


먼저 논문의 제목을 통해 해당 논문에서 풀고자 하는 문제의 대상과 방식에 대한 전체적인 설명을 먼저 드리겠습니다.
먼저 주어진 학습 데이터 셋에서 기존 관측과는 상이하여 다른 매커니즘에 의해 생성되었다고 판단할만한 관측 값을 anomaly sample이라고 부르며 이러한 이상치를 탐지하는 task를 anomaly detection 이라고 부릅니다.
Anomaly detection task는 abnormal에 대한 label의 유무에 따라 supervised setting과 unsupervised setting으로 나뉘며, 대부분은 현실에서는 label이 존재하지 않아 unsupervised setting에서의 높은 성능을 기록하는 알고리즘이 각광을 받고 있습니다.
이를 통해 Unsupervised anomaly detection on multivariate time series (USAD)는 이름에서 알 수 있듯이 다변량 시계열에서 unsupervised setting으로 Anomaly detection task를 진행하는 모델임을 알 수 있으며, 또한 Multivariate time series란 각 시간 단위마다 여러 개의 값을 가지는 시계열을 뜻하며 오른쪽 아래의 그림과 같은 시간 연속적인 데이터를 의미합니다.
논문의 제목으로 다변량 시계열 데이터에서 비지도 학습을 통한 이상 관측 모델에 대한 연구라는 것을 먼저 알 수 있습니다.
USAD의 작동 과정을 먼저 이야기하기전에 본 논문의 contribution을 이해하기 위해서 auto encoder기반 anomaly detection와 GANs기반 anomaly detection의 장단점을 먼저 설명하겠습니다.
먼저 auto encoder 기반의 anomaly detection을 설명 드리겠습니다.
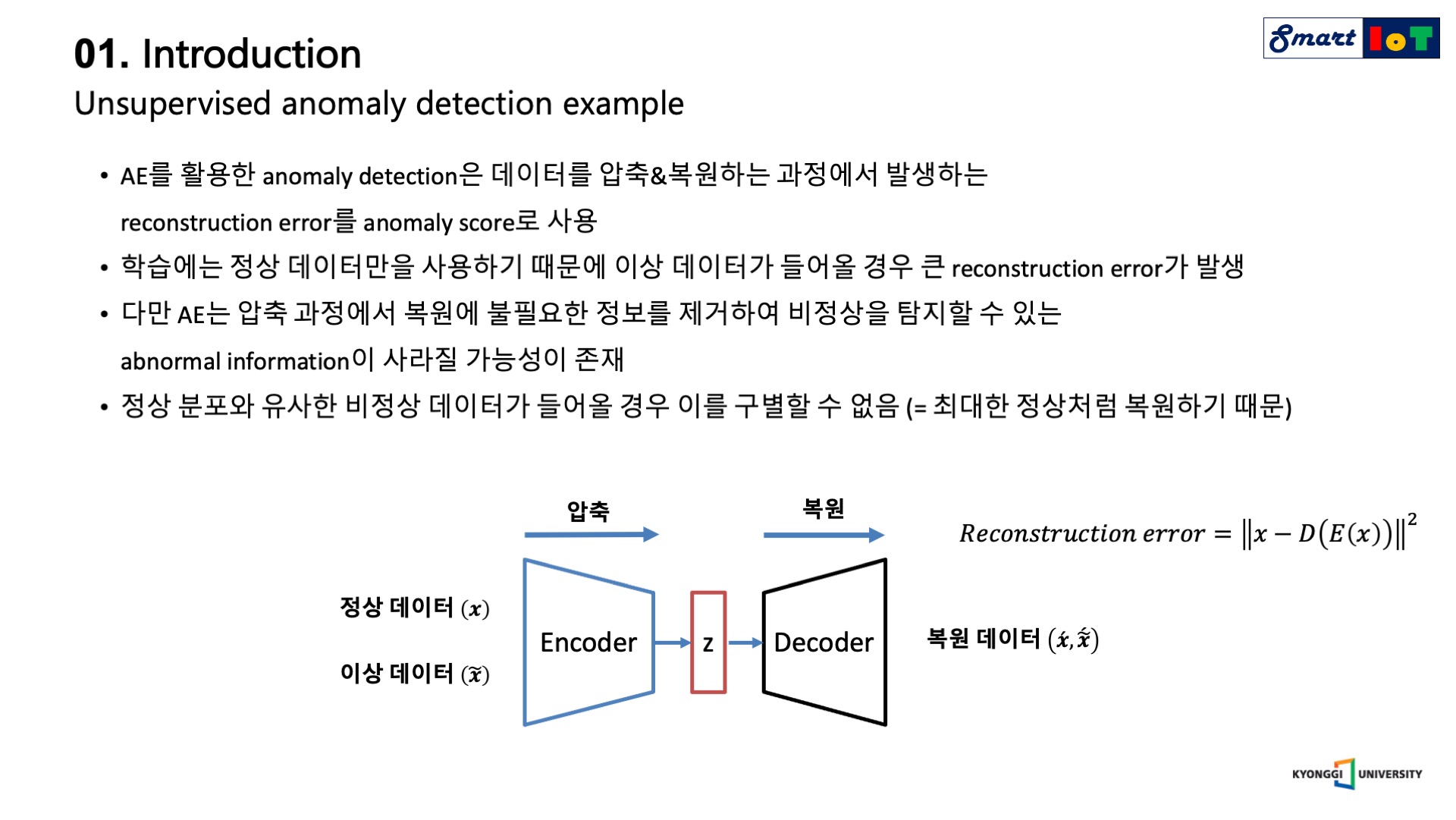
먼저 anomaly detection은 학습 단계와 탐지 단계로 구분할 수 있으며, Auto encoder 기반 모델의 학습 단계에서는 정상 데이터를 압축과 복원 과정을 거치는데, 이 때 복원된 시계열과 원본 시계열 간의 차이인 reconstruction error를 minimize 하여 정상 데이터를 잘 복원하는 모델을 구축합니다.
