네트워크 - 4. Network Layer (1)
기말고사의 주된 범위가 될 듯한 네트워크 레이어다. 이번 챕터의 목표도 살펴보자
Goal
- Network layer service 뒤에 있는 principle 이해하기 (특히 data plane)
- network layer service model
- forwarding versus routing
- how a router works
- addressing
- generalized forwarding
- internet architecture
- Internet의 instantiation, implementation
- IP protocol
- NAT, middleboxes
그럼 전체적인 overview로 먼저 들어가보자
1. Network layer: Overview
본격적으로 어떤 것을 설명하기에 앞서 우리가 배울 것의 전체적인 overview를 보는 것은 앞으로의 이해에 도움이 된다. 해당 부분에서 전체 network layer라는 숲을 보고, 그 다음 network layer에는 어떤 종류의 나무들이 사는지 알아보자.
Network-layer services and protocols
Network layer에서 제공하는 주된 service는 sending host에서 receiving host로 segment를 전송하는 것이다.
- sender는 segment들을 datagram들로 encapsulates하고, link layer에 전송한다.
- receiver는 받은 segments를 transport layer protocol에 넘겨준다.
Network layer protocol들은 모든 internet device들(예를 들어보자면 host들이나, router들)에 있다.
- router는 그것을 지나는 모든 IP datagram들에 있는 header field들을 체크한다.
-> 나중에 확인하겠지만, datagram을 체크하고, 변경한다. - datagram들을 end-end path로 전송하기 위해서 input ports에서 output ports로 옮긴다.
이런 service를 제공하기 위해서 network layer에는 크게 두 개의 function이 있다.
1. forwarding (==switching)
- router의 input link로 들어온 packet을 적당한 router output link로 옮기는 기능
- 여행을 가는 걸로 생각하면, 직접 차를 타고 움직이는 기능을 말함
- routing (global operation)
- routing algorithm들에 따라 source에서 destination까지 packet이 갈 route를 결정하는 기능
- 여행을 가는 걸로 비유하자면, 네비게이션이 갈 경로를 찾는 기능을 말함
위 기능을 구현하기 위해서 network layer는 data plane과 control plane으로 나뉜다.
Data plane (forwarding)
- local, per-router function (라우터 단위로 제공하는 기능들, 지역적임)
- router input port에 도착한 datagram을 어떻게 router output port로 옮길지 결정
Control plane (routing)
- network-wide logic (네트워크 단위의 로직)
- source host에서 destination host까지 가는 end-end path위의 router들을 결정
- 2가지 접근법이 있음
- traditional routing algorithms: router 내부에 구현되어 있어 router 내부에서 path를 계산함.
- software-defined networking(SDN): remote server들에 구현되어 있고, remote server가 전체적인 network 상황을 보면서 path를 계산
아래 control plane을 잠깐 조금 더 설명하고 넘어가자.
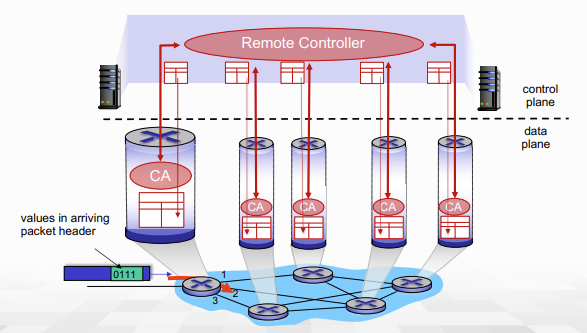
per-router control plane(traditional routing)에서는 각각의 모든 router의 control plane들이 상호작용해서 local forwarding table을 만들고, 해당 table을 lookup해서 output port를 결정한다.
-> control plane이 router 내부에 존재

반면 Software-Defined Networking(SDN)에서는 control plane이 remote server에 있어, remoter controller가 모든 정보를 취합해 route를 계산하고 forwarding table을 구성한다. 이후 해당 forwarding table을 각각의 router들에 뿌려준다. 이때 router 내부의 CA(controll agency)와 상호작용해서 forwarding table을 보내주는 형식.
-> control plane이 router 바깥에 있는 것이 중요
어떤 식으로 구현되어 있는지는 대충 봤으니까 이제 service model을 살펴보자
Network service model
Q.
Sender에서 receiver로 datagram들을 보내는 channel을 위해 필요한 service model은 무엇이 있을까...?
A.
- 각각의 datagram들을 위해 필요한 service 예시
- delivery 보장
- 40msec 이하의 delay에서의 delivery가 보장되어야 한다.
- datagram의 flow를 위해 필요한 service 예시
- In-order(순서대로) datagram이 전송을 보장되어야 한다.
- flow의 minimum bandwidth를 보장해줘야 한다.
