복습문제
# 의사결정나무는 분류와 회귀 모두 가능하다
o
# 지니지수 불순도 : 불순도를 측정해주세요
# 전체 16개 중 빨간색 10개 파란색 6개
1 - pow((10/16), 2) - pow((6/16), 2)
# 0.46875
# 불순도를 측정하는 대표적 방법 2가지를 써주세요
지니지수, 정보이득
# 불순도가 0.5에서 0.4로 낮아질 때, 0.1만큼 ( )이 있다고 말한다.
정보이득, 정보획득
information gain
# 아래 파라미터들에 대한 설명
min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터 수
min_samples_leaf : 왼쪽과 오른쪽의 브랜치 노드에서 가져야 할 최소한의 샘플 데이터 수
max_depth : 최대 깊이
max_leaf_nodes : 말단 노드(Leaf)의 최대 개수
max_features : 최적의 분할을 위한 최대 피처 갯수
# ( )는(은) 학습 데이터에 대해 과하게 학습하는 바람에 적절한 일반화를 하지못해 실제 데이터에 대한
# 오차가 증가하는 현상으로, 의사결정트리에서 이를 방지하기 위해서는
# 가지치기(pruning) 작업을 한다.
과적함
# 싸이킷런 분류 알고리즘에서 predict 할때 각 label 의 확률을 보여주는 메서드는 무엇인가요
predict_proba
from sklearn.datasets import load_wine
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
dt_clf = DecisionTreeClassifier()
wine = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target)
dt_clf.fit(X_train, y_train)
# 위 코드의 결과 중, 중요한 피처 3가지를 구해보세요
import seaborn as sns
import numpy as np
%matplotlib inline
print('Feature importances:\n'.format(np.round(dt_clf.feature_importances_, 3)))
for name, value in zip(wine.feature_names, dt_clf.feature_importances_) :
print(f'{name} : {value:.3f}')
sns.barplot(x = dt_clf.feature_importances_, y = wine.feature_names)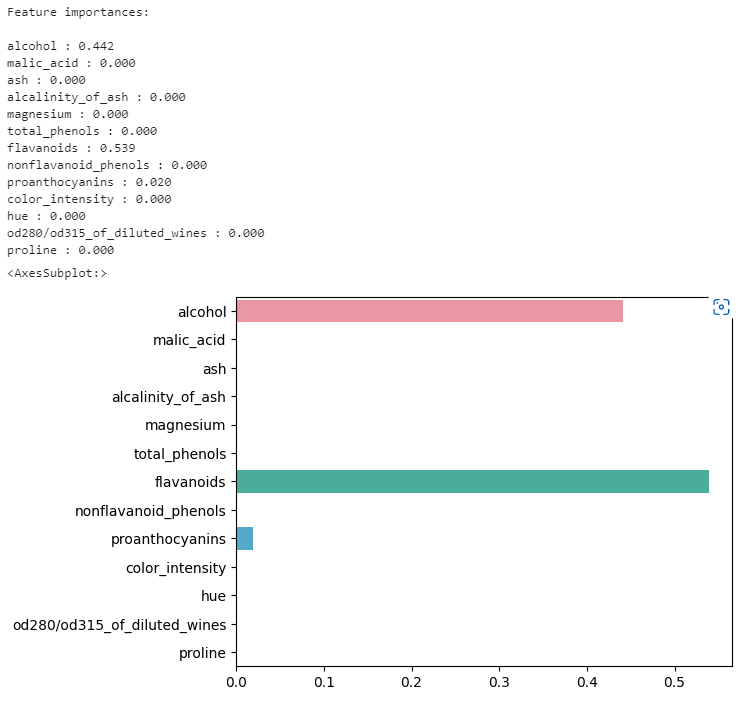
# [추가답변]
best = pd.DataFrame(index = wine.feature_names , data= dt_clf.feature_importances_,columns=['pct'])
best.sort_values(by ='pct',ascending=False)[:3] 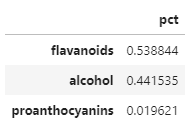
# 결정트리의 깊이(depth)가 깊을 수록 예측 성능이 좋다
x
# 의사결정나무는 스케일이나 평균을 원점에 맞추는 것과 같은 데이터 전처리가 거의 필요하지 않다
o
# 결정트리에서는 지니계수가 낮을수록 데이터의 균일도가 높은것으로 해석한다
o(위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다.)
