Train your LLMs to reason and call a search engine with reinforcement learning
실제 DeepSeek 구조에서 4 가지만 집고 넘어가보자.
- MLA (Multi-Head Latent Attention)
- MoE (Mixture-of-Experts)
- Knowledge Distillation
4. GRPO (Group Relative Policy Optimization)
라고 했지만.. GRPO 까지만 Search-R1 으로 대신하고 paper review 는 휴식기를 갖을 예정이다.. deep research 도 나오고 이용해봐야지..
Abstract
-
대규모 언어 모델 (LLM) 에서 효과적인 추론 (resoning) 과 텍스트 생성을 위해서 외부 지식과 최신 (up-to-date) 정보를 효율적으로 얻는 것이 필수적이다.
-
inference 도중 search engine 을 사용하기 위해 추론 능력을 같춘 advanced LLM 에 prompting 하는 것은 최적이 아니다. LLM 이 search engine 과 최적으로 상호 작용하는 방법을 학습하지 않기 때문이다.
-
LLM 이 강화 학습을 통해서만 학습하여 실시간 검색 (real-time retrieval) 을 통한 step-by-step 추론 중에 자동으로 (multiple) 검색 쿼리를 생성하는 DeepSeek R1 모델의 확장인 SEARCH-R1 을 소개한다.
-
SEARCH-R1 은 검색 상호작용 (multi-turn search) 를 포함한 LLM rollout 을 최적화 하며, 검색된 token masking 을 활용하여(leveraging) RL 훈련의 안정성과 간단한 output based 의 reward function 로 학습을 수행한다.
이 말을 좀 풀어서 보자면,
LLM 이 inference 를 진행하는 rollout 을 RL 로 최적화한다. 이 때 검색 결과를 token masking 한다는 건데, reward 는 간단하게면 설계한다는 의미 같다. rollout 의 의미로 보면, RL 에서는 승패가 결정될 때까지 무작위로 게임을 진행시켜 끝까지 한다는 의미로 이해하고 있다. 즉, trajectory 전부를 이야기한다.
- Query 생성 : LLM 이 스스로 웹 검색용 쿼리를 생성
- Search 실행 : 실제 search engine을 통해 최신성 유지된 관련 정보 Search
- 검색 결과 로드 : “gemma 3 was released on March 12, 2025”
- LLM 추론 : 검색 결과로 reasoning
- 필요한 경우 재 검색 : 다시 query 생성 후 반복.
- 최종 답안 출력 : “gemma 3 은 2025년 3월에 출시 되었다.”
- 결과 평가 ( reward 계산) : 정답 정확도 기준으로 RL reward.
여기서 retrieved token masking (검색된 토큰 마스킹) 은 문장에서 xxx xxx [MASKED : gemma 3 was released on March 12, 2025] xxx xxx” 로 가능하게 된다. 그리고 저 Masked 를 나오게 학습하는 방식이 아주 심플한 reward 로 구성되어있겠지. 복잡한 loss function 은 이제.. 안녕인건가..
생각해보면 사람들도 뉴스, 웹 자료에서 정보를 추출하게 되는데, 그걸 돌리면 최신성 유지가 된다. 이 자체가 LLM 이 되기 때문에 문제되지 않는다.
Introduction
search-and-reasoning (검색 및 추론) 시나리오에서 RL 을 적용하면 세 가지 주요 challenge 가 발생한다.
-
RL Framework and Stability
검색된 context 를 통합할 때 안정적인 최적화를 보장하면서 search engine 을 LLM RL framework 에 효과적으로 통합하는 방법은 불분명하다.
-
Multi-Turn Interleaved Reasoning and Search
이상적으로 LLM 은 반복적인 추론과 검색엔진 호출이 가능해야 하고, 문제의 복잡성을 기준으로 retrieval 전략을 동적으로 조정할수 있어야 한다.
-
Reward Design
전통적인 reward form ulation 이 새로운 패러다임에 잘 일반화 되지 않을 수 있기 때문에 search-and-reasoning 작업을 위한 효과적인 reward function 을 설계하는것이 중요하다.
