복습문제
# 집단별로 그룹을 지을때 사용하는 함수는?
# [답변]
groupby()
# sort 함수 두가지는?
# [답변]
sort_values() / sort_index()
# 아래 csv를 읽어들이면 'Unnamed` 컬럼이 있다. 이 컬럼을 삭제해주세요.# [주소]
"https://raw.githubusercontent.com/sidsriv/Introduction-to-Data-Science-in-python/master/mpg.csv"
# [답변]
import pandas as pd
mpg = pd.read_csv("https://raw.githubusercontent.com/sidsriv/Introduction-to-Data-Science-in-python/master/mpg.csv")
mpg = mpg.iloc[:,1:]
mpg# mpg에서 manufacturer와 class로 그룹을 만들고
# 만들어진 그룹별 hwy의 평균을 구해라
# [답변]
mpg.groupby(['manufacturer', 'class']).mean()[['hwy']]
import numpy as np
mpg.groupby(['manufacturer','class'])[['hwy']].agg(np.mean)
# class칼럼 안에 'compact', 'midsize', 'suv'인 것만 골라달라
# [답변]
mpg[(mpg['class'] == 'compact') | (mpg['class'] == 'midsize') | (mpg['class'] == 'suv')]
+) class는 예약어이기 때문에 쿼리 사용이 되지 않아서 이름 바꾸는게 가능하다면
mpg.rename({'class':'newclass'}, axis=1, inplace=True)
mpg.query('newclass in ["compact","midsize","suv"]')
# 위에서 뽑은 세종류의 자동차들에서만 cty의 평균을 구하시오
# [답변]
df = mpg.query('newclass in ["compact","midsize","suv"]')
df.agg(np.mean)[['cty']]
df['cty'].mean()
np.mean(df['cty'])
df.apply('mean')[['cty']]
# +) 추가
# 원래 형태
df.loc[:, 'cty']
# 문자가 들어가면 컬럼에 접근
df['cty']
# 하나라면 .으로 접근가능
df.cty
# 숫자가 들어가면 (요소) 슬라이싱 하는 것
df[:]
# drv가 'r' 이면 결측치로 변경하시오
# [답변]
mpg['drv'] = np.where(mpg['drv'] == "r", np.nan, mpg['drv'])
# 확인
mpg['drv'].value_counts().sort_index()np.random.?
numpy의 np.random 에는 여러 함수들이 있는데 (numpy 페이지) 이 중 몇가지만 살펴보려 한다.
np.random.rand
0부터 1 사이의 균일 분포, 균등분포라고 불리는 난수 matrix array를 생성한다. 그냥 rand()로 작성하면 값 하나가, 괄호안에 dimension를 적으면 해당 dimension을 가진 numpy array가 생성된다.

np.random.randn
평균 0, 표준편차 1을 가지는 표준정규분포 내에서 임의추출하는 함수이다. rand와 마찬가지로 원하는 차원을 넣으면 해당 차원만큼 numpy array가 생성된다.

np.random.randint
정수값만을 return 하는 함수이다. .randint(low, high, size) 순으로
low 가장 작은 값을 적는다.
high 옵션사항으로, 가장 높은 값을 적는다
size 몇개의 값을 리턴 받기 원하는지를 적는다. shape를 적고 싶다면 size=(,)의 형태로 적어줄 수 있다.

choice
np.random.choice(집단, 갯수, 복원추출여부,확률리스트)
의 구성으로 이루어진 이 함수는. 원하는 집단에서 원하는 개수를 뽑아낼 수 있는데, 복원추출여부와 추출 확률까지 지정할 수 있다.
집단 : 정수로 지정시 0 ~ (적어준 숫자-1) 범위
갯수 원하는 결과의 dimension을 정수(1차원) 혹은 튜플(2차원 이상)로 지정해주면 된다
복원 추출 여부 : True인 경우 앞에서 등장한 값이 또 뽑힐수 있고, False인 경우는 앞에서 등장한 값은 등장하지 않는다
확률 리스트 : 생략시 모든 집단의 요소가 균등한 확률로 추출되고, 각 요소에 대한 확률을 지정하여 리스트 형태로 넣어주면 해당 확률을 반영하여 추출을 하게 된다.
(단, 모든 확률의 합이 1이 되어야 한다.)

Series
일련의 객체를 담을 수 있는 1차원 배열같은 자료구조로 색인(index)라고 하는 배열의 데이터와 연관된 이름을 가지고 있다.
