Abstract
깊은 신경망은 학습이 더 어려움 따라서 이전보다 훨씬 더 깊은 네트워크를 효과적으로 학습하기 위한 Residual Learning Framework를 제안
즉 각 층을 독립적인 함수를 학습하는 방식이 아니라 해당 층 입력에 대한 잔차(residual)함수를 학습하는 방식으로 재정의함
이 방법은 학습을 더 쉽게 만들며 네트워크 깊이가 크게 증가했을 떄 정확도 향상에 유리하다는 사실을 포괄적인 실험결과를 통해 제시
1. Introduction
심층 합성곱 신경망 즉 deep CNN은 이미지 분류 분야에 획기적 발전을 이끌었고 깊은 네트워크는 low, mid, high level의 특징과 분류기를 end to end multi layer 방식으로 자연스럽게 통합하며 레이어의 깊이가 늘어날수록 특징의 level이 더욱 풍부 해질 수 있음 최근 연구에 따라 imagenet 데이터셋에서 최고의 성능을 보이는 결과들은 매우 깊은 모델을 활용하여 큰 이점을 얻음
여기서 의문이 생기는데 더 나은 네트워크를 학습하는 것은 단순히 레이어를 많이 쌓는 것으로 충분한가?
이 질문에 답을 하기 어려운 가장 큰 이유는 단순이 레이어를 많이 쌓는 것은 학습 초기부터 수렴을 가로막는 vanishing gradient(역전파 과정에서 입력층으로 갈수록 기울기가 점점 작아져서 입력 층에 가까운 층들에서 가중치 업데이트가 제대로 이루어지지 않음), gradient exploding(기울기가 입력층으로 갈수록 점차 커지다가 가중치들이 비 정상적으로 큰 값이 되면서 발산하는 현상) 문제에 있음 그러나 이 문제는 정규화된 초기화와 중간 정규화 레이어를 통해 상당 부분 해결되어 수십 개 층을 가진 네트워크도 역전파를 사용하는 확률적 경사하강법(SGD)로도 학습을 시작할 수 있게 됨
더 깊은 네트워크가 수렴하기 시작함에 따라 새롭게 성능이 저하되는 문제가 발생
네트워크 깊이가 증가하면 정확도가 어느 시점에 포화 상태에 도달한 뒤 급격히 떨어지기 시작함 이러한 정확도 하락은 오버피팅 문제가 아니었으며 이미 충분히 깊은 모델에 층을 더 쌓으면 학습 오류가 더 크게 증가한다는 사실이 보고되었고 실험을 통해 철처히 검증 함
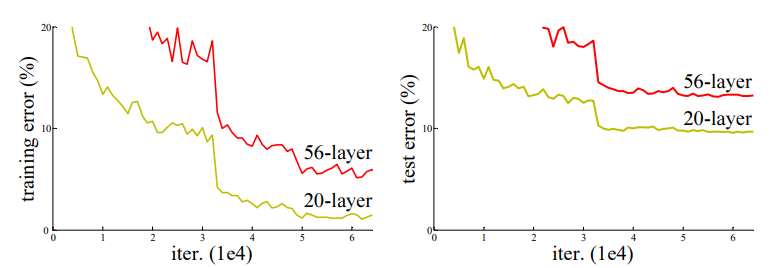
이러한 성능 저하는 모든 시스템이 같은 방삭으로 쉽게 최적화되는 것은 아님을 의미함
더 얕은 아키텍처와 그에 층을 더 쌓아 만든 깊은 아키텍처를 가정하였을 때 더 깊은 모델에는 구조적으로 추가된 층이 항등 매핑(그냥 값이 내려옴)을 가정하고 나머지 층은 학습된 더 얕은 모델에서 복사하면 이론상으로 더 깊은 모델이 더 얕은 모델보다 더 높은 학습 오차를 낼 이유가 없는데 실제 실험에서는 그냥 같거나 더 못한 성능을 보여줌
본 논문에서는 이러한 성능 저하 문제를 해결하기 위한 깊은 잔차 학습(deep residual learning) 프레임 워크를 제안
즉 단순히 여러 층을 쌓아 원하는 목적 함수를 직접 맞추려고 시도하는 대신 이들 층이 잔차 함수를 학습하게 끔 명시적으로 유도함
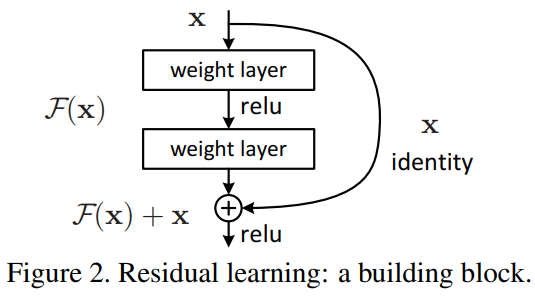
