imageNet Classification with Deep Convolutional Neural Network
NIPS-2012-imagenet-classification-with-deep-convolutional-neural-networks.pdf
Abstract
ImageNet LSVRC-2010 콘테스트에서 120만 개의 고해상도 이미지를 1000개의 다른 클래스로 분류하기 위해 크고 심층적인 컨볼루션 신경망을 훈련시켰다.
테스트 데이터에서 우리는 이전 최첨단보다 상당히 향상된 37.5%, 17.0%의 상위 1~5위 오류율을 달성했다. 6천만 개의 매개 변수와 65만 개의 뉴런을 가진 신경망은 5개의 컨볼루션 레이어로 구성되며, 그 중 일부는 최대 풀링 레이어와 최종 1000방향 소프트맥스를 가진 3개의 완전히 연결된 레이어로 구성된다.
훈련을 더 빠르게 하기 위해, 우리는 포화 상태가 아닌 뉴런과 컨볼루션 작업의 매우 효율적인 GPU 구현을 사용했다.
완전히 연결된 계층에서 과적합을 줄이기 위해 우리는 매우 효과적이라고 입증된 "dropout"이라고 불리는 최근에 개발된 정규화 방법을 사용했다.
우리는 또한 ILSVRC-2012 대회에서 이 모델의 변종을 진입시켰고, 2위 진입으로 달성한 26.2%에 비해 15.3%의 우승 상위 5위 테스트 오류율을 달성했다.
1. Introduction
객체 인식에 대한 현재의 접근 방식은 기계 학습 방법을 필수적으로 사용한다.
성능을 향상시키기 위해, 우리는 더 큰 데이터 세트를 수집하고, 더 강력한 모델을 학습하고, 과적합을 방지하기 위해 더 나은 기술을 사용할 수 있다.
최근까지 라벨링된 이미지의 데이터 세트는 수만 개의 이미지(예: NORB [16], Caltech-101/256 [8, 9], CIFAR-10/100 [12]) 순서로 비교적 작았다.
특히 라벨 보존 변환으로 증강된 경우 이 크기의 데이터 세트를 사용하여 간단한 인식 작업을 상당히 잘 해결할 수 있다.
예를 들어, MNIST 수치 인식 과제(<0.3%)의 현재 최고 오류율은 인간 성능에 접근한다[4].
그러나 현실적인 설정의 객체는 상당한 가변성을 나타내므로 이를 인식하는 방법을 배우려면 훨씬 더 큰 훈련 세트를 사용해야 한다.
그리고 실제로 작은 이미지 데이터 세트의 단점은 널리 인식되어 왔다 (예: 핀토 외). [21])이지만 수백만 개의 이미지로 레이블이 지정된 데이터 세트를 수집할 수 있게 된 것은 최근이다.
새롭게 더 큰 데이터 세트에는 수십만 개의 완전히 분할된 이미지로 구성된 LabelMe[23]와 22,000개 이상의 범주에서 1,500만 개 이상의 레이블이 지정된 고해상도 이미지로 구성된 ImageNet[6]이 포함된다.
수백만 개의 이미지에서 수천 개의 개체를 배우기 위해서는 학습 능력이 큰 모델이 필요합니다. 그러나 객체 인식 작업의 엄청난 복잡성은 이 문제를 ImageNet만큼 큰 데이터셋으로도 지정할 수 없다는 것을 의미하므로, 우리의 모델은 우리가 가지고 있지 않은 모든 데이터를 보상하기 위한 많은 사전 지식도 가지고 있어야 한다.
CNN(Convolutional Neural Network)은 그러한 모델 클래스 중 하나를 구성한다[16, 11, 13, 18, 15, 22, 26]. 이들의 용량은 깊이와 폭을 변화시켜 제어할 수 있으며, 이미지의 본질(즉, 통계의 고정성 및 픽셀 종속성의 인접성)에 대해 강력하고 대부분 올바른 가정을 한다.
따라서, 유사한 크기의 레이어를 가진 표준 피드포워드 신경망과 비교하여, CNN은 연결과 매개 변수가 훨씬 적어서 훈련하기가 더 쉬운 반면, 이론적으로 가장 우수한 성능은 조금 더 나쁠 가능성이 있다.
CNN의 매력적인 품질에도 불구하고, 그리고 지역 아키텍처의 상대적 효율성에도 불구하고, 그것들은 고해상도 이미지에 대규모로 적용하는데 여전히 엄청나게 비용이 많이 들었다.
다행히도, 고도로 최적화된 2D 컨볼루션 구현과 짝을 이룬 현재의 GPU는 흥미롭게도 큰 CNN의 훈련을 용이하게 할 만큼 강력하며 ImageNet과 같은 최신 데이터 세트에는 심각한 과적합 없이 그러한 모델을 훈련시킬 수 있는 충분한 레이블이 지정된 예가 포함되어 있다.
본 논문의 구체적인 기여는 다음과 같다.
우리는 ILSVRC-2010 및 ILSVRC-2012 경기에서 사용된 ImageNet의 하위 집합에 대해 현재까지 가장 큰 컨볼루션 신경망 중 하나를 훈련시켰으며 이러한 데이터 세트에 보고된 최고의 결과를 달성하였다. 우리는 2D 컨볼루션의 고도로 최적화된 GPU 구현과 우리가 공개적으로 이용할 수 있게 하는 컨볼루션 신경망 훈련에 내재된 다른 모든 작업을 작성했다.
우리의 네트워크는 섹션 3에 자세히 설명되어 있는 그것의 성능을 향상시키고 훈련 시간을 줄이는 많은 새롭고 특이한 특징들을 포함하고 있다.
