내가 해보고 싶었던 것은, vectorDB 를 이용하면서 LLM 모델을 사용하는 것.
data
- 데이터는 일단 대화를 하기 위한 Query-Answer 의 데이터를 찾았다.
- 정형 데이터를 넣는 예시도 있지만, 이건 사실 RDB 가 맞고, sentence, image, sound 등 의 high dimensional data 를 embedding vector 로 만드는 것이 맞다고 생각 하였다.
sentence 로 꽤 괜찮은 Query-Answer 데이터가 있다.
KoAlpaca-v1.1a
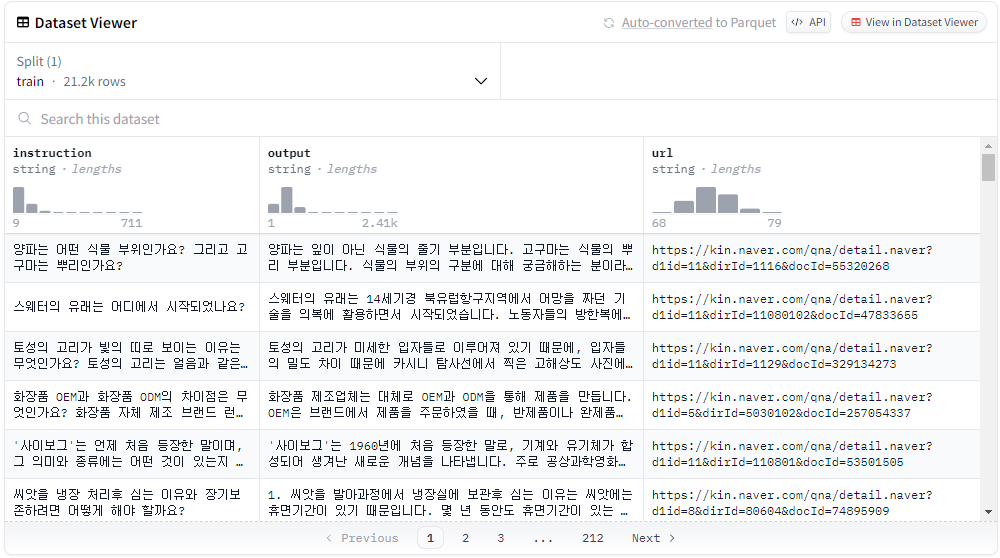
이렇게 구성된 데이터 이고, 근거 자료 까지 잘 나와 있다.
import pandas as pd
from datasets import load_dataset
DATA_SET = "beomi/KoAlpaca-v1.1a"
DATA_FILE = "./data/KoAlpaca-train.csv"
load_data = load_dataset(DATA_SET, split="train")
load_data.to_csv(DATA_FILE)
csv_data = pd.read_csv(DATA_FILE)
csv_data.sample(5)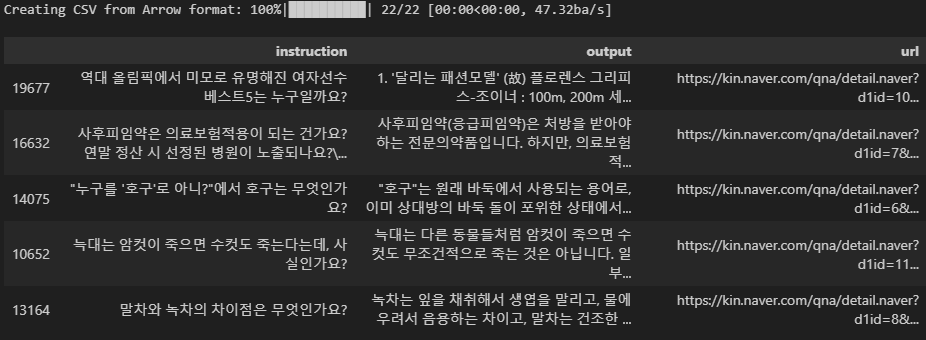
vector-db 에 넣고 조회할 데이터가 준비 되었다.
