복습 문제
# pandas 에서는 index 문자가 가능 ox
o
arr = np.arange(12).reshape((3, 4))
arr1 = arr.copy()
# arr과 arr1을 축 따라 이어 붙여라
np.concatenate([arr, arr1])
# concat 사용
a = pd.DataFrame(arr)
b = pd.DataFrame(arr1)
pd.concat([a,b])
df = pd.DataFrame({'key1': ['a', 'a', 'b',' b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
# key1로 그룹을 묶고 각 그룹에서 data1의 평균을 구해보자
df.groupby('key1').mean()[['data1']]
# 추가
df.groupby('key1').agg('mean')['data1']
# titanic 데이터를 가져와서 class와 sex별로 그룹을 짓고, age의 인원수를 세주세요
import pydataset
titanic = pydataset.data('titanic')
titanic
titanic.groupby(['class', 'sex'])['age'].count()
# [추가]
titanic.groupby(['class', 'sex']).count()['age']
# 위 데이터로 아래와 같은 그래프를 그려주세요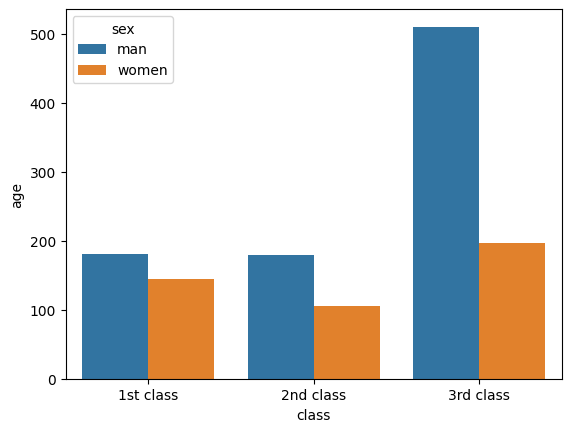
import seaborn as sns
df = titanic.groupby(['class','sex'])[['age']].count()
df.reset_index(inplace=True)
sns.barplot(data = df , x = 'class', y = 'age',hue='sex')
# titanic 데이터 프레임에서 class를 기준으로 나머지 열들을 정렬시켜주세요
# 칼럼명은 info로
titanic.melt(['class'], var_name='info')
# [추가]
titanic.melt(id_vars='class', var_name='info')
mpg = pydataset.data('mpg')
df = pd.crosstab(mpg['class'], mpg['manufacturer'])
df
# # 위 데이터프레임에서 제조사를 melt 시켜라
# 위 데이터프레임에서 제조사를 melt 시켜라
df.melt(value_vars = df.columns)
# manufacturer, year 별로 평균과 최대값을 구해보세요
import pydataset
mpg = pydataset.data('mpg')
mpg.groupby(['manufacturer', 'year']).agg([np.mean, max])
# mpg.groupby(['manufacturer', 'year']).agg(['mean', 'max'])
# displ은 최댓값, cyl은 합을 구해보세요
mpg.groupby(['manufacturer','year']).agg({'displ':max,'cyl':sum})
# [추가]
mpg.groupby(['manufacturer','year'])[['displ','cyl']]\
.agg(disp_max = ('displ','max'), cyl_sum = ('cyl', 'sum'))
# manufacturer, year로 그룹을 지어서 displ의 0.85분위수를 구하세요
mpg.groupby(['manufacturer','year'])[['displ']].quantile(.85) 피벗 테이블
pd.pivot_table(df, # 피벗할 데이터프레임
index = 'class', # 행 위치에 들어갈 열
columns = 'sex', # 열 위치에 들어갈 열
values = 'age', # 데이터로 사용할 열
aggfunc = 'mean') # 데이터 집계함수스페레드시트 프로그램과 그 외 다른 데이터 분석 소프트웨어에서 흔히 볼 수 있는 데이터 요약화 도구. 데이터를 하나 이상의 키로 수집해 어떤 키는 로우에, 어떤 키는 컬럼에 나열하며 데이터를 정렬한다.
pandas에서의 피벗테이블은 groupby기능을 사용하여 계층적 index를 활용한 연산을 가능하게 해주며, pivot_table 메서드는 마진이라고 하는 부분합을 추가할 수 있는 기능을 제공한다.
예시로, tips 데이터를 가져와 보자
tips = pydataset.data('tips')
# 요일과 흡연자 집단에서 평균을 구해보자
tips.groupby(['day', 'smoker']).agg('mean')위처럼 집단에서 계산을 하는 것은 groupby를 사용하여 쉽게 구할 수 있는데, pivot_table 을 사용하여 구할 수도 있다.
tips.pivot_table(index=['day', 'smoker'])계산 결과는 같다. 만약 tip_pct와 size에 대해서만 집계를 하고, 날짜별로 그룹을 지어보고싶다면
# tip_pct 컬럼 추가
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker')만약 어떤 조합이 비어있다면 (혹은 NA 값 이라면) fill_value를 넘길 수도 있다.