# 가장 간단한 Series 객체는 배열로부터 생성 가능
import pandas as pd
obj = pd.Series(range(10))
obj
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 5 5
# 6 6
# 7 7
# 8 8
# 9 9
# dtype: int64Series 객체의 문자열 표현은 왼쪽에 index를 보여주고 오른쪽헤 index에 해당하는 값을 보여준다. 위에서는 index를 따로 지정하지 않아 기본 으로 정수 0에서 (N-1)까지 표시되었다. Series의 배열과 index는 각각 values와 index 속성을 통해 얻을 수 있다.
obj.values
# aarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
obj.index
# RangeIndex(start=0, stop=10, step=1)만약 index를 지정하여 객체를 생성해야 할때는 아래와 같이 할 수 있다.
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
obj2
# d 4
# b 7
# a -5
# c 3
# dtype: int64따라서 Numpy 배열과 다른점이라고 하면 값 선택시 index로 라벨을 사용할 수 있다는 점이다.
obj2['c'] # 3Numpy 배열 연산을 수행해도 색인-값 연결은 유지된다.
obj2[obj2<0]
# a -5
obj2*2
# d 8
# b 14
# a -10
# c 6
# dtype: int64Series 객체는 index에 데이터 값을 매핑하고 있으므로 파이썬의 사전형과 비슷하다. 따라서 사전형을 인자로 받아야하는 많은 함수에서 대체햐여 사용할 수 있다.
'b' in obj2
# True
'e' in obj2
# False만약 Series를 DataFrame에 대입하면 index에 따라 값이 대팁되며 존재하지 않은 index에는 결측치가 들어간다. 존재하지 않는 컬럼을 대입하면 새로운 컬럼을 생성하고, 예약어 del을 사용하여 컬럼을 삭제할 수도 있다.
+) pandas에서 index는 변경이 불가하다
+) python 집합과는 달리 pandas의 index는 중복되는 값을 허용한다. 이것으로 검색을 하면 해당 값을 가진 모든 항목이 선택된다.
pandas라이브러리의 몇 기능
reindex
새로운 index에 맞도록 객체를 새로 생성한다. Series 객체에 reindex를 호출하면 데이터를 새로운 index에 맞게 재배열하고, 만약 존재하지 않는 index가 있다면 NaN을 추가한다.
- Series
obj = pd.Series([4.5, 7, -9, 3], index=['d', 'b', 'a', 'c'])
obj
# d 4.5
# b 7.0
# a -9.0
# c 3.0
# dtype: float64
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
obj2
# a -9.0
# b 7.0
# c 3.0
# d 4.5
# e NaN
# dtype: float64- DataFrame
df = pd.DataFrame(np.arange(9).reshape(3,3), index = ['d', 'a', 'b'])
print(df)
# 0 1 2
# d 0 1 2
# a 3 4 5
# b 6 7 8
df2 = df.reindex(['a', 'b', 'c', 'd'])
print(df2)
# 0 1 2
# a 3.0 4.0 5.0
# b 6.0 7.0 8.0
# c NaN NaN NaN
# d 0.0 1.0 2.0극단적인 이상치 제거하기
논리적으로 존재할 수는 있지만 극단적으로 크거나 작은 값을 극단치라고 한다. 극단치가 있으면 분석 결과가 왜곡될 수 있으므로 분석하기 전에 제거해야한다.
# 이상치 만들기
exam.rename({'class':'nclass'}, axis=1, inplace=True)
exam.iloc[0, 2] = 1
exam.iloc[1, 3] = 1
exam.iloc[2, 4] = 1극단치 기준값 구하기
극단치를 제거하려면 어디까지를 정상 범위로 볼 것인지 정해야 하는데, IQR 방식에 대해 알아보자. IQR 방식은 사분위 개념으로부터 출발한다. 전체 데이터들을 오름차순으로 정렬하고 정확히 4등분으로 나눈 후, 75지점과 25 지점의 값의 차이를 IQR 이라 한다.
IQR : Inter Quartile Range , 1사분위~3사분위이때 이 IQR에 1.5를 곱해서 75%지점에 더하면 최대값, 25% 지점의 값에서 빼면 최솟값으로 결정한다.
수염의 끝 : 3사분위 + 1.5 IQR / 1사분위 - 1.5 IQR이렇게 결정된 최대값과 최솟값 범위에 있지 않는 값을 이상치라고 간주하는 것이다.