이처럼 정상 데이터만을 학습한 Auto encoder 모델은 비정상 데이터를 입력하였을 경우 큰 값의 reconstruction error를 갖습니다.
이러한 이유는 학습에서 보지 못한 data이기 때문에 제대로 복원하지 못하는 것인데, 탐지 단계에서는 위 성질을 활용하여 정상과 이상 데이터가 혼재해 있는 데이터를 Auto encoder의 input으로 넣은 후 이를 복원하였을 때 발생한 reconstruction error를 사용하여 threshold를 넘기면 이상, 넘기지 않으면 정상으로 판단합니다.
이 때 이상 탐지의 기준이 되는 reconstruction error를 anomaly score라고 부릅니다.
Auto encoder 기반의 anomaly detection 알고리즘의 경우 학습이 용이하다는 장점이 있지만 정상 데이터의 분포와 유사한 비정상 데이터가 들어올 경우 이를 잘 구별하지 못한다는 단점이 존재합니다.
이는 Auto encoder의 압축 과정에서 복원에 불필요한 정보를 제거하기 때문인데 학습 단계에서 정상 데이터만을 사용한다는 특성과 맞물려 비정상을 탐지할 수 있는 abnormal information이 소거되는 특징이 있습니다.
다시 말하면 정상 데이터만을 학습한 Auto encoder의 경우 비정상 데이터가 들어오더라도 최대한 정상처럼 복원하는 성질이 존재하기에 미세한 차이의 anomaly sample을 검출하지 못한다는 단점이 존재합니다.
다음으로 GANs기반의 anomaly detection에 대해서 설명드리겠습니다.
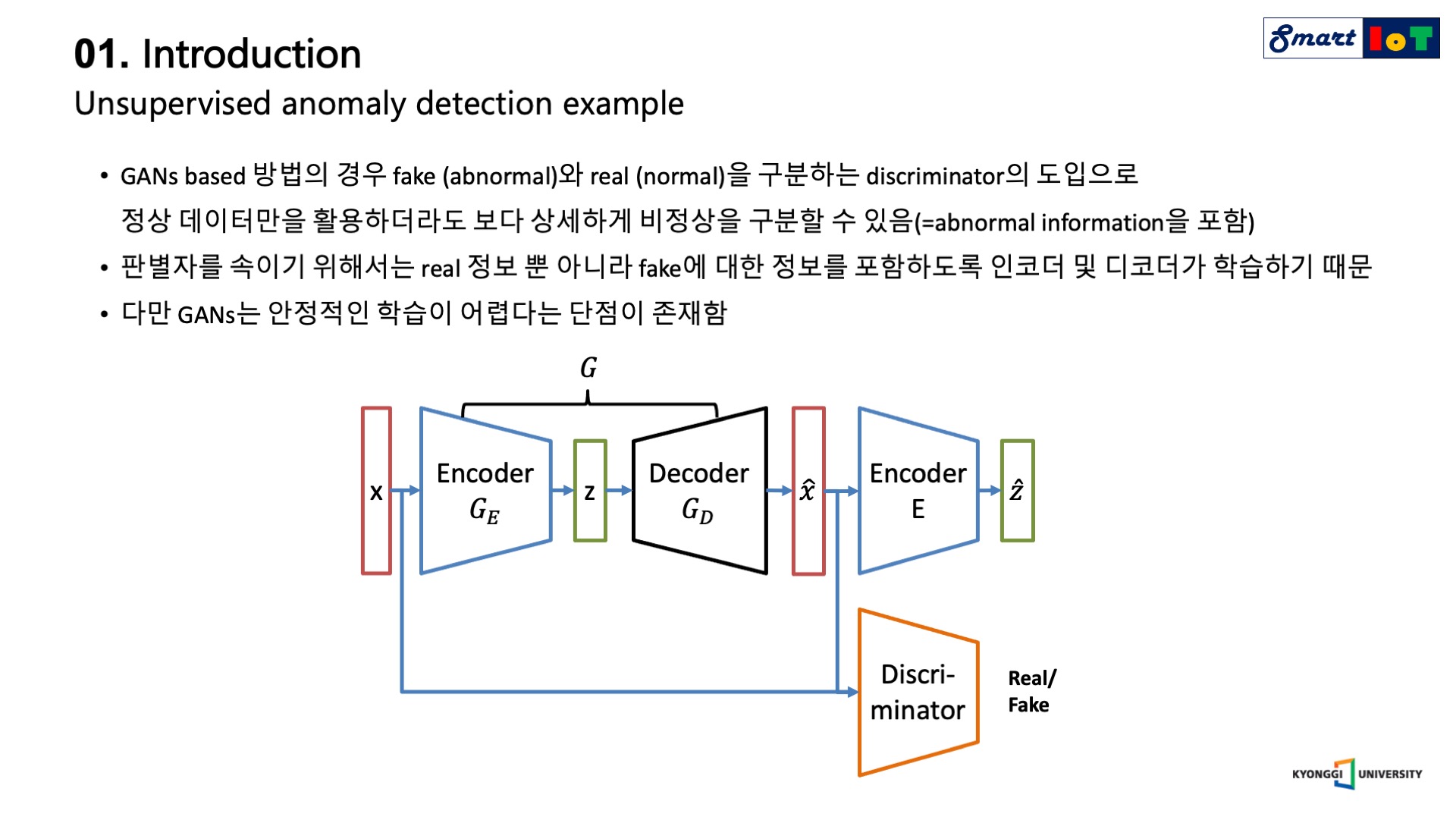
GANs는 가상 데이터를 생성하는 generator와 실제와 가상 데이터를 구분하는 discriminator로 구성됩니다.
