Paper Summary : FastViT
2. Related Work
2.1 Hybrid Vision Transformers
accuracy 를 유지하면서 효율적인 네트워크를 design 하기 위해 최근 연구에서는
conv 와 transformer design 을 결합한 hybrid architecture 를 도입하여 local, global 정보들을 효과적으로 capture 한다.
hybrid transformer = combine convolutional and transformer design
- 67 : MetaFormer Is Actually What You Need for Vision
hybrid architecture 들의 대부분에서 token mixer 는 self-attention 기반이 우세하다. 최근 MetaFormer 에서는 token mixing 의 후보로 간단하고 효율적인 Pooling 방식을 소개하였다.
2.2 Structural Reparameterization
최근 연구에서 작은 메모리 access 비용으로 reparameterizating skip connections 의 장점을 보여준다.
- 13 : RepVGG: Making VGG-style ConvNets Great Again
- 57 : MobileOne: An Improved One millisecond Mobile Backbone
Reparameterization trick? 아니… RepVGG 에서 아이디어 가져왔다.
inference 시 RepMix component 에서 reparameterizable 한 새로운 architecture 를 채택한다.
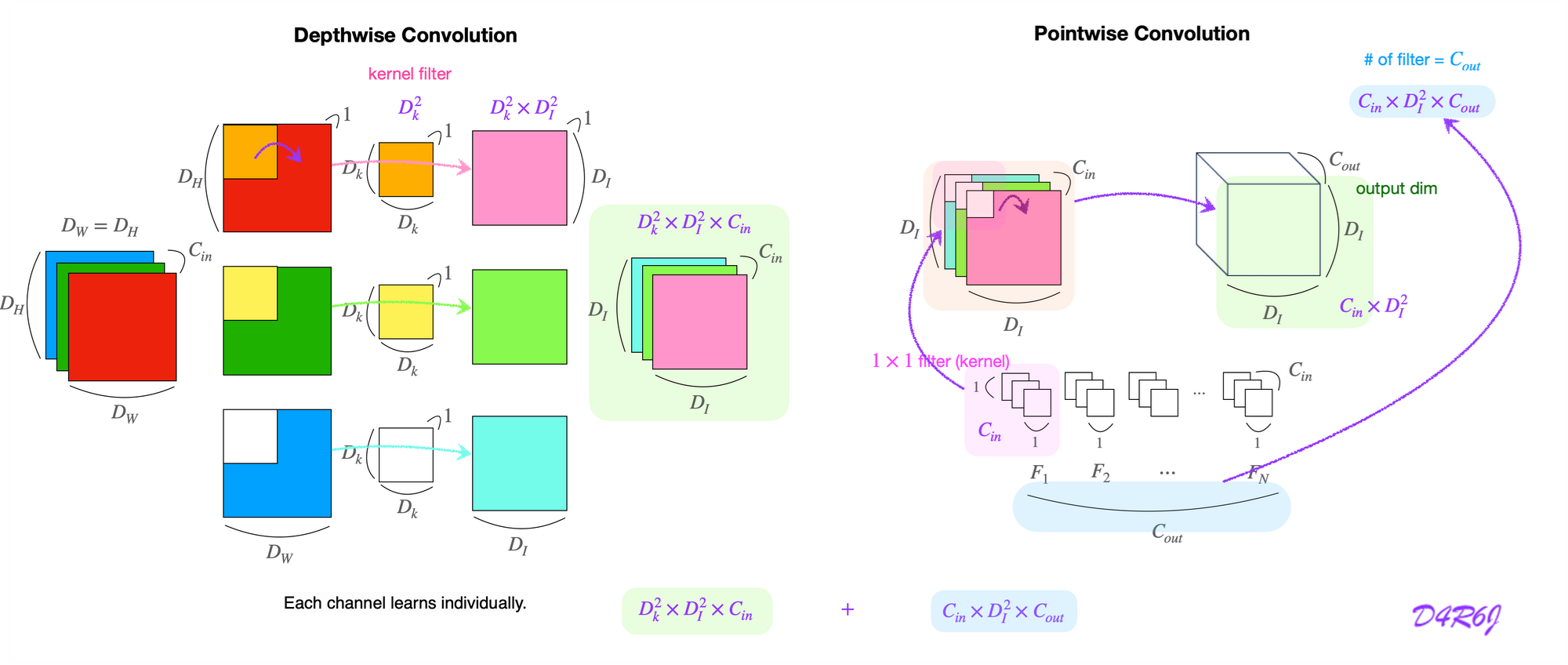
- Xception: Deep Learning with Depthwise Separable Convolutions
좀 더 효율적인 works 를 위해 depthwise 또는 pointwise conv 에 의해 그룹화 된 conv 를 사용하여 factorized 된 conv 를 채택한다.
우리가 아는 한 (To the best of our knowledge)
skip connections 를 제거하기 위한 구조적인 reparameterization 과 선형 overparameterization 은 어떤 사전적인 hybrid transformer architecture 에서도 시도되지 않았다.
