axiom of completeness
- 완비성 공리 in Real number (실수계) 부터 시작.
가 의 공집합이 아닌 부분집합 이라 하자.
bounded
- 에 대하여 인 일 때 를 위로 유계 (bounded above) 라 하고, 를 의 상계 (upper bound) 라고 한다.
- 에 대하여 인 일 때 를 아래로 유계 (bounded below) 라 하고, 를 의 하계 (lower bound) 라고 한다.
- 가 bounded above 인 동시에 bounded below 일 때는 간단히 를 유계 (bounded) 라 한다.
supremum
이때 다음 조건을 만족하는 를 의 상한 또는 최소 상계 라고 한다.
- 는 의 least upper bound (상계) 이다.
- 가 의 upper bound 이면 이다. 즉, 는 상계 중 제일 작은 것이다.
infimum
이때 다음 조건을 만족하는 를 의 하한 또는 최대 하계 라고 한다.
- 는 의 greatest lower bound (하계) 이다.
- 가 의 lower bound 이면 이다. 즉, 는 하계 중 제일 큰 것이다.
axiom of completeness
이 완비성공간이라는 것을 이야기하고, 에서만 성립하는 공리.
- 가 의 공집합이 아닌 부분집합이고, 위로 유계 이면 반드시 의 상한 가 존재.
- 가 의 공집합이 아닌 부분집합이고, 아래로 유계 이면 반드시 의 하한 가 존재.

completeness
일단 close set 으로 이해. topology 에서 정의는 좀 더 들어가야한다.
거리 공간 에 대해 라고 하자.
- Cauchy sequence.
- 상의 Cauchy sequence 이 수렴하는 점들이 에 속하면 는 complete.
- Closure.. 등등..
cauchy sequence ( 코시 수열 )
에 대하여 이면,
을 만족하는 자연수 이 존재할 때, 수열 은 Cauchy sequence 라고 한다.
그렇다면.. 실수 공간이 아니라 어떤 space 이면? 그것이 distribution 이라면?
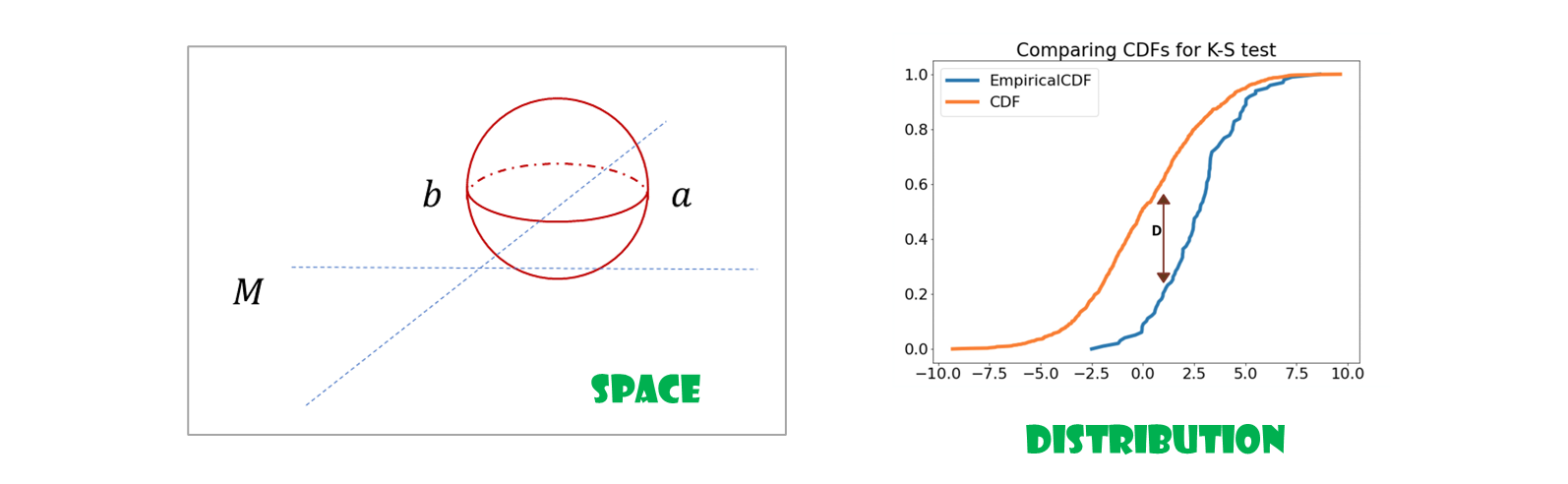
KS statistics ( TV : Total Variation 과 비슷 )
measurable 값의 차이가 가장 큰 값.
contraction for distributions
-
고정된 learning rate 의 경우, stochastic gradient descent 는 state vector 를 사용하는 Markov process 이다.