네트워크 크기는 120만 개의 레이블이 지정된 훈련 예에서도 과적합 문제를 야기하여 과적합 방지를 위해 몇 가지 효과적인 기술을 사용했으며, 이는 섹션 4에 설명되어 있다.
우리의 최종 네트워크는 5개의 컨볼루션 레이어와 3개의 완전히 연결된 레이어를 포함하며, 이 깊이는 중요한 것 같다. 우리는 (각 모델 매개 변수의 1% 이하를 포함하는) 컨볼루션 레이어를 제거하면 성능이 저하된다는 것을 발견했다.
결국, 네트워크의 크기는 주로 현재 GPU에서 사용할 수 있는 메모리 양과 우리가 기꺼이 용인할 수 있는 훈련 시간에 의해 제한된다.
우리 네트워크는 두 개의 GTX 580 3GB GPU에서 훈련하는 데 5일에서 6일이 걸린다.
우리의 모든 실험은 더 빠른 GPU와 더 큰 데이터 세트가 사용 가능할 때까지 기다림으로써 우리의 결과를 개선할 수 있다는 것을 제안한다.
2. The Dataset
ImageNet은 약 22,000개의 범주에 속하는 1,500만 개 이상의 레이블이 지정된 고해상도 이미지의 데이터 세트이다. 이 이미지들은 웹에서 수집되었고 아마존의 기계 터크 크라우드 소싱 도구를 사용하여 인간 레이블에 의해 라벨이 붙여졌다.
2010년부터 Pascal Visual Object Challenge(Pascal Visual Object Challenge)의 일환으로 ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)라는 대회가 매년 열리고 있다. ILSVRC는 각각 1000개의 카테고리에 약 1000개의 이미지가 포함된 ImageNet의 하위 집합을 사용합니다.
전체적으로 약 120만 개의 훈련 이미지, 50,000개의 검증 이미지, 15만 개의 테스트 이미지가 있습니다.
ILSVRC-2010은 테스트 세트 레이블을 사용할 수 있는 유일한 ILSVRC 버전이기 때문에 대부분의 실험을 수행한 버전이다. 우리는 ILSVRC-2012 경쟁에도 모델을 입력했기 때문에, 섹션 6에서는 테스트 세트 레이블을 사용할 수 없는 데이터 세트의 이 버전에도 대한 결과를 보고한다.
ImageNet에서는 일반적으로 top-1과 top-5의 두 가지 오류율을 보고하는 것이 일반적이며, 여기서 top-5의 오류율은 모델에서 가장 가능성이 높은 5개의 레이블 중 올바른 레이블이 아닌 테스트 이미지의 일부입니다. ImageNet은 가변 해상도 이미지로 구성되지만, 우리 시스템은 일정한 입력 차원성을 필요로 한다.
따라서, 우리는 이미지를 256 × 256의 고정된 해상도로 다운샘플링했다. 직사각형 이미지가 주어지면, 우리는 먼저 짧은 면이 길이가 256이 되도록 이미지의 크기를 조정한 다음 결과 이미지에서 중앙 256×256 패치를 잘라냈다. 우리는 각 픽셀에서 훈련 세트에 대한 평균 활동을 뺀 것을 제외하고 다른 방법으로 영상을 사전 처리하지 않았다. 그래서 우리는 픽셀의 (중심) 원시 RGB 값에 대해 네트워크를 훈련시켰다.
3. The Architecture
우리 네트워크의 아키텍처는 그림 2에 요약되어 있다.
여기에는 8개의 학습된 레이어, 즉 5개의 컨볼루션과 3개의 완전히 연결된 레이어가 포함되어 있다.
아래에서, 우리는 네트워크 아키텍처의 몇 가지 새로운 또는 특이한 특징에 대해 설명한다.
섹션 3.1-3.4는 가장 중요한 항목부터 중요도 추정에 따라 정렬됩니다.
3.1 ReLU Nonlinearity
입력 x의 함수로 뉴런의 출력 f를 모델링하는 표준 방법은 f(x) = tanh(x) 또는 f(x) = 이다.
기울기 강하를 사용한 훈련 시간 측면에서, 이러한 포화 비선형성은 비파괴 비선형성 f(x) = max(0, x)보다 훨씬 느리다.
Nair와 Hinton[20]에 이어, 우리는 이 비선형성을 가진 뉴런을 정류 선형 단위(ReLU)라고 부른다. ReLU를 사용하는 심층 컨볼루션 신경망은 탄 단위와 동등한 것보다 몇 배 빠르게 훈련한다.
이는 그림 1에 나타나 있으며, 특정 4계층 컨볼루션 네트워크에 대한 CIFAR-10 데이터 세트에서 25% 훈련 오류에 도달하는 데 필요한 반복 횟수를 보여준다.
이 그림은 우리가 전통적인 포화 뉴런 모델을 사용했다면 이 작업에 대해 그렇게 큰 신경망을 실험할 수 없었을 것이라는 것을 보여준다.
CNN에서 기존의 뉴런 모델에 대한 대안을 고려하는 것은 우리가 처음이 아니다.
예를 들면, 자렛 외. [11] 비선형성 f(x) = |tanh(x)|이 특히 Caltech-101 데이터 세트에 대한 로컬 평균 풀링 후 대조 정규화의 유형과 잘 작동한다고 주장한다.
그러나 이 데이터 세트에서 주된 관심사는 과적합을 방지하는 것이므로 이들이 관찰하는 효과는 ReLU를 사용할 때 보고하는 훈련 세트를 적합시키는 가속된 능력과 다르다.
