0️⃣ 서론
이전에 마지막으로 이야기한 유저 조회 최적화 방법을 적용해보겠습니다.
https://velog.io/@da_na/SQL-튜닝-유저-조회-SQL-튜닝-및-성능-최적화-1
그리고 해당 유저 조회 최적화 방법으로 얼마나 이전보다 성능이 향상되었는지를 확인해보는 시간을 가지도록 하겠습니다.
이전에 이야기한 최적화 방법은 아래와 같습니다.
1. email을 unique 키로 변경하여 MySQL Explain의 type을 const로 변경한다.
2. email에 index를 생성합니다.
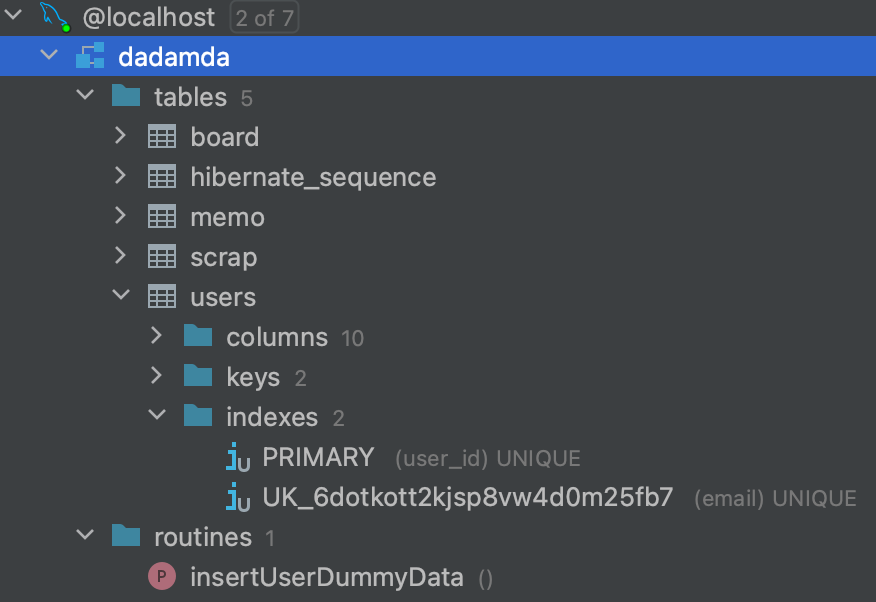
- 현재 아래의 사진처럼 users의 index는 primary인 user_id만 되어있습니다.
- 따라서, email 관련 index를 추가하여 테이블 풀 스캔을 하지 않도록 할 예정입니다.
이때, 이전에는 유저가 1천만 명인 경우를 예를 들어서, 더미데이터를 생성했지만 실제 성능 향상을 비교할 때에는 실제 서비스 사용자가 될 가능성이 높은 1만명의 유저를 더미데이터로 생성하여 성능을 비교하고자 합니다.
1️⃣ 본론
1. Email을 Unique index 생성하기
이전에 이야기한 방법은 총 2가지 방법이었습니다.
1. email을 unique 키로 변경한다.
2. email 관련 index를 생성한다.
그러나, JPA에서는 unique 키로 설정해주면 index를 생성해주기 때문에 따로 index 설정은 하지 않아도 되기 때문에 아래의 코드처럼 unique = true만 추가하여 주겠습니다.
@Column(length = 320, nullable = false, unique = true)
private String email;그러면 아래의 그림과 같이 users 테이블의 indexes에 email이 생성되었음을 알 수 있습니다.
Users 테이블 관련 JPA 전체 코드입니다.
@Getter
@NoArgsConstructor
@Entity
@ToString(exclude = "scrapList")
@Table(name = "users")
public class User extends BaseTimeEntity implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long id;
@OneToMany(mappedBy = "user")
private List<Scrap> scrapList = new ArrayList<>();
@Column(length = 100, nullable = false)
private String name;
@Column(length = 320, nullable = false, unique = true)
private String email;
@Column(length = 2083, nullable = false)
private String profileUrl;
@Column(nullable = false)
private Provider provider;
private String uuid;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private Role role;
}그리고 MySQL 데이터 베이스의 실행계획(Explain)의 결과를 확인해보겠습니다.
EXPLAIN
SELECT
users.user_id,
users.created_date,
users.deleted_date,
users.modified_date,
users.email,
users.name,
users.profile_url,
users.provider,
users.role,
users.uuid
from
users
where
users.email = '7000@gmail.com'
and users.deleted_date is null-
EMAIL UNIQUE 인덱스 전