-
이 과정의 점근적인 (asymptotic) 특성들에 관하여 많은 연구가 있지만, 점근적인 체계가 가정될 때 까지 필요한 반복 횟수에 관하여 많이 알려져 있지 않다.
-
점의 매핑 (
mappings of points) 에서 분포의 매핑 (mappings of distributions) 으로 축약 (contractions) 의 개념을 확장함으로써 후자를 다룬다.
mappings of points
-
유클리디안 ( Euclidean ) 거리 : 변수들의 차이를 제곱하여 합산한 거리.
가장 일반적인, 물리적인 거리.
-
맨하튼 거리 ( Manhattan distance ) : 변수 값들의 차이를 절대값화 하여 합한 거리 측정
초록색이 Euclidean distance.
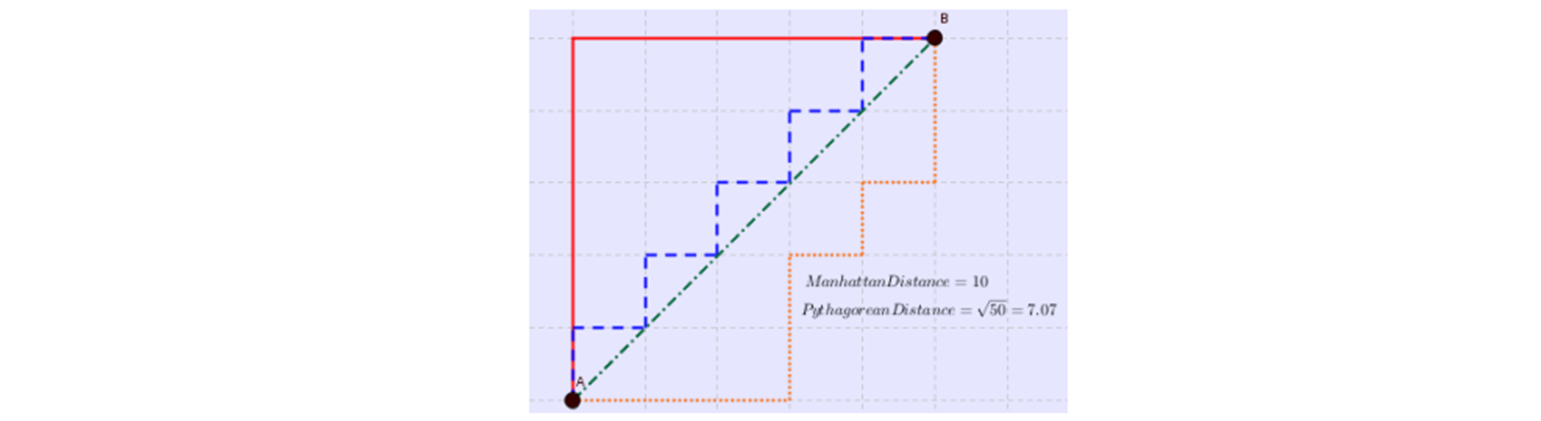
- green : 유클리디안 거리
- blue & red : 맨하튼 거리
-
Minkowski distance : Euclidean distance general version.
- 제곱 대신 을 사용하게 된다.