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns = 'day',
aggfunc='mean', fill_value=0)이처럼 그룹팅을 하지 않아도 계산값을 구해볼 수 있다. 또한 margins=True 를 넘겨서 자동으로 부분합 컬럼을 포함하도록 확장할 수 있다.
tips.pivot_table('tip_pct', index=['time', 'day'], columns='smoker', margins = True)
# smoker No Yes All
# time day
# Dinner Fri 0.139622 0.165347 0.158916
# Sat 0.158048 0.147906 0.153152
# Sun 0.160113 0.187250 0.166897
# Thur 0.159744 NaN 0.159744
# Lunch Fri 0.187735 0.188937 0.188765
# Thur 0.160311 0.163863 0.161301
# All 0.159328 0.163196 0.160803위 예시에서 All 컬럼과 로우가 추가되어 평균값을 구해준 모습을 확인해볼 수 있다. 다른 집계함수를 사용하려면 그냥 aggfunc를 넘기면 되는데, 예를 들어 count나 len함수는 그룹 크기의 교차일람표(총 개수나 빈도)를 반환한다.
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns = 'day')
# day Fri Sat Sun Thur
# time smoker
# Dinner No 0.139622 0.158048 0.160113 0.159744
# Yes 0.165347 0.147906 0.187250 NaN
# Lunch No 0.187735 NaN NaN 0.160311
# Yes 0.188937 NaN NaN 0.163863
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns = 'day', aggfunc = len, margins = True)
# day Fri Sat Sun Thur All
# time smoker
# Dinner No 3.0 45.0 57.0 1.0 106
# Yes 9.0 42.0 19.0 NaN 70
# Lunch No 1.0 NaN NaN 44.0 45
# Yes 6.0 NaN NaN 17.0 23
# All 19.0 87.0 76.0 62.0 244aggfunc = len, margins = True 을 추가하면서 All 컬럼과 로우에 교차일람표가 반환되었다.
피벗 테이블 옵션(420p)
함수 설명 values 집계하려는 컬럼 이름 혹은 이름의 리스트, 기본적으로 모든 숫자 컬럼을 집계한다. index 만들어지는 피벗테이블의 로우를 그룹으로 묶을 컬럼 이름이나 그룹 키 columns 만들어지는 피벗테이블의 컬럼을 그룹으로 묶을 컬럼 이름이나 그룹 키 aggfunc 집계함수나 함수 리스트, 기본값으로는 평균값(mean)이 사용된다. groupby컨텍스트 안에서 유효한 어떤 함수라도 가능하다 fill_value 결과 테이블에서 누락된 값을 대체하기 위한 값 dropna True인경우 **모든** 항목이 NA인 컬럼은 포함하지 않는다. margins 부분합이나 총계를 담기위한 로우/컬럼을 추가할지 여부, 기본값은 False ### 교차 일람표(혹은 교차표) 그룹 빈도를 계산하기 위한 피벗 테이블의 특수한 경우이다. 예시로 파악해보자.tips 테이블에서 시간과 흡연자에 따라 데이터를 요약해보고 싶다. 이때, groupby 혹은 pivot_table을 활용할 수도 있지만, pandas.croostab함수를 사용해 줄 수도 있다.
pd.crosstab(tips.time, tips.smoker)
# smoker No Yes
# time
# Dinner 106 70
# Lunch 45 23corsstab함수의 처음 두 인자는 배열이나 Series혹은 배열의 리스트가 될 수 있다.
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)
# smoker No Yes All
# time day
# Dinner Fri 3 9 12
# Sat 45 42 87
# Sun 57 19 76
# Thur 1 0 1
# Lunch Fri 1 6 7
# Thur 44 17 61
# All 151 93 244crosstab
범주형 변수를 기준으로 개수 파악이나 수치형 데이터를 넣어 계산할 때 사용한다.
# 예시 데이터 생성
a = ['2/18', '2/18', '2/18', '2/18', '2/20', '2/20', '2/20', '2/20', '2/25', '2/25', '2/25']
b = ['철수', '철수', '철수', '영희', '영희', '영희', '영희', '철수', '영희', '영희', '철수']
c = ['치킨', '피자', '닭발', '치킨', '닭발', '짜장면', '피자', '치킨', '피자', '치킨', '피자']
d = [1, 2, 1, 3, 4, 4, 2, 5, 3, 1, 3]
data = pd.DataFrame({'날짜':a, '사람':b, '음식':c, '개수':d})
data날짜별로 어떤 사람이 어떤 음식을 먹었나 궁금하다면 이런식으로 검색할 수 있다.