( 그런데 이 새로운 작업에 대한 데이터를 loss function 으로 설계하는 것보다는 훨씬 안정적이고 쉽게 학습하는 것이 가능하다. )
이러한 challenge 들을 해결하기 위해서, LLM 이 자가 추론을 통해 search engine 과 상호작용을 교차적으로 (interleaved manner) 수행할 수 있는 RL framework 를 소개한다.
특히 SEARCH-R1 은
- search engine 을 environment 의 부분으로 모델링하여, LLM 이 token 생성을 하면서 동시에 search engine 검색도 번갈아 수행하는 rollout sequence 를 가능하게 한다. SEARCH-R1 은 PPO, GRPO 를 포함한 다양한 강화학습 (RL) 알고리즘과 호환 가능하고, 안정적인 최적화를 보장하기 위해서 검색을 통해 얻은 token masking 기법을 적용한다.
- rollout sequence
→ 강화 학습에서 agent 가 environment 와 상호작용 하면서 생성하는 처음부터 끝까지의 state, action, reward 흐름 전체를 말한다.
-
SEARCH-R1 은 multi-turn 검색과 reasoning (추론) 을 지원하며 검색 호출은
<search>와</search>토큰에 의해서 명시적으로 수행 ( triggered explicitly ) 된다. 검색을 통해서 얻은 content 는<information>과</information>토큰 안에 포함되고, LLM (reasoning) 추론 단계에서는<think>와</think>토큰 내에 포함된다. 최종 답변은 구조적이고 반복적인 의사 결정 (decision-making) 을 가능하게 하는<answer>와</answer>토큰을 사용하여 형식화한다. -
프로세스 기반 보상의 복잡성을 피하고 간단한 결과 기반 (outcome-based) reward function 을 제공한다. 이런 최소 보상 설계 (minimal reward design) 가 search-and-reasoning 시나리오에서 효과적이라는 것을 보여준다. SEARCH-R1 은 향상된 검색 중심의 의사 결정을 위한 검색-증강 (search-augmented) RL 훈련을 도입하여 주로 parametric reasoning 에 초점을 맞춘 DeepSeek-R1 의 확장으로 볼 수 있다.
parametric reasoning
→ LLM 이 자신의 내부 parameter (학습된 지식) 를 바탕으로 추론하는 방식이다. 즉, prompt 와 RAG 에 의존되는 instruction 없이 질문 본질을 자신의 parameter 에서 찾겠다는 의미로 해석.
- 검색 엔진 호출을 통해서 LLM reasoning 에 RL 을 적용하는 데에 따른 어려움을 식별한다.
- SEARCH-R1 의 새로운 강화 학습 framework 은
-
검색 엔진과 함께하는 LLM 의 rollout 및 강화 학습의 최적화.
-
안정된 RL 훈련을 위한 검색된 token masking
-
복잡한 작업의 해결을 위한 multi-turn 의 교차 추론 및 검색
-
간단하지만 효과적인 결과 보상 함수 (outcome reward function)
을 지원한다.
-
- SEARCH-R1 의 유효성을 입증하기 위해서 체계적인 실험을 수행했고, 강력한 기준의 3개의 LLM 모델들에 비해 평균 상대적인 성능 향상이 26%, 21%, 10% 되는 것을 보여준다. 또한 추론 과 검색 설정에서 RL 에 대한 insight 도 함께 제공한다. 여기에는 RL 모델 선택과 다양한 LLM 비교, 응답 길이 분석이 포함된다.
Search-R1
- 검색 엔진을 통한 강화학습.
- 검색 엔진 호출이 교차적으로 포함 (interleave) 된 multi-turn 통한 text 를 생성.
- training template.
- reward model 설계.
를 cover 하는 SEARCH-R1 의 세부 설계를 제시한다.
Reinforcement Learning with a Search Engine
검색 엔진 를 사용하여 강화 학습 framework 을 아래와 같이 공식화한다.
- 는 policy LLM.
- 는 reference LLM .
- 는 reward function
- 은 KL-divergence.
rollout sequence 를 생성하기 위해서 policy LLM 에 주로 의존하는 사전 LLM 강화학습 방법과 다르게, SEARCH-R1 은 을 통해서 교차 검색된 추론을 명시적으로 통합한다.
