Accounting for Dependencies in Deep Learning Based Multiple Instance Learning for Whole Slide Imaging
Announcement


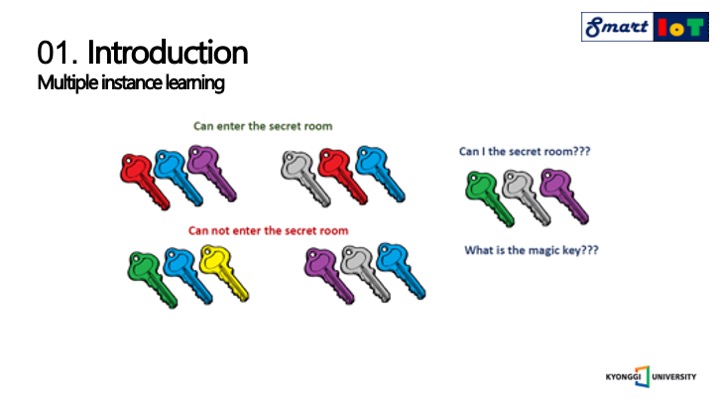
먼저 해당 논문의 논점이 되는 주요한 문제 해결 방법은 멀티플 인스턴스 러닝이며,
멀티플 인스턴스 러닝은 위쪽의 방문을 열 수 있는 키 꾸러미가 있고
아래에는 방을 열 수 없는 꾸러미가 존재한다는 정보를 가지고
오른쪽의 키꾸러미를 가지고 방문을 열 수 있느냐를 알아내는 것 입니다.
이를 전립선 암의 영역을 알아내는 문제에 적용할 경우

암은 아주 작은 영역의 지역 병변이 존재하고,
이 때 각 이미지당 오른쪽 사진처럼 여러 패치로 샘플링하여 개별 패치를 판별합니다.
샘플링을 하는 과정에서 조직학 전체 슬라이드 이미지는 엄청나게 큰 이미지 사이즈를 가지고 있기 때문에 계산 부담을 줄이기 위해 고정된 패치 사이즈로 나누어서 오른쪽 사진처럼 타일링합니다.
또한 계산 부담을 줄이기 위함도 있지만, 실제 암 영역은 아주 작은 부분을 차지하고 있기에 합성곱 신경망의 성능을 저하시키는 문제가 있기 때문입니다.
전체 이미지에 대해서 주어지는 라벨은 백의 라벨만 제공되기 때문에
모든 패치에 대해서 라벨링을 진행하는 것에는 엄청난 비용과 시간이 들어가기 때문에 일반적으로 사용하지 못합니다.
해당 문제와 같이 라벨이 적은 데이터 세트를 가지고 훈련하기 위해서는 약한 지도 학습 방법을 활용하여야하기때문에 그 중 멀티플 인스턴스 학습 방법을 사용하였습니다.
백에 대한 타일링을 진행하고 배경 이미지를 포함한 포그라운드 패치만 사용하며, 나머지 패치 중 무작위하게 부분집합을 취하여 백을 구성하였습니다.
인스턴스 라벨을 알 수 없기에 기존의 연구는 일반적으로 예측 확률의 최대값에 기초하여 한 개 또는 몇 개의 인스턴스만 반복에 사용하였습니다.
이는 시간이 매우 오래 걸리지만, 반복의 진행에 있어 단일 패치만 합성곱신경망 훈련에 사용 되었습니다.
하지만 해당 연구에서는 모든 이미지 패치를 활용하기 위해서 가중치를 통한 어텐션 메커니즘을 사용하였으며,
멀티플 인스턴스 학습에서는 의존성을 갖지않는다고 추정하였지만, 조직병리학에서는 해당되지 않았습니다.
또한 인스턴스 수준의 손실 감독이 부족하다면 오버피팅 발생 가능성이 높아지기 때문에
본 연구에서는 트랜스포머 인코더 블록을 합성곱 신경망에 내장하여 훈련 중 인스턴스간의 의존성을 명시적으로 설명할것을 제안하였으며,
인스턴스 추정 라벨을 기반으로 한 인스턴스별 손실 감독을 제안하였습니다.

