0. 개요
이 문서는 Yolo v1 모델에 대한 소개와 Personal Application, 총 2 파트를 다루고 있습니다.
Tensorflow로 진행했으며, Yolo v1 모델을 코드로 구현해보는 것에 집중하면서 Pascal Voc의 Cat class를 detect를 시도했습니다.
작년에 작성했던 글을 이 블로그에 통합시키기 위해 재구성했습니다.
1. Yolo v1 Model
1-1. 개요
Yolo v1은 논문에서 소개한 2-Stage Detector (DPM, R-CNN) 같이 특징 추출과 객체 분류, 두 가지 과정을 거쳐서 객체를 탐지하는 접근법이 아니라 특징 추출과 객체 분류를 한 번에 처리하는 1-stage Detector 접근법을 취합니다.
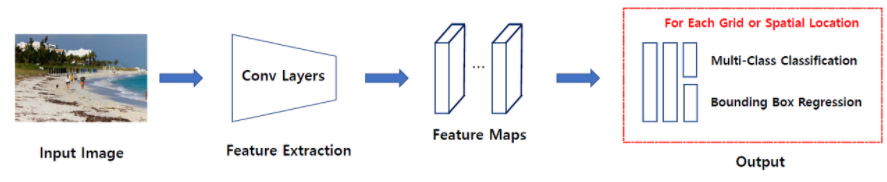
위 그림에서 보듯이 특징 추출, 객체 분류 두 문제를 단일 신경망으로 해결합니다.
논문에서는 YOLO가 object detection을 single regression problem으로 재구성했다고 합니다.
Yolo v1은 single convolutional network로 이미지를 입력받아, 각 박스의 class, 여러 개의 바운딩 박스와 박스의 위치 정보를 예측합니다. 그리고 non-max suppression을 통해 최종 바운딩박스를 선정합니다.

두 문제를 한꺼번에 처리를 하여 속도는 빠르지만 정확도는 떨어진다고 논문에서 말하고 있습니다. 이처럼 속도와 정확도의 상충 관계(trade off)가 발생합니다.
1-2. 장점
매우 빠릅니다.
- 초당 45프레임을 처리할 수 있고, fast version에서는 초당 150프레임을 처리할 수 있습니다.
- 복잡한 pipeline이 필요하지 않고 이미지에 neural netwrok를 실행하기만 하면 됩니다.
- 추가적으로 YOLO는 실시간 객체 탐지 방법보다 2배 이상의 mAP(mean average precision)을 얻었다고 논문에서 말하고 있습니다.
객체의 일반화된 representations를 학습하여 다른 도메인에서 좋은 성능을 보입니다.
- 새로운 이미지나 새로운 도메인에 적용할 때, DPM, R-CNN 같은 - detection 방법을 크게 능가합니다.
- 자연 이미지(natural image)로 학습한 후 그림(artwork)에서 test를 진행해도 다른 모델들보다 좋은 성능을 보인다고 논문에서는 말하고 있습니다.
Fast R-CNN 보다 background error가 두 배 이상 적습니다.
- YOLO는 예측할 때, 이미지 전체를 이용하기 때문에 class와 객체 출현에 대한 contextual information까지 이용할 수 있습니다.
- 반면에 Fast R-CNN은 selective search가 제안한 영역만을 이용하여 예측하기 때문에 larger context를 이용하지 못합니다. 따라서 R-CNN은 배경을 객체로 탐지하는 실수를 하게 됩니다.

