복습문제
a = [1, 2, 3, 4]
# a를 복제하는 방법은?
[답변]
1. b = a
2. c = a.copy()
3. d = copy.copy(a)
# np.sort(a)를 출력한 후 다시 a를 출력했을 때, 결과는 sort(a)와 같은가?
a = [1, 3, 4, 2]
# [답변] x
# 아래 배열을 만드세요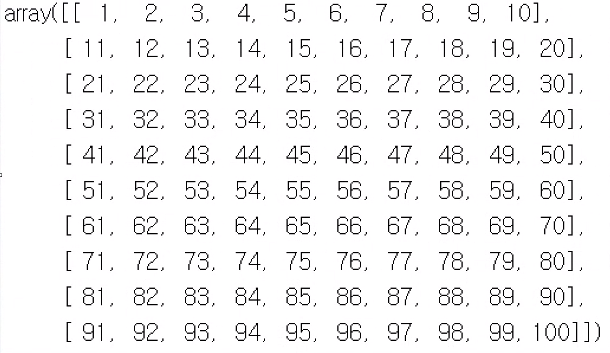
[답변]
import numpy as np
a = np.arange(1, 101).reshape(10, -1)
a
# hsplit과 vsplit의 차이를 말해보자
[답변]
# 행렬을 나누는데 hsplit 은 열을 기준으로, vsplit은 행을 기준으로 나눈다.
# vsplit : 믐 / hsplit : ㅁ|ㅁ
# [[3. 3. 0.]
# [3. 3. 3.]
# [0. 3. 3.]]
위 행렬 모양을 만들어주세요
[답변]
a = np.ones((3,3))
a = a * 3
a[[0, 2], [2, 0]] = 0
print(a)
# ***_like()의 용도는?
데이터타입과 형태를 유지하고 값을 채워준다
# 아래 array의 최대값, 열 별 최대값, 최대값의 인덱스를 추출하세요
a = np.array([[1,2,4,7], [9,88,6,45], [9,76,3,4]])
print(np.max(a))
print(np.max(a, axis=0))
print(np.argmax(a))
# 아래 배열을 만들어주세요
np.arange(25).reshape(5,5) ** 3
# 위에서 만들어진 배열 중 500보다 작으면 0, 크면 1로 값을 바꾸자
np.mean(a, axis=1)
# array([ 1, 16, 31, 46, 61, 76, 91]) 모양의 배열을 만들어라
np.arange(1, 100, 15)
# stack 이란 FIFO이다 (ox)
x
# array 객체의 속성을 3가지 이상 적어보세요
arr.shape arr.size arr.dtype
# array([[[ 0, 1, 2],
# [ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]],
# [[12, 13, 14],
# [15, 16, 17],
# [18, 19, 20],
# [21, 22, 23]],
# [[24, 25, 26],
# [27, 28, 29],
# [30, 31, 32],
# [33, 34, 35]]])
# 위 같은 모양의 배열을 만드세요
np.arange(36).reshape(3, 4, 3)
np.arange(36).reshape(3, 4, -1)
# 행렬의 곱셈
# arr1=np.array([[1,2, 1],[3,4, 2]])
# arr2=np.array([[5,6],[7,8],[1,2]])
# 위 두 배열을 곱하세요
arr1 @ arr2
np.matmul(arr1, arr2)
# 그림 불러오기
# 현재 사용중인 파일 위치 보기
pwd
# 'C:\\Users\\admin'
# 이미지 가져오기 위해 matplotlib을 가져온 후
import matplotlib.pyplot as plt
with open("lena.raw", 'rb') as f :
img = np.fromfile(f, dtype = 'ubyte', sep="")
img = np.reshape(img, [512, 512])
plt.imshow(img, cmap='gray')
# 이미지를 전치시키려면
import matplotlib.pyplot as plt
with open("lena.raw", 'rb') as f :
img_2 = np.fromfile(f, dtype = 'ubyte', sep="")
img_2 = np.reshape(img, [512, 512])
img_2.T
# 색반전 시키려면
import matplotlib.pyplot as plt
with open("lena.raw", 'rb') as f :
img_2 = np.fromfile(f, dtype = 'ubyte', sep="")
img_2 = np.reshape(img, [512, 512])
# _r 을 해주면 댐
plt.imshow(img_2, cmap='gray_r')
# 혹은
import matplotlib.pyplot as plt
with open("lena.raw", 'rb') as f :
img_2 = np.fromfile(f, dtype = 'ubyte', sep="")
img_2 = np.reshape(img, [512, 512])
img_2 = abs(255-img)
plt.imshow(img_2, cmap='gray')
# 행 열 각각 100번째에서 400번째까지 5칸 씩 띄워 출력해보세요
import matplotlib.pyplot as plt
with open("lena.raw", 'rb') as f :
img_2 = np.fromfile(f, dtype = 'ubyte', sep="")
img_2 = np.reshape(img, [512, 512])
img_2 = img_2[100:401:5, 100:401:5]
plt.imshow(img_2, cmap='gray')
# 값이 125보다 크면 255로, 125보다 같거나 작으면 0으로
import matplotlib.pyplot as plt
with open("lena.raw", 'rb') as f :
img_2 = np.fromfile(f, dtype = 'ubyte', sep="")
img_2 = np.reshape(img, [512, 512])
img_2 = np.where(img_2>125, 255, 0)
plt.imshow(img_2, cmap='gray')파일과 운영체제
파일을 읽고 쓰기 위해 열 때는 내장함수인 open을 이용하여 파일의 상대경로나 절대 경로를 넘겨주어야 한다.