- 유클리디안 ( Euclidean ) 거리, 맨하튼 ( Manhattan ) 거리 의 일반화
- 거리를 산정하는 일반식, 함수에 포함된 지수들을 조정해 줌으로써 다양한 방식의 거리 측정.
mappings of distributions
-
distance
- : symmetric
-
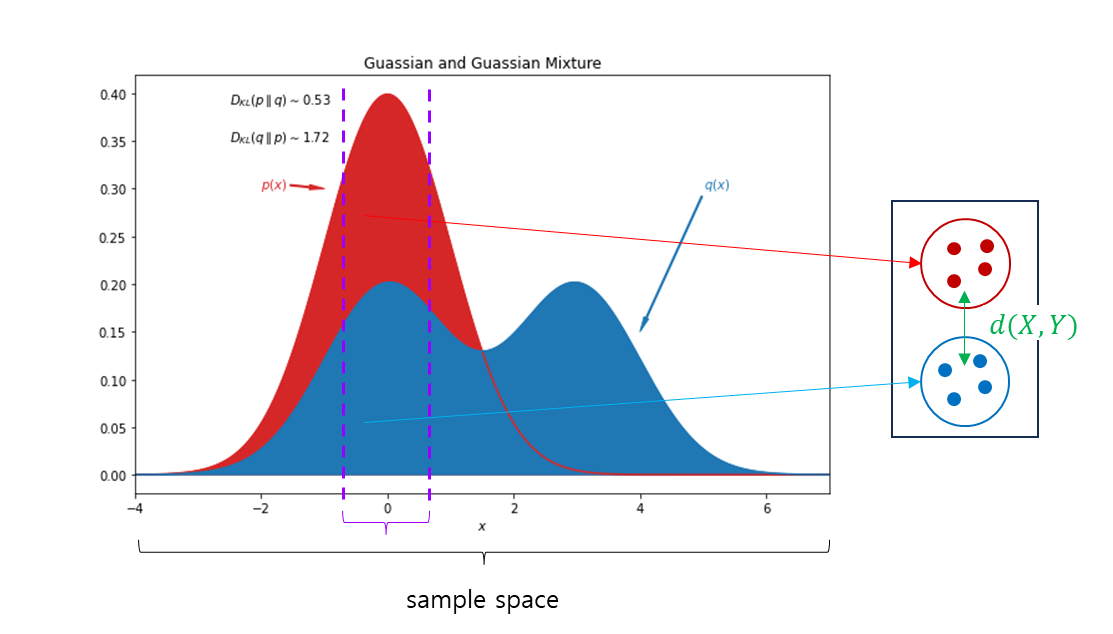
Kullback-Leibler divergence
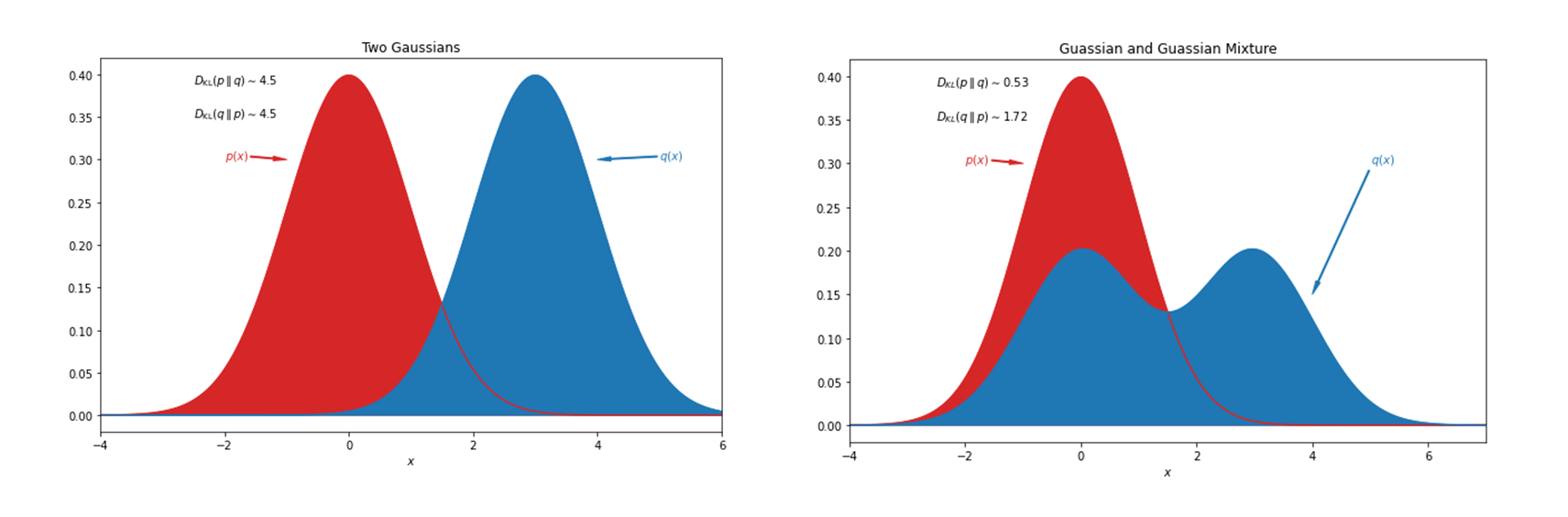
- , 값을 보면 좌측의
Two Gaussians는 같지만, 우측의Guassian and Guassian Mixture는 다르다.
