Abstract
수용 영역 내의 로컬 패치에 대한 모델 차별성을 강화하기 위해 "네트워크 내 네트워크"(NIN)라는 새로운 심층 네트워크 구조를 제안한다. 기존의 컨볼루션 레이어는 선형 필터를 사용한 후 비선형 활성화 함수를 사용하여 입력을 스캔한다.
대신, 우리는 수용적 분야 내에서 데이터를 추상화하기 위해 더 복잡한 구조를 가진 마이크로 신경망을 구축한다.
우리는 강력한 함수 근사치인 다층 퍼셉트론을 사용하여 마이크로 신경망을 인스턴스화한다.
기능 맵은 CNN과 유사한 방식으로 마이크로 네트워크를 입력 위로 밀어낸 다음 다음 다음 레이어로 공급한다.
Deep NIN은 위에서 설명한 구조의 두 개를 쌓음으로써 구현될 수 있다.
마이크로 네트워크를 통한 향상된 로컬 모델링을 통해, 우리는 분류 계층에서 기능 맵에 대한 글로벌 평균 풀링을 활용할 수 있으며, 이는 기존의 완전히 연결된 계층보다 해석하기 쉽고 과적합하기 쉽다.
CIFAR-10 및 CIFAR-100에서 NIN을 사용한 최첨단 분류 성능과 SVHN 및 MNIST 데이터 세트에서 합리적인 성능을 시연했다.
1. Introduction
컨볼루션 신경망(CNN) [1]은 교대 컨볼루션 레이어와 풀링 레이어로 구성된다.
컨볼루션 레이어는 선형 필터와 기본 수용 필드의 내부 곱을 취한 후 입력의 모든 로컬 부분에서 비선형 활성화 함수를 취한다.
결과 출력을 피쳐 맵이라고 합니다.
CNN의 컨볼루션 필터는 기본 데이터 패치를 위한 일반화된 선형 모델(GLM)이며, 우리는 GLM에서 추상화 수준이 낮다고 주장한다.
추상화에 의해 우리는 특성이 동일한 개념의 변형에 불변함을 의미한다[2].
GLM을 보다 강력한 비선형 함수 근사치로 대체하면 로컬 모델의 추상화 능력을 향상시킬 수 있다.
GLM은 잠재 개념의 샘플이 선형적으로 분리될 수 있을 때,
즉 모든 개념의 변형이 GLM에 의해 정의된 분리 평면의 한쪽에 존재할 때 추상화의 상당한 정도를 달성할 수 있다.
따라서 기존의 CNN은 잠재 개념이 선형적으로 분리 가능하다는 가정을 암시적으로 만든다.
그러나 동일한 개념에 대한 데이터는 종종 비선형 매니폴드에 존재하므로, 이러한 개념을 포착하는 표현은 일반적으로 입력의 비선형 함수가 높다.
NIN에서 GLM은 일반적인 비선형 함수 근사치인 "마이크로 네트워크" 구조로 대체된다.
본 연구에서, 우리는 마이크로 네트워크의 인스턴스화로 다중 계층 지각론[3]을 선택하는데, 이는 범용 함수 근사치이며 역 전파에 의해 훈련될 수 있는 신경망이다.
그림 1: 선형 컨볼루션 계층과 mlpconv 계층의 비교.
선형 컨볼루션 레이어는 선형 필터를 포함하며, mlpconv 레이어는 마이크로 네트워크를 포함한다(이 논문에서 다층 퍼셉트론을 선택한다).
두 계층 모두 로컬 수용 필드를 잠재 개념의 신뢰 값에 매핑한다.
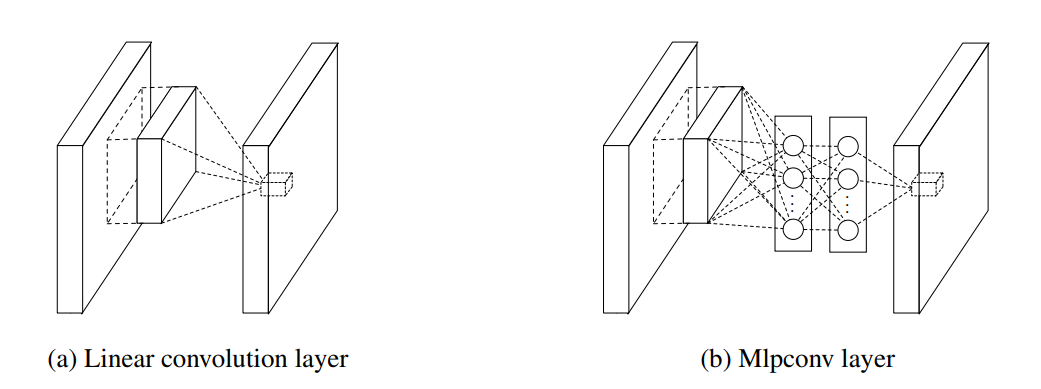
우리가 mlpconv 레이어라고 부르는 결과 구조는 그림 1의 CNN과 비교된다.
선형 컨볼루션 레이어와 mlpconv 레이어 모두 로컬 수신 필드를 출력 피처 벡터에 매핑한다.
mlpconv는 비선형 활성화 기능을 가진 여러 개의 완전히 연결된 레이어로 구성된 다중 계층 퍼셉트론(MLP)을 사용하여 입력 로컬 패치를 출력 피쳐 벡터에 매핑한다.