-
EMAIL UNIQUE 인덱스 후

여기에서 가장 크게 달라진 점은 type 부분입니다.
즉, 이전에 예측한 결과처럼 EMAIL을 Unique로 변경하였기 때문에 반드시 1건의 레코드만을 반환한다는 조건을 만족하게 됩니다.
따라서 Type이 ALL 테이블 풀 스캔에서 const로 변경되었습니다.
다시 한번 const의 방식을 설명해보면, const는 테이블의 레코드 건수와 관계없이 쿼리가 프라이머리 키나 유니크 키 컬럼을 이용하는 WHERE 조건절을 가지고 있으며, 반드시 1건을 반환하는 쿼리의 처리 방식입니다.
Type에는 system, const, eq_ref, ref, ref_or_null, index_merge, unique_subquery, index_subquery, range, index, all 방식이 있는데 system에서 all로 갈 수록 성능이 느려지기 때문에 all에서 const로 변경되었으므로 성능이 향상되었다고 예측할 수 있습니다.
2. 인덱스 생선 전 후의 성능 비교
성능을 비교하기 전에 속도에 영향을 주는 캐시를 지워서, 성능 비교를 정확하게 비교하고자 하였습니다.
SELECT SQL_NO_CACHE * FROM users;
SELECT
users.user_id,
users.created_date,
users.deleted_date,
users.modified_date,
users.email,
users.name,
users.profile_url,
users.provider,
users.role,
users.uuid
from
users
where
users.email = '7000@gmail.com'
and users.deleted_date is null
그러나, 아래와 같이 현재 MySQL의 버전이 8.0.33이기 때문에, SQL_NO_CACHE 관련 Query Cache문은 MySQL 5.7.20 버전부터 Deprecated되었습니다.
SELECT SQL_NO_CACHE * FROM users;따라서 해당 쿼리를 사용하지 않고, mysql 서버를 종료했다가 다시 실행시켜서 캐시를 직접 없애는 방법을 사용하여 시간을 측정하였습니다.
-
인덱스 생성 전 (1만건의 더미데이터)

-
인덱스 생성 후 (1만건의 더미데이터)

Actual Total Time : 12msec -> 0.000292msec 로 줄어들었음을 알 수 있습니다.
2️⃣ 결론
- 이때, 유의해야 할 점은 인덱스를 생성하면 조회 성능은 향상되지만, 삽입, 수정 성능은 떨어질 수 있습니다. 유저 테이블에 유저를 생성하고 수정하는 경우가 많은지 아니면 조회하는 경우가 많은지 판단하여 성능을 최적화해야 합니다. 하지만 이번 경우에는 회원가입을 하는 경우보다 유저가 회원을 조회하는 경우가 많기 때문에, 해당 인덱스를 추가하도록 하겠습니다.
- 스크랩 테이블과 같은 경우에는 생성이 많은지 조회가 많은지를 알 수 없기 때문에 사용자 로그 분석을 통해서 사용자들의 행동 패턴을 추적하여 성능을 최적화하는 방식으로 진행해야 될 것 같습니다.
- 이번 경우의 1만건의 더미 데이터에서는 12msec -> 0.000292msec로 줄어들었지만, 더 많은 데이터가 있을 수록 더 많은 격차가 생길 것입니다. 하지만 유저가 1만건보다 더 적을 수도 많을 수도 있기 때문에, 적절하게 생성하거나 현재 데이터를 토대로 최적화하는 것이 좋을 것이라고 생각합니다.
- 정확한 성능 비교를 위해, 비슷한 조건을 만들어 주고자 하였습니다. 따라서 성능에 영향을 줄 수 있는 캐시를 지우고 mysql 서버를 종료시켜서 비슷한 조건으로 통일시켰습니다. 이처럼 성능을 수치화해서 비교하는 것을 하기 위해서, 정확한 환경을 구축하는 것의 중요성을 다시 한 번 깨달을 수 있었습니다.