# pd.crosstab(index=, columns=)
pd.crosstab([data.사람, data.음식], data.날짜)데이터에 있는 수치형 데이터를 갯수로 계산하기 위해서는 aggfunc를 사용해 줄 수 있다.
pd.crosstab([data.사람, data.음식], data.날짜, values = data.개수)
# 오류
pd.crosstab([data.사람, data.음식], data.날짜, aggfunc=np.sum)
# 오류
pd.crosstab([data.사람, data.음식], data.날짜, values = data.개수, aggfunc=np.sum)
# O총합을 보고 싶다면 margins를 사용해볼 수 있다.
pd.crosstab(index = [data.사람, data.음식], columns = data.날짜, values = data.개수,
aggfunc = np.sum, margins = True)각 데이터의 이름을 바꾸려면 rownames, colnames, margins_name을 사용해 볼 수 있다.
pd.crosstab(index = [data.사람, data.음식], columns = data.날짜,
rownames = ['people', 'food'], colnames = ['data'])
pd.crosstab(index = [data.사람, data.음식], columns = data.날짜, values = data.개수, aggfunc = np.sum,
rownames = ['people', 'food'], colnames = ['data'], margins_name='total')총 합을 1로 만들는 정규화를 하고 싶다면 nomalize 옵션을 True로 켜주면 된다.
pd.crosstab(index = [data.사람, data.음식], columns = data.날짜, values = data.개수, aggfunc = np.sum,
normalize = True)시계열
시간상의 여러 지점을 관측하거나 측정할 수 있는 모든 것을 시계열이라 하며, 대부분은 고정빈도(fixed frequency)로 표현되는데 데이터가 존재하는 지점이 특정 규칙 (15초 마다, 1분마다, 1년마다)에 따라 고정 간격을 가지게 된다.
하지만 고정단위나 시간 혹은 단위들간의 간격으로 존재하지 않고 불규칙적인 모습으로 표현될 수도 이쓴데, 이런 시계열데이터를 어떻게 표시하고 참조할 지는 애플리케이션에 의존적이다.
pandas는 표준 시계열 도구와 데이터 알고리즘을 제공한다.
날짜, 시간 자료형, 도구
날짜와 시간을 위한 자료형, 달력 관련 기능을 제공하는 자료형이 존재한다. datetime, time, calendar 모듈을 활용하여 예시를 보자
from datetime import datetime
now = datetime.now()
now
# datetime.datetime(2022, 9, 30, 11, 14, 42, 168664)
now.year, now.month, now.day
# (2022, 9, 30)
# 크리스마스까지 남은 시간 알아보기
cristmas = datetime(2022, 12, 25)
delta = cristmas - now
delta
# datetime.timedelta(days=85, seconds=45858, microseconds=454696)datetime은 날짜와 시간을 모두 저장하여 마이크로초까지 지원한다. 또한 수 계산이 가능하기 때문에 객체 간의 시간적인 차이를 표현할 수도 있다.
datetime의 자료형(425p)
| 자료형 | 설명 |
|---|---|
| date | 그레고리안 달력을 사용하여 날짜(연, 월, 일)을 저장 |
| time | 하루의 시간을 시, 분, 초, 마이크로초 단위로 저장 |
| datetime | 날짜와 시간을 저장한다. |
| timedelta | 두 datetime값 간 차이(일, 초, 마이크로초)를 표현한다. |
| tzinfo | 지역시간대를 저장하기 위한 기본 자료형 |
Datetime 포맷 규칙(문자열⇄datetime)
datetime 객체와 timestamp 객체는 str메서드나 strftime메서드에 포맷 규칙을 넘겨서 문자열로 변환할 수 있다.
now.strftime('%Y-%m-%d')
# '2022-09-30'
type(now.strftime('%Y-%m-%d'))
# str포멧 규칙
| 포멧 | 설명 |
|---|---|
| %Y | 4자리 연도 |
| %y | 2자리 연도 |
| %m | 2자리 월[01. 12] |
| %d | 2자리 일[01, 31] |
| %H | 24시간 형식[00, 23] |
| %I | 12시간 형식[01, 12] |
| %M | 2자리 분[00, 59] |
| %S | 초[00, 61](60, 61은 윤초) |
| %w | 정수로 나타낸 요일[0(일), 6[토]] |
| %U | 연중주차[00, 53] 일요일을 그 주의 첫번째 날로 간주하며, 그 해에서 첫번째 일요일 앞에 있는 날은 0주차가 된다. |
| %W | 연중주차[00, 53] 월요일을 그 주의 첫번째 날로 간주하며, 그 해에서 첫번째 월요일 앞에 있는 날은 0주차가 된다. |
| %z | UTC시간대 오프셋을 +HHMM 혹은 -HHMM 으로 표현한다. 만약 시간대를 신경 쓰지 않는다면 비워둔다. |
| %F | %Y-%m-%d 형식에 대한 축양(예:2012-04-18) |
| %D | %m/%d/%y 형식에 대한 축약(예:04/18/12) |
이 포맷코드로 datetime.strptime을 사용하여 문자열을 날짜로 변환해보자.