H는 앞서 설명한 백을 의미하며, hk는 인스턴스를 의미합니다.
K는 인스턴스의 개수를 의미하기 때문에 이는 전체 이미지에 따라 달라질 수 있습니다.
학습하는 과정에서 손실이 인스턴스 레이블의 최대치를 기반으로 하는 것은 가중치 손실이 발생하기 때문에 문제가 있다고 설명하며,
단일 패치만 최적화에 기여하기 떄문에 학습 과정이 느려진다고 합니다.
이러한 문제를 극복하기 위해 모든 이미지 패치에 대한 어텐션 가중치를 사용하는 방법을 고안하였으며,
계산된 어텐션 가중치를 모든 패치에 적용하였습니다.
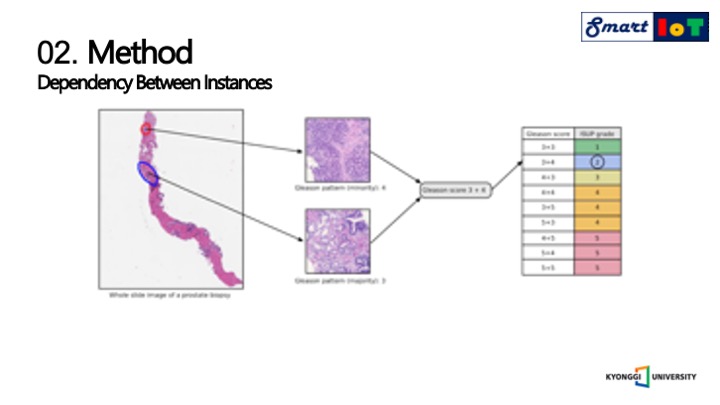
백속의 인스턴스간의 의존성이 없다는 것은 종종 받아들여지지 않는데, 다음과 같은 사진처럼 전립선 암의 심각도를 평가하기 위해서 병리학자는 두개의 뚜렷한 종양 패턴을 찾아 글리슨 점수를 계산하여야 하기 때문에 의존성이 존재합니다.
글리슨 패턴은 1부터 5점 사이의 점수를 가지며, 1점에 가까우면 정상 5점에 가까우면 악성도가 심한 암을 의미합니다.
암이 가장 많은 부분을 차지하는 두 군데의 글리슨 패턴의 점수를 매긴 후 합하여 글리슨 점수를 구하게 되는데 2개의 점수를 합한 값은 2부터 10점의 분포를 가지지만, 6점은 낮은 악성도, 7점은 중간 악성도, 8부터 10점은 높은 악성도를 의미합니다.
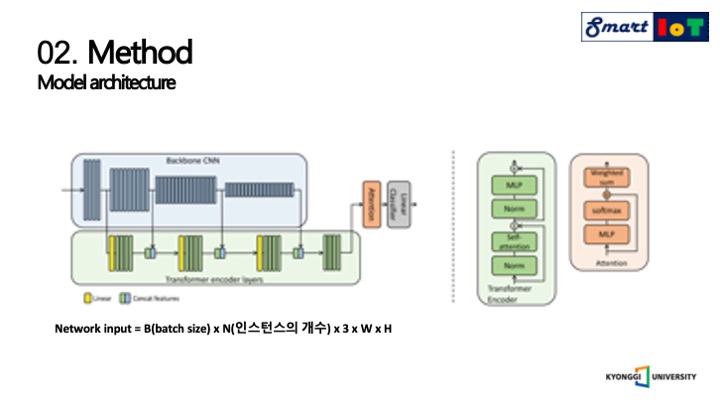
앞서 설명한 의존도를 설명하기 위해서 Backbone CNN을 사용하여서 에버리지 폴링된 여러 크기의 특징을 추출하여 트랜스포머 인코더에 사용합니다.
네트워크 입력은 배치사이즈, 인스턴스의 개수, 패치 공간의 크기를 활용합니다.
각각의 트랜스포머 인코드 계층은 풀리커넥티드 포워드 네트워크와 레이어 노말리제이션을 포함합니다.
인스턴스의 종속성을 설명하기 위해 self-attention을 사용합니다.
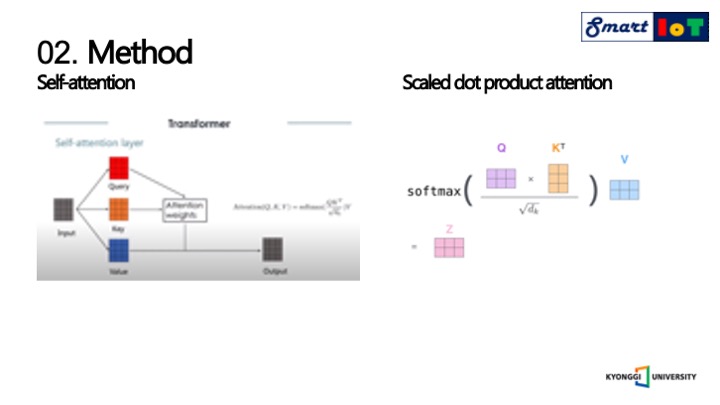
셀프 어텐션은 처음에는 문장의 단어 사이의 장거리 의존성을 포착하기 위해서 도입되었지만, 이를 컴퓨터비전에 활용하였습니다.
이중 핵심은 오른쪽의 나와있는 스칼라 닷 프로덕트 어텐션이며, 여기서 Q는 쿼리이며 영향을 받는 쪽을 의미하며, K는 Key이며 영향을 주는 쪽을 의미하고, d는 두 벡터의 내적값을 스케일링 하는 값을 의미하며, V는 Values이며 영향에 대한 가중치를 의미합니다.
스칼라 닷 프로덕션 어텐션은 Q와 K 사이를 내적하여 어텐션을 소프트맥스를 통해서 구하고 그 후에 V를 내적하여 중요한 부분을 살린다는 매커니즘을 나타냅니다.
여기서 닷 프로덕션의 값이 모두 너무 크다면 소프트맥스의 기울기가 작아지기 때문에 dk로 닷 프로덕션한 값을 스케일 하며, Value를 곱해주는 이유는 소프트맥스를 거친 값을 value에 곱해준다면 Q와 유사한 value일 수록 더 높은 값을 가지게 되기 때문입니다.
또한 셀프 어텐션은 병렬적으로 여러 번 수행됩니다.

