들어주세요
[답변]
import numpy as np
a = np.full((10, 10), 3)
print(a)Broadcasting
일반적으로 numpy 에서는 shape가 다른 배열끼리의 연산이 불가능하다. 하지만 조건을 맞춘다면 모양이 다른 배열끼리도 연산을 수행할 수 있는데 이를 Broadcasting 이라 한다. 부족한 부분은 알아서 확장하여, 더 작은 배열이 큰배열에 브로드캐스트되어 호완되는 모양새이다.
import numpy as np
arr = np.arange(1, 4)
# [1 2 3]
x = 2
print(arr * x)
# [2 4 6]배열과 스칼라의 곱을 보면 쉽게 이해할 수 있다. 곱하는 숫자는 하나이지만 배열 arrr 과 연산하면서 x = [2 2 2] 와 같은 모양의 배열로 늘어난다고 생각해볼 수 있는 것이다.
규칙
- 멤버가 하나인 배열은 어느 배열에나 가능
Value = np.array([[1,2,3,4],[2,5,6,7],[8,9,10,11],[12,13,14,15]])
Value1 = np.array([1])
print(Value + Value1)- 배열 하나의 차원이 1인 경우 가능
Value = np.array([[1,2,3,4],[2,5,6,7],[8,9,10,11],[12,13,14,15]])
Value2 = np.array([3,3,3,3])- 차원의 짝이 맞을때 가능
Value2 = np.array([3,3,3,3])
Value3 = np.array([4,5,6,7]).reshape(4,1)
IGHSX
XIGHS
array([[4],
[5],
[6],
[7]])
+
np.array([3,3,3,3])
차원이 1x4 + 4x1 의 모양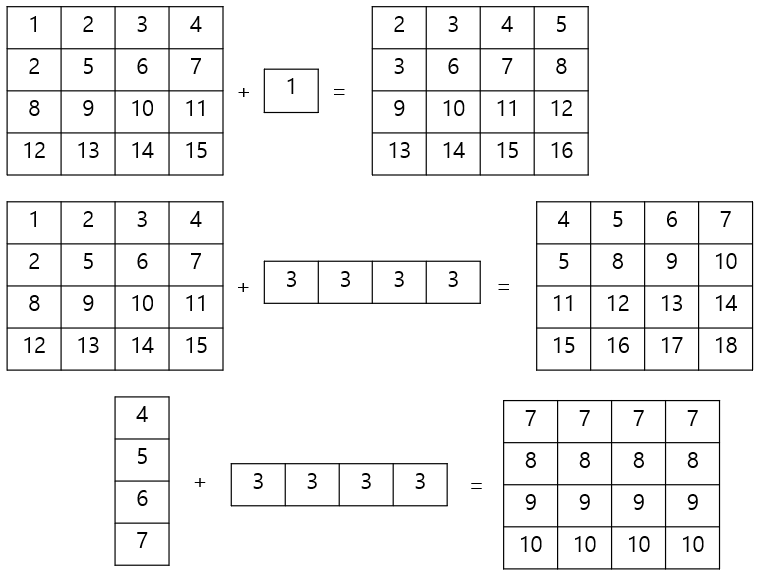
stack
numpy 배열의 결합 방법
vstack
배열을 세로로 결합할 때 사용한다. 주의할 점이라고 하면 요소(열)의 갯수가 같아야 한다는 점이다.
vstack((a, b)) 혹은 vstack([a ,b]) 의 형태로 사용
a = np.arange(10)*10
b = np.arange(10)*20
np.vstack((a, b))
# array([[ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90],
# [ 0, 20, 40, 60, 80, 100, 120, 140, 160, 180]])hstack
배열을 옆으로 결합하고 싶을 때 사용. 이때는 행이 일치해야 한다.
