0️⃣ 서론
API 성능 향상을 위해서, SQL 튜닝 관련 블로그 글을 읽다가 IS NOT NULL, IS NULL을 사용하면 인덱스를 사용해도, 전체 table을 full scan한다는 말을 보게 되었습니다.
저희 서비스에서는 User Table에서 탈퇴 날짜인 deleted_date를 null로 하고, 탈퇴하면 해당 column을 업데이트하는 방식으로 탈퇴여부를 확인하고 있었습니다.
모든 API에서는 해당 회원이 유효한 회원인지 확인하기 위해서 탈퇴한 회원인지 확인하는 과정이 모두 들어갑니다.
아래의 코드는 스크랩을 검색하는 서비스 로직입니다.
이처럼 User user = userService.validateUser(email);으로 해당 회원의 유효성을 검사를 하는 과정이 있습니다.
@Transactional
public Slice<GetScrapResponse> searchScraps(String email, String keyword, Pageable pageable) {
User user = userService.validateUser(email);
Slice<Scrap> scrapSlice = scrapRepository.searchKeywordInScrapOrderByCreatedDateDesc(user,
keyword, pageable);
return scrapSlice.map(scrap -> GetScrapResponse.of(scrap,
memoRepository.findMemosByScrapAndDeletedDateIsNull(scrap)));
}@Transactional
public User validateUser(String email) {
return userRepository.findByEmailAndDeletedDateIsNull(email).orElseThrow(
() -> new NotFoundException(ErrorCode.NOT_EXISTS_MEMBER)
);
}즉, users 테이블에서 Email이 유저의 email 인 지와 deletedDate is null인지를 확인하는 SQL 쿼리가 나가게 됩니다.
그러면 해당 SQL 쿼리가 유저가 10000000(1천만)명인 경우에 성능이 어떻게 되는지와 해당 SQL 쿼리를 개선하기 위해서 튜닝하는 과정까지 알아보겠습니다.
1️⃣ 본론
1. 더미데이터 생성
우선, SQL 쿼리의 성능의 차이를 확실하게 비교하기 위해서는 데이터가 최대한 많이 있는 것이 좋습니다.
따라서, 유저가 10000000(1천만)명인 경우의 SQL의 성능을 확인하기 위해서, 아래의 더미데이터들을 생성하겠습니다.
이때의, 프로시저를 이용해서 생성해주었습니다.
- 프로시저는 RDBMS에서 다수의 쿼리를 하나의 함수처럼 실행하기위한 쿼리의 집합입니다.
- 장점은 하나의 요청으로 SQL 명령을 여러번 실행할 수 있습니다.
- 단점은 데이터에 대한 내용 변경시, 프로시저를 변경해야 할 가능성이 존재합니다.
참고 자료 : https://velog.io/@jkijki12/MySql-더미데이터-생성하기
DELIMITER $$
DROP PROCEDURE IF EXISTS insertUserDummyData$$
CREATE PROCEDURE insertUserDummyData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 10000000 DO
