복습문제
# IQR의 범위는?
# [답변]
25% ~ 75%
1사분위 ~ 3사분위
# 산점도는 ... sns.?
# [답변]
scatterplot
# 칼럼의 데이터 타입을 int로 바꾸려면?
# [답변]
.astype('int')
# re와 sub()를 이용하여 한글이 아닌 모든 문자를 공백으로 바꾸려면
# [답변]
re.sub('[^가-힣]', " ", 변환할 것)
# 특정 칼럼의 빈도를 구하려면?
# [답변]
value_count()
# 극단치 기준 찾기에서 상한, 하한을 구하는 식의 괄호 안에 들어갈 숫자는?
# [식]
pct() - ()*IQR
pct() + ()*IQR
# [답변]
75 , 1.5
25, 1.5
# x축 눈금 레이블을 회전하는 함수는 무엇인가요?
# [답변]
plt.xticks(rotaton = 회전각도)
# 데이터 프레임을 딕셔너리로 변환하는 함수는?
# [답변]
df.dict() ---- x
# [올바른 답]
df.to_dict
# barplot에서 x축의 데이터 순서를 정의하여 줄 때 사용하는 파라미터의 이름은 무엇인가요?
# [답변]
order
# mpg dataset을 불러오세요
# [답변]
import pydataset
mpg_data = pydataset.data('mpg')
# 도시연비(cty)에서 75%, 25% 값을 각각 구하세요
# [답변]
pct75 = mpg_data['cty'].quantile(.75)
pct25 = mpg_data['cty'].quantile(.25)
# 수염의 각 끝값은 얼마입니까?
# [답변]
IQR = pct75 - pct25
a = pct75 + 1.5*IQR
b = pct25 - 1.5*IQR
# 도시연비에서 이상치의 개수는?
# [답변]
con1 = mpg_data['cty'] < 6.5
con2 = mpg_data['cty'] > 26.5
len(mpg_data[con1 | con2])
# 5개
# 데이터셋에서 그룹을 지을 때, 인덱스로 변환하지 않게 하는 옵션은?
# [답변]
as_index = False
# 구동 방식(drv) 별로 배기량(displ)에 따른 도시연비(cty) 그래프를
# 산점도로 그려주세요
# [답변]
import seaborn as sns
df = mpg_data.query('cty <= 6.5 | cty >= 26.5')
sns.scatterplot(data = df, x = 'displ', y = 'cty', hue = 'drv')
# 칼럼을 인덱스로 만드려면
# [답변]
set_index('칼럼명')
# 인덱스를 칼럼으로 옮기기 위한 함수는?
# [답변]
as_index = False
reset_index()
# df['word']의 글자 수를 알고 싶다면?
# [답변]
pd.str.len()
# serborn 에서 그래프 그리는 함수를 아는대로 적어보세요
# [답변]
bar
barh
hist
scatterplot
lineplot
countplot
boxplot
+ relplot?relplot?
산점도(scatterplot()) 와 lineplot()의 상위 개념 함수이다. relplot()을 이용하면 산점도와 선 그래프 모두를 그릴 수 있고, 두 그래프의 문법을 그대로 다 사용할 수 있다. 단지 scatter plot을 그리고 싶다면 relplot(kind="scatter") 을 line plot을 그리고 싶다면 relplot(kind="line")을 입력하면 된다.
※ kind를 적지 않으면 default값은 산점도그래프(scatterplot()) 이다.
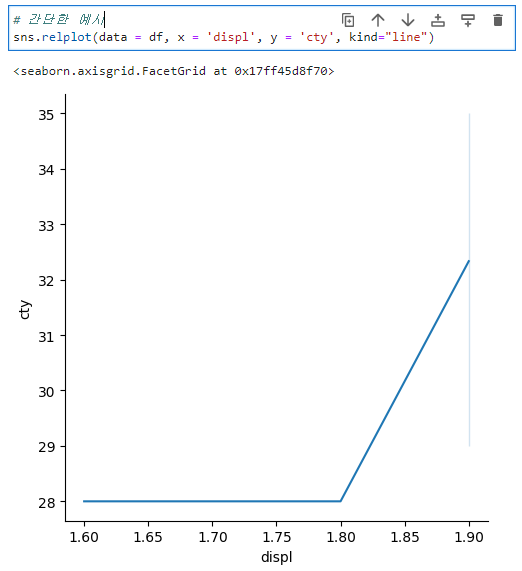
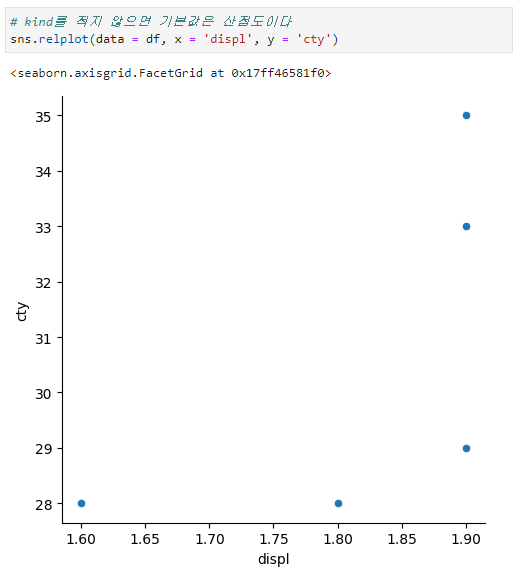
relplot()의 장점은 return 값이 FactGrid라는 것이다.