value = '2011-01-03'
datetime.strptime(value, '%Y-%m-%d')
# datetime.datetime(2011, 1, 3, 0, 0)
type(value)
# str
type(datetime.strptime(value, '%Y-%m-%d'))
# datetime.datetime값이 꼭 하나여야 하는 것은 아니다. 리스트 형식으로 여러개를 한번에 넣어줄 수도 있다.
datestr = ['7/6/2011', '8/6/2011']
type(datestr)
# list
[datetime.strptime(x, '%m/%d/%Y') for x in datestr]
# [datetime.datetime(2011, 7, 6, 0, 0), datetime.datetime(2011, 8, 6, 0, 0)]datetime.strptime은 알려진 형식의 날짜를 파싱하기에는 최적의 방법이지만 매번 포맷 규칙을 써야하는 건 귀찮은 일이기 때문에.. 서드파티 패키지인 dateuitl에 포함된 parser.parse메서드를 사용하기도 한다.
from dateutil.parser import parse
parse('2011-01-03')
# datetime.datetime(2011, 1, 3, 0, 0)dateutil은 사람이 인지하는 날짜 표현 방식의 대부분을 파싱할 수 있다.
parse('Jan 31, 1997 10:45 PM')
# datetime.datetime(1997, 1, 31, 22, 45)
parse('6/12/2022', dayfirst=True)
# datetime.datetime(2022, 12, 6, 0, 0)to_datetime 메서드는 많은 종류의 날짜 표현을 한번에 받아 처리할 수 있다.
datestrs = ['2011-07-06 12:00:00', '2022-08-17 00:00:00']
pd.to_datetime(datestr)
# DatetimeIndex(['2011-07-06', '2011-08-06'], dtype='datetime64[ns]', freq=None)
# 누락된 값으로 간주될만한 값들(None, ' ') 도 오류를 내뱉지 않는다.
idx = pd.to_datetime(datestrs + [None])
idx
# DatetimeIndex(['2011-07-06 12:00:00', '2022-08-17 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None)
idx[2]
# NaT
type(idx[2])
# pandas._libs.tslibs.nattype.NaTType
pd.isnull(idx)로케일별 날짜 포멧
| 포멧 | 설명 |
|---|---|
| %a | 축약된 요일 이름 |
| %A | 요일 이름 |
| %b | 축약된 월 이름 |
| %B | 월이름 |
| %c | 전체 날짜와 시간(예:'Tue 01 May 2012 04:20:57 PM') |
| %p | 해당 로케일에서 AM, PM에 대응되는 이름(오전, 오후) |
| %x | 로케일에 맞는 날짜 형식(예:미국이라면 2012년 5월 1일 = '05/01/2012') |
| %X | 로케일에 맞는 시간 형식(예:'04:24:12 PM') |
시계열 기초
pandas에서 찾아볼 수 있는 가장 기본적인 시계열 객체의 종류는 파이썬 문자열이나 datetime객체로 표현되는 (타임 스탬프로 index된)Series 이다.
to_range를 활용하여 날짜가 모인 리스트를 먼저 만들어줘보자
dates = pd.date_range('1/1/2000', '1/6/2000')
dates
# DatetimeIndex(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04',
# '2000-01-05', '2000-01-06'],
# dtype='datetime64[ns]', freq='D')
ts = pd.Series(np.random.randn(6), index = dates)
ts
# 2000-01-01 0.483042
# 2000-01-02 0.392641
# 2000-01-03 0.260485
# 2000-01-04 0.594300
# 2000-01-05 -0.396060
# 2000-01-06 0.151920
# Freq: D, dtype: float64
ts.index
# DatetimeIndex(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04',
# '2000-01-05', '2000-01-06'],
# dtype='datetime64[ns]', freq='D')날짜가 index로 난수가 값으로 들어간 Series가 생성되었다. 내부적으로 보면 이들 datetime객체는 DatetimeIndex에 들어있으면 새로 만들어진 ts 변수의 타입은 TimeSeries이다. 이는 다른 Series와 마찬가지로 서로 다르게 index된 객체간의 산술연산은 자동으로 날짜에 맞추진다.