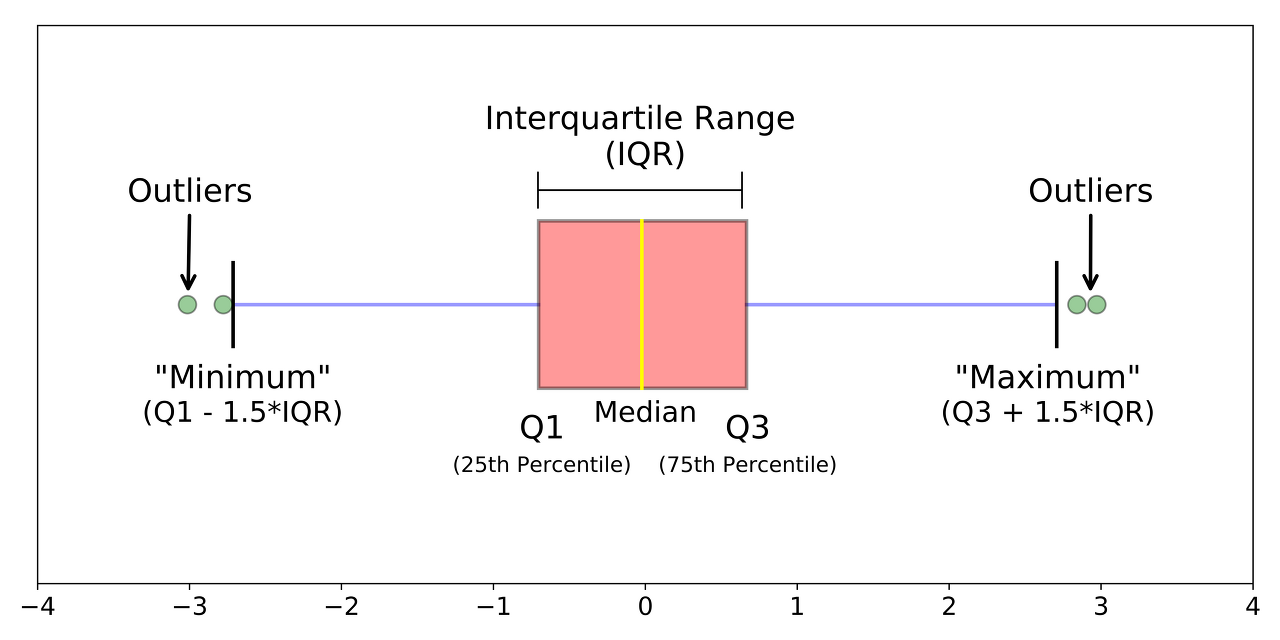
.quantile()을 이용하면 분위수를 구할 수 있다. 하위 25%에 해당하는 1사분위와 75%에 해당하는 3사분위수를 구해보자면
# 실제로 구해보자
pct75 = exam['math'].quantile(.75)
pct25 = exam['math'].quantile(.25)
IQR = pct75-pct25
IQR
# 30.75
pct75 + 1.5*IQR # 최대값 : 121.875
pct25 - 1.5*IQR # 최소값 : -1.125결과를 보니.. 최소값이 -1로 되어있어 극단적인 이상치로 잡히지 않을 것 같다. 예제를 바꿔보자.
import pandas as pd
mpg = pd.read_csv("https://raw.githubusercontent.com/sidsriv/Introduction-to-Data-Science-in-python/master/mpg.csv")
mpg = mpg.iloc[:,1:]
mpg이 예제에서 cty의 범위를 구해보자
# cty로 범위를 구해보자
pct75 = mpg['cty'].quantile(.75)
pct25 = mpg['cty'].quantile(.25)
IQR = pct75 - pct25
pct75 + 1.5*IQR # 최대값 : 26.5
pct25 - 1.5*IQR # 최소값 : 6.5hwy를 구한다면
# cty로 범위를 구해보자
pct75 = mpg['hwy'].quantile(.75)
pct25 = mpg['hwy'].quantile(.25)
IQR = pct75 - pct25
pct75 + 1.5*IQR # 최댓값 : 40.5
pct25 - 1.5*IQR # 최솟값 : 4.5극단치를 결측 처리하기
# query 사용해 검색해보기
con1 = mpg['hwy'] < 4.5
con2 = mpg['hwy'] > 40.5
mpg[con1 | con2]
# 결측 처리
np.where((mpg['hwy'] < 1.5) | (mpg['hwy'] > 40.5), np.nan, mpg['hwy'])
# 결측치 빈도 확인
mpg['hwy'].isna().sum() # 3
# 결측치를 제외한 hwy의 평균은?
mpg.query('hwy < 40.5 and hwy > 4.5').mean()[['hwy']]
# hwy 23.186147
# dtype: float64
mpg[~con1 | ~con2].hwy.mean()
23.186147186147185그래프
데이터를 그래프로 표현하면 특징을 쉽게 이해할 수 있다. 파이썬에는 2차원 그래프 뿐 아니라 3차원 그래프, 모션차트, 인터랙티브 그래프 등 그래프를 만들 수 있는 다양한 패키지가 있다.