(FactGrid : 여러개의 AxesSupbplot을 포함)
(산점도와 선은 return 값이 AxesSubplot)
(AxesSubplot : 1장의 그림 속에 모든 것을 담는다)
# 데이터 가져오기
import seaborn as sns
tips = sns.load_dataset("tips")
tips
# 그림 한번에 여러개 그리기
# hue와 비슷
# 어떤 변수로 데이터를 나눌지 col,row에 입력해주면된다
sns.relplot(data=tips, x="total_bill", y="tip", col="time")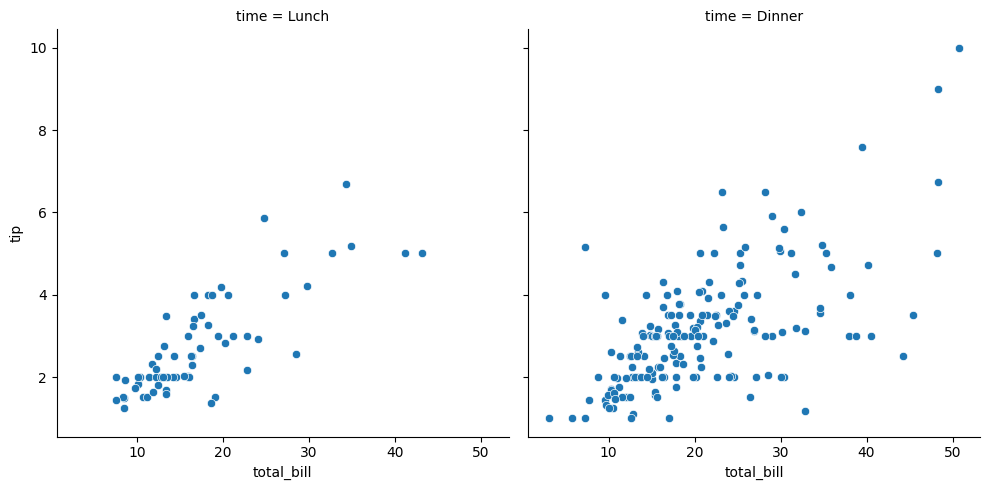
지도 시각화
지역별 통계칠르 색 차이로 표현한 지도를 단계 구분도라고 합니다. 이를 만들면 인구나 소득같은 통계치가 지역별로 어떻게 다른지 쉽게 이해할 수 있다
시군구별 인구 단계 구분도
시군구 경계 지도 데이터 준비하기
대한민국의 시군구별 경계 좌표가 들어있는 SIG.geojson 파일 읽어오기. json패키지의 json.load()를 이용하면 불러올 수 있다.
import json
geo = json.load(open('SIG.geojson.txt', encoding = 'UTF-8'))geo는 딕셔너리 구조로 되어있다. SIG_CD에는 지역을 나타내는 행정 구역 코드, geometry에 시군구 경계를 나타낸 위도와 경도 좌표가 있다.
