TabPFNv2. 하물며 Nature 에 올라와 있다.
Abstract
- TabPFN 은 테이블 데이터를 생성형 Transformer 기반 모델로 접근.
fine-tuning, data generation, density estimation, 재사용 가능한 embedding 학습을 가능. - TabPFN 은 수백만 개의 합성 데이터 셋으로 학습되는 알고리즘으로, 알고리즘 개발에 있어서 접근 방식의 강함을 보여줌.
tabular data 까지.. Attention 으로 섭렵 하려고 하는구나. 그래서 이름도 Prior 가 되냐!
- tabular data 의 다양성은 text 와 image 와 같은 가공되지 않은 비정형 다차원 데이터의 유형과 구별.
- 언어의 모델링에서는 단어의 의미가 문서간에 일관성이 있지만,
- tabular 데이터 셋은 동일한 값이 근본적으로 다른 의미를 가질 수 있다.
예를 들어서,
1. 신약 개발 데이터 셋은 화학적 속성을 기록할 수 있는 반면,
2. 재료 과학 데이터 셋은 열과 전기 속성을 기록할 수 있다.
이러한 전문화는 더 작고 독립적인 데이터 셋과 관련된 모델들이 급증 (proliferation) 하는 현상으로 이어진다.
- 인기 있는 tabular benchmarking 웹 사이트인
openml.org에서는 이 글을 쓰는 시점에서76%의 데이터셋이10,000 개 미만의 행을 포함하고 있다.
여기서 문제가, tabular data 는 하나의 열, feature 가 강한 특징을 갖는다. 따라서, 수치만 봐서는 그 관계를 feature 의 의미를 뜯어 보기 전까지는 알 수가 없다. 특히, attention 은 sequential data 에 특화 되어 있는데, 어떻게 풀어 나가는지 보자.
Deep learning 방법들은 전통적으로 tabular data 에서 힘을 발휘하지 못했는데, 그 이유는 데이터 셋들 간의 heterogeneity (이질성) 과 raw data 자체의 heterogeneity 때문 인다.
Table 데이터는
- features 라고 불리는 여러 column 이 있고,
- 다양한 scales 와 type (Boolean, categorical, ordinal, integer, floating point) 이 imbalanced 하거나
- missing data, unimportant features 그리고 outliers 등 이 존재한다.
이로 인하여, tree 기반의 모델들과 같은 non-deep-learning methods 들이 지금까지 강력한 대안으로 여겨져 왔다.
당연한 말인게, 원래 feature engineering 이 존재하고, 그것으로 결측치 혹은 missing data 을 어떻게 할지 설정하며, bagging, boosting 계열의 트리 구조 모델로 feature importance 를 구하여 weight 을 주던가 혹은 feature extract 를 하게 된거지..
하지만, 이러한 전통적인 ML 에는 몇 가지 단점이 있다.
1. 상당한 수정 없이는 분포 밖(out-of-distribution OOD) 데이터의 성능이 떨어지고,
2. 한 데이터 셋에서 다른 데이터 셋으로의 transfer of knowledge 전이도 원활하지 않다.
3. 이 모델들은 propagate gradient 를 지원하지 않아서, neural net 과의 결합이 어렵다.
실제 데이터는 0, NA, NaN 등 데이터가 부지기수이고, 각 열의 box-plot 의 median 값이 0 인 데이터도 수두룩 하다. 즉, 사용할 수 없는 데이터가 너무 많은데.. 도메인 지식 상 꼭 필요한 변수도 있고, 실제 데이터에 문제가 많아서, 모델이 잘 맞지 않는 경향이 크다.
해결책으로, TabPFN 을 소개.
- small ~ midum-sized tabular 데이터 를 위한 foundation model.
- 이 새로운 supervised tabular 학습 방법은 어떤 소~중간 규모의 데이터 셋에도 적용 가능하고,
- 최대 1만 개의 sample 과 500 개 feature 를 가진 데이터 셋 까지 압도적인 성능을 낸다.
단일 forward pass 에서 TabPFN 은 우리의 benchmarks 에서 gradient-boosted decision tree 포함하는 SOTA 기준 모델들 보다 압도적인 성능 을 낸다.
- 심지어, 4시간의 tuning 시간을 허용하더라도,
- 속도는 classificaion 에서 5140배,
- regression 에서는 3000배 더 빠르다.
거기에, TabPFN 의 fine-tuning, generative 능력 그리고 density 추정을 포함한 foundation model 의 특성도 보여준다.
사실 DeepLearning 계열의 attention 이라면.. fine-tuning 이 가능하고, 살짝 밑을 봤지만 synthetic data 도 생성하는 것 같다. 물론 prefill, KV cache 등 현재의 engineering trend 도 포함하고 있어서, 전투적으로 사용할 예정이다.
Principled in-context learning
-
TabPNF 은 in-context learning (ICL) ,
- Larage Language Model (LLM) 의 놀라운 성능을 이끌어낸 것과 같은 메커니즘을 활용.
- 완전히 학습된 강력한 tabular 예측 알고리즘을 만들어 냄.
-
ICL 은
- Larguage Language Model (LLM) 에서 처음 관찰 되었지만,
- 현재는 transformer 모델이 logistic regression 과 같은 간단한 알고리즘 을 학습할 수 있음.
이 반박을 하자면, 포크가 있으면 될 걸, 포크레인 을 사용하는 비유를 했었다. 그런데, 단 하나의 이점이 그것을 상쇄 시킨다. 위에서 언급한, "전문화된 더 작고 독립적인 데이터 셋과 관련된 모델들이 급증 (proliferation) 하는 현상으로 이어진다" 이게 해결된다면, 하나의 모델로 가능하다면.. end-to-end 처럼 현재 trend 를 반영하게 된다. 즉 포크레인이어도 된다.
- Prior-data Fitted Networks (PFNs) 는
- Gaussian Processes 와 Bayesian Neural Networks 와 같은 복잡한 알고리즘도, ICL 을 사용하여 approximated 할 수 있음을 보여줌.
- ICL 을 통해서 가능한 알고리즘들의 더 넓은 공간을 학습하게 해주며,
- closed-form solution (닫힌 형태의 해) 가 존재하지 않는 경우까지 포함.
원래 Deep Learning 계열의 모델은 Bayesian Neural Network 이다. 거기에 비선형 방정식의 해를 풀 수 있는 객체이다. 거기에 closed-form 해가 없는 건, 해는 물론 있겠지만, 못찾는 것을 approximate 한다는 거니, 아주 강력한 approximator 이므로 가능하다고 생각한다.
다만, 문제는 그 해석이 어렵다는 것인데.. GP 는 다른 의미로 데이터가 많지 않는 경우, 1-D regression 일 때, 내가 원하는 값에서 를 예측하는, 그리고 confidence interval 까지 푸는 방법이잖아. 좀 더 들여다 볼 가치가 있다.
- TabPFN 초기 버전
- principle 하게는 tabular 데이터에 ICL 을 적용할 수 있음을 보여주었지만,
- 한계가 많아서 거의 대부분의 케이스에 적용하기 어려웠다.
초기 버전을 기반으로 개선된 버전이 개발되었다.
-
새로운 TabPFN
- 데이터 셋 규모를 50배 더 크게 확장할 수 있고,
- regression tasks, categorical data 그리고 missing values 그리고 중요하지 않는 features, outliers 에 대해서 robust 한 성능을 보임.
-
TabPFN 의 핵심 아이디어
- synthetic tabular 데이터셋을 만들고,
- 그 후에 transformer 기반 신경망을 학습시켜서,
- 이 합성 데이터셋에서의 예측 문제들을 푸는 방법을 learn 한다.
-
전통적인 방식
- missing values 와 같은 데이터 문제를 해결하기 위해서 수작업으로 솔루션을 설계해야 하지만,
- 이러한 challenges 가 포함된 synthetic task 를 해결함으로써,효과적인 전략을 자율적으로 학습한다.
이러한 접근으로 ICL 을 examplar (예시) 기반의 declarative (선언적) 알고리즘 프로그래밍 프레임워크로 활용한다.
- 알고리즘적 behaviour 를 설계하기 위해서,
- 원하는 behaviour 를 보여주는 다양한 synthetic dataset 을 생성한 후,
- 이것을 만족하는 알고리즘을 모델이 encode 하도록 학습 시킨다.
- 이러한 접근 방식은 알고리즘 설계 과정을 explicit (명시적) instruction (지시문) 을 작성하는 방식에서 input-output 예시를 정의하는 방식으로 전환 시켜서,
- 다양한 도메인에서 알고리즘을 개발할 수 있는 가능성을 열어준다.
이런 접근으로
single_eval_pos이후 부터 예측으로 들어가게 되는거잖아. 생각의 전환 이랄까,ICL은 언어의 sequence 만 생각했었는데,few-show learning처럼 데이터를 앞에 두고 ICL 이라는 방법으로 밀어 넣을 줄이야..
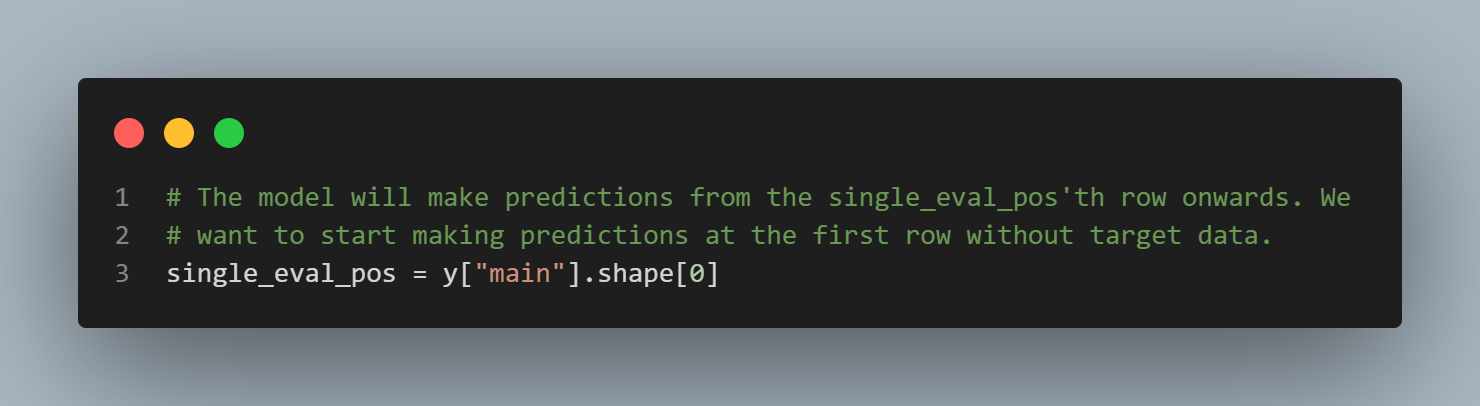
이러한 접근을 high-impact 가 큰 분야인 tabular 학습에 적용, 강력한 tabular 예측 알고리즘을 생성.