IF i <= 1000000 THEN
INSERT INTO users(user_id, created_date, modified_date, email, name, profile_url, provider, role)
VALUES(i, now(), now(), concat(i,'@gmail.com'), concat('이름', i), concat('profile_url', i), 0, 'USER');
ELSEIF (i<= 3000000 AND i >= 1000001) THEN
INSERT INTO users(user_id, created_date, modified_date, deleted_date, email, name, profile_url, provider, role)
VALUES(i, now(), now(), now(), concat(i,'@gmail.com'), concat('이름', i), concat('profile_url', i), 0, 'USER');
ELSEIF (i<= 5000000 AND i >= 3000001) THEN
INSERT INTO users(user_id, created_date, modified_date, email, name, profile_url, provider, role)
VALUES(i, now(), now(), concat(i,'@gmail.net'), concat('이름', i), concat('profile_url', i), 0, 'USER');
ELSEIF (i <= 6000000 AND i>= 5000001) THEN
INSERT INTO users(user_id, created_date, modified_date, deleted_date, email, name, profile_url, provider, role)
VALUES(i, now(), now(), now(), concat(i,'@gmail.com'), concat('이름', i), concat('profile_url', i), 0, 'USER');
ELSEIF (i<= 8000000 AND i >= 6000001) THEN
INSERT INTO users(user_id, created_date, modified_date, email, name, profile_url, provider, role)
VALUES(i, now(), now(), concat(i,'@gmail.com'), concat('이름', i), concat('profile_url', i), 0, 'USER');
ELSE
INSERT INTO users(user_id, created_date, modified_date, deleted_date, email, name, profile_url, provider, role)
VALUES(i, now(), now(), now(), concat(i,'@gmail.com'), concat('이름', i), concat('profile_url', i), 0, 'USER');
END IF;
SET i = i + 1;
END WHILE;
END$$
DELIMITER $$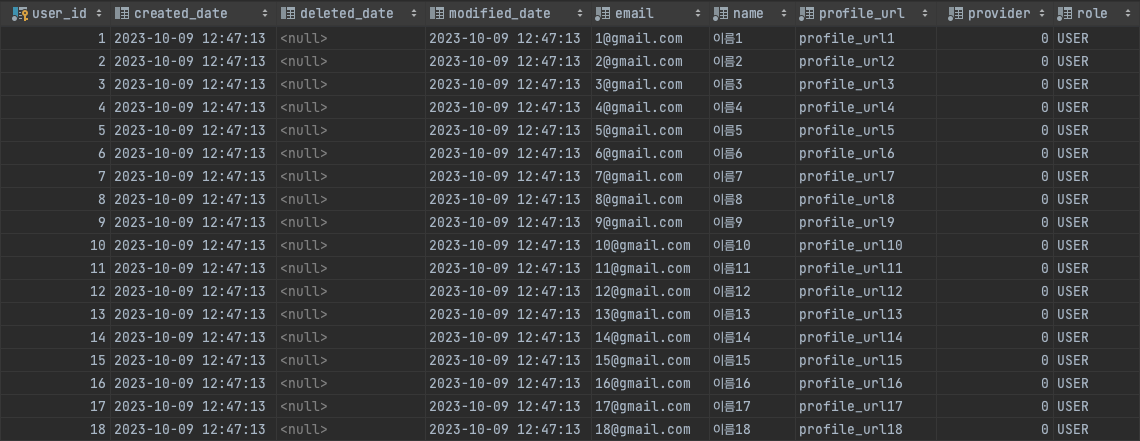
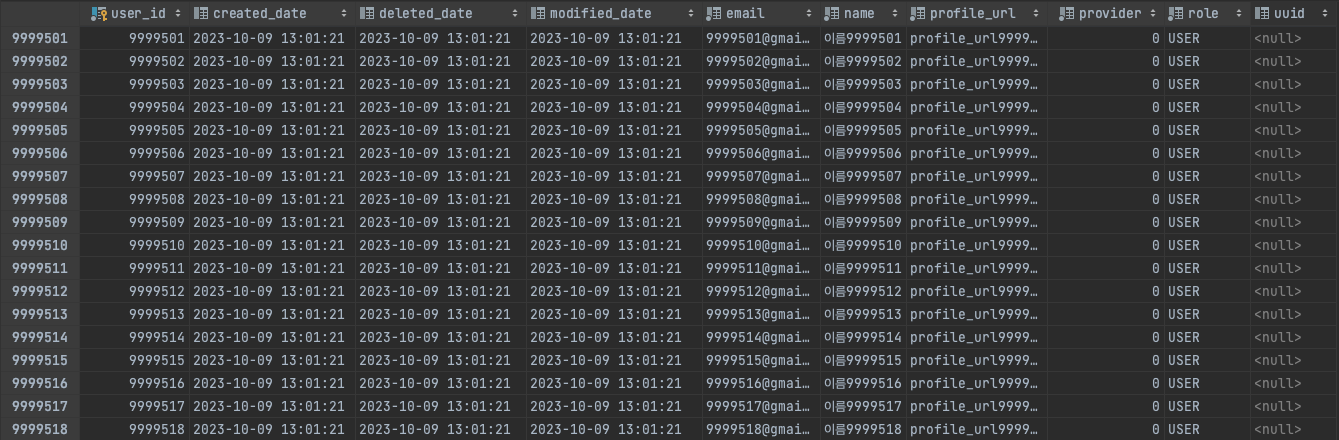
위의 사진에서 더미 데이터들이 성공적으로 생성되었음을 확인할 수 있습니다.