참고로 "인터넷"의 service model은 거의 항상 "best effort"이기 때문에 최소한의 것만 보장되는 경우가 많다. best effort는 다시 정의하자면 그냥 '최선은 다해보겠다.'라는 뜻.. 때문에 다음에 대한 보장은 보통 없음
NO guarantees on:
- 목적지까지 성공적으로 datagram을 전송
- delivery의 순서나 timing
- end-end flow를 가능케하기 위한 bandwidth
아래는 다른 network service들에 대한 guranteee 여부
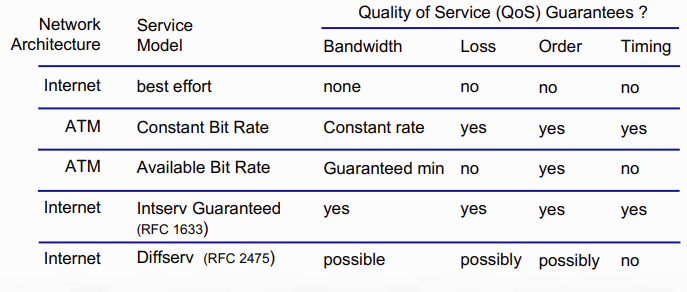
아무튼 이와 같은 best-effort service는 아래와 같은 도움을 받는다.
- Simplicity of mechanism은 internet이 어디에나 배포되고 설치되는 것을 가능하게 해준다..
- 반면 이를 가능케 하려면 당연히 core는 더욱 바빠진다. => core는 simple하게
- Bandwidth의 충분한 공급은 real-time application들이 대부분의 시간동안 좋은 성능을 낼 수 있도록 해준다..
- client network에 가까이 존재하는 replicated, application-layer distributed service들(data center나 content distribution network등..)은 여러 장소에서 service를 제공할 수 있도록 해준다.
- content provider 들이 network traffic을 너무 많이 차지하지 않을 수 있게 도와준다.
- Elastic service들의 congestion control는 best-effort 모델에 도움을 준다.
결론적으로 우리는 best-effort service model을 차용하고 있다는 것.
이제 전체적인 상황은 이해를 했으니, 구체적으로 어떻게 network layer를 구현해야 best effort가 되는지 알아보자. (늘 최선을 다하는 건 힘든 일이니까..)
What's inside a router
간단히 말하자면, Router는 L3 switch이다. 여기서 L3란 layer가 3개라는 뜻인데(나중에 배우겠지만, 그냥 switch임에도 layer가 3개인 녀석들도 있다.), Router는 input port와 output port를 가지고 있으며, input port로 들어온 packet을 어떤 output port로 보낼지 결정해야 한다. 이제 어떤 식으로 그 결정을 내리는지 자세히 알아볼 것이다.
Router architecture overview
일반적인 router architecture를 high-level에서 보면 아래의 그림과 같다.
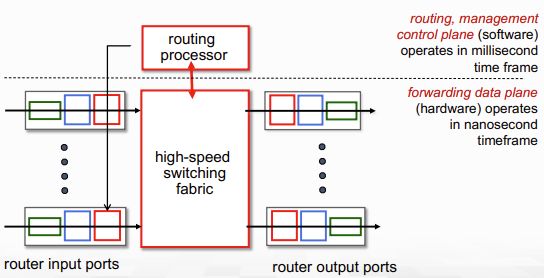
간단히 보면, routing processor가 control plane을 담당하여 routing을 관리하고, 그 아래에 있는 high-speed switching fabric에서 switching(forwarding, 맞는 output port로 보내기)을 담당한다.
- 이때 Gbps의 속도가 나기 위해서 1개의 packet forwarding은 nano second안에 처리되어야 한다. 때문에 switching은 hardware에서 처리하는 것.
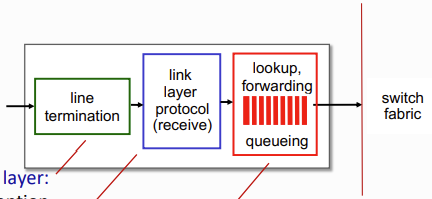
input port를 자세히 보면 위 그림과 같다.
input port에서는 physical layer인 line에서 들어온 bit가 link layer의 protocol을 통해 recevie되고, 이를 switching header field의 값을 사용해서 output port를 찾는다.
- 이 과정은 각 포트별로 이루어지기 때문에 decentralized switching이라고 한다.
이 과정은 line rate(선형 속도 O(n))이어야 하는데, 해당 계산이 link layer를 통해 packet이 전송되는 속도보다 느리면 언제나 packet이 drop되기 때문이다. 따라서 해당 계산은 최대한 빨라야 한다. output port를 계산하는 방식은 두 가지가 있다.