좀 더 읽어보자. 그러니까 이해가 안되는 부분은.. input-output 예시를 전환해서, 다양한 도메인에서 알고리즘을 개발한다는 건데.. ICL 접근 방식 가닥이 조금씩 이해되고 있음..
-
standard 한 supervised deep learning 의 ICL 접근 방식
- standard 한 supervised deep learning 과는 근본적으로 다르다.
- 보통 모델은 데이터셋 별로 학습되며,
- Adam 과 같은 hand-crafted (사람이 설계) 한 가중치 업데이트 알고리즘을 사용해서,
- 개별 샘플이나 미니 배치 단위로 parameter 를 업데이트.
- inference time 에서는 학습된 모델을 test sample 에 적용.
-
TabPFN 의 ICL 접근 방식
- TabPFN 의 접근은 across datasets (여러 데이터셋을 가로질러) 전체에 걸쳐서 학습된 후,
- 추론 시에도 개별 샘플이 아니라 데이터셋 전체를 적용.
실제 데이터 셋에 적용되기 전에, 이 모델은 다양한 예측 과제를 나타내는 수백만 개의 synthetic datasets 으로 한 번 pre-training 된다.
- inference time
- label 이 있는 training sample 과
- label 이 없는 test sample 이 모두 포함된 unseen dataset 을 입력 받아서,
- 그 데이터 셋에 대한 training 과 prediction 을 단일 neural network forward pass 에서 수행.
Step 1 : pretrained 된 하나의 Neural Network (Transformer) 에
Step 2 : labeled train 샘플 + label 이 없는 test 샘플 을 한꺼번에 입력으로 넣는다.