GANs 기반 anomaly detection은 실제 데이터를 normal로, 가상 데이터를 abnormal로 판단하여 학습을 진행하며 전반적인 구조는 아래의 그림과 같습니다.
GANs 기반 방법의 경우 input sequence의 압축 및 복원을 generator가 담당하며, 이 때 generator의 목적은 discriminator를 속이는 것이기에 generator의 encoder, decoder가 실제 정보 뿐 아니라 가상에 대한 정보를 포함하도록 강제됩니다.
즉 discriminator의 도입으로 압축과 복원을 담당하는 encoder, decoder가 보다 자세하게 비정상 데이터를 구분할 수 있게 되어 기존 AE기반 모델의 단점을 보완하는 특징이 있습니다.
다만 computer vision 등에서 발생하는 GANs의 일반적인 문제점과 마찬가지로 안정적인 학습이 어렵다는 단점이 존재합니다.
다음으로는 USAD에 대한 설명을 하겠습니다.
USAD는 두 가지 방법의 장점을 모두 취하는 모델입니다.
학습이 쉽고 안정적인 결과를 낼 수 있는 auto encoder의 장점과 discriminator의 도입으로 abnormal information을 포함할 수 있는 GANs의 장점을 결합하였습니다.
Auto encoder를 사용하되 adversarial training을 적용하여 보다 상세한 anomaly detection을 추구하였습니다.
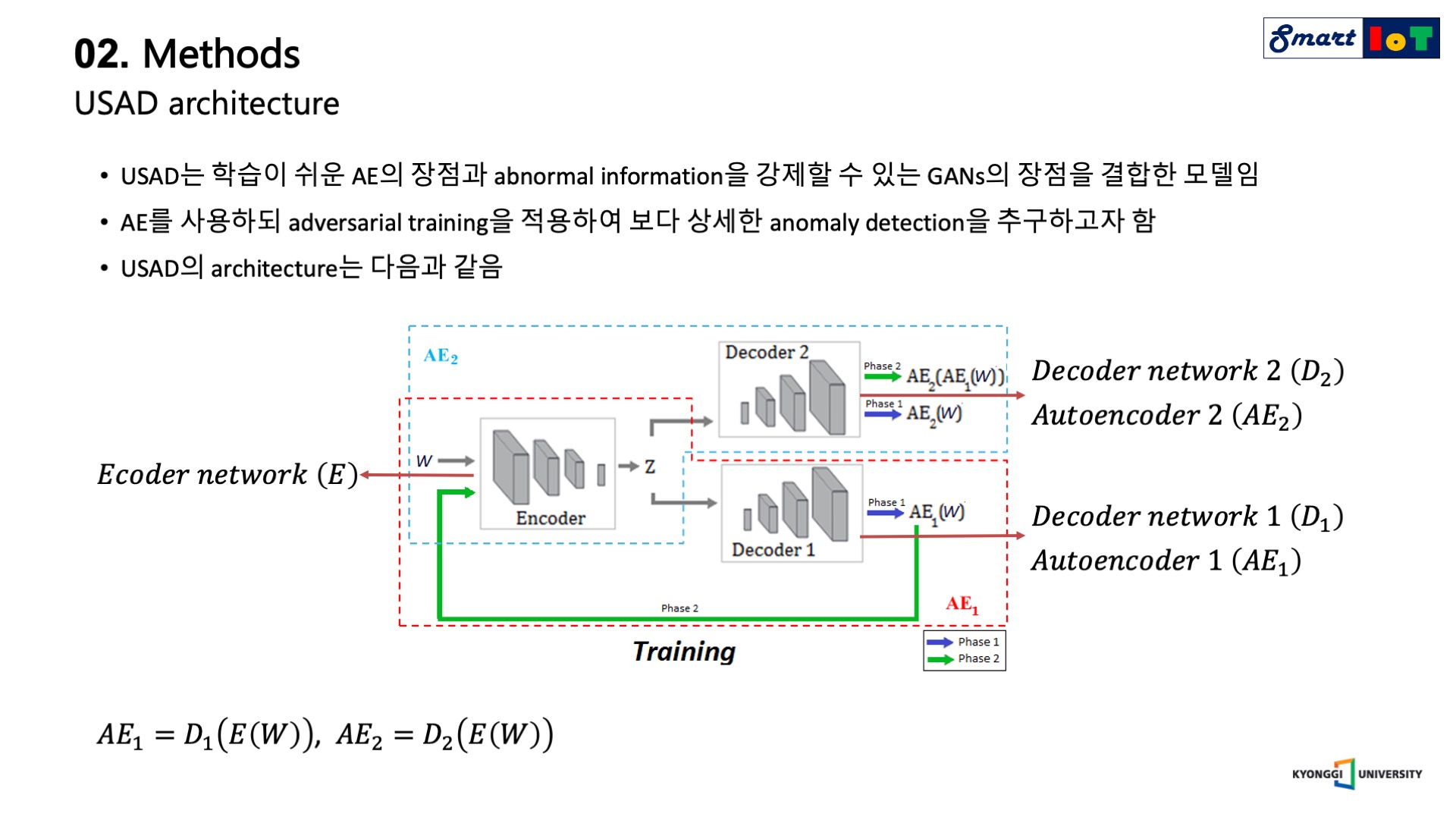
USAD의 architecture는 아래의 그림과 같으며, Adversarial training을 적용하기 위해 2개의 decoder를 사용하였다는 점 외에는 기존의 Auto encoder 기반의 anomaly detection과 동일한 구조를 갖습니다.
두 개의 decoder는 각각 D_1, D_2로 표기되며 이들은 동일한 encoder network E 를 사용한다.
