[논문리뷰] Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
Abstract
자연어로 명령하여 unseen 환경에 대해 자율적으로 안내하는 agent를 구현하는 것은 어려운 문제. agent는 단지 언어를 시각 장면에 정렬하는 것 뿐만 아니라 target으로 도달하기 위한 환경을 탐색하는 것도 필요함. 저자는 dual-scale graph 트랜스포머를 제안하며 이를 이용해서 long-term action을 계획하는 것과 정밀한 크로스 모달 이해를 결합. 저자는 위에서 본 topological map을 만들어 글로벌 액션 공간을 효율적으로 탐색할 수 있게 함. 복잡한 action 공간 추론과 세밀한 언어 정렬 간 균형을 위해 우리는 local 관찰에 대한 미시 스케일의 인코딩과 글로벌 맵상의 거시 스케일 인코딩을 그래프 트랜스포머를 통해 동적으로 결합. VLN 벤치마크 REVERIE와 SOON에서 SoTA달성한 DUET 제안하였고 R2R에서도 성공적
1. Introduction
지능이 내재된 agent에게 자동 네비게이션(Autonomous navigation)은 필수불가결한 능력
인간-기계의 상호작용을 위해 편리한 자연어가 주어졌을 떄 자율적인 agent는 이를 이해하고 사람 명령에 따를 수 있어야함. 이 목표를 달성하기 위해 어려운 task인 VLN은 최근 연구에서 많은 관심을 받음. VLN은 agent에게 언어 명령을 따를 것을 요청하고 unseen 환경에서 target 장소에 도착하도록 안내함
VLN의 초기 접근은 잘 정렬된 명령을 제공하여 한단계 한단계 안내함 예) 침실 나가서 오른쪽 돌고 복도 걸어가 끝에서 왼쪽에서 돌아 쇼파앞에서 멈춰-> instructions_l
이렇게 정밀한 VLN task는 디테일한 명령을 agent가 정렬할 수 있도록 하지만 매 단계마다 안내문이 필요하다는 점에서 실용성이 떨어짐
더 편리한 agent와의 상호작용을 위해서는 목표지향적인 명령으로 달성된다 -> 거실로 들어가서 테이블 위 화분에 물 줘, 거실에 가서 하얀 꽃병에 있는 식물에 물을 줘
그러나 이러한 task는 방과 오브젝트에서 정렬 뿐만 아니라 target에 도달하기까지 효율적인 탐색을 둘 다 수행해야 하므로 더 어렵다.
효율적인 새로운 공간을 탐색과 이전 결정들을 바로잡기 위해 에이전트는 이미 실행한 명령문을 따르고 방문한 지점을 기억해야 함
현재 많은 VLN 접근법은 LSTM같은 RNN으로 기억하고 고정된 크기의 벡터로 네비게이션 히스토리를 압축
단언컨데 그러한 암시적 메모리 메커니즘은 저장하거나 이전의 경험을 복잡한 시공간 구조에서 용하는 것은 비효율적일 수 있다.
최근 몇몇 접근법에서는 명확하게 이전의 관찰과 action을 저장하는 것과 긴 범위의 의존성을 action 예측에 활용하기 위해 트랜스 포머를 사용하는 것을 제안함(PREVALENT)
그러나 이러한 모델은 local action만 따름(즉 이웃한 장소로만 이동)->각 액션이 각 시점(상태)에 대해서 독립이며 동일한 분포를 따른다고 가정.