Step 3 : Network 가 train 부분을 context 로 읽고, test 에 대해 바로 예측을 뱉는 구조.parameter 를 업데이트 하는 training 이 아니라, dataset 안의 예시를 조건 삼아서 규칙을 내부적으로 맞춰보는 incontext learning? 아니 그러면 매번 넣을 때, 기존의 train data 를 넣고, 분포를 찾은 다음, test data 를 넣는다는거네? 그게 incontext learning 인 것이야.
tabular data 를 training 하고 finetuning, inference 할 때
attention_head가 사용되는게 뭔가.. 이질적 이면서도, 새로운 것을 받아들여야 하는 기대감 이랄까.. 그런 것이 든다.
Overview of the proposed method.
-
Fig. 1
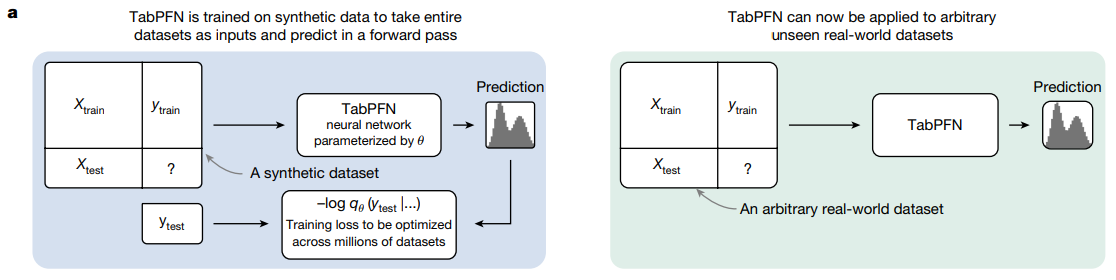
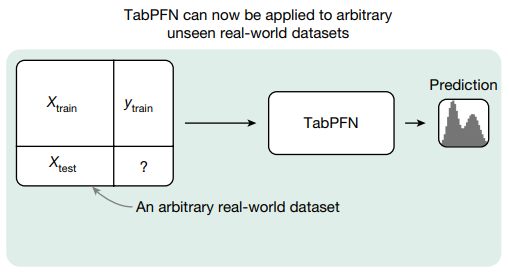
a. TabPFN 사전 학습 과 사용에 대한 개괄적인 설명.
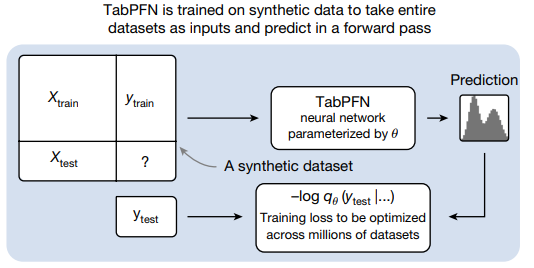
-
TabPFN 은 합성 데이터로 학습되고, 데이터 셋 전체를 입력 받아서 한번의 forward pass 로 예측
-
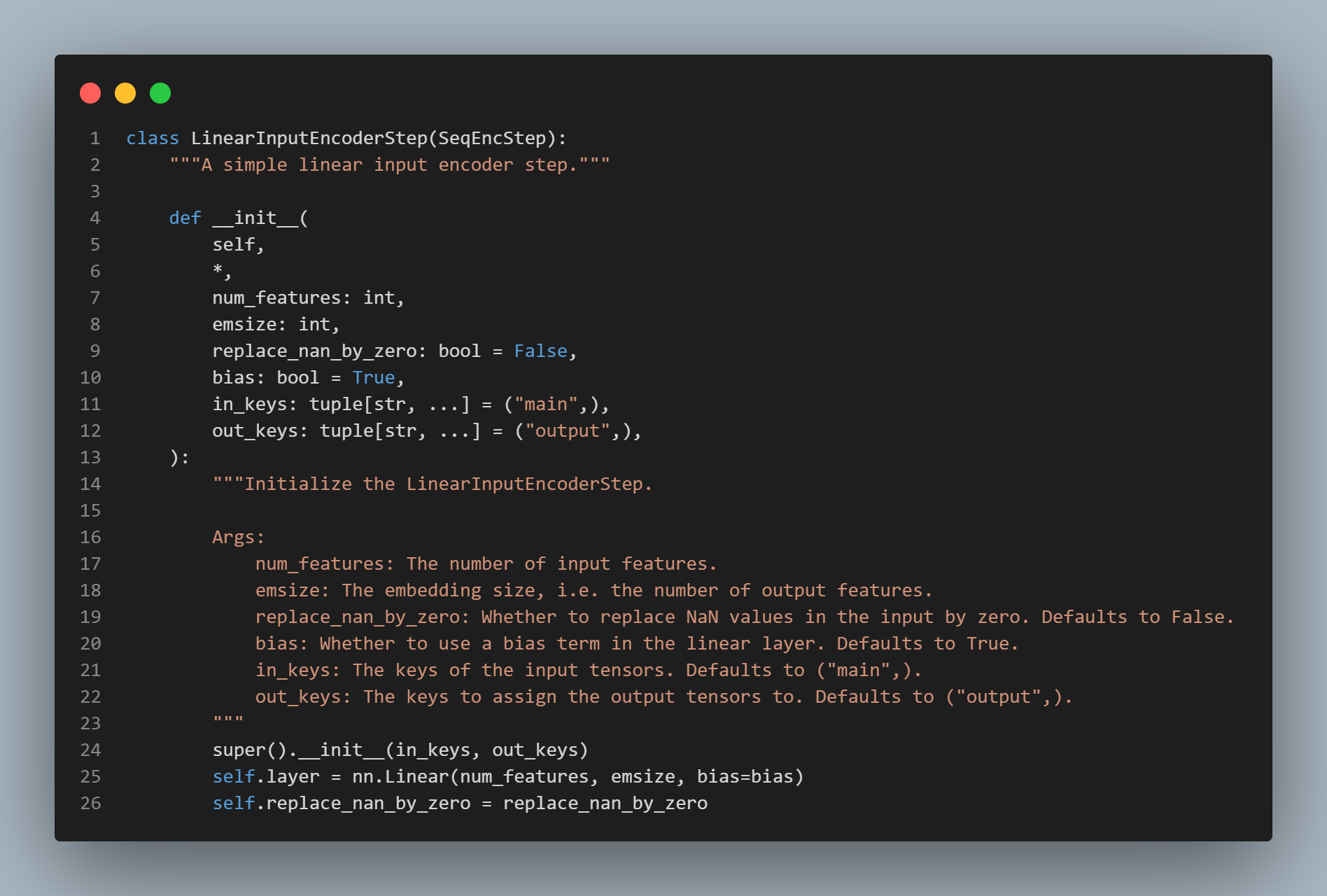
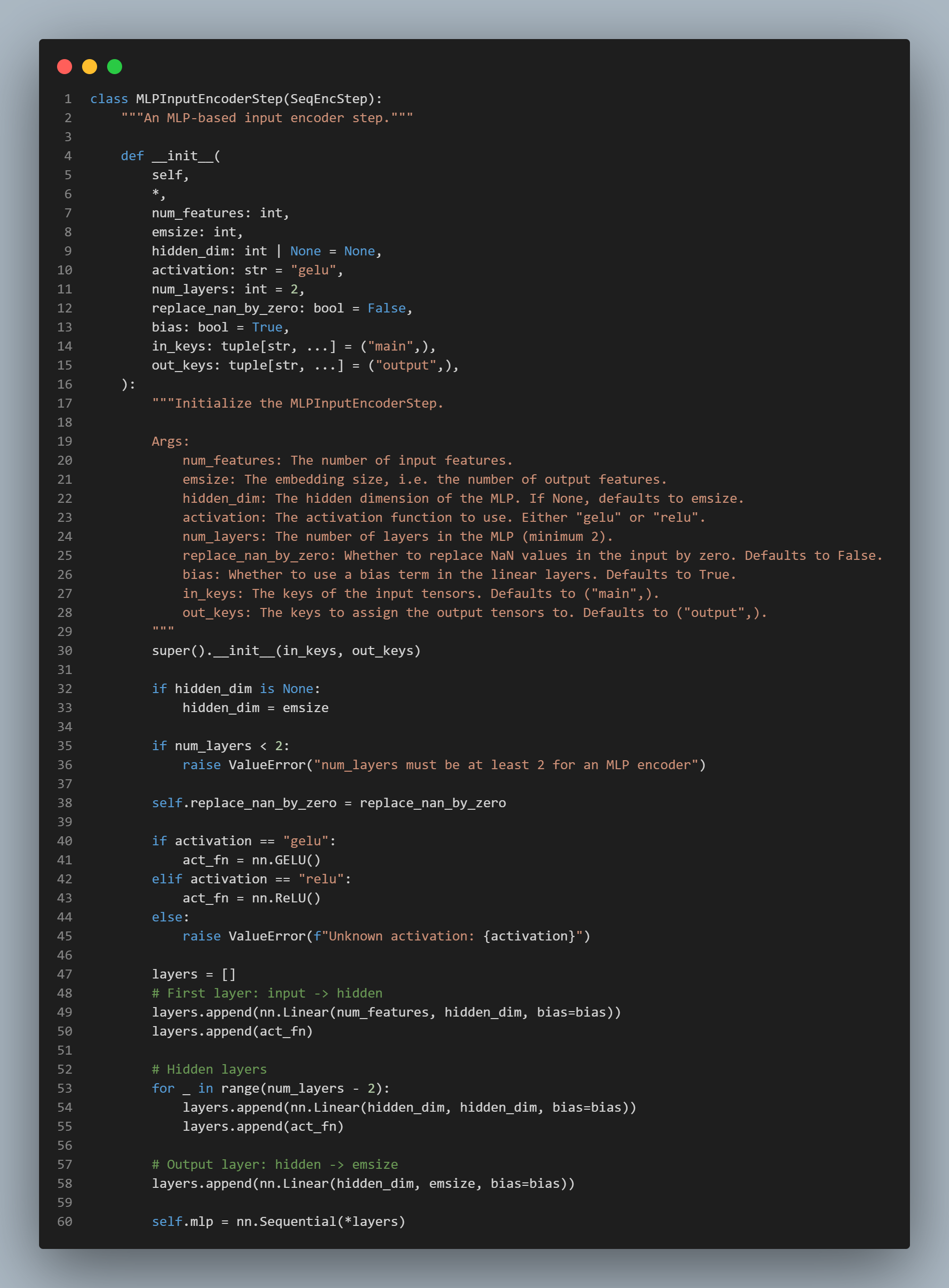
TabPFN : 에 의해서 parameterized 된 neural network
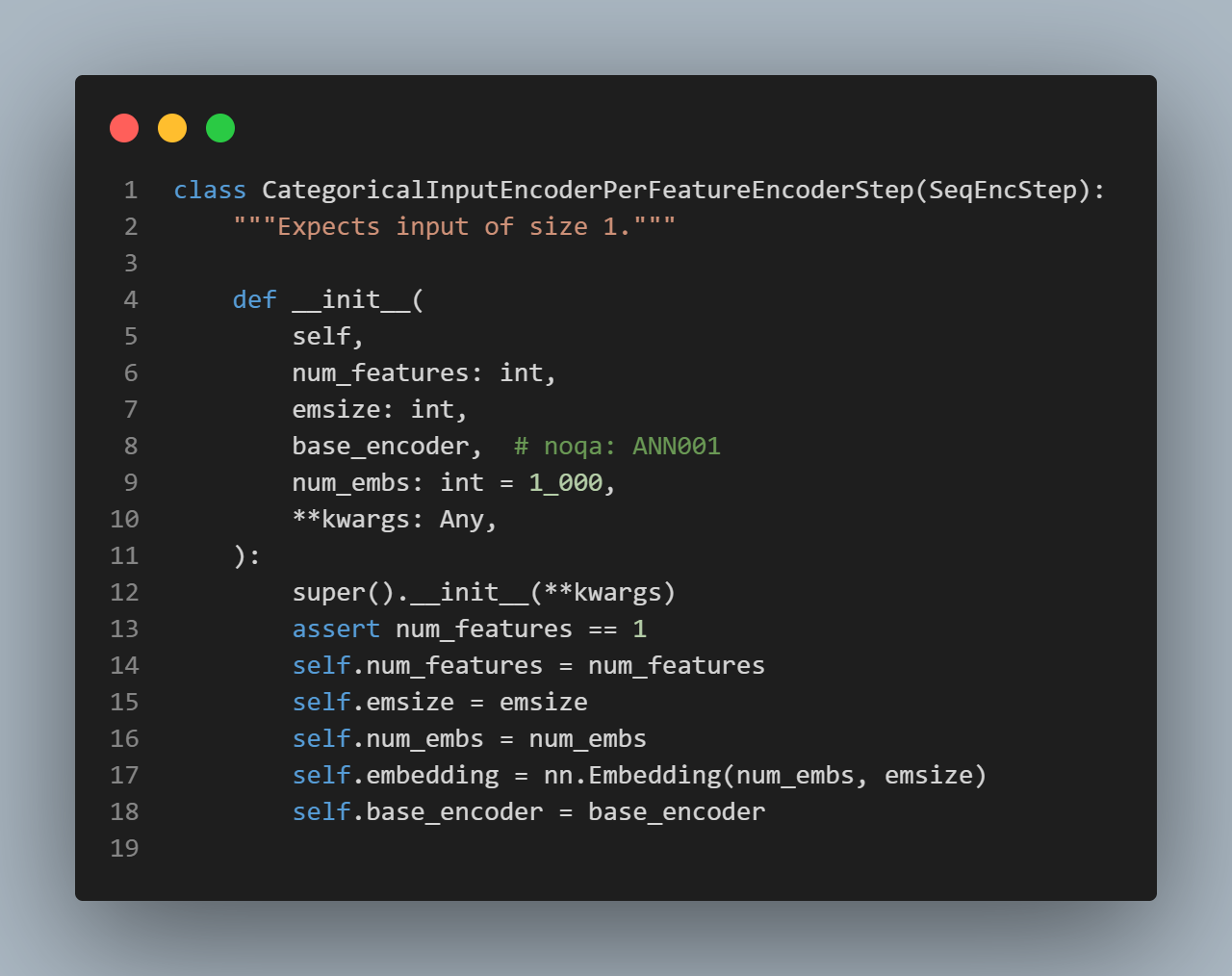
상속 잘먹였다.
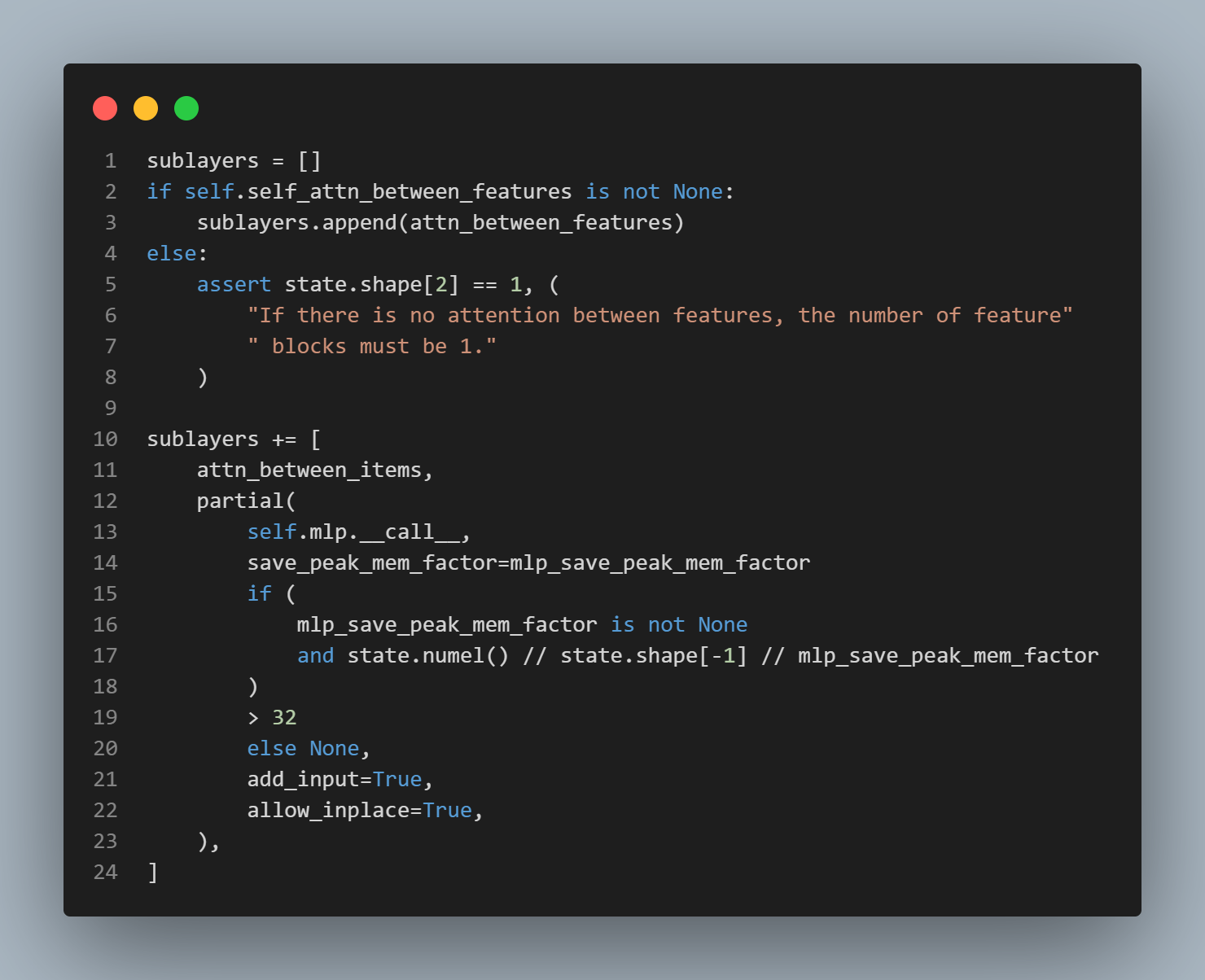
Classifier와Regressor를 Architecture 거쳐서 만들게 하고 그걸 factory 함수에서 제어하게 함.
-
: 수백만 개의 dataset 에 걸쳐서 (데이터 셋 전부) 최적화 해야하는 training loss.
그렇지. negative log-likelihood 계산 는
CrossEntropyLoss로 하는거지.