W를 training data 안에 있는 sequence의 window라고 하였을 때 두 개의 Decoder에 따라 Auto encoder는 각각 왼쪽 아래와 같이 표기된다.

이제 USAD의 학습 단계와 탐지 단계에 대해서 설명드리겠습니다.
USAD는 두 단계를 거쳐서 학습이 진행되며, 첫 번째 단계는 auto encoder training 단계로 기존의 auto encoder를 학습하는 것과 동일한 과정을 거친다.
이를 수식으로 표현하면 1에 나와있는 두 가지의 수식으로 나타낼 수 있습니다.
학습의 첫 번째 단계인 auto encoder training 과정에서는 각각의 auto encoder가 training data에 속해있는 input W (real, normal)를 잘 복원하도록 학습을 진행합니다.
다음으로 두 번째 단계인 adversarial training 과정에서는 각각의 auto encoder (AE_1, AE_2)는 실제 데이터와 AE_1의 데이터를 구분하도록 AE_2를 교육하고 AE_1을 교육하여 AE_2를 속이기 위한 목적을 지닙니다.
AE_2는 실제 데이터인 W와 AE_1로 부터 복원된 가상 데이터인 AE_1(W)를 구분하도록 학습하며, 반면 AE_1은 AE_2의 real과 fake에 대한 판별 성능을 저하시키는 것을 목적으로 학습이 진행됩니다.
결론적으로 AE_1은 GANs에서 생성자의 역할을, AE_2는 판별자의 역할을 수행한다.
Adversarial training 단계에서의 목적함수는 아래의 두 가지로 나타낼 수 있으며 먼저 생성자 역할을 수행하는 첫 번째 auto encoder는 실제 데이터 W와 가상 데이터에 대한 AE_2의 결과인 AE_2(AE_1(W))간의 차이를 최소화 시켜야 판별자를 속일 수 있습니다.
반대로 판별자 역할을 수행하는 두 번째 auto encoder는 가상 데이터가 입력으로 들어 왔을 때 실제 데이터와의 차이를 최대화 시켜야 실제 데이터와 가상 데이터를 잘 구별하고 있다고 볼 수 있으며, 이는 더 높은 reconstruction error 값이 나올수록 더 잘 구별하고 있다고 볼 수 있습니다.
따라서 AE_1은 가상 데이터에 대한 AE_2의 reconstruction error를 줄이도록 학습하고, 반대로 AE_2는 가상 데이터에 대한 reconstruction error를 키우도록 학습합니다.

앞서 설명드린 두 가지 training phase를 하나의 loss function으로 표기하면 다음과 같으며, 먼저 위 수식의 세부 항에 대해서 설명드리겠습니다.
각각의 loss에서 앞의 항은 실제 데이터에 대한 reconstruction error로써 원본 데이터를 잘 복원하는 auto encoder training의 loss에 해당합니다.
Auto encoder training term을 통해서 원래의 input을 잘 복원하도록 학습이 진행됩니다.
다음으로 두 번째 항의 경우 adversarial training의 loss로 구성되어 있다.
앞에서 살펴본 minimize, maximize term이 부호로써 각각 +,-로 표기가 된 것을 확인할 수 있습니다.
마지막으로 두 항을 합할 때 곱해지는 분모의 n은 학습 중인 epoch을 뜻하여 학습 초반에는 실제 데이터에 대한 reconstruction error에 가중치를 주고 학습 후반에는 adversarial training에 가중치를 주는 역할을 합니다.
이제 각각의 auto encoder 관점에서 loss를 설명하겠습니다.
AE_1에 적용되는 loss를 살펴보면 실제 데이터에 대한 reconstruction error와 가상 데이터에 대한 AE_2의 reconstruction error가 모두 최소일 때 최소값을 갖습니다.
이를 통해 AE_2가 가상 데이터에 대한 판별력이 떨어지는 것을 목표로 하는 것을 확인할 수 있습니다.
반대로 AE_2에 적용되는 loss를 살펴보면 실제 데이터에 대한 reconstruction error가 최소이고, 가상 데이터에 대한 AE_2의 reconstruction error가 최대일 때 최소값을 갖습니다.
즉 가상 데이터가 들어왔을 때 anomaly가 들어왔다는 신호인 reconstruction error를 크게 내뱉도록 학습이 진행됩니다.
GANs 기반 anomaly detection에서 실제 데이터는 normal, 가상 데이터는 abnormal로 사용하는 것을 감안하면 AE_2는 결국 normal과 abnormal의 미세한 차이를 극대화시키는 역할을 하게 됩니다.
이러한 이유로 기존의 auto encoder 기반 anomaly detection model보다 높은 성능을 보입니다.
학습이 완료된 USAD를 사용하여 실제 anomaly detection을 수행하는 과정을 알아보겠습니다.