path = 'examples/ss.txt'
# 해당 경로의 파일을 열겠다
f = open(path)기본적으로 파일은 읽기 전용 모드인 'r'로 열린다. 파일 핸들 f를 리스트로 생각할 수 있으며 파일의 매 줄을 순회할 수 있다.
for line in f :
pass이렇게 파일을 열게되면 EOL(end of line) 문자가 그대로 남아있으므로 rstrip() 과 같이 끝을 제거하는 코드를 자주 확인할 수 있다.
파일 객체를 open 했다면 작업이 끝났을 때는 명시적으로 close() 를 사용하여 닫아주어야 한다. 하지만 with 문 사용시 파일 작업을 끝낸 후 자동으로 닫아준다.
with open(path) as f :
lines = [x.rstrip() for x in f]ndarray 의 type
dtype은 ndarray가 메모리에 있는 특정 데이터를 해석하기 위해 필요한 정보(혹은 메타데이터)를 담고 있는 객체이다
arr1 = np.array([0, 1, 2], dtype=np.float64)
arr.dtype
# dtype('float64')dtype 이 있기에 Numpy가 강력하면서도 유연한 도구가 될 수 있었다고. 산술 데이터의 dtype은 float나 int 같은 자료혀의 이름과 하나의 원소가 차지하는 비트수로 이루어진다. 파이썬 float 객체에서 사용되는 값은 8바이트 혹은 64비트로 이루어지는데 이 자료형은 Numpy 에서 float64로 표현된다
ndarray의 astype메서드를 사용하면 배열의 dtype을 명시적으로 변환(캐스팅)이 가능하다
arr = np([1, 2, 3, 4, 5])
arr.dtype
# dtype('int64')
float_arr = arr.astype(np.float64)
float_arr.dtype
# dtype('float64')만약 숫자형식의 문자열을 담고 있는 배열이 있다면 숫자로 변환할 수도 있다.
import numpy as np
numeric_st = np.array(['15', '1.23', '-6'], dtype = np.string_)
numeric_st.dtype
# dtype('S4')
numeric_st.astype(np.float)
# array([15. , 1.23, -6. ])
# 근데 위와같이... 1.23 같은 값이 있는데 int로 변환하려하면 에러난다. 크기를 확인하고 변환해야한다NumPy 자료형 몇가지
| 자료형 | 자료형 코드 | 설명 |
|---|---|---|
| int8, uint8 | i1, u1 | 부호가 있는 8비트와 부호가 없는 8비트 정수형 |
| floa64 | f8 또는 d | 확정밀도 부동 소수점 |
| bool | ? | True와 False 값을 저장하는 불리언형 |
| Object | 0 | 파이썬 객체형 |
불리언값으로 선택하기
예시로 사용할 중복된 이름이 있는 배열과 randan함수로 임의의 표준 정규 분포 데이터를 생성하자
names = np.array(['Bob', 'Kily', 'Will', 'Joe', 'Bob', 'Kily', 'Will'])
data = np.random.randn(7, 4)
배열에 == 으로 비교연산을 하면 names를 'Will' 문자열과 비교하면서 불리언 배열을 반환한다.