요새는 사용하는 framework, library, db 들이 더욱 다양해졌고, 선택의 폭이 넓어졌는데 대신 기능들도 각자 비교해야 하고, 개발은 쉬워졌다. 확실히 개발보다 데이터 영역이 커보인다.
vector-db
vector-db 를 둘 중 고민했는데,
실제로 vector-db 를 현재는 간단하게 사용할 예정이라 chromadb 를 선택하였다. 굉장히 가볍게 보였고, 만약 사이즈가 커지고 서비스 레벨로 간다면 faiss 급으로 고려해볼만 하겠지만, 현재 준비하는 사이즈는 가벼운 chromadb 가 낮다고 판단, PersistentClient 를 하면 데이터를 file 에 저장하여 file db 인 sqlite 를 사용하던데.. 참고하면 된다.
embedding model
무슨 model 로 선택할 지도 human parameter 가 되는 세상이다.
bespin-global/klue-sroberta-base-continue-learning-by-mnr 사용 예정
다른 더 괜찮은 모델이 있다면 바꿔서 하면 될듯, 실제 openai embedding 이 좋다는 말은 들었지만, 최대한 안쓰는 방향으로 해볼 예정이다. 데이터를 넣는 것도 찜찜한건 덤이기도..
from tqdm import tqdm
EMBEDDING_MODEL = "bespin-global/klue-sroberta-base-continue-learning-by-mnr"
# model load
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
model_name_or_path=EMBEDDING_MODEL
)
data code
참고 url : https://docs.trychroma.com/usage-guide#adding-data-to-a-collection
data 를 아래 형식처럼 준비.
collection.add(
documents=["doc1", "doc2", "doc3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"},
{"chapter": "3", "verse": "5"},
{"chapter": "29", "verse": "11"}, ...],
ids=["id1", "id2", "id3", ...]
)- query 로 질의할 예정,
- query
instruction을 선택된 모델로 encoding 한 후 embedding list 에 저장, - query-answer
instruction-output은 metadata 에 두고, - reference
url은 uri 에 저장한다. - encoding 시간이 역시 좀 걸린다.
# ready for data
# order : index, embedding, metadata, document, uri
ids = list()
embeddings = list()
metadatas = list()
for row in tqdm(csv_data.iterrows()):
index = row[0]
instruction = row[1].instruction
output = row[1].output
url = row[1].url
embedding = model.encode(instruction, normalize_embeddings=True)
metadata = {
"query": instruction,
"answer": output,
"url": url
}
ids.append(str(index))
embeddings.append(embedding)
metadatas.append(metadata)chromadb
create
- collection 생성
CHROMADB_PATH = "./storage"
COLLECTION_NAME = "koalpaca_data"
DISTANCE_METHOD = "l2"
import chromadb
chroma_client = chromadb.PersistentClient(
path=CHROMADB_PATH
)
collection = chroma_client.create_collection(
name=COLLECTION_NAME,
metadata={"hnsw:space": DISTANCE_METHOD}
)-
추가로 킵 할 내용.
hnsw:space
Hierarchical Navigable Small Worlds
paper : https://arxiv.org/abs/1603.09320
code : https://github.com/nmslib/hnswlib
ip and cosine are numerically unstable in HNSW.
The higher the dimensionality, the more noise is introduced, since each float element of the
vector has noise added, which is then subsequently included in all normalization calculations.
This means that higher dimensions will have more noise, and thus more error.생각해보면, vectorDB 이므로 두 vector 의 distance 를 구할 때,
l2는 각 요소의 거리를 뺀 합은 거리에 대한 정보를 가지고 핸들링 하지만,- cosine similarity 가 어떤 의미 인지는 알겠으나..
inner-product는 조회 되는 vector 도 1차원 vector 일 것인데, 을 하면 거리 정보 없이 그냥 위치 정보만 가지고 곱하고 더하므로 정보 너무 잃어 버릴듯,
-higher the dimensionality일 때 문제가 더욱 생길 가능성이 높아 보인다.- 기본적으로 높은 차원인 문장 처리를 할 때는
l2를 사용.
insert
- chromadb 에 넣는 로직. chunk size 로 분할해서 넣는다.
- 넣는 것은 시간이 얼마 걸리지 않는다.