앙상블 학습
여러개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 하는 기법. 전통적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 세 가지로 나눌 수 있으며, 이외에도 스태킹을 포함한 다양한 앙상블 학습 방법이 있다.
보팅(Voting): 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식으로, 일반적으로 서로 다른 알고리즘의 분류기를 결합한다. 크게 하드보팅과 소프트보팅으로 유형을 나눠볼 수 있다.
-하드보팅: 다수결의 원칙과 비슷하게 다수의 분류기가 결정한 예측값을 최종 결과값으로 선정
-소프트보팅: 분류기들의 레이블 값 결정확률을 모두 (1끼리/0끼리 각각) 더해 이를 평균내어 가장 높은 결과를 선정하는 방법
→ 일반적으로 소프트보팅의 예측성능이 더 뛰어나 더 많이 사용된다.
배깅(Bagging): 보팅과 마찬가지로 여러 분류기를 통해 최종 예측 결과를 결정하지만, '동일한 분류기'로 데이터 샘플링만 서로 다르게 가져가면서 학습을 수행한다. 데이터 샘플링 방식은 '부트스트래핑(Bootstrapping)이며 교차 검증과는 다르게 데이터의 중복이 허용된다. 랜덤 포레스트가 대표적인 방식이다.
부스팅(Bossting): 여러개의 분류기가 순차적으로 학습을 수행하지만, 먼저 학습한 분류기에서 예측이 틀린 데이터에 대해 (올바르게 예측할 수 있도록) 추가적인 가중치를 부여하면서 학습과 예측을 진행한다. 대표적인 방식으로는 GBM(Gradient Boosting Machine), XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)이 있다.
ML 모델의 성능은 다양한 테스트 데이터에 의해 검증되므로 '어떻게 높은 유연성을 가지고 현실에 대처할 수 있는가'가 중요한 평가요소가 된다.
Voting 예제(유방암 데이터 셋)
사이킷 런은 보팅방식의 앙상블을 구현한 VotingClassifier 클래스를 제공하고 있다. 이것을 이용하여 위스콘신 유방암 데이터 세트를 예측/분석해보기로 하자.
데이터 및 모듈 불러오기
import pandas as pd
import numpy as np
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
data_df[:3]
Voting 분류기 생성 및 이용
로지스틱 회귀와 KNN을 기반으로 하여 소프트 보팅 방식으로 보팅 분류기를 만들어보자. VotingClassifier 클래스를 이용하여 생성할 수 있다.
# 개별 모델은 로지스틱 회귀와 KNN
lr_clf = LogisticRegression(solver = 'liblinear')
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
# estimators에 리스트 값으로 Classifier 객체들을 튜플 형식으로 입력
# voting 옵션에 hard 기입시 하드보딩 / soft 기입시 소프트 보딩 / 디폴트 값은 hard이다.
vo_clf = VotingClassifier(estimators=[('LR', lr_clf), ('KNN', knn_clf)], voting='soft')
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=11)
# VotinVotingClassifier 학습/예측/평가
vo_clf.fit(X_train, y_train)
vo_pred = vo_clf.predict(X_test)
print(f'voting 분류기 정확도 : {accuracy_score(y_test, vo_pred):.4f}')결과가 voting 분류기 정확도 : 0.9474로 약 94.7%의 정확도가 뽑혔다. 개별 모델별로 결과를 알고 싶다면 아래와 같이 볼 수 있다.
# 개별 모델의 학습/예측/평가
classifiers = [lr_clf, knn_clf]
for classifier in classifiers :
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print(f'{class_name} 정확도 : {accuracy_score(y_test, pred):.4f}')LogisticRegression 정확도 : 0.9474
KNeighborsClassifier 정확도 : 0.9561으로 나왔는데 보팅 분류기의 정확도가 조금 더 높게 나타난 것을 알 수 있었다. 이때 또 하나의 궁금증이 생겼는데 앞서 보통 하드 보팅보다 소프트 보팅이 좋다고 했는데 여기서도 그럴까?