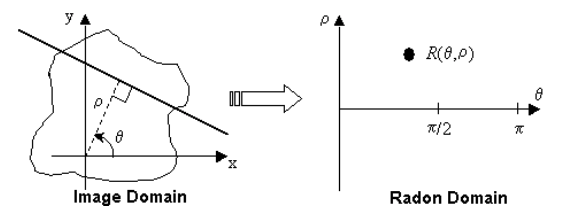
wasserstein metric
Radon-nikodym 의 정리 생각나네.. 기하 통계 봐야하는데..
for a radon space
Radon space
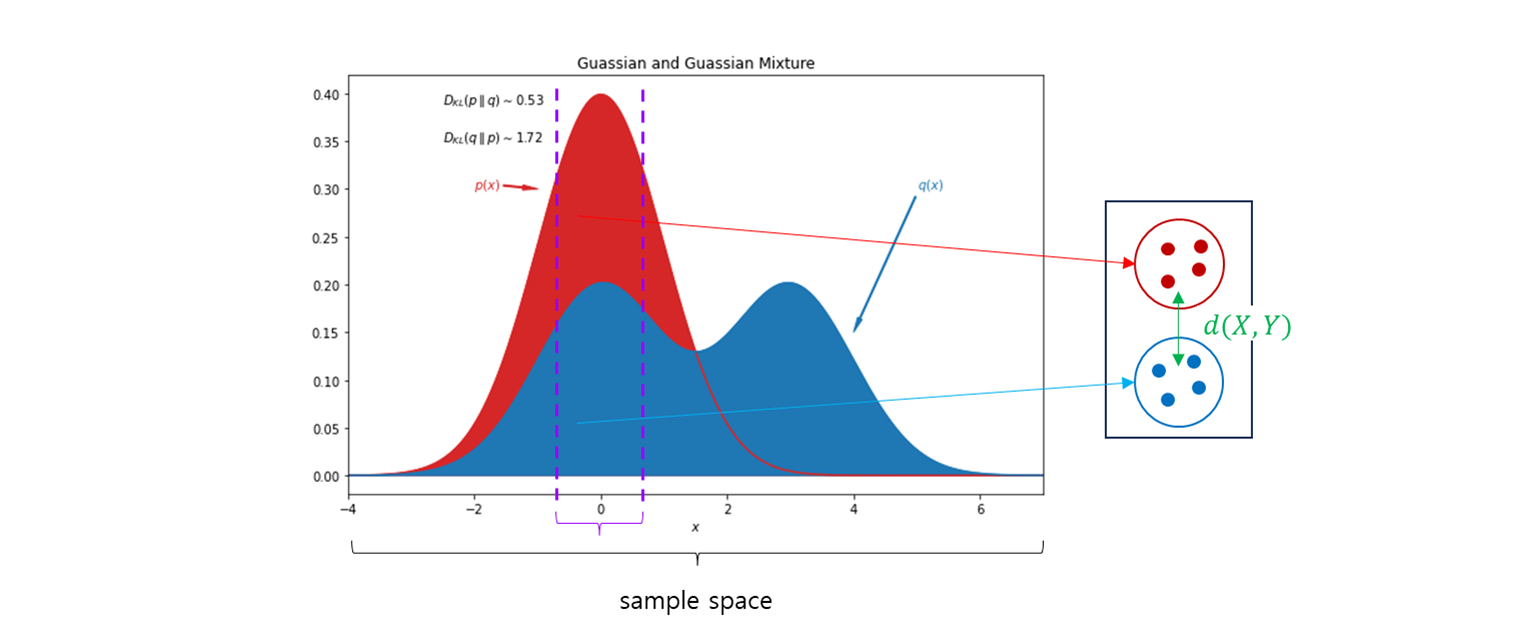
는 공간에 대한 모든 분포의 집합 이라고 하자.
