0️⃣ 서론
이전에 작성한 게시글에서도 말씀드렸듯이 저희 서비스에서는 DND을 이용한 보드에 스크랩을 추가하고 이동하는 기능인 보드 기능을 추가하였습니다.
https://velog.io/@da_na/UUID-사용자에게-보여주는-URL-관련-보드의-고유키-값-구성하기
이때, 프론트 파트에서 React의 DND-kit 라이브러리를 사용하여, 보드 기능을 구현하였습니다.
아래의 링크는 저희 팀의 프론트 개발자의 관련 글입니다.
https://velog.io/@hannatoo/프로젝트-타입스크립트-프로젝트에서-jsx-import하기
따라서 보드 기능을 사용하기 위해서 어떠한 DB를 가져야 하는지 데이터 구조가 적합한지 살펴보겠습니다!
1️⃣ 본론
1. 보드 기능의 데이터 구조 살펴보기
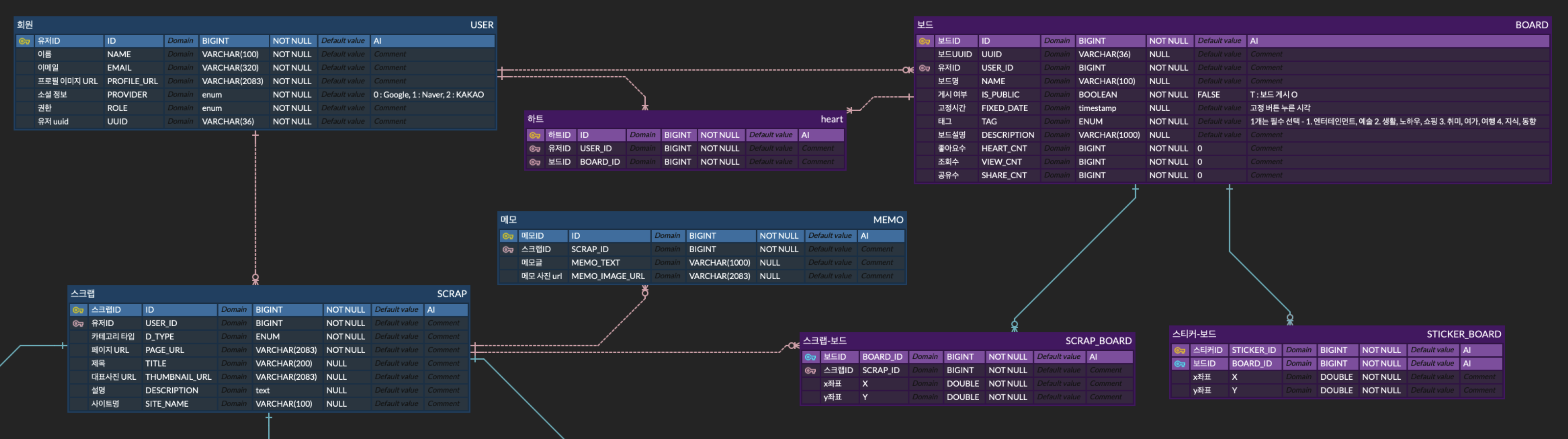
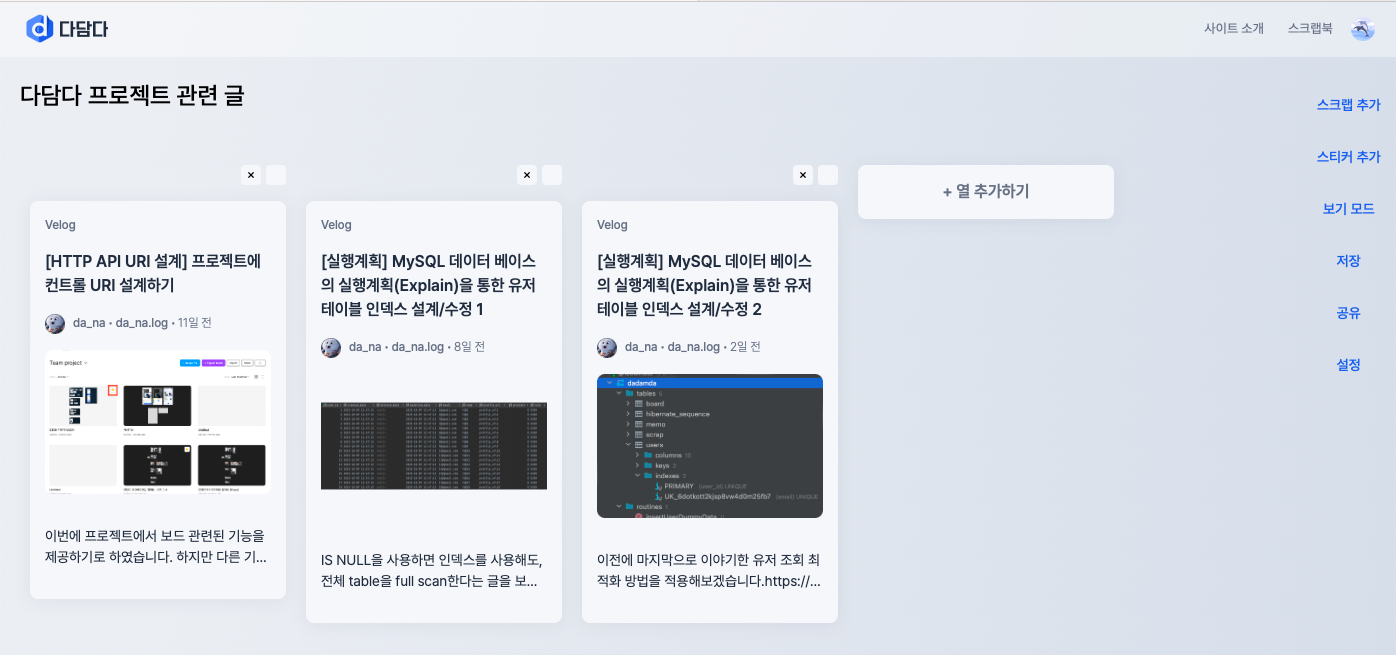
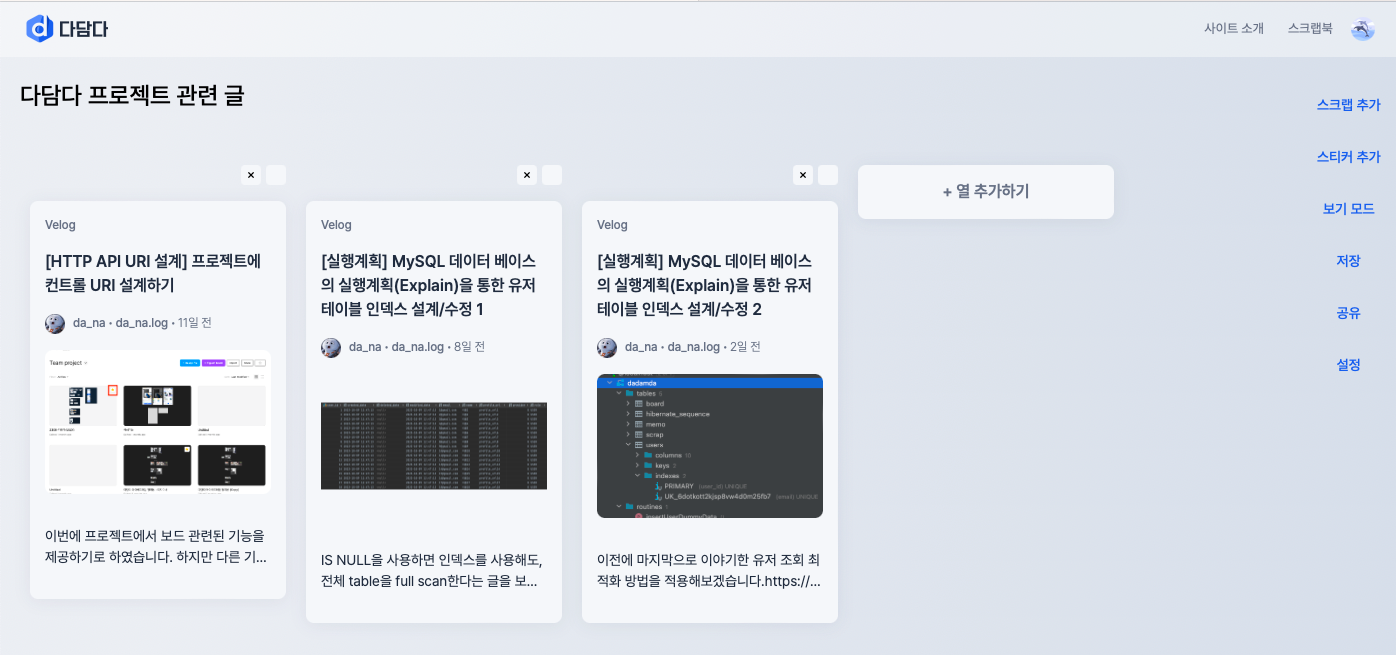
위의 그림의 보드 DND-kit 라이브러리에서 사용하는 데이터 구조입니다.