# 보통 하드 보팅보다 소프트 보팅이 좋다고 했는데 여기서도 그럴까?
vo_clf_hard = VotingClassifier(estimators=[('LR', lr_clf), ('KNN', knn_clf)], voting='hard')
vo_clf_hard.fit(X_train, y_train)
vo_pred = vo_clf_hard.predict(X_test)
print(f'voting 분류기 정확도 : {accuracy_score(y_test, vo_pred):.4f}')
# voting 분류기 정확도 : 0.9561엥 결과값이 voting 분류기 정확도 : 0.9561 으로 더 높게 나왔다. 이는 하드보팅의 경우 여러 분류기 중 가장 높은 결과값을 가져오기 때문으로 보인다. 따라서 이렇게 나온 정확도 만으로는 어느게 더 좋다 판단할 수 없는 부분인 듯하고...
여기서는 보팅 분류기의 정확도가 각각의 모델들보다 정확도가 조금 더 높게 나왔지만, 보팅이 무조건 조건 기반 분류기보다 예측성능이 좋다고 확신할 수는 없다. 데이터의 특성과 분포 등 다양한 요건에 따라 선택해야하는 문제이다.
배깅 - 랜덤 포레스트
랜덤 포레스트는 결정트리를 기반으로 하는 방식으로, 장점인 쉽고 직관적임을 그대로 가지고 있으나 깊어진 깊이로 인해 과적합이 발생할 수 있다는 단점을 수십~수천개의 트리를 결합함으로 극복한다. 이로인해 편향-분산 트레이드오프의 효과를 극대화 시킬 수 있는것이다.
여러개의 결정트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링한 후 학습을 수행하며, 이를 모아 최종적으로 예측이 결정된다. 만약 데이터의 갯수가 100개이고 결정트리 분류기가 3개라면 데이터 갯수가 100개인 서브셋을 3개 생성하는데, 이렇게 데이터 셋이 중첩되게 분리하는 기법을 부트스트래핑(Bootstrapping)이라고 한다. 본래 통계학에서 여러 개의 작은 데이터 셋을 임의로 만들어 개별 평균의 분포도를 측정하는 목적으로 만든 샘플링 방식
이렇게 데이터가 중첩된 개별 데이터 셋에 결정 트리 분류기를 각각 적용한 후 그 결과를 종합해 예측성능을 높이는 기법이 랜덤포레스트이다.
예제(사용자 행동 인식 데이터 셋)
사이킷런은 RandomForestClassifier 클래스를 통해 랜덤 포레스트 기반의 분류를 지원한다. 앞서 한번 다뤄봤던 사용자 행동인식 데이터 셋을 이용해 살펴볼 것이며, 그때 정의한 함수를 활용하겠다.
# 중복된 피처명 정리
def get_new_feature_name_df(old_feature_name_df):
# column_name으로 그룹지어서 cumcount()로 피처별 중복 존재시 숫자를 부여
# reset_index()로 column_index를 생성한다
feature_dup = pd.DataFrame(old_feature_name_df.groupby("column_name").cumcount()).reset_index()
# features.txt의 column_index는 1부터 시작이기 때문에
feature_dup.columns = ["column_index", "dup_cnt"]
feature_dup["column_index"] = feature_dup["column_index"] + 1
# column_index를 기준으로 머지 후 중복컬럼명 변경
new_feature_name_df = pd.merge(old_feature_name_df, feature_dup, how='outer')
# 만약 x라는 컬럼명이 있다면 x_1, x_2와 같이 변경되도록 한다
new_feature_name_df['column_name'] = new_feature_name_df.apply(lambda x: x.column_name + "_" + str(x.dup_cnt) \
if x.dup_cnt > 0
else x.column_name, axis=1)
return new_feature_name_df
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./UCI HAR Dataset/UCI HAR Dataset/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./UCI HAR Dataset/UCI HAR Dataset/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv('./UCI HAR Dataset/UCI HAR Dataset/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./UCI HAR Dataset/UCI HAR Dataset/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./UCI HAR Dataset/UCI HAR Dataset/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test이전에 사용했던 '사용자 행동 인식 데이터 불러오기 함수'를 불러와줬다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 경고메시지 무시하고 싶을때, 다시 켜고 싶다면 'default'
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_get_human_dataset()를 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 세트로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state = 0, max_depth=8)
rf_clf.fit(X_train, y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print(f'RandomForest 정확도 : {accuracy}')