빠른 학습은 대규모 데이터 세트에 대해 훈련된 대형 모델의 성능에 큰 영향을 미친다.
그림 1: ReLU(솔리드 라인)를 가진 4계층 컨볼루션 신경망은 탄 뉴런(대시 라인)을 가진 등가 네트워크보다 CIFAR-10에서 6배 빠른 25% 훈련 오류율에 도달한다.
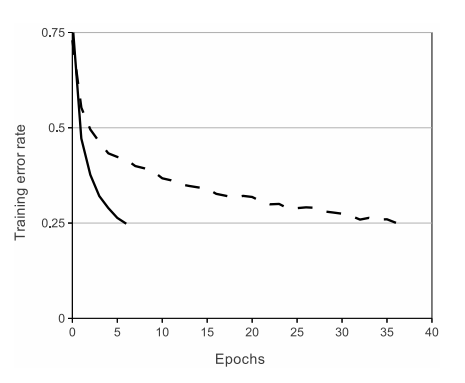
각 네트워크의 학습 속도는 훈련을 가능한 빨리 하기 위해 독립적으로 선택되었다.
어떤 종류의 정규화도 사용되지 않았다. 여기서 입증된 효과의 크기는 네트워크 아키텍처에 따라 다르지만 ReLU를 사용하는 네트워크는 포화 신경세포를 사용하는 등가물보다 몇 배 빠르게 학습한다.
3.2 Training on Multiple GPUs
GTX 580 GPU 한 개에는 3GB의 메모리만 있어 훈련 가능한 네트워크의 최대 크기를 제한한다.
GPU 하나에 맞추기에는 너무 큰 네트워크를 훈련시키는 데 120만 개의 훈련 예시가 충분한 것으로 나타났다.
따라서 우리는 두 개의 GPU에 망을 분산시킨다. 현재의 GPU는 호스트 머신 메모리를 거치지 않고 서로의 메모리에서 직접 읽고 쓸 수 있기 때문에 특히 교차 GPU 병렬화에 적합하다.
우리가 사용하는 병렬화 체계는 기본적으로 커널(또는 뉴런)의 절반을 각 GPU에 배치하고, 한 가지 추가 트릭을 가지고 있다: GPU는 특정 계층에서만 통신한다.
이는 예를 들어, 계층 3의 커널은 계층 2의 모든 커널 맵에서 입력을 취한다는 것을 의미한다.
그러나 계층 4의 커널은 동일한 GPU에 상주하는 계층 3의 커널 맵에서만 입력을 받는다.
연결 패턴을 선택하는 것은 교차 검증의 문제이지만, 이는 계산 양의 허용되는 부분일 때까지 통신량을 정밀하게 조정할 수 있게 해준다.
결과 구조는 시레산 외 연구진이 채용한 칼럼니스트 CNN과 다소 유사하다.
[5] 열이 독립적이지 않다는 점을 제외하고(그림 2 참조).
이 체계는 하나의 GPU에서 훈련된 각 컨볼루션 계층에 절반의 커널이 있는 네트와 비교하여 상위 1위와 상위 5위의 오류율을 각각 1.7%와 1.2% 줄인다. 2GPU 네트는 1GPU net2보다 훈련 시간이 약간 적게 걸린다.
- 1GPU 네트는 실제로 최종 컨볼루션 레이어의 2GPU 네트와 같은 수의 커널을 가지고 있다.
이는 네트워크의 매개 변수의 대부분이 마지막 컨볼루션 레이어를 입력으로 취하는 첫 번째 완전히 연결된 레이어에 있기 때문이다.
따라서 두 그물이 거의 동일한 수의 매개 변수를 갖도록 하기 위해, 우리는 최종 컨볼루션 레이어(또는 뒤에 완전히 연결된 레이어)의 크기를 반으로 줄이지 않았다.
따라서 이러한 비교는 2GPU의 절반 크기보다 크기 때문에 1GPU에 유리하게 치우쳐 있다.
3.3 Local Response Normalization
ReLU는 포화 상태를 방지하기 위해 입력 정규화가 필요하지 않은 바람직한 특성을 가지고 있습니다.
적어도 일부 훈련 예제가 ReLU에 긍정적인 입력을 생성한다면, 학습은 그 뉴런에서 일어날 것이다.
그러나 우리는 다음과 같은 지역 정규화 계획이 일반화에 도움이 된다는 것을 여전히 발견한다. kernel i 위치(x, y)를 적용한 후 ReLU 비선형성, 반응 정규화 활동 를 적용하여 계산된 뉴런의 활동을 로 표시한다.
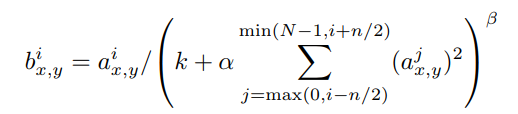
여기서 합은 n개의 "인접" 커널 맵에서 동일한 공간 위치에서 실행되며, N은 계층에서 커널의 총 수입니다.
커널 맵의 순서는 물론 임의적이며 훈련이 시작되기 전에 결정된다. 이러한 종류의 반응 정규화는 실제 뉴런에서 발견되는 유형에서 영감을 받은 측면 억제 형태를 구현하여 다른 커널을 사용하여 계산된 뉴런 출력 간의 큰 활동을 위한 경쟁을 유발한다.
k, n, α, β는 검증 집합을 사용하여 값을 결정하는 초 매개 변수이며, k = 2, n = 5, α = , β = 0.75를 사용했다. 특정 계층에서 ReLU 비선형성을 적용한 후 이 정규화를 적용했다(섹션 3.5 참조).