헤딩 구조는 JSON과 같은 데이터 구조임을 알 수 있습니다.
즉, "A"는 첫번째 열을 의미하고, A열에 배열을 가지고 있으며 배열의 순서에 따라서 A열의 행이 정해집니다.
아래의 데이터 구조는 중요한 부분을 위주로 간략하게 나타내었습니다.
{"A":[
{"scrapId":9,
"description":"이번에 프로젝트에서 보드 관련된 기능을 제공하기로 하였습니다...",
"pageUrl":"https://velog.io/@da_na/HTTP-API-URI-설계-프로젝트에-컨트롤-URI-설계하기","siteName":"Velog",
"title":"[HTTP API URI 설계] 프로젝트에 컨트롤 URI 설계하기",
"author":"da_na",
"authorImageUrl":"https://velog.velcdn.com/images/da_na/profile/image.jpg",
"blogName":"da_na.log",
"dtype":"article",
"id":"9.616648527914574"}],
"B":[
{"scrapId":8,
"description":"IS NULL을 사용하면 인덱스를 사용해도, 전체 table을 full scan한다는 글을 보았습니다...",
"pageUrl":"https://velog.io/@da_na/SQL-튜닝-유저-조회-SQL-튜닝-및-성능-최적화-1","siteName":"Velog",
"title":"[실행계획] MySQL 데이터 베이스의 실행계획(Explain)을 통한 유저 테이블 인덱스 설계/수정 1","author":"da_na",
"blogName":"da_na.log",
"dtype":"article",
"id":"8.425313977182695"}],
"C":[
{"scrapId":7,
"description":"이전에 마지막으로 이야기한 유저 조회 최적화 방법을 적용해보겠습니다...",
"pageUrl":"https://velog.io/@da_na/실행계획-MySQL-데이터-베이스의-실행계획Explain을-통한-유저-테이블-인덱스-설계수정-2",
"siteName":"Velog",
"title":"[실행계획] MySQL 데이터 베이스의 실행계획(Explain)을 통한 유저 테이블 인덱스 설계/수정 2",
"author":"da_na",
"blogName":"da_na.log",
"dtype":"article",
"id":"7.837758400701152"}]}2. MySQL의 데이터 구조
저희 서비스는 MySQL인 RDBMS의 DB 구조를 가지고 있습니다.
따라서 RDBMS 구조로 보드의 기능을 구현하는 경우 기존에 저장되어 있는 스크랩과 보드를 연결해주는 또다른 스크랩-보드를 매핑하는 테이블을 추가하여, 보드 내의 해당 스크랩 위치 정보를 저장해야 합니다.
저희는 x를 열, y를 행을 저장하는 column을 추가해주었습니다.
위의 데이터 구조에서 몇 번째 열인지(예시 : "A"), 몇번째 행("A"열에서 배열의 몇 번째 스크랩인지)인지를 저장하면 됩니다.
예시로 scrapId가 9번인 것은 x = A, y = 1를 저장할 수 있습니다.