# set the size to save once
CHUNK_SIZE = 4096
total_index = len(embeddings) // CHUNK_SIZE + 1
# convert numpy arrary to list
embeddings = [ embedding.tolist() for embedding in tqdm(embeddings) ]
for index in tqdm(range(total_index)):
# set 'start' and 'end' index
start_idx = index * CHUNK_SIZE
end_idx = (index + 1) * CHUNK_SIZE
# save data from selected indexes
chunk_ids = ids[start_idx:end_idx]
chunk_embeddings = embeddings[start_idx:end_idx]
chunk_metadatas = metadatas[start_idx:end_idx]
# add chunk data in collection
collection.add(
ids=chunk_ids,
embeddings=chunk_embeddings,
metadatas=chunk_metadatas,
)-
조심할 부분이
collection.add에서uris: The uris of the images to associate with the embeddings. Optional.인데, images 와 관계 없으면 uris 에 데이터가 들어가지 않는다. 코드를 보면
elif images is not None: embeddings = self._embed(input=images) else: if uris is None: raise ValueError( "You must provide either embeddings, documents, images, or uris." ) if self._data_loader is None: raise ValueError( "You must set a data loader on the collection if loading from URIs." ) embeddings = self._embed(self._data_loader(uris))과 같이 images 에 데이터가 없으면, urls 에 데이터가 들어가지 않는다. 왜 조심해야 하냐면, image 가 아닌 document, text 들 또한 url 이 있어 보였다. 이렇게 종속 되는 데이터는 같은 level 이 아닌 하위 level 로 데이터를 따로 수집해야 맞다고 본다.
delete
이렇게 지우면 collection 을 지우는 것.
chroma_client.delete_collection(
name="koalpaca_data"
)다시 collection 을 생성해야 한다.
select
from pprint import pprint
result = collection.query(
query_embeddings=model.encode
(
"OPEC+, OPEC 차이는?",
normalize_embeddings=True
).tolist(),
n_results=2
)
pprint(result)- result
distence로 2개를 고른다.
{'data': None,
'distances': [[0.0, 0.722766637802124]],
'documents': [[None, None]],
'embeddings': None,
'ids': [['0', '6647']],
'metadatas': [[{'answer': '양파는 잎이 아닌 식물의 줄기 부분입니다. 고구마는 식물의 뿌리 부분입니다. \n'
'\n'
'식물의 부위의 구분에 대해 궁금해하는 분이라면 분명 이 질문에 대한 답을 찾고 있을 '
'것입니다. 양파는 잎이 아닌 줄기 부분입니다. 고구마는 다른 질문과 답변에서 언급된 것과 '
'같이 뿌리 부분입니다. 따라서, 양파는 식물의 줄기 부분이 되고, 고구마는 식물의 뿌리 '
'부분입니다.\n'
'\n'
' 덧붙이는 답변: 고구마 줄기도 볶아먹을 수 있나요? \n'
'\n'
'고구마 줄기도 식용으로 볶아먹을 수 있습니다. 하지만 줄기 뿐만 아니라, 잎, 씨, '
'뿌리까지 모든 부위가 식용으로 활용되기도 합니다. 다만, 한국에서는 일반적으로 뿌리 부분인 '
'고구마를 주로 먹습니다.',
'query': '양파는 어떤 식물 부위인가요? 그리고 고구마는 뿌리인가요?'},
{'answer': '양파는 비싼 약보다 더 좋은 다양한 약효를 지닌 상미식 품입니다. 심지어 하루 반 개씩 '
'먹으면 각종 암 예방, 고혈압, 당뇨병, 간장병, 위장병, 피부병 등 다양한 건강효과를 볼 '
'수 있습니다. 이 외에도 혈액순환이 좋아지고 산소와 영양의 공급이 원활해지며, 간의 해독 '
'작용도 합니다. 또한 근육통이나 어깨결림, 신경통에도 치료 효과가 있습니다. 하지만 '
'양파껍질로 피부 관리를 하는 것은 추천되지 않으며, 양파를 생으로 먹거나 양파즙 파스를 '
'만드는 것이 좋습니다.',
'query': '양파는 몸에 좋은가요?\n'
'채소로도 쓰이며, 약으로도 쓰이는 양파가 몸에 좋은 영향을 미치는지 궁금합니다. 답변 '
'부탁드립니다.'}]],
'uris': None}Ollama
llm model download
작업 환경 : Windows 11
작업 폴더 위치 : project\ollama
모델 저장 위치 : project\ollama\EEVE-KOREAN-Instruct-10.8B-v1.0-GGUF
> pip install huggingface-hub
> huggingface-cli download heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF ggml-model-Q5_K_M.gguf --local-dir ./EEVE-KOREAN-Instruct-10.8B-v1.0-GGUF --local-dir-use-symlinks False
Ollama
ollama 에서 gguf 파일을 변환을 해서 올려줘야 하는데, 그때 필요한 것이 Modelfile
Modelfile
FROM ggml-model-Q5_K_M.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER stop <s>
PARAMETER stop </s>이 Modelfile 은 각각의 모델마다 template 이라는 것이 있다. instructor 학습을 할 적에 쓰는 template 이 좀 다르다. 이것은 ollama 에서 지정한 문법이다.