2. MySQL Explain을 사용하여 현재 유저 조회 SQL 성능 살펴보기
MySQL Explain은 '데이터 베이스가 데이터를 찾아가는 일련의 과정을 사람이 알아보기 쉽게 DB 결과 셋으로 보여주는 것'입니다.
따라서, MySQL Explain 실행계획을 활용하여 기존의 쿼리를 튜닝할 수 있을 뿐만 아니라 성능 분석, 인덱스 전략 수립 등과 같이 성능 최적화에 대한 전반적인 업무를 처리할 수 있습니다.
아래의 SQL 쿼리를 MySQL Explain으로 데이터 베이스의 성능 및 쿼리를 살펴보겠습니다.
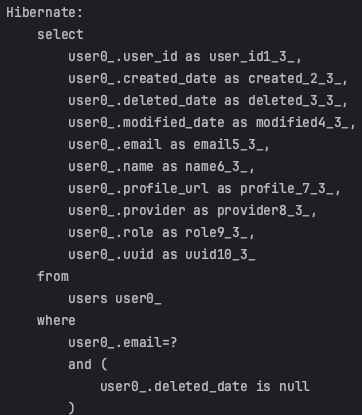
위의 SQL 쿼리를 아래의 EXPLAIN으로 나타내었습니다.
EXPLAIN
SELECT
users.user_id,
users.created_date,
users.deleted_date,
users.modified_date,
users.email,
users.name,
users.profile_url,
users.provider,
users.role,
users.uuid
from
users
where
users.email = '7000000@gmail.com'
and users.deleted_date is nullMySQL Explain 결과의 각 항목별 의미
1. id
- SELECT 쿼리 별 부여되는 식별자 값(행이 어떤 SELECT 구문을 나타내는 지를 알려주는 것)
2. select_type : 각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시되는 칼럼
- SIMPLE : 단순 SELECT (Union 이나 Sub Query 가 없는 SELECT 문)
- PRIMARY : UNION이나 서브쿼리를 가지는 SELECT 쿼리의 실행 계획에서 가장 바깥쪽에 있는 단위 쿼리
- UNION : UNION 쿼리에서 Primary를 제외한 나머지 SELECT, UNION과 UNION ALL 절로 생성된 임시 테이블을 의미
- DEPENDENT_UNION : UNION 과 동일하나, 외부 결과에 의존할 때 표현된다. UNION 쿼리가 내부에서 사용되었을때 표현된다.
- UNION_RESULT : UNION 쿼리의 결과물
- SUBQUERY : Sub Query 또는 Sub Query를 구성하는 여러 쿼리 중 첫 번째 SELECT문(FROM절 외에서 사용되는 서브 쿼리를 의미한다.)
- DEPENDENT_SUBQUERY : Sub Query 와 동일하나, 외곽쿼리에 의존적임 (값을 공급 받음)
- DERIVED : SELECT로 추출된 테이블 (FROM 절 에서의 서브쿼리 또는 Inline View)
- MATERIALIZED : MySQL 5.6 에서부터 추가되었으며, IN 절 내의 서브쿼리를 임시테이블로 만들어 조인을 하는 형태로 최적화를 해준다.
- UNCACHEABLE SUBQUERY : Sub Query와 동일하지만 공급되는 모든 값에 대해 Sub Query를 재처리하여 캐싱되지 못한다.
- UNCACHEABLE UNION : UNION 과 동일하지만 공급되는 모든 값에 대하여 UNION 쿼리를 재처리
3. Type : 각 테이블의 레코드를 어떻게 읽었는지에 대한 접근 방식
💡 쿼리 튜닝 시 반드시 체크해야 할 중요한 정보입니다.
- ALL(테이블 풀 스캔)을 제외한 나머지는 모두 인덱스를 사용하는 접근 방식입니다.
- system에서 ALL으로 갈수록 성능이 느려집니다.
- MySQL 옵티마이저는 이러한 접근 방법과 비용을 함께 계산해서 최소의 비용이 필요한 접근 방법을 선택해 쿼리를 처리합니다.