# ts와 2단위로 슬라이싱된 ts의 계산
ts + ts[::2]
# 2000-01-01 -0.690855
# 2000-01-02 NaN
# 2000-01-03 4.318800
# 2000-01-04 NaN
# 2000-01-05 -1.015993
# 2000-01-06 NaN
# dtype: float64index 선택, 부분선택
시계열은 라벨에 기반하여 데이터를 선택하고 indexing 할때 Series와 동일하게 동작한다.
stamp = ts.index[2]
stamp # Timestamp('2000-01-03 00:00:00', freq='D')
ts[stamp] # 2.1594001707867148
ts['2000-01-01']
# -0.34542764339194565특정 구간만 넘겨서 데이터를 검색할 수도 있다.
dates = pd.date_range('1/1/2000', '10/1/2000', freq='1m')
dates
# DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-30',
# '2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
# '2000-09-30'],
# dtype='datetime64[ns]', freq='M')
ts = pd.Series(np.random.randn(9), index = dates)
ts['2000-03']
# 2000-03-31 0.068707
# Freq: M, dtype: float64이때 검색은 [연] 혹은 [연, 월]의 형태로 넘겨야 하며. [월]의 형태로는 검색되지 않는 듯 하다.
대부분의 시계열 데이터는 타임스탬프를 이용하여 Series를 나눌 수 있다.
ts['31/1/2000' : '30/4/2000']
# 2000-01-31 0.140722
# 2000-02-29 -0.267278
# 2000-03-31 0.068707
# 2000-04-30 0.856962
# Freq: M, dtype: float64to_range
함수의 기본적인 사용법은 첫 번째 전달인자를 시작날짜, 두번째 전달인자를 종료날짜로 입력하면 된다. 이렇게 하면 시작하는 일부터 종료일까지 매일의 날짜를 생성
pd.date_range('2022-09-30', '2022-10-10')
# DatetimeIndex(['2022-09-30', '2022-10-01', '2022-10-02', '2022-10-03',
# '2022-10-04', '2022-10-05', '2022-10-06', '2022-10-07',
# '2022-10-08', '2022-10-09', '2022-10-10'],
# dtype='datetime64[ns]', freq='D')(년-월-일) 같은 형식 뿐 아니라 년/월/일 혹은 월/일/년 과 같은 다양한 날자 입력형태를 지원하기 때문에 원하는 형식을 선택하여 날짜 생성이 가능하다. datetime 모듈의 datetime 자료형도 지원한다.
from datetime import datetime
from datetime import timedelta
now = datetime.now()
in_two_weeks = now+timedelta(weeks=2)
pd.date_range(datetime.now(), in_two_weeks)빈도를 설정하기 위해서는 freq 변수를 사용해 줄 수 있다. 'D'는 일자를 'M'을 월 'Y'는 년도를 나타내며 'H'와 같이 시간을 빈도로 사용할 수도 있다.
# 3일 단위로 뽑고 싶다.
pd.date_range('2020-10-07', '2020-10-20', freq='3D')
# DatetimeIndex(['2020-10-07', '2020-10-10', '2020-10-13', '2020-10-16',
# '2020-10-19'],
# dtype='datetime64[ns]', freq='3D')
pd.date_range('2020-9-07', '2020-12-20', freq='M')
# DatetimeIndex(['2020-09-30', '2020-10-31', '2020-11-30'], dtype='datetime64[ns]', freq='M')
pd.date_range('2020-12-07', '2020-12-20', freq='5H')
# DatetimeIndex(['2020-12-07 00:00:00', '2020-12-07 05:00:00',
# '2020-12-07 10:00:00', '2020-12-07 15:00:00',
# '2020-12-07 20:00:00', '2020-12-08 01:00:00',
# '2020-12-08 06:00:00', '2020-12-08 11:00:00',
# '2020-12-08 16:00:00', '2020-12-08 21:00:00',
# ... 이하 생략또 하나 자주 사용되는 매개변수는 periods 이다. 이는 시작 날짜와 종료날짜를 periods 매개변수에 전달된 기간만큼 동일하게 나누어 출력해준다.
# 기간이 5개의 날짜로 나뉘어 출력된 것을 확인
pd.date_range(start='2022-10-01', end='2022-10-20', periods=10)
# DatetimeIndex(['2022-10-01 00:00:00', '2022-10-03 02:40:00',
# '2022-10-05 05:20:00', '2022-10-07 08:00:00',
# '2022-10-09 10:40:00', '2022-10-11 13:20:00',
# '2022-10-13 16:00:00', '2022-10-15 18:40:00',
# '2022-10-17 21:20:00', '2022-10-20 00:00:00'],
# dtype='datetime64[ns]', freq=None)중복된 색인을 가지는 시계열 데이터
시계열 데이터와 같은 경우에는 여러 데이터가 특정 타임스탬프에 몰려있는 모습을 왕왕 발견할 수 있다.
