📖 Tutorial
이 단계를 마치면 여러분은 과소적합과 과적합의 개념을 이해하고, 이러한 개념을 적용하여 모델을 보다 정확하게 만들 수 있습니다.
Experimenting With Different Models
이제 여러분들은 모델의 정확도를 측정할 수 있는 신뢰할 수 있는 방법을 사용하여 여러 모델을 실험하고 어떤 모델이 가장 적합한 예측을 제공하는지 확인할 수 있습니다. 하지만, 다른 여러 모델에는 어떤 모델이 존재할까요?
scikit-learn 라이브러리 문서에 따르면, 의사 결정 트리 모델에는 많은 옵션이 있음을 알 수 있습니다(아마 여러분이 필요하거나 원하는 것보다 더 많은 옵션). 이 중 가장 중요한 옵션은 트리의 깊이를 지정합니다. 이 과정의 첫 번째 레슨에서 트리의 깊이는 예측에 도달하기 전에 얼마나 많은 분할을 하는지 측정하는 것임을 기억하십시오. 아래는 상대적으로 얕은 트리를 나타냅니다.
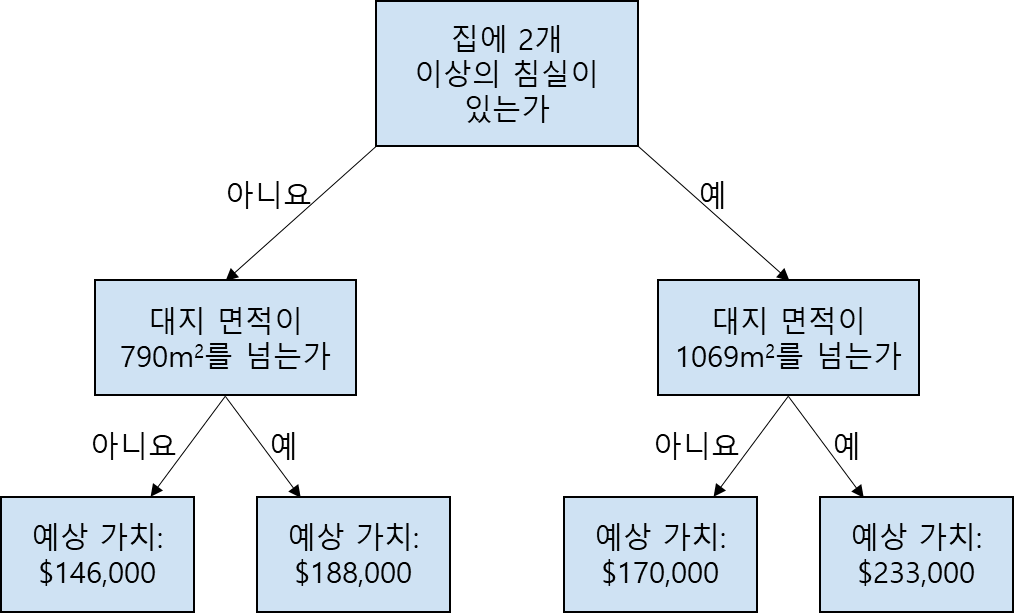
실제로, 트리에서 10개 이상의 분류를 가지는 것은 흔한 일이 아닙니다. 트리가 더 깊어질수록, 데이터셋은 여러 잎으로 나뉘기 때문에 각 잎은 더 적은 수의 주택을 가지고 있습니다. 만약 트리가 한 번의 분류만 거친다면, 데이터는 총 2개의 그룹으로 나뉘게 됩니다. 만약 이 그룹이 다시 나뉜다면 4개의 그룹이, 또 다시 나뉜다면 8개 그룹이 생성됩니다. 이렇게 각 레벨 당 분류를 통해 그룹의 수를 2배씩 곱해 나가면 깊이 10에는 총 개의 주택 그룹이 생기고, 이는 총 1024개의 잎이 생기는 것을 의미합니다.
더 많은 이파리로 주택들을 나누면서 각 이파리에는 더 적은 수의 주택이 할당됩니다. 주택이 거의 없는 이파리는 주택의 실제 가치에 상당히 가까운 예측을 하지만, 새로운 데이터에 대해서는 매우 신뢰할 수 없는 예측을 할 수 있습니다(각각의 예측이 주택 몇 개의 데이터에만 기초하기 때문).