names == "Will"
array([False, False, True, False, False, False, True])각각의 이름이 data배열의 각 행에 대응한다고 생각했을 때, 만약 전체 행에서 "Will" 에 대응하는 이름만 뽑고 싶다면 이 불리언 배열을 배열의 색인으로 사용할 수 있다.
data[names == "Will"]
# array([[ 0.44623627, -1.53261915, -1.15275628, 0.46101203],
# [-0.18380532, 0.44294637, -0.40352028, -1.87709117]])불리언 배열은 색인하려는 축의 길이와 반드시 동일한 길이를 가져야한다. 만약 'Will' 이라는 두 사람 중에 뒤에 있는 Will의 값만 가져오려면
data[names == "Will", 2:]
# array([[-1.15275628, 0.46101203],
# [-0.40352028, -1.87709117]])위와같이 컬럼지정을 해줄 수도 있다. 마찬가지로 Will이 아닌 요소들을 선택하려면 != 혹은 ~ 같은 부정요소를 사용하여 조건절을 부인하면 된다.
mask1 = (names == "A") | (names == "B") | (names == "C")
print(data[~mask1])보다시피 여러 개를 한번에 지정하는 것도 가능하다!
mask = (names == "D") | (names == "E")
print(data[mask])데이터로 그래프 그리기
데이터 불러오기
import seaborn as sns
df = sns.load_dataset('titanic')
df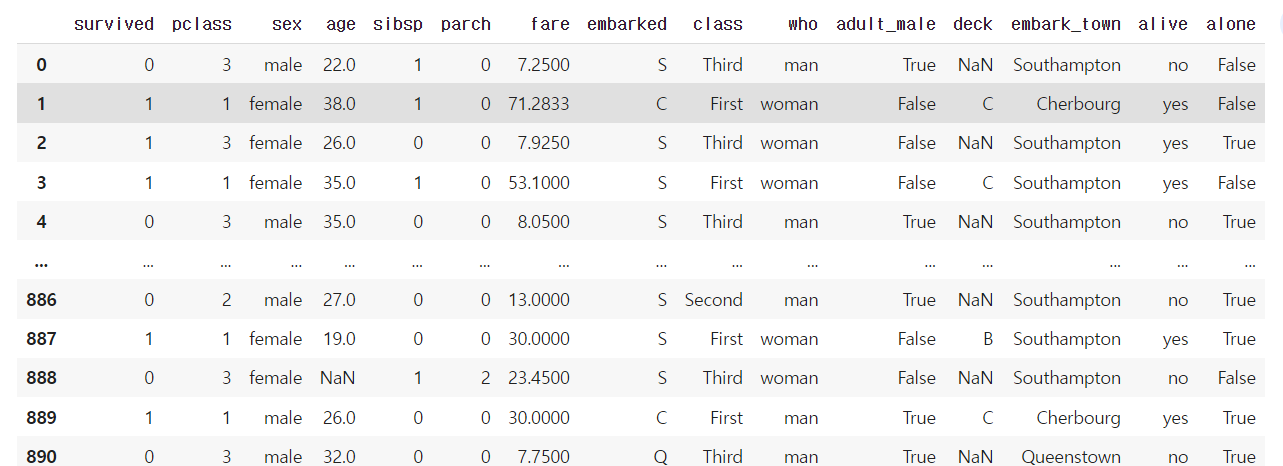
빈도 막대 그래프를 그리기 위해 contplot() 를 사용해 보겠다.
sns.countplot(data = df, x = 'sex')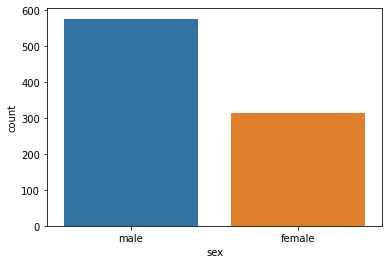
countplot에 입력한 x는 그래프의 x축을 정하는 기능을 합니다. 이렇게 함수의 옵션을 설정하는 명령어를 파라미터(Parameter) 혹은 매개변수라 합니다.
모듈
어떤 패키지는 함수가 굉장히 많기 때문에 비슷한 함수들끼리 묶어 몇 개의 모듈로 나뉘어 있습니다. 패키지명.모듈명.함수명() 의 형태로 로드할 수 있습니다.