- Destination-based forwarding: header에 있는 destination field값만 사용해서 전송
- Generalized forwarding: header의 다른 field 값들도 사용해서 forwarding
Destination-based forwarding
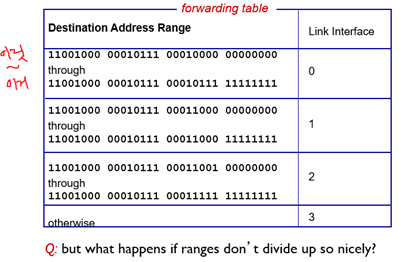
위 사진처럼 범위를 설정해서 해당하는 link interface (output port)에 해당 packet을 전달하는 방식이 바로 destination-based forwarding이다.
만약 범위가 겹쳐서 나눠지면, 반드시 공통으로 들어가야하는 부분과 아무거나 와도 되는 부분으로 분리한다.
예를 들어 1101000 100000부터 1101000 111111까지가 0번 포트로 가는 범위였는데, 만약 1101000 101000부터 1101000 101111까지는 3번 포트로 가도록 routing결과가 변경된다면? 겹치는 부분만 3으로 나누고 나머지는 여전히 0번으로 보내는 것!
그냥 보면 어려우니까 그림으로 보자

이렇게 0번이 얌전히 00010000 00000000부터 00010111 11111111까지 먹고 있었는데 갑자기 00010000 00000100부터 00010000 00000111까지는 3번 포트로 가도록 routing 결과가 바꼈다? 그럼 위 그림과 같이 routing table을 수정된다.
그렇다면 어떤 식으로 패킷당 갈 link interface를 결정할까? 그 방식이 바로 Longest prefix match이다.
longest prefix match는 말 그대로, destination address 값과 forwarding table의 각 entry를 비교할 때 맨 앞의 비트부터 비교를 해서 가장 많이 일치한 interface로 해당 값을 보낸다.

위 그림에서 1번 packet은 0번 interface로 보내는 것이고, 2번 packet은 1번 interface로 보내는 것.
이제 그렇다면 이 과정이 왜 가장 빠른 시간에 비교할 수 있는 방법인지 살펴볼 것이다.
사실 LPM은 특별한 알고리즘 없이 진행해버리면 O(NM)의 시간이 걸린다. 근데 빠른 속도를 위해서 하드웨어에 구현되어 있으니 특별한 알고리즘을 구현할 수가 없다...
그래서 LPM은 TCAM(Ternary Content Addressable Memory) 를 사용해서 수행된다.
(O(N+M)이며 1 clock cycle안에 가능)
- content는 각각 addressable해서 table 크기와 상관 없이 한 clock cycle만에 retrieve할 수 있어진다.
- Cisco Catalyst는 TCAM에서 최대 1M개의 routing table entry를 갖는다.
packet의 정보를 이용해서 output port를 찾는 방법에 대해서 배웠으니, 이제 해당 port(interface)로 packet을 물리적으로 전송하는 방법을 알아보자.
Switching fabrics
Switching fabric은 input link에서 적당한 output link로 pakcet을 전송한다. switching rate는 이렇게 packet이 input에서 output으로 전송되는 속도를 말한다.
- 보통 링크 속도(input/output line rate)의 배수로 측정된다.
- 예를 들어 N개의 input이 있으면, switching rate = link rate * N
- 하지만, 보통은 NR보다 더 적은 속도만 지원하기 때문에 여기서 bottleneck 현상이 발생한다..
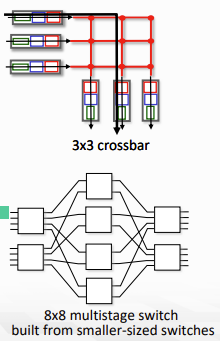
아무튼 switching fabric의 종류는 아래 그림에서 볼 수 있듯 3가지가 존재한다.
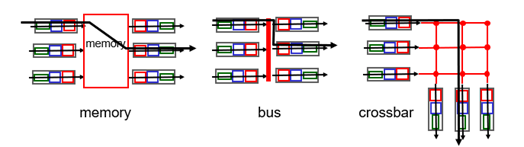
사실 이 그림은 발전한 시간 순으로 나열된 것. memory에 넣어서 하던 것이 가장 옛날 방식이고, bus가 그다음, 지금은 interconnection network 방식을 선택한다. (bus도 가끔 사용)
메모리를 사용한 스위칭부터 차근차근 봐보자.
Switching via memory
- 1세대 router에서 사용
- CPU의 직접적인 control 아래에서 switching
- packet은 system memory에 복사된 후, 전송된다. (datagram당 2번의 bus crossing)
- 이 사이의 데이터 전송은 system bus를 통해서 이루어지며, 이는 모든 링크에 의해서 공유되기 때문에 결국 이 memory bandwidth에 의해서 속도가 제한됐다.
- 구현하기는 쉬워서 처음에 많이 사용됐던 방식이다.