MLP는 모든 로컬 수신 필드 간에 공유됩니다.
기능 맵은 CNN과 유사한 방식으로 입력 위로 MLP를 밀어낸 다음 다음 다음 레이어로 공급된다.
NIN의 전체적인 구조는 여러 mlp conv 레이어의 적층이다.
전체 심층 네트워크의 요소를 구성하는 마이크로 네트워크(MLP)가 mlpconv 계층 내에 있기 때문에 "네트워크 내 네트워크"(NIN)라고 불리며, CNN의 분류를 위해 기존의 완전히 연결된 계층을 채택하는 대신 마지막 mlpconv 계층의 공간 평균을 c의 신뢰로 직접 출력한다.
범주는 글로벌 평균 풀링 레이어를 거쳐서 결과 벡터는 소프트맥스 레이어에 공급된다.
기존 CNN에서는 중간에서 블랙박스 역할을 하는 완전히 연결된 계층 때문에 목표 비용 계층의 범주 수준 정보가 이전 컨볼루션 계층으로 다시 전달되는 방식을 해석하기 어렵다.
대조적으로, 전역 평균 풀링은 마이크로 네트워크를 사용한 강력한 로컬 모델링에 의해 가능해진 특징 맵과 범주 간의 대응을 시행하기 때문에 더 의미 있고 해석 가능하다.
또한 완전히 연결된 계층은 과적합되기 쉽고 드롭아웃 정규화[4][5]에 크게 의존하는 반면, 전역 평균 풀링은 전체 구조에 대한 과적합을 기본적으로 방지하는 구조 정규화 그 자체이다.
2. Convolutional Neural Networks
고전적인 컨볼루션 뉴런 네트워크[1]는 대체적으로 쌓인 컨볼루션 레이어와 공간 풀링 레이어로 구성된다.
컨볼루션 레이어는 비선형 활성화 함수(정화기, 시그모이드, 탄 등)에 이어 선형 컨볼루션 필터에 의해 형상 맵을 생성한다.
선형 정류기를 예로 들어 기능 맵은 와 같이 계산할 수 있습니다.

여기서 ()는 피쳐 맵의 픽셀 인덱스이고, 는 위치 중심의 입력 패치를 나타냅니다.
() 및 는 형상 지도의 채널을 인덱싱하는 데 사용됩니다.
이 선형 컨볼루션은 잠재 개념의 인스턴스들이 선형적으로 분리될 때 추상화에 충분하다.
그러나 우수한 추상화를 달성하는 표현은 일반적으로 입력 데이터의 비선형 함수가 높다.
기존 CNN에서, 이는 잠재 개념의 모든 변형을 다루기 위해 지나치게 완전한 필터 세트[6]를 활용하여 보상할 수 있다. 즉, 개별 선형 필터는 동일한 개념의 다른 변화를 감지하는 방법을 학습할 수 있다.
그러나 단일 개념에 대한 필터가 너무 많으면 이전 계층으로부터의 모든 변동 조합을 고려해야 하는 다음 계층에는 추가 부담이 발생한다 [7].
CNN과 마찬가지로, 상위 레이어의 필터는 원래 입력에서 더 큰 영역으로 매핑된다.
아래 계층에서 하위 수준 개념을 결합하여 상위 수준 개념을 생성한다.
따라서, 우리는 각 로컬 패치를 더 높은 수준의 개념으로 결합하기 전에 더 나은 추상화를 수행하는 것이 유익할 것이라고 주장한다.
최근의 maxout network [8]에서, 피처 맵의 수는 아핀 피처 맵에 대한 최대 풀링에 의해 감소된다.
(아핀 피처 맵은 활성화 함수를 적용하지 않고 선형 컨볼루션의 직접적인 결과이다.)
선형 함수에 대한 최대화는 모든 볼록 함수를 근사화할 수 있는 조각별 선형 근사치를 만든다.
선형 분리를 수행하는 기존의 컨볼루션 레이어에 비해, 최대 출력 네트워크는 볼록 세트 내에 있는 개념을 분리할 수 있기 때문에 더 강력하다.
이 개선은 여러 벤치마크 데이터 세트에서 최고의 성능을 발휘하는 최대 출력 네트워크를 가능하게 한다.
그러나 maxout 네트워크는 잠재 개념의 인스턴스들이 입력 공간의 볼록 집합 내에 있다는 선호를 부과하며, 이것이 반드시 유지되지는 않는다.
잠재된 개념의 분포가 더 복잡한 경우 더 일반적인 함수 근사치를 사용할 필요가 있을 것이다.
우리는 로컬 패치에 대한 보다 추상적인 특징을 계산하기 위해 각 컨볼루션 계층 내에 마이크로 네트워크가 도입되는 새로운 "네트워크 내 네트워크" 구조를 도입하여 이를 달성하고자 한다.
입력 위로 마이크로 네트워크를 슬라이딩하는 것은 몇몇 이전 연구에서 제안되었다.
예를 들어, 구조화 다층 퍼셉트론(SMLP) [9]은 공유 다층 퍼셉트론을 입력 이미지의 다른 패치에 적용한다.