-
설명
{{- if .System }} <s>{{ .System }}</s>System prompt 가 있다면 System 을 출력하라.
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""System prompt 를 넣어주고, 조건문을 수행핳면 System prompt 를 지정했으므로 이것이 치환 되서 들어갈 것이다.
<s>Human: {{ .Prompt }}</s>그리고 사용자가 질문을 하게 되면, 스페셜 토큰이 앞에 붙어서 그 다음에 질문을 날리면 부분에 들어가게 된다. 여기서 한 번 끝나게 되고,
<s>Assistant:다음으로 어시스턴트가 “:” 로 끝났다. 그러면 이제 모델이 받아서 답변을 주게 된다.
이와 같이 template 를 정확하게 하는 경우와 그렇지 않응ㄴ 경우가 굉장히 크기 때문에 이것은 template 는 꼭 확인을 하고, 모델 별로 template 을 확인한 다음에 넣는 것이 좋다.
현재 사용할 model 은
Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models
모델이며,
template를 보려면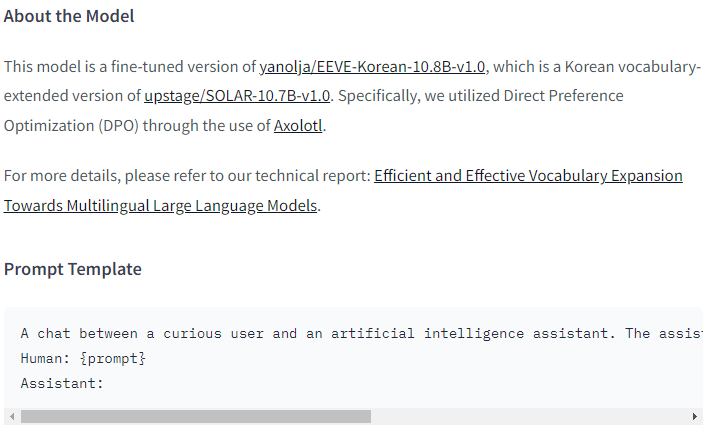
이것을 보고 넣어주면 된다. template 에 대한 문법에 대해 궁금하면 ollama 의 공식 사이트에 보면 친절하게 나와있다.
Ollama 에서 windows 를 다운 받고 설치한다.
set model with Ollama
-
명령어 확인
\project\ollama> ollama Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model pull Pull a model from a registry push Push a model to a registry list List models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama [command] --help" for more information about a command. \project\ollama> ollama list NAME ID SIZE MODIFIED -
ollama create, 생성.
ollama create EEVE-Korean-10.8B -f EEVE-Korean-Instruct-10.8B-v1.0-GGUF/Modelfile \project\ollama> ollama create EEVE-Korean-10.8B -f EEVE-Korean-Instruct-10.8B-v1.0-GGUF/Modelfile 2024/04/15 18:46:34 parser.go:73: WARN Unknown command: TEMPERATURE transferring model data creating model layer creating template layer creating system layer creating parameters layer creating config layer using already created layer sha256:b9e3d1ad5e8aa6db09610d4051820f06a5257b7d7f0b06c00630e376abcfa4c1 writing layer sha256:6fe7ed0d1aa9d7d4f3b6397184caf17b9b558739bc00f5abde876ee579fbf51a writing layer sha256:1fa69e2371b762d1882b0bd98d284f312a36c27add732016e12e52586f98a9f5 writing layer sha256:fc44d47f7d5a1b793ab68b54cdba0102140bd358739e9d78df4abf18432fb3ea writing layer sha256:6dfba5058d8d9a7829a8f0617f2e10c71fb928f150acfe99ee714384034b1020 writing manifest success \project\ollama> ollama list NAME ID SIZE MODIFIED EEVE-Korean-10.8B:latest acb55eed16e7 7.7 GB About a minute agoollama create은 기본 default 명령어. 낸가 어떤 모델명을 지정할 지, latest 로 지정한 것이 이름.-f 는 파일을 지정.