1-3. Bounding Box 예측 방식
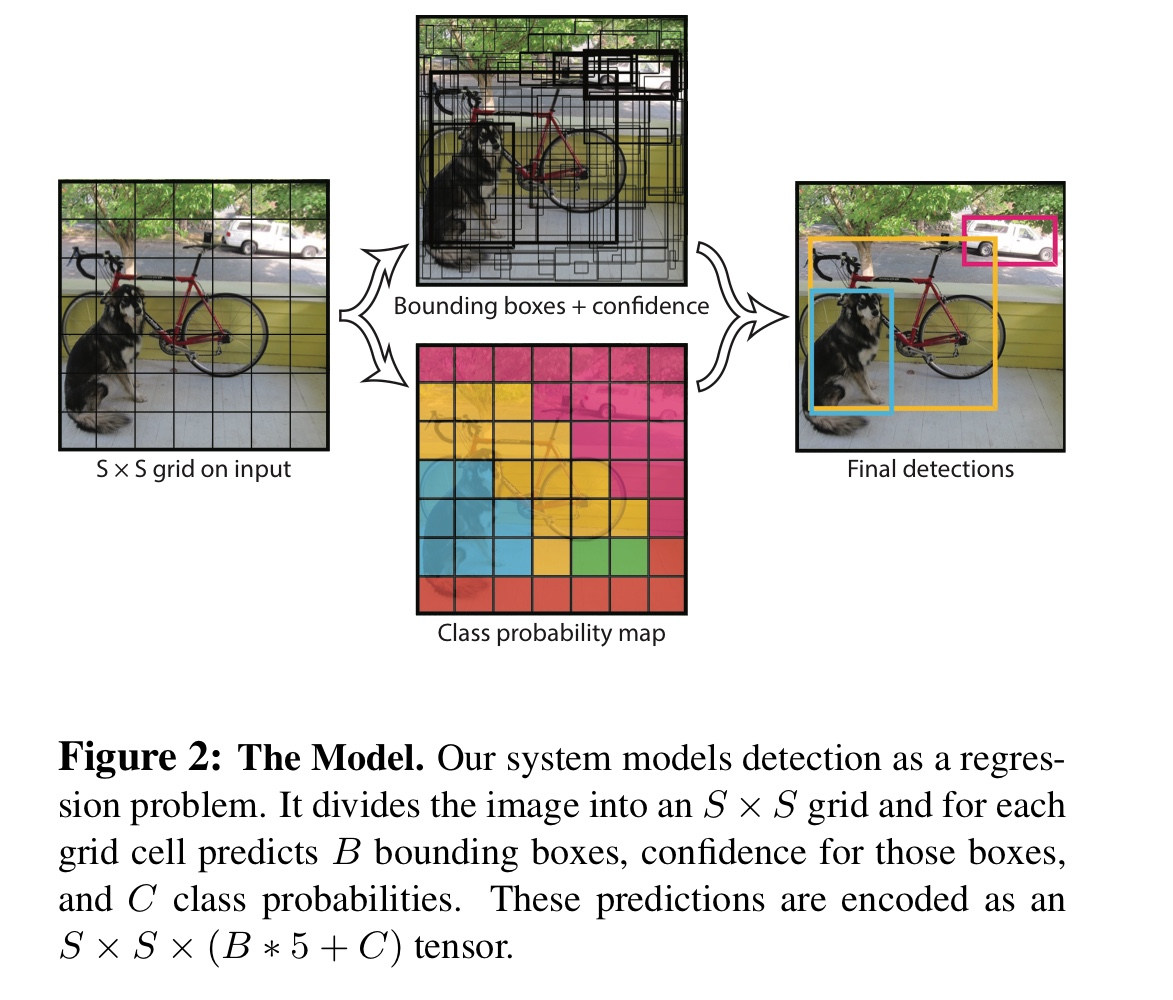
YOLO는 object detection의 개별 요소를 하나의 network로 통했습니다. 어떠한 방식으로 작동하는지 알아보도록 하겠습니다.