해당 연구에서는 트랜스포머를 활용하는 두 가지 변형을 제안하였으며, 가장 간단한 변형은 에버리지 풀링 후 백본 CNN의 끝에만 트랜스포머 인코더를 부착하는 것이며, 이는 다른 연구에서 제안된 방식과 비슷하지만, 다른 연구에서는 에버리지 풀링 전에 부착하였다는 차이점이 있었습니다.
그리고 기존의 연구는 패치의 공간 영역 사이의 의존성을 설명하는 것이지만, 우리는 패치간의 의존성에 대해 설명하고자 하였습니다.
때문에 트랜스포머의 출력및입력 숨겨진 차원이 동일하도록 인코딩된 데이터의 차원성을 유지하며, 이것을 트랜스포터 멀티플 인스턴스 학습이라고 명명하였습니다.
그리고 또한 서로 다른 수준의 합성곱 신경망 출력 특징에는 서로 다른 의미 정보가 내포되어있기 때문에 여러 쳑도의 패치간의 의존성을 포착하기 위해서 트랜스포머와 백본 합성곱 신경망의 더욱 변형을 주었는데, ResNet의 블록 뒤에 별도의 트랜스포머 인코더 블록을 부착하여 다양한 피라미드 형식의 수준에서 패치 인코딩을 캡쳐하였습니다.
첫번째 트렌스포머 인코더의 출력은 평균 풀링 후에 다음 스케일 공간에 연결되면 최종 인코더 레이더까지 이어서 스케일되어 공급되며, 그 뒤에 어텐션 레이어가 이어집니다.
그리고 해당 모델의 결과가 오른쪽에 나와있는 B입니다.
왼쪽의 a는 실제 암이 존재하는 공간을 마스킹한 것이며, B는 라벨을 예측한 결과를 마스킹한 이미지입니다.
그리고 B처럼 패치별로 고밀도 시작화를 적용하기 위해서 슬라이딩 윈도우 접근법을 사용하였으며,

해당 이미지와 유사하게 동작합니다.

멀티플 인스턴스 학습의 문제점 중 하나는 최적화를 위한 인스턴스 레이블이 부족하다는 것이 있으며 이를 위해서 준지도 학습에서는 유사 레이블이 일부 중간 추정을 사용하거나 다른 네트워크의 예측를 사용하였는데, 여기서는 각 이미지 패치에 대해 유사 레이블을 생성하고 추가 패치별 손실을 사용하여 최적화 프로세스를 제안하였습니다.
L은 총 손실을 의미하며, Lbag은 백 레벨의 손실을 의미하며, L패치는 패치 레벨의 손실을 의미하며, 해당 모델에서는 두가지 손실 모두에 대해서 교차 엔트로피 손실 함수를 사용하였습니다.
C는 백 레벨의 예측을 의미하며, 오른쪽 위의 수식으로 나타낼 수 있으며, 패치 수준의 예측에 대해서는 왼쪽 아래와 같은 수식으로 나타낼 수 있습니다.

