[논문리뷰] Training Region-based Object Detectors with Online Hard Example Mining. CVPR 2016 (OHEM)
Abstract
객체탐지는 Region-based CNN으로 상당한 발전을 이루었지만 훈련과정은 여전히 많은 휴리스틱과 튜닝이 어려운 하이퍼파라미터가 포함된다.
즉 과정이 end to end하지 못하며 각각의 stage를 최적화하는 데에는 많은 비용이 듦
-> 왜 end-to-end해야 하는가? 한 단계의 최적화가 다른 단계에 영향을 미치지 못함
-> task 마다 새롭게 단계마다 최적화 해주어야 함
-> 이는 결국 모델의 일반화 성능이 부족해지는 문제로 귀결될 수 있다.
따라서 Region-based CNN을 학습하기 위한 간단하지만 효과적인 Online hard example mining(OHEM)을 제시
detection 데이터셋은 많은 easy sample과 적은 hard sample이 존재함
hard sample을 자동으로 선택하는 것은 학습을 더 효과적이고 효율적으로 만들 수 있음
OHEM을 통해 여러 휴리스틱과 하이퍼파라미터를 제거함으로 모델을 End-to-End와 하자 이는 데이터셋이 더 크고 어려울수록 효과가 커진다.
1. Introduction
이미지 분류와 객체탐지는 CV의 가장 기본적인 과제인데 object detector는 객체 탐지의 문제를 이미지 분류문제로 축소시켜 변환하여 학습함 -> regoin proposal로 localization을 수행하고 딥러닝으로 classification을 처리
하지만 이렇게 축소하게 되면 레이블이 부여된 객체 수와 배경의 수의 간의 심각한 불균형이 존재하게 됨
이를 고전적인 슬라이딩 윈도우로 처리하면 1:10만까지 올라가며 최근 방법들에서는 좀 완화하였지만 여전히 불균형비율이 높음
이러한 문제는 불균형을 해결하면서 더 빠르고 높은 정확도를 제공하는 학습법이 필요함을 제시함
이는 과거부터 존재했던 문제이고 부트스트래핑(bootstrapping) 또는 현대에는 하드 네거티브 마이닝(hard negative mining)이라는 방법으로 과거에는 해결해 왔음
하드 네거티브 마이닝: 많은 수의 네거티브 샘플 중 대부분은 쉬운문제 따라서 모델이 틀린 어려운 문제만 지속적으로 학습시키자
-> 이미 어느 정도 학습된 모델의 가중치 학습을 중단시킴
-> 고정된 모델에 학습에 사용되지않은 이미지를 입력으로 사용하여 일정 confidence score이상의 오답샘플을 자름
-> 해당 샘플들 오답 샘플로 하여 다시 가중치 학습을 지속함
-> 즉 특정 주기마다 모델이 어려워하는 오답샘플을 찾고 이를 중심으로 학습시킴
왜? 워차피 오답샘플이 압도적으로 많음 정답샘플과의 균형을 위해서는 워차피 골라서 일부만 사용해야함 그렇다면? 어려워하는 샘플만 골라서 학습시키자
이렇게 효과적인 방법이 있는데 왜 fast-rcnn과 후속 모델에서는 사용하지 않았을까?