이것은 로 볼 수 있으며, 는 교차된 검색 추론 (retrieval-and-reasoning) 을 나타낸다. 이를 통해서 외부 정보 검색이 요구되는 추론 집약적 작업에서는 보다 효과적인 의사 결정이 가능해진다. rollout process 에 대한 자세한 설명은 밑의 섹션에서 설명한다.
- 는 질문이나, 입력의 prompt
- 는 LLM 이 생성한 응답 ( 교차된 search engine 등의 결과 포함 )
- 는 기준이 되는 모델 ( paper 에서는 Llama 등이겠지만 이게 GPT, Claude, Gemini 등 이겠지..)
- 는 respone 품질을 측정하는 보상 함수
- 는 현재 policy 가 reference LLM 의 기준에서 얼마나 벗어났는지 측정
좋은 응답을 생성하면서, reference policy 의 기준이 되는 LLM 과 너무 멀어지지 않도록 penalty 로 제한하여 학습하는 구조를 의미한다. 즉, (search engine dist) 를 포함한 policy 의 output dist 인 과 reference 분포 차이를 divergence 로 측정해서 regularization 한다.
Rollout 구조를 위의 내용을 직접 가져와서 flow 를 따져보자.
-
Query 생성 : LLM 이 스스로 웹 검색용 쿼리를 생성
- 사용자 입력 질문 “가장 stable 한 LLM의 가장 최신 릴리즈된 모델은 뭐야?”
-
Search 실행 : 실제 search engine을 통해 최신성 유지된 관련 정보 Search
- LLM 추론 시작
<think>가장 stable 하면서 최신 LLM 이란…</think> - Search Engine
<search>최신 LLM 중 가장 stable 한 모델 searching…</search>
- LLM 추론 시작
-
검색 결과 로드 : “gemma 3 was released on March 12, 2025”
<information>gemma 3 was released on March 12, 2025</information>결과 주입
-
LLM 추론 : 검색 결과로 reasoning
<think>gemma 3 인데..</think>
-
필요한 경우 재 검색 : 다시 query 생성 후 반복.
- 필요할 경우 추가하여
<search>다시 시작. - 이 조건에 대해서는 KL divergence 혹은 reward 혹은 다른 LLM 이용 등으로 필요 가능성 체크.
- 필요할 경우 추가하여
-
최종 답안 출력 : “gemma 3 은 2025년 3월에 출시 되었다.”
<answer>gemma 3 은 2025년 3월에 출시 되었다.</answer>
-
결과 평가 ( reward 계산) : 정답 정확도 기준으로 RL reward.
- reward model 로 응답의 질을 평가 (사실성, 신뢰도 ..)
- KL-divergence 로 기존 모델 와 차이를 제어하며 학습.
-
policy update
- PPO, GRPO 등 + KL Penalty
KL divergence
- Discrete dist 일 때.
- Continuous dist 일 때.
이 수식은 KL-regularized RL object 에서 확장된 구조.
현재 학습 중 policy 인 이 기존 policy 인 와 얼마나 다른 확률 분포를 갖는지 측정.
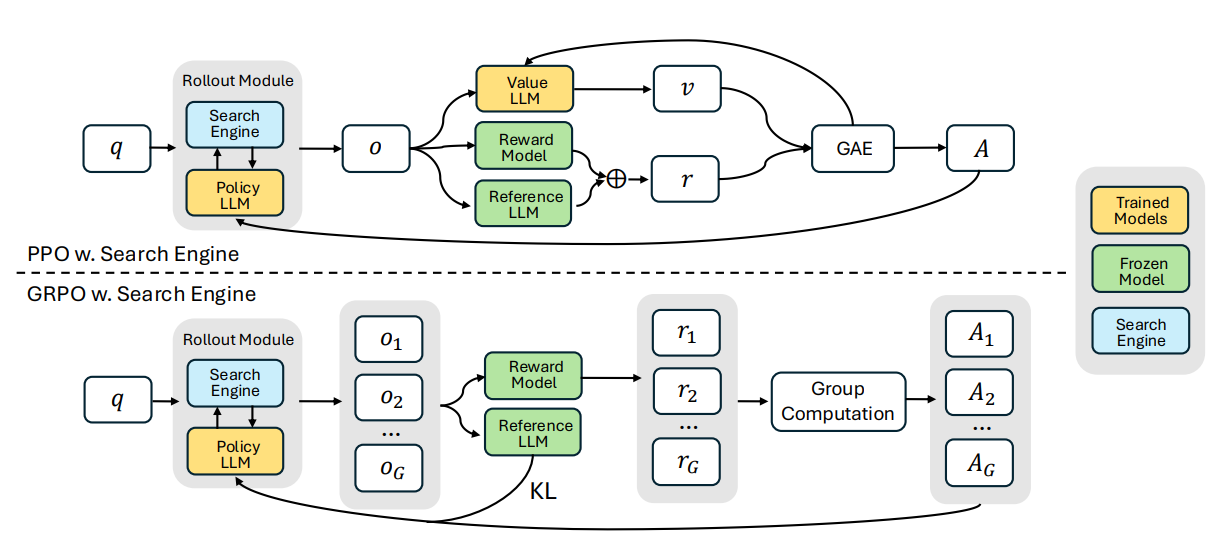
접근 방식은 PPO (Proximal Policy Optimization) 와 GRPO (Group Relative Policy Optimization) 이라는 두 가지 잘 정립된 policy gradient RL 방법을 기반으로 하며, 그들 각각의 장점을 활용하여 retrieval-augment 추론을 최적화한다.