여기에서 살펴봐야 할 점은 장점과 단점을 살펴보고 해당 데이터 구조가 적합한지 살펴보겠습니다.
가장 큰 장점은 데이터가 중복되지 않는다는 점입니다.
스크랩의 정보가 이미 스크랩 테이블에 저장되었기 때문에 해당 scrapId만 참조하는 정보가 있으면 해당 스크랩의 정보를 따로 저장하지 않아도 됩니다.
첫 번째 단점은 보드 내에서 스크랩을 삭제하거나, 스크랩의 행을 변경하는 등 스크랩 위치를 변경하는 경우 다른 스크랩의 행과 열에 영향을 주게 됩니다.
저희 서비스는 DND를 사용하기 때문에 스크랩의 위치 변경이 매우 빈번할 것이라고 예상됩니다.
예를 들어, 아래의 표와 같이 스크랩이 보드안에 존재한다고 하면, 스크랩 ID가 1인 스크랩을 B 열에 1로 옮기겠습니다.
| 보드ID | 스크랩 ID | x좌표 | y좌표 |
|---|---|---|---|
| 1 | 1 | A | 1 |
| 1 | 2 | A | 2 |
| 1 | 3 | A | 3 |
그러면 같은 x좌표에 있었던 스크랩들의 y좌표 모두 변경해야 합니다.
| 보드ID | 스크랩 ID | x좌표 | y좌표 |
|---|---|---|---|
| 1 | 1 | B | 1 |
| 1 | 2 | A | 1 |
| 1 | 3 | A | 2 |
두 번째 단점은 DND-kit의 데이터 구조인 JSON으로 변경해줘야 합니다.
위의 DB의 데이터를 프론트에게 전달해주기 위해서 A : ["scrapId:1", "scrapID:2", "scrapID:3"] 이런식으로 변경해줘야 합니다.
더 나아가, 프론트에서 백엔드로 데이터를 전달해줄때에도 y좌표를 찾기 위해서 해당 배열을 돌면서 y좌표를 추출해내는 과정이 필요합니다.
그리고 마지막 단점은 JOIN문이 빈번해집니다.
현재 보드 테이블과 스크랩 테이블을 매핑하는 테이블에서 스크랩 테이블을 참조하고 있기 때문에 해당 스크랩 ID와 스크랩 테이블의 ID를 조인해야 합니다. 그리고 해당 스크랩의 메모들도 별도의 메모 테이블이 존재하기 때문에, 스크랩 테이블과 메모 테이블을 조인하는 쿼리가 발생하게 됩니다.
보드에서는 업데이트가 계속 발생하므로 조회가 몇초 간격으로 일어나는 데 이때에 JOIN문이 다수 발생합니다.
장점
- 데이터가 중복되지 않는다.
단점
- 행을 변경한 경우, 다른 스크랩의 모든 y를 변경해야 한다.
- json으로 변환해줘야 한다.
- join이 빈번하다.
따라서 이러한 여러 단점이 있기 때문에 RDBMS를 활용한 데이터 구조는 적합하지 않다고 판단하였습니다.
3. NoSQL 데이터 구조
그러면 이러한 단점을 해결하기 위해서는 어떠한 데이터 구조가 적합할지 생각하던 중에 DND-kit의 데이터 구조와 매우 유사한 NoSQL 데이터 베이스를 사용하면 따로 위치 정보를 저장할 필요없이, 그대로 저장하면 되지 않을까??라는 생각을 하게 되었습니다.
따라서 NoSQL 중 가장 대표적인 DB인 MongoDB를 사용하려고 하였습니다.
하지만, MongoDB를 사용하면, 기존의 AWS RDS가 아닌 MongoDB 용 DB를 따로 생성해야 하며 사용해본 적이 없어서 학습 시간이 소요되는 등 시간 및 비용 측면에서 부담이 되었습니다.
그리고 RDBMS보다 NoSQL 데이터 베이스는 비교적 조회 속도가 훨씬 빠르지만, 업데이트와 삽입이 느리다는 단점이 있습니다.