따라서 agent는 N step되돌아가려면 네비게이션 모델이 N번 동작해야 하므로 불안정하고 자원이 많이 듦
잠재적인 해결책은 지금까지 관찰된 모든 방문했던 장소와 안내 가능한 장소를 명시적으로 추적/기록한 맵을 구축하는 것-> node 와 graph기반
맵은 agent가 효율적인 long-term navigation plans를 만들 수 있게 함
그 예시로 agent는 맵에 있는 모든 이동가능한 장소로부터 장기적인 목표를 고를 수 있고 맵을 이용해서 목표까지 최단거리를 계산할 수 있음
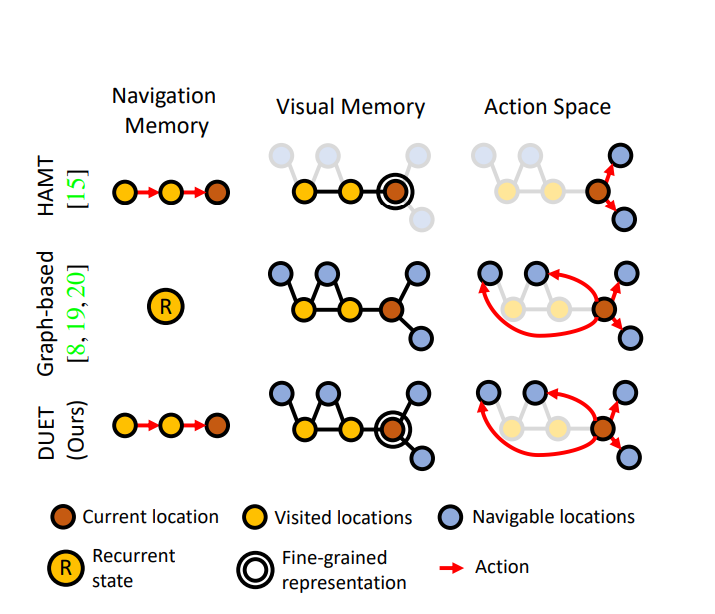
토폴로지 맵은 이전에 VLN 작업들에서 이미 연구됐는데 이러한 방법들은 여전히 2가지 문제점을 가지고 있음
- Figure 2 가운데처럼 네이게이션 상태를 추적하기 위해 순환 구조에 의존함-> 탐색을 위한 장기적인 추론 능력을 크게 떨어뜨림
- 토폴로지 맵의 각각의 노드들은 시각 특징을 압축한 형태-> 이러한 거시적인 표현은 complexity를 감소시키지만 지시문 안에서 세밀한 오브젝트와 장면묘사를 정확히 정렬하는데 필요한 디테일이 부족할 수 있음
따라서 저자들은 이 두 단점을 첫 번째는 하나의 트랜스포머 아키텍처로 두 번째는 dual-scale action planning(이중 스케일 액션 플래닝) 방식으로 해결하고자 함->토폴로지 맵과 Dual-scale graph Transformer(DUET)을 제안함
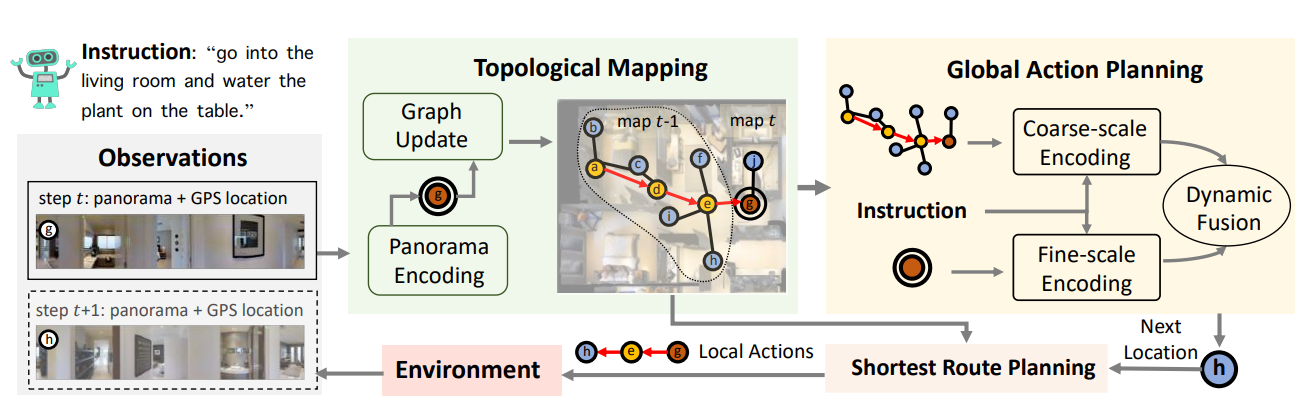
그림 1에서(맨위) 모델은 토폴로지 매핑과 global action planning 2개의 모듈로 구성
토폴로지 매핑에서는 새롭게 관찰된 장소를 추가하고 노드의 시각표현을 업데이트하는 방식으로 맵을 구성하고 각 step마다 global action planning 모듈이 맵에서의 다음 이동할 장소를 고르거나 멈추는 것을 선택함
언어를 세밀하게 정렬(fine-grained language grounding)하는 것과 큰 그래프에 대한 추론(reasoning)의 균형을 위해 저자들은 dual-scale:현재 위치의 미시적(fine-scale)표현과 맵의 거시적(coarse-scale)표현으로부터 action 예측을 동적으로 결합하는 것을 제안
특히 트랜스포머를 통해 vision-language간 크로스 모달의 관계를 잘 포착하고 그래프 토폴로지 정보를 트랜스포머에 추가하여 맵 인코딩을 향상함
행동모방과 보조task 수행을 통한 사전학습 모델은 가상의 상호작용 데모 생성자를 통해 정책학습을 추가로 향상시킴
결과적으로 DEUT은 벤치마크 REVERIE나 SOON에서 SoTA이고 R2R에서도 상당한 향상이 있었음
3개의 contribution
1. VLN을 위한 토폴로지 맵과 DUET을 제안하고 이것은 global action을 효율적으로 계획하기 위해 거시적 맵 인코딩과 미시적 현재위치 인코딩을 결합함