Loss Masking for Retrieved Tokens
-
PPO 와 GRPO 모두에서 token 수준의 loss 는 전체 rollout sequence 에 대해 계산된다. SEARCH-R1 에서 rollout sequence 는 LLM 생성 토큰과 외부 통로 (검색 엔진) 에서 검색된 토큰으로 구성된다.
-
LLM 생성 토큰을 최적화 하면 검색 엔진과 상호작용을 하고 추론을 수행하는 능력을 향상 시키지만, 검색된 토근에 동일한 최적화를 적용하면 의도하지 않는 학습 현상 (unintended learning) 이 발생할 수 있다.
-
이러한 문제를 해결하기 위해서, 검색된 token 에 대한 loss masking 을 도입하여 policy gradient objective 가 LLM-generated 토큰에 대해서만 계산되도록 보장하고 검색된 content 는 최적화 프로세스에서 제외한다. 이러한 접근 방식은 search-augmented 생성의 유연성을 유지하면서 훈련을 안정화 한다.
-
여기서 의도하는 바는 실제 검색에 추출된 데이터는 내가 원하지 않은 신뢰성이 떨어지는 데이터일 가능성이 있다. 실제로 search engine 뿐만 아니라 최신 document 또한 학습하기 쉬운 구조가 아니다.
-
따라서 구조적인 patten 을 만들고, 인식하기 좋게 전처리 과정이 일단은 필요하다. 추후에는 학습하기 쉬운 형태의 문서로 일반화 될 가능성이 크다.
-
이것을 컨트롤 하기 위해, LLM 이 직접 직접 만든 토큰만 학습 대상이 되어야 하므로, 이때 사용하는 방법 중 하나가 “retrieved token masking” 이다. 여기서 loss masking 은 실제, retrieved token 의 probability 기반의 loss 를 계산하지 않는 것으로, detach 를 한다던가, 진짜 masking 을 해서 loss 계산에 넣지 않을 듯 하다.
물론, “groundedness check llm” 도 들어갈 것이고, meta 의 Llama 시의 filtering 도 들어갈 것 이라 생각된다.
예시로 보자면
loss = loss * mask # mask 가 0 이면 loss 에 미반영.
loss = loss.sum()
loss.backward()retrieved_logits = model(x).detach() # gradient 연산에서 제외.
fullcontext_logits = torch.cat([generated_logits, retrieved_logits], dim=1)
loss = cross_entropy(fullcontext_logits, labels)
loss.backward().detach()는 해당 tensor 가 autograd graph 에서 분리되어 loss 가 gradient 에 적용되지 않는다.- 다만 코드를 보면 모델 전체 출력의 일부만 retrieved token 이 되므로, 이때는 위와 같은 torch 자체의 concat 보다는 masking 이 더 유연하게 적용 가능하다.
0으로 눌러버리는게 훨씬 깔끔.
PPO with Retrieval deatch.
PPO 의 policy update
- : advantage : reward 기반으로 계산.
- : policy 의 training parameter.