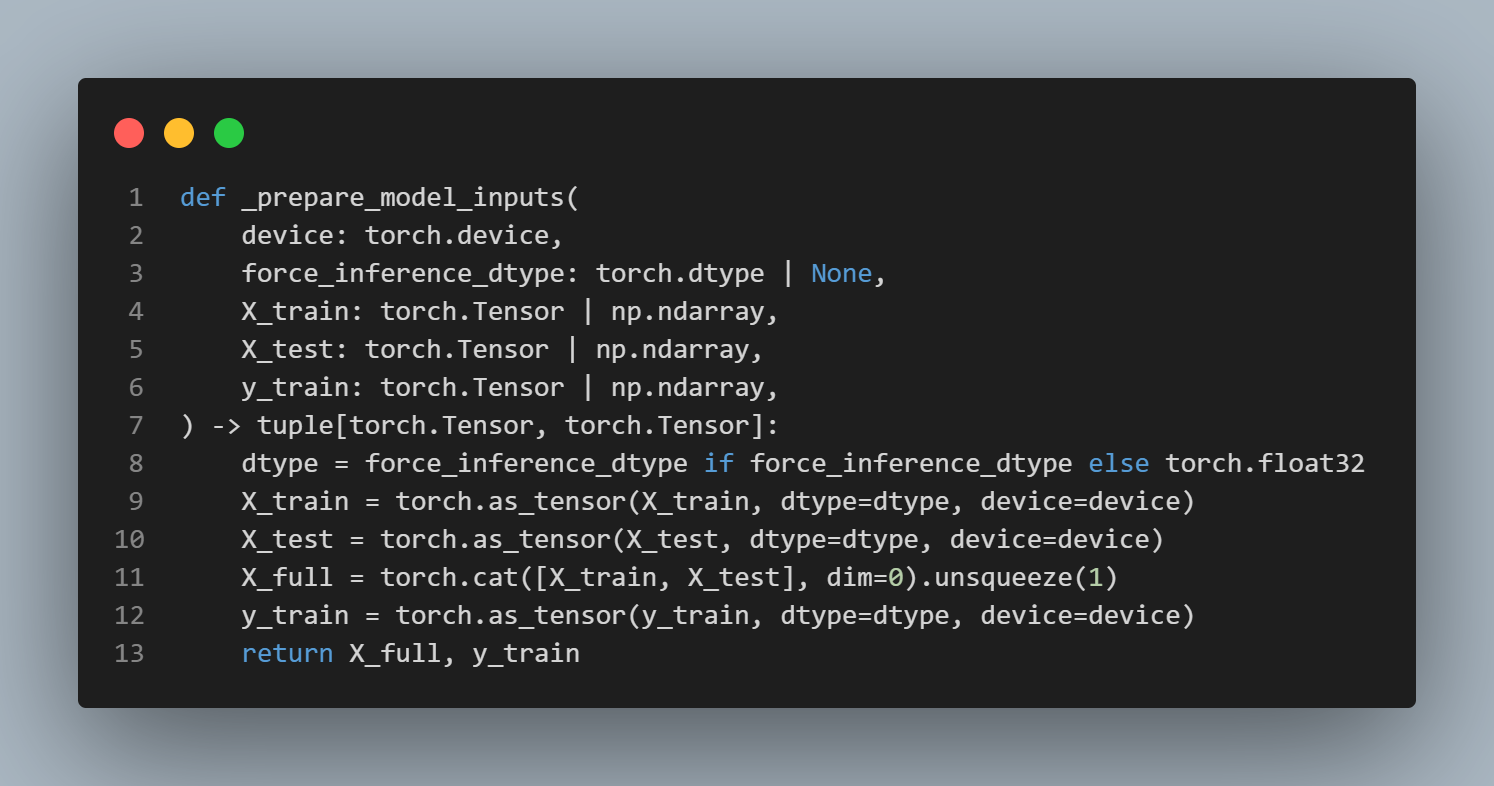
x_full코드를 보면,X_train, X_test를concat으로 묶는 부분이 보인다.
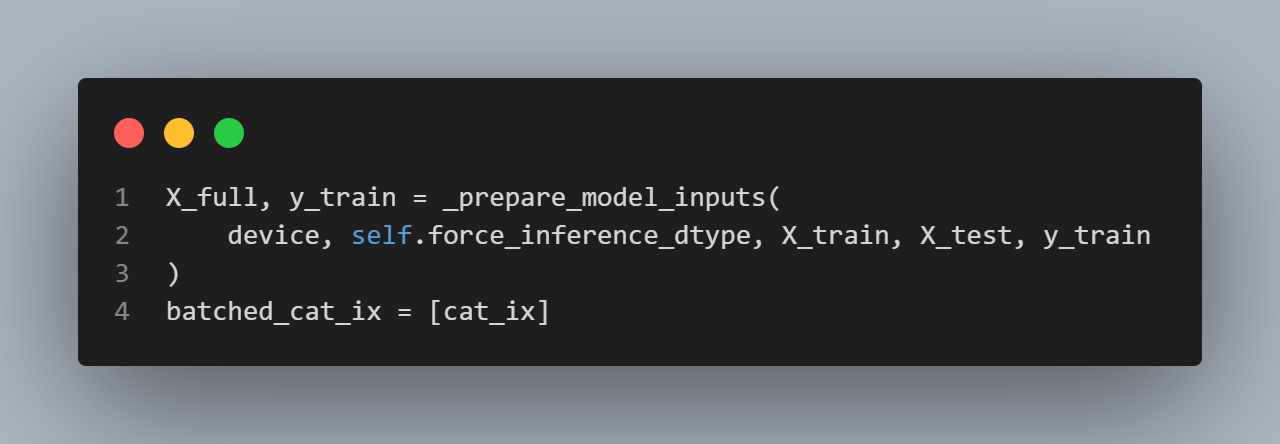
inference 할 때
-
TabPFN 은 이제 임의의 미공개 실 세계의 데이터 셋에 적용 가능.
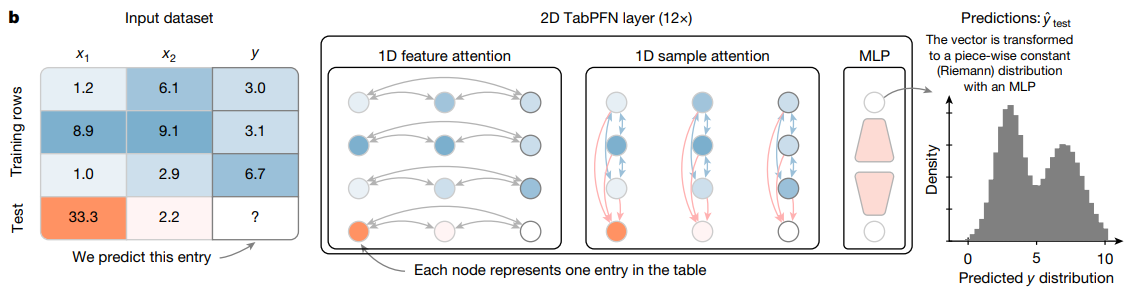
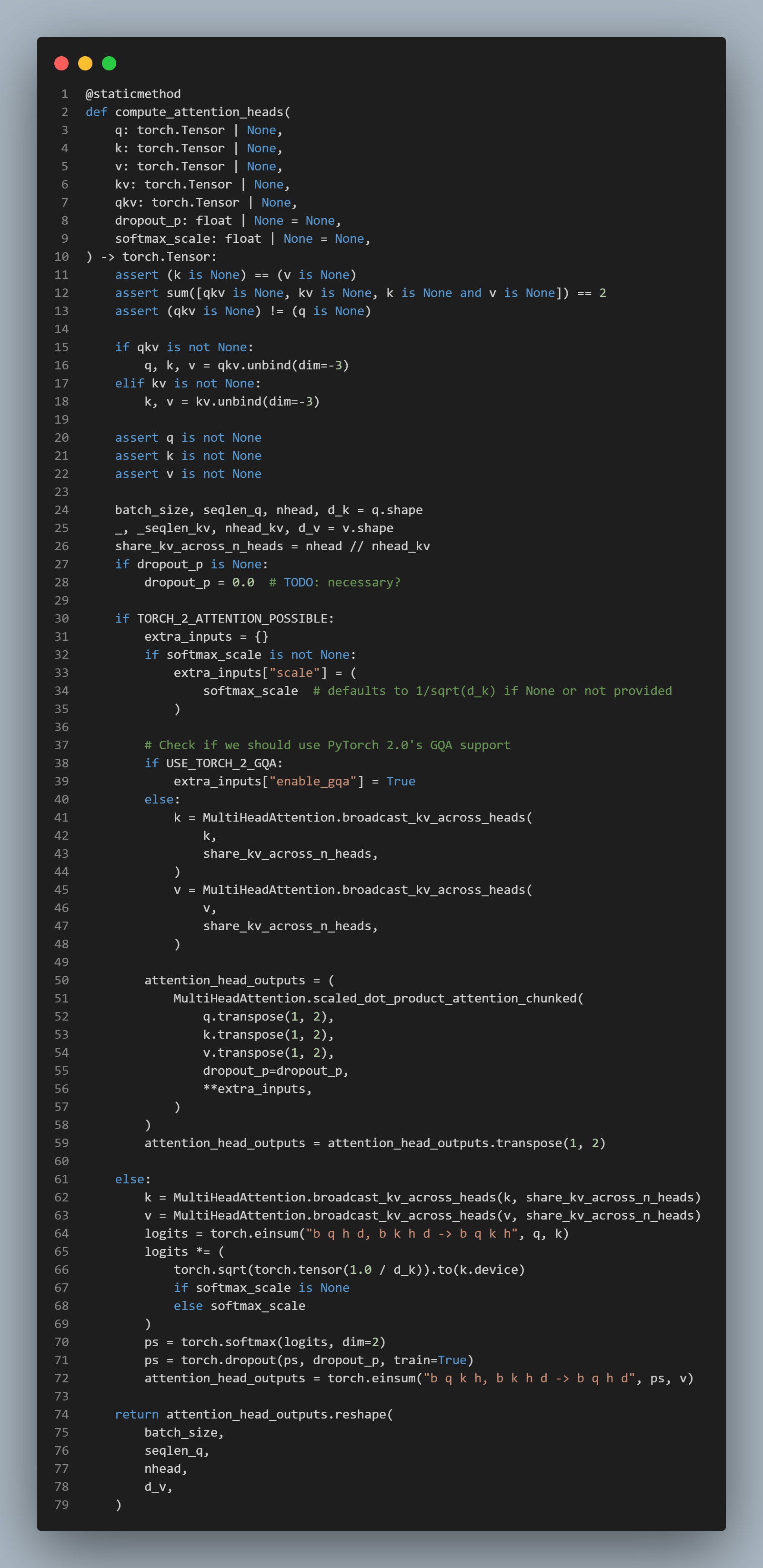
b. TabPFN architecture.
- 100 million 개가 넘는 synthetic 과제를 풀도록 모델을 학습 시킴.
- 이 Architecture 는 table 에서 나타나는 2차원 데이터에 맞게 조정한, standard transformer encoder 를 변형한 것.
?의 entry 를 예측. 각 노드는 table 에서 하나의 entry 를 표현 분포를 예측.- vector 는 MLP 를 사용하여 구간별 상수(Riemann) 분포로 변환.