다른 작업에서는 신경망 기반 필터가 얼굴 탐지에 대해 훈련된다[10].
그러나 둘 다 특정 문제를 위해 설계되었으며 둘 다 슬라이딩 네트워크 구조의 한 층만 포함하고 있다.
NIN은 보다 일반적인 관점에서 제안되며, 마이크로 네트워크는 모든 기능 수준에 대한 더 나은 추상화를 설득하기 위해 CNN 구조에 통합된다.
3. Network In Network
먼저 제안된 "Network In Network" 구조의 주요 구성 요소인 MLP 컨볼루션 계층과 3.1절과 3.2절의 글로벌 평균 풀링 계층을 강조한다. 그러면 3.3절에 전체적인 NIN에 대해 자세히 설명하겠습니다.
3.1 MLP Convolution Layers
잠재 개념의 분포에 대한 이전이 없다면, 잠재 개념의 더 추상적인 표현을 근사화할 수 있기 때문에 로컬 패치의 특징 추출을 위해 범용 함수 근사치를 사용하는 것이 바람직하다.
방사형 기본 네트워크와 다층 퍼셉트론은 잘 알려진 두 개의 범용 함수 근사치이다.
우리는 두 가지 이유로 이 연구에서 다층 퍼셉트론을 선택한다.
첫째, 다층 퍼셉트론은 역 전파를 사용하여 훈련된 컨볼루션 신경망 구조와 호환된다.
둘째, 다층 퍼셉트론은 기능 재사용 정신[2]과 일치하는 심층 모델 그 자체일 수 있다.
이 새로운 유형의 레이어는 본 논문에서 MLP가 GLM을 대체하여 입력을 융합하는 mlpconv라고 한다.
그림 1은 선형 컨볼루션 레이어와 mlpconv 레이어의 차이를 보여준다.
mlpconv 레이어에 의해 수행되는 계산은 다음과 같다:
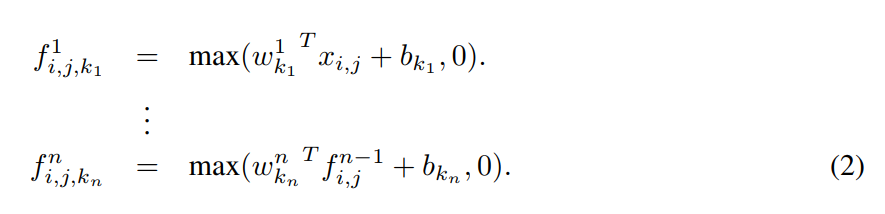
여기에 다층 퍼셉트론의 층 수가 있다.
정류된 선형 단위는 다층 퍼셉트론에서 활성화 기능으로 사용됩니다.
교차 채널(교차 피쳐 맵) 풀링 관점에서, 방정식 2는 일반 컨볼루션 레이어의 계단식 교차 채널 매개 변수 풀링과 같다.
각 풀링 레이어는 입력 피쳐 맵에서 가중 선형 재조합을 수행한 다음 정류자 선형 단위를 통과한다.
교차 채널 풀링된 피쳐 맵은 다음 레이어에서 교차 채널 풀링됩니다.
이 계단식 교차 채널 매개 변수 풀링 구조는 교차 채널 정보의 복잡하고 학습 가능한 상호 작용을 허용한다.
교차 채널 매개 변수 풀링 계층은 또한 1x1 컨볼루션 커널을 가진 컨볼루션 계층과 동일하다.
이 해석은 NIN의 구조를 이해하기에 직설적이다.
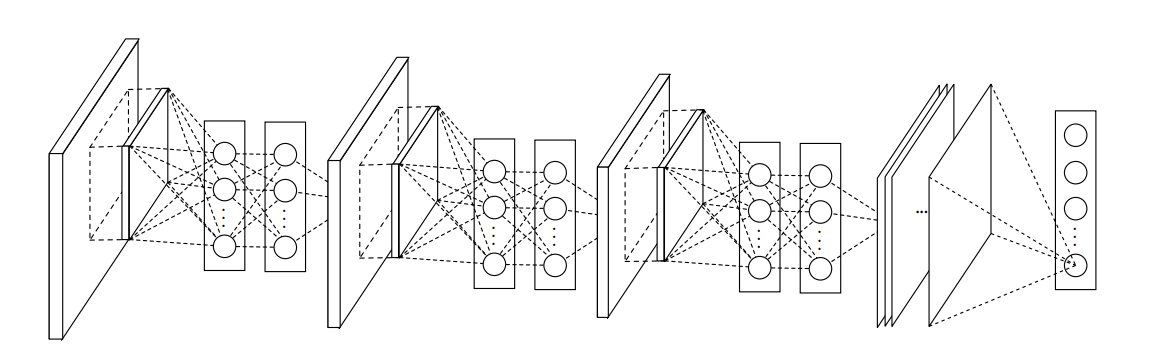
그림 2: 네트워크 내 네트워크의 전체 구조
본 논문에서 NIN은 3개의 mlp conv 레이어와 1개의 글로벌 평균 풀링 레이어의 스택을 포함한다.
maxout 계층과의 비교: maxout 네트워크의 maxout 계층은 여러 아핀 피처 맵에서 최대 풀링을 수행한다 [8]. 최대 출력 계층의 기능 맵은 다음과 같이 계산됩니다.