Switching via bus
- shared bus를 통해서 input port의 memory에서 output port의 memory로 전송됐다.
- 중요한 것은 input port와 output port에 각각 memory가 생겼다는 점
- bus connection이기 때문에 여기서도 bus bandwidth에 의해서 스위칭 스피드가 제한된다. (bus 속도가 중요한데, 이걸 올리는건 쉽지 않음)
- 또한 이 bus도 공유했기 때문에 하나의 packet이 bus를 통과하고 있으면, 다른 packet들은 대기해야 한다.
- Cisco 5600에서는 32 Gbps bus를 사용한다. 이는 access router로 사용하기엔 충분!
- Access router는 사용자가 사용하는, edge단에 가까운 router를 의미함.
- Core는 훨씬 바쁘기 때문에 이거 가지곤 택도 없다.
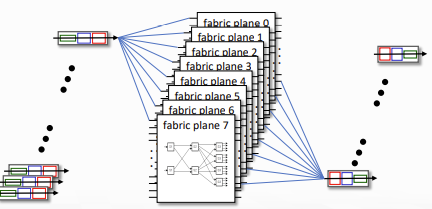
Switching via interconnection network
- Crossbar, Clos networks 등 interconnection net들은 원래 multiprocessor에서 processor들을 연결하기 위해서 개발됐다.
- bus의 bandwidth에 의해 속도가 제한되는 것을 극복하기 위해서 등장함
- 작은 switches의 multiple stage들로 이루어진 n*n multistage swtich이다.
- parallelism이 사용 가능해서, 같은 output port로 가는 packet이 아니라면 동시에 전송될 수 있다!
- datagram을 고정된 크기의 cell로 자르고, fabric을 통과시킨 뒤 다시 datagram으로 조립해 내보낸다.
- 위 그림과 같이 scaling하기 쉽다!
- Cisco CRS router에서 사용하는데, 8개의 switching plane기본으로 가지고, 각 plane당 3-stage interconnection network를 갖는다. (100's Tbps이상의 switching capacity)
Queuing
Input port queuing
만약 input port 속도가 switching 속도보다 빠르면, input queue에서 queuing이 발생한다. input buffer overflow로 인한 queueing delay와 loss도 같이 발생하게 된다.
- Head-of-the-Line(HOL) blocking: queue의 첫 번째에 있는 datagram이 전송될 수 있는 다른 queue의 forwarding까지 막을 수 있다..! (아래 그림 참조)

Output port queuing
output port에서 transmission되는 속도보다 더 빠르게 datagram이 도착하는 경우 buffering 발생. input보단 output에서의 queuing이 더 일반적이다.
당연히 output port buffer overflow 발생시 queuing delay와 loss 발생한다..
또한, 어떤 packet을 drop할지도 생각해봐야된다... (FIFO는 쫌...) 그 이유는 멀리서 온 packet을 버리는 경우 network cost가 높아진다.
Scheduling discipline은 queued datagram 중 어떤 것을 transmission할지 선택한다.
- Priority scheduling.. 누가 가장 좋은 성능을 낼 것인가.
잠깐 코너 속의 코너로 그렇다면, 얼만큼의 버퍼 사이즈를 가져야 좋은지에 대해서 생각해보자.
무조건 클수록 좋을까? buffer가 크다면, drop 없이 모든 packet이 쌓일텐데, 그렇게되면 모든 packet의 delay가 점점 길어진다.
그렇다고 무조건 짧다면? drop되는 패킷이 점점 많아질 것...
RFC 3439 rule of thumb에 따르면, 평균 buffering은 일반적인 RTT (250msec 정도)에 link capacity C를 곱한 값이라고 한다.
- C가 10Gbps라면, buffer는 2.5Gbit가 되는 것.
이후부턴 조금 더 복잡한 계산과 이해가 필요하기 때문에 따로 블록으로 뺐다.
최근 연구에 따르면 N개의 flow가 있을 때 buffering = RTT * C / sqrt(N)의 공식이 성립한다고 한다.
- RTT * C는 1명의 Sender가 있을 때 dynamicity를 고려한 buffer size이다.
- TCP의 congestion control에서 봤듯, data는 점점 많이 증가하다가 갑자기 전송량이 절반으로 줄어든게 된다.
- 예를 들어 100개의 packet을 보낸다면, 이후에는 50개의 packet을 보내는것.
- 또한 이때 window size가 50으로 줄어든 것이기 때문에 이후에 새로운 packet을 보내기 위해선 50개의 ACK이 올 때까지 기다린다.
- 즉 Sender는 잠깐동안 packet을 보내지 않는다...! 또한, 만약 link에 아예 packet이 없다면 그것은 network가 under utilization된 상황이기 때문에 network 전체로 봤을 때 매우 좋지 않은 상황이다.