# sklearn 패키지의 metrics 모듈 로드하기
import sklearn.metrics
# sklearn 패키지의 metrics 모듈 속 accuracy_score를 사용하겠다
sklearn.metrics.accuracy_score()하지만 매번 모듈의 함수를 사용할 때 패키지명을 입력하는게 번거롭다면 from 패키지명 import 모듈명 으로 로드하면 된다.
metrics.accuracy_score()조금이라도 타이핑 할것이 줄어들었다. 만약 함수명으로만 사용하고 싶다면 함수만 직접 로드하면된다.
from sklearn.metrics import accuracy_score()
accuracy_score()함수의 사용법이 궁금할땐
간혹 함수를 사용하다보면 파라미터를 지정하는 방식 등 문법이 헷갈리거나 궁금할때, 기억이 나지 않을때가 있습니다. 이럴때 함수명 앞이나 뒤에 물음표를 넣으면 매뉴얼을 출력합니다. 여기에는 함수소개, 파라미터 사용법, 예제 코드가 들어있습니다.
# sns.countplot() 매뉴얼을 출력하고싶다
sns.countplot?데이터 프레임 만들기
# 먼저 pandas 패키지 로드
import pandas as pd
# 데이터 프레임 만들기
pd.DataFrame([1, 2, 3, 4])pandas는 데이터를 가공할 때 사용하는 패키지 입니다. 데이터 프레임을 만들때에는 pandas의 DataFrame() 을 이용합니다.
pd.DataFrame([[1, 2, 3, 4], ['a', 'b', 'c', 'd']])
# 0 1 2 3
# 0 1 2 3 4
# 1 a b c d엑셀 읽어서 데이터 사용하기
먼저 엑셀을 읽어온다
import pandas as pd
# 엑셀 읽어오기
exam = pd.read_excel("excel_exam.xlsx")불러온 엑셀에서 수학 열을 보고싶다면
exam['math']
# 0 50
# 1 60
# 2 45
# 3 30
# 4 25
# 5 50
# 6 80
# 7 90
# 8 20
# 9 50
# 10 65
# 11 45
# 12 46
# 13 48
# 14 75
# 15 58
# 16 65
# 17 80
# 18 89
# 19 78
# Name: math, dtype: int64수학컬럼의 평균을 구해보자
print(exam['math'].mean())
print(np.mean(exam['math']))
print(sum(exam['math'])/20)
# 데이터 프레임을 모두 넣어도 각각의 열대로 평균을 구해주긴 한다
# 하지만 이렇게 구하면 경고가 뜬다
np.mean(exam)
# 그럴때는 이렇게 축을 지정해주면 뜨지 않는다
np.mean(exam, axis = 0)이 데이터 프레임을 csv로 다시 저장하겠다면
# 데이터프레임을 csv로 저장하겠다
exam.to_csv("csv_exam.csv")그런데 저장된 파일을 다시 열어보면
# 다시 열어보기
pd.read_csv("csv_exam.csv")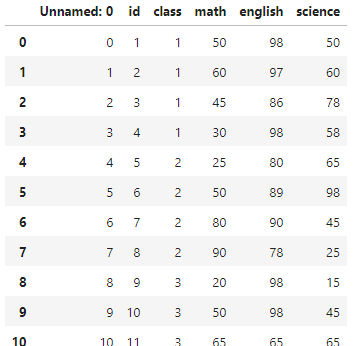
이런식으로 원래 인덱스였던 것이 값이 되어 열로 추가되어 있는 모습을 확인할 수 있다. 이를 없애려면 두가지 방법이 있는데
# 없애고 싶어 평소처럼 []로 자르겠다 하였지만
pd.read_csv("csv_exam.csv").[:, 1:]