선형 함수에 대한 최대 출력은 모든 볼록 함수를 모델링할 수 있는 조각 선형 함수를 형성합니다.
볼록 함수의 경우, 함수 값이 특정 임계값보다 낮은 표본이 볼록 집합을 형성합니다.
따라서, 국소 패치의 볼록함수를 근사함으로써, maxout은 샘플이 볼록 세트 내에 있는 개념(즉, 볼, 볼록 원뿔)에 대해 분리 하이퍼플레인을 형성할 수 있는 기능을 가지고 있다.
Mlpconv 레이어는 볼록함수 근사치가 범용함수 근사치로 대체된다는 점에서 maxout 레이어와 다르며, 이는 잠재 개념의 다양한 분포를 모델링하는 데 더 큰 능력을 가지고 있다.
3.2 Global Average Pooling
기존의 컨볼루션 신경망은 네트워크의 하위 계층에서 컨볼루션(convolution)을 수행한다.
분류를 위해, 마지막 컨볼루션 레이어의 피처 맵은 벡터화되어 완전히 연결된 레이어로 공급되고, 그 다음에 소프트맥스 로지스틱 회귀 계층[4][8][11]이 공급된다.
이 구조는 컨볼루션 구조를 전통적인 신경망 분류기와 연결한다.
그것은 컨볼루션 레이어를 형상 추출기로 취급하며, 결과 형상은 전통적인 방식으로 분류된다.
그러나 완전히 연결된 계층은 과적합되기 쉬우므로 전체 네트워크의 일반화 능력을 방해한다.
중퇴는 힌튼 외 연구진에 의해 제안되었다. [5]
정규화로서, 훈련 중에 완전히 연결된 층에 대한 활성화의 절반을 무작위로 0으로 설정합니다.
일반화 능력이 향상되었고 과적합이 방지되었다[4].
본 논문에서, 우리는 CNN의 전통적인 완전히 연결된 계층을 대체하는 글로벌 평균 풀링이라는 또 다른 전략을 제안한다. 아이디어는 마지막 mlpconv 계층에서 분류 작업의 각 해당 범주에 대해 하나의 특징 맵을 생성하는 것이다.
피처 맵 위에 완전히 연결된 레이어를 추가하는 대신, 우리는 각 피처 맵의 평균을 취하고, 결과 벡터는 소프트맥스 레이어에 직접 공급된다.
완전히 연결된 레이어에 대한 글로벌 평균 풀링의 한 가지 장점은 피처 맵과 범주 간의 대응을 시행함으로써 컨볼루션 구조에 더 기본적이라는 것이다.
따라서 형상 맵은 범주 신뢰 맵으로 쉽게 해석될 수 있다.
또 다른 장점은 전역 평균 풀링에서 최적화할 매개 변수가 없기 때문에 이 계층에서 과적합이 방지된다는 것이다.
또한, 전역 평균 풀링은 공간 정보를 요약하므로 입력의 공간 번역에 더욱 강력하다.
우리는 글로벌 평균 풀링을 개념(범주)의 신뢰 맵이 되도록 기능 맵을 명시적으로 강제하는 구조적 정규화기로 볼 수 있다.
이것은 mlpconv 레이어가 GLM보다 신뢰 맵에 더 나은 근사치를 만들기 때문에 가능하다.
3.3 Network In Network Structure
NIN의 전체적인 구조는 mlpconv 레이어의 스택이며, 그 위에 글로벌 평균 풀링과 목표 비용 레이어가 있다.
하위 샘플링 레이어는 CNN과 maxout 네트워크에서와 같이 mlp conv 레이어 사이에 추가할 수 있다.
그림 2는 세 개의 mlp conv 레이어가 있는 NIN을 보여준다.
각 mlpconv 계층에는 3계층 퍼셉트론이 있다.
NIN과 마이크로 네트워크 모두에서 계층 수는 유동적이며 특정 작업에 맞게 조정될 수 있다.
4. Experiments
4.1 Overview
CIFAR-10[12], CIFAR-100[12], SVHN[13] 및 MNIST[1]의 네 가지 벤치마크 데이터 세트에서 NIN을 평가한다.
데이터 세트에 사용되는 네트워크는 모두 3개의 스택형 mlpconv 레이어로 구성되며, 모든 실험에서 mlpconv 레이어는 입력 이미지를 2배로 다운 샘플링하는 공간 최대 풀링 레이어로 이어진다.
레귤레이터로서 드롭아웃은 마지막 mlpconv 레이어를 제외한 모든 출력에 적용된다.
구체적으로 명시되지 않는 한, 실험 섹션에서 사용되는 모든 네트워크는 네트워크 상단에 완전히 연결된 계층 대신 전역 평균 풀링을 사용한다.
적용되는 또 다른 정규화기는 크리셰프스키 외 연구진이 사용한 체중 감퇴이다 [4].
그림 2는 이 섹션에서 사용되는 NIN 네트워크의 전체적인 구조를 보여줍니다.
파라미터의 자세한 설정은 보충 자료에 나와 있습니다.