- 반면 sender가 데이터를 보내지 않아도 buffer에 data가 있다면, 그건 utilization됐다고 할 수 있는데, 이 전부를 고려한 buffer의 크기가 RTT * C이다!
그렇다면, 사용자가 더 많아졌을 땐 왜 buffer size를 더 줄일까?
- 사람이 많아지면 1명일 때보다 dynamicity가 줄어들고(buffer underutilization 확률 감소) network traffic이 normalize된다.
- TCP congestion control에서 봤던 톱날 모양의 packet 전송 그래프에서 톱날이 거의 사라지고 1자 선이 된다는 뜻
- 때문에 buffer의 size를 줄일 수 있다...!
Keep bottlenect link just full enough but not fuller
를 기억하자.
솔직히 위 내용 이해하려고 시간 꽤 썻다...
아무튼 이제 이 buffer를 어떻게 관리하는지 살펴보자. buffer의 관리는 drop과 marking으로 나뉜다.
- Drop: buffer가 가득찼을 때, 어떤 packet은 올리고 어떤걸 drop할지
- Tail drop은 도착하는 packet을 드랍하는 것이고 priority는 우선순위를 고려해서 drop하는 것이다.
- Tail drop은 그렇게 좋지는 않은 정책인데, TCP를 생각해보자. TCP는 패킷을 보냈다 안 보냈다한다. (window size만큼 보내다가.. 갑자기 안보내다가.. 이를 bursty하다고 함)
- 만약 sender가 여럿 있다고 생각해보자. buffer size가 12인데 4개의 packet을 보내는 sender가 4명 있다면? 마지막 sender가 보내는 packet은 전부 다 loss될 것이다.
- Marking: ECN, RED 등의 congestion signal을 어떤 packet에 marking할지
- ECN은 Network assisted Congestion Control을 구현하기 위해 사용되는 header field값
- RED는 Random Packet Drop이라고 하는데, 앞서 설명했던 하나의 sender가 보내는 packet은 싹다 버리는 상황을 피하기 위해 만들어졌다.
Packet scheduling은 어떤 packet을 다음 link에 보낼지 결정하는 것이다. FCFS, priority, RR, weighted fair queuing 등의 기법이 있다.
FCFS
- 말 그대로 도착하는 순서대로 output port로 전송하는 것 (FIFO)
- simple하기 때문에 network core에서 사용한다.
Priority scheduling
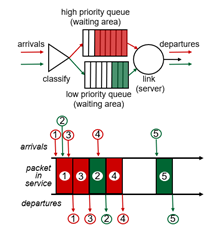
- 도착한 traffic은 분류되고, 이 분류된 class에 따라서 queued된다.
- classification을 위해 몇몇 header field가 사용된다.
- 가장 높은 priority queue의 packet을 보낸 후, 다른 queue의 packet을 전송한다.
- priority class 내에서는 FIFO에 따라 전송된다.
- Non-preemptive하기 때문에 만약 일반 packet이 보내지는 도중 높은 priority packet이 도달하면, 기다렸다가 간다.
Round Robin
- header field의 몇몇 값에 따라 분류하는 건 같음.
- priority scheduling이라고 할 수도 있는데, 더 짦은 queue에 넣어진 packet은 더 빨리 전송되기 때문이다.
- 또한 더 높은 priority의 queue에는 더 적은 수의 packet만 도달하기 때문에 일반 queue보다 더 빨리 전송됨.
- 모든 queue를 돌면서 하나씩 보낸다.
- 한 flow에서 오는 packet은 하나의 queue에 박혀야되는데, 만약 그렇지 않다면 out-of-order로 전송될 수 있기 때문이다.
Weighted fair queuing
- Round Robin을 일반화한것.
- 각 class는 weight를 갖고, 각 cycle마다 그 weight만큼 보냄
- traffic class당 최소한의 bandwidth을 보장해줄 수 있음.
이렇게 지금까지 low level의 view로 봤을 때, router에서 어떻게 packet이 forwarding되는지 살펴봤다. 다음은 protocol level에서 살펴보자.
IP: Internet Protocol
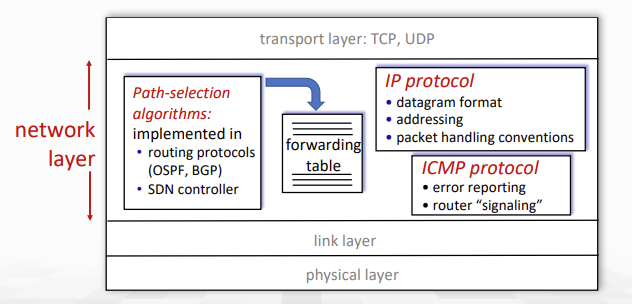
다음은 network layer에서의 기능 들이다.