<think> 모델이 생성한 토큰 A B </think>
<information> 검색 결과 토큰 C D </information>에서의 probability 계산.
→ 여기서 는 search engine 이므로 mask 또는 deatch 해야한다.
그러면 실제 미분 시에는
가 되며, search engine 에서 나온 token 부분은 gradient 이 무시되게 된다.
PPO + Search Engine
PPO (Proximal Policy Optimization) 은 RL stage 에서의 동안 LLM ( 대형 언어 모델) 을 미세조정 하는데 일반적으로 사용되는 인기 있는 actor-critic 강화 학습 알고리즘이다. reasoning + search engine 호출 시나리오에서는 아래와 같은 objective 를 최대화 하여 LLM 을 최적화 시킨다.
- 변수 : dataset 에서 가져온 input sample.
- 변수 : reference policy 로부터 sample 되고 search engine 에서 검색된 검색 엔진 호출 결과와 interleaved (교차 검색) 된 모델의 생성 출력을 나타낸다.
- : 입력된 와 이전 정책으로 rollout 된 응답 에 대한 기댓값.
- : token 이전 까지의 sequence.
- : 현재의 policy model 과 참조 policy model.
- : 현재 policy 가 token 를 생성할 확률.
- : 이전 policy 가 token 를 생성할 확률.
- 는 token loss masking 작업이다. 가 이면 는 LLM 생성 토큰이고, 이면 검색 토큰이 된다. indicator function 이라는 것인가?..
- 는 masked token 을 제외하고 regulaization ( token 수의 평균 )
- 는 token 위치에서의 advantage (reward based)
- term 은 training 안정화를 위한 PPO 에 도입된 clipping 관련 하이퍼 파라미터.
advantage estimate 는 미래의 보상 (future reward) 및 학습된 value function 를 기반으로 Generalized Advantage Estimation (GAE) 를 사용하고 계산한다.
GRPO + Search Engine ( 1 )
policy optimization 은 안정성을 향상시키고, 추가적인 value function approximation 의 필요성을 피하기 위해서 GRPO (Group Relative Policy Optimization) 가 도입되었다. GRPO 는 학습된 value function 에 의존하는 대신 여러 sampled 출력의 평균 보상 기준으로 활용한다는 점에서 PPO (Proximal Policy Optimization) 과는 다르다.
구체적으로 각 입력 질문 에 대해서 GRPO 는 참조 policy 로부터 응답 그룹 를 샘플링한다. 그 다음, policy model 은 아래의 following objective function 을 최대화 하는 방식으로 최적화된다.
- 과 는 hyperparameter 이다.
- 는 각 group 내에 생성된 output 들의 상대적인 reward 를 기반으로 계산된 advantage (행렬) 항으로 나타난다.
- 이러한 접근법은 의 계산에 추가적으로 복잡성이 발생하는 것을 피한다.
- 는 token loss masking 연산이다. 만약 이면 는 LLM 생성 토큰이고, 이면 검색 토큰이 된다.
RL concept.
- 일반 RL 에서 Advantage 를 계산하려면 value function 와 reward baseline 이 필요.PPO 를 돌려보면 알지만, actor 와 critic 의 두 모델이 설정되고,
- actor : 현재 정책 : 무엇을 생성할지 결정하는 역할
- critic : 상태/입력 에 대한 value 를 추정 : baseline 의 역할
- advantage : or GAE 등을 사용.
- GRPO 는 그룹 내의 생성된 output 들의 상대적인 reward 를 기반으로 advantage 를 만듬.
- 이렇게 계산하면 가 없이 각 응답에 대한 normalized 또는 ranked advantage 계산 가능.
- critic 모델 없이도 advantage 유도가 가능.
trade-off
-
PPO 는 두 개의 model 을 활용하여 actor 는 행동을 선택하고, critic 은 value estimation 을 통해서 reward 함수에 관여하여 상대적 advantage 를 평가.
-
GRPO 는 하나의 모델에 내가 원하는 질문에 대한 답을 sampling 을 하여 rewrad 가 높은 단일 모델에서의 어떤 한 부분의 공간을 이해하고자 하는 모델 학습법.
