📖 Tutorial
여러분은 모델을 만들었습니다. 하지만 이 모델은 어느정도의 성능을 가질까요?
이번 레슨에서는, 여러분의 모델 성능을 측정할 수 있는 model validation에 대해서 배울 것입니다.
모델 성능을 측정하는 것은 여러분 모델을 반복적으로 향상시키는데 큰 도움이 됩니다.
What is Model Validation
여러분은 지금까지 만든 거의 모든 모델을 평가해야 합니다. 대부분의 애플리케이션에서, 모델 성능의 측정 값은 예측 정확도를 의미합니다. 다시 말해, 이 모델의 예측이 실제 데이터에 얼마나 근접하는지를 이야기 합니다.
많은 사람들이 에측 정확도를 측정할 때 큰 실수를 합니다. 그들은 트레이닝 데이터로 예측을 하고, 그 예측을 트레이닝 데이터의 목표값과 비교합니다. 이 접근 방식의 문제와 해결 방안은 잠시 후에 확인할 수 있지만, 우선 어떻게 해결할 수 있을지 생각해봅시다.
먼저, 모델 성능을 우리가 이해할 수 있는 방식으로 요약해야 합니다. 10,000채의 주택에 대한 예측값과 실제 주택값을 비교해 보면 좋은 예측값과 안좋은 예측값이 섞여있는 것을 확인할 수 있습니다. 단순히 10,000채의 주택 리스트를 훑어보는 것은 무의미한 작업입니다. 우리는 이를 하나의 지표로 요약할 필요가 있습니다.
모델 성능을 요약할 수 있는 많은 지표가 있지만, Mean Absolute Error(MAE 라고도 함) 지표로 우선 시작해보겠습니다. 이 지표의 마지막 단어인 error로 시작하여 이 지표를 분석해 봅시다.
각 주택에 대한 예측 에러는 다음과 같이 표현됩니다:
에러 = 실제 주택의 가격 - 예상 가격즉, 만약 주택의 가격이 $150,000이고 여러분의 예측값이 $100,000이라면, 에러는 $50,000이 됩니다.
MAE 지표에서는 우선 각 오류의 절대값을 구합니다. 이렇게 하면 각 오류가 양수로 변환됩니다 그런 다음 해당 값의 절대 오차의 평균을 구합니다. 이 것이 모델 성능을 측정하는 우리의 척도입니다. 문장으로는, 다음과 같이 표현할 수 있습니다:
평균적으로, 우리의 예측은 X 만큼 빗나갔다.
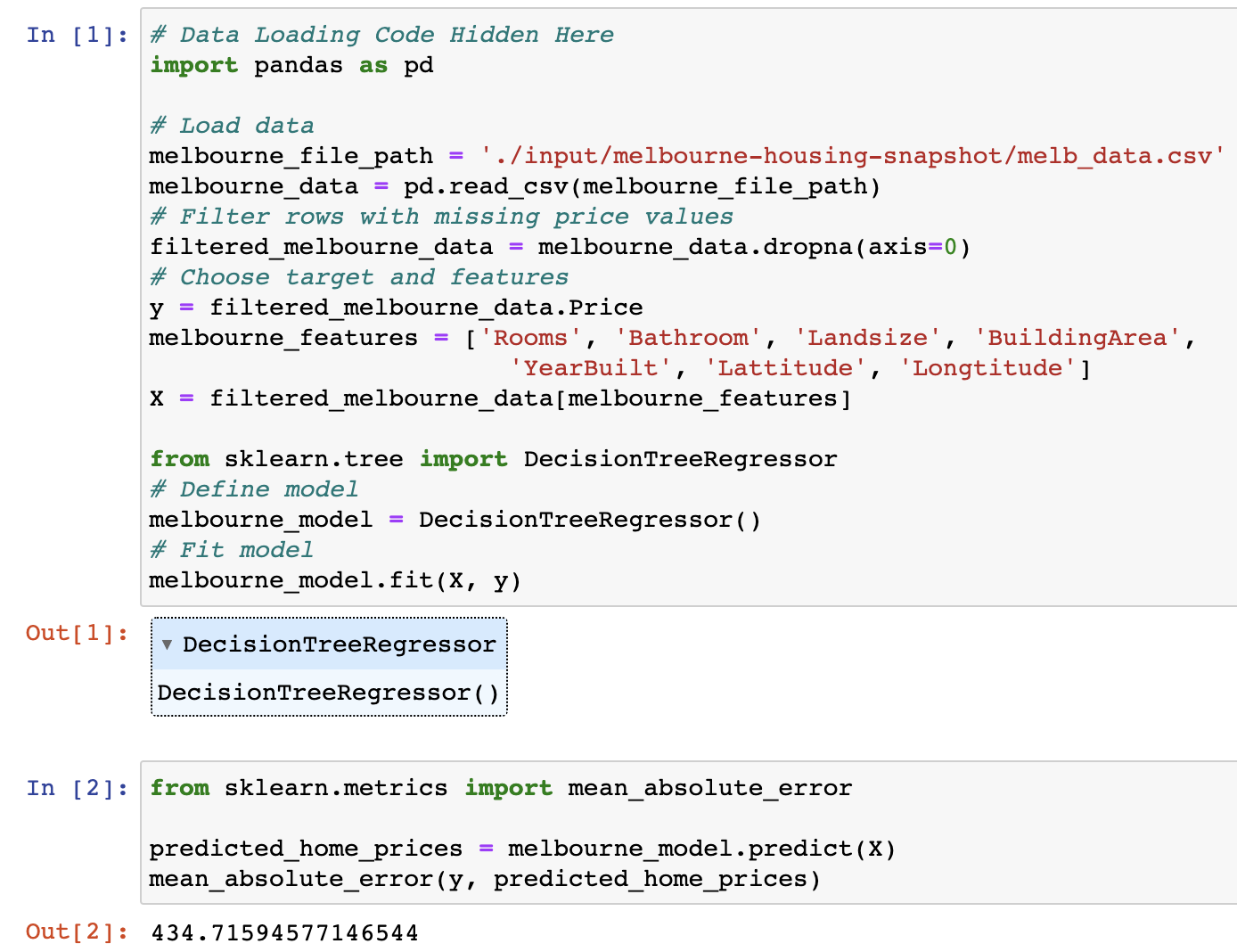
MAE를 계산하기 위해서는 우선 모델이 필요합니다. 아래와 같이 모델을 생성하겠습니다.