-
입력 이미지를
S x S grid로 분할합니다. -
객체의 중심이
grid cell에 맞아떨어지면 그grid cell은 객체를 탐지했다고 표기합니다. -
각
grid cell은B개의 바운딩박스와 각 바운딩박스에 대한confidence score를 예측합니다.confidence score는 얼마나 자신 있게 박스가 객체를 포함하고 있는지, 얼마나 정확하게 예측했는지를 반영합니다.
confidence는Pr(Object) * IOU로 계산합니다. cell에 객체가 존재하지 않을 시에Pr(Object)는 0이 되어confidence score는 0이 됩니다. 객체가 존재하면Pr(Object)는 1이 되고IoU와 곱해져confidence는IOU가 됩니다. -
각 바운딩 박스는 5개의 정보를 갖고 있습니다.x,y,w,h와confidence입니다.
x,y는 바운딩박스의 중심을 나타내며 grid cell의 경계에 상대적인 값입니다.
width와 height는 전체 이미지에 상대적인 값입니다.
마지막으로confidence는 예측된 박스와 진짜 박스 사이의 IOU 입니다. -
각 grid cell은 바운딩박스 이외에도
class 확률을 예측합니다.최종적으로 예측값은
(S x S x (B * 5 + C))크기의 tensor를 갖습니다. 논문에서는S = 7,B = 2,C = 20을 사용하여7 X 7 X 30 tensor를 갖습니다. (Pascal VOC Dataset 기준) -
non-max suppression을 거쳐서 최종 바운딩박스를 선정합니다.
1-4. YOLO v1 Architecture
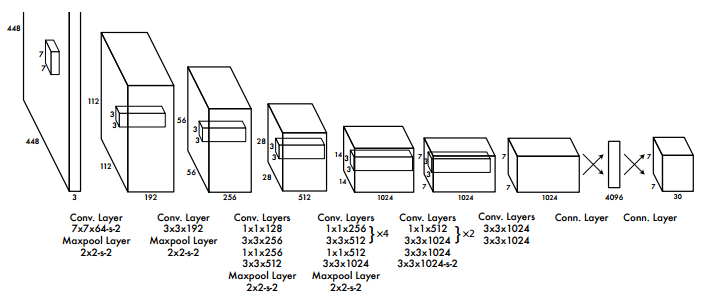
YOLO v1는 Image classification을 위한 GooLeNet 구조에 영감을 받아 해당 네트워크 구조를 설계했습니다. 기존의 GoogLeNet은 Inception module을 사용하지만 YOLO v1은 Inception module을 일자로 이어둔 모델을 사용했습니다.
YOLO는 convolutional layer로 이미지로부터 특징을 추출하고, FC layer로 Bounding box와 class 확률을 예측합니다.
YOLO는 24개의 convolutional layer와 2개의 fully connected layer로 이루어져 있습니다.
그리고 Image classfication을 위한 GoogLeNet에서 영향을 받아 1x1 차원 감소 layer 뒤에 3x3 convolutional layer를 이용합니다.
Fast version YOLO의 경우 네트워크에서 convolutional layer의 수를 24개에서 9개로 줄이고, 적은 filter 수를 사용했다. 네트워크 구조 이외에 모든 parameter는 original YOLO와 같습니다.
네트워크의 최종 출력은 7x7x30 tensor 입니다. (VOC dataset에 맞춘 output 크기)
1-5. Loss Function

YOLO는 sum-squared error를 손실함수로 이용합니다. 이는 다음과 같은 이유로 모델의 불안정성을 발생시켜서 손실함수를 수정해서 사용합니다.
- localization error와 classification error를 동등하게 가중치를 주는 것은 비이상적일 수 있습니다.
- 객체를 포함하고 있지 않은 grid cell은 confidence 값이 0을 갖습니다. 이는 객체를 포함한 grid cell의 gradient를 폭발하게 하고(객체를 포함한 confidence가 0을 향하게 하고) model이 불안정하게 만듭니다.
이 문제를 해결하기 위해서 바운딩 박스의 좌표에 대한 손실을 증가시키고 객체를 포함하고 있지 않은 박스에 대한 confidence 손실을 감소시킵니다. 이를 실행하기 위해 두 가지 파라미터를 사용합니다.
