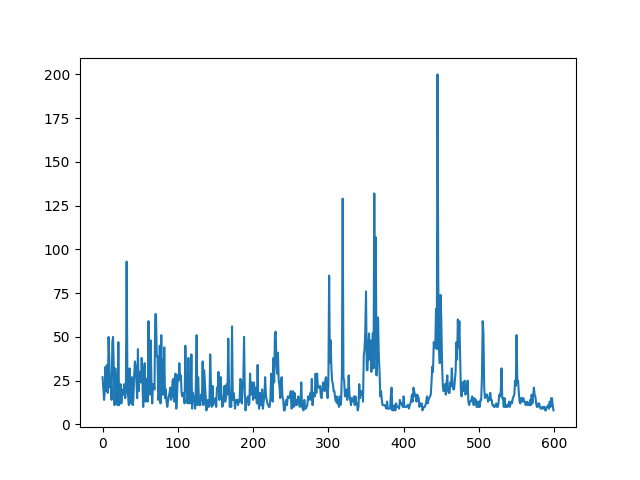
지난 시간 DQN을 코딩하여 openai gym의 CartPole-v0 모델을 학습한 결과입니다.
전체적으로 보면 점점 증가하는 것처럼 보여 얼핏 보면 잘 학습되었다고 볼 수 있습니다.

기존 DQN의 문제점
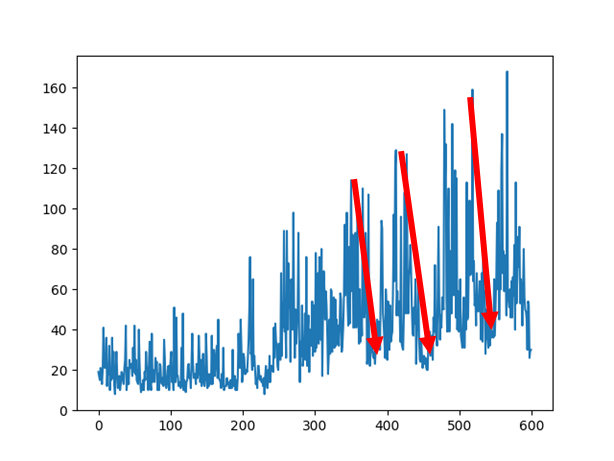
300 에피소드가 지나가면서 성능이 급격하게 올라가기 시작하는데 그러다가 갑자기 확 떨어지는 부분을 확인할 수 있습니다. 이것을 최악의 망각(catastrophic forgetting)이라고 합니다. replay buffer를 늘리거나 learning rate를 감소시키면 이러한 영향이 조금 감소할 수는 있지만, 학습이 느려지기 때문에 완벽한 해결책은 아닙니다.
일반 신경망 학습 때 처럼 "손실을 보면 알 수 있지 않을까?" 라고 생각할 수 있지만, 손실이 줄어들더라도 정상적인 동작을 한다는 보장이 없습니다.
DQN의 3번째 개선
사실 이번 코드를 보면 지난번 제시한 문제점 중 2가지만 해결했습니다.
- Go deep
- Capture & replay
- Serperate network
일반적인 네트워크로 학습하는 경우 Q-가치를 업데이트 하면 타깃이 흔들리는 문제가 발생합니다. 이는 꼬리를 잡으려 움직이면 꼬리가 도망가는 것처럼 자신의 꼬리를 쫒아 뱅글뱅글 도는 강아지와 비슷합니다.
이 문제를 해결하기 위해서는 네트워크를 두 개로 만들어 각각 타깃과 Q-가치를 따로 업데이트 하도록 하는 것이 해결책이었습니다.
코드상으로는 기존 모델을 초기화하고, 이를 깊은 복사를 통한 새로운 타겟 모델 객체를 생성해줍니다.
model = keras.models.Sequential([
keras.layers.Dense(32, activation="elu", input_shape=input_shape),
keras.layers.Dense(32, activation="elu"),
keras.layers.Dense(32, activation="elu"),
keras.layers.Dense(n_outputs)])
target = keras.models.clone_model(model)
target.set_weights(model.get_weights())다음은 기존의 업데이트 함수입니다.
def training_step(batch_size):
experiences = sample_experiences(batch_size)
states, actions, rewards, next_states, dones = experiences
next_Q_values = model.predict(next_states)
max_next_Q_values = np.max(next_Q_values, axis=1)
target_Q_values = (rewards + (1 - dones) * discount_factor * max_next_Q_values)
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, n_outputs)
with tf.GradientTape() as tape:
all_Q_values = model(states)
Q_values = tf.reduce_sum(all_Q_values * mask, axis=1, keepdims=True)
loss = tf.reduce_mean(loss_fn(target_Q_values, Q_values))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))기존 업데이트 함수의 4번째 줄에서 보듯 model을 예측하지 않고 target을 통하여 예측하도록 바꾸어 줍니다.
def training_step(batch_size):
experiences = sample_experiences(batch_size)
states, actions, rewards, next_states, dones = experiences
next_Q_values = target.predict(next_states) # model -> target
max_next_Q_values = np.max(next_Q_values, axis=1)
target_Q_values = (rewards + (1 - dones) * discount_factor * max_next_Q_values)
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, n_outputs)
with tf.GradientTape() as tape:
all_Q_values = model(states)
Q_values = tf.reduce_sum(all_Q_values * mask, axis=1, keepdims=True)
loss = tf.reduce_mean(loss_fn(target_Q_values, Q_values))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))마지막으로 target네트워크의 가중치도 업데이트를 하여야 하기 때문에 일정 에피소드 주기로 업데이트를 하도록 마지막 두 줄을 추가하였습니다.
all_reward = []
for episode in range(600):
print('episode {}'.format(episode))
obs = env.reset()
sum_reward = 0
for step in range(200):
epsilon = max(1 - episode / 500, 0.01)
obs, reward, done, info = play_one_step(env, obs, epsilon)
sum_reward += reward
if done:
break
all_reward.append(sum_reward)
if episode > 50:
training_step(batch_size)
if episode % 50 == 0:
target.set_weights(model.get_weights())타깃 모델이 자주 업데이트 되지 않기 때문에 Q-가치의 타깃이 안정적이게 됩니다.