# 행정구역 코드 출력
geo['features'][0]['properties']
# {'SIG_CD': '42110', 'SIG_ENG_NM': 'Chuncheon-si', 'SIG_KOR_NM': '춘천시'}
# 위경도 좌표 출력
geo['features'][0]['geometry']
# {'type': 'MultiPolygon',
# 'coordinates': [[[[127.58508551154958, 38.08062321552708],
# [127.58565575732702, 38.0802009066172],
# [127.58777905808203, 38.080354190085544],
# 이하생략시군구별 인구 데이터 준비하기
# Population_SIG.csv : 시군구별 인구 통계 데이터
# 2021년의 행정구역 코드, 지역이름, 인구
import pandas as pd
df_pop = pd.read_csv('Population_SIG.csv')
df_pop.info()
# 0 code 278 non-null int64
# 1 region 278 non-null object
# 2 pop 278 non-null int64
# 행정 구역 코드를 나타낸 df_pop의 code는 int 타입으로 되어 있으나
# 이것이 문자 타입으로 되어있어야 지도를 만드는 데 활용할 수 있다
df_pop['code'] = df_pop['code'].astype(str)folium 패키지를 사용하여 단계 구분도 만들기
# 설치
!pip install folium
# folium.Map()을 이용하여 배경지도 만들기
import folium
map_sig = folium.Map(location = [35.95, 127.7], # 지도의 중심 위경도 좌표
zoom_start = 8, # 확대 단계
tiles = 'cartodbpositron') # 지도 종류
map_sig
# 단계 구분도 만들기
# folium.Choropleth() 를 이용할 수 있다.
folium.Choropleth(
geo_data = geo, # 지도 데이터
data = df_pop, # 통계 데이터
columns = ('code', 'pop'), # df_pop 행정구역 코드, 인구
key_on = 'feature.properties.SIG_CD').add_to(map_sig)
# key_on : df_pop 행정구역 코드, 인구
# add_to: 앞에서 만든 배경지도 map_sig에 이 구분도를 덧씌워 저장하겠다
map_sig
# 앞에서 출력한 지도는 지역이 색으로 구분되 표현되어있지 않습니다.
# 분위수를 이용해 지역을 적당히 나누는 계급 구간을 정한 후
bins = list(df_pop["pop"].quantile([0, 0.2, 0.4, 0.6, 0.8, 1]))
bins
# [8867.0, 50539.6, 142382.20000000004, 266978.6, 423107.20000000024, 13565450.0]
# 이 구분을 사용해 색으로 표현\
# 배경 지도 만들기
map_sig = folium.Map(location = [35.95, 127.7],
zoom_start = 8,
tiles = 'cartodbpositron')
# 단계 구분도 만들기
folium.Choropleth(
geo_data = geo,
data = df_pop,
columns = ('code', 'pop'),
key_on = 'feature.properties.SIG_CD',
fill_color = 'YlGnBu',
fill_opacity = 1,
line_opacity = 0.5,
bins = bins).add_to(map_sig)
map_sig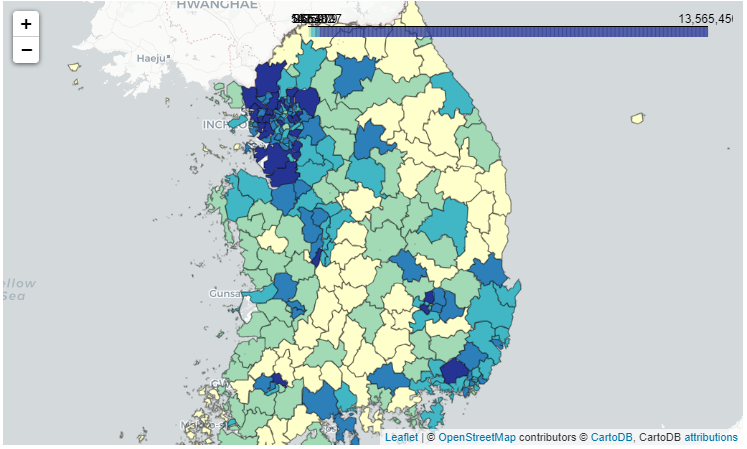
folium.Choropleth(
geo_data = "지도 데이터 파일 경로 (.geojson, geopandas.DataFrame)"
data = "시각화 하고자 하는 데이터파일. (pandas.DataFrame)"
columns = (지도 데이터와 매핑할 값, 시각화 하고자하는 변수),
key_on = "feature.데이터 파일과 매핑할 값",
fill_color = "시각화에 쓰일 색상",
legend_name = "칼라 범주 이름",
).add_to(m)인터렉티브 그래프
마우스 움직임에 반응하며 실시간으로 모양이 변하는 그래프를 뜻한다.