# SyntaxError: invalid syntax
# 오류가 뜬다.
# pandas에서는 행렬에 접근할때 iloc로 접근해야한다
exam_1 = pd.read_csv("csv_exam.csv").iloc[:, 1:]
exam_1.head()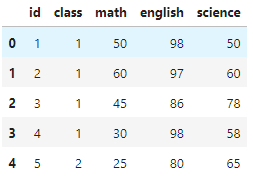
혹은 아예 파일 저장시 index 저장옵션을 꺼주면된다
# index 저장을 꺼주기
exam.to_csv("csv_exam_index_false.csv", index = False)
pd.read_csv("csv_exam_index_false.csv")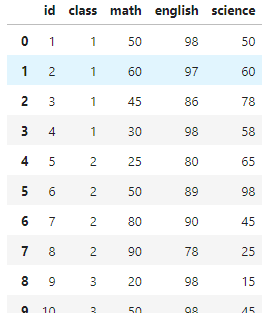
데이터를 파악할 때 사용하는 명령어
| 함수 | 기능 |
|---|---|
| head() | 앞부분 출력 |
| tail() | 뒷부분 출력 |
| shape | 행, 열 개수 출력 |
| info() | 변수 속성 출력 |
| describe() | 요약 통계량 출력 |
변수명 바꾸기
rename기능을 사용해주면 된다
{'기존 변수명' : '새 변수명'}
exam.rename(columns={'english': 'eng'})
exam.rename({'english': 'eng'}, axis=1)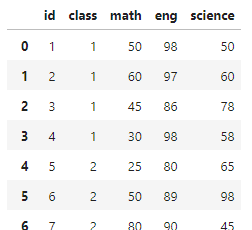
만약 여러개를 한번에 변환하고 싶다면 어렵지 않다. 반점을 사용하여 구분해주면 되는 것이다
# 두개를 변환하려면 반점 사용
exam.rename({'english':'eng', 'science':'sci'}, axis=1)
exam.rename(columns={'english':'eng', 'science':'sci'})
저장 옵션
무언가 계산하거나 컬럼을 추가한 뒤 그 값을 원래의 데이터에 덮어쓰기 위해서 exam = exam--의 형태를 사용해도 괜찮지만, 덮어쓰기 옵션 inplace를 사용해도 된다
exam.rename(columns={'english':'eng', 'science':'sci'}, inplace=True)
exam문제
수학 영어 과학 3열의 합으로 새로운 열을 추가하세요
exam['hap'] = exam['math']+exam['eng']+exam['sci']
exam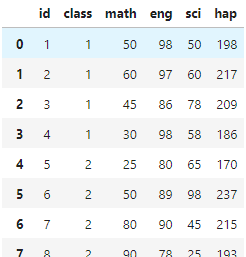
평균이 70초과라면 합격, 아니라면 불합격의 값을 가지는 '합격 여부'라는 이름의 열을 추가하세요.
exam['mean'] = (exam['math']+exam['eng']+exam['sci'])/3
exam['합격여부'] = np.where(exam['mean']>70, '합격', '불합격')