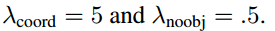
- λcoord는 바운딩 박스 좌표 손실에 대한 파라미터입니다. 바운딩 박스에 대한 손실을 5배 가중치로 두어 높은 패널티를 부여합니다.
- λnoobj은 객체를 포함하고 있지 않은 박스에 대한 confidence 손실의 파라미터입니다. 논문에서는 0.5로 설정했습니다. 즉, 배경인 경우 0.5의 가중치를 두어서 패널티를 낮추는 것입니다.
위 두 가지 파라미터로 localization error(바운딩 박스 좌표)와 classification error(잘못된 클래스 분류)에 가중치를 다르게 부여하게 됩니다.
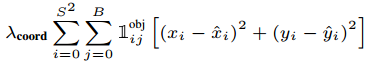
- x,y는 바운딩 박스 좌표입니다. 정답 좌표랑 예측 좌표 차이를 제곱하여 error를 계산하게 됩니다.
- 1objij는 obj는 객체가 탐지된 바운딩 박스를 말합니다.(가장 높은 IOU를 가진 바운딩박스), 이 수식은 i번째 grid에서 j번째 객체를 포함한 바운딩박스를 의미합니다.
- λcoord는 localization error의 페널티를 키우기 위한 파라미터로 5로 설정되어있습니다.
- 즉, 객체를 포함한 바운딩박스의 좌표에는 5배의 페널티를 부과합니다.

- 바운딩 박스의 너비와 높이에 대한 error입니다. 너비와 높이에도 5배의 페널티를 부여하는 것을 확인할 수 있습니다.
- 큰 박스에서 작은 변화와 작은 박스에서 작은 변화는 차이가 있습니다. 이를 보정해주기 위해 bounding box의 width와 height을 제곱근을 이용해 계산합니다.
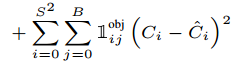
- 객체를 포함한 바운딩 박스에 대한 confidence error 입니다.
- 는 cell i에서 confidence score를 나타냅니다.
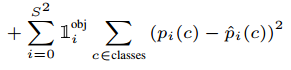
- p(c) 클래스 확률에 대한 error입니다. 객체를 포함한 바운딩박스에 대해서만 계산합니다.
- classification error에 대한 부분으로 생각할 수 있습니다.
YOLO는 여러 개의 bounding boxes를 각각의 grid cell에서 예측합니다. 학습 시에 각 grid cell마다 한 개의 bounding box를 원하기 때문에 bounding boxes 중에서 ground truth와 가장 IOU가 높은 box만 선택해서 학습시킵니다.
- 이때 선택된 한 개의 bounding box를 “responsible”이라 할당합니다.
2. Cat Detection
2-1. Comparison Hyperparmeters between Original Paper and Custom when Training
논문의 저자들은 다음과 같은 방법으로 모델을 학습시켰습니다.
Basic
- Epoch = 135, batch_size = 64, input_width = 448, input_height = 448
- num_classes = 20
Loss_function
- coord_scale : 5
- noobj_scale : 0.5
- obj_scale : 1
Optimizer
- SGD(Stochastic Gradient Descent) with momentum = 0.9,
- decay = 0.0005
Learning rate Scheduling
0.001 [1 epoch] –> 0.01 [75 epochs] –> 0.001 [30 epochs] –> 0.0001 [30 epochs]
Overfitting을 막기 위해
- Dropout과 Data Augmentation을 활용했습니다.
저는 제 학습 환경의 성능과 목적을 고려하여 다음과 같은 방법으로 모델을 학습시켰습니다.