1. path-selection algorithms: OSPF, BGP 등의 routing protocol과 SDN controller에 의해서 구현된다.
2. IP protocol: Datagram format, addressing, packet 처리에 대한 convention들을 나타낸다.
3. ICMP protocol: error reporting이나 router signaling을 담당한다.
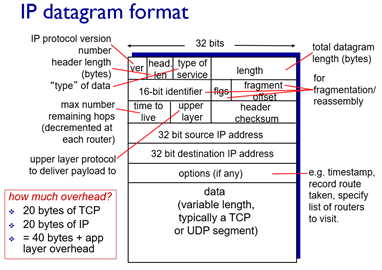
IP datagram format은 위 그림과 같다. 위에서부터 살펴보자.
- IP protocol version number는 IPv4인지 IPv6인지 알아야 router에서 맞게 처리하기 때문에 필요하다.
- Type of service: 첫 6bit는 diffserv를 위해 사용되고 나머지 1비트는 ECN 비트이다. 여기서 ECN은 앞서 말했듯 network assisted congestion control을 위해 사용되는 비트. congestion 발생시 mark된다.
- length: 전체 datagram 길이 byte단위
- 16-bit identifier, flgs, fragment offset: fragmentation/reassembly를 위한 field. IPv6에선 fragmentation이 없기 때문에 해당 필드도 없음
- TTL: 남은 hop 개수 (라우터 하나 거칠때마다 1씩 감소)
- header checksum: TTL이 바뀌기 때문에 매번 계산해줘야 한다. (IPv6에는 TTL이 없어 괜찮다.)
- Upper layer protocol: 상위 헤더에 대한 hint. TCP/UDP 헤더에는 따로 자신이 어떤 프로토콜인지 알리는 값이 없기 때문에 IP에서 이를 알려주고 구분함.
- 참고로 datagram의 최대 크기는 64KB까지 되지만, 보통은 IP fragmentation 때문에 1500byte만 사용한다.
- TCP header로 20byte, IP header로 20byte하면 Application layer에선 최대 1460byte만 사용 가능... 이를 MSS라고 함.
- 또 참고로 IPv6에서 없는 값들은 16-bit identifier, flgs, fragment offset, time-to-live, header checksum, options field가 없음
ip datagram이 어떻게 이루어져있는지도 확인했으니, 이제 각각 ip를 통해서 어떻게 전송(addressing)되는지 보자.
IP addressing
IP address는 각 host와 router들의 interface당 1개씩 결합된 32-bit identifier이다.
- 여기서 주의해야할 점은 host나 router당 하나가 아니라, 기기에서 사용하는 network interface 하나당 한 개의 IP가 지정된다는 점이다.
Interface는 host/router와 physical link 사이의 연결을 의미한다.
- router는 일반적으로 여러 개의 interface를 갖는다.
- 반면 host는 보통 1개 아님 2개의 interface를 갖는다. (랜 하나 와이파이 하나)
이 interface들이 실제로 어떻게 연결되는지는 다음 chapter들에서 살펴볼 예정. 그냥 딱 말하자면 wired ethernet interface들은 ethernet switch에 의해서 연결되고, Wifi는 WiFi base station(Access Point)에 의해서 연결된다.
그렇다면 모든 host들이 하나의 network에 연결되어 있을까? 정답은 아니다.
네트워크는 여러 계층구조로 이루어져있는데, 하위 계층의 net을 의미하는 subnet이 바로 그것이다. 이제 subnet을 알아보자.
Subnet
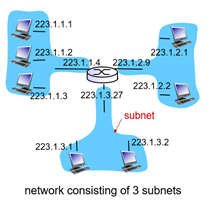
Subnet은 router를 통과하지 않고 내부에서 물리적으로 연결된 device interface들을 의미한다.
IP address는 subnet part와 host part로 구성된다.
- subnet part: 같은 subnet에 있는 device들은 공통된 상위 bit를 갖는다. (115.145.~)
- host part: 남은 bits는 host를 구분하기 위해서 사용된다.
Subnet을 결정하기 위해서 router로부터 각각의 interface를 분리한다. (위 그림에서 분리된 각각의 섬모양 네트워크들이 바로 subnet!
- 만약 subnet의 ip가 223.1.3.0/24라면 상위 24비트 까지가 subnet part임 (이때 /24를 subnet mask라고 부름)
CIDR: Classless InterDomain Routing(사이다라고 읽음)
- address에서 subnet portion이 임의로 주어짐.
- class가 있다면 네 종류의 subnet mask(8, 16, 24, 32)만 가능하다.
- 만약 이때 한 subnet에 5개의 host만 있다면? subnet mask를 24로 지정하게 되고, 256개의 device를 연결할 수 있는 subnet에 5개만 연결되니 낭비가 심한 것!