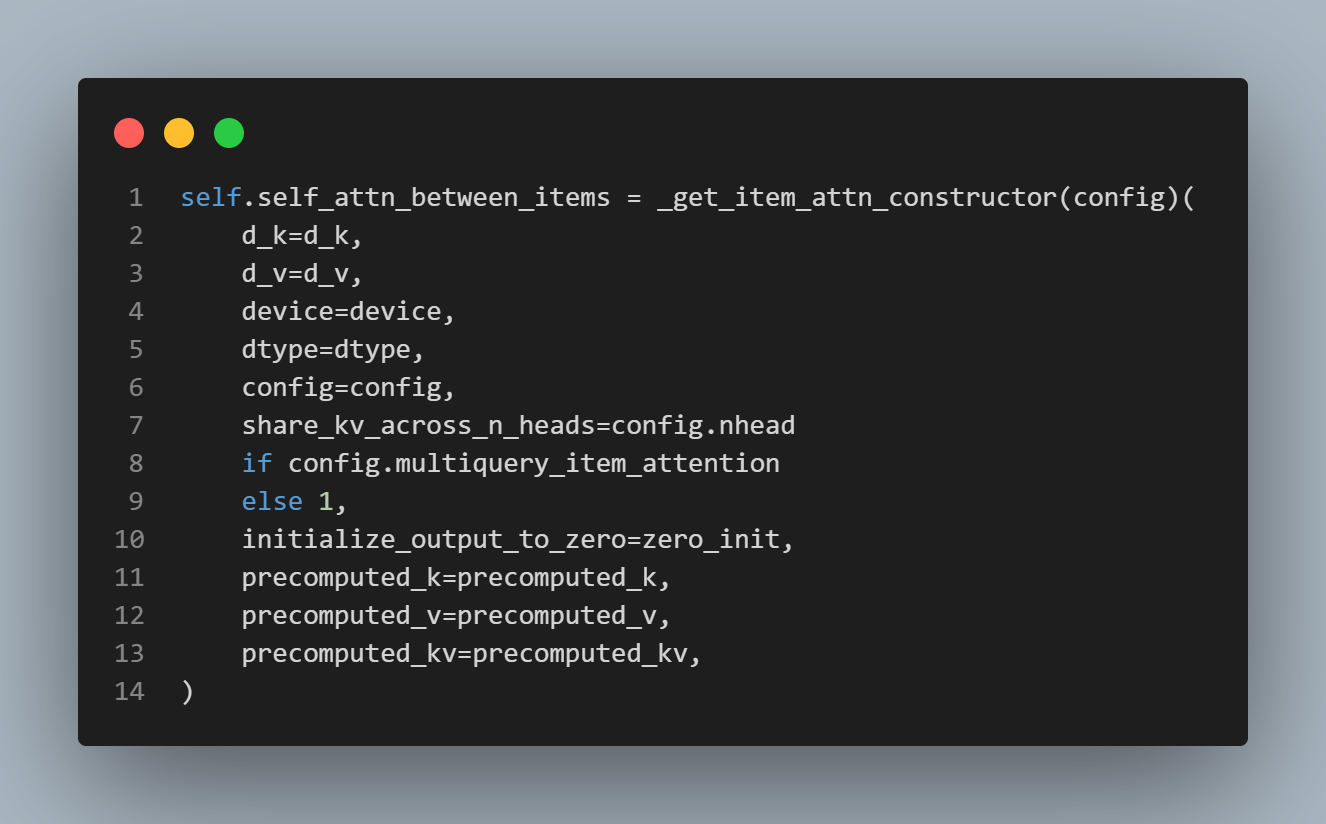
sample attention: sample (행) 간 attention
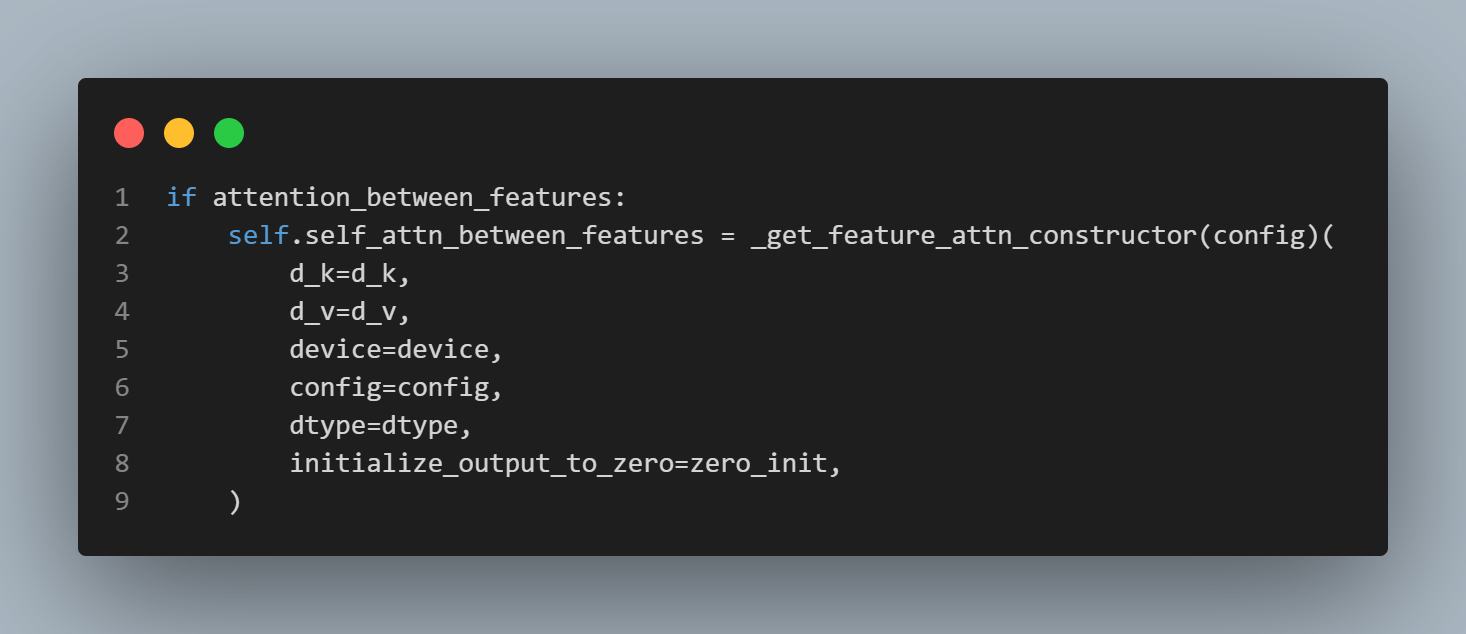
feature attention: feature (열) 간 attention
-
Overview of the TabPFN prior
-
Fig. 2
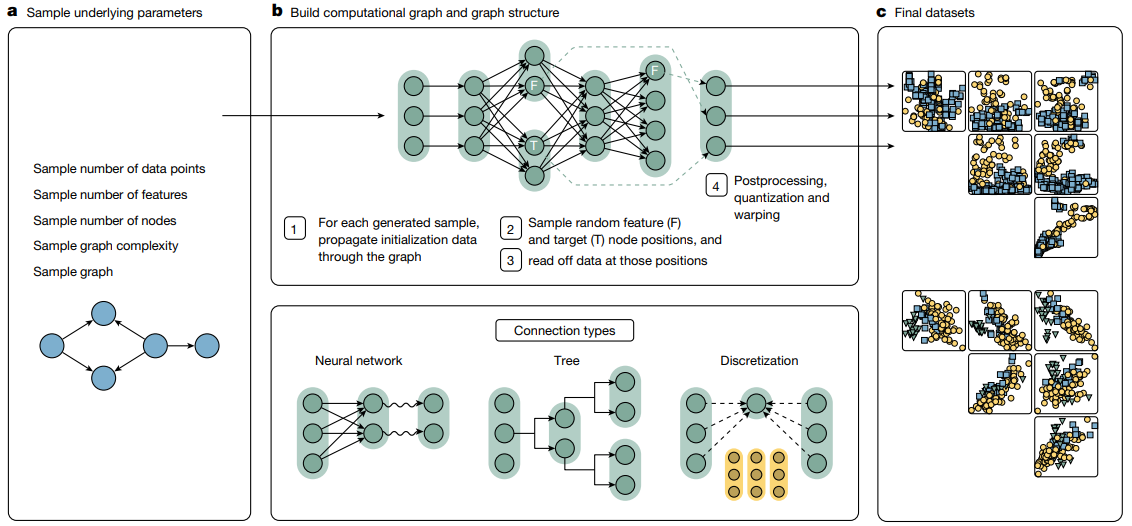
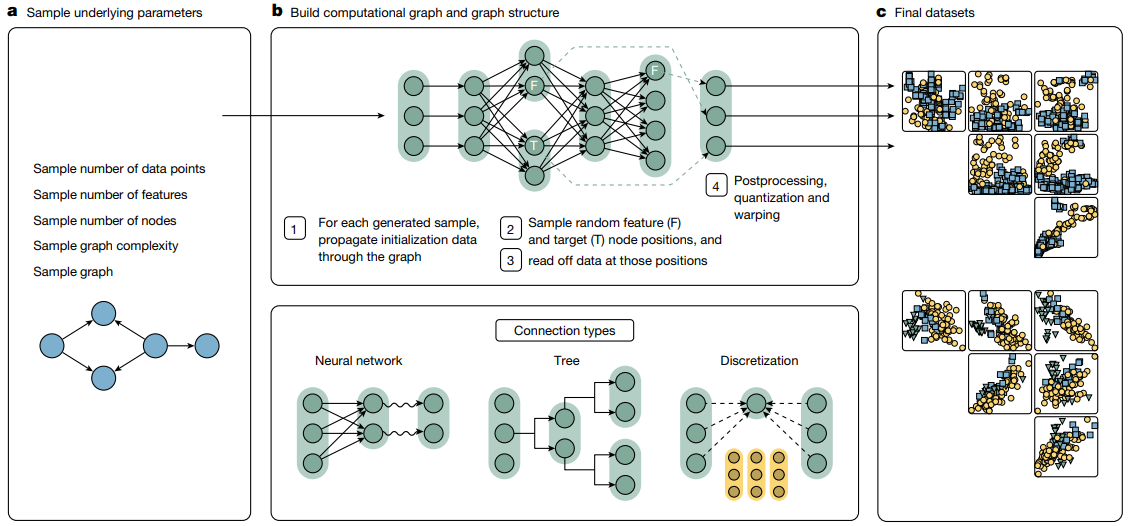
a. 각 데이터 셋 마다, 먼저 상위 수준의 hyuperparameters 를 샘플링.
- 기본 파라미터들을 샘플링.
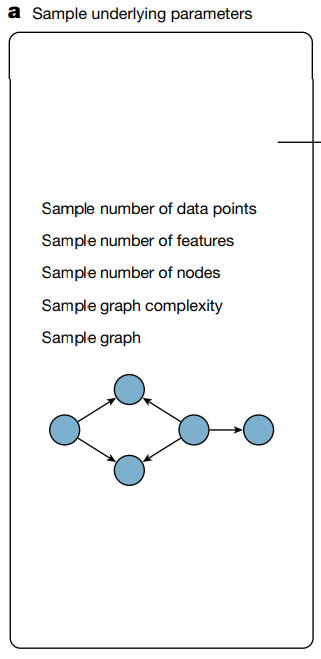
- data point 의 개수를 샘플링.
- features 의 개수를 샘플링. (Feature node 중 sampling)
- nodes 의 개수를 샘플링. (Feature node, Target node,Hidden node) 까지 존재.
- graph 의 복잡도를 샘플링.
- graph 를 샘플링.
edge: 어떤 node 값이 어떤 node 값을 만드는데 입력으로 들어가는지 결정.Sample graph complexity 에서 일단 홀딩. SCM 내용 부터 이해 후에 다시..
b. 이 hyuperparameter 들을 바탕으로,
-
계산 graph 와 graph 구조를 build 한다.