이 계획은 Jarrett 등의 국소 대조 정규화 계획과 약간 유사하다. [11]이지만 평균 활동을 빼지 않기 때문에 "밝기 정규화"라고 더 정확하게 말할 수 있습니다.
반응 정규화를 통해 상위 1개 오류율과 상위 5개 오류율이 각각 1.4%, 1.2% 감소합니다. 또한 CIFAR-10 데이터 세트에 대한 이 계획의 효과를 검증하였다. 4계층 CNN은 정규화 없이 13%, 정규화 3으로 11%의 테스트 오류율을 달성했다.
3.4 Overlapping Pooling
CNN의 풀링 레이어는 동일한 커널 맵에서 인접 뉴런 그룹의 출력을 요약한다.
전통적으로 인접한 풀링 단위로 요약된 이웃은 중복되지 않는다(예: [17, 11, 4].
좀 더 정확히 말하면, 풀링 레이어는 각각 풀링 유닛의 위치를 중심으로 한 크기 z × z의 이웃을 요약하여 픽셀 간격으로 배치된 풀링 유닛의 그리드로 구성된 것으로 생각할 수 있다.
s = z를 설정하면 CNN에서 일반적으로 사용되는 기존의 로컬 풀링을 얻을 수 있으며,
s < z를 설정하면 중복 풀링을 얻을 수 있다.
이것은 s = 2 및 z = 3을 사용하는 네트워크 전반에 걸쳐 사용됩니다.
이 체계는 등가 치수의 출력을 생성하는 비분할 체계 s = 2, z = 2와 비교하여 상위 1과 상위 5의 오류율을 각각 0.4%, 0.3% 감소시킵니다.
우리는 일반적으로 훈련 중에 중복 풀링을 가진 모델이 오버핏이 약간 더 어렵다는 것을 관찰한다.
3.5 Overall Architecture
이제 우리는 CNN의 전체적인 아키텍처를 설명할 준비가 되었다. 그림 2에서 설명한 것처럼, 네트는 가중치를 가진 8개의 레이어를 포함하고 있다. 처음 5개는 컨볼루션이고 나머지 3개는 완전히 연결되었다.
마지막 완전히 연결된 레이어의 출력은 1000 클래스 레이블에 대한 분포를 생성하는 1000방향 소프트맥스로 공급된다. 우리의 네트워크는 다항 로지스틱 회귀 목표를 최대화하는데, 이는 예측 분포에서 올바른 레이블의 로그 확률의 훈련 사례 전반에서 평균을 최대화하는 것과 같다.
두 번째, 네 번째 및 다섯 번째 컨볼루션 계층의 커널은 동일한 GPU에 있는 이전 계층의 커널 맵에만 연결된다(그림 2 참조).
세 번째 컨볼루션 계층의 커널은 두 번째 계층의 모든 커널 맵에 연결된다. 완전히 연결된 층의 뉴런은 이전 층의 모든 뉴런과 연결됩니다.
반응 정규화 계층은 첫 번째 및 두 번째 컨볼루션 계층을 따른다.
섹션 3.4에서 설명한 종류의 최대 풀링 계층은 다섯 번째 컨볼루션 계층뿐만 아니라 반응 정규화 계층 모두를 따른다.
ReLU 비선형성은 모든 컨볼루션 및 완전히 연결된 계층의 출력에 적용된다.
그림 2: CNN의 아키텍처에 대한 그림으로, 두 GPU 간의 책임에 대한 설명을 명시적으로 보여 준다.
한 GPU는 그림의 맨 위에 계층 부분을 실행하는 반면 다른 GPU는 맨 아래에 계층 부분을 실행한다.
GPU는 특정 계층에서만 통신합니다.
네트워크의 입력은 150, 528차원이며, 네트워크의 나머지 층에 있는 뉴런의 수는 253, 440–186, 624–64, 896–64, 896–43,264–4096–1000으로 주어진다.
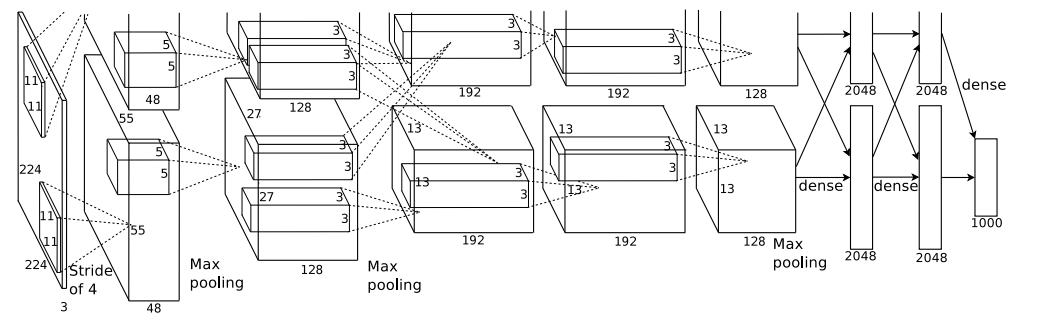
- 공간 제약으로 인해 이 네트워크를 자세히 설명할 수 없지만, 여기서 제공하는 코드와 매개 변수 파일인 http://code.google.com/p/cuda-convnet/에 의해 정확히 지정된다.
첫 번째 컨볼루션 레이어는 4픽셀의 보폭으로 11×11×3 크기의 96개의 커널을 가진 224×224×3 입력 이미지를 필터링한다.