접근 방식
- system : 레코드가 1건만 존재하는 테이블 또는 한 건도 존재하지 않는 테이블을 참조하는 형태
- const : 테이블의 레코드 건수와 관계없이 쿼리가 프라이머리 키나 유니크 키 컬럼을 이용하는 WHERE 조건절을 가지고 있다.
- 반드시 1건을 반환하는 쿼리의 처리 방식
- eq_ref : 조인을 할 때 Primary Key
- ref : 조인을 할 때 Primary Key 혹은 Unique Key가 아닌 Key로 매칭하는 경우
- 동등(Equal) 조건으로 검색할 때 사용하는 접근 방식
- ref 타입은 반환되는 레코드가 반드시 1건이라는 보장이 없으므로 const, eq_ref 보다는 느리지만 동등한 조건으로만 비교되기에 매우 빠른 레코드 조회 방법 중 하나
- ref_or_null : ref 와 같지만 null 이 추가되어 검색되는 경우
- index_merge : 두 개의 인덱스가 병합되어 검색이 이루어지는 경우
- unique_subquery : IN 절 안의 서브쿼리에서 Primary Key가 오는 특수한 경우
- index_subquery : unique_subquery와 비슷하나 Primary Key가 아닌 인덱스인 경우
- range : 특정 범위 내에서 인덱스를 사용하여 원하는 데이터를 추출하는 경우
- 인덱스를 하나의 값이 아닌 범위로 검색하는 경우
- 주로 “<, >, IS NULL, BETWEEN, IN, LIKE” 등의 연산자를 이용해 인덱스 검색할 때 사용
- 일반적으로 애플리케이션의 쿼리가 가장 많이 사용하는 접근 방법
- index : 인덱스를 처음부터 끝까지 찾아서 검색하는 경우(인덱스 풀스캔)
- all : 테이블을 처음부터 끝까지 검색하는 경우(테이블 풀 스캔)
- 가장 비효율적인 방법
4. key : 최종 선택된 실행 계획에서 사용되는 인덱스
- 쿼리 튜닝 시 key 칼럼에 의도했던 인덱스가 표시되는지 확인하는 것이 중요
- 실행 계획의 type이 ALL일 때와 같이 인덱스를 전혀 사용하지 못하면 NULL로 표시됨
5. key_len : 선택된 인덱스의 길이
- 쿼리를 처리하기 위해 다중 칼럼으로 구성된 인덱스에서 몇 개의 칼럼까지 사용했는지 표기
6. ref : 접근 방법이 ref면 참조 조건(equal 비교 조건)으로 어떤 값이 제공됐는지 표시
- 상숫값 → const, 다른 테이블의 칼럼값이면 그 테이별명과 칼럼명이 표시
- 조인 칼럼의 타입(NUMBER, VARCHAR 등)은 동일하게 일치시키는 편이 좋다.
7. rows : 실행 계획의 효율성 판단을 위해 예측했던 레코드 건수
- 쿼리를 처리하기 위해 얼마나 많은 레코드를 읽고 체크해야 하는지를 의미
8. filtered : 필터링되고 남은 레코드의 비율
- 통계 값 바탕으로 계산한 값으로 실제 결과 값과 반드시 일치하지 않는다.
9. extra : 옵티마이저가 어떻게 동작하는지에 대해 알려주는 힌트 값
- Using filesort : ORDER BY 처리가 인덱스를 사용하지 못할 때 실행 계획의 Extra 칼럼에 표시
- 이는 조회된 레코드를 정렬용 메모리 버퍼에 복사해 퀵 소트 또는 힙 소트 알고리즘을 이용해 정렬 수행
- ORDER BY가 사용된 쿼리의 실행 계획에서만 나타날 수 있음
- 많은 부하를 일으키므로 가능하다면 쿼리를 튜닝하거나 인덱스를 생성하는 것이 좋음
- Using index(커버링 인덱스) : 인덱스만 읽어서 쿼리를 모두 처리할 수 있는 경우
- Using temporary : 쿼리를 처리하는 동안 중간 결과를 담아 두기 위해 임시 테이블(Temporary Table)을 생성하여 표시된 것
- Using index for skip scan : MySQL 옵티마이저가 인덱스 스킵 스캔 최적화를 사용할 경우
- Using join buffer(Block Nested Loop, hash join) : 빠른 쿼리 실행을 위해 조인되는 칼럼에는 인덱스를 생성
- Using where : MySQL 엔진에서 별도의 가공을 해서 필터링 작업을 처리한 경우
참고 자료
위의 MySQL Explain을 실행하면, 아래와 같이 결과가 나오게 됩니다.