# RandomForest 정확도 : 0.9195792331184255약 91.9%의 정확도를 보여줬다.
예제(유방암 데이터 셋)
그렇다면 또 궁금해지지 않는가. 위에서 VotingClassifier을 사용하여 구해줬던 정확도와 RandomForestClassifier를 사용하여 구해준 정확도의 차이가
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=11)
# 랜덤 포레스트
rf_clf = RandomForestClassifier(random_state = 0, max_depth=8)
rf_clf.fit(X_train, y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print(f'RandomForest 정확도 : {accuracy}')RandomForest 정확도 : 0.9824561403508771위에서 Soft Voting 시 나왔던 정확도가 약 0.95% 정도였는데, RandomFrest는 정확도가 약 98%로 엄청 높게 나왔다. 우와
랜덤 포레스트의 하이퍼 파라미터 및 튜닝
트리 기반의 앙상블 알고리즘의 단점을 꼽자면 하이퍼 파라미터가 너무 많은데다가 배깅, 부스팅, 학습, 정규화 등을 위한 하이퍼 파라미터까지 추가되므로 다른 ML 알고리즘에 비해 많을 수 밖에 없다는 점이다.
그나마 랜덤 포레스트가 적은 편에 속하는데, 하이퍼 파라미터가 대부분 결정트리에서 사용되는 하이퍼 파라미터와 같은 파라미터가 대부분이기 때문이다.
n_estimators : 결정트리의 갯수를 지정하며 디폴트 값은 10개
max_features는 결정트리에서는 디폴트 값이 전체 피처 이지만, 랜덤포레스트에서는 전체 피처의 sqrt 만큼 참조한다
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [8, 16, 24],
'min_samples_leaf' : [1, 6, 12],
'min_samples_split' : [2, 8, 16]
}
# RandomForestClassifier 객체 생성
# n_estimators = 생성할 결정트리의 갯수.
rf_clf = RandomForestClassifier(n_estimators=50, random_state=0, n_jobs=-1)
# GridSearchCV 생성
grid_cv = GridSearchCV(rf_clf, param_grid = params, cv = 2, n_jobs = -1)
grid_cv.fit(X_train, y_train)
print(f'최적 하이퍼 파라미터 :\n{grid_cv.best_params_}')
print(f'최고 예측 정확도 :\n{grid_cv.best_score_}')최적 하이퍼 파라미터 :
{'max_depth': 8, 'min_samples_leaf': 1, 'min_samples_split': 2}
최고 예측 정확도 :
0.9560244222892031이렇게 추출된 최적 하이퍼 파라미터로 다시 RandomForestClassifier를 학습시킨 뒤 이번에는 별도의 테스트 데이터 셋에서 예측성능 측정해보면
rf_clf1 = RandomForestClassifier(n_estimators=100, min_samples_leaf=1, max_depth=6, min_samples_split=2, random_state=0)
rf_clf1.fit(X_train, y_train)
pred = rf_clf1.predict(X_test)
print(f'예측 정확도 : {accuracy_score(y_test, pred)}')
# 예측 정확도 : 0.9824561403508771별도의 테스트 데이터 셋에서 수행한 예측 정확도 수치는 대략 98%가 떴다 (와아)
피처별 중요도 보기(시각화)
import matplotlib.pyplot as plt
import seaborn as sns
# 피처별 중요도 상위 20개 뽑기
# 중요도를 변수에 담아주고
ftr_importance_values = rf_clf1.feature_importances_
# 중요도와 컬럼명을 변수에 담아줌
ftr_importances = pd.Series(ftr_importances_values, index = X_train.columns)