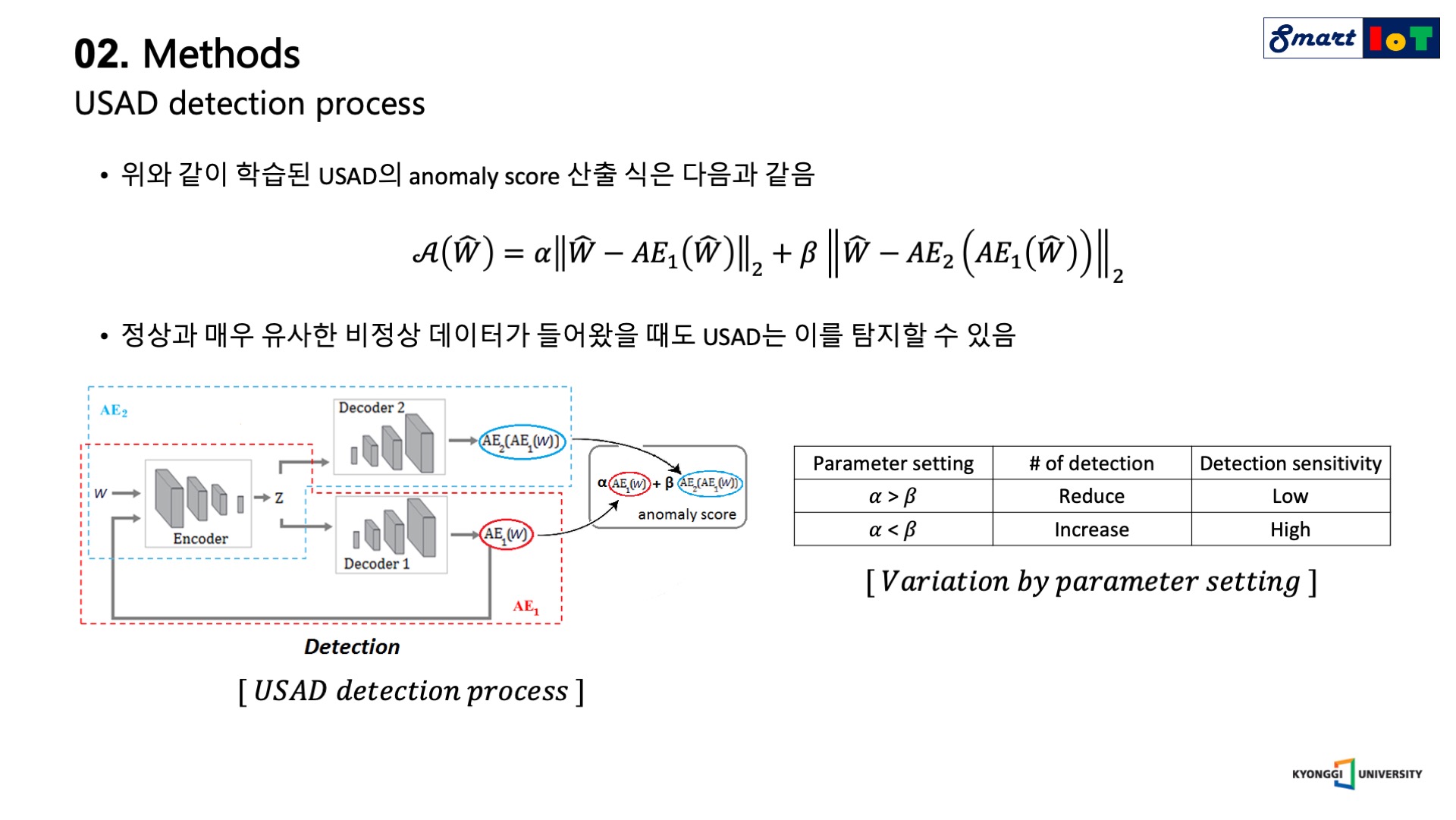
먼저 USAD의 anomaly score 산출 공식은 위의 수식과 같습니다.
hat W은 unseen data, 즉 train data에 존재하지 않은 새로운 sequence의 window를 뜻하며 normal과 abnormal이 혼재되어있습니다.
USAD의 anomaly score는 input과 AE_1의 reconstruction error와 더불어 입력과 가상 데이터에 대한 AE_2의 reconstruction error의 가중합으로 산출할 수 있습니다.
USAD의 anomaly score는 뒷 항에 해당하는 가상 데이터에 대한 AE_2의 reconstruction error를 사용하여 정상과 매우 유사한 분포를 지닌 비정상 데이터가 들어오더라도 이를 탐지할 수 있게 됩니다.
두 가지 항을 결합할 때 사용되는 hyper-parameter인 alpha와 beta 합은 1로 설정이 되며 parameter setting에 따라 오른쪽 표와 같은 결과를 얻을 수 있습니다.
beta가 커진다는 것은 정상 분포와 약간만 달라지더라도 큰 anomaly score를 발생시키기 때문에 detection의 횟수는 증가하고, 이에 따라 detection sensitivity가 높아지게 됩니다.
반대로 실제 데이터에 대한 reconstruction error를 더욱 크게 반영할 경우 미세한 anomaly detection은 불가하여 detection 수는 감소하고 detection sensitivity는 낮아지게 됩니다.
