7.1 전체 구조
지금까지 본 신경망은 인접하는 계층의 모든 뉴런과 결합되어 있었다.
- 이를 완전연결이라고 하며, 완전히 연결된 계층을 Affine 계층이라는 이름으로 구현했다.
Affine 계층을 사용해서 층이 5개인 완전연결 신경망은 다음과 같다.
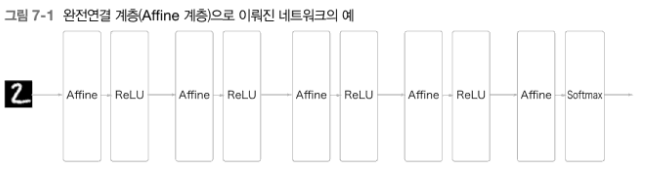
- 완전연결 신경망은 Affine 계층 뒤에 활성화 함수 ReLU(or Sigmoid) 계층이 이어짐.
Affine-ReLU계층 조합이 4개가 쌓였고, 마지막 5번째 층은 Affine 계층에 이어서Softmax계층에서 최종 결과(확률)을 출력
CNN의 구조를 접목하면 다음과 같다.
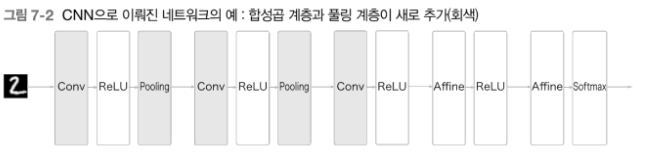
- CNN에서는 새로운
합성곱 계층과풀링 계층이 추가된다. - CNN에서 주목할 또 다른 점은 출력에 가까운 층에서는 지금까지의
Affine-ReLU구성을 사용할 수 있다는 점이다. - 또, 마지막 출력 계층에서는
Affine-Softmax조합을 그대로 사용
7.2 합성곱 계층
CNN에서는 패딩, 스트라이드 등 CNN 고유의 용어가 등장한다.
또, 각 계층 사이에는 3차원 데이터같이 입체적인 데이터가 흐른다는 점에서 완전연결 신겨암ㅇ과 다르다.
7.2.1 완전연결 계층의 문제점
완전연결 계층에서는 인접하는 계층의 뉴런이 모두 연결되고, 출력의 수는 임의로 정할 수 있다.
완전연결 계층의 문제점은 무엇일까??
데이터의 형상이 무시된다는 점이다.- 형상이 3차원인 이미지 데이터를 완전연결 계층에 입력할 때는 3차원 입력데이터를 평평한
1차원 데이터로 평탄화해줘야 한다. - MNIST 사례에서는 형상이
(1, 28, 28)인 이미지(1 채널, 세로 28픽셀, 가로 28 픽셀)를 1줄로 세운784개의 데이터를 첫 Affine 계층에 입력했다.
- 형상이 3차원인 이미지 데이터를 완전연결 계층에 입력할 때는 3차원 입력데이터를 평평한
이미지는 3차원 형상이며, 이 형상에는 소중한 공간적 정보가 담겨 있다.
- 예를 들어, 공간적으로 가까운 픽셀은 값이 비슷
- RGB의 각 채널은 서로 밀접하게 관련되어 있거나, 거리가 먼 픽셀끼리는 별 연관이 없음
3차원 속에서 의미를 갖는 본질적인 패턴이 숨어있다.
- 하지만, 완전연결 계층은 형상을 무시하고 모든 입력 데이터를 동등한 뉴런(같은 차원의 뉴런)으로 취급하여 형상에 담긴 정보를 살릴 수 없다.
한편, 합성곱 계층은 형상을 유지한다.
- 이미지도
3차원 데이터로 입력 받으며, 마찬가지로 다음 계층에도3차원 데이터로 전달한다. - 그래서 CNN에서는 이미지처럼 형상을 가진 데이터를 제대로 이해할 수 있는 것이다.
CNN에서는 합성곱 계층의 입출력 데이터를 특징 맵이라고도 한다.
- 합성곱 계층의 입력데이터를 입력 특징 맵
- 합성곱 계층의 출력데이터를 출력 특징 맵
7.2.2 합성곱 연산
합성곱 계층에서는 합성곱 연산을 처리한다.
합성곱 연산은 이미지 처리에서 말하는 필터 연산에 해당한다.