그중 seaborn은 그래프를 만들 때 많이 사용하는 패키지로 이를 이용하면 쉽고 간결한 코드로 그래프를 만들 수 있다.
산점도
mpg 데이터로 산점도를 뽑아보자
# 산점도의 특성상 x와 y를 둘다 지정
sns.scatterplot(data=mpg, x='displ', y='hwy')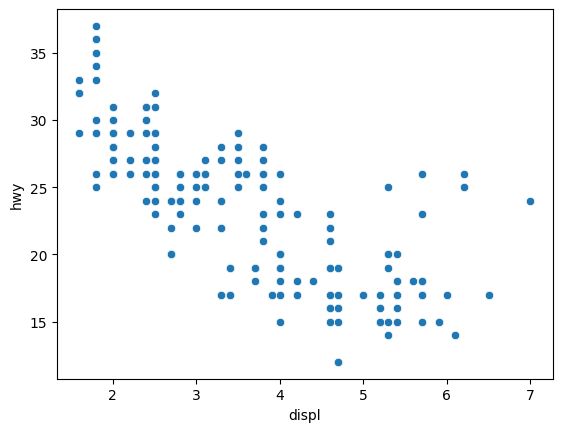
# 색을 주고 싶다면 hue
sns.scatterplot(data=mpg, x='displ', y='hwy', hue = 'drv')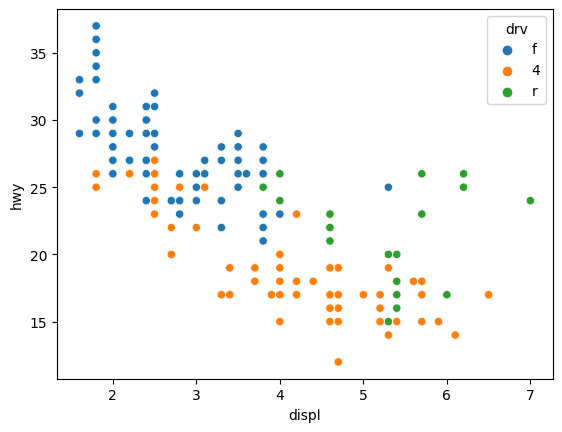 축은 기본적으로 모든 범위의 데이터를 보여주도록 설정 되어있지만 일부반 표현하고 싶을 때는
축은 기본적으로 모든 범위의 데이터를 보여주도록 설정 되어있지만 일부반 표현하고 싶을 때는 .set()의 xlim 과 ylim 을 이용해 설정할 수 있다.
# x축 범위 3~6으로 제한
# y축 범위 10~30으로 제한
sns.scatterplot(data=mpg, x='displ', y='hwy')\
.set(xlim=(3, 6), ylim = (10, 30))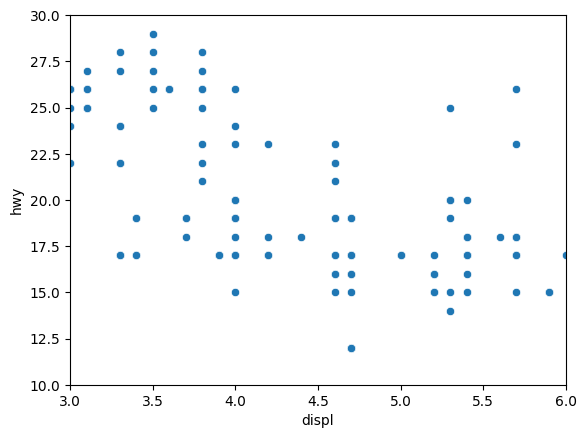
그래프 설정 바꾸기
한번 설정하면 종료할때까지 바꾼 설정이 유지된다. 따라서 설정을 되돌리고 싶다면 Jupyter lab을 새로 실행하거나 커널을 새로 실행하면 된다.