산점도 만들어보기
ploty 패키지로 인터렉티브 그래프 만드는 방법을 알아보자
# jupyter-dash는 ploty로 만든 그래프를 노트북에 출력하는 패키지
!pip install plotly jupyter-dash
# 설치 후 재시작산점도 만들기
# 그래프 만드는데 사용할 데이터 가져오기
import pandas as pd
import pydataset
mpg = pydataset.data('mpg')plotly.express의 scatter()을 이용하면 seaborn의 scatterplot() 와 비슷한 문법으로 산점도를 만들수 있다.
import plotly.express as px
px.scatter(data_frame=mpg, x='cty', y='hwy', color='drv')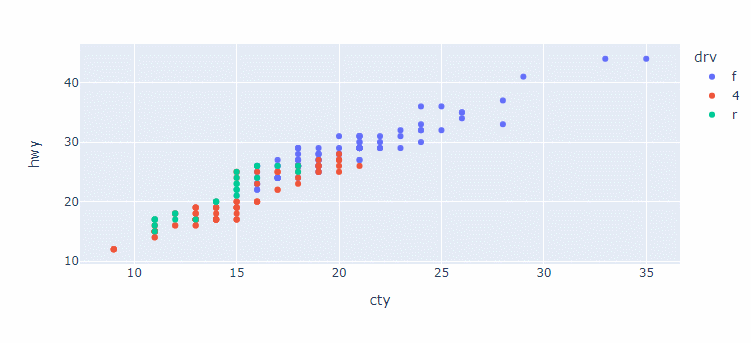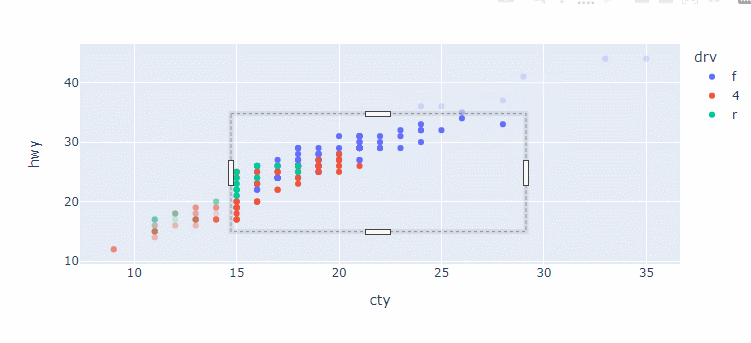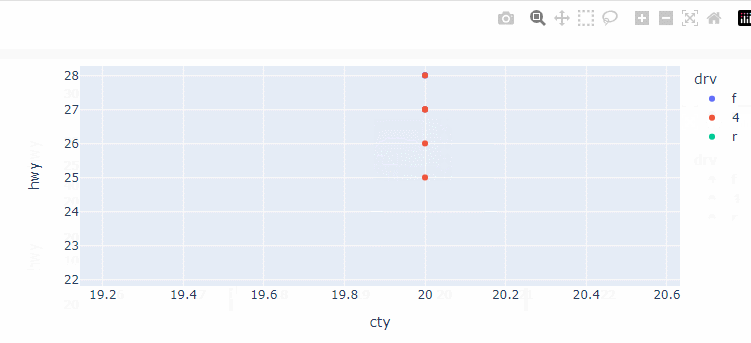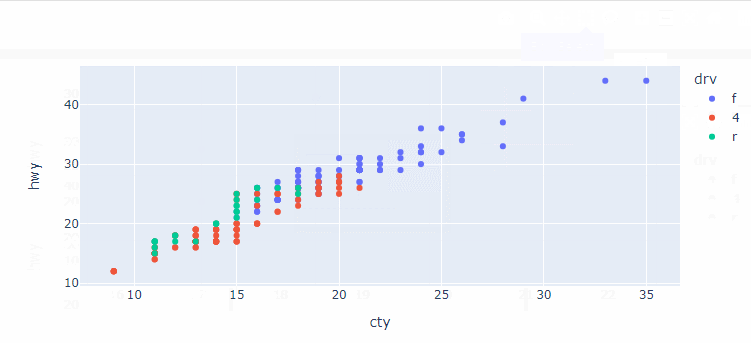
막대 그래프
# 자동차 종류별 빈도 구하기
df = mpg.groupby('class', as_index=False)\
.agg(n = ('class', 'count'))
df = df.rename({'class':'category'}, axis=1)