# 예시로 사용할 데이터
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
'1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts
# 2000-01-01 0
# 2000-01-02 1
# 2000-01-02 2
# 2000-01-02 3
# 2000-01-03 4
# dtype: int32먼저 is_unique 속성을 이용하면 색인이 유일한가 확인해 볼수 있는데. 위 데이터는 유일하지 않기때문에 False가 출력될 것이다.
dup_ts.index.is_unique
# False이 시계열 데이터를 인덱싱하면 중복 여부에 따라 슬라이스가 다르게 생성된다.
dup_ts['1/3/2000']
# 4
dup_ts['1/2/2000']
# 2000-01-02 1
# 2000-01-02 2
# 2000-01-02 3
# dtype: int32날짜 범위, 빈도, 이동
일반적인 시계열은 pandas에서 불규칙적인 것으로 간주된다. 즉 고정된 빈도를 가지지 않는다는 것이다. pandas에는 리샘플링, 표준 시계열 빈도 모음, 빈도추록 그리고 고정된 빈도의 날짜 범위를 위한 도구가 있다. 아래 예시를 보자
ts
# 2000-01-31 0.140722
# 2000-02-29 -0.267278
# 2000-03-31 0.068707
# 2000-04-30 0.856962
# 2000-05-31 0.304651
# 2000-06-30 -1.041304
# 2000-07-31 -1.172663
# 2000-08-31 -0.350149
# 2000-09-30 -0.264990
# Freq: M, dtype: float64
resampler = ts.resample('D')문자열 'D'는 '일'로 해석되며 ts 데이터를 고정된 일 빈도로 변환하기 위해 resample 메서드를 사용한 것이다.
데이터 시프트
shift는 시간 축에서 앞이나 뒤로 이동하는 것을 의미한다. Series와 DataFrame은 index를 변경하지 않고 데이터 자체만 앞이나 뒤로 느슨하게 움직이는 shift 메서드를 가지고 있다.
ts = pd.Series(np.random.randn(4),
index=pd.date_range('1/1/2000', periods=4, freq='M'))
ts
# 2000-01-31 0.316513
# 2000-02-29 -2.485310
# 2000-03-31 -0.522996
# 2000-04-30 1.285127
# Freq: M, dtype: float64
ts.shift(2)
# 2000-01-31 NaN
# 2000-02-29 NaN
# 2000-03-31 -1.774875
# 2000-04-30 2.174596
# Freq: M, dtype: float64
ts.shift(-1)
# 2000-01-31 0.449687
# 2000-02-29 0.290666
# 2000-03-31 -0.012018
# 2000-04-30 NaN
# Freq: M, dtype: float64위처럼 shift를 하게 되면 시계열의 시작이나 끝 지점에 결측치가 발생하게 된다.
ts / ts.shift(1) -1
# 2000-01-31 NaN
# 2000-02-29 -1.375435
# 2000-03-31 -0.353626
# 2000-04-30 -1.041345
# Freq: M, dtype: float64shift는 일반적으로 한 시계열 내에서 혹은 DataFrame 내에서 컬럼으로 표현할 수 있는 여러 시계열에서의 퍼센트 변화를 계산할 때 흔히 사용하며, 코드로는 위와 같이 표현하여 사용한다.
빈도를 알고 있다면 shift에 빈도를 넘겨 타임스탬프가 확장되도록 할 수도 있다.
ts.shift(2, freq='M')
# 2000-03-31 -1.197776
# 2000-04-30 0.449687
# 2000-05-31 0.290666
# 2000-06-30 -0.012018
# Freq: M, dtype: float64리샘플링
시계열의 빈도를 변환하는 과정을 일컫는다. 상위 빈도의 데이터를 하위 빈도로 집계하는 것을 다운샘플링 이라하며 반대과정을 업샘플링이라고 한다. pandas 에서는 resample 메서드를 가지고 있는데, 빈도변환과 관련된 모든 작업에서 유용하게 사용되는 메서드이다. groupby 메서드와 같이 데이터를 그ㅜㅂ짓고 요약함수를 적용하는 식이다.