새로 실행하지 않고 설정을 되돌리려면 다음 코드를 실행하면 된다
plt.rcParams.update(plt.rcParamsDefault)설정 바꾸는 코드
import matplotlib.pyplot as plt
plt.rcParams.update({'figure.dpi' : '150'}) # 해상도, 기본값 72
plt.rcParams.update({'figure.figsize' : [8, 6]}) # 가로 세로크기, 기본값 []6, 4
plt.rcParams.update({'font.size' : '15'}) # 글자크기, 기본값 10
plt.rcParams.update({'font.family' : 'Malgun Gothic'}) # 폰트, 기본값 sans-serif여러요소르 한 번에 설정하려면 {여기에} 나열해도 된다
plt.rcParams.update({'figure.dpi' : '150',
'figure.figsize' : [8, 6],
'font.size' : '15',
'font.family' : 'Malgun Gothic' })그래프 저장하기
import matplotlib.pyplot as plt
# savefig(파일이름, 해상도)
plt.savefig('aa.png', api = 300)주의할 점은 그래프를 뽑아낸 바로 그 쉘에 함께 적어야 한다는 것이다
막대그래프
mpg 데이터의 drv별로 hwy의 평균을 구해 그래프를 그려보자
# 값 구하기
# 그래프를 그리기 위해 변수를 인덱스로 바꾸지 않아야한다
# as_index=False로 꺼준다
mpg_df = mpg.groupby('drv', as_index = False)[['hwy']].agg('mean')
mpg_df잘 모르겠다면 차이를 보자
mpg_df = mpg.groupby('drv')[['hwy']].agg('mean')
mpg_df = mpg.groupby('drv', as_index = False)[['hwy']].agg('mean')
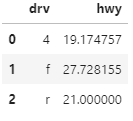
혹은 만든후에 index를 칼럼으로 보내겠다고 할 수도 있다.
mpg_df = mpg.groupby('drv')[['hwy']].agg('mean')
mpg_df.reset_index()
그래프 그리기
sns.barplot(data = mpg_df.reset_index(), x = 'drv', y = 'hwy')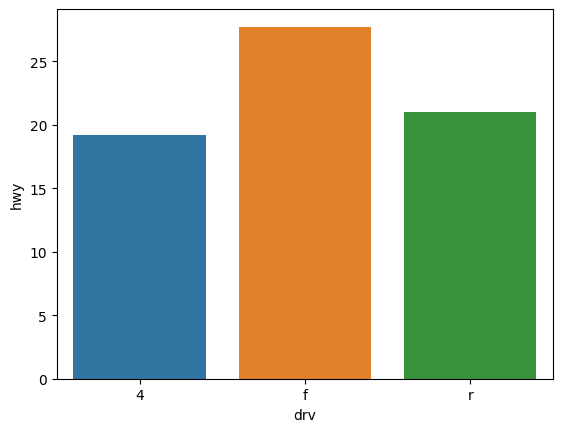
그래프 정렬하기
# drv 그룹별로 묶을 때 index옵션꺼주기
mpg_df = mpg.groupby('drv', as_index = False)[['hwy']].agg('mean')
# 정렬
mpg_df = mpg_df.sort_values(by='hwy', ascending=False)
# 그래프 뽑기
sns.barplot(data = mpg_df, x='drv', y='hwy')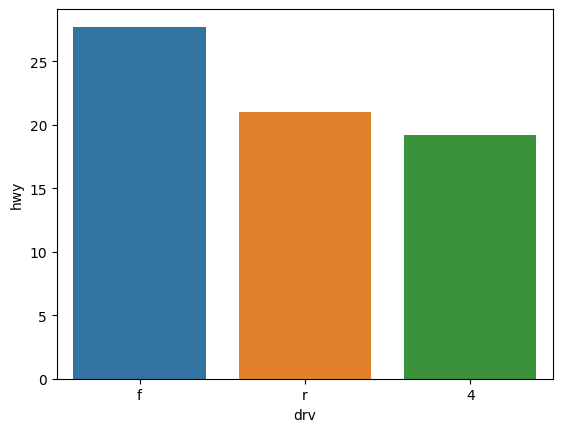
선 그래프
데이터를 선으로 표현한 그래프를 뜻한다. 시간에 따라 달라지는 데이터를 표현시 자주 사용하는데, 일정 시간 간격을 두고 나열된 데이터를 시계열 데이터, 시계열 데이터를 선으로 표현한 그래프를 시계열 그래프 라고 한다
# 데이터 불러오기
import pydataset
economics = pydataset.data("economics")
# 타입보기
economics.info()