우리는 Alex Krizhevsky에 의해 개발된 초고속 큐다-콘넷 코드에 우리의 네트워크를 구현한다[4]. 데이터 세트의 사전 처리, 훈련 및 검증 세트의 분할은 모두 Goodfellow 등[8]을 따른다.
우리는 크리제프스키 외 연구진 등이 사용하는 훈련 절차를 채택한다. [4].
즉, 가중치와 학습 속도에 대한 적절한 초기화를 수동으로 설정한다.
네트워크는 128 크기의 미니 배치를 사용하여 훈련된다.
훈련 과정은 초기 가중치와 학습 속도에서 시작하여 훈련 세트의 정확도가 향상되는 것을 멈출 때까지 계속되며, 그 다음 학습 속도가 10의 척도로 낮아진다.
이 절차는 최종 학습 속도가 초기 값의 1%가 되도록 반복한다.
4.2 CIFAR-10
CIFAR-10 데이터 세트[12]는 총 50,000개의 훈련 영상과 10,000개의 테스트 영상으로 구성된 10개 클래스의 자연 영상으로 구성된다.
각 이미지는 32x32 크기의 RGB 이미지입니다.
이 데이터 세트의 경우 Goodfellow 등이 사용한 것과 동일한 글로벌 대비 정규화와 ZCA 화이트닝을 적용한다.
최대 출력 네트워크[8]에 있습니다.
우리는 교육 세트의 마지막 10,000개의 이미지를 검증 데이터로 사용한다.
이 실험에서 각 mlpconv 계층에 대한 형상 맵의 수는 해당 maxout 네트워크에서와 동일한 수로 설정된다.
두 개의 하이퍼 파라미터는 유효성 검사 세트를 사용하여 조정됩니다.
즉, 로컬 수용 필드 크기와 무게 감소입니다.
그런 다음 하이퍼 파라미터가 고정되고 교육 세트와 검증 세트를 모두 사용하여 네트워크를 처음부터 다시 교육합니다.
결과 모델이 테스트에 사용됩니다.
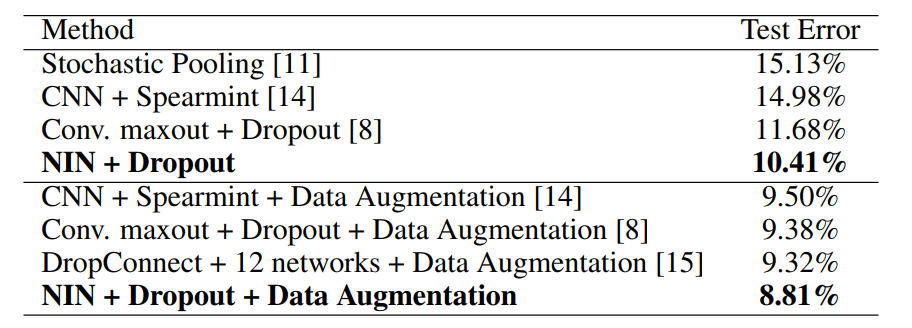
우리는 이 데이터 세트에서 10.41%의 테스트 오류를 얻는데, 이는 최첨단 데이터 세트에 비해 1% 이상 향상된다.
이전 방법과의 비교는 표 1과 같다.
표 1: 다양한 방법의 CIFAR-10에 대한 오류율을 테스트합니다.
우리의 실험에서 NIN에서 mlpconv 계층 사이에서 드롭아웃을 사용하면 모델의 일반화 능력을 향상시켜 네트워크의 성능을 향상시킨다는 것이 밝혀졌다.
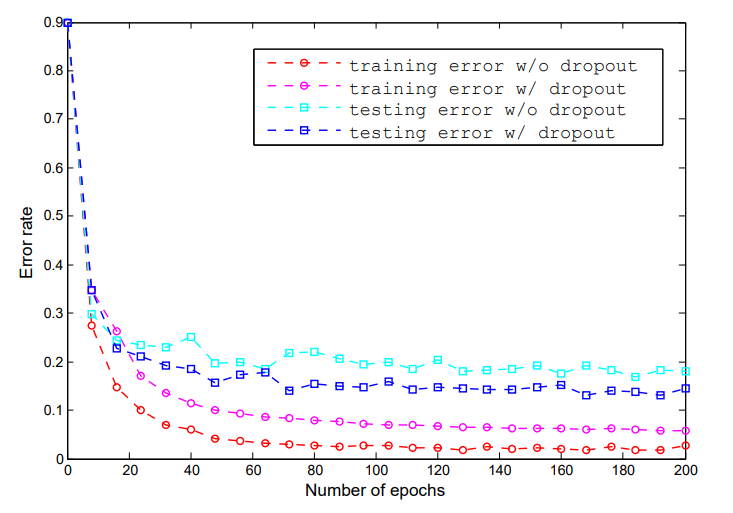
그림 3에서 보듯이, mlpconv 레이어 사이에 드롭아웃 레이어를 도입하면 테스트 오류가 20% 이상 감소하였다.
이 관찰은 Goodfellow 등[8]과 일치한다.
따라서 드롭아웃은 본 논문에서 사용된 모든 모델에 mlpconv 레이어 사이에 추가된다.
