import torch
import torch.nn as nn
from typing import Tuple
```python
class LSTMController(nn.Module):
def __init__(self, input_size: int, hidden_size: int) -> None:
super(LSTMController, self).__init__()
self.layer = nn.LSTM(input_size=input_size, hidden_size=hidden_size)
self.lstm_h_state = nn.Parameter(torch.randn(1, 1, hidden_size) * 0.05)
self.lstm_c_state = nn.Parameter(torch.randn(1, 1, hidden_size) * 0.05)
for p in self.layer.parameters():
if p.dim() == 1:
nn.init.constant_(p, 0)
else:
stdev = 5 / (np.sqrt(input_size + hidden_size))
nn.init.uniform_(p, -stdev, stdev)
def get_initial_state(self, batch_size: int):
lstm_h = self.lstm_h_state.clone().repeat(1, batch_size, 1)
lstm_c = self.lstm_c_state.clone().repeat(1, batch_size, 1)
return lstm_h, lstm_c
def forward(self, x, state):
output, state = self.layer(x.unsqueeze(0), state)
return output.squeeze(0), state # 입력된 x와 state에 대한 다음 state를 반환LSTM의 특징은 입력과 이전 state를 받아서 다음 state를 반환한다는 것입니다.
이를 이용하여 controller를 구현해주었습니다.
self.layer = nn.LSTM(input_size=input_size, hidden_size=hidden_size)이렇게 nn.LSTM에 input_size와 hidden_size를 넣어주면 알아서 LSTM을 만들어줍니다.
for p in self.layer.parameters(): # initialize parameters
if p.dim() == 1:
nn.init.constant_(p, 0)
else:
stdev = 5 / (np.sqrt(input_size + hidden_size))
nn.init.uniform_(p, -stdev, stdev)이부분은 적절히 initialize하는 부분이니 우리가 신경쓰진 않아도될 것 같네요
def get_initial_state는 lstm의 initial state를 반환해주는 함수입니다.
def forward(self, x, state):
output, state = self.layer(x.unsqueeze(0), state)
return output.squeeze(0), state # 입력된 x와 state에 대한 다음 state를 반환LSTM Controller는 쉽네요. 다만 한가지만 명심합시다. 입력된 x와 state에 대한 다음 state를 반환한다는 것입니다. 즉, x와 state를 받아서 다음 state를 반환하는 것이지, x와 state를 받아서 다음 x를 반환하는 것이 아닙니다.