hstack((a, b)) 혹은 hstack([a ,b]) 의 형태로 사용
a = np.arange(0, 5)*5
b = np.arange(0, 5)*5
np.hstack((a, b))
# array([ 0, 5, 10, 15, 20, 0, 5, 10, 15, 20])문제
아래 배열 a, b 모양을 변형해주세요
1. c = [[1 2 3]
[4 5 6]] 를 만들어 주세요
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.vstack((a, b))
print(c)
2. [array([[1, 2, 3]]), array([[4, 5, 6]])] 으로 다시 잘라주세요
np.vsplit(c, 2)
3. 아래 그림대로 배열을 만들고, blue, yellow, red, blue_를 만들어주세요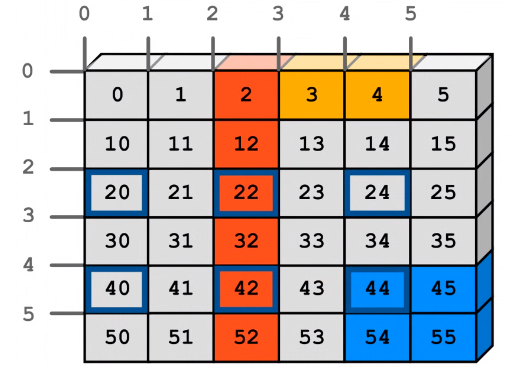
a = np.arange(6)
b = np.array([[0], [10], [20], [30], [40], [50]])
c = a+b
yellow = c[[0, 0], [3, 4]]
red = c[:,2]
blue = c[4:, 4:,]
blue_line = c[2::2, ::2]---
axis(배열 축)
1차원 배열
arr = np.array([0,1, 2, 3, 4])
print(arr)
# [0 1 2 3 4]1차원에서 축은 axis0 하나뿐입니다. 행과 열의 개념은 따로 없습니다.
2차원 배열
arr2 = np.arange(8).reshape(2, 4)
print(arr2)
# [[0 1 2 3]
# [4 5 6 7]]위는 2행 4열 크기의 배열이다. 2차원이기 때문에 축이 2개로
axis0 = 행
axis1 = 열이라고 행각하면 쉽습니다. 단, 이는 2차원에서만 해당하는 이야기 입니다.
3차원 배열
arr3 = np.arange(18).reshape(2, 3, 3)
print(arr3)
# [[[ 0 1 2]
# [ 3 4 5]
# [ 6 7 8]]
# [[ 9 10 11]
# [12 13 14]
# [15 16 17]]]3차원에서는 (높이, 행, 열) 의 순서라고 생각하면 된다. 즉 위 배열은 3행 3열짜리 배열이 2층으로 쌓여있는 모양. 3차원이기 때문에 축이 3개입니다
axis0 = 높이
axis1 = 행
axis2 = 열개념
배열은 리스트의 중첩이고, 축이라는 것은 안쪽 리스트부터 순서대로 번호를 붙인 것입니다. 행렬개념으로 이해하기 보다는 중첩의 의미로 이해해야 차원이 올라가도 헷갈리지 않습니다.
flatten()
다차원 배열 공간을 1차원으로 평탄화해주는 함수이다. 아래 예시를 보면 (4, 8) 크기의 배열이 한줄로 변한것을 볼수 있다.
a = np.arange(32).reshape(4, 8)
print(a)
# [[ 0 1 2 3 4 5 6 7]
# [ 8 9 10 11 12 13 14 15]
# [16 17 18 19 20 21 22 23]
# [24 25 26 27 28 29 30 31]]
print(a.flatten())
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30 31]split
배열 분할하기
transpose
T
먼저 T메소드부터 알고가는게 좋을 것 같다.
행렬의 행과 열을 바꾸는 방법으로 shape를 본래와 반대 즉, 역방향으로 변경할 수 있는 메소드이다.
arr = np.arange(10).reshape(2,5)
print(arr)
# [[0 1 2 3 4]
# [5 6 7 8 9]]
print(arr.T)
[[0 5]
# [1 6]
# [2 7]
# [3 8]
# [4 9]]arr.transpose() or np.transpose(arr)
2차원에서는 그 결과가 T와 다르지 않다.
arr = np.arange(10).reshape(2,5)
print(arr)
# [[0 1 2 3 4]
# [5 6 7 8 9]]
print(arr.transpose())
# [[0 5]
# [1 6]
# [2 7]
# [3 8]
# [4 9]]
print(np.transpose(arr))
# [[0 5]
# [1 6]
# [2 7]
# [3 8]
# [4 9]]3차원의 경우에는 차이가 보인다. 먼저 T의 경우
arr = np.arange(36).reshape(2,6,3)
print(arr)
# [[[ 0 1 2]
# [ 3 4 5]
# [ 6 7 8]
# [ 9 10 11]
# [12 13 14]
# [15 16 17]]
# [[18 19 20]
# [21 22 23]
# [24 25 26]
# [27 28 29]
# [30 31 32]
# [33 34 35]]]
# 먼저 T의 경우
print(arr.T)