드롭아웃 정규화기가 없는 모델은 CIFAR-10 데이터 세트에 대해 14.51%의 오류율을 달성하며, 이는 이미 정규화기로 많은 이전 최첨단 데이터 세트를 능가한다(최대화 제외).
드롭아웃 없는 최대 출력의 성능은 사용할 수 없으므로, 본 논문에서는 드롭아웃 정규화된 버전만 비교한다.
그림 3: mlpconv 레이어 간 드롭아웃의 정규화 효과.
훈련의 첫 200개 시에서 중퇴자가 있는 경우와 없는 경우 NIN의 훈련 및 테스트 오류가 표시된다.
이전 연구와 일관성을 유지하기 위해, 우리는 또한 번역과 수평 뒤집기 확대를 통해 CIFAR-10 데이터 세트에 대한 우리의 방법을 평가한다.
우리는 새로운 최첨단 성능을 설정하는 8.81%의 시험 오차를 달성할 수 있다.
4.3 CIFAR-100
CIFAR-100 데이터 세트[12]는 CIFAR-10 데이터 세트와 크기와 형식이 동일하지만 100개의 클래스를 포함하고 있다. 따라서 각 클래스의 이미지 수는 CIFAR-10 데이터 세트의 10분의 1에 불과하다.
CIFAR-100의 경우 하이퍼 파라미터를 튜닝하지 않고 CIFAR-10 데이터 세트와 동일한 설정을 사용한다.
유일한 차이점은 마지막 mlpconv 계층이 100개의 기능 맵을 출력한다는 것이다.
CIFAR-100의 경우 35.68%의 테스트 오차가 얻어지며, 이는 데이터 증가 없이 현재 최고의 성능을 1% 이상 능가한다.
성능 비교에 대한 자세한 내용은 표 2에 나와 있습니다.
표 2: 다양한 방법의 CIFAR-100에 대한 오류율을 테스트합니다.

4.4 Street View House Numbers
SVHN 데이터 세트[13]는 630,420 32x32 컬러 이미지로 구성되며, 훈련 세트, 테스트 세트 및 추가 세트로 나뉜다.
이 데이터 세트의 작업은 각 이미지의 중앙에 위치한 숫자를 분류하는 것입니다.
훈련 및 시험 절차는 Goodfellow 등[8]에 따른다.
즉, 교육 세트에서 선택한 클래스당 400개의 샘플과 추가 세트의 클래스당 200개의 샘플이 검증을 위해 사용됩니다.
나머지 교육 세트와 추가 교육 세트가 교육에 사용됩니다.
검증 세트는 하이퍼 파라미터 선택을 위한 지침으로만 사용되며 모델 교육에는 사용되지 않는다.
데이터 세트의 전처리는 Goodfellow 등을 다시 따른다. [8], 이것은 국소 대조 정규화였다.
SVHN에서 사용되는 구조와 매개변수는 CIFAR-10에 사용되는 것과 유사하며,
이는 3개의 mlp conv 레이어와 글로벌 평균 풀링으로 구성된다.
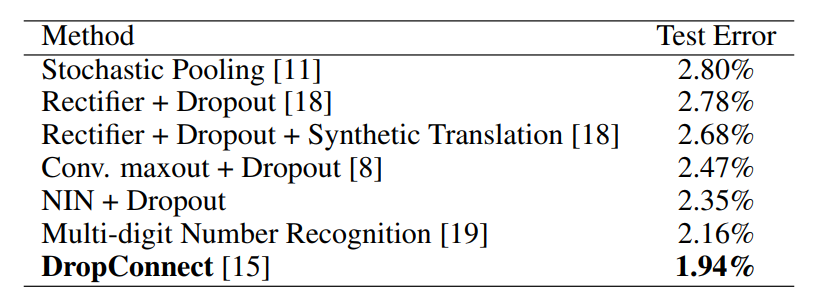
이 데이터 세트의 경우 2.35%의 테스트 오류율을 얻는다.
우리는 우리의 결과를 데이터를 증강하지 않은 방법과 비교하며, 비교 결과는 표 3에 나와 있다.
표 3: 다양한 방법의 SVHN에 대한 오류율을 테스트합니다.
4.5 MNIST
MNIST [1] 데이터 세트는 크기가 28x28인 손으로 쓴 숫자 0-9로 구성된다. 총 60,000개의 훈련 이미지와 10,000개의 테스트 이미지가 있습니다.
이 데이터 세트의 경우 CIFAR-10에 사용된 것과 동일한 네트워크 구조가 채택된다.
그러나 각 mlpconv 계층에서 생성된 기능 맵의 수는 감소한다.
MNIST는 CIFAR-10에 비해 더 간단한 데이터 세트이기 때문에, 더 적은 수의 파라미터가 필요하다.
우리는 데이터 확대 없이 이 데이터 세트에서 우리의 방법을 테스트한다.
결과는 컨볼루션 구조를 채택한 이전 연구와 비교되며 표 4에 나와 있다.
표 4: 다양한 방법의 MNIST에 대한 오류율을 테스트합니다.