수백만개의 예제를 SGD로 학습하는 deep cnn기반의 purely online learning algorithm으로 변환됨에 따라 생긴 기술적의 어려움에 있음
즉 기존의 epoch단위 학습(전체 데이터셋의 규모로 모델 변화)에서 mini batch의 iteration단위(좀 더 작은 단위로 모델 가중치가 변함) 학습으로 변환됨에 따라 생긴 차이로 인해 적용하기가 어려움
기존 방법은 일정 기간동안 고정된 모델로 새 예제를 찾아 학습집합에 포함시키고 이어지는 기간동안 그 고정된 학습집합으로 모델을 학습함
그러나 CNN을 SGD로 학습할 때는 수십만 단계의 iteration동안 업데이트가 필요하고 이 중에서 몆번의 iteration이라도 정지하게 되면 학습속도가 매우 느려짐
따라서 purely online form of hard example selection기법이 필요함
-> end to end
즉 이 논문에서는 purely online 환경을 위한 새로운 부트스트래핑 기법 OHEM을 제안함
SGD을 간단히 수정해서 각 예제의 현재 loss 값에 따라 비균등하고 동적인 분포로 예제를 샘플링함
-> 어떻게? 각 sgd 의 미니배치에는 1~2장의 이미지 밖에 없지만 수천개의 후보영역(region proposal)이 존재함 이 후보예제들중 loss가 크고 다양성이 높은 예제를 우선하여(오답샘플을) 샘플링 하여 backpropagation을 수행함 -> 이를 fast RCNN에 도입
2. related work
객체탐지는 cv분야에서 가장 오래되고 근본적인 문제를 다룸
최근에 hard negative mining 이라고 불리는 데이터 부트스트래핑 개념은 대부분 객체 탐지기에 공통적으로 사용되어 왔음
이 접근방식중 상당수는 CNN으로 특징추출하고 나서도 여전히 SVM을 사용했는데 왜? hard negative mining은 기존에 SVM에서 사용했기 때문
한가지 주목할 예외는 Fast RCNN과 Fater RCNN인데 이는 SVM 안쓰고 SGD기반의 순수 온라인기반(END TO END)으로 학습되므로 기존의 방법을 적용할 수 없음
본 연구는 이 문제를 해결하기 위해 최적화와 탐지 정확도를 향상시키는 온라인 하드 예제 채굴 알고리즘을 제안
Hard example mining: 널리 사용되는 하드 예제 채굴 알고리즘은 두 가지가 있는데 첫 번째는 SVM 최적화에 사용되는 방식 이 경우 학습 알고리즘은 작업 집합(working set)을 유지하며 SVM을 이 집합에서 수렴할 때까지 학습한 후
특정 규칙에 따라 일부 예제를 제거하고 새로운 예제를 추가하면서 작업 집합을 갱신하는 과정을 반복
이 규칙은 negative sample 중 쉬운 예제를 제거하고 어려운 예제를 추가하여 최적의 SVM을 찾음 여기서 중요한 점은 작업 집합은 전체 학습 집합의 부분 집합임
두 번째 방법은 SVM이 아닌 모델들에 사용되며 얕은 신경망 이나 부스팅된 결정 트리 등 다양한 모델에 적용되어 왔음 이 알고리즘은 보통 양성 예제 데이터셋과 무작위 음성 예제 집합으로 시작함(비율 맞추어서) 어느정도 학습된 모델을 전체 데이터셋을 돌려서 어려운 오답샘플을 찾고 이를 다시 학습하는 방법으로 수행
-> 보통 한번만 반복함
CNN기반 object detection 모델에 대한 설명 ....
Hard sample selection in deep learning
딥러닝에서 어떻게 hard sample selection을 하고있는지
보통 각 데이터 포인트의 현재 loss값을 기반으로 hard sample을 선택한다는 점에서 유사
Fracking deep convolutional image descriptors(ICLR. 2015)에서는 손실값을 기준으로 더 큰 무작위 예제 집합에서 어려운 양성 및 음성 예제를 각각 선택해서 이미지 descriptor학습에 사용
Unsupervised learning of visual representations using videos(ICCV. 2015)에서는 양성 패치 쌍이 주어졌을 때 triplet loss를 사용하여 대규모 예제 집합에서 hard negative patch를 찾음
Online Batch Selection for Faster Training of Neural Networks(ICLR. 2016)에서는 우리 방법과 유사하게 loss 기반 미니배치 SGD학습을 위한 online hard sample selection을 연구하였지만 이미지 classification에 초점을 맞추고있음 여기에 보완하여 Region based 객체 탐지기용 전략에 초점을 맞춘다.