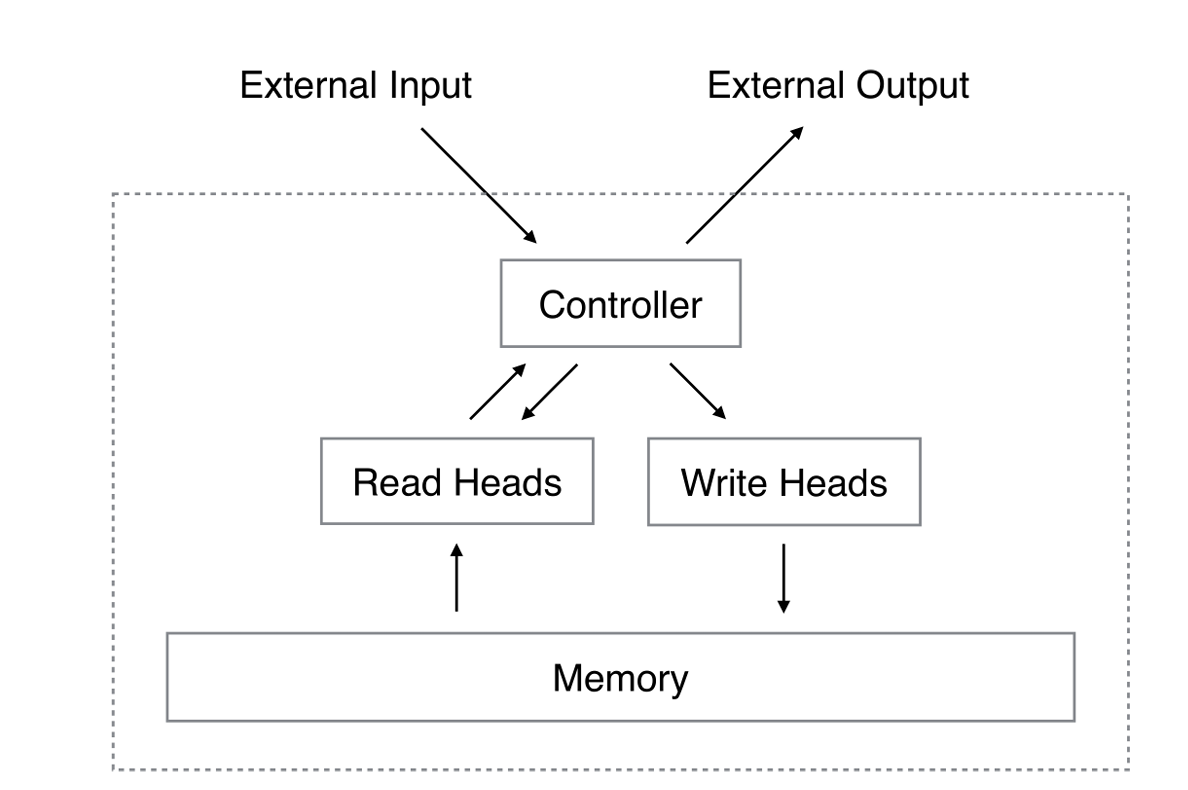
Head
head는 메모리에 대한 read, write를 담당하는 모듈입니다.
우리가 착각하지 말아야 할 것은 read와 write는 각각 하나의 head가 담당한다는 것입니다. 즉, head는 하나의 read와 하나의 write를 담당합니다.
ReadHead와 WriteHead는 Memory와 Controller의 hidden_size를 받아서 Memory에 정보를 쓰고 읽어오는 역할을 합니다.
Head를 먼저 구현하고 상속을 통해 ReadHead와 WriteHead를 구현해보겠습니다.
import torch.nn.functional as F
class Head(nn.Module):
def __init__(self, memory: Memory, hidden_size: int) -> None:
super(Head, self).__init__()
self.memory = memory
self.k_layer = nn.Linear(hidden_size, self.memory.size[1]) # (128,40)
self.beta_layer = nn.Linear(hidden_size, 1)
self.g_layer = nn.Linear(hidden_size, 1)
self.s_layer = nn.Linear(hidden_size, 3)
self.gamma_layer = nn.Linear(hidden_size, 1)