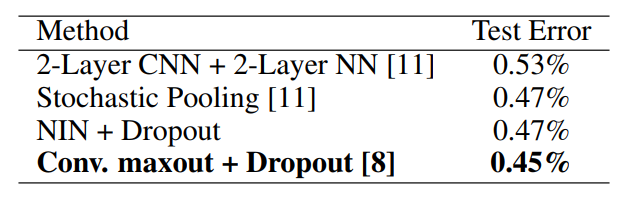
MNIST가 매우 낮은 오류율로 조정되었기 때문에 현재 최고(0.45%)와 비교할 수는 있지만 더 나은 성능(0.47%)을 달성한다.
4.6 Global Average Pooling as a Regularizer
전역 평균 풀링 계층은 둘 다 벡터화된 형상 맵의 선형 변환을 수행한다는 점에서 완전히 연결된 계층과 유사하다.
차이는 변환 행렬에 있습니다.
글로벌 평균 풀링의 경우 변환 행렬이 접두사로 지정되며 동일한 값을 공유하는 블록 대각선 요소에서만 0이 아닙니다.
완전히 연결된 계층은 고밀도 변환 매트릭스를 가질 수 있으며 값은 역 전파 최적화의 영향을 받는다.
글로벌 평균 풀링의 정규화 효과를 연구하기 위해, 우리는 모델의 다른 부분은 그대로 유지하면서 글로벌 평균 풀링 계층을 완전히 연결된 계층으로 교체한다.
우리는 완전히 연결된 선형 레이어 이전의 드롭아웃과 없이 이 모델을 평가했다.
두 모델 모두 CIFAR-10 데이터 세트에서 테스트되었으며, 성능 비교는 표 5에 나와 있다.
표 5: 완전히 연결된 계층과 비교한 글로벌 평균 풀링.

표 5에서 보듯이, 드롭아웃 정규화 없이 완전히 연결된 계층은 최악의 성능을 보였다(11.59%)
이는 정규화기가 적용되지 않는 경우 완전히 연결된 계층이 교육 데이터에 오버핏될 것으로 예상된다.
완전히 연결된 계층 이전에 드롭아웃을 추가하면 테스트 오류(10.88%)가 감소했습니다.
글로벌 평균 풀링은 세 가지 테스트 오류 중 가장 낮은 테스트 오류(10.41%)를 달성했습니다.
그런 다음 글로벌 평균 풀링이 기존 CNN에 대해 동일한 정규화 효과를 가지는지 여부를 탐색한다. 우리는 힌튼 외가 묘사한 대로 전통적인 CNN을 인스턴스화한다. [5]는 세 개의 컨볼루션 레이어와 하나의 로컬 연결 레이어로 구성된다.
로컬 연결 계층은 16개의 기능 맵을 생성하며, 이 맵은 드롭아웃과 함께 완전히 연결된 계층에 공급된다.
비교를 공정하게 하기 위해, 우리는 글로벌 평균 풀링 체계의 각 범주에 대해 하나의 피쳐 맵만 허용되기 때문에 로컬 연결 계층의 피쳐 맵 수를 16개에서 10개로 줄인다.
그런 다음 드롭아웃 + 완전히 연결된 계층을 글로벌 평균 풀링으로 대체하여 글로벌 평균 풀링을 가진 동등한 네트워크를 생성한다.
성능은 CIFAR-10 데이터 세트에서 테스트되었다.
계층이 완전히 연결된 이 CNN 모델은 17.56%의 오류율만 달성할 수 있다.
중퇴를 추가하면 힌튼 외 연구진이 보고한 것과 유사한 성능(15.99%)을 달성한다[5].
이 모델에서 완전히 연결된 계층을 글로벌 평균 풀링으로 대체함으로써 16.46%의 오류율을 얻는데,
이는 드롭아웃이 없는 CNN에 비해 1% 향상되었다.
정규화로서 글로벌 평균 풀링 계층의 효과를 다시 검증한다.
드롭아웃 정규화 결과보다 약간 더 나쁘지만, 우리는 범주의 신뢰도를 모델링하기 위해 정류된 활성화가 있는 선형 필터가 필요하기 때문에 선형 컨볼루션 계층에 글로벌 평균 풀링이 너무 까다로울 수 있다고 주장한다.
4.7 Visualization of NIN
우리는 NIN의 마지막 mlpconv 계층에서 기능 맵을 글로벌 평균 풀링에 의한 범주의 신뢰 맵으로 명시적으로 적용하는데, 이는 NIN의 mlpconv와 같은 더 강력한 로컬 수용적 필드 모델링을 통해서만 가능하다.
이 목적을 얼마나 달성하는지 이해하기 위해 CIFAR-10에 대해 훈련된 모델의 마지막 mlpconv 계층에서 기능 맵을 추출하고 직접 시각화한다.
그림 4는 CIFAR-10 테스트 세트에서 선택한 10개 범주 각각에 대한 일부 예제 이미지와 해당 기능 맵을 보여줍니다.
글로벌 평균 풀링에 의해 명시적으로 시행되는 입력 이미지의 실측 진실 범주에 해당하는 특징 맵에서 가장 큰 활성화가 관찰될 것으로 예상된다.
지상 진실 범주의 특징 맵 내에서, 가장 강력한 활성화는 원본 이미지에서 객체의 동일한 영역에서 대략적으로 나타나는 것을 관찰할 수 있다.