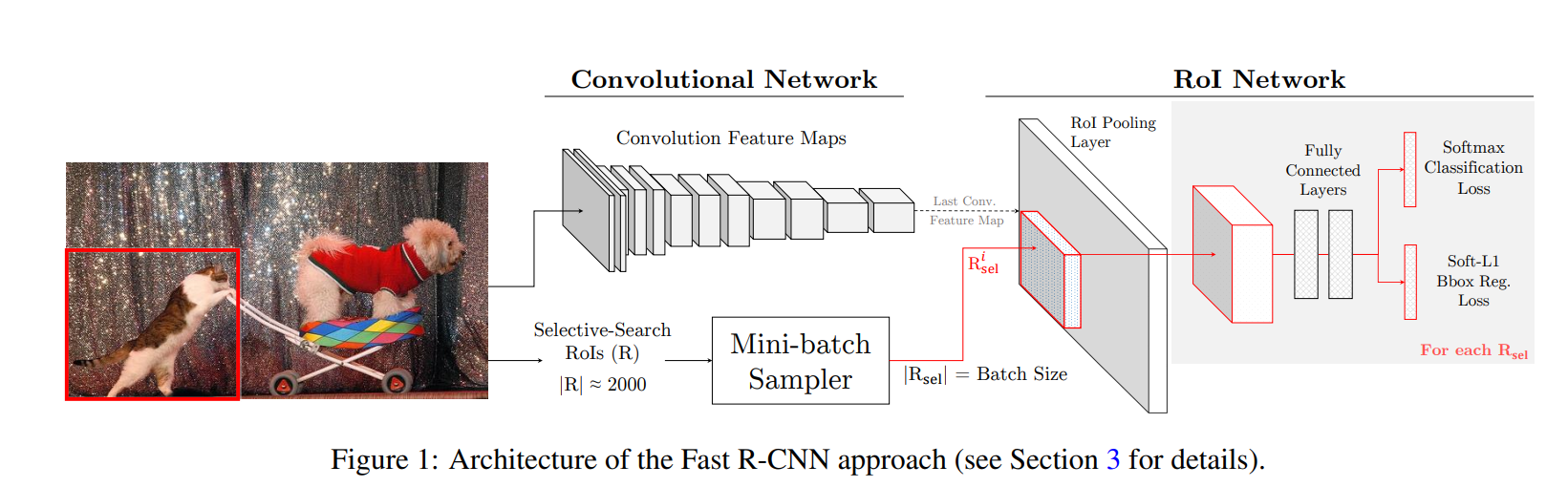
3. Overview of Fast R-CNN
Fast R-CNN에 대한 개괄적인 설명
왜 Fast R-CNN을 타겟 프레임워크로 선정하였는가?
1. end to end 시스템이다
2. conv과 rol로 구성된 이중 네트워크 구조는 다른 최신 detector도 사용하므로 폭넓게 우리 알고리즘을 적용할 수 있다.
3. 기본 구조는 비슷하지만 FRCN은 전체 conv 네트워크 학습을 허용하며 SPPnet과 MR-CNN은 conv 네트워크를 고정시킨다는 점에서 차이가 있다.
4. 마지막으로, SPPnet과 MR-CNN은 SVM 분류기를 따로 학습하기 위해 RoI 네트워크의 feature들을 캐시해두어야 하며 이 과정에서 하드 네거티브 마이닝을 사용하는 반면 FRCN은 RoI 네트워크 자체를 통해 원하는 분류기를 직접 학습시킨다.
FRCN은 학습시 Rol샘플링 절차에서 여러 휴리스틱을 사용하는데 이 방법을 도입하면 이 휴리스틱과 관련된 하이퍼 파라미터를 제거 할 수 있다.
데이터 불균형 문제를 해결하기 위해 FRCN은 각 미니배치에서 정답:배경 비율을 1:3으로 설정하였는데 즉 배경 배치를 무작위로 언더샘플링하여 전체 Rol중 약 25퍼만 정답으로 유지하였음 이 비율을 깨면 정확도가 mAP기준 3%정도 감소하게 됨(중요한 하이퍼 파라미터)
그러나 우리의 방법을 사용하면 이 비율 하이퍼 파라미터를 제거해도 됨
4. Our approach
우리는 Fast R-CNN을 학습하기 위한 간단하면서도 효과적인 온라인 하드 예제 채굴 알고리즘을 제안함
Online hard example mining: 하드 예제 채굴 알고리즘을 정의하는 반복적 절차는 일정 시간 동안 고정된 모델을 사용해 새로운 예제를 찾아 활성 학습 집합에 추가하고 그 후 일정 시간 동안, 해당 활성 학습 집합으로 모델을 학습한다.
R-CNN이나 SPPnet에서처럼 SVM 기반 객체 탐지기에서는 수십 또는 수백 장의 이미지를 검사하여 활성 학습 집합이 임계 크기에 도달하도록 하고 SVM을 활성 학습 집합에서 수렴할 때까지 학습한다. 이 과정은 모든 서포트 벡터가 포함될 때까지 반복한다.
이러한 전략을 FRCN의 ConvNet 학습에 적용하면 예제를 선택하는 동안 모델이 업데이트되지 않아 학습이 느려진다.