이런 현상을 과적합(overfitting) 이라고 합니다. 모델이 너무 트레이닝 셋에 완벽하게 학습된 경우, 새로운 형태의 데이터가 들어왔을 때 좋지 못한 결과를 만드는 것이죠.
반대로, 트리를 아주 얕게 만드는 경우에는 해당 주택을 뚜렷한 그룹으로 나누지 못합니다.
극단적으로 트리가 오직 2개 또는 4개의 그룹으로 주택을 나눈다면, 각 그룹은 정말 많은 수의 주택을 가지고 있을 것입니다. 이 경우 주택 가격의 예측값은 트레이닝 데이터의 주택 가치에서도 많이 떨어져있을 수 있습니다(같은 이유로 유효성 검사도 좋은 결과가 나오지 않을 것). 이처럼 모델이 데이터에서 중요한 차이와 패턴을 파악하지 못해서 트레이닝 데이터에서도 성능이 떨어지는 경우를 과소적합(underfitting) 이라고 합니다.
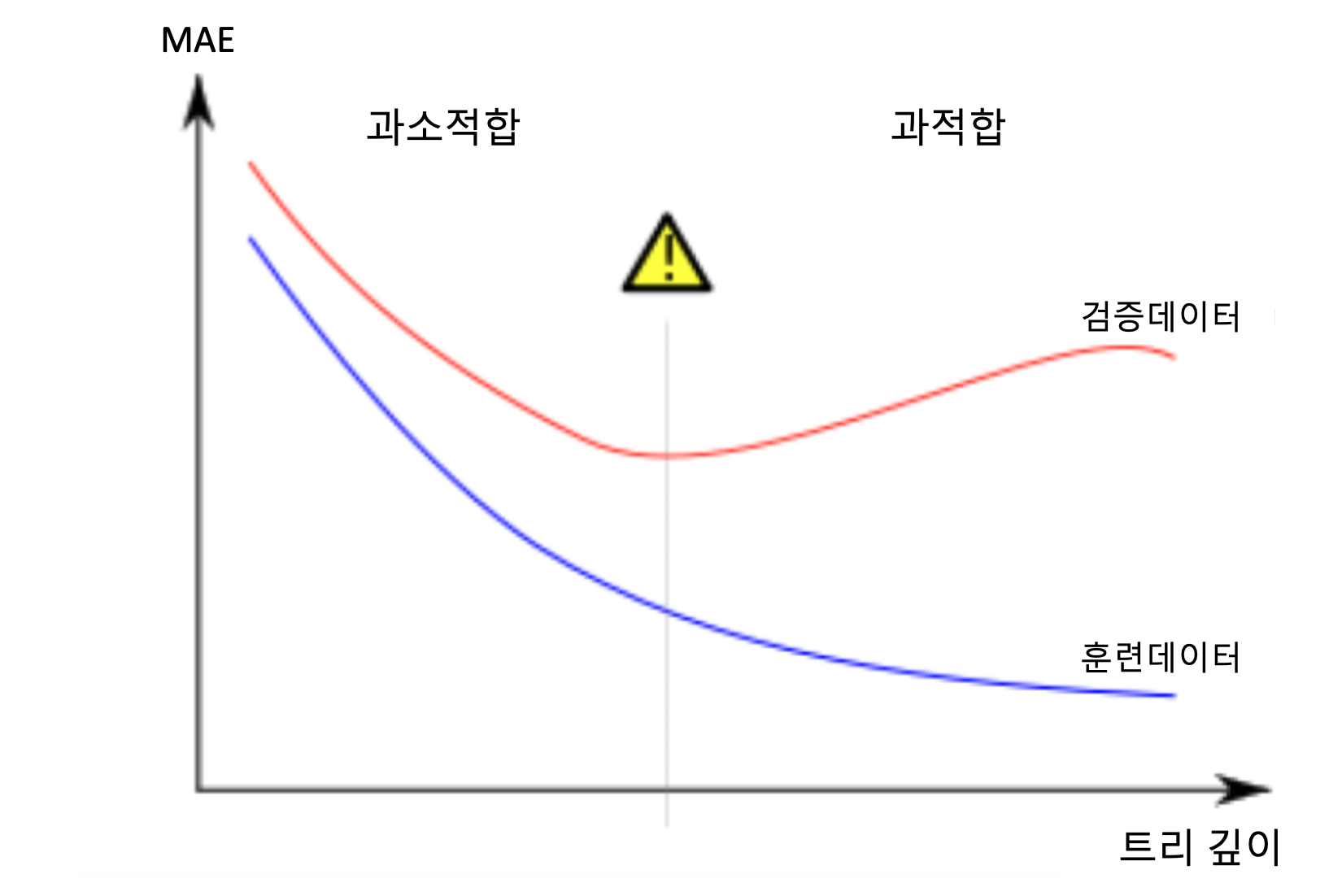
검증 데이터에서 추정하는 새 데이터에 대한 정확성에 관심이 있기 때문에, 과소적합과 과적합 사이의 최적 지점을 찾아야 합니다. 아래와 같이 시각적으로, 우리는 (빨간색) 유효성 검사 곡선의 극소점을 찾아야 합니다.