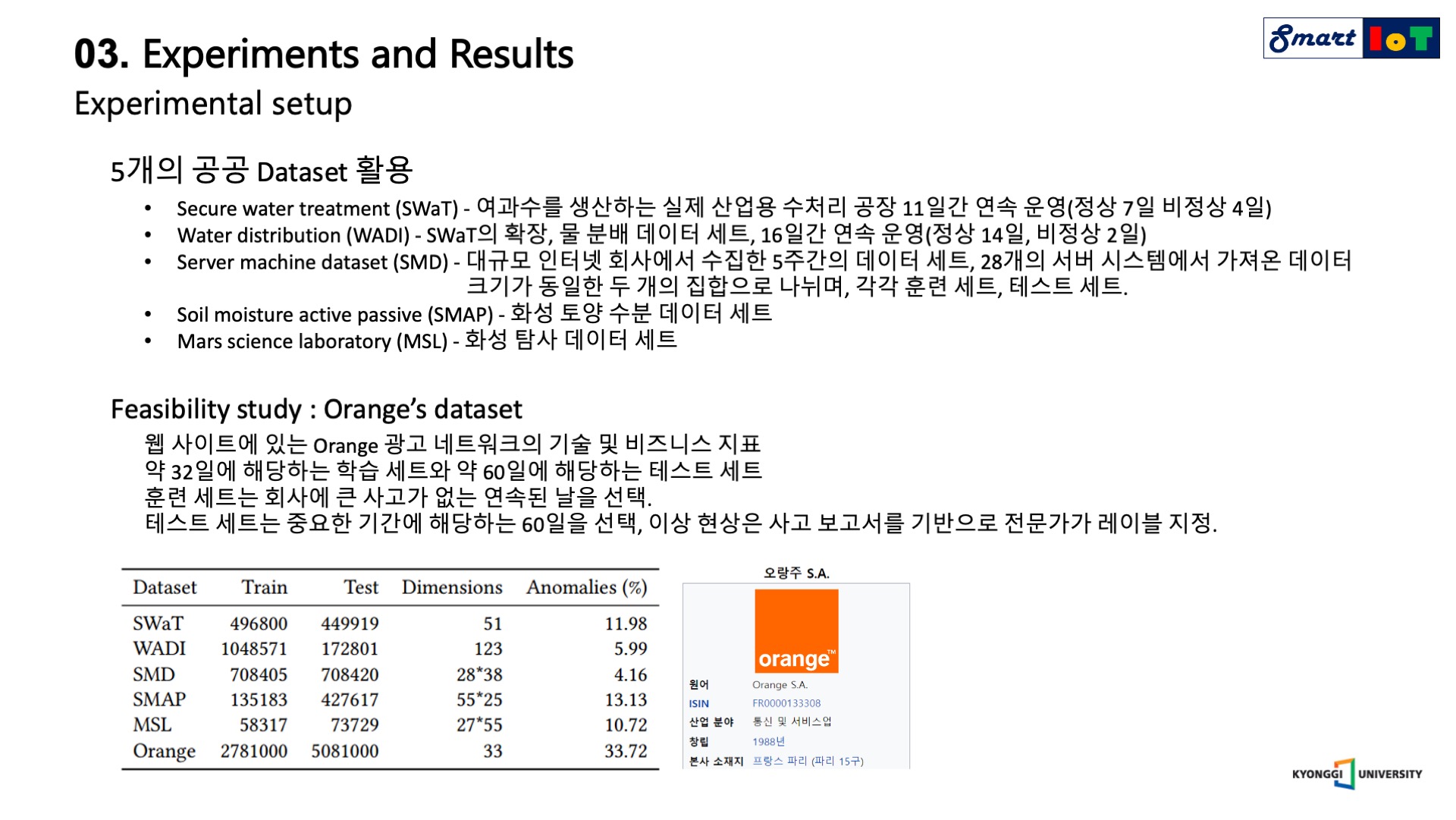
USAD는 총 5가지 public datasets와 1가지 private dataset을 활용하여 성능을 검증하였습니다.
5가지 public datasets은 다음과 같으며, Swat는 여과수를 생산하는 실제 산업용 공장에서의 11일간의 기록이며, WADI는 swat의 확장으로 물 분배 데이터 세트를 의미하며, 총 16일간의 기록입니다.
SMD는 인터넷 회사에서 5주간 28개의 서버 시스템에서 가져온 데이터이며, SMAP, MSL은 나사에서 제공되는 화성 탐사와 관련된 데이터 입니다.
타당성 조사를 위해서 Orange의 데이터세트를 사용하였으며, 약 32일의 학습 데이터와 60일의 테스트 데이터 세트로 구성하였으며, 테스트 데이터 세트는 중요한 기간에 해당하는 60일을 선택하였고, 이상 현상은 사고 보고서를 기반으로 전문가가 직접 라벨링을 진행하였습니다.