우리의 주요 통찰은 이 반복적 절차를 온라인 SGD 기반의 FRCN 학습 방식과 결합할 수 있다는 것인데 핵심은 각 SGD 반복이 적은 수의 이미지만 샘플링하더라도 각 이미지에는 수천 개의 RoI가 존재하므로 휴리스틱이 아닌 loss 기반으로 hard example을 선택할 수 있다는 것
좀 더 구체적으로, 온라인 하드 예제 채굴 알고리즘(OHEM)은 다음과 같은 절차로 진행됨
1. SGD 반복 t에서 주어진 입력 이미지에 대해 먼저 ConvNet으로 feature map을 계산한다.
2. 그런 다음 RoI 네트워크는 샘플링된 미니배치 대신 이 feature map과 모든 입력 RoI(R)을 사용해 forward pass를 수행한다.(이 단계는 RoI pooling, 몇 개의 fc layer, 그리고 각 RoI에 대한 손실 계산만 포함되며 손실 값은 현재 네트워크가 해당 RoI에 대해 얼마나 잘 수행했는지를 나타냄)
3. hard sample은 손실 값 기준으로 RoI들을 정렬한 후 성능이 가장 나쁜 B/N개를 선택하여 구성된다.(대부분의 forward 계산은 conv feature map을 통해 RoI 간 공유되므로 모든 RoI에 대해 forward하는 데 필요한 추가 연산은 비교적 적음 또한, 모델 업데이트에 사용되는 RoI 수가 적기 때문에 역전파(backward pass) 비용은 기존과 동일)
- 여기서 한 가지 주의할 점은 위치가 겹치는 RoI들은 손실이 서로 연관될 가능성이 높다는 것 그리고 해상도 차이로 인해 이러한 겹치는 RoI들이 conv feature map의 동일한 위치에 매핑될 수 있고 이는 손실이 중복 계산되는 문제를 야기할 수 있음
-
이러한 중복되고 상관된 RoI들을 제거하기 위해, 우리는 기존에서 제안된 표준 비최대 억제(NMS)를 사용해 중복 제거를 수행 -> IoU 임계값 0.7을 사용하여 강하게 겹치는 RoI들만 억제
-
이 과정에서 데이터 균형을 위해 정답 오답의 선택 비율은 필요하지 않음 어떤 클래스가 무시되었다면 그 클래스의 loss가 커지고 결국 선택될 확률도 높아지게 됨
-
일부 이미지에서는 정답 RoI가 쉬운 경우(예: 정면 자동차 이미지) 미니배치에 오직 배경만 사용될 수도 있으며 반대로 배경이 단순한 경우(예: 하늘, 풀밭 등)에는 미니배치가 전부 정답으로 채워질 수도 있음
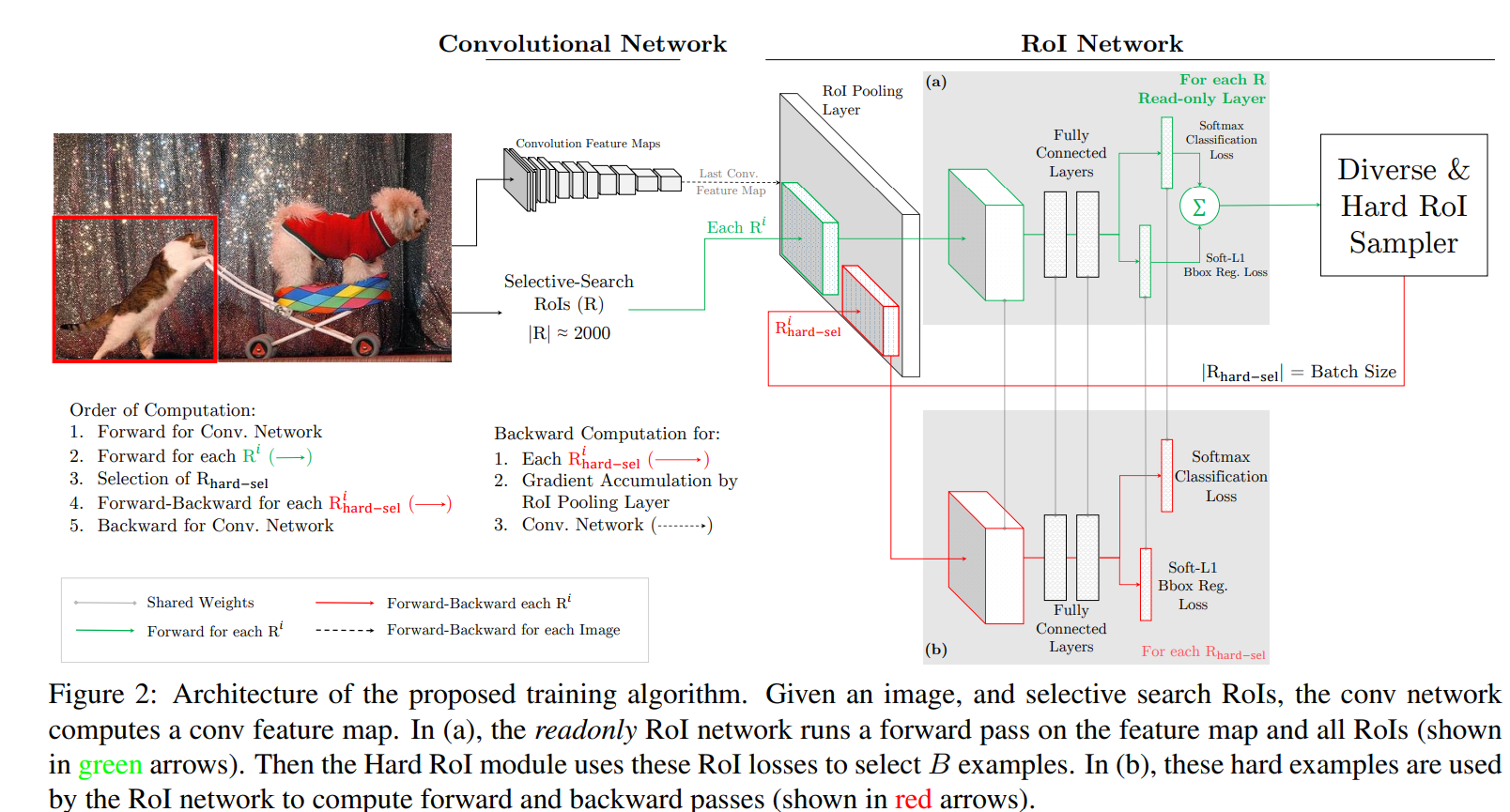
Implementation details: FRCN 탐지기에서 OHEM을 구현하는 방법은 여러 가지가 있으며 각 방법 서로 다른 trade off를 가짐
가장 직관적인 방법은 loss layer를 수정하여 hard example 선택을 직접 수행하도록 하는 것 loss layer는 모든 RoI의 loss를 계산하고 이 값을 기준으로 hard sample를 정렬 및 선택한 다음 선택되지 않은 RoI들의 손실을 0으로 설정함 이 방식은 구현은 간단하지만 비효율적인데 대부분의 RoI가 손실 0으로 인해 gradient가 없음에도 불구하고 RoI 네트워크는 모든 RoI에 대해 메모리를 할당하고 backward pass까지 수행함