- address format: a.b.c.d/x
- x는 address에서 subnet portion의 길이
이제 개념을 알게 됐으니, 자연스레 두 가지 질문이 떠오른다.
Question1. Subnet에 포함된 한 host는 어떻게 IP 주소를 얻을 수 있을까? (address의 host part)
2. network는 그 자체로 IP address를 어떻게 얻을까? (address의 network part)
첫 번째 질문의 답은 아래와 같다.
1. 사람이 직접 sysadmin의 config file에 하나씩 hard-coding하는 방법.
2. DHCP(Dynamic Host Configuration Protocol)을 사용해서 서버가 동적으로 address를 할당하는 방법.
- plug-and-play
- IP를 관리하고 할당해줄 수 있는 controller가 있어야한다.
DHCP
DHCP의 목표는 host가 network에 join할 때, network server에게 동적으로 IP address를 얻을 수 있도록 하는 것이다.
- 사용 중인 address에 대해서 lease(대여기간)을 연장할 수 있어야한다.
- 영원히 할당하는 것이 아니라, timeframe 단위로 쪼개서 제한시간을 걸고 할당
- network에 join/leave하는 mobile user를 지원해줘야한다.
DHCP에는 크게 다음 4가지 packet이 있다.
- Host가 broadcast하는 DHCP discover msg (DHCP discover) [optional]
- 위 패킷에 대한 DHCP server의 response msg (DHCP offer) [optional]
- Host가 IP address를 요청하는 DHCP request msg
- DHCP server가 address를 보내주는 DHCP ACK msg
DHCP 시나리오는 다음과 같다.
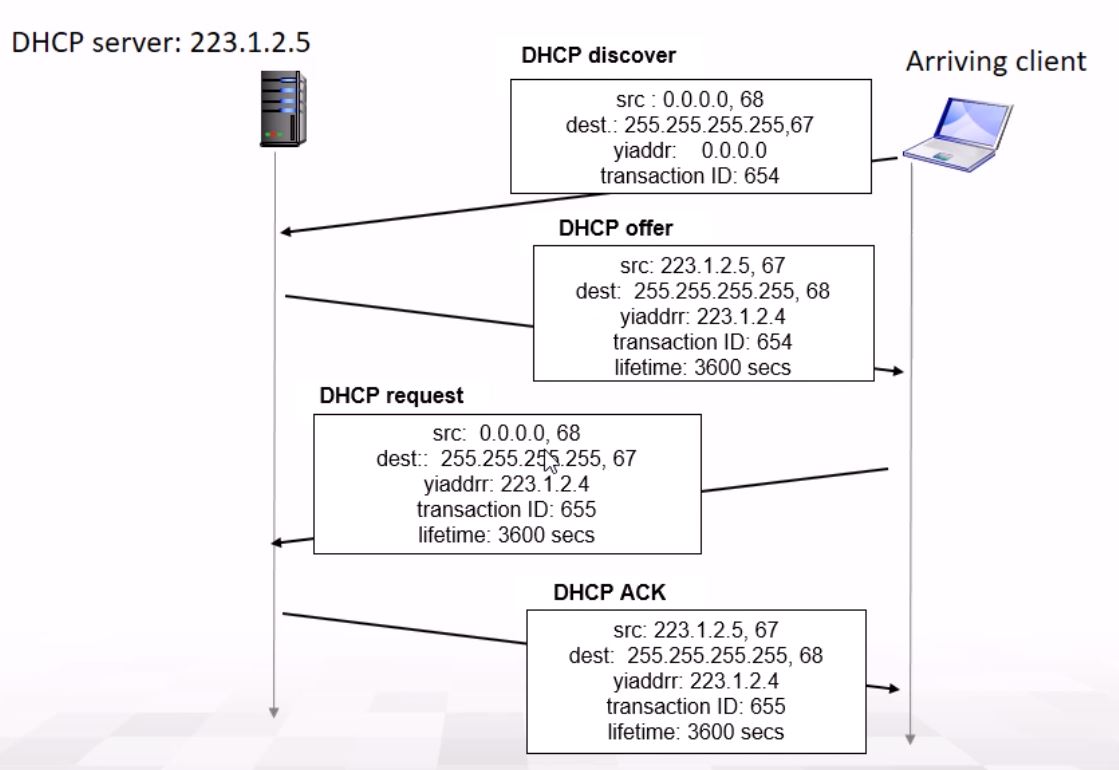
- Host가 DHCP discover msg을 broadcast함.
- broadcast하는 거기 때문에 모든 host가 해당 pkt을 받는다.
src: 0.0.0.0, 68 dest: 255.255.255.255, 67 (FFFF FFFF FFFF FFFF) yiaddr: 0.0.0.0 transaction id: 654 - 여기서 src와 dest ip의 68과 67은 subnet mask가 아닌 port 번호로 67, 68로 보통 지정되어 있다.