# 데이터 생성
rng = pd.date_range('2000-01-01', periods = 100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index = rng)
ts만약 월(M)별로 그룹을 지어 평균값을 계산하고 싶다면 아래와 같이 계산할 수 있다.
ts.resample('M').mean()
# 2000-01-31 -0.150589
# 2000-02-29 0.130844
# 2000-03-31 -0.196888
# 2000-04-30 -0.132901
# Freq: M, dtype: float64다운 샘플링
시계열 데이터를 규칙적인 하위 빈도로 집계하는 일은 특별한 것이 아니다. 집게할 데이터는 고정 빈도를 가질 필요가 없으며 잘라낸 시계열 데이터의 조각 크기를 원하는 빈도로 정의한다.
resample 사용하여 데이터를 다운 샘플링할 때 고려해야할 사항은 두가지이다
- 각 간격의 양끝 중에서 어느 쪽을 닫아줄 것인가?
- 집계하려는 구간의 라벨을 간적의 시작으로 할지 끝으로 할지예시로 조금 더 알아보자
rng = pd.date_range('2000-01-01', periods=12, freq='T')
ts = pd.Series(np.arange(12), index=rng)
ts
# 2000-01-01 00:00:00 0
# 2000-01-01 00:01:00 1
# 2000-01-01 00:02:00 2
# 2000-01-01 00:03:00 3
# 2000-01-01 00:04:00 4
# 2000-01-01 00:05:00 5
# 2000-01-01 00:06:00 6
# 2000-01-01 00:07:00 7
# 2000-01-01 00:08:00 8
# 2000-01-01 00:09:00 9
# 2000-01-01 00:10:00 10
# 2000-01-01 00:11:00 11
# Freq: T, dtype: int32이 예시 데이터를 5분 단위로 묶어서 각 그룹의 합을 집계하고 싶다면 아래와 같이 할 수 있다.
ts.resample('5min', closed='right').sum()
# 1999-12-31 23:55:00 0
# 2000-01-01 00:00:00 15
# 2000-01-01 00:05:00 40
# 2000-01-01 00:10:00 11
# Freq: 5T, dtype: int32
ts.resample('5min', closed='left').sum()
# 2000-01-01 00:00:00 10
# 2000-01-01 00:05:00 35
# 2000-01-01 00:10:00 21
# Freq: 5T, dtype: int32여기서 인자로 넘긴 빈도('5min')는 5분 단위로 증가하는 그룹의 경계를 정의한다. 기본적으로 시작값을 그룹의 왼쪽에 포함시키는데, closed=right를 명시하면 시작값을 그룹의 오른쪽에 포함시킨다. 위의 결과값으로 비교해보자.
OHLC 리샘플링
금융분야에서 시계열 데이터를 집계하는 아주 흔한 방식은 각 버킷에 대해 4가지 값(시가 고가 저가 종가)를 계산하는 것이다. 이를 OHLC라고 하며 how='ohlc'를 넘겨서 한번에 이 값을 담고있는 DataFrame을 얻을 수 있다.
ts.resample('5min').ohlc()
# open high low close
# 2000-01-01 00:00:00 0 4 0 4
# 2000-01-01 00:05:00 5 9 5 9
# 2000-01-01 00:10:00 10 11 10 11업샘플링과 보간
하위 빈도에서 상위 빈도로 변환할 때는 집계가 필요하지 않다.
# 예시로 사용할 DataFrame 생성
frame = pd.DataFrame(np.random.randn(2, 4),
index=pd.date_range('1/1/2000', periods = 2, freq = 'W-WED'),
columns = ['Colorado', 'Texas', 'New York', 'Ohio'])
frame
# Colorado Texas New York Ohio
# 2000-01-05 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-12 -0.422656 -0.678607 -0.652662 0.826493위 데이터에 요약함수를 사용하면 그룹당 하나의 값이 들어가고 그 사이에 결측치가 들어간다. asfreq 메서드를 이용하여 어떤 요약함수도 사용하지 않고 상위 빈도로 리샘플링해보자
df_daily = frame.resample('D').asfreq()
df_daily
# Colorado Texas New York Ohio
# 2000-01-05 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-06 NaN NaN NaN NaN
# 2000-01-07 NaN NaN NaN NaN
# 2000-01-08 NaN NaN NaN NaN
# 2000-01-09 NaN NaN NaN NaN
# 2000-01-10 NaN NaN NaN NaN
# 2000-01-11 NaN NaN NaN NaN
# 2000-01-12 -0.422656 -0.678607 -0.652662 0.826493값이 자동으로 설정한 일자('D')별로 늘어난 것을 확인 할 수 있다. 데이터가 없던 요일에는 모두 NaN이 들어가 있다. 만약 비어있는 값들을 채우고 싶다면 아래와 같이 할 수 있다
frame.resample('D').ffill()
# Colorado Texas New York Ohio
# 2000-01-05 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-06 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-07 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-08 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-09 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-10 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-11 -0.973326 1.128379 0.208500 -0.813392
# 2000-01-12 -0.422656 -0.678607 -0.652662 0.826493앞에 있는 값이 아래로 쭉 들어간 것을 확인할 수 있다. fillna와 reindex메서드에서 사용했던 보간 메서드를 리샘플링에서도 사용할 수 있다.