for layer in [
self.k_layer,
self.beta_layer,
self.g_layer,
self.s_layer,
self.gamma_layer,
]:
nn.init.xavier_uniform_(layer.weight, gain=1.4)
nn.init.normal_(layer.bias, std=0.01)
self._initial_state = nn.Parameter(
torch.randn(1, self.memory.size[0]) * 1e-5)
def get_initial_state(self, batch_size: int):
return F.softmax(self._initial_state, dim=1).repeat(batch_size, 1)
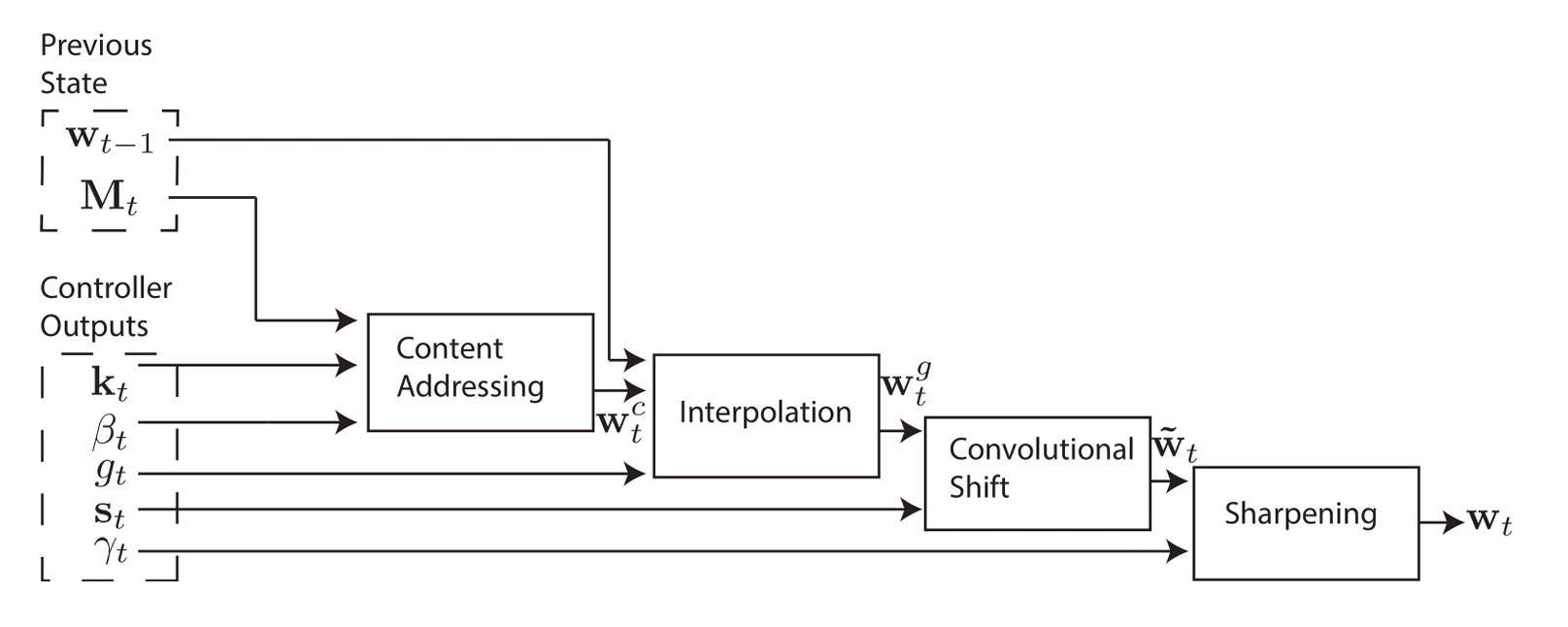
def get_head_weight(
self, x: torch.Tensor, previous_state: torch.Tensor, memory_matrix: torch.Tensor
) -> torch.Tensor:
k = self.k_layer(x)
beta = F.softplus(self.beta_layer(x)) # softplus는 log(1+e^x)를 의미
g = torch.sigmoid(self.g_layer(x))
s = F.softmax(self.s_layer(x), dim=1)
gamma = 1 + F.softplus(self.gamma_layer(x))
w_c = F.softmax(
beta
* F.cosine_similarity(