해당 수도코드는 pseudo-labels의 계산을 위한 알고리즘이며, Bag속에 있는 모든 patch에 대해서 계산을 진행하였고, 먼저 각 이미지에 대한 패치 수준의 추론을 실행하고 어텐션 가중치 a와 인스턴스 클래스 ck의 앙상블을 예측한 후 백 라벨이 0이 아니라면 A가 상위 10%에 속할 패치의 경우 앙상블 레이블의 결과를 할당하며 하위 10%에 속하는 패치의 대해서는 0으로 할당하고 나머지 80%에 대해서는 알수없다는 플래그를 할당합니다.
그리고 백 라벨이 0이라면 모든 패치 라벨이 0이여야 하므로 모든 패치에 대해서 0으로 할당합니다.
추가적으로 앙상블 어텐션 가중치가 작지도 크지도 않은 일부 패치의 경우 예측 라벨을 할당하지 않으며, Lpatch loss에서 제외하도록 하고 알 수 없음으로 표시합니다.
예측 라벨의 계산이 끝난 뒤 다음 레이어로 주어진다면 추가 패치별 손실을 사용하여 모델을 다시 최적화합니다.
이렇게 휴리스틱하게 10%만 남기는 과정을 통해 가장 신뢰할 수 있는 패치만 유지하도록 합니다.
하지만 해당 연구의 목표를 전체 분류의 정확도 개선이 아닌 dense segmentation map을 그리는 것이 목표입니다.

실험은 다음과 같은 환경에서 진행되었으며, 백본 네트워크로는 레스넷50을 사용하였고 이미지넷으로 프리트레이닝을 진행, 최적화 함수로는 아담을 사용하였으며 초기값과 네트워크의 학습률을 달리하여 점진적으로 진행하게 하였습니다.
학습 방법으로는 코사인 러닝 레이트 스케줄러를 사용하여서 학습을 50에폭 진행하였으며, 드랍아웃은 사용하지 않고 트렌스포머 레이어에 디케이를 0.1로 주어 실험을 진행하였고 매개 변수 조정을 위해 파이브 폴드 교차검증을 사용하였습니다.

실험에 사용된 학습 데이터셋은 PANDA의 전립선 등급 과제 챌린지 데이터 세트를 사용하였으며, 이미지는 총 11000장으로 전체 슬라이드 이미지로 구성되어있습니다.
실험에 사용된 이미지는 최대 사이즈보다 4배적은 이미지들이 사용되었습니다.
채점 기준은 글리슨 패턴 점수를 글리슨 점수로 변환 후 이를 기초하여 국제 비교기병학회 등급으로 변환됩니다.
패치를 구분하는 과정에는 정사각형의 224픽셀 사이즈 패치로 배열하며, 패치의 임의성을 보장하기 위해서 왼쪽 상단 모서리에서 간격을 띄우고, 세포가 들어있으며 배경을 포함한 패치들만 보관하며, 나머지 패치에서는 GPU의 한계로 인해서 임의의 56장만 유지하였습니다.
데이터 인풋 사이즈를 위와 같이 맞추기 위해서 배치 사이즈는 16을 사용하였습니다.
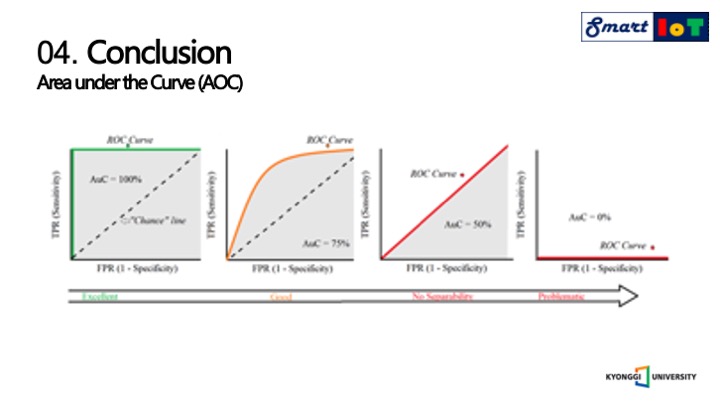
먼저 결과에 대한 평가 기준부터 설명드리겠습니다.
AOC는 ROC커브를 대상으로 하며 roc 커브의 밑 면적의 너비를 계산한 것을 의미합니다.