두 분포 사이의 Wasserstein distance 는 아래와 같다.
여기서 는 marginals 와 를 포함한 에 대한 확률 분포들의 집합.
- 두 확률 분포 의 joint dist 들의 집합
- : 그 중 하나 : 지수 조정 → 다양한 방식으로 거리 조정.
의 expectation 을 가장 작게 추정한 값.
explain
→ infimum..
Wasserstein metric 은 두 가지 매우 중요한 속성이 있다.
1. complete (완비성) 을 의미한다.
2. 에 있는 축약은 에 있는 축약을 유도한다 (induces).
measure theory, and next !!
매핑이 주어지면
- 에 pointwise 로 적용하여 를 구성할 수 있다.
와 라 하자.
- 모든 특정 가능한 이벤트 에 대해서 에 의한 pre-image 를 나타낸다.
그 다음 를 갖는다.
이 형태는 많이 봤다.
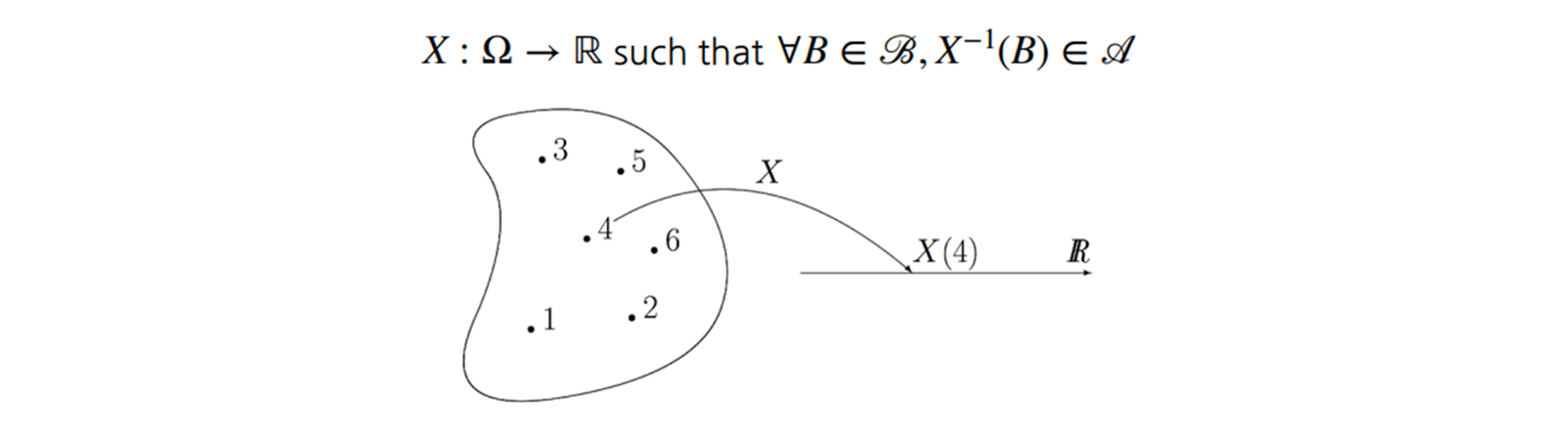
Random Variable 와 Distribution, 그리고 Optimal transport . . .
transformer 기하 내용도 봐야하고, metric, loss 도 더 연구를 해야하고, entropy 개념도 정리하고, 현재 잘 나오는 SOTA 논문도 보고, 시스템, 제품 개발도 해야하는데.. 세상의 속도는 너무 빨리 앞으로 나간다. 정말 다들 너무 잘 따라간다.. ㅎㅎ 열심히 해야지!
ref
-
Parallelized Stochastic Gradient Descent
https://papers.nips.cc/paper_files/paper/2010/file/abea47ba24142ed16b7d8fbf2c740e0d-Paper.pdf -
Wasserstein GAN
https://www.slideshare.net/slideshow/wasserstein-gan-i/75554346 -
On Radon Measure
https://sites.math.washington.edu/~farbod/teaching/cornell/math6210pdf/math6210Radon.pdf