memory_matrix + 1e-16, k.unsqueeze(1) + 1e-16, dim=-1
),
dim=1,
)
w_g = g * w_c + (1 - g) * previous_state
w_t = self._shift(w_g, s)
w = w_t**gamma
w = torch.div(w, torch.sum(w, dim=1).unsqueeze(1) + 1e-16)
return w
def _convolve(self, w: torch.Tensor, s: torch.Tensor) -> torch.Tensor:
assert s.size(0) == 3
t = torch.cat([w[-1:], w, w[:1]], dim=0)
c = F.conv1d(t.view(1, 1, -1), s.view(1, 1, -1)).view(-1)
return c
def _shift(self, w_g: torch.Tensor, s: torch.Tensor) -> torch.Tensor:
result = w_g.clone()
for b in range(len(w_g)):
result[b] = self._convolve(w_g[b], s[b])
return result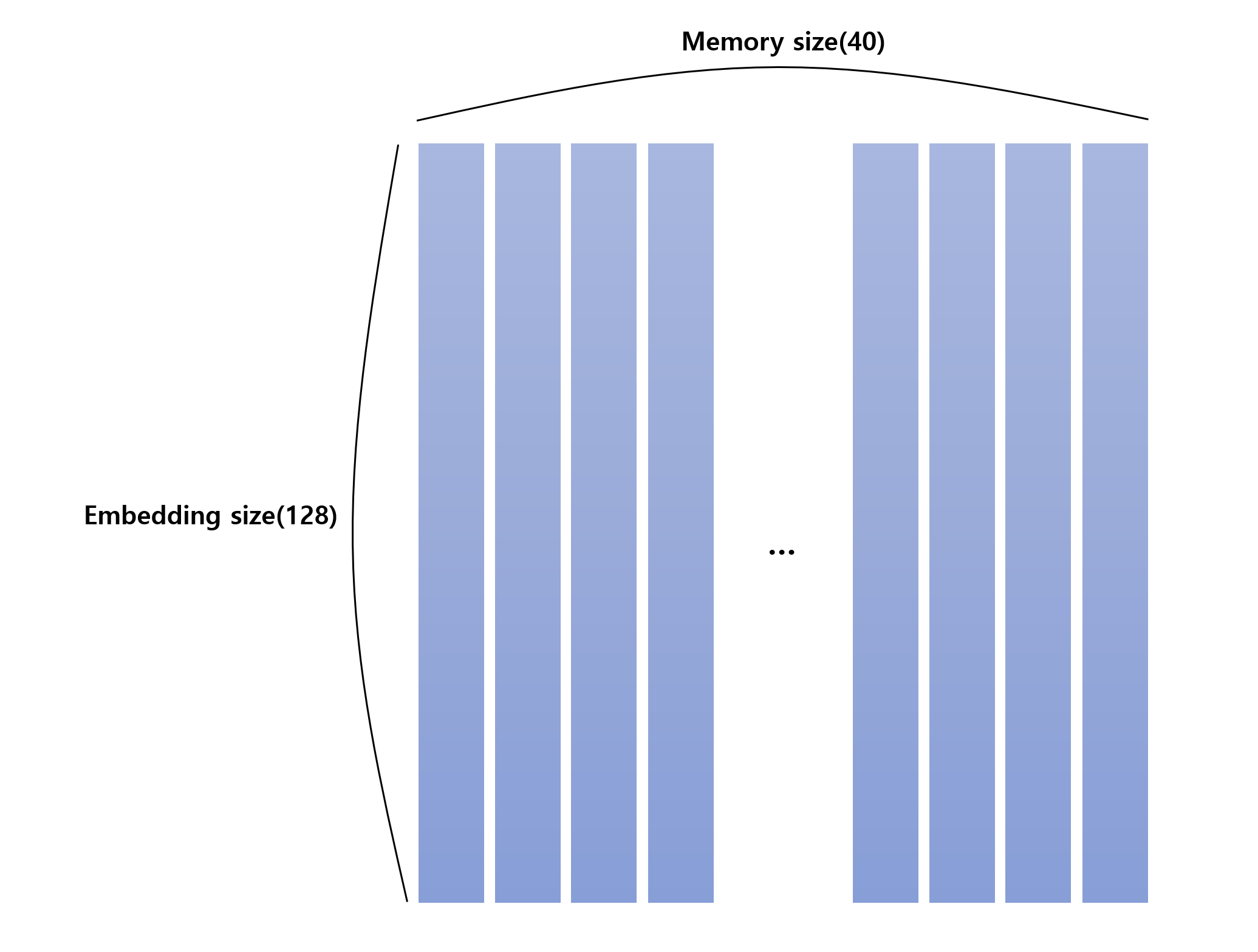
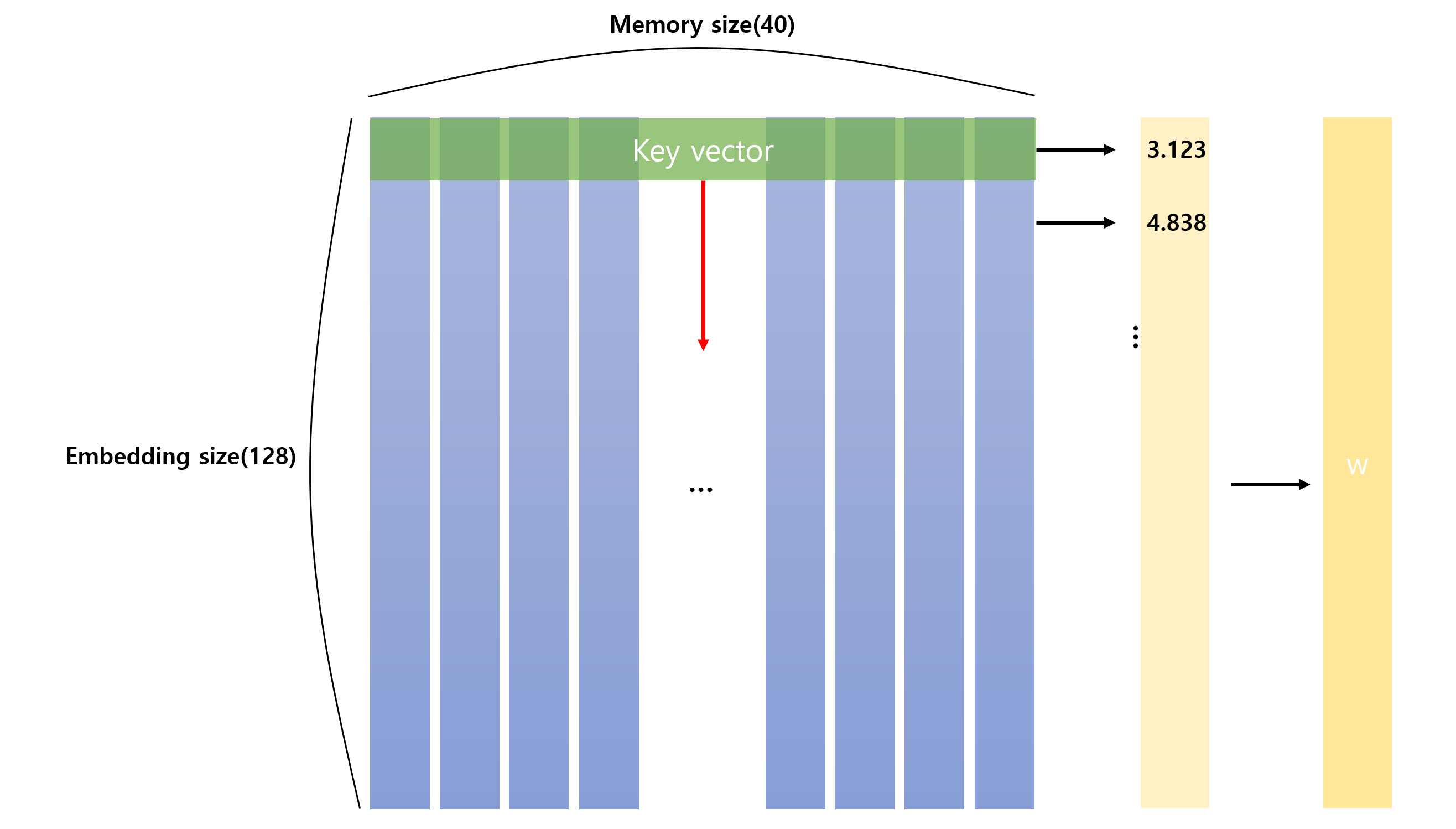
일단 현재 memory는 위 사진과 같이 구성되어 있습니다.
Controller의 input을 받아 k_layer를 통해 k를 얻습니다. k는 memory의 각 row와의 cosine similarity를 구하기 위한 key입니다.
그림으로 봅시다.