# 값으로 sorting하여 20개 자르기
ftr_top20 = ftr_importances.sort_values(ascending = False)[:20]
ftr_top20worst perimeter 0.172372
worst radius 0.113298
mean concave points 0.087370
worst area 0.086899
worst concave points 0.084124
mean perimeter 0.079804
mean concavity 0.059255
area error 0.052285
mean area 0.038816
worst concavity 0.027484
radius error 0.026148
mean radius 0.025458
worst texture 0.020172
perimeter error 0.019891
mean texture 0.015773
worst smoothness 0.013333
worst fractal dimension 0.011248
worst compactness 0.009950
worst symmetry 0.008632
mean smoothness 0.006465
dtype: float64시각화하기
plt.figure(figsize=(8, 6))
plt.title('Feature imporances Top 20')
sns.barplot(x = ftr_top20, y=ftr_top20.index)
plt.show()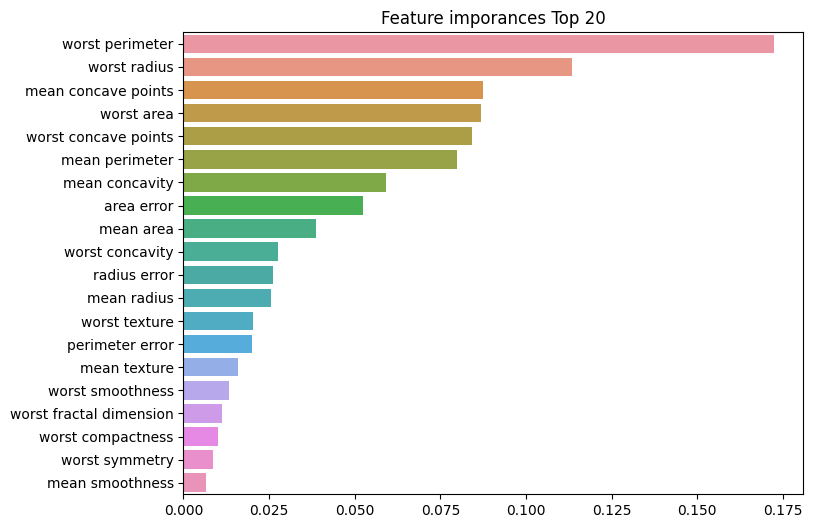
랜덤 포레스트는 CPU 병렬 처리도 효과적으로 수행되어 빠른 학습이 가능하기 때문에 뒤에 소개할 그래디언트 부스팅보다 예측 성능이 약간 떨어지더라도 랜덤 포레스트로 일반 기반 모델을 먼저 구축하는 경우가 많다.
GBM(Gradient Boosting Machine)
부스팅 알고리즘은 여러개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여하며 오류를 개선해 나가는 학습 방식이다. 대표적으로 AdaBoost(Adaptive boosting)와 그래디언트 부스트 가 있다.
AdaBoost는 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘으로, 각각의 분류기에 가중치를 부여한 뒤 결합하는 방식이다.
GBM 역시 AdaBoost와 유사하나 가중치의 업데이트 방법시 '경사 하강법9Gradient Descent)'를 이용하는 것이 차이점이다. 오류값은 `실제 값 - 예측값`
- 경사 하강법(Gradient Descent)
분류의 실제 결과값을y로 피처를x1,x2,…,xn로 피처에 기반한 예측 함수를F(x)라고 할 때,오류식h(x) = y − F(x)을 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트 하는 것이다.
사용자 행동 인식 예제
GBM은 분류와 회귀 둘다 가능하며, 사이킷런에서는 GBM 기반의 분류를 위해서 GradientBoostingClassifier클래스를 제공한다.
from sklearn.ensemble import GradientBoostingClassifier
import time
# 사용자 정의 함수 get_human_dataset()을 이용해 데이터 가져오기
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행시간 측정을 위함. 시작시간 설정
start_time = time.time()
# 학습 및 예측
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train, y_train)
pred = gb_clf.predict(X_test)
print(f'정확도 : {accuracy_score(y_test, pred)}')
print(f'수행시간 : {time.time() - start_time}')정확도 : 0.9389209365456397
수행시간 : 1144.8965108394623앞서 RandomForest의 정확도가 약 91.9%가 나왔던 걸 생각해보면, 기본 하이퍼 파라미터 만으로 약 93.9%의 예측 정확도가 나온건 예측 성능이 더 좋다고 말해볼 수 있다. 그렇지 않은 경우도 분명 있겠지만, 일반적으론느 GBM이 RandomForest보다는 예측 성능이 조금 더 뛰어난 경우가 많다고 한다.