다음으로는 2차 가중 카파에 대해서 설명드리겠습니다.
2명의 관찰자가 존재하여야하며 두 관찰자 간의 측정 범주 값에 대한 일치도를 측정하는 방법입니다.
그리고 0부터 1 사이의 값을 가지며, 범주에 대한 의미는 오른쪽 표와 같습니다.
해당 연구의 결과에서는 예측과 목표값 사이의 유사성을 측정하기 위해서 2차 가중 카파를 사용하여 측정하였습니다.
모든 메트릭은 테스트 데이터를 제외한 데이터셋에 대하여 파이브 폴드를 진행하여서 계산되었습니다.
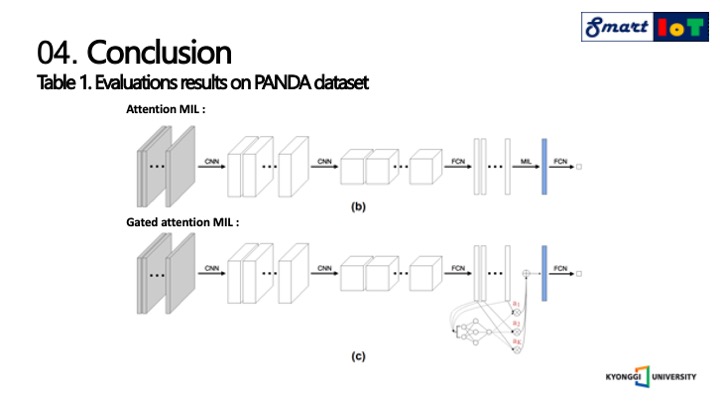
그리고 다음은 비교 대상에 대해서 설명드리겠습니다.
위의 모델은 어텐션 가중치를 활용한 멀티플 인스턴스 학습 모델이며 해당 연구와 어텐션 가중치를 사용하였다는 점은 같지만 구조적으로 다른 것을 알 수 있습니다.
아래의 모델은 Gated attention mechanis을 멀티플 인스턴스 학습에 사용하였으며, 빨간색은 인스턴스 점수에 해당합니다.
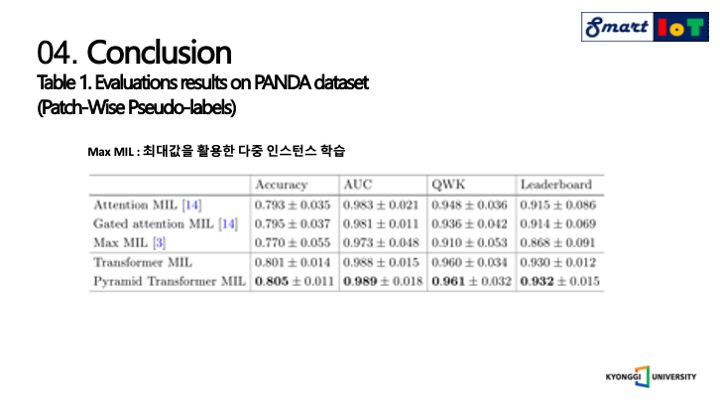
다음 결과는 패치 와이즈를 사용한 결과이며, 해당 연구에서는 전체 이미지를 패치로 나누어서 전부 사용한 것으로 보입니다.
해당 연구에서 제안된 학습방법이 검증 데이터와 테스트 데이터 모두에서 기존의 유사한 모델들의 정확도 보다 앞서는 것을 볼 수 있습니다.
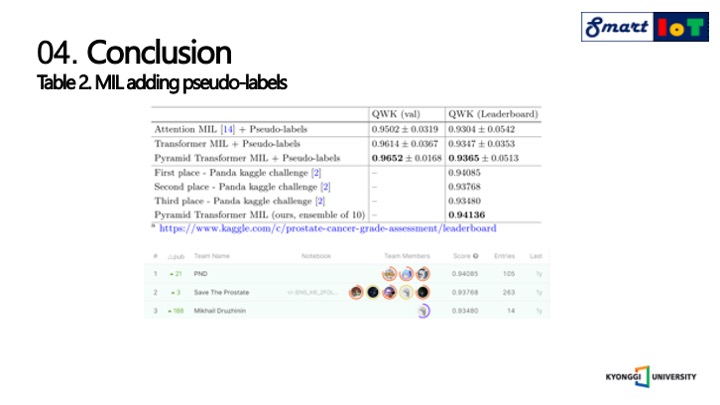
다음으로는 앞서 제안하였던 유사 라벨에 대한 supervision을 추가한 성능입니다.
모든 경우에 성능은 표1 에 있는 결과보다 약 1%이상 향상 되었음을 알 수 있고, PANDA 캐글 챌린지 우승자의 2차 가중 카파에 대한 결과들과 동등함을 알 수 있고, 앙상블을 진행하여 10개의 모델을 앙상블한 결과는 캐글 챌린지에서 1등을 차지할수 있었을 것이라고 합니다.