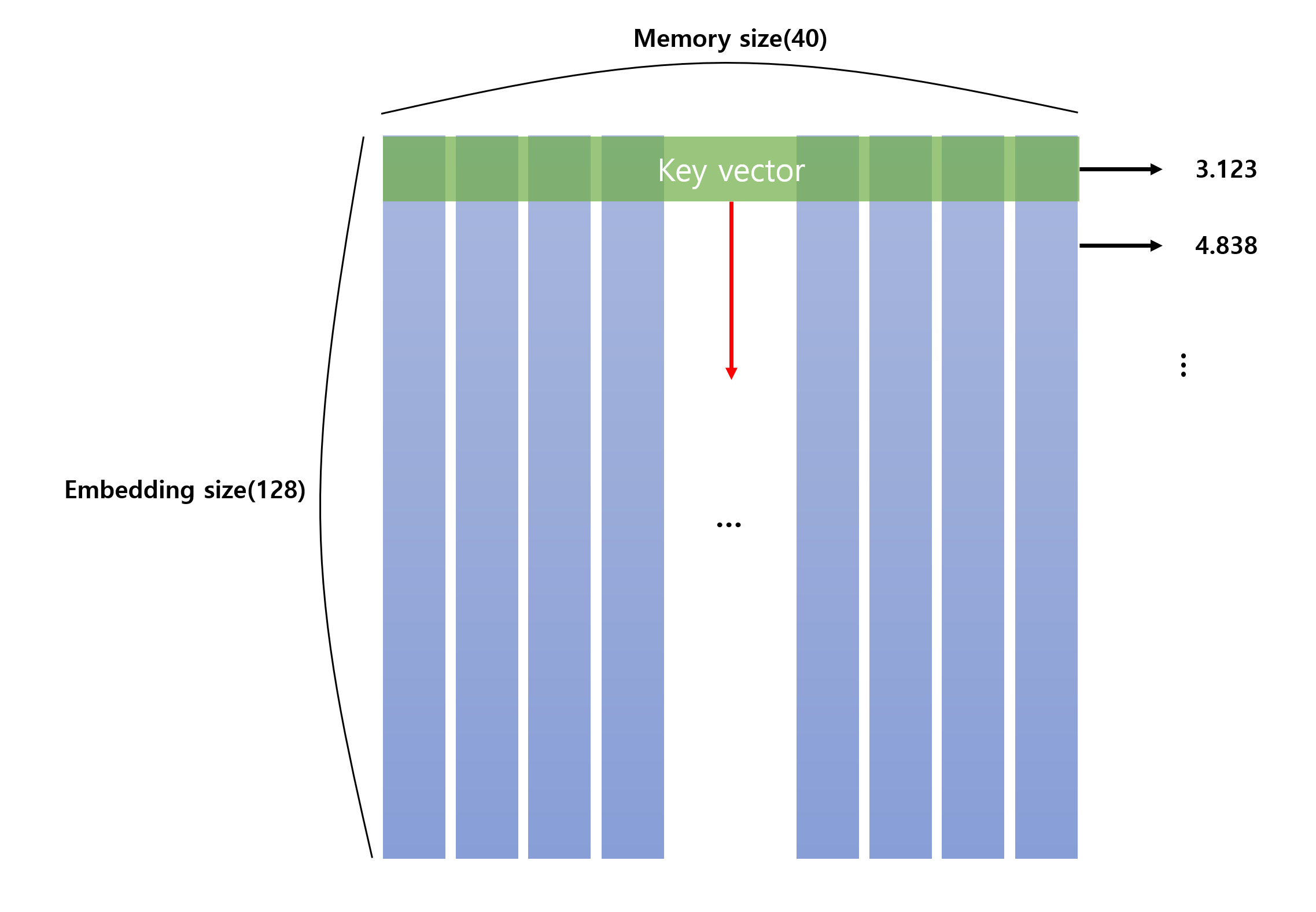
key vector가 각 행을 지나며 cosine similarity를 구하게 되면 위와 같이 각 행과의 유사도를 구할 수 있습니다.
이제 softmax를 통해 각 행의 weight를 구합니다.
이때 키 강도인 beta라는 변수를 추가해 집중의 정도를 조절할 수 있습니다.