df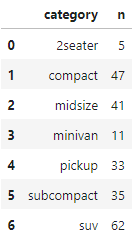
# 이런식으로 컬럼을 만들어 줄 수도 있다.
test = mpg.groupby('class')[['class']].agg('count')
test = test.rename({'class' : 'n'}, axis = 1)
test.reset_index()
# 막대 그래프 만들기
px.bar(data_frame=df, x = 'category', y='n', color='category')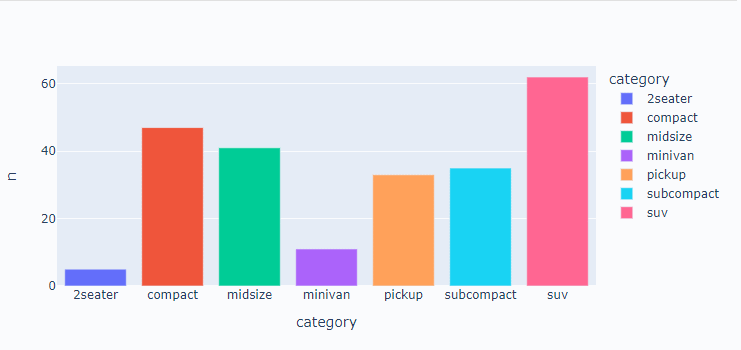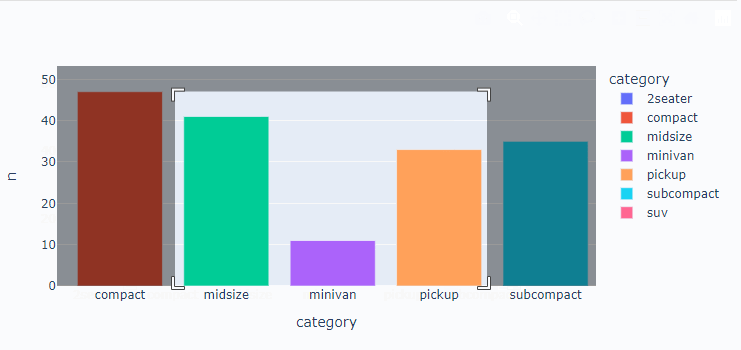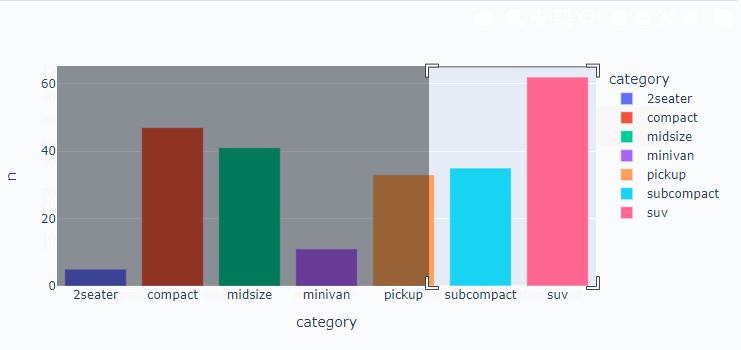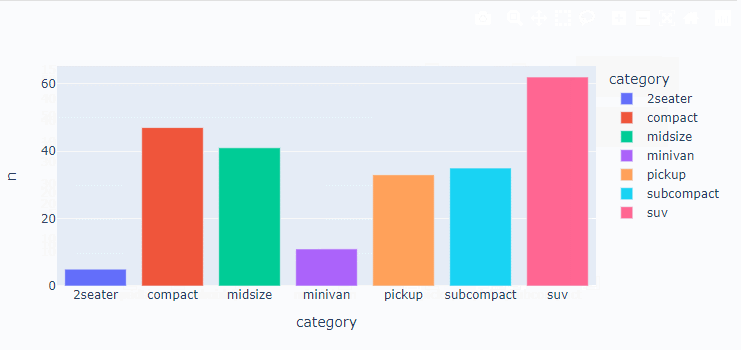
loc 와 iloc로 선택
DataFrame의 로우에 대해 라벨로 index하는 방법으로는 특수한 필드인 loc와 iloc 를 이용할 수 있다. 축 이름을 선택할 때는 loc를 , 정수 index로 선택할 때에는 iloc를 이용한다.
import pandas as pd
import numpy as np
# 사용할 데이터 만들기
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index = ['Ohio', 'Colorado', 'Utah', 'New York'],
columns = ['one', 'two', 'three', 'four'])
data
# 축의 라벨로 하나의 로우와 여러 컬럼을 선택해보자
data.loc['Ohio', ['two', 'three']]
# two 1
# three 2
# Name: Ohio, dtype: int64
# iloc를 이용하면 정수 색인으로도 위와 비슷하게 선택 가능
data.iloc[2, [3, 0, 1]]
# four 11
# one 8
# two 9
# Name: Utah, dtype: int64이 두 함수는 슬라이스도 지원할 뿐더러 단일 라벨이나 라벨 리스트도 지원한다.
data.loc[:'Ohio', 'two']
# Ohio 1
# Name: two, dtype: int64
print(data.iloc[:,:3][data.three>5])
# one two three
# Colorado 4 5 6
# Utah 8 9 10
# New York 12 13 14*args, **kwargs
*args = *arguments 의 줄임말
여러(복수) 개의 인자를 함수로 받고자 할 때 쓰인다.