더 나아가, 보드에서는 하나의 보드 안에 들어가는 스크랩을 조회하는 기능과 업데이트하는 기능만 존재하기 때문에 해당 보드 안에 스크랩을 검색하거나, 정렬하는 기능을 제공할 예정이 없어서 NoSQL의 장점을 잘 살릴 수 없었습니다.
4. JSON 형태를 MySQL의 열에 저장
따라서 저희는 MySQL의 장점과 NoSQL 구조를 살리기 위해서, 원래의 MySQL의 데이터 구조에서 하나의 열만을 추가하여 해당 열에 보드의 정보인 JSON 데이터구조를 저장하기로 하였습니다.
해당 열은 @Column(columnDefinition = "TEXT") private String contents;
매우 긴 문자열 구조이기 때문에 TEXT 데이터 타입으로 데이터를 저장하였습니다.
public class Board extends BaseTimeEntity {
@Id
@GeneratedValue
@Column(name = "board_id")
private Long id;
@Column(columnDefinition = "BINARY(16)", nullable = false, unique = true)
private UUID uuid;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", nullable = false)
private User user;
@Column(length = 100, nullable = false)
private String title;
@Column(columnDefinition = "boolean", nullable = false)
private boolean isPublic;
@Column(columnDefinition = "boolean default false", nullable = false)
private boolean isShared;
private LocalDateTime fixedDate;
@Column(nullable = false)
private TAG tag;
@Column(length = 1000)
private String description;
@Column(columnDefinition = "TEXT")
private String contents;
@ColumnDefault("0")
private Long heartCnt;
@ColumnDefault("0")
private Long viewCnt;
@ColumnDefault("0")
private Long shareCnt;
}첫 번째 단점으로는 '스크랩 데이터가 중복된다.'입니다.
스크랩 테이블이 따로 존재하지만, 해당 contents의 컬럼에도 해당 데이터가 동시에 들어가므로 데이터가 중복될 수 있습니다.
두 번째 단점은 '유효성 검사가 되지 않는다'입니다.
해당 컬럼이 null일 수도 있고, null이 아닐 수도 있어서 null 관련된 유효성을 검사하지 못하고, 데이터 구조가 올바르게 저장되었는지도 정확하게 파악할 수 없습니다.
세 번째 단점은 '검색과 정렬 등 여러 기능을 사용하지 못한다.'입니다.
그러나, 현재 저희 보드 서비스에서는 검색, 정렬을 사용하지 않으므로 해당되지는 않습니다. 그러나, 나중에 서비스가 더 고도화되어 검색, 정렬, 개수 조회등을 구현하게 된다면 MonogDB를 사용할 계획을 하고 있습니다.
하지만 이러한 단점에도 불구하고, 빠른 기능 구현 및 새로운 DB 구축 최소화와 같이 시간 및 비용 측면에서도 우수하고, 프론트와 백엔드 모두 정보를 가공할 필요가 없는 등 여러 장점이 더 많아서 해당 방법을 사용하기로 하였습니다.

참고 자료 : https://velog.io/@effirin/DB에-JSON-저장하기
2️⃣ 결론
- 이전까지는 MySQL은 당연히 관계형 데이터구조를 가지고 있어야하고, NoSQL DB는 JSON과 같이 비관계형 데이터구조를 가지고 있으므로 두 가지를 혼합해서 사용하는 방법을 생각해보지 못했습니다. 그러나, 멘토님들의 조언과 참고자료를 바탕으로 장점과 단점을 비교해보니, 현재 저희 서비스에 적합한 DB 구조는 MySQL과 NoSQL 데이터 베이스 구조를 혼합한 구조라는 것을 알 수 있었습니다. 그러나, 여러 단점이 아직도 존재하기 때문에 완벽한 구조라고는 할 수 없지만 현재 상황에서는 빠른 개발과 배포 및 비용 측면에서 적합한 구조였고, 서비스가 더 고도화될수록 언제든지 데이터베이스 구조가 변경될 수 있기 때문에 앞으로 기능 개발을 위해서 MongoDB도 학습하여 철저하게 꼭 필요한 순간이 되면 도입할 수 있도록 대비해야겠다는 생각을 하게 되었습니다.