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 date 478 non-null object
# 1 pce 478 non-null float64
# 2 pop 478 non-null int64
# 3 psavert 478 non-null float64
# 4 uempmed 478 non-null float64
# 5 unemploy 478 non-null int64
# dtypes: float64(3), int64(2), object(1)
# memory usage: 26.1+ KBsns.lineplot() 을 이용하면 선 그래프를 만들 수 있다.
# x축 : 시간을 나타내는 date
# y축 : 실업자수를 나타낸 unemploy
sns.lineplot(data=economics, x = 'date', y='unemploy')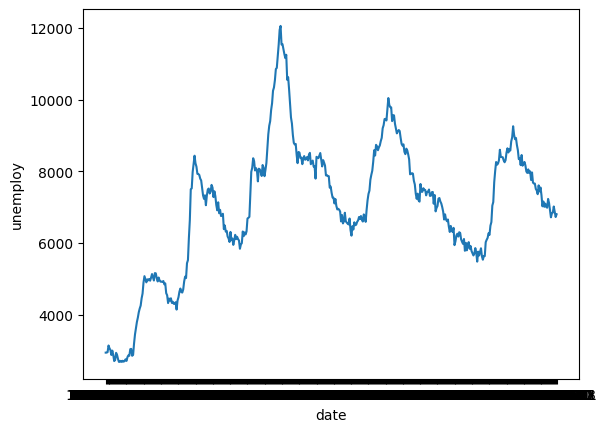 x축을 보면 굵은 선이 그려져있는데, 이는 날짜를 나타낸 문자가 담긴 'date'의 값이 여러변 겹쳐 표시되어서 그런 것이다.
x축을 보면 굵은 선이 그려져있는데, 이는 날짜를 나타낸 문자가 담긴 'date'의 값이 여러변 겹쳐 표시되어서 그런 것이다.
x축에 연도가 표시되도록 astype()을 사용하여 데이터 타입을 변경해보자.
# 바꾸는 방법은 이렇다
economics['unemploy'] = economics['unemploy'].astype('float')
economics.info()
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 date 478 non-null object
# 1 pce 478 non-null float64
# 2 pop 478 non-null int64
# 3 psavert 478 non-null float64
# 4 uempmed 478 non-null float64
# 5 unemploy 478 non-null float64
# int64 였던 unemploy 타입이 float64로 변경되었다.
# date의 값 변경해보기
economics['date'] = economics['date'].astype('datetime64')
economics.info()
# 0 date 478 non-null datetime64[ns]이 상태에서 다시 그려보면
sns.lineplot(data=economics, x = 'date', y='unemploy')pd.to_datetime() 의 형태로도 변경할 수 있다.
economics['date2'] = pd.to_datetime(economics['date'])
economics.info()
# 6 date2 478 non-null datetime64[ns]상자 그림
데이터의 분포 또는 퍼져있는 형태를 직사각형 상자 모양으로 표현한 그래프이다.
sns.boxplot(data=mpg, x='drv', y='hwy')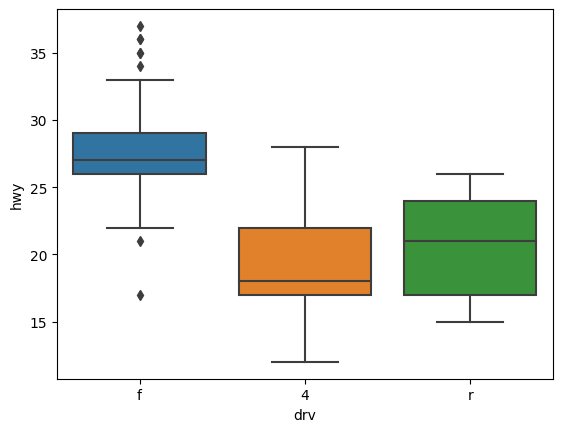
# hwy의 값만 보자
sns.boxplot(data=mpg, y='hwy')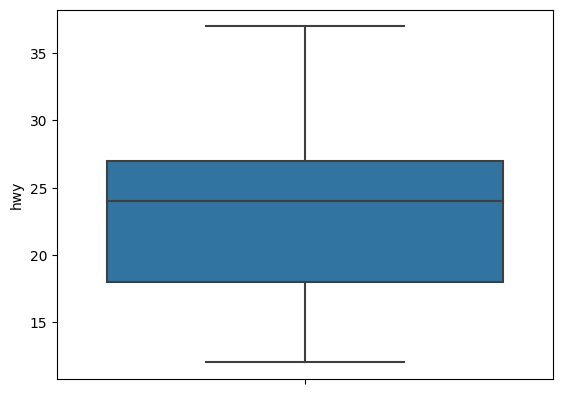
복지패널 데이터 분석
데이터 분석 준비
pip install pyreadstat
# 데이터 불러오기
# Koweps_hpwc14_2019_beta3.sav 데이터는 로컬컴퓨터에 저장되어있다
raw_welfare = pd.read_spss("Koweps_hpwc14_2019_beta3.sav")
raw_welfare
# 데이터 검토하기
raw_welfare.shape#행열갯수 출력 : (14418, 830)
raw_welfare.info() # 변수 속성 출력 : dtypes: float64(826), object(4)
raw_welfare.describe() # 요약 통계량7개 가져와서 컬럼 이름 바꾸기
# 분석에 사용할 변수 7개 가져오기
welfare = raw_welfare.copy()
welfare = welfare.loc[:, ['h14_g3', 'h14_g4', 'h14_g10', 'h14_g11', 'p1402_8aq1', 'h14_eco9', 'h14_reg7']]
# .columns=[]를 이용해 이름 바꾸기
welfare.columns = ['sex', 'birth', 'marriage_type', 'religion', 'income', 'code_job', 'code_region']
welfare컬럼의 이름을 바꿀때는 rename도 있지만 .columns = []의 형태를 사용할 수도 있다. 단, rename처럼 하나하나 대응시키는게 아니기 때문에 .columns 메소드를 사용할 때에는 데이터 프레임의 칼럼 갯수와 바꾸려는 이름들의 갯수가 정확히 일치되어야 한다.