GRPO + Search Engine ( 2 )
추가적으로 KL divergence 를 reward function 내에 penalty 로 포함 시키는 대신에, GRPO 는 trained 중인 policy 와 reference policy 간의 KL divergence 를 loss function 에 직접 추가하는 방식으로 regularization 을 수행한다. KL divergence loss 를 계산할 때 또한 retrieved token masking 이 적용된다.
- 이렇게 되면, 기존 PPO 에서는 당연히 KL term 이 reward 내부에 있어서 컨트롤 하기 어렵지만,
- GRPO 에서는 KL term 이 밖에 있어서 loss 설계가 쉬워지고, regularization 효과 제어가 좋다.
- retrieved token masking 으로, 기존 검색된 token 은 gradient 계산에서 제외, 학습 오염을 방지.
분포 관점에서 본다면, 실제 LLM 으로 critic 모델을 돌려서 reward 에 관여하는 baseline model 을 가져오는 것이 아닌, VAE 처럼 sampling 해서 여러 데이터를 가져와서 LLM 의 한 dist 를 가지고 latent dist 로 유사하게 만든다고 볼 수 있다. 따라서 그렇게 설계된 reward function 으로 추가적인 분포를 “aha moment” 와 같은 방법으로 모델 학습에 기여하게 된다. 특히 놀라운 점은 질문에 대한 다양성이라도 그 분포 안에 neighborhood 이므로, 몇 번의 sampling 만으로도 유사한 분포를 만들 수 있다.
여기까지 생각해보면,
- LLM 의 잘 만들어진 거대한 분포가 있다. 이것을 policy LLM 으로 사용한다.
- search engine 으로 새로운 지식을 검색한다.
- 새로운 데이터는 masking 으로 막고, 모델의 오염을 방지한다.
- PPO 의 기존 방식은 actor-critic 의 관계로 두 모델을 사용한다면,
- GRPO 는 샘플링 방식으로 잘 만들어진 거대 분포의 일부분을 가져온다.
- 샘플링 된 reward function 들로 group regularization 으로 만든다.
- 이렇게 만들어진 advantage matrix 를 policy LLM 에 적용시킨다.
새로운 학습의 데이터는 masking 되어서 오염이 방지 되는데, 마지막 문제는 최신성이 유지 되는가?
Text Generation with Interleaved Multi-turn Search Engine Call
interleaved 된 multi-turn 검색 엔진 호출을 사용하여 LLM 응답 생성을 위한 rollout process 를 설명.
-
LLM 이 text 생성과 외부 검색 엔진 query 를 번갈아 사용하는 framework 을 따른다. 구체적으로 system instruction 은 외부 검색이 필요할 때마다 LLM 이 두 검색 호출 토큰인
<search>와</search>사이에 검색 쿼리를 캡슐화 하도록 가이드 한다. -
LLM 이 생성된 sequence 에서 이러한 token 을 감지하면 검색 쿼리를 추출하고, 검색 엔진에 질의하고, 관련 결과를 검색 후 가져온다. 검색된 정보는 특수 검색 토큰인
<information>과</information>내에 포함되고 진행 중인 현재 rollout sequence 에 추가되어 다음 생성 단계를 위한 추가적인 context 역할을 한다.
이러한 프로세스는 다음 조건 중 하나가 충족될 때까지 반복적으로 계속된다.
- 검색 엔진 호출 budget 이 소진 될 때 까지.
- 모델이 최종 응답을 생성할 때 까지.
이 응답은 지정된 응답 토큰 <answer> 와 </answer> 사이에 감싸져 있다.
완벽한 workflow 는 아래와 같다.
Algorithm 1
LLM Response Rollout with Multi-Turn Search Engine Calls.
Require : Input query , policy model , search engine , maximum search budget .
Ensure : Final response .
- Initialize rollout sequence
- Initialize search call count
- while do
- Generate response token
- // Append to rollout sequence
- if
<search></search>detected in then - // Extract search query
- ( ,
<search>,</search>) - // Insert into
- +
<information></information> - Increment search call count
- end if
- if
<answer></answer>detected in then - // Terminate rollout
- return final generated response
- end if
- end while
- return final generated response
Training Template
SEARCH-R1 을 train 하기 위해서는 초기 LLM 이 사전 정의된 intruction 을 따르도록 지시하는 간단한 template 을 만드는 것부터 시작한다.