2. 그래프 트랜스포머를 사용하여 토폴로지 맵을 인코딩하고 instruction과의 cross-modal 관계를 학습 -> 이를 통해 action 예측이 장기적 네비게이션 메모리에 기반을 두게 함(instruction이 가지는 전역적인 특징을 토폴로지 맵과의 학습을 통해 전역적으로 action을 수행하도록)
3. DUET는 목표 지향 시각-언어 내비게이션(VLN) 벤치마크에서 SoTA를 달성 특히 REVERIE와 SOON 데이터셋에서 SR을 20% 이상 향상, 또한 세밀한 수준의 VLN 작업에서도 일반화가 가능하여, R2R 데이터셋에서는 SR이 4% 증가
2. Related work
vision-and-language navigation(VLN)
instruction을 포함한 네이게이션 task는 많은 관심을 얻었고 초기 VLN 방법론은 RNN과 cross-modal attention이 채택됨
최근에는 특히 사전학습된 트랜스포머 아키텍처를 기반으로 좋은 성능을 보이고 있음
PRESS나 adopts BERT가 instruction 인코딩을 위해 사용되고 다양한 변형 형태의 ViLBERT가 insturction와 시각적 경로 간의 호환성은 측정하였으나 순차적인 행동은 예측하지 못함
Recurrent VLN-BERT는 트랜스포머 아키텍처에 순환 유닛(recurrent unit)을 삽입하여 이 한계를 극복하고 행동 예측을 함
다음으로 E.T.와 HAMT에서는 하나의 순환유닛에 의존하는 대신 모든 관찰과 행동사이의 장기 의존성을 포착하기 위해 트랜스포머를 사용
Maps for navigation
시각적 내비게이션(visual navigation) 분야에서는 오랫동안 SLAM을 사용해 환경의 거리 기반 지도(metric maps)를 구축하는 전통이 있음 이는 비모수적(non-parametric) 방법(모델이 데이터에 맞게 유연한 크기를 가짐), 신경망(neural networks), 또는 둘의 혼합 을 통해 해결하고 이를 VLN에 적용하였음
그러나 실시간 내비게이션 중에 거리 기반 지도의 구축은 어렵고 정확한 계산이 요구되어 환경을 사전에 탐색(pre-exploration)하거나 다른 위치로 되돌아가기(back-tracking) 위해 지도를 위상적(topological) 구조(그래프 형태)로 표현할 것을 제안
최근의 몇몇 VLN 연구들도 전역적 행동 계획(global action planning)을 지원하기 위해 위상적 지도(topological maps)를 사용하였으나 이들은 상태 추적(state tracking)에 순환 구조(recurrent architectures)를 사용하여 한계가 있었고, 언어 기반 정렬(language grounding)을 위한 미세 수준(fine-scale) 표현이 부족했음
우리는 이러한 한계들을 위상적 지도와 함께 사용하는 이중 스케일 그래프 트랜스포머(dual-scale graph transformer)를 통해 해결하고자 함