Basic
- Epoch = 135, Batch_size = 24, input_width = 224, input_height = 224
- num_classes = 1
Loss_function
- coord_scale : 10
- noojb_scale : 0.1
- obj_scale : 0.5
- class_scale = 0.1 (원논문에는 없었지만, 클래스의 자유도를 위해 생성)
Optimizer
Adam
Learing rate Scheduling
- 초기 learning rate를 0.0001로 설정하고 lr_decay_rate를 0.5로 지정해 2,000 steps마다 1/2씩 감소
Overfitting을 막기 위해
- Dropout과 Data Augmentation을 활용했습니다.
학습을 마친 YOLO 모델은 PASCAL VOC의 이미지에 대해 각각 98개의 bounding boxes를 출력합니다. 이렇게 나온 98개의 bounding boxes들에 대해 NMS(Nom-Maximum Suppression)을 적용합니다.
2-2. PASCAL VOC Dataset
PASCAL VOC Dataset은 PASCAL VOC challenge에서 쓰이던 데이터셋입니다. 2005년에서 2012년까지 진행되었으며, 그중 PASCAL 2007과 PASCAL 2012 데이터셋이 벤치마크 데이터셋으로 자주 쓰입니다. PASCAL VOC는 대표적인 Object Detection 데이터셋 중 하나입니다. PASCAL VOC Dataset은 20개의 class를 가지고 있습니다. 본 프로젝트는 이 중 ‘Cat’만 선택하여 1개의 label을 가지고 학습을 진행했습니다.
Aeroplane,Bicycle,Bird,Boat,Bottle,Bus,Car,Cat,Chair,Cow,Diningtable,Dog,Horse,Motorbike,Person,Pottedplant,Sheep,Sofa,Train,Tvmonitor
본 프로젝트에서는 PASCAL VOC 2007년 데이터셋의 Train 데이터의 개수가 적은 것을 고려하여 2007년과 2012년 데이터셋을 혼합하여 학습에 사용하였습니다.
- Train 데이터로는 2007 Test (4,952 images) + 2012 Train (5,717 images), 총 10,669장을 사용했습니다.
- Validation 데이터로는 2007 Validation (2,510 images), 총