exam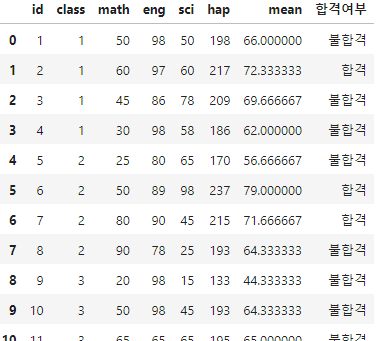
pydataset의 mpg 데이터를 가져와, contplot으로 drv 컬럼을 cyl 별로 그려봅시다
# pydataset과 seaborn 을 사용하기 위해 다운
!pip install seaborn
!pip install pydataset
from pydataset import data
mpg = data("mpg")
import seaborn as sns
sns.countplot(data = mpg, x = 'drv', hue='cyl')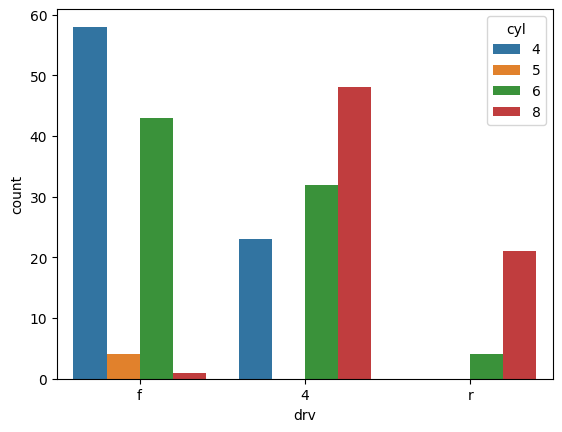
total 열을 추가해라 cty 와 hwy의 평균으로
mpg['total'] = (mpg['cty']+mpg['hwy'])/2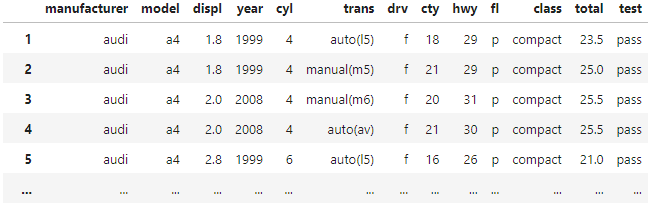
빈도수 파악하기
value_counts() 를 사용한다. 예를 들어 test 칼럼에서 pass, fail의 빈도수는 몇번인지 구해보자
a = mpg['test'].value_counts()
a
# pass 128
# fail 106
# Name: test, dtype: int64파악한 빈도수로 그림그려보기. bar 형태로 출력하고 싶다면 barh = 가로로 출력 / bar = 세로출력 둘 중 고르면 된다. 그런데 a.plot(kind='bar') 으로 출력해보면
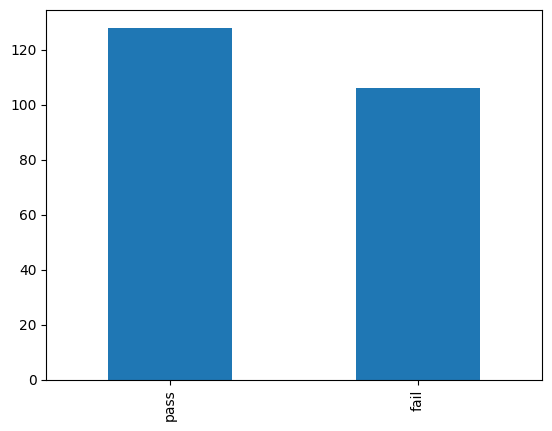
이와 같이 x축 이름이 세로로 서있는 것을 확인할 수 있다. 이는 가독성이 좋지 않으니 수정하고 싶다면 rot 옵션으로 잡아주면 된다.
a.plot(kind='bar', rot = 0 )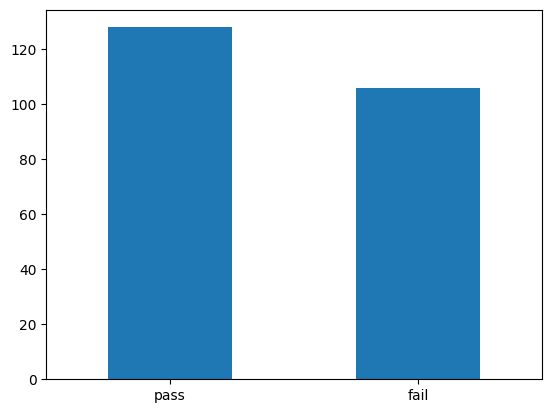
다시 문제
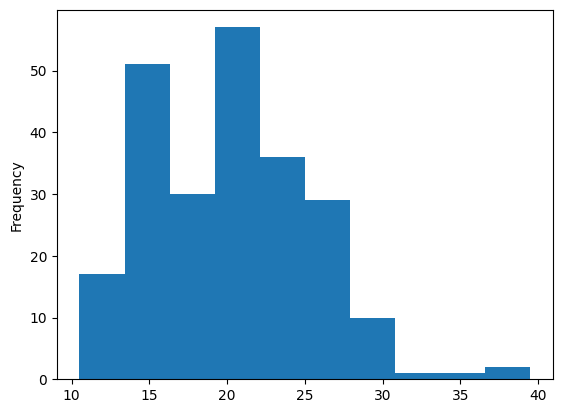
total 칼럼에서 max값과 min 값을 구하세요
print(mpg['total'].max()) # 39.5
print(np.max(mpg['total'])) # 39.5
print(max(mpg['total'])) # 39.5
print(mpg['total'].min()) # 10.5
print(np.min(mpg['total'])) # 10.5
print(min(mpg['total'])) # 10.5
# 혹은 이렇게 일일히 구하지 않고
# 요약을 보여주는 describe 를 사용하여 확인할 수도 있다.
mpg['total'].describe()matplot 시각화
# mpg['total'].plot()
# mpg['total'].plot(kind = 'hist')
mpg['total'].plot.hist()