나이와 월급의 관계 보기
print(min(welfare.birth)) # 1907
print(max(welfare.birth)) # 2018
# 최대값인 2018 년생을 1살로 처리해 새로운 열(age) 만들기
welfare['age'] = 2019- welfare['birth']
welfare['age']
# age 열을 int 형으로 바꿔주세요
welfare['age'] = welfare['age'].astype('int')
welfare['age']
# 나이별로 소득의 평균을 구해보기
df = welfare.groupby(['age']).mean()[['income']].dropna()
# groupby에 값이 하나라면 []안해도 괜찮다
# welfare.groupby('age').mean()[['income']].dropna()
# 나이별로 소득의 평균을 구해보기
df = welfare.groupby(['age']).mean()[['income']].dropna()
# 인덱스 내려주기
df = df.reset_index()
# df로 lineplot를 그려보자
sns.lineplot(data = df, x='age', y='income')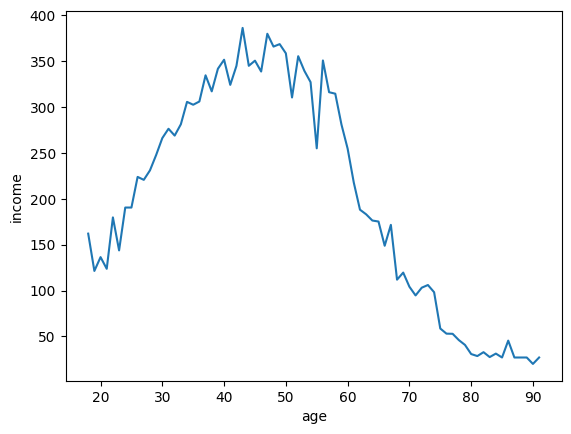
연령대에 따른 월급 차이
'''
새 칼럼 age_gen 을 만드는데
30이하 : young
60이하 : middle
나머지 : old
'''
welfare['age_gen'] = np.where(welfare['age'] <= 30, 'young',
np.where(welfare['age'] <=60, 'middle','old'))
# 데이터 타입을 카테고리 형으로 변경
welfare['age_gen'] = welfare['age_gen'].astype('category')
#welfare.info()
# 세대별 income 의 소득평균
df_gen = welfare.groupby(['age_gen', 'gender'])[['income']].mean()
df_gen = df_gen.reset_index()
# 세대별 나이별 소득평균 그래프
sns.barplot(data = df_gen, x = 'age_gen', y = 'income' , hue = 'gender')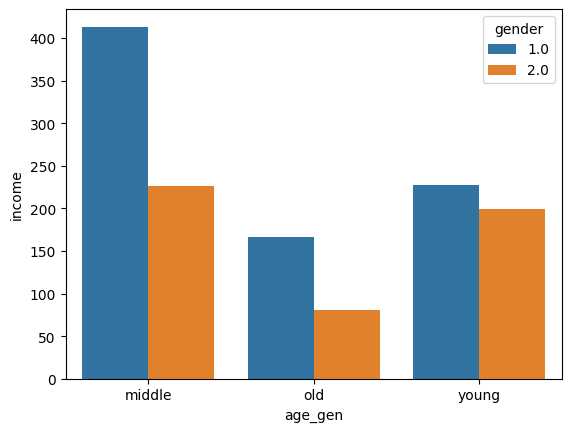
--
텍스트 마이닝
문자로 된 데이터에서 가치 있는 정보를 얻어내는 분석 기법을 뜻한다. 가장 먼저 하는 작업은 문장을 구성하는 어절들이 어떤 품사인지 파악하는 형태소 분석으로, 어절의 품사를 파악한 다음 의미를 지닌 품사를 추출해 어떤 단어가 얼마나 많이 사용되었는지를 파악할 수 있다.