최대 스텝이 기존 160 정도에서 좀 더 200에 가까워 졌습니다.
Double DQN
개선이 되었다는 것은 분명하나, 우리가 원하던 만큼 다이나믹하게 변하진 않았습니다.
그 이유는 타깃 모델은 벨만 방정식의 최댓값 연산 때문에 실제 얻을 수 있는 보상보다 더 많이 받을 것이라고 과대평가를 하게 됩니다.
이를 개선하기 위해서는 벨만 업데이트를 수정하여 다음 상태의 최선의 행동을 선택할 때는 타깃 모델이 아니라 온라인 모델을 사용하도록 제안한 것이 Double DQN입니다.
- 기본
DQN의 업데이트 식 - 수정된
Double DQN의 업데이트 식- 행동: 온라인 신경망(Q)으로 부터 선택
- 행동가치: 타깃 신경망(Q')으로부터 계산
`
다음은 바로 전에 수정하였던 DQN의 업데이트 코드입니다.
def training_step(batch_size):
experiences = sample_experiences(batch_size)
states, actions, rewards, next_states, dones = experiences
next_Q_values = target.predict(next_states)
max_next_Q_values = np.max(next_Q_values, axis=1)
target_Q_values = (rewards + (1 - dones) * discount_factor * max_next_Q_values)
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, n_outputs)
[이하 생략...]def training_step(batch_size):
experiences = sample_experiences(batch_size)
states, actions, rewards, next_states, dones = experiences
next_Q_values = model.predict(next_states)
best_next_actions = np.argmax(next_Q_values, axis=1)
next_mask = tf.one_hot(best_next_actions, n_outputs).numpy()
next_best_Q_values = (target.predict(next_states) * next_mask).sum(axis = 1)
target_Q_values = (rewards+(1-dones) * discount_factor * next_best_Q_values)
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, n_outputs)
[이하 생략...]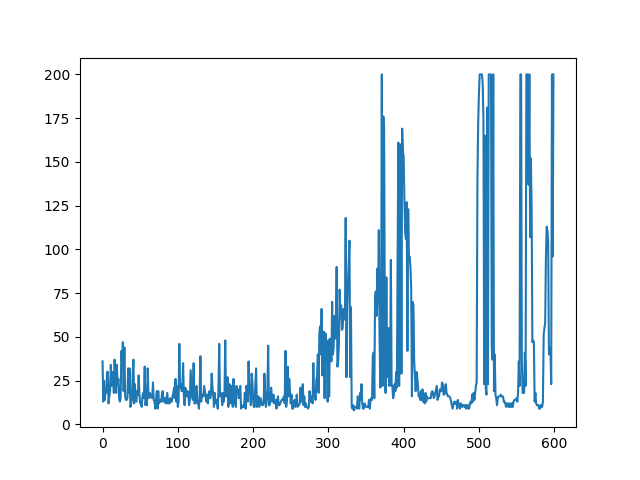
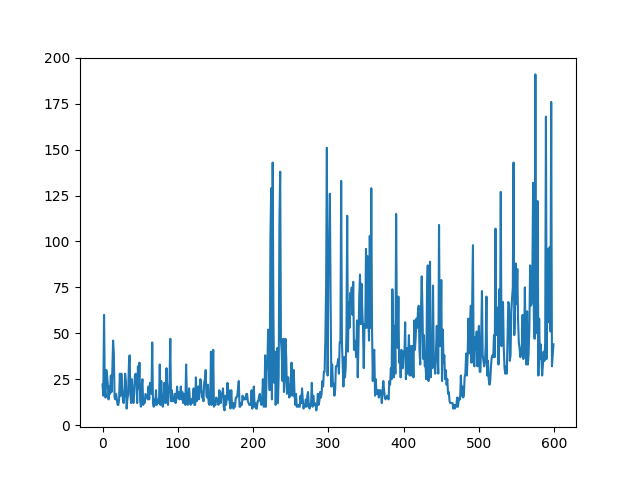
여전히 catastrophic forgetting 문제가 있지만, 개선이 있다는 것 또한 분명합니다.
실제 딥마인드 팀은 0.00025 정도로 작은 학습률을 사용하고 10,000 스텝마다 타깃 모델을 업데이트하고 재생 버퍼의 크기를 100만으로 키우고 5천만 스텝동안 알고리즘을 실행하였습니다.
우리의 모델 역시 재생 버퍼를 키우고 스텝과 에피소드를 늘린다면 분명 더 발전할 수 있을 것입니다.
하지만 위의 figure의 경우 그나마 잘 나온 경우에 속하고 재수가 없는 경우 아래와 같은 학습을 보이는 경우도 있으니 어느정도의 trade-off가 필요한지 감이 오질 않습니다..