예를 들어서 사람의 이름과 성을 분리한 후 출력하고 싶은데, 몇개의 입력이 들어올지 모르는 상황. 이럴때 *args를 인자로 받는다. 받은 후 함수 내부에서는 튜플로 받은 것처럼 인식함.
**kwargs = keyword argument 의 줄임말
키워드를 제공한다. **kwargs는 (키워드 = 특정값)의 형태로 함수를 호출할 수 있게 해주고, 그대로 dic형태인 {'키워드':'특정값'} 의 모습으로 함수 내부로 들어간다.
# kwargs 예시
# key 부분의 값으로 may가 들어오면 다른 문구가 출력되는 코드이다
def Hello(**kwargs) :
for key, value in kwargs.items() :
if 'may' in kwargs.keys():
print("Have a nice Day!")
else :
print("{0} is {1}".format(key, value))
Hello(MyName='Joe')
# MyName is Joe
Hello(may="Jeo")
# Have a nice Day!zip함수(*args와 **kwargs)
동일한 개수로 이루어진 자료형을 묶어주는 역할을 한다.
A = [0, 1, 2]
B = [3, 4, 5]
for i in zip(A, B) :
print(i, type(i))
# (0, 3) <class 'tuple'>
# (1, 4) <class 'tuple'>
# (2, 5) <class 'tuple'>리스트와 문자열끼리도 가능하지만, 문자열과 리스트 처럼 서로 다른 타입이여도 엮어주는 것이 가능하다 한다.
A와 B의 길이가 서로 다르다면 길이가 더 짧은 자료형에 맞추어져 엮어진다. 매칭이 되는 부분까지만 매칭해주기 때문에 그로 인한 오류는 생기지 않는다
A = [0, 1, 2, 3, 4, 5]
B = ["6","'5"]
list(zip(A, B))
# [(0, '6'), (1, "'5")]2차원 리스트에서 행이 아니라 열 순서대로 가져오고 싶다면, 아래 예시로 보자
# ex) 예시로 사용할 2차원리스트 생성
alist = np.arange(1, 10).reshape(3, 3)
alist
# array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])zip 함수에 *agrs 를 인수로 넣을 수 있다. 리스트를 그냥 입력하지 말고 *를 붙여 입력하면 col끼리 서로 붙는 효과가 생긴다.
for i in zip(*alist) :
print(i)
# (1, 4, 7)
# (2, 5, 8)
# (3, 6, 9)*args 를 인수로 받는 함수에 리스트를 변수로 넣어주는 경우 리스트 합에 *를 붙여서 넣어주면 리스트 자체가 통으로 들어가는 것이 아닌, 각각의 내부 요소값이 변수로 인식되는 듯하다.
# 입력이 들어오는데
def ex(*args):
# 들어오면 변수값을 타입과 함께 출력하겠다
print(args, type(args))
# 변수들을 각각 출력해달라
print(*args, end='\n\n')
for i in args:
print(i)
ex([1, 2, 3, 4, 5])
# ([1, 2, 3, 4, 5],) <class 'tuple'>
# [1, 2, 3, 4, 5]
# [1, 2, 3, 4, 5]
ex(*[1, 2, 3, 4, 5])
# (1, 2, 3, 4, 5) <class 'tuple'>
# 1 2 3 4 5
# 1
# 2
# 3
# 4
# 5
ex(*[[1, 1], [2, 2]])
# ([1, 1], [2, 2]) <class 'tuple'>
# [1, 1] [2, 2]
# [1, 1]
# [2, 2]위 예시를 보면 그냥 리스트를 넣으면 통으로 인식되어 각각의 요소들을 출력하겠다 했음에도 리스트 전체가 나오는 모습을 확인할 수 있다. 하지만 *를 붙여주어 입력한 리스트는 요소 하나하나가 변수로 인식되어 각각의 요소들이 잘 떨어져 출력되는 모습을 확인할 수 있었다.
(+이 페이지 읽어보기)