
Sora : Video generation models as world simulators
Link
내용에서 중요하게 볼 것은, 어떤 models 과 어떤 approach 로 이런 result 가 나왔느냐? 를 중점적으로 볼 것이다.
Abstract
- video data 에 대한 generative models 의 large-scale training 을 explore 한다.
- 다양한 지속시간 (variable durations), 해상도 (resolutions) 와 화면비 (aspect ration) 의 video 와 image 에 대한 text-conditional diffusion models 을 같이 학습 시킨다.
- 비디오와 이미지의 latent code 의 시공간 (spacetime) 부분 (patch) 에서 operate 하는 transformer architecture 를 활용한다.
- 가장 큰 model Sora 는 1분짜리 고화질 (high fidelity) 비디오를 생성 할 수 있다.
- video generation models 을 scaling 하는 것이 물리적인 세계 (physical world) 의 다목적의 "누구나 사용할 수 있는" simulator 를 구축하는데 알맞는 길임을 제안한다.
첨언을 하자면.. 실제 세상 (real world) 가 아니라 물리적인 세상 (physical world) 로 적은 것이 소름이다.. top-tier 놈들 대체 무슨 시각과 생각으로 세상을 보고 있는거냐?
이 technical report 는
- 모든 유형의 visual data 를 generative models 의 large-scale training 이 가능하게 하는 unified representation 으로 변환하는 방법.
- Sora 의 역량과 그 한계의 qualitative evaluation.
에 focuses 한다. 모델과 구현의 세부 내용은 이 리포트에 포함하지 않는다.
이제 대 AI 시대가 열리고, 각 Big-Tech 마다 모델과 훈련, 코드들이 경쟁이 됨으로써 충분히 공감한다.
Related works
사전 연구로는
-
recurrent networks
- Unsupervised learning of video representations using lstms. (2015)
- Recurrent environment simulators. (2017)
- World models. (2018)
-
generative adversarial networks
- Generating videos with scene dynamics. (2016)
- Mocogan: Decomposing motion and content for video generation. (2018)
- Adversarial video generation on complex datasets. (2019)
- Generating long videos of dynamic scenes. (2022)
-
autoregressive transformers
- Videogpt: Video generation using vq-vae and transformers. (2021)
- Nüwa: Visual synthesis pre-training for neural visual world creation. (2022)
-
diffusion models
- Imagen video: High definition video generation with diffusion models. (2022)
- Align your latents: High-resolution video synthesis with latent diffusion models. (2023)
- Photorealistic video generation with diffusion models. (2023)
을 포함한 다양한 방법을 사용하여 video data 의 generative model 을 연구하였다. 이런 작업들은 visual data 의 좁은 category, 짧은 video, 또는 고정된 크기의 video 에 focus 를 둔다.
Sora 는 visual data 의 일반화 모델이다. 그것은 다양한 지속시간 (diverse durations), 화면비 (aspect ration) 및 해상도 (resolutions) 에 걸친 video 와 image, 최대 1분짜리 고품질의 비디오 까지 생성할 수 있다.
Turning visual data into patches
-
internet-scale data 를 학습하여 일반적인 능력을 습득하는 대규모 언어 모델
- Attention is all you need. (2017) : Transformer
- Language models are few-shot learners. (2020) : GPT3
에서 영감을 얻는다. LLM paradigm 의 성공은 text 의 다양한 modalities - 코드, 수학 과 다양한 자연어를 우아하게 (elegantly) 하나로 합치는 토큰의 사용에 의해 가능해졌다. visual data 의 generative model 이 어떻게 이와 같은 이점들을 상속 받을 수 있는지 고려한다. LLMs 는 text tokens 가 있는 반면 Sora 는 visual patches 가 있다.
-
이러한
patches는 이전 연구에서 visual data 의 모델에 효과적인 표현으로 보여졌다.- An image is worth 16x16 words: Transformers for image recognition at scale. (2020) : ViT
- Vivit: A video vision transformer. (2021)
- Masked autoencoders are scalable vision learners. (2022)
- Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution. (2023)
patches 이 비디오들과 이미지들의 다양한 유형에 대한 생성 모델을 training 하기 위해 높은-확장성 (highly-scalable) 과 효과적인 representation 임을 발견하였다.