두 번째 컨볼루션 레이어는 첫 번째 컨볼루션 레이어의 (응답 정규화 및 풀링) 출력을 입력으로 가져와서 크기 5 × 5 × 48의 256 커널로 필터링한다.
세 번째, 네 번째 및 다섯 번째 컨볼루션 레이어는 어떤 개입된 풀링 또는 정규화 레이어 없이 서로 연결되어 있다.
세 번째 컨볼루션 레이어는 크기가 3 × 3 × 256인 384개의 커널을 두 번째 컨볼루션 레이어의 (정규화된, 풀링된) 출력에 연결한다.
네 번째 컨볼루션 레이어는 크기가 3 × 3 × 192인 384개의 커널을 가지고 있으며,
다섯 번째 컨볼루션 레이어는 크기가 3 × 3 × 192인 256개의 커널을 가지고 있다. 완전히 연결된 층은 각각 4096개의 뉴런을 가지고 있습니다.
4. Reducing Overfitting
우리의 신경망 아키텍처는 6천만 개의 매개 변수를 가지고 있다.
ILSVRC의 1000개 클래스는 각 훈련 예제를 이미지에서 레이블로 매핑하는 데 10비트의 제약을 가하지만, 이는 상당한 과적합 없이 그렇게 많은 매개 변수를 학습하기에는 불충분한 것으로 밝혀졌다. 아래에서는 과적합과 싸우는 두 가지 주요 방법에 대해 설명합니다.
4.1 Data Augmentation
이미지 데이터에 대한 과적합을 줄이는 가장 쉽고 일반적인 방법은 레이블 보존 변환(예: [25, 4, 5])을 사용하여 데이터 세트를 인위적으로 확장하는 것이다.
우리는 두 가지 고유한 형태의 데이터 증강을 채택하는데, 두 가지 형태 모두 변환된 이미지를 매우 적은 계산으로 원래 이미지에서 생성할 수 있도록 허용하기 때문에 변환된 이미지를 디스크에 저장할 필요가 없다.
구현에서 GPU가 이전 이미지 배치에 대해 교육하는 동안 변환된 이미지는 CPU의 파이썬 코드로 생성된다.
따라서 이러한 데이터 확대 체계는 사실상 계산에서 자유롭다.
첫 번째 형태의 데이터 확대는 이미지 변환과 수평 반사를 생성하는 것으로 구성된다.
우리는 256x256 이미지에서 무작위 224 × 224 패치(및 이들의 수평 반사)를 추출하고 이러한 추출된 패치 4에 대해 네트워크를 훈련시킴으로써 이를 수행한다.
이는 훈련의 크기를 2048배까지 증가시키지만, 결과적인 훈련 예는 물론 상호의존성이 높다.
이 계획이 없었다면, 우리의 네트워크는 상당한 과적합으로 인해 어려움을 겪었고, 이로 인해 우리는 훨씬 더 작은 네트워크를 사용해야 했을 것이다.
테스트 시간에, 네트워크는 5개의 224 × 224 패치(네 개의 코너 패치와 중앙 패치)와 수평 반사(따라서 모두 패치)를 추출하고, 10개의 패치에 대해 네트워크의 소프트맥스 계층에 의해 만들어진 예측을 평균화함으로써 예측을 한다.
두 번째 형태의 데이터 확대는 훈련 이미지에서 RGB 채널의 강도를 변경하는 것으로 구성된다.
구체적으로, 우리는 ImageNet 교육 세트 전체에서 RGB 픽셀 값의 집합에 대해 PCA를 수행한다.
각 훈련 이미지에 발견된 주성분의 배수를 평균 0과 표준 편차 0.1의 가우스에서 추출한 임의의 변수 시간에 비례하는 크기로 추가한다.
따라서 각 RGB 이미지 픽셀 = T에 다음 양을 추가합니다.
여기서 와 는 고유 벡터와 RGB 픽셀 값의 고유값이며 는 각각 이다.
각 는 특정 훈련 이미지의 모든 픽셀에 대해 한 번만 그려지며, 해당 이미지가 다시 훈련에 사용된다.
이 체계는 자연 이미지의 중요한 속성, 즉 객체 ID가 조명의 강도와 색상의 변화에 불변한다는 것을 대략적으로 포착한다.
이 체계는 상위 1개 오류율을 1% 이상 줄입니다.
- 이것이 그림 2의 입력 영상이 224 × 224 × 3차원인 이유입니다.
4.2 Dropout
많은 다른 모델의 예측을 결합하는 것은 테스트 오류를 줄이는 매우 성공적인 방법이지만 [1, 3] 이미 훈련하는 데 며칠이 걸리는 대형 신경망에는 너무 비싼 것으로 보인다.
그러나, 훈련 중에 약 2배만 드는 매우 효율적인 모델 조합 버전이 있다. 최근에 도입된 "dropout"[10] 기법은 0.5 확률로 각 숨겨진 뉴런의 출력을 0으로 설정한다.
이런 식으로 "탈락"되는 뉴런은 전진 패스에 기여하지 않으며 역 전파에도 참여하지 않습니다.
그래서 입력이 제시될 때마다 신경망은 다른 아키텍처를 샘플링하지만, 이러한 모든 아키텍처들은 가중치를 공유한다.
이 기술은 뉴런이 특정한 다른 뉴런의 존재에 의존할 수 없기 때문에 뉴런의 복잡한 공동 적응을 감소시킨다.
따라서 다른 뉴런의 많은 다른 무작위 하위 집합과 함께 유용한 더 강력한 특징을 학습하도록 강요된다.
테스트 시간에 우리는 모든 뉴런을 사용하지만 출력에 0.5를 곱한다.