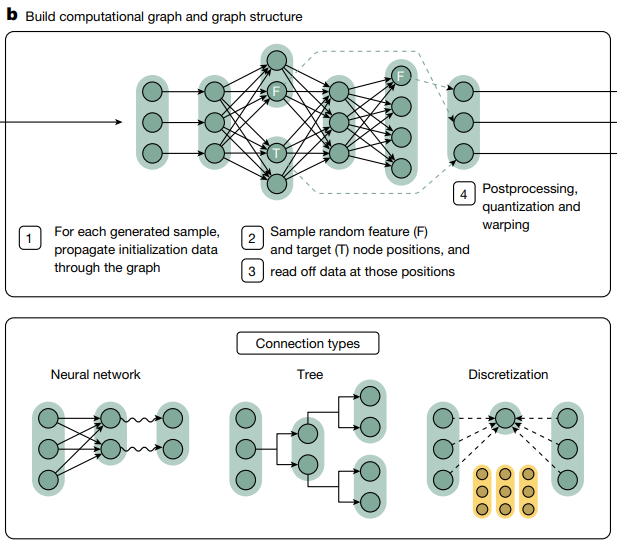
- 샘플 하나를 만들 때마다, initialization data 를 graph 에 전파하여 (흘려보내며) node 값 들을 계산.
- feature (F) 와 target (T) 노드 위치를 random 하게 샘플링.
- 그 위치에서 데이터를 읽음.
- 후처리를 quantization 하고 warping 한다.
- edge 를 연결해주는 connection types : NN(linear layer), 트리구조(rule based), 이산화구조(categrical).
Linear
MLP
Categorical
-
데이터 셋을 생성하는 계산 함수를 encode 하는 structual causal model (SCM) 을 구성.
-
각 node 는 하나의 vector 를 가지고, computational graph 에서 각 edge 는 연결 유형 중 하나에 따라 정해진 함수를 구현.
-
각 단계(Step) 별 과정.
Step 1)random noise 변수들로 initialization data 를 생성, 이것을 그래프의 root node 에 넣어서 생성될 각 샘플에 대해서 computational graph 를 통해 전파.Step 2)graph 에서 feature (labelledF) 와 target node (targetT) 위치를 무작위로 샘플링.Step 3)샘플링된 feature 와 traget 의 node 위치에서 중간 데이터 표현 (intermediate representations) 를 추출.Step 4)추출 데이터를 후처리 (post-process).
c. 최종 데이터 셋을 가저옴.
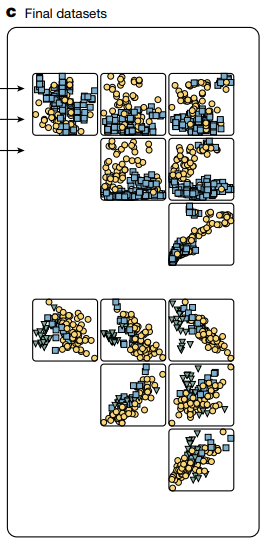
- feature 쌍 들의 상호작용을 그래프로 나타내고, node 색상은 sample 의 class 를 나타낸다.
- 기본 파라미터들을 샘플링.
Data generation :
- generative process 를 정의하는데 (our prior) 이 prior 를 이용.
- features 와 target 사이의 관계가 다양하게 달라지는 여러 형태의 tabular data set 을 만듬.
- 이 데이터 셋은 모델이 마주칠 수 있는 광범위한 잠재적 시나리오를 포착하도록 설계.
- 생성 과정에서 수백만 개의 데이터 셋을 샘플링.
- 각 데이터 셋 마다 샘플들의 subset 의 목표값을 마스킹하여,
- supervised prediction 문제를 시뮬레이션 함.
- missing value 또한 random 하게 mask 를 통해 고려해준다.
prior 설계에 대한 내용은 "Synthetic data based on causal models" 섹션에 나와 있다.`
Pre-training :
- transformer model 인 PFN 을 학습시켜서,
- input feature 와 unmasked (label 이 보이는) 한 sample 들이 context 로 주었을 때,
- 모든 합성 데이터셋에서 마스킹된 타겟 를 예측 하도록 함.
- 이 단계에서는 모델 개발을 하는 동안, 한번만 수행되며,
- 모든 데이터 셋을 예측하는 데 사용할 수 있는 범용적인 학습 알고리즘 을 학습.
Real-world prediction
- 그렇게 학습된 최종 모델은 이제 임의의 미공개된 real-world set 에서도 적용 가능.
- training sample 은 모델의 컨텍스트 로써 제공되며,
- 모델은 ICL 을 통해 이러한 미공개된 데이터 셋의 label 들을 예측.
접근 방식은 이론적인 기반을 가지고 있음
합성 데이터 셋으로 정의된 prior 에 대한 approximating Bayesian prediction 으로 볼 수 있음. 훈련된 PFN 은 posterior predictive distribution 인
를 approximate 하고, 따라서 PFN pre-training 하는 동안 사용된 인공 (artificial) 데이터 셋 분포에 대해 지정된 분포 하에서의 Bayesian prediction 을 반환.
An architecture designed for tables
- Transformer model
- flexible deep learning 과 foundation models 의 구조
- sequence 기반으로 동작
- attention 메커니즘을 사용하여 sequence 항목간의 정보를 결합
- long-range 의존성을 효과적으로 capture
- data 의 복잡한 관계성을 학습
Transformer 기반의 모델은 sequence tokens 를 입력 받아서 attention 으로 항목 간 정보를 결합하여 long-range 의존성과 복잡한 관계를 잘 학습. tabular data 에 적용 될 수 있지만, TabPFN 은 두 가지 주요 한계를 해결.
-
transformer 는 sequence 를 위해 설계되어서, input data 를 tabular structure 가 아닌 single sequence 로 처리.
-
ML 모델들은 fit-predict 모델들로 사용되는데, Transformer 는 traning set 에 한번 fitted 된 후, 여러 test set 에 재사용.
Transformer 기반의 ICL (In Context Learning) 알고리즘은
- single pass 로 train 과 test 를 입력 받아 train 과 test 를 동시에 수행.
- fit 된 모델을 재사용할 경우, training set 을 다시 계산.tabular structure 를 더 효과적으로 활용하기 위해서, table 의 각 셀에 별도의 representation 을 할당하는 architectur 를 제안.
-
양 방향 (two-way) attention 메커니즘을 사용
- 해당 행 (즉, 각 sample) 의 각 features 를 attending
- 해당 열 (즉, 모든 다른 sample) 의 동일한 features 에 attending
-
architecture 특징
- sample 과 features 의 순서에 관계 없이 결과가 같은 architecture 가 되게 함.
- 따라서, sample 과 features 의 개수 측면에서 훈련 중 만나는 table 보다 더 큰 table 적용 가능.
- training 및 extrapolation (관찰 범위 바깥의 값을 추정) 할때, 더 효율적 수행 가능.
-
algorithm optimization
- fit-predict 설정에서 각 test sample 에 대한 training set 에서 반복적인 계산을 줄이기 위해, training 과 test 샘플에 대한 추론을 분리 가능
- training sample 의 표현 방식은 test set 에 영향을 받지 않으므로, training 과 inference 를 분리할 수 있도록 training sample 의 key 와 value 를 cache 함.

- 이를 통해 training set 에 대해서 한 번만 ICL 을 수행하고, 결과 상태를 저장 후, multiple test set 추론에 재사용 가능.
KV cache 를 잘 이용했다고 볼 수 있다.
- LLM 의 KV Cache 는 이전 token 의 KV 인데, TabPFN 의 KV Cache 는 Training set 의 KV.
- LLM 은 첫 토큰 생성 시에 캐시가 생긴다면, TabPFN 은 fit() 시 한 번 생김
- LLM 은 다음 토큰 생성시 재사용 되는데, TabPFN 은 predict() 시 재사용 된다.
- LLM 은 점진적으로 증가하는 sequence 인 반면, TabPFN 은 고정된 training set.
- LLM 은 Autoregressive generation 에 최적화라면 TabPFN 은 Training set representation 의 재사용.
-
cumpute, memory optimization
- 10,000 개의 training sample 과 10 개의 features 를 가진 데이터셋 에서, 최적화된 train-state caching 은 추론 속도를 CPU 에서 300x (32s 0.1s), GPU 에서 6x 향상.
- features 가 10x (100개) 늘려 사용하면 추론 속도를 CPU 에서 800x, GPU 에서 30배 향상.
- GPU 에서 속도 향상이 낮은 이유는, GPU 의 대규모 병렬 구조를 제대로 활용하지 못했기 때문.
솔직하게 말하네.
- 이 측정 값은 pre-processing 과 ensembling 단계를 제외한, 추론 과정에만 초점을 맞추고 있으며, 자세한 단계는
inference details에 설명.
-
flash attention, activation checkpointing 과 상태를 순차적으로 계산하는 방법을 사용
- layer norm 을 half-precision(FP16/BF16) 으로 계산
- architecture 의 memory 와 연산 요구량을 더 최적화
-
최적화를 통해 메모리 요구량을 4배로 줄여서 cell 당 1000 byte 미만의 메모리만 필요하게 만듬.
-
결과적으로, 단일 H100 GPU 에서 최대 50 million 셀을 가진 데이터셋 (예: 5 million row, 10 features) 에 대해서도 예측을 수행 가능.