At a high level
i. videos 를 lower-dimensional latent space 로 압축한다 (compressing).
- High-resolution image synthesis with latent diffusion models. (2022)
ii. representation 을 spacetime patchs 로 분해한다 (decomposing).
iii. videos 를 patches 로 전환한다.
Video compression network
-
visual data 의 dimensionality 를 줄이는 network 훈련을 한다.
- Auto-encoding variational bayes.(2013) : VAE
내 생각인데.. visual data 를 VAE 로 하는 것 보다는, Vector Quantized 계열로 가져가는게 더 효율적 일 것으로 생각한다. base VAE 로는 분명 latent space 도 그렇고 부담이 될 것이다. 아니면 다른 파생된 VAE 모델..
이 네트워크는 원본 비디오 (raw video) 를 input 으로 받아서 시간적 (temporally), 공간적 (spatially) 으로 압축된 latent representation 을 output 으로 내보낸다. Sora 는 이 압축된 latent space 내에서 훈련되고, 그 다음에 videos 를 생성한다. 또한 생성된 latents 를 pixel space 에 다시 매핑하여 해당하는 decoder model 을 훈련한다.
Generative-AI 의 기본 flow. 아니 잠깐만.. image 들의 연속성을 어떻게 하느냐가 궁금했는데 비디오 자체를 학습한다고? 그렇구나;;
Spacetime Latent Patches
압축된 input video 가 주어지면, transformer tokens 로써의 역할을 하는 연속적인 시공간 패치 (sequence of spacetime patches) 를 추출한다. 이미지는 단지 단일 프레임의 비디오 이므로, 이 방법은 image 에도 동작한다. patch 기반된 representation 을 통해서 Sora 는 다양한 해상도, 지속시간, 화면 비율의 비디오와 이미지를 train 을 할 수 있다. inference time 시, 적절한 크기의 grid 에 randomly 초기화된 patches 를 배열하여 생성된 비디오의 size 를 control 할 수 있다.
적절한 크기의 grid .. 추상적 단위..
Scaling transformers for video generation
-
Sora is a diffusion model
- Deep unsupervised learning using nonequilibrium thermodynamics. (2015)
- Denoising diffusion probabilistic models. (2020)
- Improved denoising diffusion probabilistic models. (2021)
- Diffusion Models Beat GANs on Image Synthesis. (2021)
- Elucidating the design space of diffusion-based generative models. (2022)
"noisy" patches (및 text prompts 와 같은 conditioning 정보) 가 입력으로 주어지면 original "clean" patches 를 예측하도록 훈련된다.
-
중요한 것은, Sora 는 diffusion transformer 이다.
- Scalable diffusion models with transformers. (2023)
Transformers 는
-
language modeling
- Attention is all you need. (2017) : Transformer
- Language models are few-shot learners. (2020) : GPT3
-
computer vision
- An image is worth 16x16 words: Transformers for image recognition at scale. (2020) : ViT
- Vivit: A video vision transformer. (2021)
- Masked autoencoders are scalable vision learners. (2022)
- Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.
-
and image generation
- Generative pretraining from pixels. (2020)
- Zero-shot text-to-image generation. (2021) : DALL-E
- Scaling autoregressive models for content-rich text-to-image generation. (2022)