2,510장을 사용했습니다. - Test 데이터로는 2007 Train (2,501 images), 총
2,501장을 사용했습니다
2-3. Training & Evaluation
원논문에서는 Darknet 자체 프레임워크에서 GoogLeNet과 비슷한 layer를 직접 정의해서 학습시켰습니다. 그래서 저는 GoogLeNet과 비슷한 Inception-v3 모델과 Tensorflow 프레임워크에서 최종적으로 총 5,700 steps의 Training과 8,300 steps의 Validation을 진행했습니다.
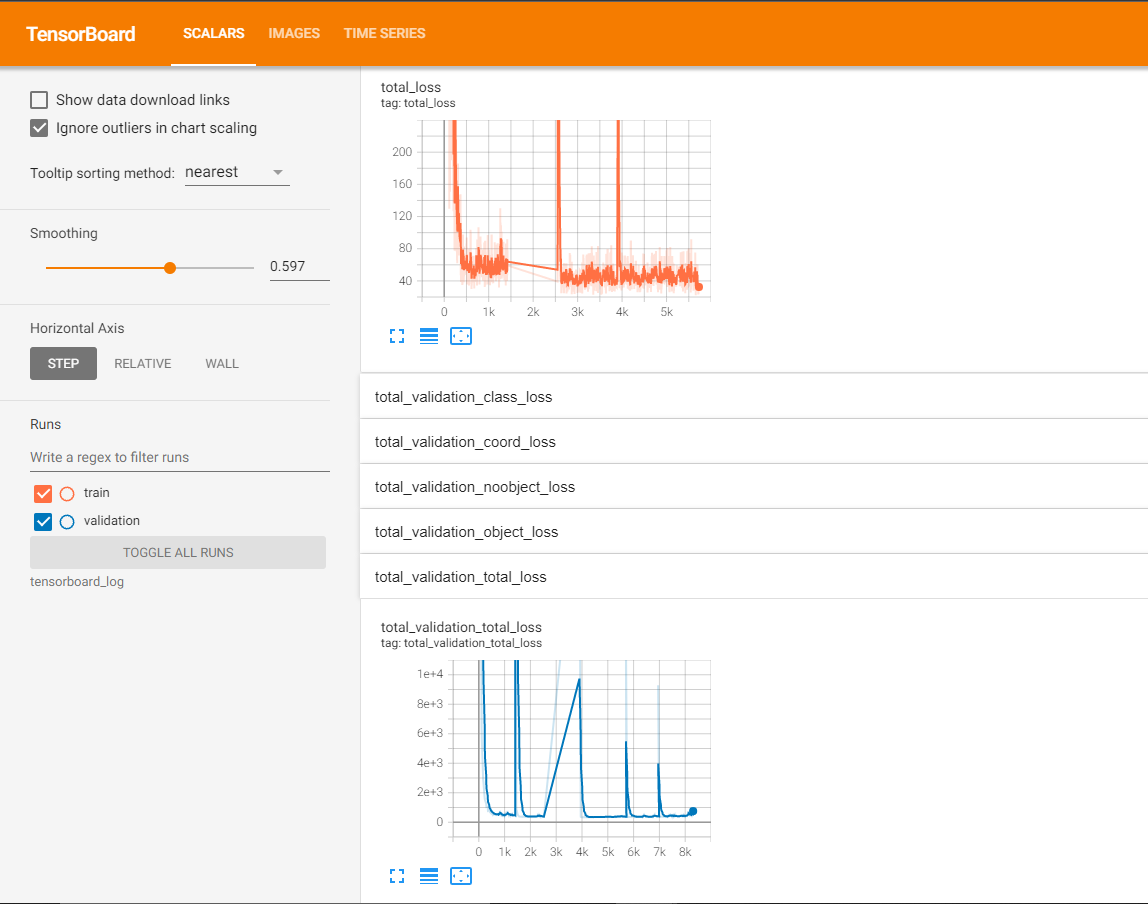
Total Loss와 Validation loss가 지속적으로 감소해서 학습을 진행할수록 일반화된 성능이 점진적으로 향상되는 과정을 확인할 수 있었습니다.
2-4. Test
8,300 steps의 트레이닝 이후 Test 데이터셋으로 사용한 Pascal VOC 2007 Train의 2,501장의 이미지를 테스트 데이터로 활용했습니다. 총 2,501장의 이미지 중, 고양이가 담긴 이미지는 총 166장이어서 166장의 이미지를 가지고 테스트를 진행했습니다.
결과는 다음과 같습니다.
일반적인 검출



여러 마리의 고양이


크기가 작은 고양이 검출


크기가 큰 고양이 검출


2-5. 개선점
위의 예시에서 볼 수 있듯이 Confidence Score가 학습량에 비례해서 높게 나오지 않고, Yolo v1 알고리즘 특성상 Confidence가 가장 큰 1개의 Bounding box를 형성하기 때문에 고양이 마릿수에 비례해 bounding box 형성이 안 됩니다.
그리고 Input_size를 작게 설정해서 학습한 결과, 고양이의 크기가 크게 나오는 이미지에서는 고양이의 크기에 비례한 Bounding box 형성이 안 되는 모습을 볼 수 있습니다.
이러한 문제에 대한 이유는 여러 가지가 있을 수 있지만, 크기, 색깔, 종 등 다양한 특성을 가진 고양이들을 학습하기에 학습데이터의 양이 불충분했던 점을 주요 원인 중 하나로 볼 수 있습니다. 따라서 다양한 고양이 이미지들을 더 수집한 후, Training을 진행하는 과정을 통해 Confidence Score를 향상하게 시키고 고양이 크기에 비례한 Bounding box 형성을 개선점을 가질 수 있을 것 같습니다.