그림 4의 두 번째 열에 있는 자동차와 같은 구조화된 물체에 특히 해당된다.
범주의 기능 맵은 범주 정보만 사용하여 학습됩니다.
객체의 경계 상자가 세분화된 레이블에 사용되는 경우 더 나은 결과가 예상된다.
시각화는 다시 NIN의 효과를 보여준다.
mlpconv 레이어를 사용한 강력한 로컬 수용적 필드 모델링을 통해 달성된다.
그런 다음 글로벌 평균 풀링은 범주 수준 피쳐 맵 학습을 시행합니다. 일반적인 물체 탐지에 대해 추가 탐사를 할 수 있다.
파라벳 등의 장면 라벨링 작업에서와 동일한 맛의 범주 수준 특징 맵을 기반으로 탐지 결과를 얻을 수 있다. [20].
5. Conclusions
우리는 분류 작업을 위해 "네트워크 내 네트워크"(NIN)라는 새로운 심층 네트워크를 제안했다.
이 새로운 구조는 기존의 CNN에서 완전히 연결된 계층을 대체하기 위해 다층 퍼셉트론을 사용하는 mlpconv 레이어와 글로벌 평균 풀링 레이어로 구성된다.
Mlpconv 레이어는 로컬 패치를 더 잘 모델링하며, 글로벌 평균 풀링은 전체적으로 과적합을 방지하는 구조적 정규화 역할을 한다.
NIN의 이 두 가지 구성 요소로 CIFAR-10, CIFAR-100 및 SVHN 데이터 세트에서 최첨단 성능을 입증했다.
기능 맵의 시각화를 통해, 우리는 NIN의 마지막 mlpconv 계층의 기능 맵이 범주의 신뢰 맵이라는 것을 입증했고, 이는 NIN을 통해 객체 탐지를 수행할 수 있는 가능성을 유발한다.
References
[1] Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning ´
applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
그림 4: 마지막 mlpconv 레이어의 기능 맵 시각화
기능 맵의 상위 10% 활성화만 표시됩니다.
특징 지도에 해당하는 범주는 1. 비행기, 2. 자동차, 3. 새, 4. 고양이, 5. 사슴, 6. 개, 7. 개구리, 8. 말, 9. 배, 10. 트럭이다. 입력 이미지의 실제에 해당하는 기능 맵이 강조 표시됩니다.
왼쪽 패널과 오른쪽 패널은 서로 다른 예일 뿐입니다.

[2] Y Bengio, A Courville, and P Vincent. Representation learning: A review and new perspectives.
IEEE transactions on pattern analysis and machine intelligence, 35:1798–1828, 2013.
[3] Frank Rosenblatt. Principles of neurodynamics. perceptrons and the theory of brain mechanisms.
Technical report, DTIC Document, 1961.
[4] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
[5] Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov.
Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[6] Quoc V Le, Alexandre Karpenko, Jiquan Ngiam, and Andrew Ng. Ica with reconstruction cost
for efficient overcomplete feature learning. In Advances in Neural Information Processing
Systems, pages 1017–1025, 2011.
[7] Ian J Goodfellow. Piecewise linear multilayer perceptrons and dropout. arXiv preprint
arXiv:1301.5088, 2013.
[8] Ian J Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, and Yoshua Bengio.
Maxout networks. arXiv preprint arXiv:1302.4389, 2013.
[9] C¸ aglar G ˘ ulc¸ehre and Yoshua Bengio. Knowledge matters: Importance of prior information for
optimization. arXiv preprint arXiv:1301.4083, 2013.
[10] Henry A Rowley, Shumeet Baluja, Takeo Kanade, et al. Human face detection in visual scenes.
School of Computer Science, Carnegie Mellon University Pittsburgh, PA, 1995.
[11] Matthew D Zeiler and Rob Fergus. Stochastic pooling for regularization of deep convolutional
neural networks. arXiv preprint arXiv:1301.3557, 2013.
[12] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images.
Master’s thesis, Department of Computer Science, University of Toronto, 2009.
[13] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng.
Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on
Deep Learning and Unsupervised Feature Learning, volume 2011, 2011.
[14] Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine
learning algorithms. arXiv preprint arXiv:1206.2944, 2012.
[15] Li Wan, Matthew Zeiler, Sixin Zhang, Yann L Cun, and Rob Fergus. Regularization of neural
networks using dropconnect. In Proceedings of the 30th International Conference on Machine
Learning (ICML-13), pages 1058–1066, 2013.
[16] Mateusz Malinowski and Mario Fritz. Learnable pooling regions for image classification.
arXiv preprint arXiv:1301.3516, 2013.
[17] Nitish Srivastava and Ruslan Salakhutdinov. Discriminative transfer learning with tree-based
priors. In Advances in Neural Information Processing Systems, pages 2094–2102, 2013.
[18] Nitish Srivastava. Improving neural networks with dropout. PhD thesis, University of Toronto,
2013.
[19] Ian J Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay Shet. Multi-digit
number recognition from street view imagery using deep convolutional neural networks. arXiv
preprint arXiv:1312.6082, 2013.
[20] Clement Farabet, Camille Couprie, Laurent Najman, Yann Lecun, et al. Learning hierarchical ´
features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence,
35:1915–1929, 2013.