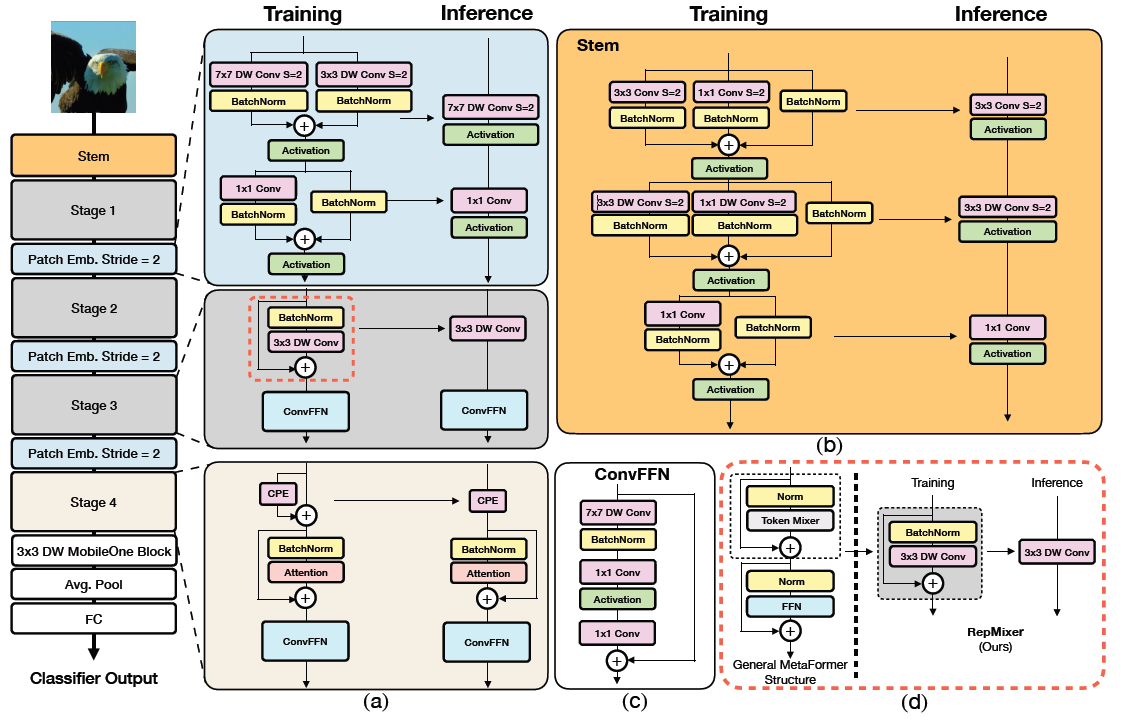
3. Architecture
3.1 Overview
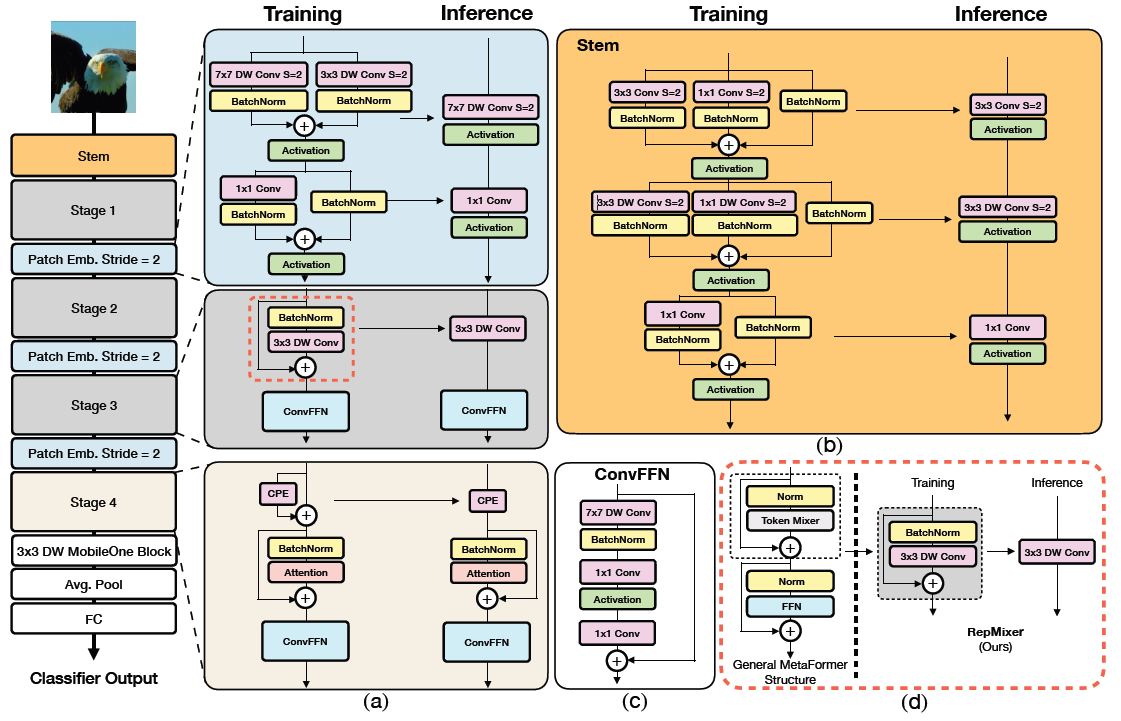
FastViT is a hybrid transformer and has four distinct stages which operate at different scales as shown in Figure 2.
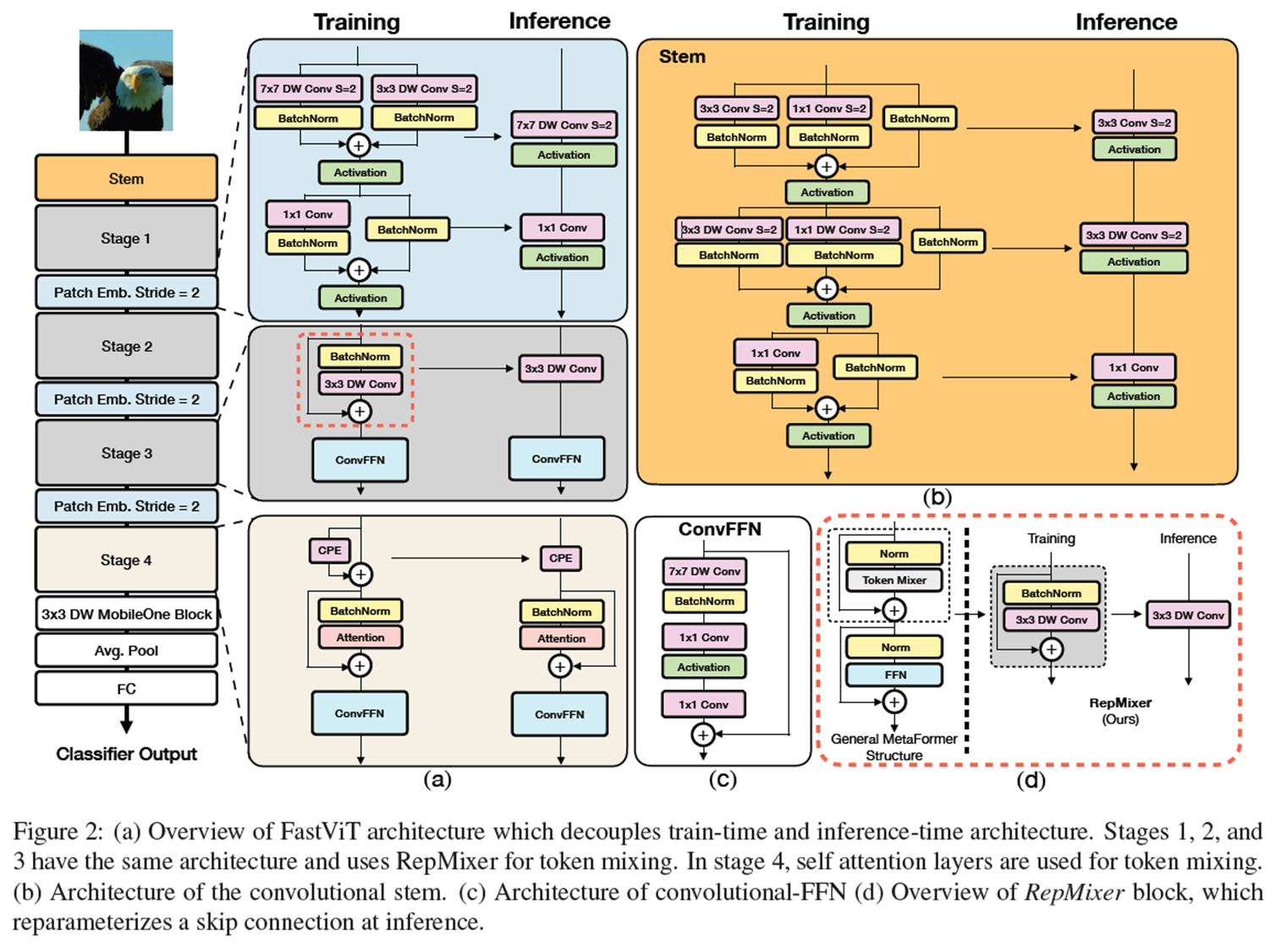
FastViT uses RepMixer, a token mixer that reparameterizes a skip connection, which helps in alleviating (완화하다) memory access cost (see Figure 2d)
3.2 Reparameterizes a skip connection
3.2.1 RepMixer ( Reparameterization Mixer )
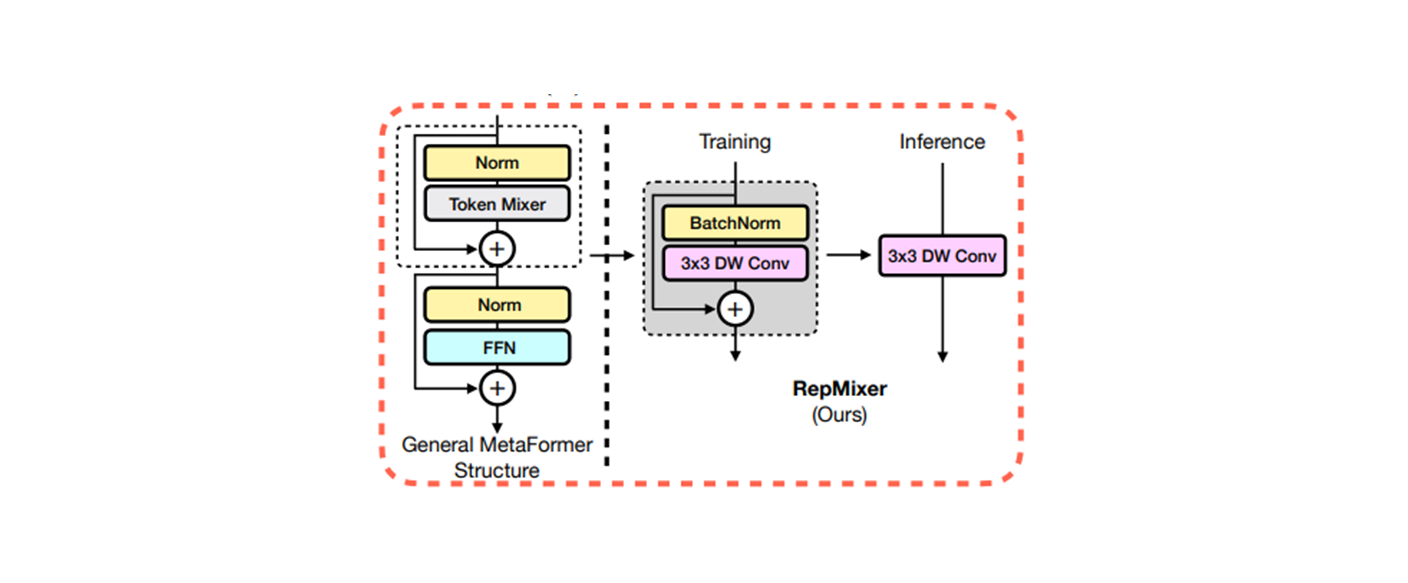
: non-linear activation function
: Batch Normalization layer
: depthwise convolution layer.
연산이 복잡하므로, 간단하게 non-linear activation function 을 지우고, input 값에 대한 bias 를 구하고 를 구하는 것이..
it can be reparameterized at inference time to a simgle depthwise convolutional layer
def reparameterize_model(model: torch.nn.Module) -> nn.Module:
...
# Avoid editing original graph
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, "reparameterize"):
module.reparameterize()
return modelGreen : conv + BN layer → conv + Bias
Orange : conv + BN layer → conv + Bias
Identity + BN : conv + BN layer → conv + Bias
def reparameterize(self):
...
if self.inference_mode:
return
kernel, bias = self._get_kernel_bias()
self.reparam_conv = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups,
bias=True,
)
self.reparam_conv.weight.data = kernel
self.reparam_conv.bias.data = bias
# Delete un-used branches
for para in self.parameters():
para.detach_()
self.__delattr__("rbr_conv")
self.__delattr__("rbr_scale")
if hasattr(self, "rbr_skip"):
self.__delattr__("rbr_skip")
self.inference_mode = True- independent validate code.