Training algorithms for sequential perdiction
Behavior cloning(행동모방)은 순차적으로 예측하기 위해 가장 널리 사용되는 학습이나 알고리즘이나 훈련과 테스트 사이에서 발생하는 분포변화(distribution shift)문제를 겪을 수 있음
이 한계를 해결하기 위해 scheduled sampling, DAgger, 강화학습등 다양한 알고리즘이 제시됨
최근 대부분 VLN에서는 행동모방과 A3C기반 강화학습을 사용하는 편이며 일부 연구에서는 soft expert distillation을 통해 보상함수를 학습하는 방법을 제안
하지만 보상이 희소한 과제에서는 RL을 적용하기 어려우므로 대신 상호작용하는 전문가(interactive demonstrator)를 사용하여 전문가를 모방하고 순차학습과정의 supervision을 제공함
3. Method
문제 정의 : 일반적인 이산(discrete) 환경에서의 VLN은 무방향 그래프(노드간 양방향 이동이 가능한) 로 표현 됨
여기서 는 이동가능한 K개의 노드의 지점을 나타내고 는 노드간의 연결관계 즉 엣지를 나타냄(두 지점간 이동이 가능한지)
agent는 RGB카메라와 GPU센서를 가지고 있고 unseen환경에서 시작 노드에 초기화 됨
agent의 목표는 자연어 명령을 해석하고 그래프를 탐색하며 목표 지점과 명령 속 구체적인 오브젝트를 찾는 것.
는 L개의 단어로 이루어진 명령의 워드 임베딩.
각 time step 에서 agent에게 파노마라 뷰와 현재 위치노드 의 위치좌표가 주어짐 파노라마는 개의 이미지()로 쪼개지고 각 이미지는 feature vector 로 표현되며 각각 하나의 고유한 시점을 가짐.
또한, 정밀한 시각인식을 위해 파노라마에서 추출된 라벨링된 오브젝트 바운딩 박스 또는 오브젝트 detector로 감지된 m개의 obeject feature를 사용함.
게다가 agent는 자신의 좌표뿐만 아니라 둘러싸고 있는 몇개의 이동가능한 이웃한 노드 도 인식하고 있음.
는 의 subset임
-> 이동가능한 이웃의 경로는 현재시점의 파노라마 뷰이미지의 일부와 1대1 매핑이 됨
즉 전체 파노라마 뷰에서 이웃노드를 바라보는 그 방향을 바라보는 이미지가 1개이상 존재함
현재 시점 에서 가능한 action space 는 이동할와 현재에서 멈추는를 포함함
agent가 해당 위치에서 stop을 결정하면 파노라마에서 타겟 object를 예측하는 것이 필요함
탐험과 언어정렬은 VLN agent의 두가지 필수적인 능력임
그러나 이전까지 연구에서는 local action 만 따라 장기적인 action planning을 방해하거나 object 표현이 부족하여 정밀한 정렬을 하지 못함
우리의 연구는 이 두가지 문제를 dual-scale 표현과 global action planning으로 해결하고자 함
3.1. Topological Mapping