오른쪽 아래의 표에 도표로 세부사항들이 나와있습니다.

다음으로는 평가 지표에 대해서 설명드리겠습니다.
각각의 데이터 세트에 대한 평가 지표는 정밀도, 재현율, F1 score, F1 star로 구성되며 F1 star의 경우 정밀도와 재현율의 평균을 사용하여 도출된 값입니다.
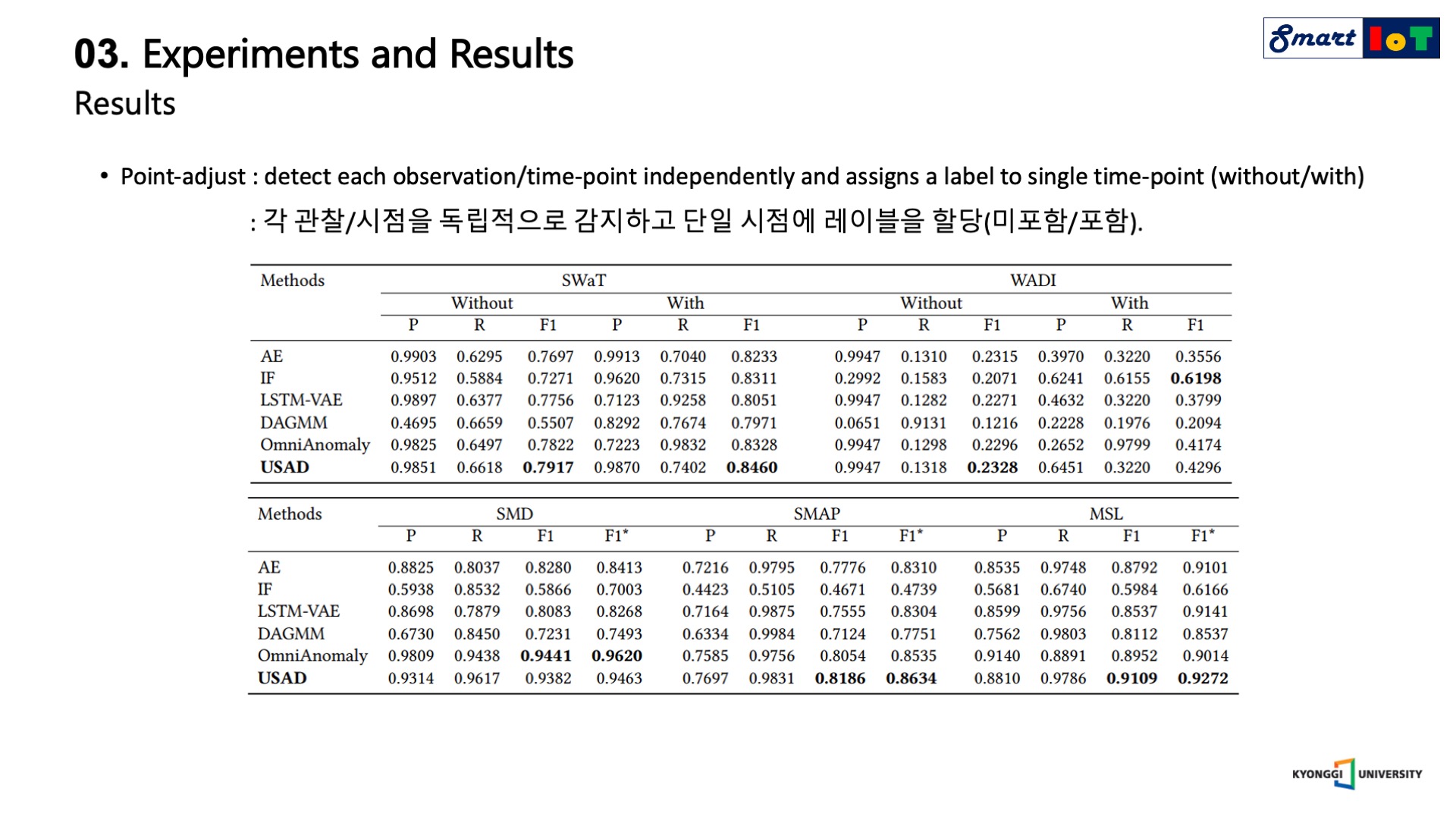
다음은 5가지 datasets에 대한 비교 모델과의 성능 비교표입니다.
첫 번째 표의 without/with는 포인트 어드저스트 적용 여부를 뜻하며 point-adjust란 각각의 observation/time-point에 대해서 독립적으로 anomaly를 detecting 한 결과 입니다.
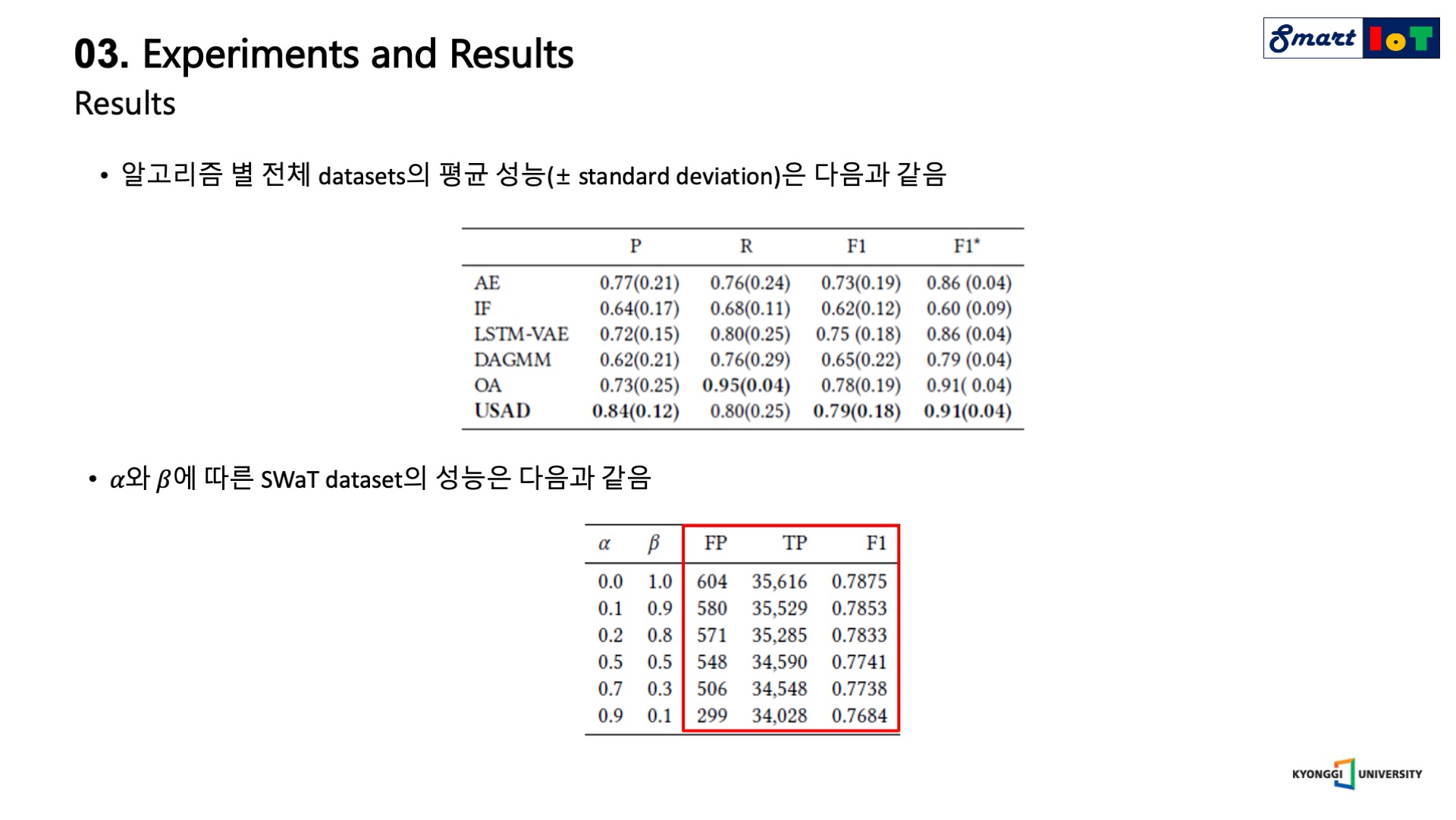
다음은 5가지 데이터 세트에 대한 알고리즘 별 평균 성능을 기록한 표 이며, 가로는 표준 편차를 의미합니다.