이는 지수적으로 많은 드롭아웃 네트워크에 의해 생성된 예측 분포의 기하학적 평균을 취하는 합리적인 근사치이다.
우리는 그림 2의 처음 두 개의 완전히 연결된 계층에서 드롭아웃을 사용한다.
중퇴자가 없으면 우리 네트워크는 상당한 과적합을 보인다.
중퇴는 수렴에 필요한 반복 횟수를 대략 두 배로 늘린다.
5. Details of learning
우리는 128개의 예제 배치 크기, 0.9의 운동량, 0.0005의 무게 감소와 함께 확률적 기울기 강하를 사용하여 모델을 훈련시켰다.
우리는 이 작은 양의 체중 감퇴가 모델이 학습하는 데 중요하다는 것을 발견했습니다. 다시 말해서, 여기서 체중 감퇴는 단순한 정규화가 아니라 모델의 훈련 오류를 감소시킨다. 가중치에 대한 업데이트 규칙은 다음과 같습니다.
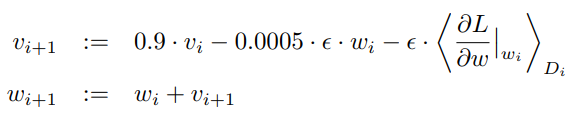
여기서 는 반복 지수, 는 모멘텀 변수, 은 학습 속도, 그리고
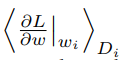
는 에서 평가된 에 대한 목표 파생물의 번째 배치 에 대한 평균입니다.
표준 편차 0.01의 0 평균 가우스 분포에서 각 계층의 가중치를 초기화했다.
우리는 두 번째, 네 번째 및 다섯 번째 컨볼루션 레이어와 완전히 연결된 은닉 레이어에서 뉴런 편향을 상수 1로 초기화했다.
이 초기화는 ReLU에 긍정적인 입력을 제공함으로써 학습의 초기 단계를 가속화한다.
우리는 상수 0으로 나머지 층에서 뉴런 편향을 초기화했다.
우리는 모든 계층에 대해 동일한 학습 속도를 사용했으며, 훈련 내내 수동으로 조정했다.
우리가 추적한 경험적 접근은 검증 오류율이 현재 학습 속도에 따라 개선되지 않을 때 학습 속도를 10으로 나누는 것이었다.
학습 속도는 0.01로 초기화되었고 종료 전에 세 번 감소되었습니다.
우리는 두 개의 NVIDIA GTX 580 3GB GPU에서 5일에서 6일이 걸리는 120만 개의 이미지 훈련 세트를 통해 네트워크를 약 90 사이클 동안 훈련시켰다.
그림 3: 224x224x3 입력 이미지에서 첫 번째 컨볼루션 레이어가 학습한 11x11×3 크기의 컨볼루션 커널 96개. 상위 48개 커널은 GPU 1에서 학습되었고 하위 48개 커널은 GPU 2에서 학습되었다. 자세한 내용은 섹션 6.1을 참조한다.

6. Results
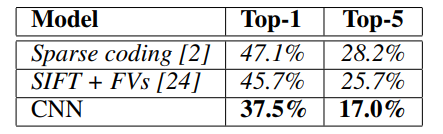
ILSVRC-2010에 대한 우리의 결과는 표 1에 요약되어 있다. 우리 네트워크는 37.5%와 17.0%5의 상위 1위 및 상위 5위 테스트 세트 오류율을 달성한다.
ILSVRC 2010 대회에서 달성한 최고의 성능은 다른 특징에 대해 훈련된 6개의 희소 코딩 모델에서 생성된 예측을 평균하는 접근법으로 47.1%, 28.2%였으며, 그 이후 가장 잘 발표된 결과는 피셔에서 훈련된 2개의 분류기 예측으로 평균하는 접근법으로 45.7%와 25.7%이다. 두 가지 유형의 촘촘하게 샘플링된 특징에서 계산된 벡터(FV) [24].
표 1: ILSVRC 2010 테스트 세트의 결과 비교. 이탤릭체에서는 다른 사람들이 성취한 최상의 결과이다.
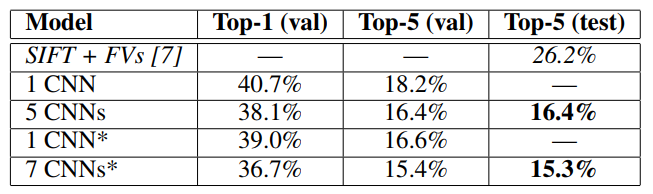
우리는 또한 ILSVRC-2012 대회에 모델을 출품하여 표 2에 결과를 보고하였다.
ILSVRC-2012 테스트 세트 라벨은 공개적으로 사용할 수 없으므로, 우리가 시도한 모든 모델에 대한 테스트 오류율을 보고할 수는 없다.
이 단락의 나머지 부분에서는 검증 오류율과 테스트 오류율이 0.1% 이상 차이가 나지 않기 때문에 서로 교환하여 사용합니다(표 2 참조).
본 논문에서 설명한 CNN은 상위 5개 오류율 18.2%를 달성한다. 5개의 유사한 CNN의 예측을 평균하면 16.4%의 오류율을 제공한다. 마지막 풀링 레이어에 대해 6번째 컨볼루션 레이어를 가진 CNN을 훈련시켜 전체 ImageNet Fall 2011 릴리스(15M 이미지, 22K 범주)를 분류한 다음 ILSVRC-2012에서 "세밀하게 조정"하면 오류율이 16.6%가 된다.
