복습문제
# pd.cut() 과 pd.qcut()을 아래 괄호안에 각각 알맞게 넣으세요
가. 동일 길이로 나누어서 범주를 만든다 ( pd.cut )
나. 동일 개수로 나누어서 범주를 만든다 ( pd.qcut )
# stack 과 unstack을 아래 괄호 안에 각각 알맞게 넣으세요
가. 로우를 컬럼으로 피벗시킨다 ( unstack )
나. 데이터의 컬럼을 로우로 피벗시킨다( stack )
# merge 함수는 기본적으로 합집합 결과를 반환한다 ( ox )
x - 교집합 결과를 반환한다 (inner join)
# data = pd.Series([1., -999., 2., -999., -1000., 3.])
# # 위 시리즈에서 -999와 -1000을 NaN으로 바꿔주세요
data.replace([-999, -1000], np.nan)
# [추가답변]
data = np.where(data<=-999,np.nan,data)
# 데이터에 중복되는 값을 제거하기 위해 쓰이는 메소드는?
.drop_duplicates()
# 정규 표현식에서 하나 이상의 공백을 의미하는 것은
\s+
# DataFrame이나 Series에서 무작위로 몇개의 값(레이블)을 출력하는 메서드는?
.sample()
# 아래 DataFrame속 인덱스 1번자리에 새로운 행 new_row를 추가하세요
df = pd.DataFrame({'A' : ['a5', 'a6'], 'B' : ['b5', 'b6'], 'C' : ['c5', 'c6']})
new_row = pd.DataFrame([['aaa', 'bbb', 'ccc']], columns = df.columns)
# [답변]
pd.concat([df.iloc[:1], new_row, df.iloc[1:]], ignore_index = True)
# 위 df에 new_row를 마지막 자리에 붙여주세요
pd.concat([df, new_row])
# 위를 실행시키면 원래 있던 인덱스가 유지되는데 이를 무시하고 새로 매기고 싶다면 어떤 옵션을 사용해야 하는가
ignore_index = True
np.random.seed(1234)
a = pd.DataFrame(np.random.randn(1000, 5))
# 실행 결과로 얻어진 값들 중 절대값이 3 이상의 값이 포함된 행만 찾으려면
a[(np.abs(a) > 3).any(1)]
# pydataset 에서 movies 데이터를 가져와 title, year, length 만 뽑아보지
import pydataset as py
movies = py.data('movies')
movies = movies[['title', 'year', 'length']]
# [추가답변]
movies.iloc[:,:3]
# length 컬럼을 3가지로 쪼개어
# 1~59 : short / 60~99 : mid / 100~179 : long
# 으로 나눠주세요
group_names = ['short', 'mid', 'long']
threshold = [1, 60, 100, 180]
pd.cut(movies['length'], threshold, labels=group_names )
# [추가 답변]
pc.cut(movies['length'], 3, ['short', 'mid', 'long'])
# 새로운 칼럼으로 추가해주세요
cate = pd.cut(movies['length'], threshold, labels=group_names )
movies['length_category'] = cate
movies
df = pd.read_excel("excel_exam.xlsx")
# 엑셀파일에서 class를 기준으로 과목과 점수를 정렬시켜 주세요.
df.melt(id_vars=['class'],
value_vars = ['math', 'science', 'english'],
var_name='과목', value_name='점수')338p 예제
data = pd.read_csv("https://raw.githubusercontent.com/wesm/pydata-book/3rd-edition/examples/macrodata.csv")
data.head()