-
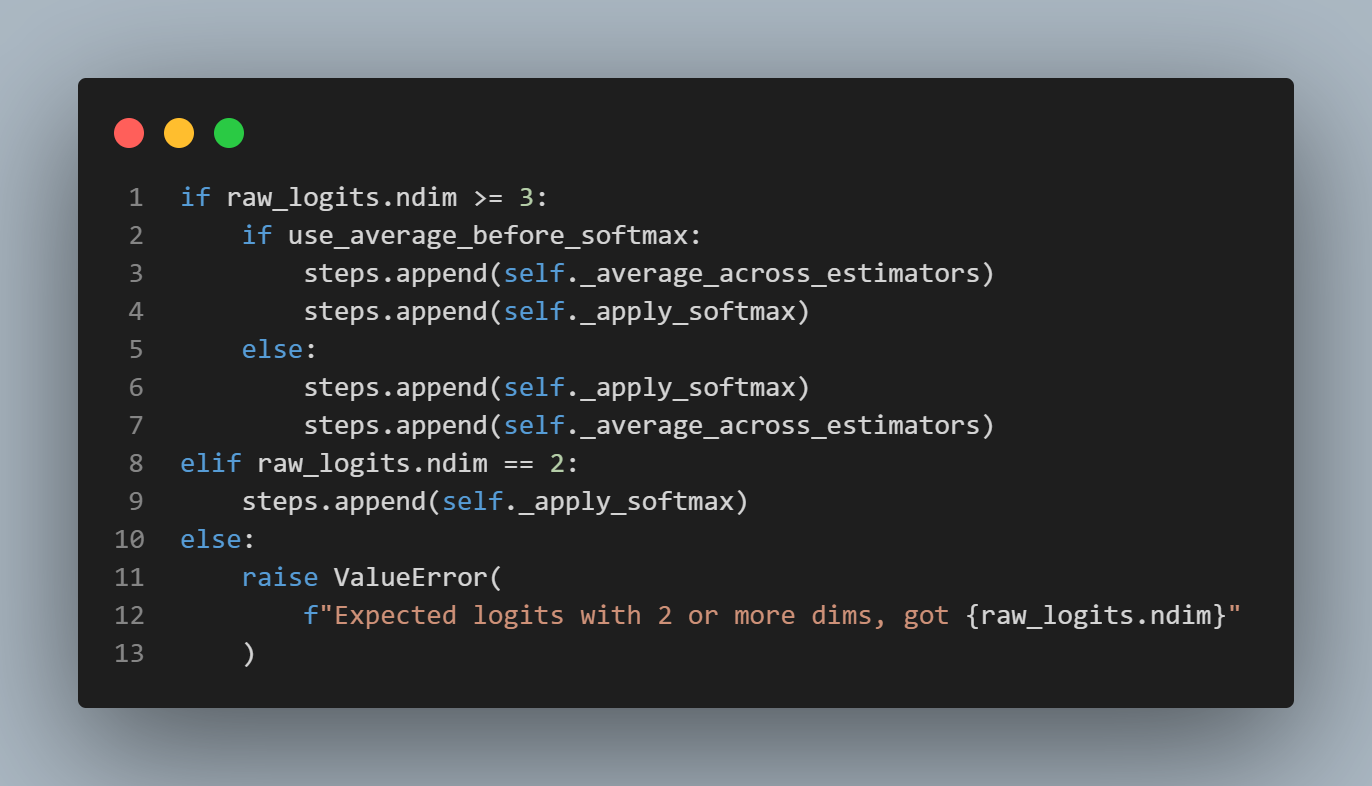
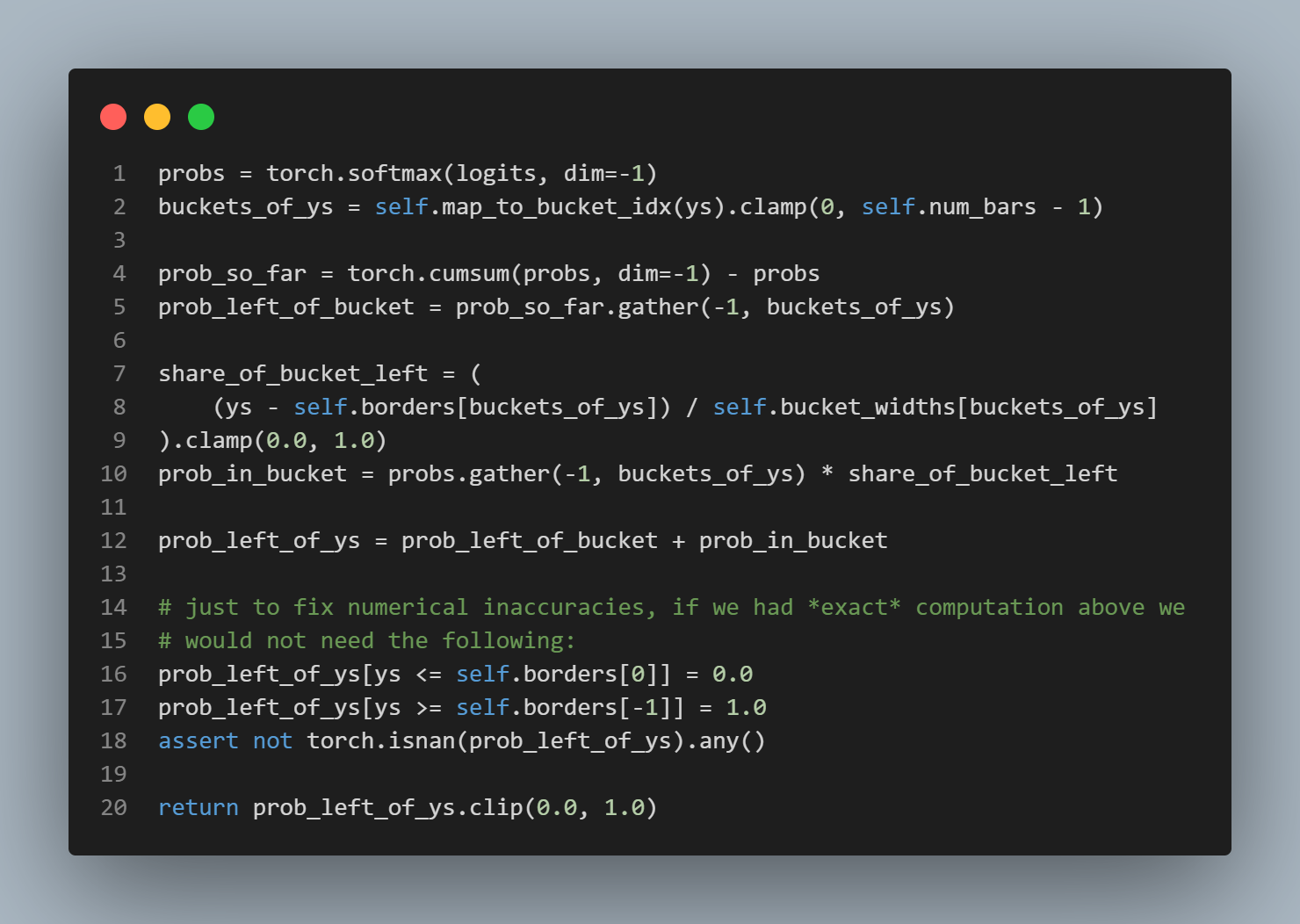
regression tasks 의 경우, piece-wise(구간 별) 상수 출력 분포를 사용, 이를 통해서 단일 값이 아닌 목표의 분포를 예측 할 수 있다.
classifier일 경우softmax(logits)로 확률 분포 변환
regression일 경우 bucket 확률 분포로 변환
이렇게 결과를 분포로 뽑아내는걸 생각을 못했어. 사실 Prior 라고 하고 Attention 이 들어가서 내 개인적인 사고방식이 틀에 박혀있었어.
Synthetic data based on causal models
- TabPFN 의 성능은 real-world tabular data 의 특성과 어려움(도전 과제) 를 잘 캡처한 적절한 합성 훈련 데이터 셋을 생성하는 데에 달려 있음.
- 데이터 셋을 생성하기 위해서 structural causal models (SCMs) 에 기반한 접근 방식을 개발.
- SCMs 는 data 에 내제된 causal relationships 와 generative 과정을 표현하기 위한 공식적인 framework 을 제공.
- 대규모 공개 tabular data 모음 대신, 합성 데이터에 의존함으로써, 개인 정보 및 저작권 침해, 훈련 데이터에 테스트 데이터가 섞이는 오염, 데이터 가용성 제한과 같은 foundational models 의 일반적인 문제를 피함.
- generative pipeline 은 먼저 데이터 셋의 크기, 특징의 개수, 그리고 난이도와 같은 high-level 의 hyperparameters 를 샘플링하여 각 합성 데이터셋의 전반적인 속성을 제어.
Step
1.PerFeatureTransformer에서data_dags파라미터로 DAG (Directed Acyclic Graph) 를 받는다.
2.feature와target속성으로 변수 역할 구분
3.feature와target로 실제 feature/target index mapping
4. DAG 의 Laplacian 행렬을 사용해서 positional encoding 을 생성'LM' : Largest (in magnitude) eigenvalues. 'SM' : Smallest (in magnitude) eigenvalues. 'LA' : Largest (algebraic) eigenvalues. 'SA' : Smallest (algebraic) eigenvalues. 'BE' : Half (k/2) from each end of the spectrum.
L = nx.directed_laplacian_matrix(graph)이용[[ 0.99 -0.148081 -0.262168 -0.01 -0.259042] [-0.148081 0.99 -0.483378 -0.010095 -0.135017] [-0.262168 -0.483378 0.8 -0.163355 -0.200388] [-0.01 -0.010095 -0.163355 0.99 -0.469376] [-0.259042 -0.135017 -0.200388 -0.469376 0.8 ]]
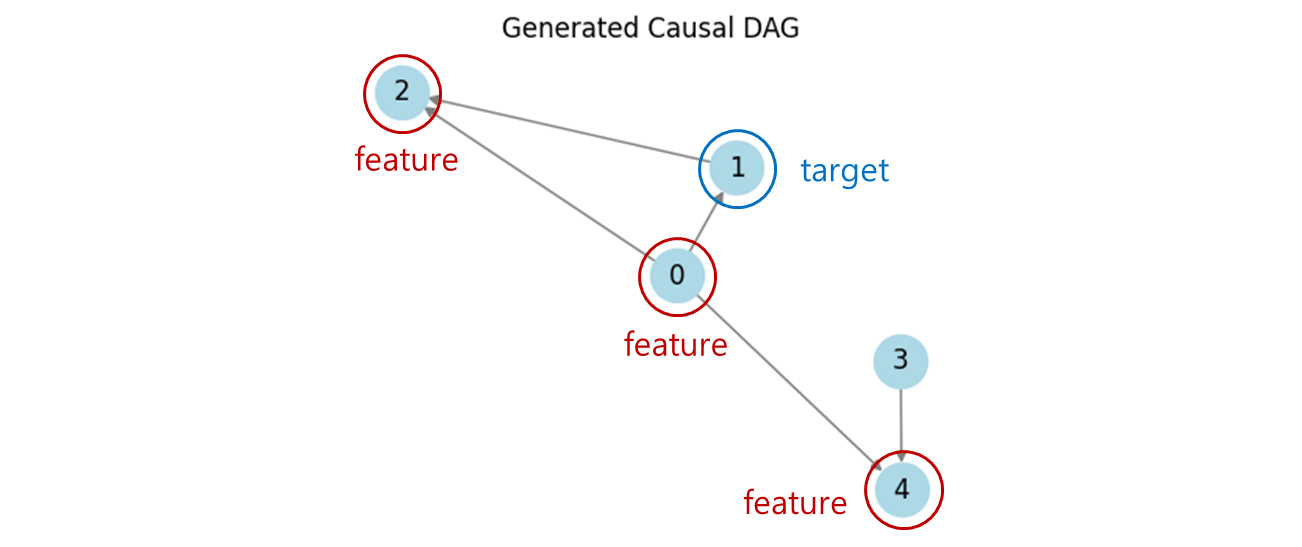
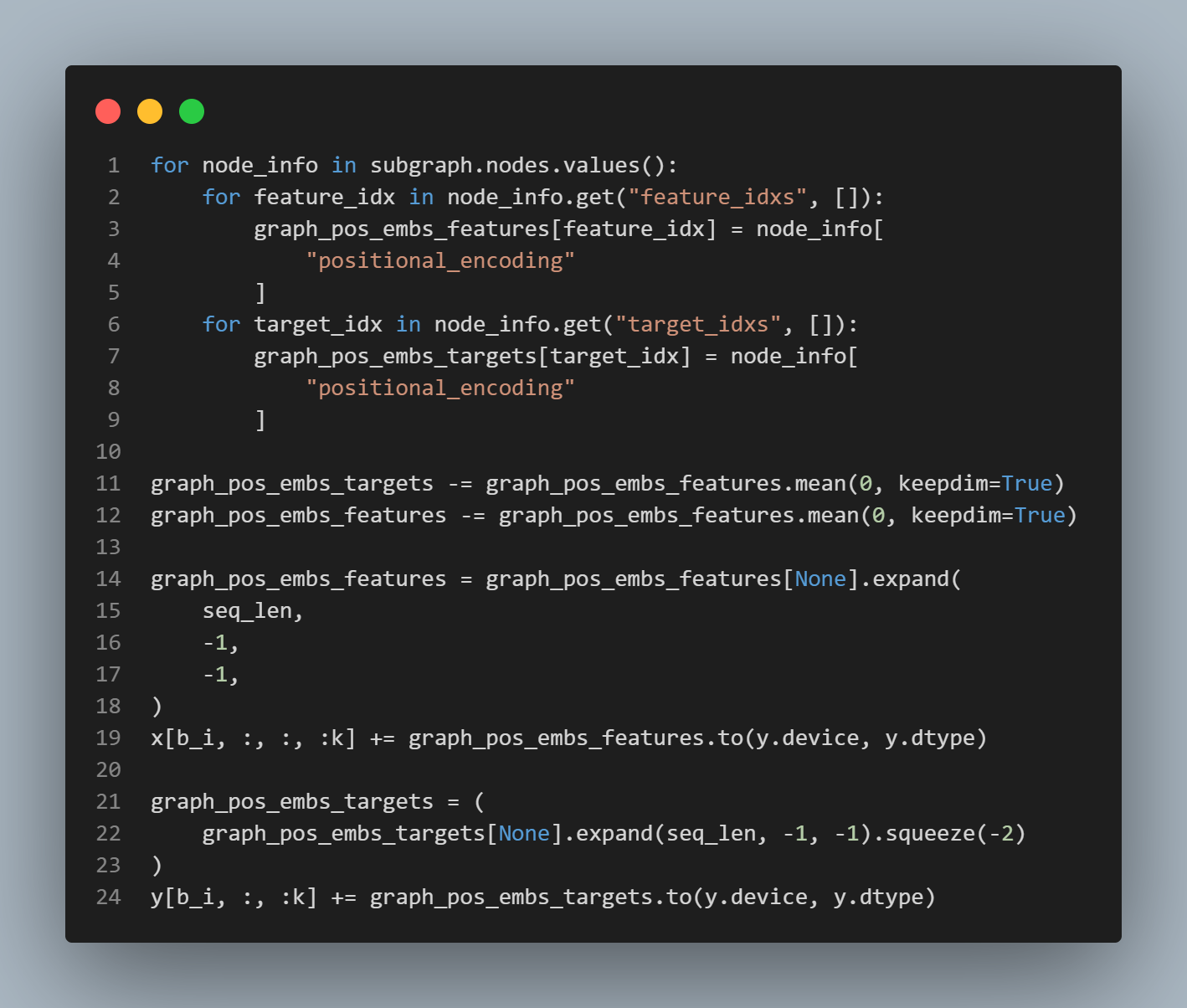
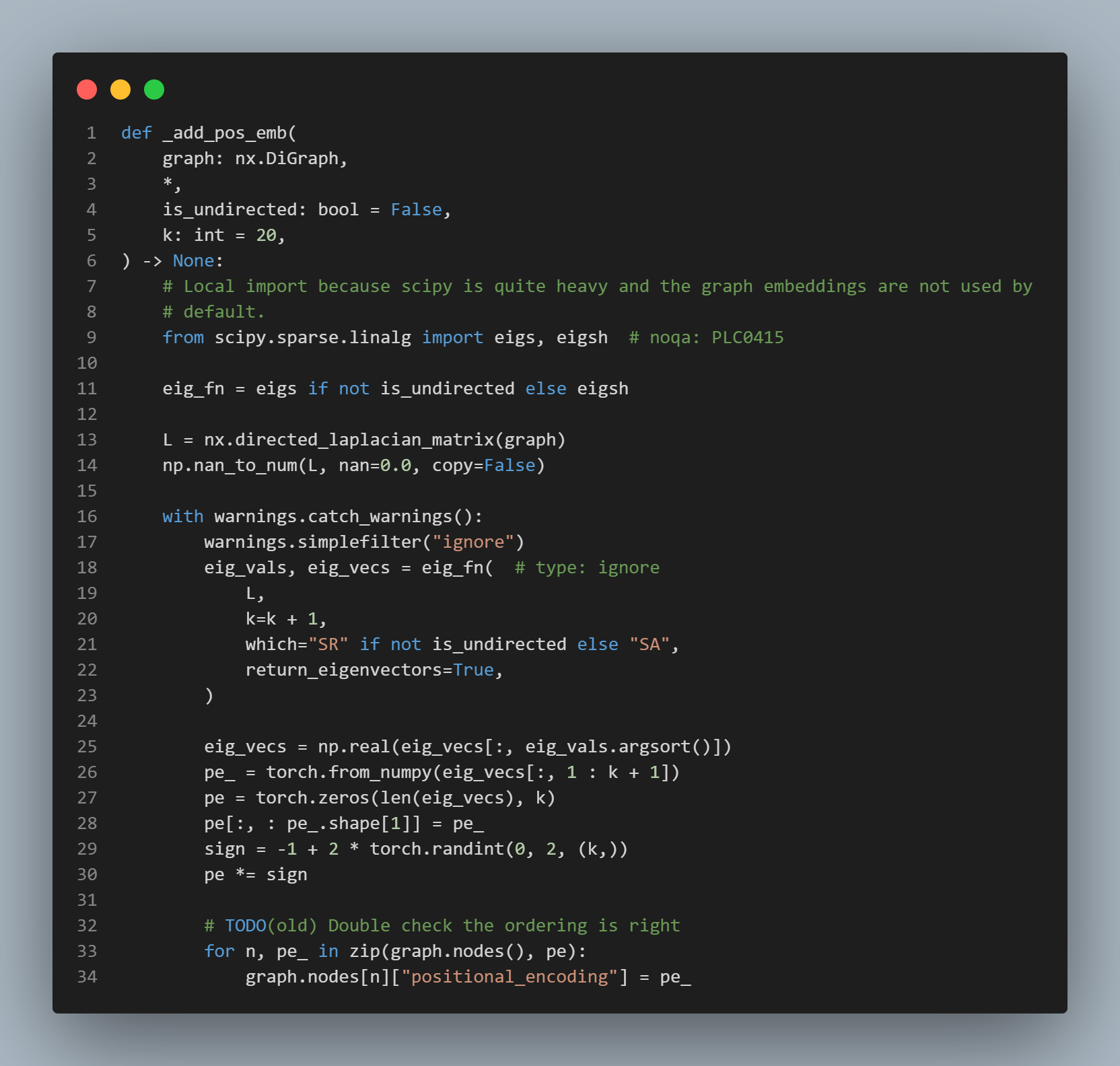
이러한 hyperparameter 를 기준으로 데이터 셋의 기반이 되는 causal structure 를 규정하는 방향성 비순환 그래프 (DAG) 를 구성.
- dataset 내의 각 샘플을 생성하기 위해서 initialization data 라고 불리는 random 생성 노이즈를 causal graph 의 root node 를 통해 전파.
- 초기화 데이터는 random normal 과 uniform 분포 에서 샘플링하여 생성.
- sample 들 사이에 비 독립성 (독립적이지 않은 정도) 이 다양한 정도 (varying degree) 로 나타남.