이 작업에서 diffusion transformers 가 video models 로써도 잘, 효과적으로 scale 한다는 것을 발견하였다. 아래 video 들에서 traning 이 진행됨에 따라서 fixed seed 와 input 이 있는 video 샘플을 비교한다. training 계산이 증가함에 따라서 sample quality 가 눈에 띄게 향상된다.
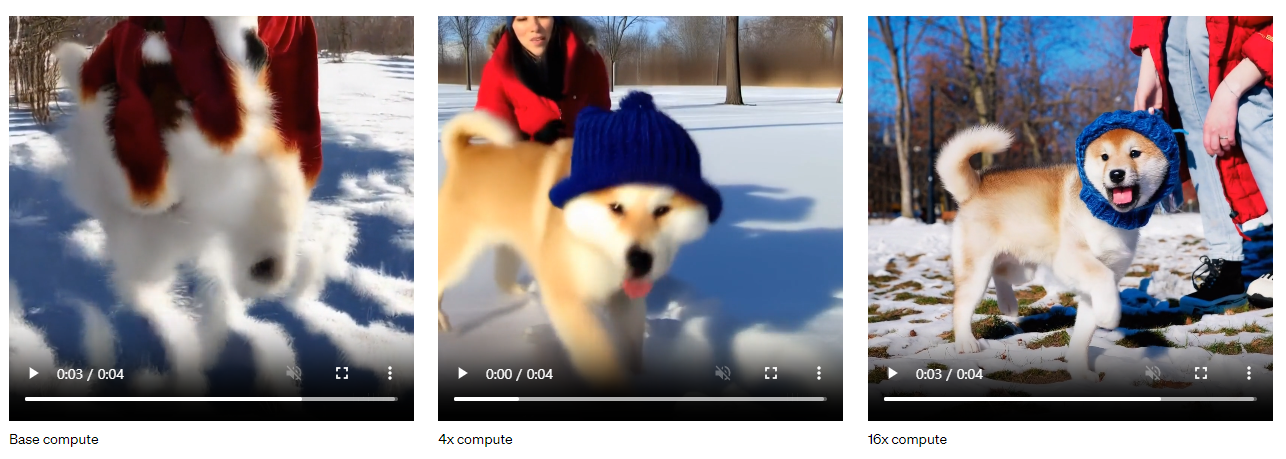
Base compute 는 사람, 개의 형체가 없다. 그냥 흐물흐물한 무언가 이상한 개체 정도로 인식된다.
4x compute 는 blur 하지만 어느 정도 사람, 개 형태를 갖춰서 생성하게 된다. 배경이 이제 인식된다.
16x compute 는 완전한 사람과 계 그리고 배경까지 완벽하다고 본다.
Variable durations, resolutions, aspect ratios
이미지와 비디오 생성에 대한 과거의 접근 방식은 전형적으로 standard size 의 videos 를 trim 하거나, resize, crop 한다 (e.g., 256x256 resolution 의 4 sec videos). 데이터를 native size 로 training 하는 대신, 여러 benefits 을 제공한다는 것을 찾았다.
Sampling flexibility
Sora 는 가로 p videos, 세로 p videos 및 그 사이의 모든 것을 sampling 할 수 있다. 이것으로 Sora 는 다양한 장치들, 그들의 다양한 화면 비율로 직접적으로 content 를 만들 수 있다. 또한, full resolution 으로 생성하기 전에 더 작은 크기의 content prototype 을 빠르게 만들 수 있다. -- (동일한 모델을 사용하여)

와.. 학습 해상도가 다른 비디오를 그냥 있는 그대로 학습했다는거 아냐? 그래서 같은 모델로 다양한 resolution 을 뽑아낼 수 있다는 거잖아.. 그러니 위에서 말한 "inference time 시에 적절한 크기의 grid 에 randomly 초기화된 patches 를 배열하여 생성된 비디오의 size 를 control 할 수 있다." 는 거잖아?
Improve framing and composition
비디오 고유의 native 화면 비율로 training 을 하면, 구성 (composition) 과 framing 이 향상되는것을 경험적으로 발견했다. generative models 를 training 할 때, 일반적으로 하는 모든 training video 를 square 로 자르는 모델의 버전과 기존의 Sora 와 비교한다. square crop (왼쪽) 으로 훈련된 모델은 때때로 주체가 부분적으로만 보이는 비디오를 생성한다. Sora (right) 로부터 나온 videos 와 비교하면, framing 이 향상 되었다.

Language understanding
text-video 생성 시스템을 training 하려면 해당 text caption 이 같이 있는 대량의 비디오가 필요하다. DALL-E 3 에서 소개된 re-captioning 기술을 videos 에 적용한다. (NO WAY!!) 먼저 높은 설명(descriptive)력의 captioner model 을 훈련하고 나서, 이를 사용하여 training set 에 있는 모든 videos 에 대한 text captions 을 생성한다. 높은 설명력의 video captions 에 대한 training 을 통해 text 의 정확도 뿐만 아니라 videos 의 전반적인 질도 향상된다는 것을 발견 하였다.
아니 잠깐만.. DALL-E 3 에서 사용한 re-captioning 기술을 비디오에 적용.. 해서 데이터 생성하고
DALL-E 3 과 유사하게 GPT 를 활용하여 short user prompts 를 video model 로 보낼 때는 더 길고 자세한 caption 으로 변환한다. 이를 통해서 Sora 는 user prompt 를 정확하게 따르므로, 고품질의 비디오를 생성할 수 있다.
와... GPT 를 써서 대충 짧게 쓴 문장을 Sora 에 맞게 길게 필요한 prompts 로 바꿔서 모델에 보낸다는 것 아냐?

참고로 이거 video 다..;;;;
Prompting with images and videos
모든 결과는 text-to-video 의 sample 들로 보여준다. 그러나 Sora 는 기존에 존재하고 있는 이미지나 비디오와 같은 다른 입력을 통해서도 prompted 를 할 수 있다. 이 기능을 통해서 Sora 는 광범위한 image 및 video 편집 작업을 수행할 수 있다. -- 완벽하게 반복되는 비디오, 정적 이미지의 애니메이션화, 시간의 앞으로 또는 뒤로 비디오 확장, 등
Animating DALL-E images
-
Sora 는 입력으로 image 와 prompt 가 제공되는 video 를 생성할 수 있다. 아래에는 DALL-E 2 와 DALL-E 3 image 를 기반으로 생성된 video 예시를 볼 수 있다.
- Improving image generation with better captions. (2023) : DALL-E 3
- Hierarchical text-conditional image generation with clip latents. : DALL-E 2
-
Shiba Inu dog wearing a beret and black turtleneck.