def validate(args): ... # create model model = create_model( args.model, pretrained=args.pretrained, num_classes=args.num_classes, in_chans=3, global_pool=args.gp, scriptable=args.torchscript, inference_mode=args.use_inference_mode, ) ... # Reparameterize model model.eval() if not args.use_inference_mode: _logger.info("Reparameterizing Model %s" % (args.model)) model = reparameterize_model(model)
3.2.2 Positional Encodings
conditional positional encodings
pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))]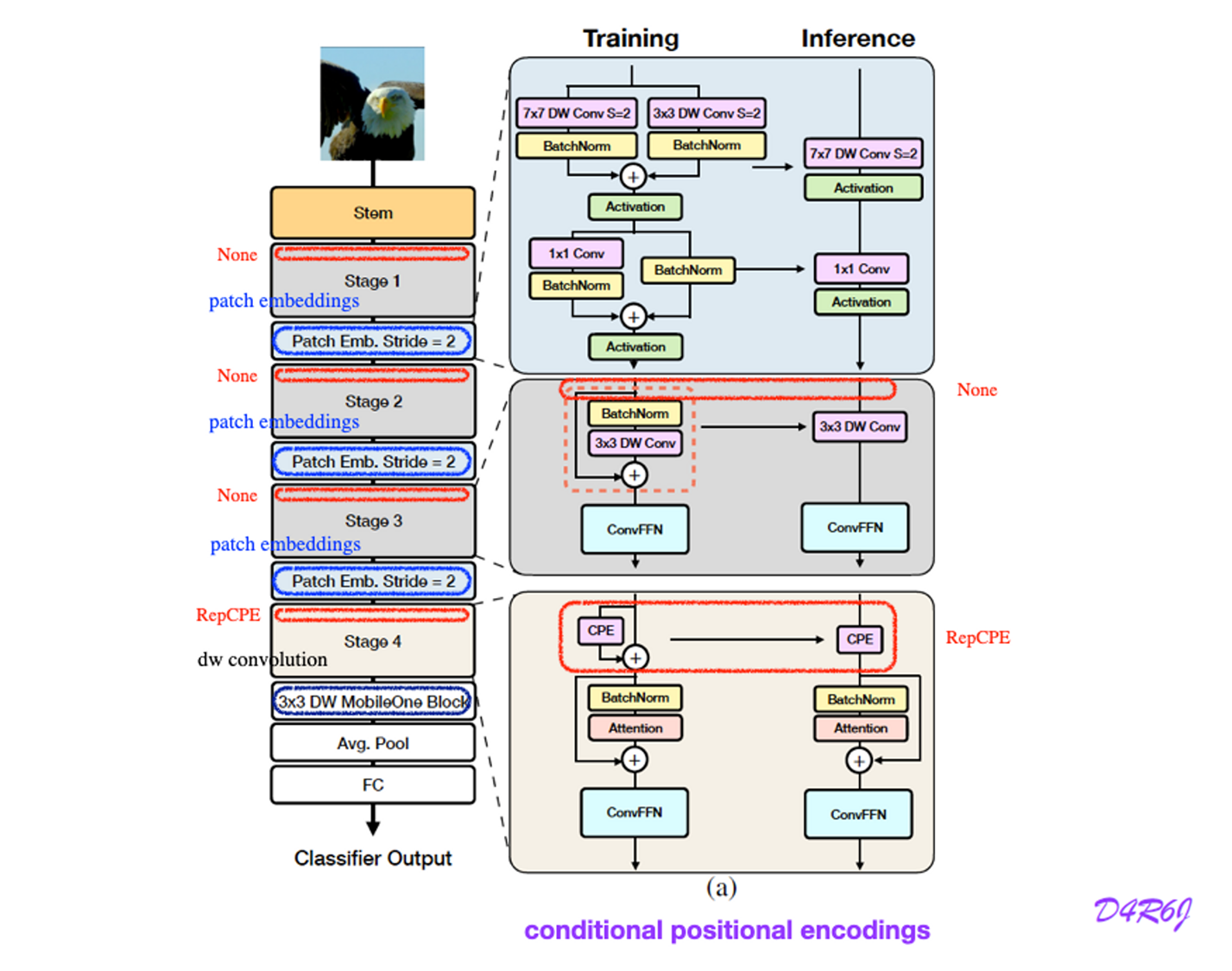
depth-wise conv operator 과 patch embedding 을 더한 것의 결과로써 이 encoding 들이 만들어 졌다.
- RepCPE ( Conditional Positional Encoding )
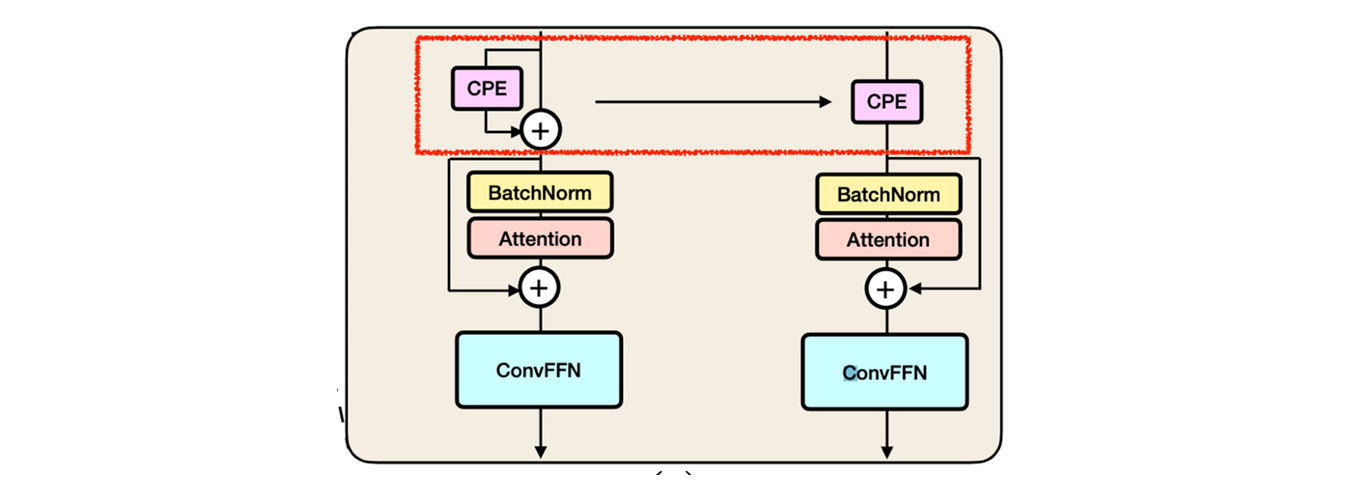 positional encoding 을 training time 에서는 residual connection 개념으로 학습하고, inerence time 에서는 역시 re-parameterize conv 로 넘겨서 연산 비용을 줄였다.
positional encoding 을 training time 에서는 residual connection 개념으로 학습하고, inerence time 에서는 역시 re-parameterize conv 로 넘겨서 연산 비용을 줄였다.class RepCPE(nn.Module): ... def forward(self, x: torch.Tensor) -> torch.Tensor: if hasattr(self, "reparam_conv"): x = self.reparam_conv(x) return x else: x = self.pe(x) + x return x- inference mode
if inference_mode: self.reparam_conv = nn.Conv2d( in_channels=self.in_channels, out_channels=self.embed_dim, kernel_size=self.spatial_shape, stride=1, padding=int(self.spatial_shape[0] // 2), groups=self.embed_dim, bias=True, ) - training mode
else: self.pe = nn.Conv2d( in_channels, embed_dim, spatial_shape, 1, int(spatial_shape[0] // 2), bias=True, groups=embed_dim, )
- inference mode
3.2.3 Empirical analysis
reparameterizing skip connections ( when inference ) 의 이점 을 좀 더 효과적 ( in terms of latency : 응답 대기 시간 ) token mixer ( MetaFormer S12 architecture ) 의 Pooling 과 RepMixer 사용시 비교.