# PeriodIndex : 시간 간격을 나타내기 위한 자료형
# 아래에서는 year과 quarter 컬럼을 합쳐서 새로운 이름을 붙여주였다.
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter, name='date')
columns = pd.Index(['realgdp', 'infl', 'unemp'], name='item')
data = data.reindex(columns=columns)
data.index = periods.to_timestamp('D', 'end')
ldata = data.stack().reset_index().rename(columns={0: 'value'})
ldata.pivot(index = 'date', columns = 'item', values = 'value')
ldata['value2'] = np.random.randn(len(ldata))
ldata.pivot(index='date', columns='item', values=['value', 'value2'])pivot
PeriodIndex
그래프 뽑기
import pydataset as py
tips = py.data('tips')
# crosstab : 교차 그래프
# 요일별 파티 숫자를 뽑고, 파티 숫자 대비 팁 비율을 보여주고 싶다.
party_counts = pd.crosstab(tips['day'], tips['size'])
party_counts
# size 1 2 3 4 5 6
# day
# Fri 1 16 1 1 0 0
# Sat 2 53 18 13 1 0
# Sun 0 39 15 18 3 1
# Thur 1 48 4 5 1 3
# 1인과 6인은 제외
# party_counts = party_counts.loc[:, 2:5]
# 각 로우의 합이 1이 되도록 정규화
party_pcts = party_counts.div(party_counts.sum(1), axis=0)
party_pcts
# size 1 2 3 4 5 6
# day
# Fri 0.052632 0.842105 0.052632 0.052632 0.000000 0.000000
# Sat 0.022989 0.609195 0.206897 0.149425 0.011494 0.000000
# Sun 0.000000 0.513158 0.197368 0.236842 0.039474 0.013158
# Thur 0.016129 0.774194 0.064516 0.080645 0.016129 0.048387
party_pcts.plot.bar()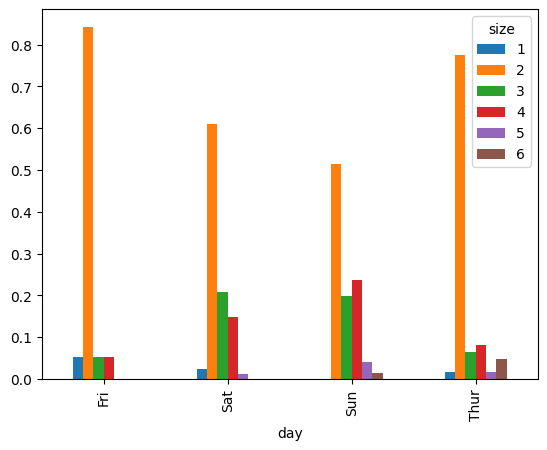
위 결과를 보면 알겠지만 matplot에서는 x축을 정해줘도 되지만, 기본적(자동)으로 x축은 index로 잡혀있다.
그리기 전에 요약을 해야하는 데이터는 seaborn 패키지를 이용하면 헐씬 간단히 처리 가능하다
# 팁 데이터 그리기
import seaborn as sns
tips['tip_pct'] = tips['tip']/(tips['total_bill'] - tips['tip'])
sns.barplot(x='tip_pct', y='day', data=tips)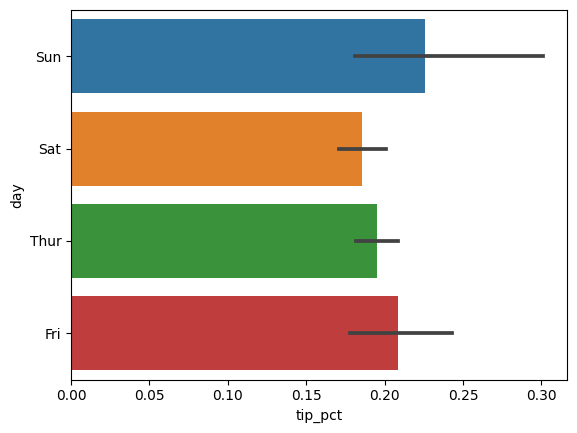
다양한 범주형 값을 가지는 데이터를 시각화하는 한가지 방법은 패싯 그리드를 이용한 것이다.. 는 seaborn 에서는 이제 factorplot을 사용하는 것보다 catplot을 사용하는 것을 권장하고 있다.