수학적으로 우리가 목표로하는 근본적인 매핑을 라고 할 때, 쌓아높은 비 선형 층들이 다른 매핑인 를 학습하도록 설계함 원래 매핑은 로 다시 표현됨 우리는 원본 매핑을 직접 최적화 하는 것 보다 잔차함수를 최적화 하는 편이 더 쉽다고 가정 극단적으로 항등 매핑 즉 더 이상학습 할 게 없 때 네트워크가 취할 수 있는 기본 해답 -> 더 깊은 네트워크가 최소한은 얕은 네트워크와 같은 결과를 낼 수 있게 하는 매핑이 최적이라면 비선형 층들을 여러 겹 쌓아 항등 매핑 자체를 맞추는 것 보다 잔차를 0에 가깝게 만드는 편이 더 쉽다는 의미
이때 는 shortcut연결을 갗춘 feedforward 신경망을 통해 구현할 수 있으며 shortcut연결은 하나이상의 층을 건너 뛰는 연결을 말함 여기서 shortcut연결은 단순히 항등 매핑을 수행하며 이 연결의 출력은 쌓인 층들의 출력에 더해짐 또 shortcut연결은 추가적인 파라미터나 계산 복잡도를 늘리지 않으며 전체 네트워크는 역전파를 사용하여 SGD로 end to end 학습이 가능하고 기존에 널리 쓰이는 라이브러리를 사용해도 solver를 변경하지 않고 구현 가능
따라서 이 논문이 수행한 결과는
1. 매우 깊은 잔차 네트워크는 최적화 하기 쉬우나 단순히 층을 쌓은 plain 네트워크는 깊이가 커질수록 더 높은 학습 오류를 보임
2. 깊은 잔차 네트워크는 깊이를 크게 늘릴 때 쉽게 정확도를 향상시키며 기존 네트워크보다 훨씬 우수한 결과를 냄
또한 최적화 난이도와 방법의 효과는 특정 데이터셋에 국한되지 않으며 1000층 이상의 모델까지도 가능성을 탐구
2. Related work
Residual Representations: 이미지 인식 분야에서 VLAD는 사전에 대한 잔차 벡터를 이용해 인코딩 하는 표현이며 Fisher vector는 VLAD의 확률적 버전으로 볼 수 있음
두 방법 모두 이미지 검색과 분류에서 강력한 얕은 표현으로 활용되어 왔고 벡터 양자화 과정에서 원본 벡터 대신 잔차 벡터를 인코딩 하는 방식이 더 효과적이라고 알려짐
저 수준의 비전과 컴퓨터 그래픽스 분야에서 편미분 방정식을 풀기 위해 널리 쓰이는 Multigrid 방법은 다중 스케일에서 가각의 하위 문제를 재정의 하는 방식을 취함 이때 각 하위 문제는 더 낮은 해상도와 더 높은 해상도 사이에서 발생하는 잔차 해 에 대응 Multigird의 대안인 hierarchal basis preconditioning역시 두 스케일 간의 잔차 벡터를 나타내는 변수를 사용
이러한 방식의 솔버(solver 수학 문제를 해결하는 소프트 웨어)들은 잔차 특성을 고려하지 않은 일반적인 솔버들 보다 훨씬 빠르게 수렴 이는 잘 구성된 문제설정 또는 사전 조건화가 최적화를 단순하게 할 수 있음을 보임
Shortcut connections: shortcut연결과 관련된 실무적이고 이론적인 연구는 오래 진행 되었고 초기 다층 퍼셉트론을 학습할 때 네트워크 입력에서 출력으로 직접 연결되는 선형층을 추가하는 방식이 이러한 예 중 하나
기울기 소실과 폭주문제를 해결하기 위해 중간 레이어 몇 개를 직접 보조 분류기로 연결하기도 함
shortcut연결을 통해 계층 반응, 기울기, 역전파 에러 등을 중심화 하는 여러 기법을 제안
이 연구와 동시에 진행된 highway network는 게이트 함수를 갖춘 shortcut연결을 제시함