Initialization data sampling참고. - 데이터들이 computational graph 의 edge 를 따라 이동하는 동안, 다양한 계산 맵핑을 적용
Example >- 선형 혹은 비선형 activation function (sigmoid, ReLU, modulo, sine) 를 사용하는 작은 neural network.
- categorical features 를 생성하기 위한 이산화 메커니즘.
- 국소적(local), rule-based 의존성을 인코딩 하기 위한 decision tree 구조가 포함.
- 각 edge 에서 Gaussian noise 를 추가하여 생성된 data 에 불확실성을 도입.
- 각 노드에서의 중간 데이터 표현을 저장.
Computational edge mappings참고. - causal graph 를 탐색한 후, 샘플 된 feature 와 target node 에서 중간 표현을 추출하여 feature value 와 연관된 target value 로 구성된 샘플을 얻음.
- 다양한 데이터상의 어려움과 복잡성을 합성 데이터 셋에 통합함으로써, TabPFN 이 real-world 데이터 셋에서 유사한 이슈를 처리하는 전략을 개발할 수 있도록
training ground(학습 환경) 을 조성.
- 예를 들어 tabular data 에서 흔히 나타나는 missing values 를 생각.
- 합성 데이터 생성 과정에서 missing values 의 패턴과 비율이
- 서로 다양한 합성 데이터셋 들을 TabPFN 에 노출 시킴으로써,
- 모델이 real-world dataset 에서도 일반화 되는(통하는) missing value 처리 방법을 효과적인 방법으로 학습하게 됨.
- post-processing 기법을 적용하여, 현실감을 향상 시키고, 학습된 예측 알고리즘의 robustness 를 검증.
- 이러한 기법에는 Kumaraswamy 분포를 이용한 warping, 복잡한 선형 왜곡 도입, 이산화된 특성을 흉내내는 quantization 이 포함.
이러한 생성 과정을 통해 모델 학습 1회당 약 100 million 개 규모의 방대한 합성 데이터셋 corpus 를 만들었으며, 각 데이터셋은 서로 다른 (고유한) causal structure, 특성 (feature) 타입, 그리고 함수적 특성을 가진다.
Post-processing섹션 참고.
conclusion
TabPFN 은 ICL (In Context Learning) 을 활용
최대 10,000 개의 sample 과 500 개의 feature 를 가진 데이터 셋에서
전통적으로 사람이 설계한 접근들 (방식들) 보다
매우 효율적인 알고리즘을 자율적으로 (autonomously) 발견함으로써,
tabular data 모델링에 중대한 변화를 가져왔다.synthetic data (합성 데이터) 를 기반으로 한 foundation model 로의 전환은 다양한 분야에서 tabular data 분석을 위한 새로운 가능성을 열어주었다.
-
Potential future directions
- 더 큰 data set 으로 확장
- data drift handling
- tabular data 작업들과 관계된 fine-tuning 기능 조사
- 이러한 접근의 이론적 기반 이해
-
Future work
- 시계열 및 multi-modal 과 같은 데이터 유형을 다루기 위한,
- ECG(심전도), neuroimaging (신경영상), genetic(유전) 데이터처럼 특정 modalities 에 맞춘,
- 특화된 prior 를 만드는 방향
tabular data 모델링 분야가 계속 발점함에 따라서 TabPFN 과 같은 foundation model 이 연구자들의 역량을 강화하는데 중요한 역할을 할 것.
Ref.
- paper : Accurate predictions on small data with a tabular foundation model
- DSBA Seminar 자료