# 데이터 로딩 코드
import pandas as pd
# 데이터 읽기
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 가격에 결측값이 있는 행 제거
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# 타겟과 feature 설정
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
# 모델 정의
melbourne_model = DecisionTreeRegressor()
# 모델 피팅
melbourne_model.fit(X, y)모델이 생성되고 나서, 다음 코드를 통해 MAE를 구할 수 있습니다:
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)
The Problem with "In-Sample" Scores
방금 계산한 측정값은 "샘플 내" 점수라고 할 수 있습니다. 우리는 모델을 만들고 평가하는 데 단일 주택 "샘플"을 사용했습니다. 이 것이 나쁜 이유입니다.
실제 대형 부동산 시장에서 문 색깔이 집값과 무관하다고 상상해보세요.
그러나, 우리 데이터 샘플에서 녹색 문이 있는 모든 가정은 매우 가격이 높았습니다. 이 모델의 일은 집값을 예측하는 패턴을 찾는 것입니다. 그래서 이 패턴을 보게 될 것이고, 항상 녹색 문이 있는 집을 높은 가격으로 예측할 것입니다.
이 패턴은 트레이닝 데이터에서 파생되었기 때문에, 모델은 트레이닝 데이터에서 정확한 결과를 도출합니다.
하지만 이 모델이 새로운 데이터를 확인할 때 이 패턴이 유지되지 않으면 실제 사용할 때 이 모델은 매우 부정확하게 됩니다.
모델의 실제 성능은 새로운 데이터를 예측하는 데에서 나오기 때문에, 모델을 구축하는 데 사용되지 않은 데이터를 통해 성능을 측정해야합니다. 가장 간단한 방법은 모델 구축 프로세스에서 일부 데이터를 제외한 다음, 이러한 데이터를 사용하여 모델의 성는을 테스트하는 것입니다. 이 데이터를 validation data, 유효성 검사 데이터라고 합니다.
Coding It
scikit-learn 라이브러리에는 데이터를 두 조각으로 나누는 train_test_split 함수가 존재합니다. 해당 데이터 중 일부를 모델에 적합한 트레이닝 데이터로 사용하고, 나음 다른 데이터를 유효성 검사 데이터로 사용하여 mean_absolute_error를 계산합니다.
해당 코드는 다음과 같습니다:
from sklearn.model_selection import train_test_split
# 데이터를 트레이닝, 유효성 검사 데이터로 나누며, 각각은 타겟과 feature들이 존재함
# 데이터를 나누는 작업은 rng(Random Number Generator)에 의해 결정됨
# random_state에 값을 지정해주면 항상 같은 분열 결과를 나타냄
# 아래 코드를 실행
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# 모델 정의
melbourne_model = DecisionTreeRegressor()
# 모델 피팅
melbourne_model.fit(train_X, train_y)
# 유효성 검사 데이터에서 예측 가격을 가져옴
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))

Wow!
"In-sample" 데이터에 의한 MAE는 약 $500이었습니다. 하지만, "Out-ofsample" 데이터에 의한 MAE는 $250,000을 넘습니다.
이것은 거의 정확하게 맞는 모델과 가장 실용적인 목적으로 사용할 수 없는 모델의 차이입니다. 참고로, 검증 데이터의 평균 주택 가치는 110만 달러입니다. 따라서, 새로운 데이터의 error는 평균 주택 가치의 약 1/4입니다.
모델을 개선하기 위해서 더 나은 feature을 찾거나 다른 모델 유형을 선정하기 위해 실험하는 등의 다양한 방법이 존재합니다.
Your Turn
이 모델을 개선시키기 전에, 모델 평가를 여러분 스스로 해보세요.