이 게이트들은 데이터에 따라 달라지며 학습 파라미터를 갖는 반면 우리가 상요하는 항등 shortcut은 파라미터가 없음 highway network에서 게이트가 닫히면 그 레이어들은 비 잔차 함수를 표현하게 되지만 우리의 공식화에서는 항상 잔차함수를 학습하며 항등 shortcut은 결코 닫히지 않음 따라서 모든 정보는 항상 그대로 전달되고 여기에 더해 추가적인 잔차 함수를 학습하게 됨
3. Deep Residual Learning
3.1 Residual Learning
먼저 를 소수의 층만 쌓아서 학습해야 할 근본적인 매핑을 가정했을 떄 x는 이 layer들 중 첫 번쨰 층의 입력에 해당됨
여러 비선형 층이 복잡한 함수를 점근적으로 근사할 수 있다고 가정한다면 이 비선형 층들의 잔차함수 즉 도 점근적으로 근사할 수 있다고 가정하는 것과 동일함(입력과 출력의 차원이 같다고 전제)
따라서 쌓은 layer들이 직접 를 근사하게끔 기대하기 보다 이 층들이 잔차 함수 를 근사하도록 명시적으로 설정함 그러면 원래 함수는 로 다시 표현됨 이 두형태모두 궁극적으로 원하는 함수를 근사할 수 있으리라 가정 가능하지만 학습의 용이성은 달라질 수 있음
이렇게 함을 다시 생각하면 성능 저하 문제에 대한 반 직관적인 현상에서 동기를 얻은 것인데 추가로 쌓은 층이 항등 매핑으로 구성될 수 있다면 더 깊은 모델은 더 얕은 모델 보다 학습 오류가 결코 커지지 않아야 함 그런데 성능 저하문제는 솔버들이 여러 비선형 층으로 항등 매핑을 근사히가 어렵다는 점을 시사
반면에 잔차학습으로 재정의하면 항등매핑이 최적이라면 솔버는 단순이 여러 비선형 층들의 가중치를 0에 가깝게 만들어 항등매핑에 가까워 지도록 할 수 있음
실제로는 항등 매핑이 최적일 가능성은 낮지만 우리가 제안하는 이 재정의는 문제를 사전 조건화 하는데 도움이 될 수 있으며 만약 최적 함수가 0 매핑보다 항등 매핑에 더 가깝다면 이 함수를 완전히 새롭게 학습한느 것 보다 항등 매핑을 기준으로 작은 변형을 찾는 편이 더 쉬움 이는 실험 결과를 통해 학습된 잔차 함수들은 전반적으로 출력값이 작음을 보였으며 이는 항등 매핑이 일종의 합리적인 사전 조건을 제공함을 시사함
3.2 Identity Mapping by shortcuts
잔차학습을 여러 층을 쌓은(블록 형태) 부분마다 적용하며 하나의 빌딩 블록을 제시함 이 논문에서는 형식적으로 여기서 x와 y는 층들의 입력과 출력벡터를 나타내며 함수는 잔차 매핑을 의미 그림 2에 제시된 두 층 짜리에서 F는 이때 시그마는 렐루를 나타내고 편의상 bias는 생략
연산 F + x는 shortcut연결과 요소별 덧셈으로 구현하고 이 덧셈 후에 비선형을 추가로 적용(relu)
이 shortcut연결은 추가적인 파라미터나 계산 복잡도를 늘리지 않아 실제 활용 측면에서도 매력적일 뿐 아니라 plain네트워크와 residual네트워크를 비교하는 데 있어서도 중요함 따라서 우리는 동일한 파라미터 수, 동일한 깊이, 동일한 폭, 동일한 계산 비용을 갖춘 plain/residual 네트워크를 공정하게 비교 가능
입력차원과 출력차원이 달라지는 경우에는 shortcut연결을 통해 선형사영(정사영)을 수행하여 차원을 맞추어 줄 수 있음
위에 식에서도 사각행렬 를 사용할 수 있으나 항등 매핑 만으로도 성능저하 문제를 해결하기에 충분하고 효율적임을 보일 것이므로 차원을 맞출때만 사용