Categorical 데이터
컬럼 내에 특정 값이 반복되어 존재하는 경우는 흔하다.
import numpy as np
import pandas as pd
values = pd.Series(['apple', 'orange', 'apple',
'apple'] * 2)
values.unique()
# array(['apple', 'orange'], dtype=object)
values.value_counts()
# apple 6
# orange 2
# dtype: int64
values = values.astype('category')
values
# 0 apple
# 1 orange
# 2 apple
# 3 apple
# 4 apple
# 5 orange
# 6 apple
# 7 apple
# dtype: category
# Categories (2, object): ['apple', 'orange']위 예시와 같이 중복되어 만든 후 category형으로 변환할 수도 있겠지만, 데이터웨어하우스의 경우 구별되는 값을 담고있는 차원테이블과 그 테이블을 참조하는 정수키를 사용하는 것이 일반적이다.
values = pd.Series([0, 1, 0, 0] * 2)
dim = pd.Series(['apple', 'orange'])
dim
# 0 apple
# 1 orange
# dtype: object
values_1 = dim.take(values)
values_1
# 0 apple
# 1 orange
# 0 apple
# 0 apple
# 0 apple
# 1 orange
# 0 apple
# 0 apple
# dtype: objecttake메서드를 사용하면 Series 내에 저장된 원래 문자열을 구할 수 있다. 여기서 정수로 표현된 값은 범주형 또는 사전형 표기법이라고 한다. 별개의 값을 담고있는 배열은 범주, 사전 또는 단계 데이터라호 부른다. 번주형 데이터를 가리키는 정수값은 범주코드 혹은 코드 라고 표현한다.
pandas의 Categorical
pandas에는 정수기반의 범주형 데이터를 표현(혹은 인코딩) 할 수 있는 Categorical 형이라는 특수 데이터형이 존재한다.
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)
df = pd.DataFrame({'fruit': fruits,
'basket_id': np.arange(N),
'count': np.random.randint(3, 15, size=N),
'weight': np.random.uniform(0, 4, size=N)},
columns=['basket_id', 'fruit', 'count', 'weight'])
df
# basket_id fruit count weight
# 0 0 apple 6 1.540141
# 1 1 orange 14 0.501853
# 2 2 apple 7 0.906206
# 3 3 apple 9 1.335428
# 4 4 apple 8 0.121256
# 5 5 orange 6 2.443048
# 6 6 apple 6 1.654848
# 7 7 apple 6 0.742091이 예제에서 df['fruit']는 문자열 객체의 배열로, 범주형 데이터로 변경하려면 아래와 같이 할 수 있다.
fruit_cat = df['fruit'].astype('category')
fruit_cat
# 0 apple
# 1 orange
# 2 apple
# 3 apple
# 4 apple
# 5 orange
# 6 apple
# 7 apple
# Name: fruit, dtype: category
# Categories (2, object): ['apple', 'orange']Categorical 객체는 categories와 codes 속성을 가진다.
c = fruit_cat.values
type(c)
# pandas.core.arrays.categorical.Categorical
c.categories
# Index(['apple', 'orange'], dtype='object')
c.codes
# array([0, 1, 0, 0, 0, 1, 0, 0], dtype=int8)기존에 정의된 범주와 범주 코드가 있다면 from_codes 함수를 이용하여 범주형 데이터를 생성하는 것도 가능하다
categories = ['apple', 'orange']
codes = [0, 1, 0, 0, 0, 1, 0, 0]
pd.Categorical.from_codes(codes, categories)
# ['apple', 'orange', 'apple', 'apple', 'apple', 'orange', 'apple', 'apple']
# Categories (2, object): ['apple', 'orange']범주형으로 변경하는 경우 명시적으로 지정하지 않는 한 특정 순서를 보장하지 않는다. 따라서 categories 배열은 입력 데이터의 순서에 따라 다른 순서로 나타낼 수 있다. from_codes를 사용하거나 다른 범주형 데이터 생성자를 이용하는 경우 순서를 지정하기 위해서는 아래와 같이 할 수 있다.
categories = ['apple', 'orange']
codes = [0, 1, 0, 0, 0, 1, 0, 0]
pd.Categorical.from_codes(codes, categories, ordered = True)
# ['apple', 'orange', 'apple', 'apple', 'apple', 'orange', 'apple', 'apple']
# Categories (2, object): ['apple' < 'orange']위 결과를 보면 ['apple' < 'orange'] 부분이 있는 것이 보일 것이다.