논문에서는 이렇게

코드에서는 이렇게
w_c = F.softmax(
beta
* F.cosine_similarity(
memory_matrix + 1e-16, k.unsqueeze(1) + 1e-16, dim=-1
),
dim=1,
)구현을 했습니다.
그다음 단계는 보간(Focusing by Location)을 통해 weight를 구하는 것입니다.
논문에서는 이렇게
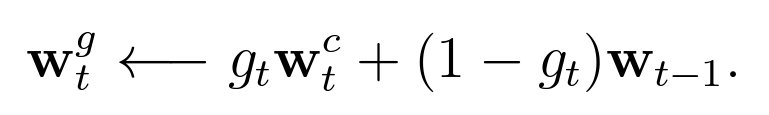
표현되어 있습니다.
딱봐도 수식이 굉장히 쉽죠?
과거의 과중치와 현재의 과중치를 조합하여 새로운 과중치를 구하는 것입니다.
근데 사실 왜 이렇게 하는지 모르겠어요. 논문에서 되어 있으니까...
LSTM이 이전 단계를 기억해서 하니까 그래서 하는건가? 라는 생각이 들긴 하지만...
어쨌든
w_g = g * w_c + (1 - g) * previous_state이렇게 코드로는 구현합니다.
이후 순환 이동(rotational shift)단계를 시행합니다.
이동가중치 s를 사용해 다른 메모리에 집중할 수 있도록 해줍니다.
s는 softmax를 통과했으므로, 총 합은 1입니다.
논문에서는 이렇게(코드는 따로 안보겠습니다. 어려워용)
이후 선명화(sharpening)을 통해 weight를 구합니다.
논문에서는 이렇게
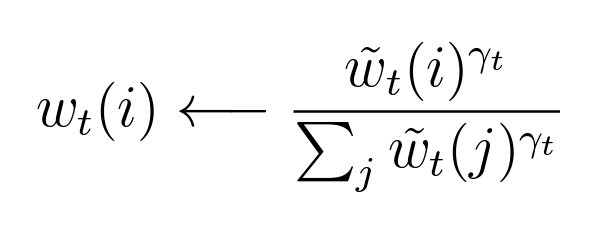
표현했습니다.
이렇게 Head의 구현이 끝났습니다.
Read Head
ReadHead는 Head를 상속받아 구현합니다.
class ReadHead(Head):
def forward(
self, x: torch.Tensor, previous_state: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
w = self.get_head_weight(x, previous_state, self.memory.matrix)
return torch.matmul(w.unsqueeze(1), self.memory.matrix).squeeze(1), w입력으로 x와 이전 단계의 state를 받습니다.
w = self.get_head_weight(x, previous_state, self.memory.matrix)전에 구현했던 함수를 그대로 사용합니다.
matrix와 입력을 같이 넘겨주면 가중치 벡터를 구할 수 있습니다.
이후 matrix와 가중치 벡터를 곱해주면 그것이 read vector가 됩니다.
이때, 가중치 벡터는 이후에 다시 사용됩니다.
return torch.matmul(w.unsqueeze(1), self.memory.matrix).squeeze(1), w그래서 가중치 벡터도 함께 반환합니다.
왜냐면 다음에 다시 보간을 할 때, 이전 단계의 가중치 벡터를 사용해야 하기 때문입니다.
굳! 잘구현했습니다.
Write Head
여기서는 WriteHead를 구현해보겠습니다.
ReadHead와 다른 점은, WriteHead는 가중치 벡터를 이용해 메모리를 수정해야 한다는 점입니다.