@register_model
def fastvit_t8(pretrained=False, **kwargs):
"""Instantiate FastViT-T8 model variant."""
layers = [2, 2, 4, 2]
embed_dims = [48, 96, 192, 384]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, True, True, True]
token_mixers = ("repmixer", "repmixer", "repmixer", "repmixer")@register_model
def fastvit_t12(pretrained=False, **kwargs):
"""Instantiate FastViT-T12 model variant."""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 256, 512]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, True, True, True]
token_mixers = ("repmixer", "repmixer", "repmixer", "repmixer")@register_model
def fastvit_s12(pretrained=False, **kwargs):
"""Instantiate FastViT-S12 model variant."""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 256, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
token_mixers = ("repmixer", "repmixer", "repmixer", "repmixer")@register_model
def fastvit_sa12(pretrained=False, **kwargs):
"""Instantiate FastViT-SA12 model variant."""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 256, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))]
token_mixers = ("repmixer", "repmixer", "repmixer", "attention")@register_model
def fastvit_sa24(pretrained=False, **kwargs):
"""Instantiate FastViT-SA24 model variant."""
layers = [4, 4, 12, 4]
embed_dims = [64, 128, 256, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))]
token_mixers = ("repmixer", "repmixer", "repmixer", "attention")@register_model
def fastvit_sa36(pretrained=False, **kwargs):
"""Instantiate FastViT-SA36 model variant."""
layers = [6, 6, 18, 6]
embed_dims = [64, 128, 256, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))]
token_mixers = ("repmixer", "repmixer", "repmixer", "attention")@register_model
def fastvit_ma36(pretrained=False, **kwargs):
"""Instantiate FastViT-MA36 model variant."""
layers = [6, 6, 18, 6]
embed_dims = [76, 152, 304, 608]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))]
token_mixers = ("repmixer", "repmixer", "repmixer", "attention")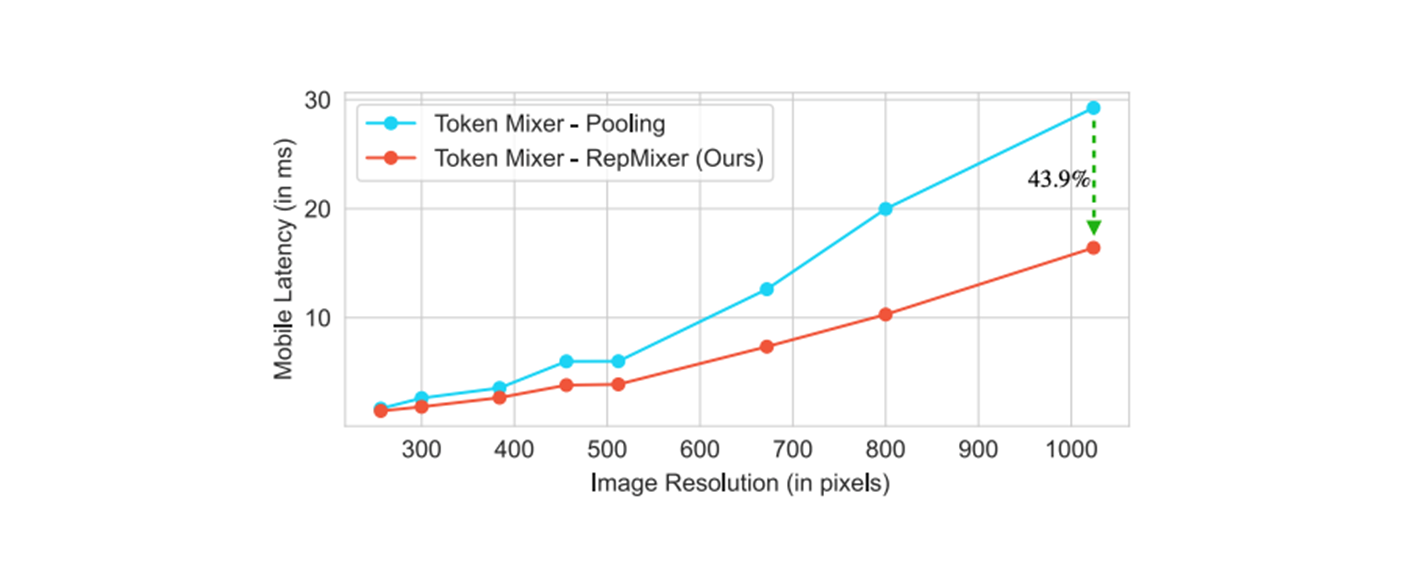
resolutions starting from to
At , using RepMixer will lower the latency by
At larger resolutions , latency is lowered significantly by
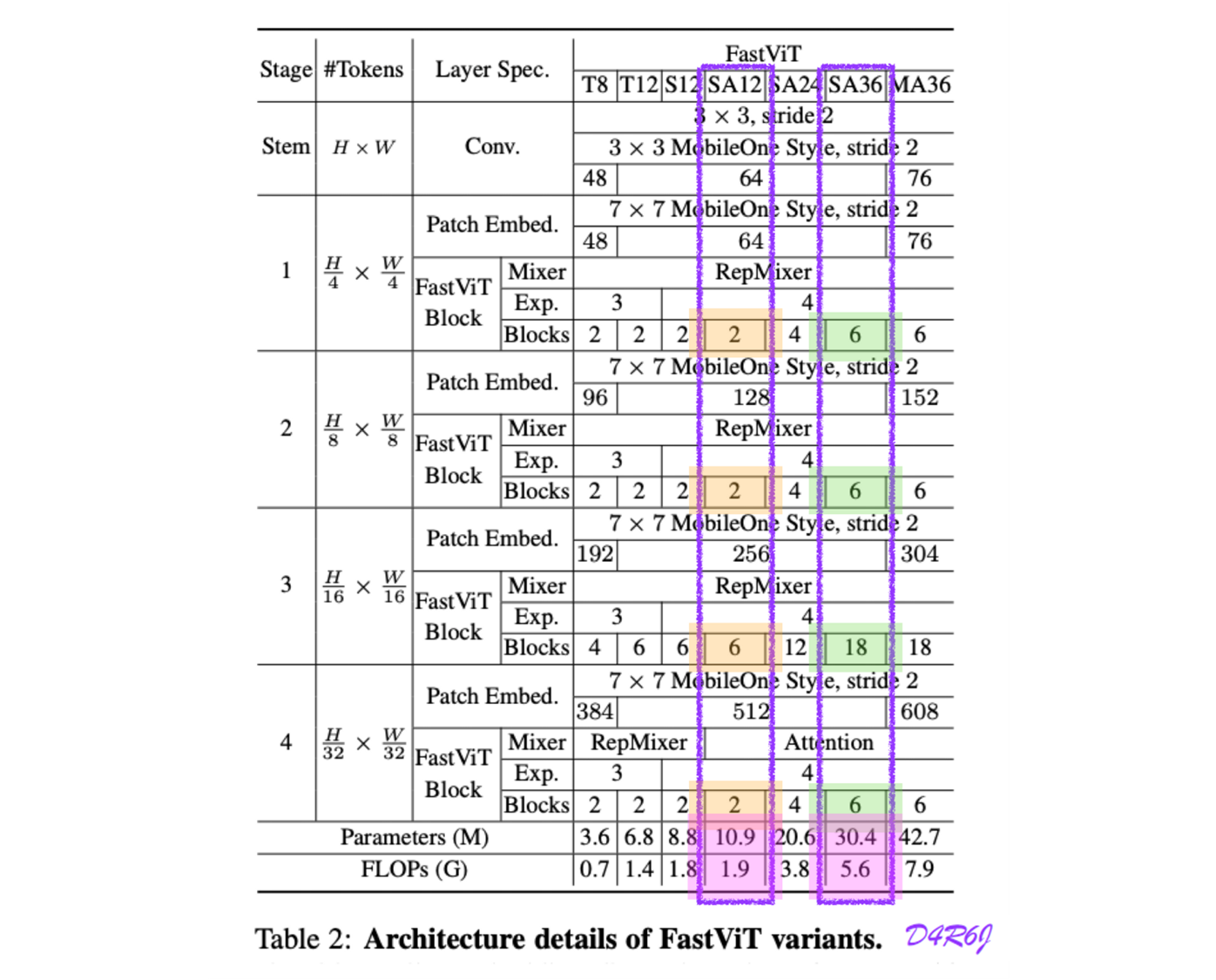
3.3 Linear Train-time Overparameterization

- (FLoating point OPerations) : 부동 소수점 연산 사칙연산을 포함하여 root, log, exponential 등의 연산도 해당되며, 각각을 1회 연산으로 계산.