잔차함수의 형태는 유연하겨 2층 또는 3층을 사용하지만 더 많은 층을 사용하는 것도 가능함 단 한 층만 사용하는 것은 선형 층에 가깝게 되어 별다른 이점을 주지는 않음
여기까지의 표기는 단순화를 위해 Fc layer로 설명하였지만 convolutional layer에서도 동일하게 적용할 수 있으며 요소별 덧셈은 두 특성 맵에 대하여 채널별로 수행 됨
3.3 Network Architecture
따라서 여러 종류의 plain/residual 네트워크에서 실험하였고 일관된 현상을 관찰
Plain Network: baseline으로 VGG네트워크의 설계 철학에서 영감을 얻었으며 convolutional layer들은 대부분 3x3필터를 사용하며 다음의 규칙을 따름
1. 동일한 출력특성 맵 크기를 같은 레이어들에는 동일한 필터를 배정
2. 특성맵 크기가 절반이 되면 per-layer 연산 복잡도를 유지하기 위해 필터 수를 2배 늘림
다운 샘플링은 stride가 2인 합성곱 레이어로 직접 수행하고 네트워크의 마지막은 평균풀링 레이어와 1000차원의 fc레이어로 구성 가중치를 갖는 레이어는 34개
주목 포인트는 VGG보다 필터 수와 연산 복잡도가 낮음
Residual netsork: 위의 plain을 기반으로 shortcut연결을 삽입하여 해당 네트워크를 residual버전으로 전환 항등 연결은 입력과 출력이 같을때 바로 사용가능 차원이 늘어나게 된다면 두가지 방안 고려
1. 여전히 항등 매핑을 사용하되 차원이 늘어나는 부분에 0값을 채워 넣음 추가파라미터 필요 x
2. 1x1 합성곱을 사용해 차원을 맞추는 투영을 이용
3.4 Implementation
imagenet구현은 기존 방식을 따르며 이미지의 짧은 변을 256, 480범위에서 무작위로 뽑아 리사이즈하고 그대로 사용하거나 이미지를 좌우반전하여 224x224크기의 영역을 무작위로 crop하여 픽셀의 평균앖을 빼주고 표준 색상 증강 기법을 따름
각 합성곱 직후와 활성화 함수 직전에 BN을 사용하고 가중치 초기화는 He 초기화를 사용하고 모든 plain/residual 네트워크는 처음부터 학습함
SGD의 미니배치는 256을 사용하고 초기학습률은 0.1 오류가 plateau에 도달하면 10배로 감소
모델은 최대 60x10^4번 iteration까지 학습하며 weight decay는 0.0001, 모멘텀은 0.9를 사용하고 관행에따라 dropout은 사용하지 않음
4. Experiments
4.1 Imagenet classification
1000개의 클래스로 이루어진 imagenet 분류 데이터셋에서 이 방법을 평가 모델은 128만장의 학습 이미지로 학습하고 5만장의 검증 이미지로 평가 또한 테스트 서버를 통해 10만장의 테스트 이미지에 대한 최종 결과도 얻음
plain network: 먼저 깊이가 18층과 34층인 plain 네트워크를 평가
34층의 결과가 18층보다 떨어지는 것을 확인 할 수 있음
이 이유를 알기 위해 두 모델의 학습과정 전반과 오류 및 검증 오류를 비교
34층이 학습 전반에서 18층 보다 학습오류가 더 높게 유지되는 성능 저하 문제가 관찰
이는 18층의 네트워크 솔루션 공간이 34층 네트워크의 솔루션 공간의 부분집합임에도 불구하고 나타난 현상
이러한 최적화 난이도가 단순히 vanishing gradient문제라고 보기는 어렵다고 주장