두 개의 가중치 벡터를 추가로 수정합니다.
e는 erase vector, a는 add vector입니다.
class WriteHead(Head):
def __init__(self, memory: Memory, hidden_size: int) -> None:
super(WriteHead, self).__init__(memory=memory, hidden_size=hidden_size)
self.e_layer = nn.Linear(hidden_size, memory.size[1])
self.a_layer = nn.Linear(hidden_size, memory.size[1])
for layer in [self.e_layer, self.a_layer]:
nn.init.xavier_uniform_(layer.weight, gain=1.4)
nn.init.normal_(layer.bias, std=0.01)
def forward(self, x: torch.Tensor, previous_state: torch.Tensor) -> torch.Tensor:
w = self.get_head_weight(x, previous_state, self.memory.matrix)
e = torch.sigmoid(self.e_layer(x))
a = self.a_layer(x)
self.memory.write(w, e, a)
return we와 a를 구하기 위해 각각의 layer를 추가로 만들어줍니다.
self.e_layer = nn.Linear(hidden_size, memory.size[1])
self.a_layer = nn.Linear(hidden_size, memory.size[1])Controller로부터 입력을 받아 memory size(=40)크기의 vector를 만들어 줍니다.
수정하는 부분을 살펴봅시다.
논문에서는 erase는 이렇게
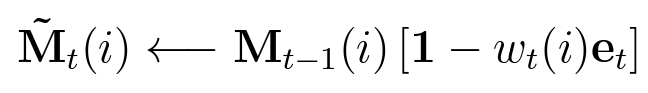
add는 이렇게
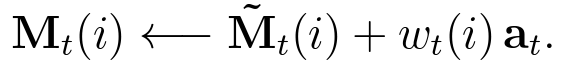
구현이 되어있습니다.
memory의 write부분을 보면, 이렇게 구현되어 있습니다.
def write(self, w, e, a):
self.matrix = self.matrix * (1 - torch.matmul(w.unsqueeze(-1), e.unsqueeze(1))) + torch.matmul(w.unsqueeze(-1), a.unsqueeze(1))Neural Turing Machine(NTM)
파츠들을 다 잘 만들어줬으니, 조립해보겠습니다.
class NTM(nn.Module):
def __init__(
self,
num_ways,
img_size = 28,
memory_size = (128, 40), # [0]embedding_size = 128, [1]memory_size = 40
hidden_size = 200):
super(NTM, self).__init__()
input_size = img_size * img_size + num_ways
controller_input_size = input_size + memory_size[1]
self.memory = Memory(size=memory_size) # (128, 40)
self.read_head = ReadHead(memory=self.memory, hidden_size=hidden_size)
self.write_head = WriteHead(memory=self.memory, hidden_size=hidden_size)
self.controller = LSTMController(
input_size=controller_input_size, hidden_size=hidden_size
)
self.fc = nn.Linear(hidden_size + memory_size[1], 5)
nn.init.xavier_uniform_(self.fc.weight, gain=1)
nn.init.normal_(self.fc.bias, std=0.01)
def get_initial_state(self, batch_size: int):
self.memory.reset(batch_size)
read = self.memory.get_initial_read(batch_size)
read_head_state = self.read_head.get_initial_state(batch_size)
write_head_state = self.write_head.get_initial_state(batch_size)
controller_state = self.controller.get_initial_state(batch_size)
return (read, read_head_state, write_head_state, controller_state)
def forward(
self,
x: torch.Tensor,
previous_state: Tuple[
torch.Tensor, torch.Tensor, torch.Tensor, Tuple[torch.Tensor]
],
):
(
previous_read,
previous_read_head_state,
previous_write_head_state,
previous_controller_state,
) = previous_state
controller_input = torch.cat([x, previous_read], dim=1)
controller_output, controller_state = self.controller(
controller_input, previous_controller_state
)
read_head_output, read_head_state = self.read_head(
controller_output, previous_read_head_state
)
write_head_state = self.write_head(controller_output, previous_write_head_state)
fc_input = torch.cat((controller_output, read_head_output), dim=1)
state = (read_head_output, read_head_state, write_head_state, controller_state)
return F.softmax(self.fc(fc_input), dim=1), state특이한 점은
input_size = img_size * img_size + num_ways이 부분입니다.
LSTM이기 때문에 입력으로 이전의 state를 받아야 합니다.
그 부분만 이해하면 쉽게 이해할 수 있습니다.