- Ex > Dot product →
- FastViT-SA12 ( # of Parameters : 10.9M , FLOPs(G) 1.9 )
@register_model def fastvit_sa12(pretrained=False, **kwargs): """Instantiate FastViT-SA12 model variant.""" layers = [2, 2, 6, 2] embed_dims = [64, 128, 256, 512] mlp_ratios = [4, 4, 4, 4] downsamples = [True, True, True, True] pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))] token_mixers = ("repmixer", "repmixer", "repmixer", "attention")- Stage 1 ( 2 loop ), Stage 2 ( 2 loop ), Stage 3 ( 6 loop )
self.token_mixer = RepMixer( dim, kernel_size=kernel_size, use_layer_scale=use_layer_scale, layer_scale_init_value=layer_scale_init_value, inference_mode=inference_mode, ) assert mlp_ratio > 0, "MLP ratio should be greater than 0, found: {}".format( mlp_ratio ) mlp_hidden_dim = int(dim * mlp_ratio) self.convffn = ConvFFN( in_channels=dim, hidden_channels=mlp_hidden_dim, act_layer=act_layer, drop=drop, ) - Stage 4 ( 2 loop ) : RepCPE + Attention
pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))]self.norm = norm_layer(dim) self.token_mixer = MHSA(dim=dim) assert mlp_ratio > 0, "MLP ratio should be greater than 0, found: {}".format( mlp_ratio ) mlp_hidden_dim = int(dim * mlp_ratio) self.convffn = ConvFFN( in_channels=dim, hidden_channels=mlp_hidden_dim, act_layer=act_layer, drop=drop, ) # Drop path self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity() # Layer Scale self.use_layer_scale = use_layer_scale if use_layer_scale: self.layer_scale_1 = nn.Parameter( layer_scale_init_value * torch.ones((dim, 1, 1)), requires_grad=True ) self.layer_scale_2 = nn.Parameter( layer_scale_init_value * torch.ones((dim, 1, 1)), requires_grad=True )
- Stage 1 ( 2 loop ), Stage 2 ( 2 loop ), Stage 3 ( 6 loop )
- FastVit-SA36 ( # of Parameters : 30.4M, FLOPs(G) 5.6 )
@register_model def fastvit_sa36(pretrained=False, **kwargs): """Instantiate FastViT-SA36 model variant.""" layers = [6, 6, 18, 6] embed_dims = [64, 128, 256, 512] mlp_ratios = [4, 4, 4, 4] downsamples = [True, True, True, True] pos_embs = [None, None, None, partial(RepCPE, spatial_shape=(7, 7))] token_mixers = ("repmixer", "repmixer", "repmixer", "attention")
3.4 Large Kernel Convolutions
RepMixer 의 receptive field 는 self-attention token mixer 와 비교할 때 local 이다.
token_mixers = ("repmixer", "repmixer", "repmixer", "attention")self-attention 을 기본으로하는 token mixers 은 계산 비용이 굉장히 비싸다.
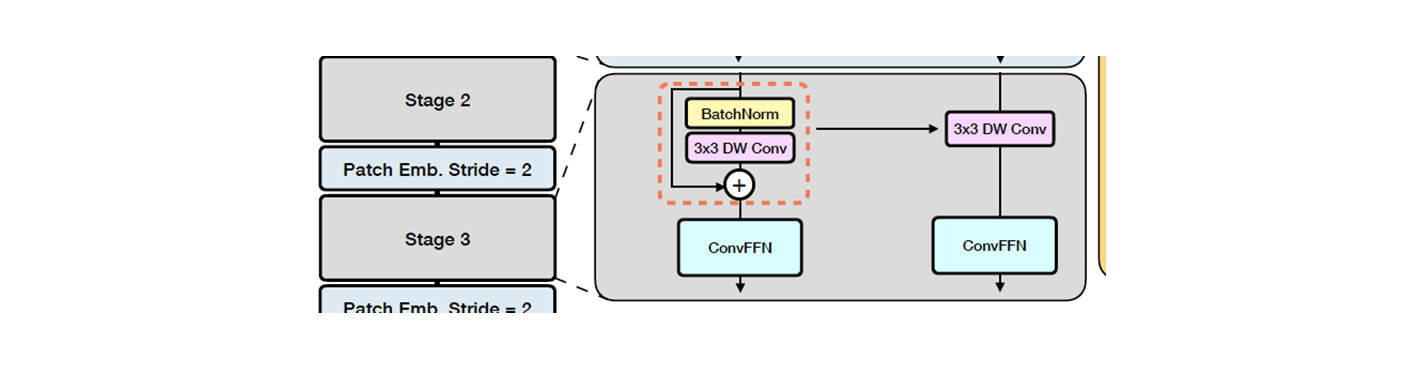
self-attention 을 사용하지 않은 early stage 의 receptive field 를 향상시키기 위해 depthwise large kernel conv 와 결합하는 것이 효율적인 접근법이다.
class RepMixerBlock(nn.Module):
...
self.token_mixer = RepMixer(
dim,
kernel_size=kernel_size,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
inference_mode=inference_mode,
)
assert mlp_ratio > 0, "MLP ratio should be greater than 0, found: {}".format(
mlp_ratio
)
mlp_hidden_dim = int(dim * mlp_ratio)
self.convffn = ConvFFN(
in_channels=dim,
hidden_channels=mlp_hidden_dim,
act_layer=act_layer,
drop=drop,
)
class RepMixer(nn.Module):
def __init__(...):
....
if inference_mode:
self.reparam_conv = nn.Conv2d(
...