Answer the given question. You must conduct reasoning inside <think> and </think> first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a search engine by <search> query </search>, and it will return the top searched results between <information> and </information>. You can search as many times as you want. If you find no further external knowledge needed, you can directly provide the answer inside <answer> and </answer> without detailed illustrations. For example, <answer> Beijing </answer>. Question: question.
Table 1 : Template for SEARCH-R1.
training 과 추론 중 question 이 특정 질문으로 대체된다.
위 template (prompt engineering) 를 분해해보면 다음과 같다.
- 주어진 질문에 답해줘.
- 새로운 정보를 얻을 때마다 먼저
<think>와</think>내부에서 reasoning 을 수행해. - reasoning 후에 지식이 부족하다고 판단되면
<search>query</search>로 search engine 을 호출하면<information>과</information>사이에서 top search 된 결과가 반환 될 것. - 너가 원하는 여러 번 검색할 수 있어.
- 더 이상 외부 지식이 필요하지 않는 경우 detail 한 설명 없이
<answer>와</answer>사이에 최종 답변을 바로 제공하면 된다. 예를 들어서<answer>Bejing</answer>.
이러한 template 은 모델의 출력을 반복적인 방식으로,
- reasoning process ( 추론 과정 )
- search enging calling function ( 검색 엔진 호출 기능 )
- answer ( 최종 답변 )
이렇게 세 부분으로 구성된다.
의도적인 제약을 structural format (구조적인 형식) 으로 제한하고, 내용에 대한 구체적인 편향 (content-specific biases) 은 피한다.
- 반성적인 추론 (reflective reasoning) 을 강제로 요구하거나,
- 검색 엔진 호출을 무조건 수행하게 하거나,
- 특정 문제 해결 방식을 고정하는 것과 같은 것
이러한 접근은 강화 학습 process 에서 모델이 보여주는 natural learning dynamics (자연스러운 학습) 이 편향되지 않고 관찰될 수 있도록 보장한다.
Reward Modeling
reward function 은 강화 학습의 최적화 프로세스를 가이드 하는 primary training signal 역할을 한다. SEARCH-R1 을 교육하기 위해서 모델 응답의 정확성을 평가하는 final outcome rewards 만으로 구성된 rule-based reward 시스템을 채택한다. 예를 들어, 사실적인 추론 작업 (factual reasoning tasks) 에서는 정확한 문자열 매칭과 같은 rule-based 기준을 사용하여 정확성을 평가할 수 있다.
여기서 는 응답 에서 추출된 최종 답변이고, 는 ground truth 의 답이다. DeepSeek r1 과 달리 학습된 모델이 이미 강력한 구조적 형식 (structural adherence) 을 따르고 있기 때문에 format rewards 를 따로 포함하지 않았다. 더 복잡한 format rewards 는 future work 으로 남긴다.
더욱이, outcome 이나 process 에 대한 평가를 위해서 neural reward models 를 학습하는 것은 의도적으로 피했고, 이것은 DeepSeek r1 의 접근을 따른 것이다.
- 대규모 강화학습 환경에서는 neural reward model 에서 reward hacking 에 취약하고
- 이러한 모델들을 다시 학습하는 데 드는 계산 비용과 복잡성이 크기 때문.
이러한 결정을 하게 된 이유이다.
그렇다면, reward modeling 의 설계는 최신 데이터에 대한 학습된 참/거짓 이 아닌 (이걸 하려면 위의 복잡한 reward 모델링등 필요) 질문에 대한 답으로 논리적으로 맞냐, 맞지 않느냐, 정도로 engine search 와 LLM 의 interleaved manner 로 추론하고, 샘플링하여 reward 에 녹이는 거네.
명확한 데이터가 실제가 맞냐 아니냐는 다른 문제네. 최신 정보가 잘못된 정보여도 논리적으로 포장되면 reward 가 올라가게 되니, 실제 온전한 데이터를 검색하게 하는게 키포인트네. 그렇다 해도 retrieved token 은 masking 을 처리해서 학습 과정에서 제외 시키니까, 완전한 데이터를 가져가려면 초기 DPO 셋을 만들던가 해서 SFT 로 어느 정도 학습한 다음에 강화학습 시키는것도 방법이긴 하겠다.