이 문제를 해결하기 위해 우리는 Figure 2에서 제시한 구조를 제안하는데 RoI 네트워크를 두 개로 복제하여 이 중 하나는 read-only로 두어 모든 RoI에 대해 forward pass만 수행하고 다른 표준 RoI 네트워크는 forward와 backward 모두에 메모리를 할당함 하나의 SGD 반복에서 주어진 conv feature map을 기준으로 읽기 전용 RoI 네트워크가 forward pass를 수행하고 모든 입력 RoI(R)에 대한 loss를 계산함
이 네트워크는 backpropagation을 수행하지 않으므로 중간값들을 저장할 메모리를 할당하지 않음
일단 모든 후보 Rol에 대해 읽기 전용 네트워크를 통해 loss를 계산하고 손실이 높은 Rol를 골라냄 선택된 hard sample들은 표준 Rol네트워크로 전달되고 이 샘플에 대해서만 CNN의 가중치 업데이트가 진행 됨
이 논문에서는 단일 이미지로 구성된 미니배치를 N번 수행하고 이를 누적하여 가중치를 조정함 여기서는 N=2 B=128을 사용했는데 이는 즉 2장의 이미지에 대해 Rol 4000개를 뽑아서 여기서 hard sample 128을 뽑아 표준 Rol 네트워크에서 학습을 진행함
5. Analyzing online hard example mining
기존 방식과 OHEM을 실험을 통해 비교 또한 모든 rol을 사용하는 방법과도 비교
결과로 OHEM이 기존보다 2.4% 모든 Rol을 사용하는 것보다 4.8퍼 높았음
Robust gradient estimates: 이미지 수를 N = 2로 제한하면,
같은 이미지에서 나온 RoI들 간 상관성이 높아 gradient가 불안정해지고 수렴이 느려질 수 있다는 우려가 있음 FRCN는 이러한 문제가 실제 학습에서는 큰 문제가 되지 않았다고 보고했는데 우리는 동일한 이미지에서 손실 값이 큰 예제들을 선택하므로 이들이 더 높은 상관성을 가질 수 있다는 점에서 우려를 불러일으킬 수 있음 이 우려를 해결하기 위해 N = 1로 설정하여 RoI 간 상관성을 더 높이고 우리 방법이 얼마나 견고한지 확인하는 실험을 진행함. 기존 FRCN은 N = 1에서 mAP가 약 1포인트 하락한 반면 우리 방법은 성능이 거의 유지됨 이 결과는 OHEM이 GPU 메모리 절약을 위해 적은 수의 이미지를 사용하는 경우에도 견고하게 동작함을 보여줌
Why just hard examples, when you can use all:
OHEM은 하나의 이미지 내 모든 RoI를 고려한 뒤 하드 예제를 선택하는 것이 중요하다는 가설에 기반함
하지만 하드 예제만이 아니라 모든 RoI를 학습에 사용하면 어떻게 될까?