sns.catplot(x='day', y='tip_pct', hue='time', col='smoker',
kind='bar', data=tips[tips.tip_pct<1])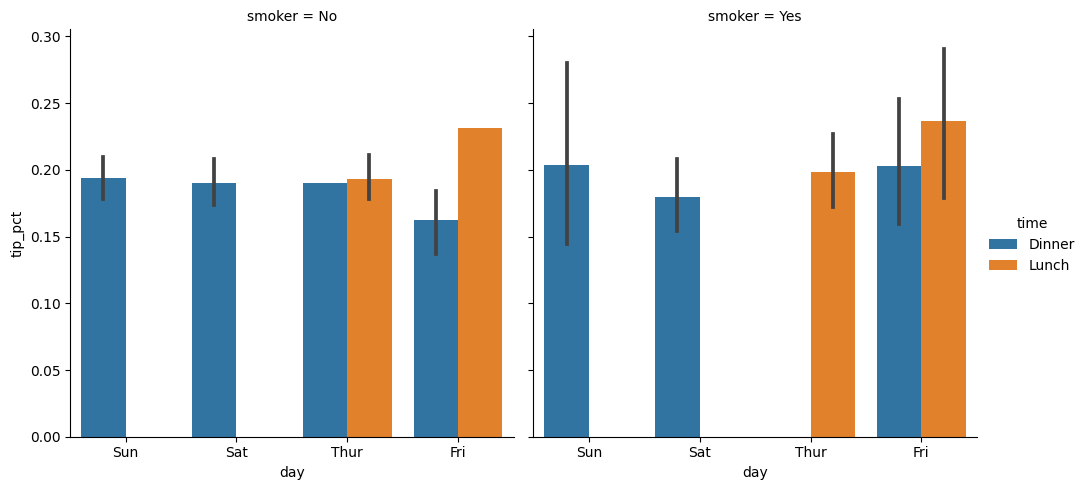
컬럼에 여러함수 적용하기
# 예시로 사용할 데이터 불러오기
import pydataset as py
tips = py.data('tips')
# 팁 비율을 담기위한 컬럼 하나 추가
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
# 컬럼에 여러함수 적용하기
# 예시로 사용할 데이터 불러오기
import pydataset as py
tips = py.data('tips')
# 팁 비율을 담기위한 컬럼 하나 추가
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
# 컬럼에 따라 다른 함수를 사용하여 집계를 수행하거나
# 여러 함수를 한번에 적용하기를 원한다면
# 칼럼 이름 : 함수, 칼럼 이름 : 함수
grouped.agg({'tip':np.max, 'size':np.min})
# 혹은 리스트 안에 묶어서 보낸다
# 아래는 세가지 통계를 동일하게 계산하겠다 넘겨준 것이다.
grouped.agg(['count', 'mean', 'max'])
# 만약 (name, function) 모양의 튜플리스트를 넘기면
# 각 튜플에서 첫원소가 DataFrame 에서 컬럼이름으로 사용된다.
grouped.agg([('foo', 'mean'), ('bar', np.std)])Apply
가장 일반적인 GroupBy 메서드의 목적은 apply 이다. 이 메서드는 객체를 여러 조각으로 나누고, 전달된 함수를 각 조각에 일괄 적용한 후 이를 다시 합친다.
# 특정 컬럼에서 가장 큰 값을 가지는 로우를 선택하는 사용자 함수
def max_row(df, n=5, column='tip_pct') :
return df.sort_values(by=column)[-n:]
# 기본값이 5로 잡혀있는 함수이지만, 6개를 뽑아내고 싶다면 아래처럼 따로 명시 가능
max_row(tips, n=6)
# total_bill tip sex smoker day time size tip_pct
# 110 14.31 4.00 Female Yes Sat Dinner 2 0.279525
# 184 23.17 6.50 Male Yes Sun Dinner 4 0.280535
# 233 11.61 3.39 Male No Sat Dinner 2 0.291990
# 68 3.07 1.00 Female Yes Sat Dinner 1 0.325733
# 179 9.60 4.00 Female Yes Sun Dinner 2 0.416667
# 173 7.25 5.15 Male Yes Sun Dinner 2 0.710345만약 이 사용자 함수를 위에서 만든 grouped에 적용시키고 싶다면 apply 안에 넣어주면 되는데, apply 메서드로 넘길 함수가 추가적인 인자를 받는다면 함수 이름 뒤에 붙여서 넘겨주면 된다.