)
else:
# BatchNorm2d 이거 왜 빼는지?
self.norm = MobileOneBlock(
...
use_scale_branch=False,
num_conv_branches=0,
)
# DWConv(BN(X)) + X
self.mixer = MobileOneBlock(
dim,
dim,
kernel_size,
padding=kernel_size // 2,
groups=dim,
use_act=False,
)
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale = nn.Parameter(
layer_scale_init_value * torch.ones((dim, 1, 1)), requires_grad=True
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
if hasattr(self, "reparam_conv"):
x = self.reparam_conv(x)
return x
else:
if self.use_layer_scale:
x = x + self.layer_scale * (self.mixer(x) - self.norm(x))
else:
x = x + self.mixer(x) - self.norm(x)
return xFFN 에 DW large kernel conv 를 채택한다.
class ConvFFN(nn.Module):
...
out_channels = out_channels or in_channels
hidden_channels = hidden_channels or in_channels
self.conv = nn.Sequential()
self.conv.add_module(
"conv",
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=7,
padding=3,
groups=in_channels,
bias=False,
),
)
self.conv.add_module("bn", nn.BatchNorm2d(num_features=out_channels))
self.fc1 = nn.Conv2d(in_channels, hidden_channels, kernel_size=1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_channels, out_channels, kernel_size=1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)and patch embedding layers.
# Patch merging/downsampling between stages.
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]:
network.append(
PatchEmbed(
patch_size=down_patch_size,
stride=down_stride,
in_channels=embed_dims[i],
embed_dim=embed_dims[i + 1],
inference_mode=inference_mode,
)
)-
FastVit : Full Model
4. Experiments
4.1 Image Classification
-
Training data
- ImageNet-1K Data set.
- 1.3M training images, 50K validation images.
-
Hyper parameter setting.
- 300 epochs using AdamW optimizer, weight decay 0.05
- peak learning rate for a total batch size of 1024.
- The number of warmup epochs is set to 5
- cosine schedule is used to decay the learning rate.
-
Fine-tune models for 30 epochs
- weight decay of
- learning rate of
- batch size of 512
latency 를 측정하기 위해, respective (각각의) 방법에 대응하는 input size 를 사용 한다.
iPhone latency 측정을 위해서 Core ML Tools (v6.0) 를 사용하는 모델을 export 하고, iPhone 12 Pro Max 에 있는 iOS 16 에서 run 하고 batch size 는 모든 모델에 대해서 1 로 set 한다.
- Notice
- HardSwish is not well supported by Core ML.
- “ * ” denotes we replace it with GELU for fair comparison.
- “ “ denotes that model has been modified from original implementation for efficient deployment.
- Models which could not be reliably exported either by TensorRT or Core ML tools are annotated by “ - ”
Comparison with SOTA Models
ImageNet-1k dataset 으로 최근의 SOTA model 과 비교 해보자. 공정한 비교를 위해서 비용이 많이 드는 reshape operation 들을 피하여 official 한 implementation 로부터 ConvNeXt 를 수정한다.
두 가지 다른 compute fabrics ( 데스크탑 gpu 와 mobile device ) 에서 최근 SOTA 를 비교할 때 Fast-ViT 이 best accuracy-latency trade-off 이 가장 좋다는 이야기…

Knowledge distillation
RegNet 16GF 를 가지고 DeiT 에서 설명된 셋팅으로 follow 한다. Fast-ViT 을 300 epoch 학습하며 true label 로써 teacher 의 hard decision 으로 나온 hard distillation 을 사용한다.
distillation 을 위해 추가된 classification head 는 알아서 하시길..
| Model | Image size | Param | FLOPs | GPU Latency | Mobile Latency | Top-1 Acc |
|---|---|---|---|---|---|---|
| FastViT-SA24 | 256 | 20.6 | 3.8 | 3.8 | 2.6 | 83.4 |
| EfficientFormer-L7 | 224 | 82.1 | 10.2 | 7.5 | 7.0 | 83.3 |
parameter less, FLOPs less, lower latency
4.2 Robustness Evaluation
ImageNet-A (IN-A)
a dataset that contains naturally occurring examples that are misclassified by ResNets

https://paperswithcode.com/dataset/imagenet-a
ImageNet-R (IN-R)
a dataset that contains natural renditions of ImageNet object classes with different textures and local image statistics

https://paperswithcode.com/dataset/imagenet-r
ImageNet-Sk (IN-Sk)
a dataset that contains black and white sketches of all ImageNet classes, obtained using google image queries.

https://paperswithcode.com/dataset/imagenet-sketch
ImageNet-C
a dataset that consists of algorithmically generated corruptions (blur, noise) applied to the ImageNet test-set. corruption error is reported (lower is better) and for other datasets Top-1 accuracy is reported (higher is better).

https://paperswithcode.com/dataset/imagenet-c
Results on robustness benchmark datsets.