- DHCP server는 해당 discover에 대한 DHCP offer msg를 보낸다.
- 해당 offer msg에는 lifetime도 지정해준다. (3600secs)
src: 223.1.2.5, 67 dest: 255.255.255.255, 68 yiaddr: 223.1.2.4 transaction ID: 654 lifetime: 3600secs - Host는 transaction ID를 통해 자신이 보낸 discover msg에 대한 응답임을 알 수 있다.
- Client에 IP가 없기 때문에 또다시 broadcast로 전송하는 것..
- 만약 client가 이미 IP를 할당 받았고, 해당 IP를 재사용하길 원한다면 여기까지의 과정은 skip하고 아래 과정만 진행한다.
- Host는 해당 IP를 사용하겠다는 DHCP request msg를 보낸다.
src: 0.0.0.0, 68 dest: 255.255.255.255, 67 (FFFF FFFF FFFF FFFF) yiaddr: 223.1.2.4 transaction id: 655 lifetime: 3600secs
- 위 패킷에선 아직 자신의 source ip로 지정된 ip를 명시하지 않은 것을 볼 수 있는데, (또한 아직도 broadcast를 사용하는 것도 볼 수 있다) 아직 사용이 확실시 되지 않았기 때문이다.
- 만약 offer했는데 다른 client가 와서 후닥닥 그 ip를 쓰면 안되니까..
- 또한 위와는 별개의 transaction id를 사용하는 것도 확인할 수 있다.
- DHCP가 해당 IP address를 써도 된다는 최종 승인인 DHCP ACK msg를 보낸다.
src: 223.1.2.5, 67 dest: 255.255.255.255, 68 yiaddr: 223.1.2.4 transaction ID: 655 lifetime: 3600secs
- 드디어 마지막으로 ACK이 간 후, client는 자신의 IP를 해당 yiaddr로 지정해서 사용할 수 있다.
- 이 마지막 과정은 Assign address를 위해 반드시 필요하다.
이 과정에서 DHCP는 단지 IP address만 할당해주는 것이 아니라 host에게 더 많은 정보를 알려준다.
- first-hop router(default gateway)의 address.
- subnet 외부와 통신하기 위해서 거쳐야하는 router, 무조건 알아야된다는 뜻.
- DNS server의 이름과 IP address
- network mask (host portion과 subnet portion을 구분하기 위해서)
또한 이 모든 과정은 UDP로 이루어지는데, Client에는 아직 IP address가 없기 때문에 TCP connection을 만들 수 없어서 UDP를 사용한다.
여기까지가 첫 번째 질문에 대한 답변이다....
두 번째는 뭐였는지 가물가물 하니 다시 불러오자.
Network는 IP address의 subnet part를 어떻게 얻나?
정답은 의외로 간단하게 해당 subnet의 provider ISP에게서 얻는다. provider ISP address space의 일부를 할당받는 것.
- 만약 ISP's block이 1100100 00010111 00010000 00000000라면 (200.23.16.0/20)
- ISP는 3bits를 IP address range용도로 사용하여 아래와 같은 8개의 block들을 할당할 수 있다.
- 1100100 00010111 00010000 00000000 (200.23.16.0/23)
- 1100100 00010111 00010010 00000000 (200.23.18.0/23)
- 1100100 00010111 00010100 00000000 (200.23.20.0/23)
... - 1100100 00010111 00011110 00000000 (200.23.30.0/23)
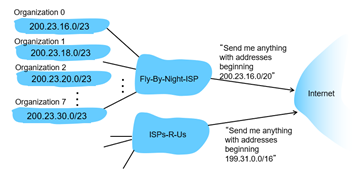
위와 같은 Hierarchical addressing을 통해 routing information을 효율적으로 광고할 수 있다.
또한 하나의 조직이 만약 다른 ISP로 이동했을 지라도, ISP의 routing table만 update하면 될 뿐 subnet 내부의 ip는 변경하지 않아도 되니 아주 효율적이다!
Q. 추가적으로 ISP는 어떻게 IP를 할당받느냐..?
A. DNS를 관리하고, Domain name을 지정하며 ICANN이라는 기관에서 할당받은 것.
Q. 32bit의 ip를 쓴다면 그건 세상에 최대 2^32개의 interface만 존재할 수 있다는 말이다. 1인당 쓰는 기기가 스마트폰, 워치, 태블릿, 노트북, 데스크탑에다가 각종 IoT 기기들만 해도 2^32개가지곤 부족할 것 같은데.. 하물며 Interface가 저 개수로 제한되는 것은 말이 안된다.
A. NAT이 IPv4의 부족함을 해결해준다. (다음에 배움) 그리고 IPv6도 새로 나왔다!
다음 게시글에서는 NAT에 대해서 배워보자