위의 결과표를 각 항목에서 SQL 성능에서 중요한 항목인 type과 rows, extra를 해석해보겠습니다.
- type은 ALL입니다.
- 즉, 현재는 테이블을 처음부터 끝까지 검색하는 경우(테이블 풀 스캔)입니다.
- 따라서, 가장 비효율적인 방법이므로 성능을 최적화하는 것이 중요합니다.
- rows는 9966666입니다.
- 실행 계획의 효율성 판단을 위해 읽고 체크해야하는 레코드 건수가 9966666로 매우 많습니다.
- extra는 Using where입니다.
- 즉, MySQL 엔진에서 별도의 가공을 해서 필터링 작업을 처리한 경우입니다.
3. 최적화할 수 있는 방법 생각해보기
MySQL Explain 결과값을 보고 나서, 생각한 최적화 방법입니다.
따라서, 실제로 최적화되었는지 알 수 없지만, 다음 블로그글으로 실제로 최적화되는지 확인해보겠습니다.
1. 저희는 이메일이 고유값이기 때문에 반환되는 레코드가 반드시 1건이라는 보장이 있습니다.
- const: 모든 컬럼에 대해 PK, 유니크 키 등 동등 조건으로 검색 (반드시 1건의 레코드만 반환)
- 따라서, email을 unique 키로 변경하여 MySQL Explain의 type을 const로 변경하려고 합니다.
@Getter
@NoArgsConstructor
@Entity
@ToString(exclude = "scrapList")
@Table(name = "users")
public class User extends BaseTimeEntity implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long id;
@OneToMany(mappedBy = "user")
private List<Scrap> scrapList = new ArrayList<>();
@Column(length = 100, nullable = false)
private String name;
@Column(length = 320, nullable = false)
private String email;
@Column(length = 2083, nullable = false)
private String profileUrl;
@Column(nullable = false)
private Provider provider;
private String uuid;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private Role role;
}2. email에 index를 생성합니다.
- 현재 아래의 사진처럼 users의 index는 primary인 user_id만 되어있습니다.
- 따라서, email 관련 index를 추가하여 테이블 풀 스캔을 하지 않도록 할 예정입니다.

2️⃣ 결론
- 이전까지는 기능 개발을 하는 데에만 집중하고, 프로젝트 기간이 2~3개월로 짧아서 최적화까지는 하지 못했습니다. 그러나, 이번달 초에 출시하고 나서 거의 기능 개발이 마무리 되어서 성능 향상을 위해서 최적화를 하기 시작하면서 새로운 부분과 SQL을 더 깊이 알 수 있는 시간이어서 아주 뜻깊은 시간이었습니다.
- 처음으로 MySQL Explain을 사용해서 현재 작성한 코드 및 쿼리의 성능을 살펴보았습니다. 당연히 email과 같은 부분이 index되어 있는 줄 알았는데, 자세히 살펴보면서 index가 user_id만 되어 있는 모습을 보고, 당연한 것은 없고 더 자세하게 살펴보아야겠다는 생각을 했습니다.
- 성능을 향상할 부분은 스크랩 조회 기능과 같이 여러 테이블을 조인하고 복잡한 쿼리만 해당되는 줄 알았습니다. 더 나아가, index는 되어 있으므로 SQL 튜닝보다는 open search와 같은 검색 오픈소스를 사용하는 것이 성능면에서는 훨씬 좋지 않을까 생각했습니다. 그러나, 바로 새로운 기술을 도입하면 새로운 기술을 배우고 DB를 만들고 비용이 들기 때문에 현재 시점에서 최대한 SQL을 최적화하여 최대한 투입되는 리소스를 줄이고 최적화가 더이상 되지 않는 경우에 새로운 기술을 도입하는 것이 좋겠다는 생각을 했습니다.