-
Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka dotted monster, all interacting in a playful environment.

-
An image of a realistic cloud that spells "SORA".

-
In an ornate, historical hall, a massive tidal wave peaks and begins to crash. Two surfers, seizing the moment, skillfully navigate the face of the wave.

Extending generated videos
Sora 는 또한 시간의 앞으로 (forward : ) 또는 뒤로 (backward : ) videos 를 확장 시킬 수 있다. 아래의 영상은 generated video 의 한 부분 (segment) 로부터 시작해서 시간의 뒤로 (backward : ) 확장된 3개의 video 이다.
backward 는 시간의 역순이다.
- 기준이 되는 시작점 (약 00:11)
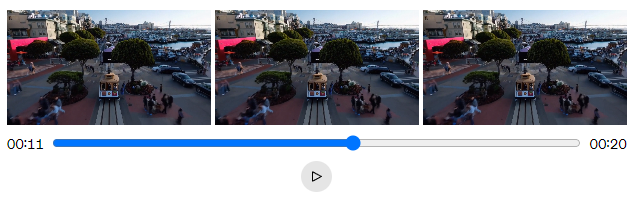
(backward : )
- backward 이므로, 영상의 처음이 끝점 (00:00)

이 방법을 사용하면, video 를 앞으로 및 뒤로 확장하여 원활한 (seamless) 무한 루프를 생성할 수 있다.


14 초 다음 0 초로 가는데 영상이 무리가 없다. 처음에 초를 안보고 약 30초 넘게 끝날 때까지 보고 있었다.
Video-to-video editing
Diffusion models 를 통해서 text prompts 에서 images 와 videos 를 편집하는 다량의 (plethora) 방벅들이 가능해졌다.
-
아래에서는 이러한 방법 중 하나인 SDEdit 를 Sora 에 적용했다.
- Sdedit: Guided image synthesis and editing with stochastic differential equations. (2021)
이 기술을 통해서 Sora 는 input videos 의 스타일과 환경을 zero-shot 으로 transform 하는 것이 가능해졌다.
- recreate in the style of a charcoal drawing, making sure to be black and white

;;;; 할 말이 없어진다 이건..
Connecting videos
또한 Sora 를 사용하여 두 개의 input videos 사이를 점진적으로 interpolate 하여 완전히 다른 주제 (entirely different subjects) 와 장면 구성들 (scene compositions) 을 사이를 원활히 전환할 수 있다. 아래의 예시에서 중앙의 비디오는 왼쪽과 오른쪽의 해당 비디오 사이를 interpolate 한다.


1 번째 video 만 보면, 6 초에서 7 초가 될 때 드론에서 나비로 바뀐다. 배경도 로마 콜로세움에 해초가 자라날 줄이야... interpolate 이 진짜 이렇게 되서 만약 나온다면, 해보고 싶은 scene 이 있다.

이건 거의 Inception 혹은 Interstellar 의 Cooper station 같다... 잘된다.
Image generation capabilities
Sora 는 image 생성도 가능하다. 한 frame 의 시간적 (temporal) 범위를 갖는 공간 grid 에 Gaussian noise 의 patches 를 입혀서 image generation 을 한다. 이 모델은 최대 해상도의 다양한 크기의 images 를 생성할 수 있다.
- Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field.
- Vibrant coral reef teeming with colorful fish and sea creatures.

- Digital art of a young tiger under an apple tree in a matte painting style with gorgeous details.
- A snowy mountain village with cozy cabins and a northern lights display, high detail and photorealistic dslr, 50mm f/1.2

Emerging simulation capabilities
video model 이 대규모로 trained 될때 여러가지 흥미로운 새로운 기능을 보여준다는 것을 발견했다. 이러한 기능들을 통해 Sora 는 물리적 세계에서 사람, 동물 및 환경의 일부 측면 (aspects: 외관, 모양) 을 simulate 할 수 있다. 이러한 속성들은 3D, 객체 등에 대해 explicit inductive biases 가 없이 나타난다. 그들은 순전히 scale 의 현상이다.
여기서 말하는 scale 의 현상은 엄청 많은 영상 데이터에서 나오는.. 힘인듯 하다..
3D consistency.
Sora 는 dynamic camera motion 을 통한 videos 를 생성할 수 있다. 카메라가 이동하고 회전함에 따라서, 사람과 장면 요소들이 3차원 공간에서 일관되게 움직인다.