Example
트리의 깊이를 제어하는 방법에는 다양한 방법이 존재하며, 대부분의 경우 트리의 일부 경로가 다른 경로와 다른 깊이를 가질 수 있습니다. 그러나 max_leaf_nodes 인자는 과적합과 과소적합을 제어하는 데 매우 합리적인 방식을 제공합니다. 모델에서 더 많은 이파리가 생성될 수 있도록 할 수록 모델은 과소적합에서 과적합으로 더 많이 이동합니다.
유틸리티 함수를 활용하여 max_leaf_nodes 값에 따른 MAE 점수의 차이를 다음과 같이 계산할 수 있습니다:
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)데이터는 이미 봤던 코드(이미 작성한 코드)를 활용하며 train_X, train_y, val_X, val_y로 읽습니다.
# 데이터를 읽는 코드
import pandas as pd
# 데이터 읽기
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 결측값이 있는 행 제거
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# 타겟과 Feature 설정
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# 각각 타겟과 feature에 대한 훈련/검증 데이터 분류
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)이 후 for 루프를 통해 다른 Max_leaf_nodes 값에서 MAE를 서로 비교할 수 있습니다.
# 서로 다른 max_leaf_nodes 값으로 MAE 비교
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
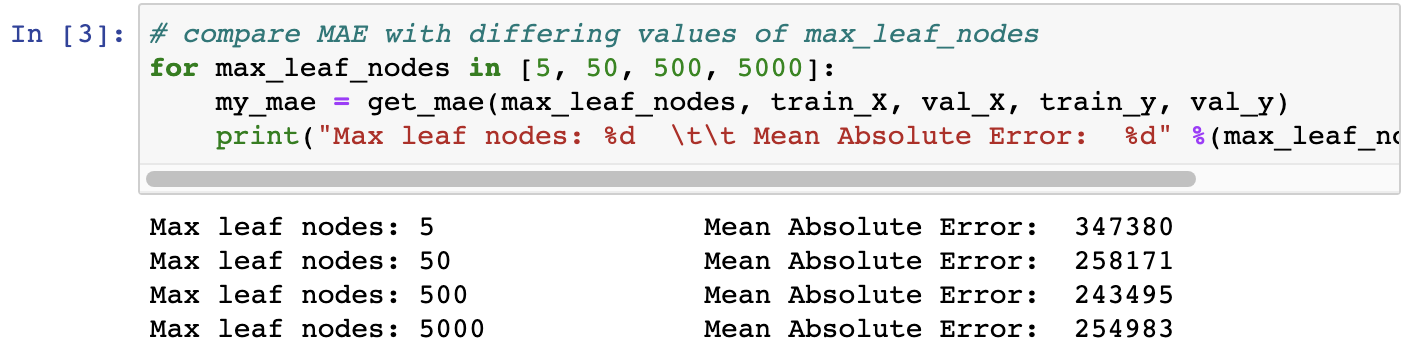
나열된 옵션 중, max_leaf_nodes 값이 500일 때 가장 최적의 해임을 알 수 있습니다.
Conclusion
모델에서 생길 수 있는 문제는 다음과 같습니다:
- 과적합: 실제 데이터에서 나오지 않는 가짜 패턴을 캡처하여 정확도가 떨어지는 예측을 수행합니다.
- 과소적합: 패턴을 캡쳐하지 못해 정확도가 떨어지는 예측을 수행합니다.
우리는 모델 훈련에 사용되지 않는 검증 데이터를 사용하여 모델의 정확도를 측정합니다. 이를 통해 많은 모델을 시도하고 최상의 모델을 유지할 수 있습니다.
Your Turn
이전에 작성한 모델을 최적화해보시길 바랍니다.