성능 비교 표를 정리하면 대부분의 경우에서 USAD가 좋은 성능을 보여주는 것을 확인할 수 있습니다.
특히 auto encoder를 활용한 anomaly detection과 비교하면 월등한 성능을 보여줍니다.
다음은 SWaT data에 대한 hyper-parameter별 성능을 기록한 표이다.
앞서 저자가 설명한대로 beta값이 커짐에 따라 detection의 수가 많아짐을 확인할 수 있습니다.

다음은 다운 샘플링, 윈도우 사이즈, 잠재 공간의 차원, 이상 징후의 백분율에 따른 연구 결과 입니다.
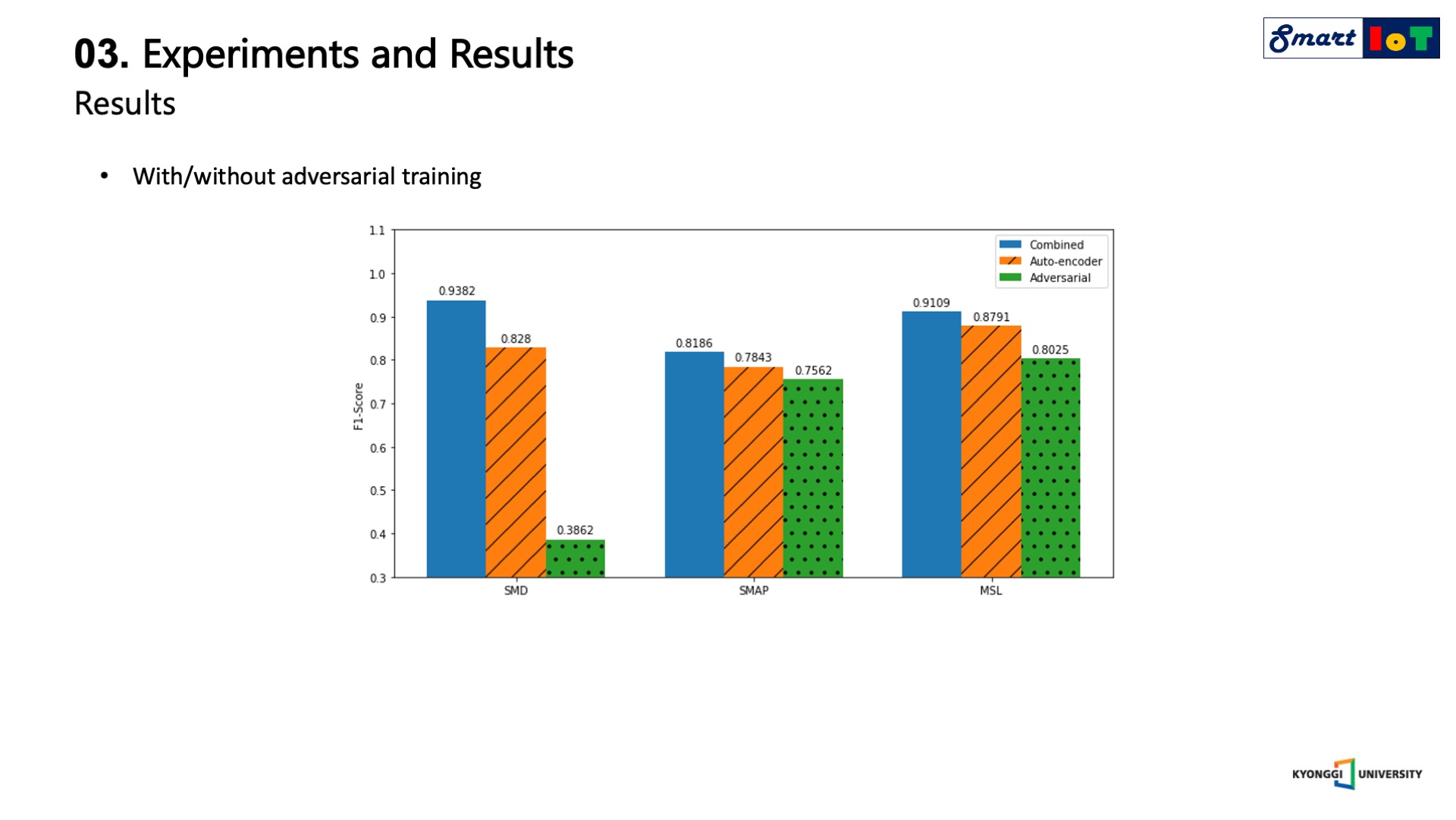
마지막으로 USAD에서 적대적 훈련의 효과를 확인하기 위한 절제 연구 결과는 다음과 같습니다.
3가지 데이터 세트에 대해서 순수 adversarial의 성능은 가장 낮으나 auto encoder와 결합했을 때 가장 좋은 성능을 보인 것을 확인할 수 있습니다.
결론적으로 USAD는 기존의 auto encoder 기반의 anomaly detection 알고리즘의 장점과 GANs 기반의 anomaly detection 알고리즘의 장점을 결합한 방법이였습니다.