오른쪽 사진의 17 밑에 두 사람이 걸어가고 있고 회전하면서 찍고 있는 영상이다.
Long-range coherence and object permanence.
video 생성 시스템의 significant 한 challenge 는 long videos 를 sampling 할 때, 시간적인 일관성을 유지하는 것이었다. Sora 는 매번은 아니지만, 종종 단기 및 장기 종속성을 (both short- and long- range) 효과적으로 모델링 할 수 있다는 것을 발견했다. 예를 들어, Sora 는 사람, 동물 및 객체들이 가려지거나 frame 에서 벗어날 때에도 유지할 수 있다. 마찬가지로, single sample 에서 동일한 캐릭터의 여러 장면을 생성하여 비디오 전체에서 해당 모습을 유지할 수 있다.



왼쪽은 객체들로 가려지거나 frame 에서 벗어나도 유지하는 느낌인 video.
오른쪽은 single sample 에서 동일한 캐릭 여러 장을 생성하는 느낌인 video.
Interacting with the world.
Sora 는 때때로 간단한 방법으로 세상의 상태에 영향을 주는 행동을 simulate 을 할 수 있다. 예를 들어서, 화가는 시간이 지나면서 canvas 를 따라 새로운 획(그림)을 그릴 수 있고, 남자가 햄버거를 먹고 빵에 치아가 물린 자국을 남길 수 있다.

빵 먹고 남은, 물었던 모양, 남은 디테일 ;; diffusion transformer .. @ㅅ@
Simulating digital worlds.
Sora 는 artificial processes 도 simulate 할 수 있다. 한 가지 예시는 video games 이다. Sora 는 basic policy 로 Minecraft player 를 동시에 컨트롤 할 수 있고, 그 세계와 높은 정확도의 dynamics 한 것들을 동시에 rendering 할 수 있다. 이런 기능들을 "Minecraft." 라는 caption 을 언급하여 Sora 에게 prompting 하여 zero-shot 을 유도할 수 있다.

이러한 기능들은 video models 의 지속적인 scaling 으로 인해 physical, digital 세계 그리고 그 안에 사는 객체, 동물 및 사람들을 만드는 높은 성능의 시뮬레이터의 개발을 위해 맞는 길임을 제안한다.
unreal engine 에 대항하겠다는 거냐? 지금 너희들이 가지고 있는 데이터가, video 에 dall-e 2/3 이 re-captioning 한 그 어마어마한 대량의 질좋은 video-text 학습 데이터가 있어야하고, 그걸 커버할 수 있는 리소스가 필요한건데? ;; 이런 말 할꺼면 모델, 데이터 공개 하던가;; 지금 상황에 가성비는 unreal 이 맞지.
참고로 Minecraft 는 voxel 방식으로 real-world 를 가장 일관성있는 구조로 만들 수 있는 최고의 환경이다.
Discussion
Sora 는 현재 시뮬레이터로서 많은 (numerous) 한계를 보여주고 있다. 예를 들어, 유리 깨짐 (glass shattering) 과 같은 많은 기본 상호 작용의 물리적 현상을 정확하게 모델링하지 못한다. 음식을 먹는 것과 같은 다른 상호 작용 (Other interactions) 이 항상 object 상태에 알맞은 변화를 가져오는 것은 아니다. 장기간 (long duration) 샘플들에서 발생하는 불일치나 개체의 자발적인 출현 (spontaneous appearances : 알맞지 않는 돌출 행동 으로 이해) 과 같은 모델의 보통의 오답 모드를 나열한다.
물리 엔진이 아닌 것을, real world 를 physical world 로 보면서 collision 처리 로직이나 occlusion culling 등 또한 진짜 영상으로만 밀어 붙이려고 하는게.. nlp, vision, 등에서도 prior knowledge 나 supervision 없이 ...

도플 갱어 인가? ...
Today, Sora 가 가지고 있는 능력이 Video 모델의 지속적인 확장 (scaling) 이 물리적 세계와 디지털 세계, 및 그안에 사는 개체들, 동물들 그리고 사람들을 만드는 높은 성능의 시뮬레이터 개발을 위해 맞는 길 임을 보여주고 있다고 믿는다.
목적은 물리엔진, 세상, 가상화 환경을 전문가 다 재끼고, 영상 데이터로만 만들겠다는 거잖아? 너희들 미쳤어?