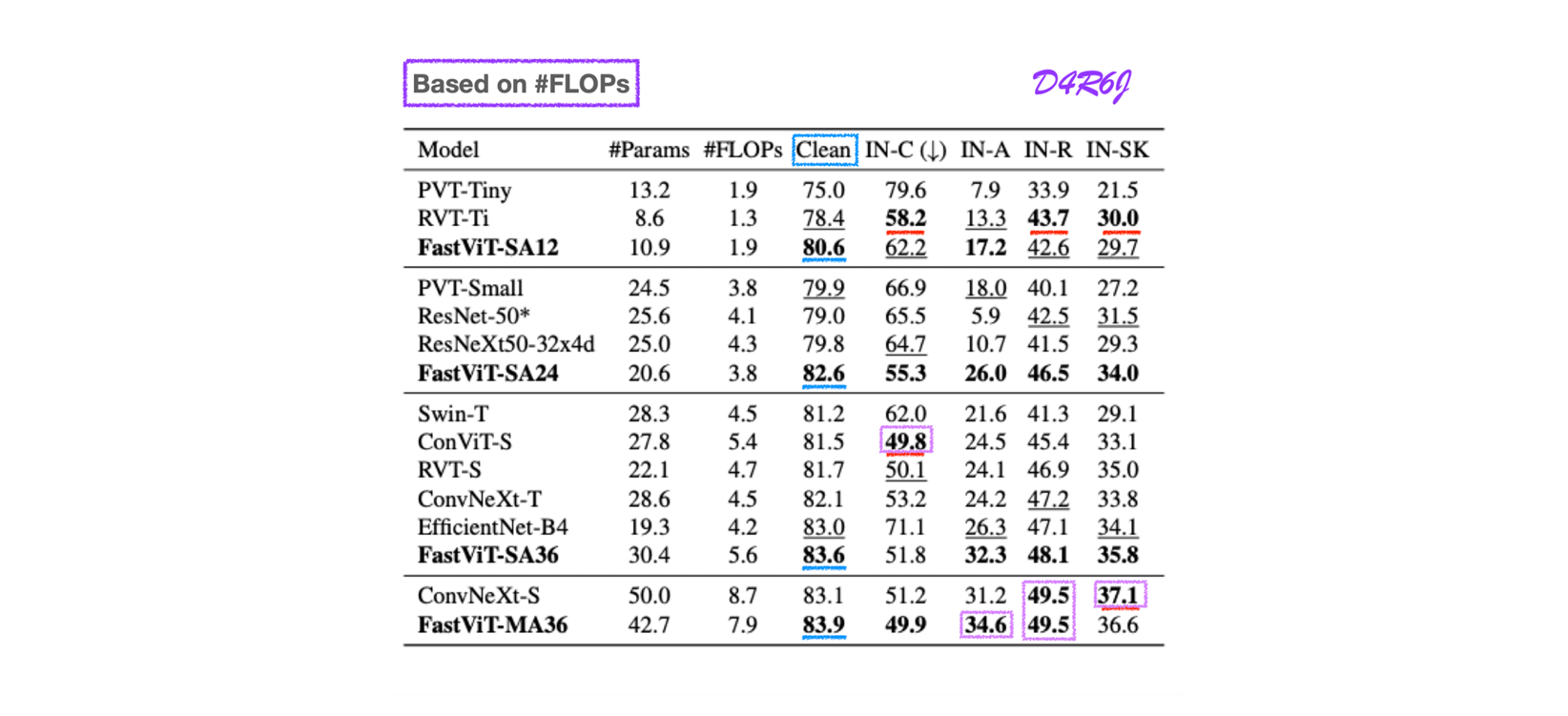
Section 3.2.3 에서 논의된 robustness 향상에 도움이 되는 self-attention layers 가 들어간 조합에서 patch embedding layer 들과 FFN 에서 large kernel convolution 들을 사용하는 Architecture 를 선택한다.
- FLOPs 가 낮을 때는 타 모델에 비해 좀 떨어지는 경향을 보인다.
- 역시 over-parameter 일 때가 성능 상은 좋은 듯 하다. FLOPs 비해 가성비 측면도 고려 대상이 될듯하다.
4.3 3D Hand mesh estimation
최근 실시간 3D hand mesh 추정에 CNN based 백본 으로 소개된다. 백본으로는 feature extraction 을 위하여 HRNets 을 사용하는 METRO 와 MeshGraphormer 를 제외한 ResNET 또는 MoibleNet 군을 사용한다.

https://lmb.informatik.uni-freiburg.de/projects/freihand/
공정하게 비교하기 위해서 훈련을 위한 데이터 셋는 FreiHand 데이터 셋만 사용하고, 그 결과를 pre-train, train 또는 더 추가된 pose datasets 의 fine-tune (미세 조정) 에 인용(cite) 한다.
ImageNet-1k 로 pre-training 을 하고, “End-to-end human pose and mesh reconstruction with transformers” 에서 설명된 실험을 설정하여 FreiHand 데이터 셋으로만 train 한다.
4.4 Semantic Segmentation and Object Detection
For semantic segmentation ( 영역 분할 )
Semantic segmenation
→ 이미지 내에서 객체가 속한 Class가 무엇인지에 대해서만 판단. ( 의미론적 분할 )

Instance segmentation ( 개별적 분할 )

→ Class 안의 Instance 들 간의 구분 가능.
Panoptic Segmentation
→ Sementic & Panoptic Segmentation 조합.
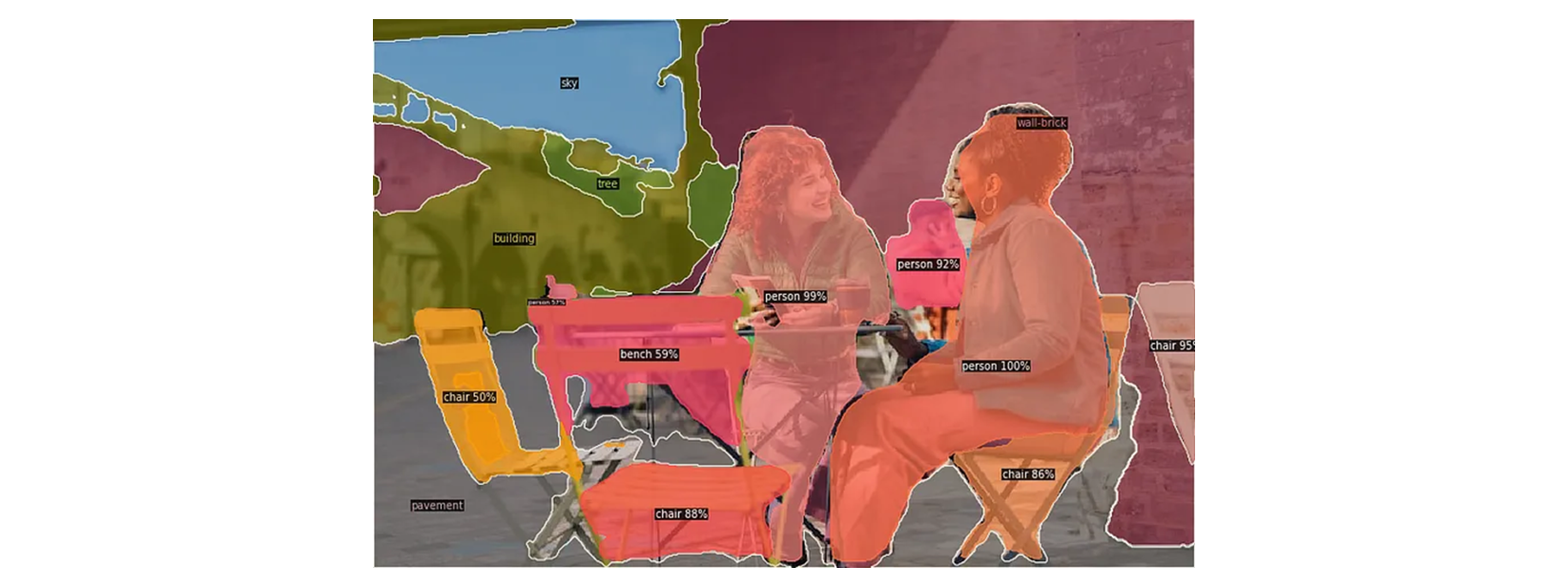
ADE20k dataset.
20K training images and 2K validation images with 150 semantic categories.
https://groups.csail.mit.edu/vision/datasets/ADE20K/

For object detection ( 개체 검출 )
MS-COCO dataset.
with 80 classes containing 118K training and 5K validation images