# 특정 컬럼에서 가장 큰 값을 가지는 로우를 선택하는 사용자 함수
def max_row(df, n=5, column='tip_pct') :
return df.sort_values(by=column)[-n:]
grouped.apply(max_row, n=2)
# total_bill tip sex smoker day time size tip_pct
# day smoker
# Fri No 92 22.49 3.50 Male No Fri Dinner 2 0.155625
# 224 15.98 3.00 Female No Fri Lunch 3 0.187735
# Yes 222 13.42 3.48 Female Yes Fri Lunch 2 0.259314
# 94 16.32 4.30 Female Yes Fri Dinner 2 0.263480
# Sat No 21 17.92 4.08 Male No Sat Dinner 2 0.227679
# 233 11.61 3.39 Male No Sat Dinner 2 0.291990
# Yes 110 14.31 4.00 Female Yes Sat Dinner 2 0.279525
# 68 3.07 1.00 Female Yes Sat Dinner 1 0.325733
# Sun No 186 20.69 5.00 Male No Sun Dinner 5 0.241663
# 52 10.29 2.60 Female No Sun Dinner 2 0.252672
# Yes 179 9.60 4.00 Female Yes Sun Dinner 2 0.416667
# 173 7.25 5.15 Male Yes Sun Dinner 2 0.710345
# Thur No 89 24.71 5.85 Male No Thur Lunch 2 0.236746
# 150 7.51 2.00 Male No Thur Lunch 2 0.266312
# Yes 201 18.71 4.00 Male Yes Thur Lunch 3 0.213789
# 195 16.58 4.00 Male Yes Thur Lunch 2 0.241255이 결과를 보면 max_row 사용자 함수가 DataFrame의 각 부분에 모두 적용이 되었고, pandas.concat을 이용하여 하나로 합쳐진 다음 그룹 이름표가 붙었다. 결과적으로 계층적 색인을 가지게 되고, 내부 index는 DataFrame의 index값을 가지게 된다.
변위치 분석과 버킷 분석
pandas의 cut과 qcat메서드를 사용하여 선택한 크기만큼 혹은 표본 변위치에 따라 데이터를 나눌 수 있었다. 이 함수들을 groupby와 조합하면 데이터 묶음에 대해 변위치 분석 이나 버킷분석을 매우 쉽게 수행할 수 있다.
먼저 임의의 데이터 묶음을 cut을 이용해 등간격 구간으로 나눠보기
frame = pd.DataFrame({'data1':np.random.randn(1000),
'data2':np.random.randn(1000)})
quartiles = pd.cut(frame.data1, 4)
quartiles[:10]
# 0 (-2.072, -0.285]
# 1 (-0.285, 1.501]
# 2 (-0.285, 1.501]
# 3 (-0.285, 1.501]
# 4 (-2.072, -0.285]
# 5 (-0.285, 1.501]
# 6 (1.501, 3.288]
# 7 (-0.285, 1.501]
# 8 (-0.285, 1.501]
# 9 (-0.285, 1.501]
# Name: data1, dtype: category
# Categories (4, interval[float64, right]): [(-3.866, -2.072] < (-2.072, -0.285] < (-0.285, 1.501] < (1.501, 3.288]]cut에서 반환되는 건 category 객체이고, 이는 groupby로 바로 넘길수 있다. 그러므로 만약 data2 컬럼에 대한 몇가지 통계를 계산하고 싶다면 아래와 같이 해볼 수 있다.
def get_stats(group):
return{'min':group.min(), 'max':group.max(),
'count':group.count(), 'mean':group.mean()}
grouped = frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()
# min max count mean
# data1
# (-3.866, -2.072] -1.496580 1.541658 20.0 0.054825
# (-2.072, -0.285] -2.447100 3.037643 374.0 0.066839
# (-0.285, 1.501] -2.798966 2.928006 534.0 0.015219
# (1.501, 3.288] -2.793402 2.374199 72.0 -0.118767이렇게 등간격 버킷을 해봤다면 표본 변위치에 기반한, qcut을 이용한 크기가 같은 버킷도 계산해보자.
# lables = False를 넘겨서 구하겠다.
grouping = pd.qcut(frame.data1, 10, labels = False)
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()그룹에 따른 결측치 채우기
우락된 데이터를 정리할 때는 dropna를 사용하여 걸러내기도 하지만, fillna 메서드를 사용하여 평균값이나 고정된 값 등으로 채우는 경우도 있다.