모두 BN를 사용하기 때문에 forward되는 신호가 0이 아닌 분산을 갖도록 보장되고 backward되는 기울기 크기도 BN 덕분에 안정적인 상태를 유지함을 확인했기 때문임
즉 순전파와 역전파 모두 소실되지 않음을 확인 사실 34층도 여전히 경쟁력있는 정확도를 달성할 수 있는데 이는 솔버가 어느정도는 작동하고 있음을 의미 따라서 사실 지수적으로 낮은 수렴속도를 보이는 것이 아닌가? 가정
이는 학습 오류를 감소시키는데 영향을 주는 요인 일 수 있음
residual network: 18층과 34층인 residual네트워크를 평가 기본적인 네트워크 구조는 동일하지만 모든 3x3필터 쌍마다 shortcut연결을 추가한 점만 다름 차원이 증가할 때는 o으로 패딩하는 방식을 택함
이 방법은 추가적인 파라미터가 전혀 없음
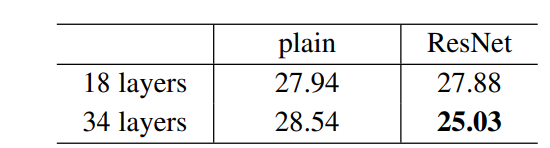
1. 잔차학습을 사용하면 상황이 반전되며 34층이 18층보다 더 우수한 결과를 보임
2. plain과 비교 했을 때 34층짜리는 top1 오류를 3.5퍼줄임 깊은 시스템에서 잔차학습이 효과적임을 증명
3. 18층에서는 유사한 정확도를 내지만 초기학습에서 더 빠른 수렴속도를 보임 지나치게 깊지 않은 경우 기존의 SGD도 좋은 해를 찾을 수 있지만 더 빠른 최적화를 돕는 역할을 수행
identity vs projection shortcut
파라미터가 없는 항등 shortcut이 학습에 도움을 주는 것은 확인했는데 차원이 변하면 어떻게 처리하는지 3가지 옵션을 비교
- 차원이 증가 할 떄 0으로 패딩 즉 늘어난 차원만 0으로 처리
- 차원이 증가할때 1x1 con을 사용하여 projection shotcut 나머지는 항등매핑
- 전부 projection
세 옵션은 모두 기존보다 좋은 성능임 B는 A보다 성능이 약간 더좋음 0에서 패딩된 차우너 부분에서 실제 잔차학습이 일어나지 않아서 B가 더 좋음
C가 B보다 성능이 근소하게 좋지만 추가 파라미터가 생김 투영 shortcut자체는 성능 저하 문제를 해결하는데 필수적인 요소는 아님 따라서 옵션 c는 배제
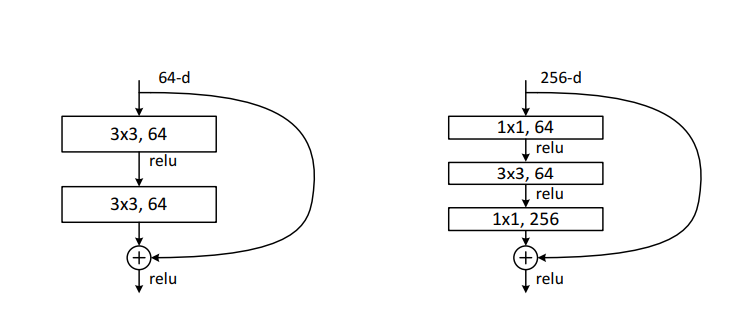
Deeper bottleneck architecture
이미지넷을 위한 더 깊은 네트워크 구조 소개
잔차를 2층대신 3층으로 설계하고 1x1합성곱 층은 차원을 줄이고 늘리는 역할을 담당하며 3x3층의 입력차원을 작게 만듬
파라미터가 없는 항등 shortcut은 특히 중요한데 projection으로 바꾼다면
이 shortcut은 두 개의 고차원(high-dimensional) 지점에 연결되어야 하므로 시간 복잡도와 모델 크기가 두 배가 됨 따라서 항등 shortcut은 bottleneck 구조에서 훨씬 더 효율적인 모델을 만들어 줌
50-layer ResNet: 34층짜리 네트워크에서 각 2층짜리 블록을 이 3층짜리 bottleneck 블록으로 대체하여 50층짜리 ResNet을 만듬
원이 증가할 때는 옵션 B를 사용
이 모델의 FLOPs(곱셈-덧셈 연산 수)는 약 38억
101-layer 및 152-layer ResNets: 더 많은 3층짜리 블록을 사용해 101층 및 152층 ResNet을 구성
네트워크 깊이가 크게 늘었음에도 불구하고 152층 ResNet의 113억FLOPs으로 이는 VGG-16/19 보다 여전히 낮은 수준