앞서 언급한 5개의 CNN을 사용하여 2011년 가을 전체 릴리스에서 사전 훈련된 두 CNN의 예측을 평균하면 15.3%의 오류율을 얻을 수 있다.
두 번째로 우수한 콘테스트 항목은 다른 유형의 촘촘하게 샘플링된 기능에서 계산된 FV에 대해 훈련된 여러 분류기의 예측을 평균하는 접근법으로 26.2%의 오류율을 달성했다[7].
표 2: ILSVRC-2012 검증 및 테스트 세트의 오류율 비교. 이탤릭체에서는 다른 사람들이 성취한 최상의 결과이다.
별표(*)가 있는 모델은 ImageNet 2011 Fall 릴리즈 전체를 분류하기 위해 "사전 교육"되었습니다.
자세한 내용은 섹션 6을 참조하십시오.
마지막으로, 우리는 또한 10,184개의 범주와 890만 개의 이미지를 가진 2009년 가을 버전의 ImageNet에 대한 오류율을 보고한다.
이 데이터 세트에서는 이미지의 절반을 훈련에 사용하고 절반은 테스트에 사용하는 문헌의 관례를 따른다.
확립된 테스트 세트가 없기 때문에, 우리의 분할은 반드시 이전 작성자가 사용한 분할과 다르지만, 이는 결과에 크게 영향을 미치지 않는다.
이 데이터 세트에서 상위 1위와 상위 5위의 오류율은 67.4%와 40.9%이며, 위에서 설명한 순에 의해 달성되지만 마지막 풀링 레이어에 6번째 컨볼루션 레이어가 추가된다.
이 데이터 세트에 대해 가장 잘 발표된 결과는 78.1%와 60.9%[19]이다.
6.1 Qualitative Evaluations
그림 3은 네트워크의 두 데이터 연결 계층에서 학습한 컨볼루션 커널을 보여준다.
네트워크는 다양한 색상의 블럽뿐만 아니라 다양한 주파수 및 방향 선택 커널을 학습했다.
섹션 3.5에 설명된 제한된 연결의 결과인 두 GPU에 의해 표시되는 전문화에 주목한다.
GPU 1의 커널은 대체로 색에 구애받지 않는 반면 GPU 2의 커널은 대부분 색에 따라 다르다.
이러한 종류의 전문화는 모든 실행 중에 발생하며 특정 무작위 가중치 초기화(GPU의 모듈 번호 변경)와는 무관하다.
- 섹션 4.1에 설명된 대로 10개 패치에 대한 평균 예측이 없는 오류율은 39.0%이며
18.3%
그림 4: (왼쪽) 8개의 ILSVRC-2010 테스트 이미지와 우리 모델에 의해 가장 가능성이 높은 것으로 간주되는 5개의 라벨.
각 이미지 아래에 올바른 라벨이 기록되고, 올바른 라벨에 할당된 확률도 빨간색 막대와 함께 표시됩니다 (상단 5에 해당하는 경우).

(오른쪽) 첫 번째 열에 다섯 개의 ILSVRC-2010 테스트 영상이 표시됩니다.
나머지 열은 테스트 이미지에 대한 피처 벡터로부터 유클리드 거리가 가장 작은 마지막 은닉 레이어에서 피처 벡터를 생성하는 6개의 훈련 이미지를 보여준다.
그림 4의 왼쪽 패널에서 우리는 8개의 테스트 이미지에 대한 상위 5개의 예측을 계산하여 네트워크가 무엇을 배웠는지를 질적으로 평가한다.
왼쪽 상단에 있는 진드기와 같은 중앙을 벗어난 개체도 넷으로 인식할 수 있습니다.
상위 5개 레이블은 대부분 합리적입니다.
예를 들어, 다른 유형의 고양이만 표범의 그럴듯한 라벨로 간주됩니다. 어떤 경우에는 사진의 의도된 초점에 대해 정말로 애매한 부분이 있습니다.
네트워크의 시각적 지식을 조사하는 또 다른 방법은 마지막 4096차원 은닉 계층에서 이미지에 의해 유도된 기능 활성화를 고려하는 것이다.
두 개의 영상이 작은 유클리드 분리를 가진 특징 활성화 벡터를 생성하는 경우, 신경망의 상위 레벨은 이러한 벡터를 유사한 것으로 간주한다고 말할 수 있다.
그림 4는 이 측정에 따라 테스트 세트의 영상 5개와 교육 세트의 영상 6개를 보여줍니다.
픽셀 수준에서 검색된 교육 영상은 일반적으로 첫 번째 열의 쿼리 이미지에 L2에서 가깝지 않습니다.
예를 들어, 검색된 개와 코끼리는 다양한 포즈로 나타납니다. 우리는 보충 자료에 더 많은 테스트 이미지에 대한 결과를 제시한다.
두 4096차원 실제 값 벡터 사이의 유클리드 거리를 사용하여 유사성을 계산하는 것은 비효율적이지만, 자동 인코더를 훈련하여 이러한 벡터를 짧은 이진 코드로 압축함으로써 효율적일 수 있다.
이렇게 하면 이미지 레이블을 사용하지 않으므로 에지의 패턴이 비슷한 이미지를 의미적으로 유사하든 그렇지 않든 검색하는 경향이 있는 원시 픽셀[14]에 자동 인코더를 적용하는 것보다 훨씬 더 나은 이미지 검색 방법을 생성할 수 있다.
7. Discussion
우리의 결과는 거대하고 심층적인 컨볼루션 신경망이 순수하게 지도된 학습을 사용하여 매우 어려운 데이터 세트에서 기록을 깨는 결과를 달성할 수 있음을 보여준다.