하지만 사이킷런의 GradientBoostingClassifier는 약한 학습기의 순차적인 예측 오류 보정을 통해 학습을 수행하므로 멀티 CPU core 를 사용하더라도 병렬 처리가 지원되지 않아 대용량 데이터의 경우에는 학습 시간에 너어어어무 오랜 시간이 필요할 수도 있다. 반면, 랜덤포레스트의 경우 상대적으로 빠른 수행 시간을 보장해주기 깨문에 더 쉽게 예측 결과를 도출 할 수 있다.
GBM 하이퍼 파라미터
loss: 경사 하강법에서 사용할 비용함수를 지정. 특별한 이유가 없으면 기본값인 'deviance'를 그대로 적용한다.learning_rate: GBM이 학습을 진행할 때마다 적용하는 학습률로 weak learner가 순차적으로 오류 값을 보정해 나가는데 적용하는 계수이다. 0~1사이의 값을 지정할 수 있으며 디폴트는 0.1. 값이 작을수록 최소 오류값을 찾기 때문에 예측 성능은 높아질 가능성이 크지만 수행시간이 너무 오래 걸릴 수 있다. 이러한 특성 때문에 'n_estimators' 와 상호 보완적으로 조합해 사용하는 편으로, learning_rate를 작게하고 n_estimators를 크게하면 더 이상 성능이 좋아지지 않는 한계점까지 끌어올려볼 수 있는 것이다.n_estimators: weak learner의 개수. 기본값은 100. 개수가 많을 수록 예측 성능이 어느정도 좋아질 수 있으나 수행시간이 오래걸린다.subsample: weak lerner가 학습에 사용하는 데이터 샘플링의 비율. 기본값은 1은 전체 학습 데이터를 기반으로 학습한다는 의미(0.5라면 train data중 50%를 기반으로 학습). 과적합이 염려되는 경우에는 1보다 작은 값으로 설정한다.
GridSearchCV로 하이퍼 파라미터 튜닝 실습해보기
%%time
from sklearn.model_selection import GridSearchCV
params = {"n_estimators": [100, 500], "learning_rate": [0.05, 0.1]}
# GBM 객체 생성 후 GridSearchCV
gb_clf = GradientBoostingClassifier(random_state=0)
grid_cv2 = GridSearchCV(gb_clf, param_grid = params, cv=2, verbose=1)
grid_cv2.fit(X_train, y_train)
print(f"최고 예측 정확도:{grid_cv2.best_score_:.4f}")
print(f"최적 하이퍼 파라미터:\n{grid_cv2.best_params_}")
print()Fitting 2 folds for each of 4 candidates, totalling 8 fits
최고 예측 정확도:0.9451
최적 하이퍼 파라미터:
{'learning_rate': 0.05, 'n_estimators': 500}
CPU times: total: 5.23 s
Wall time: 5.23 s예상보다는 빠른 속도였는데
%%time
from sklearn.ensemble import RandomForestClassifier
params = {"n_estimators": [100, 500]}
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv2 = GridSearchCV(rf_clf, param_grid = params, cv = 2, n_jobs = -1)
grid_cv2.fit(X_train, y_train)
print(f"최고 예측 정확도:{grid_cv2.best_score_:.4f}")
print(f"최적 하이퍼 파라미터:\n{grid_cv2.best_params_}")
print()최고 예측 정확도:0.9516
최적 하이퍼 파라미터:
{'n_estimators': 100}
CPU times: total: 266 ms
Wall time: 3.45 sRandomForest의 속도가 더 빠른 모습을 볼 수 있었다. (잘못된 비교라면 말해주시기 바랍니다)