대통령 연설문 텍스트 마이닝
KoNLPy 패키지를 사용하여 한글 텍스트로 형태소 분석하기
# 패키지 설치
pip install konlpy연설문을 불러오겠다. 여기에 접근하거나, 다운받아서 현재 사용중인 파일 아래에 저장해주어 가져와도 된다.
moon = open('speech_moon.txt', 'r', encoding = 'utf-8').read()특수문자, 한자 등의 요소를 제거해야한다. re의 sub를 이용해 한글이 아닌 모든 문자를 공백으로 바꾼 후 명사를 추출해보자
# 문자 제거
import re
moon = re.sub('[^가-힣]', ' ', moon)
# moon # 확인
# 명사추출 테스트해보기
import konlpy
hannanum = konlpy.tag.Hannanum()
hannanum.nouns("대한민국의 영토는 한반도와 그 부속도서로 한다")
# ['대한민국', '영토', '한반도', '부속도서']
# 이제 연설문에서 추출해보자
nouns = hannanum.nouns(moon)
# nouns # 확인
# 데이터 프레임으로 변환
df = pd.DataFrame({'word' : nouns})
# df # 확인한글자로 된 단어는 의미가 없는 경우가 많으므로 pd.str.len()을 이용해 단어의 글자수를 나타낸 변수를 추가한 다음 두 글자 이상인 단어만 추출
df['count'] = df.iloc[:, 0].str.len()
df = df.query('count>1').sort_values('count')
# df[df['count'] > 1] 도 가능
# 단어 빈도 구하기
top20 = df.groupby('word', as_index = False)\
.agg('count') \
.sort_values('count', ascending = False)[:20]
top20그래프 그리기
sns.barplot(data=top20, y='word', x='count')
한글이 다깨진다.
plt.rcParams.update({'font.family' : 'Malgun Gothic'})
sns.barplot(data=top20, y='word', x='count')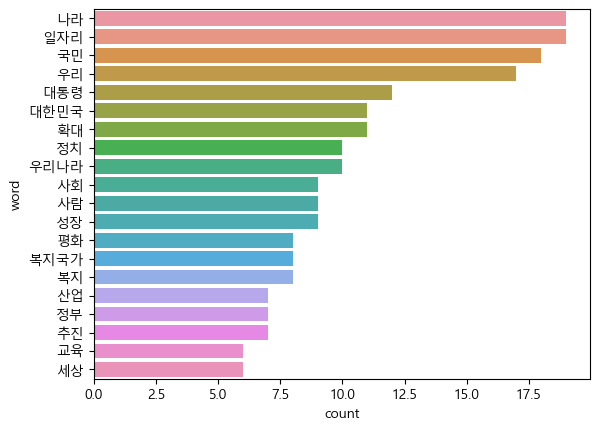
y 값의 글자를 회전시켜보겠다
sns.barplot(data=top20, y='word', x='count')
plt.yticks(rotation=30)
plt.show()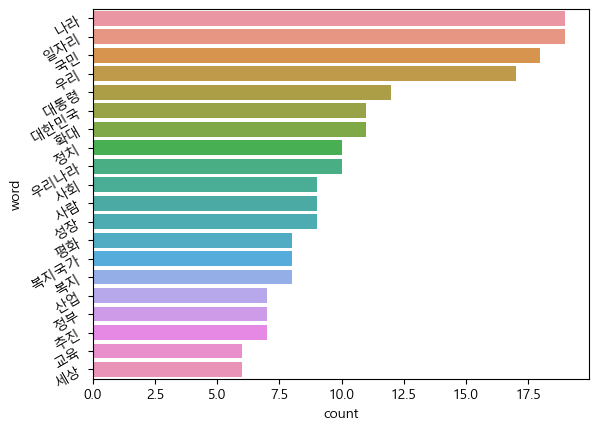
이게 더 보기가 편한가..
워드 클라우드로 만들어보기
단어의 빈도를 구름 모양으로 표현한 그래프이다. 단어에 빈도에 따라 글자의 크기와 색이 다르게 표현되므로 얼마나 사용되었는지 쉽게 파악할 수 있다.
# 워드 클라우드 만들기
!pip install wordcloud
from wordcloud import WordCloud
# 객체 만들기
wc = WordCloud(font_path = 'malgun.ttf',
random_state = 1234,
background_color = 'white')워드클라우드는 단어는 key, 빈도는 value로 구성된 딕셔너리 자료 구조를 이용해 만든다
# dataFrame을 딕셔너리로 만들기
dic_w = top20.set_index("word").to_dict()['count']wc.generate_from_frequencies()를 이용해 클라우드를 만들어주자. 이미지를 출력하는 코드는 한 셀에 넣어 함께 실행 해야한다
import matplotlib.pyplot as plt
# 워드 클라우드 만들기
img_wordcloud = wc.generate_from_frequencies(dic_w)
# 출력하기
plt.axis('off')
plt.imshow(img_wordcloud)