# [[[ 0 18]
# [ 3 21]
# [ 6 24]
# [ 9 27]
# [12 30]
# [15 33]]
# [[ 1 19]
# [ 4 22]
# [ 7 25]
# [10 28]
# [13 31]
# [16 34]]
# [[ 2 20]
# [ 5 23]
# [ 8 26]
# [11 29]
# [14 32]
# [17 35]]]배열의 모양이 (2,6,3)에서 (3, 6, 2)의 형태로 변경된 것을 확인 할 수 있다.
arr.transpose(0, 2, 1)
# array([[[ 0, 3, 6, 9, 12, 15],
# [ 1, 4, 7, 10, 13, 16],
# [ 2, 5, 8, 11, 14, 17]],
# [[18, 21, 24, 27, 30, 33],
# [19, 22, 25, 28, 31, 34],
# [20, 23, 26, 29, 32, 35]]])transpose() 의 괄호 안에 들어가는 값은 axis 번호이다. 기존에 shape(2,6,3) 는
axis0번 = 2
axis1번 = 6
axis2번 = 3이라고 매칭 되어있는데, transpose 안에 (0, 2, 1) 순서를 이렇게 재배열 해줌으로서
2는 axis0번으로
6은 axis2번으로
3은 axis1번으로변경된것이다. 그러니까 shape(2, 3, 6) 과 같은 모양새로 말이다.
boolean Indexing
# 조건에 맞으면 T or 조건에 맞지 않으면 F로 리턴
print(a>7)
# [False False True True True]
# type 이 bool이라고 명시해줌으로서 0=F 1=T 의 형태가 됨
mask = np.array([0, 1, 1, 0, 0, 1, 0, 0], dtype = bool)
print(mask)
# [False True True False False True False False]
where
np.where : 조건을 만족하는 값의 index를 리턴한다
인덱스만 반환
np.where 내에 조건만 적으면 인덱스가 반환된다.
a = np.arange(6, 11)
# where 조건을 적으면 인덱스가 반환
print(np.where(a > 7))
# (array([2, 3, 4]),)
print(np.where(a%3==0))
# (array([0, 3]),)
# 인덱스가 출력되기 때문에 []안에 넣어주면 바로 값이 튀어나온다
print(a[np.where(a > 7)])
# [ 8 9 10]2차원 배열의 경우 결과가 조금.. 보기 어렵다
a = np.array([[2, 19, 11], [9, 15, 14]])
np.where(a > 10)
# (array([0, 0, 1]), array([0, 2, 0]))결과의 위치를 보는 방법은 앞 배열은 axis=0 뒤 배열은 axis=1 에 해당하기 때문에 쉽게 풀어보자면 (0, 0) (0, 2) (1, 0) 의 자리에 해당하는 값이 있다는 말이다.
응용
where(조건, 조건을 만족했을 시, 만족하지 않았을 시) 의 형태로 브로드 캐스팅 된다.
a = np.array([[2, 19, 11], [9, 15, 14]])
np.where(a<2, a+10, a)+) 문제
# **2 = 각 행에 있는 값들을 제곱해주라는 의미
a = np.arange(-15, 15).reshape(5,6) **2
print(a)
# 1. 각 행별로 최댓값은 각각 얼마입니까?
print(np.max(a[0])) # 225
print(np.max(a[1])) # 81
print(np.max(a[2])) # 9
print(np.max(a[3])) # 64
print(np.max(a[4])) # 196
print(np.max(a, axis=1))
# [225 81 9 64 196]
# 2. 각 열별로 평균은 얼마입니까?
print(np.mean(a[:,0])) # 81.0
print(np.mean(a[:,1])) # 76.0
print(np.mean(a[:,2])) # 73.0
print(np.mean(a[:,3])) # 72.0
print(np.mean(a[:,4])) # 73.0
print(np.mean(a[:,5])) # 76.0
print(np.mean(a, axis=0))
# [81. 76. 73. 72. 73. 76.]
# 3. 10보다 작은 수를 모두 골라라
print(a[np.where(a<10)])
# 4. 10보다 작은것은 모두 0으로, 크거나 같은 것은 1로 바꾸자
np.where(a<10, 0, 1)