EEVE-Korean-Instruct-10.8B-v1.0-GGUF에 들어있는Modelfile을 지정. -
ollama run (만든 모델의 이름) 이 될건데, 실행.
project\ollama> ollama run EEVE-Korean-10.8B:latest >>> 대한민국의 수도는 어디야? 안녕하세요! 대한민국의 수도에 대해 궁금하신 점을 도와드리겠습니다. 서울은 공식적으로 대한민국 서울특별시(Seoul Special Metropolitan City)로, 한반도 북부에 위치한 도시입니다. 서울은 나라의 정치, 경제, 문화 중심지로, 정부 기관, 대규모 기업 본사, 다양한 관광 명소들이 위치해 있습니다. 세계에서 가 장 인구 밀도가 높은 도시 중 하나이며, 약 1000만 명의 주민이 살 있으며, 서울의 광역 수도권 지역에는 2500만 명이 거주하고 있습니다.
inference example
question = "김치찌개 끓여줘"
print(question)
print("-" * 50)
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOllama(model="EEVE-Korean-10.8B:latest")
prompt = ChatPromptTemplate.from_template("너 이름은 '붕붕' 이고, 질문 '{question}' 에 간단히 답해줘.")
chain = prompt | llm | StrOutputParser()
print(chain.invoke({"question": question}))-
ChatOllama를 사용하여Ollama로 loading 된 모델(EEVE-Korean-10.8B:latest)을 불러와서 -
prompt로"너 이름은 '붕붕' 이고, 질문 '{question}' 에 간단히 답해줘."간단하게 구현해봤다. -
chain 걸고 모델을 invoke 하여 결과를 보면
김치찌개 끓여줘
--------------------------------------------------
물론이죠! 질문에 도움을 드리게 되어 기쁩니다. 하지만 김치찌개를 직접 만들어 드릴 수는 없다는 점을 알려드려야 해요. AI 어시스턴트로서 조리 과정을 실제로 수행할 수 있는 능력이 없기 때문입니다. 그러나 몇 가지 레시피 간단한 레시피를 원하신다면, 다음의 간단한 단계를 따라 해보세요:
1. 돼지고기 다짐육을 적당히 자릅니다 (대략 300g 정도).
2. 중불에서 고기를 팬에 살짝 볶아주세요.
3. 잘게 썬 양파(대략 1/4개), 다진 마늘(약간), 그리고 고추가루(취향에 맞게)를 추가하세요. 약 3분정도 더 조리해서 향이 날 때까지 익힙니다.
4. 김치(대략 2컵 정도, 원하는 매운맛 강도에 따라 조절 가능)와 물을 (고기에서 나온 기름이나 국물이 있다면 생략할 수 있지만 없다면 대략 1/4컵 정도) 넣습니다.
5. 소금과 설탕으로 간을 맞춥니다 (각각 대략 한 큰술씩, 취향에 맞게 조절).
6. 약불로 줄이고 김치가 익고 맛이 어우러지도록 약 20분간 끓여주세요. 필요하다면 양념을 조절하세요.
7. 마지막으로 파와 참기름(선택사항)으로 고명을 올려서 뜨겁게 내놓으세요.
도움이 되셨길 바랍니다! 질문이 더 있거나 추가적인 도움이 필요하시면 알려주세요.이와 같이 나온다.
LangServe 나 LangSmith 등 다양한 방법으로 좀 더 깊게 접근해볼 예정.
ref
-
vector (chromadb) 예시
https://velog.io/@acdongpgm/DB.-벡터-데이터베이스Vector-database-ChromaDB-사용해보기 -
langchain (ollama 등 다양한 방법론) 예시
https://github.com/teddylee777/langserve_ollama
https://www.youtube.com/watch?v=VkcaigvTrug