# 임의의 값으로 s 생성 후 결측치 만들어주기
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s
# 0 NaN
# 1 -0.955049
# 2 NaN
# 3 1.538963
# 4 NaN
# 5 1.175806
# 결측치를 평균값으로 대체하겠다
s.fillna(s.mean())
# 0 -0.550804
# 1 1.059657
# 2 -0.550804
# 3 -2.952832
# 4 -0.550804
# 5 0.240764
# dtype: float64그룹별로 채워넣고 싶은 값이 다르다고 가정해보자. 데이터를 그룹으로 나누고 apply함수를 사용하여 각 그룹에 대해 fillna를 적용하면 된다.
# ['East']*4 : ['East'] 안에 있는 4 원소를 이어 붙인다.
group_key = ['East']*4 + ['West']*4
group_key
# ['East', 'East', 'East', 'East', 'West', 'West', 'West', 'West']
# 사용할 데이터 생성하기
states = ['Ohio', 'New York', 'Vermont', 'Florida',
'Oregon', 'Neveda', 'California', 'Idaho']
data = pd.Series(np.random.randn(8), index = states)
data
# Ohio 0.009396
# New York -2.293617
# Vermont 0.157365
# Florida -0.464273
# Oregon 1.601083
# Neveda -0.699348
# California -1.869271
# Idaho 1.821285
# dtype: float64
# 결측값 만들기
data[['Vermont', 'Neveda', 'Idaho']] = np.nan
data
# Ohio 0.637577
# New York -0.848165
# Vermont NaN
# Florida -1.685802
# Oregon 0.844560
# Neveda NaN
# California -2.863670
# Idaho NaN
# dtype: float64위에서 만들어준 group_key의 East West 가 순서대로 index(states)에 적용되어 나눠진대로 mean 평균값을 구해주었다.
data.groupby(group_key).mean()
# East -0.632130
# West -1.009555
# dtype: float64이 값으로 결측치를 채워보자
# 들어온 값(g)를 채워주는데 평균값(mean())으로 넣을것이다.
fill_mean = lambda g:g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
# Ohio 0.637577
# New York -0.848165
# Vermont -0.632130
# Florida -1.685802
# Oregon 0.844560
# Neveda -1.009555
# California -2.863670
# Idaho -1.009555
# dtype: float64그룹에 따라 미리 정의된 다른 값을 채워넣어야 할 경우도 있을것이다. 각 그룹은 내부적으로 name이라는 속성을 가지고 있으므로 이를 활용하면 가능하다
# 어떤 컬럼에 어떤 값을 넣을지 미리 정의한 후 담아준다.
fill_values = {'East' : 0.5, 'West':-1}
# 들어온 값(g)를 채워주는데, 미리 정의된 값(fill_values)을 넣어줄 것이다.
# 이때 괄호 안에는 컬럼 명이 들어가게된다.
fill_func = lambda g:g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)랜덤 표본과 순열(sample)
대용량의 데이터를 몬테카를로 시뮬레이션이나 다른 애플리케이션에서 사용하기 위해 랜덤 표본을 뽑아낼때, 뽑아내는 방법은 여러가지가 있겠지만 그 중 sample 메서드를 사용해보자.
몬테카를로 시뮬레이션
몬테카를로 메서드 혹은 다중 확률 시뮬레이션
불확실한 사건의 가능한 결과를 추정하는 데 사용되는 수학적 기법
# 예시를 위한 트럼프 카드 덱 만들기
# 하트 스페이스 클럽 다이아몬드
suits = ['H', 'S', 'C', 'D']
# 카드의 값
card_val = (list(range(1, 11)) + [10] * 3) * 4
# 카드 이름
base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']
cards = []
for suit in ['H', 'S', 'C', 'D'] :
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
deck
# AH 1
# 2H 2
# 3H 3
# 4H 4
# 5H 5
# 6H 6
# 7H 7
# 8H 8
# 9H 9
# ... 이하생략52장의 카드가 생성되었다. 이 카드들을 무작위로 뽑기 위해 sample을 사용한 사용자 함수draw를 생성한다.
def draw(deck, n=5) :
return deck.sample(n)
draw(deck)
# 9C 9
# 5C 5
# 2C 2
# 3S 3
# 6C 6
draw(deck, n=3)
# 6D 6
# 2H 2
# 5D 5
# dtype: int64각 세트별로 2장의 카드를 무작위로 뽑고 싶다면, 그룹을 나누고 apply를 사용하면된다.
# 마지막 글자에 세트 이름이 있으니 이를 뽑아주는 변수를 만들어준다
get_suit = lambda card:card[-1]
deck.groupby(get_suit).apply(draw, n=2)
# C KC 10
# 2C 2
# D 5D 5
# 8D 8
# H 3H 3
# 10H 10
# S 9S 9
# 2S 2
# dtype: int64