쉬운 예제들은 손실이 작기 때문에 gradient에 거의 영향을 주지 않고, 결국 학습은 자동적으로 하드 예제에 집중되지 않을까?
이를 실험적으로 검증해 보았음 큰 미니배치를 사용할 경우 이에 맞춰 학습률을 조정하는 것이 중요하여 VGG16에는 학습률 0.003, VGGM에는 0.004로 설정했을 때 최적 성능을 얻은것을 이용하여 실험
이 설정을 통해 B = 128일 때보다 VGG16과 VGGM 모두에서 mAP가 약 1포인트 상승하였지만 OHEM은 모든 RoI를 사용하는 경우보다 여전히 1포인트 이상 성능이 우수함 심지어 더 작은 mini-batch 크기로 gradient를 계산하기 때문에 학습 속도도 더 빠름
7. Adding bells and whistles
성능 개선을 위한 추가적인 방법들
- Multi-scale
이미지 크기를 다양하게 변경하여 학습 밎 테스트 수행
이미지의 짧은 변(shortest side)의 길이를 스케일(s)로 정의하여 학습 과정에서는 미리 정의된 스케일 집합 중에서 하나의 스케일을 무작위로 선택하여 이미지를 리사이즈한 후 모델에 입력 VGG16 네트워크를 사용할 때 학습 스케일은 s ∈ {480, 576, 688, 864, 900} 픽셀을 사용했으며 이미지의 최대 크기는 1000 픽셀로 제한.
테스트 시에는 이미지에 대해 미리 정의된 모든 스케일로 리사이즈한 후 각각 모델에 입력하여 결과를 얻음 VGG16 네트워크를 사용할 때 테스트 스케일은 s ∈ {480, 576, 688, 864, 1000} 픽셀을 사용했으며 최대 크기는 1000 픽셀로 동일하게 제한
이렇게 다양한 스케일에서의 결과를 종합하여 최종 탐지 결과를 얻음
- Iterative bounding-box regression 반복적 바운딩 박스 회귀
객체의 위치를 나타내는 바운딩 박스의 정확도를 높이기 위해 여러 번 반복적으로 조정하는 방법 (Mask R-CNN 논문에서 제안)
과정:
(1) 네트워크는 각 제안된 RoI에 대해 confidence score와 함께 첫 번째로 조정된 바운딩 박스 (R1)를 예측
(2) 점수가 높은 R1 박스들을 다시 한번 평가하여 점수를 재조정하고 위치를 더욱 정밀하게 조정하여 두 번째로 조정된 바운딩 박스 (R2)를 얻음
(3) 최종적인 후보 박스 집합 (RF)으로 R1과 R2의 합집합을 사용
(4) 후처리 과정으로, RF에 대해 NMS를 적용하여 겹치는 박스들을 제거 이때 IoU임계값은 0.3으로 비교적 낮게 설정
(5) 마지막으로, RNMS의 각 박스 r(i)에 대해 박스들 중 r(i) IoU가 0.5 이상으로 겹치는 박스들을 사용하여 가중 투표를 수행 이는 겹치는 박스들의 정보를 종합하여 최종 바운딩 박스의 위치를 더욱 정확하게 결정