단일 컨볼루션 레이어를 제거하면 네트워크 성능이 저하되는 것이 주목할 만하다.
예를 들어, 중간 계층을 제거하면 네트워크의 상위 1개 성능에 대해 약 2%의 손실이 발생한다. 그래서 우리의 결과를 얻기 위해서는 깊이가 정말 중요합니다.
실험을 단순화하기 위해, 특히 레이블이 지정된 데이터의 양을 증가시키지 않고 네트워크의 크기를 크게 증가시킬 수 있는 충분한 계산 능력을 얻는 경우 도움이 될 것으로 예상함에도 불구하고, 우리는 감독되지 않은 사전 훈련을 사용하지 않았다.
지금까지, 우리의 결과는 네트워크를 더 크게 만들고 더 오래 훈련시켰기 때문에 향상되었지만, 우리는 인간 시각 시스템의 초시적 경로에 맞추기 위해 여전히 가야 할 많은 크기의 순서를 가지고 있다.
궁극적으로 우리는 시간적 구조가 정적 이미지에서 누락되거나 훨씬 덜 분명한 매우 유용한 정보를 제공하는 비디오 시퀀스에 매우 크고 깊은 컨볼루션 네트를 사용하고 싶다.
References
[1] R.M. Bell and Y. Koren. Lessons from the netflix prize challenge. ACM SIGKDD Explorations Newsletter, 9(2):75–79, 2007.
[2] A. Berg, J. Deng, and L. Fei-Fei. Large scale visual recognition challenge 2010. www.imagenet.org/challenges. 2010.
[3] L. Breiman. Random forests. Machine learning, 45(1):5–32, 2001.
[4] D. Cire¸san, U. Meier, and J. Schmidhuber. Multi-column deep neural networks for image classification. Arxiv preprint arXiv:1202.2745, 2012.
[5] D.C. Cire¸san, U. Meier, J. Masci, L.M. Gambardella, and J. Schmidhuber. High-performance neural
networks for visual object classification. Arxiv preprint arXiv:1102.0183, 2011.
[6] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical
Image Database. In CVPR09, 2009.
[7] J. Deng, A. Berg, S. Satheesh, H. Su, A. Khosla, and L. Fei-Fei. ILSVRC-2012, 2012. URL
http://www.image-net.org/challenges/LSVRC/2012/.
[8] L. Fei-Fei, R. Fergus, and P. Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. Computer Vision and Image Understanding, 106(1):59–70, 2007.
[9] G. Griffin, A. Holub, and P. Perona. Caltech-256 object category dataset. Technical Report 7694, California Institute of Technology, 2007. URL http://authors.library.caltech.edu/7694.
[10] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[11] K. Jarrett, K. Kavukcuoglu, M. A. Ranzato, and Y. LeCun. What is the best multi-stage architecture for object recognition? In International Conference on Computer Vision, pages 2146–2153. IEEE, 2009.
[12] A. Krizhevsky. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
[13] A. Krizhevsky. Convolutional deep belief networks on cifar-10. Unpublished manuscript, 2010.
[14] A. Krizhevsky and G.E. Hinton. Using very deep autoencoders for content-based image retrieval. In ESANN, 2011.
[15] Y. Le Cun, B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard, L.D. Jackel, et al. Handwritten digit recognition with a back-propagation network. In Advances in neural information processing systems, 1990.
[16] Y. LeCun, F.J. Huang, and L. Bottou. Learning methods for generic object recognition with invariance to
pose and lighting. In Computer Vision and Pattern Recognition, 2004. CVPR 2004. Proceedings of the
2004 IEEE Computer Society Conference on, volume 2, pages II–97. IEEE, 2004.
[17] Y. LeCun, K. Kavukcuoglu, and C. Farabet. Convolutional networks and applications in vision. In
Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on, pages 253–256.
IEEE, 2010.
[18] H. Lee, R. Grosse, R. Ranganath, and A.Y. Ng. Convolutional deep belief networks for scalable unsupervised
learning of hierarchical representations. In Proceedings of the 26th Annual International Conference
on Machine Learning, pages 609–616. ACM, 2009.
[19] T. Mensink, J. Verbeek, F. Perronnin, and G. Csurka. Metric Learning for Large Scale Image Classification:
Generalizing to New Classes at Near-Zero Cost. In ECCV - European Conference on Computer
Vision, Florence, Italy, October 2012.
[20] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th
International Conference on Machine Learning, 2010.
[21] N. Pinto, D.D. Cox, and J.J. DiCarlo. Why is real-world visual object recognition hard? PLoS computational
biology, 4(1):e27, 2008.
[22] N. Pinto, D. Doukhan, J.J. DiCarlo, and D.D. Cox. A high-throughput screening approach to discovering good forms of biologically inspired visual representation. PLoS computational biology, 5(11):e1000579, 2009.
[23] B.C. Russell, A. Torralba, K.P. Murphy, and W.T. Freeman. Labelme: a database and web-based tool for image annotation. International journal of computer vision, 77(1):157–173, 2008.
[24] J. Sánchez and F. Perronnin. High-dimensional signature compression for large-scale image classification. In Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on, pages 1665–1672. IEEE, 2011.
[25] P.Y. Simard, D. Steinkraus, and J.C. Platt. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, volume 2, pages 958–962, 2003.
[26] S.C. Turaga, J.F. Murray, V. Jain, F. Roth, M. Helmstaedter, K. Briggman, W. Denk, and H.S. Seung. Convolutional networks can learn to generate affinity graphs for image segmentation. Neural Computation, 22(2):511–538, 2010.