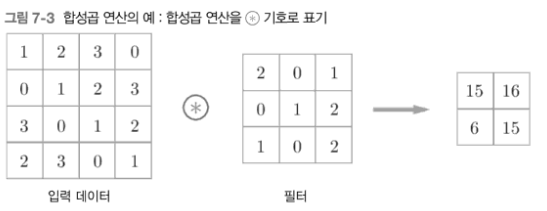
합성곱 연산은 입력 데이터에 필터를 적용한다.
- 데이터와 필터의 형상을 (높이, 너비)로 표기
- 문헌에 따라 필터를 커널이라고 칭하기도 한다.
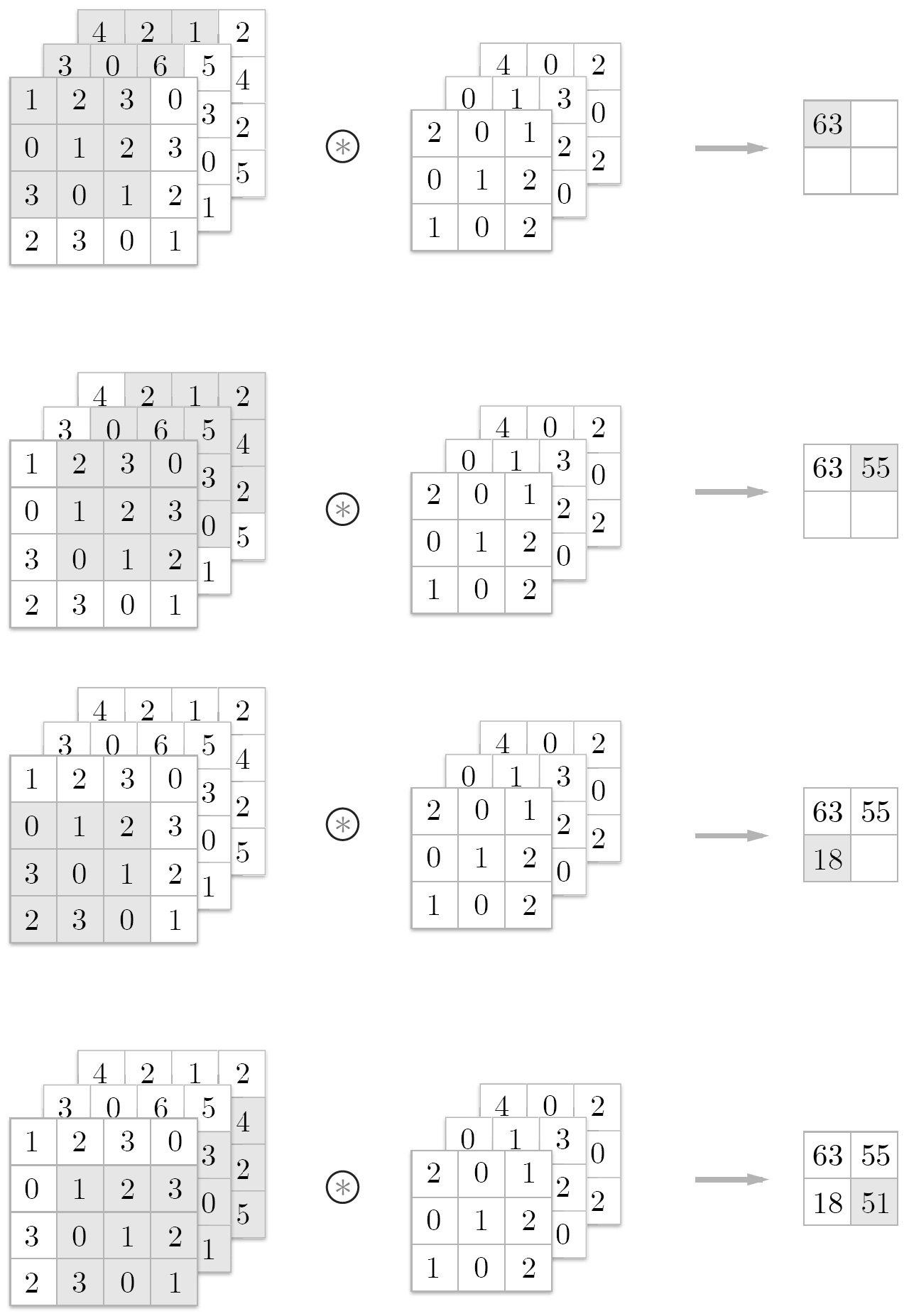
합성곱 연산의 계산 순서는 다음과 같다.
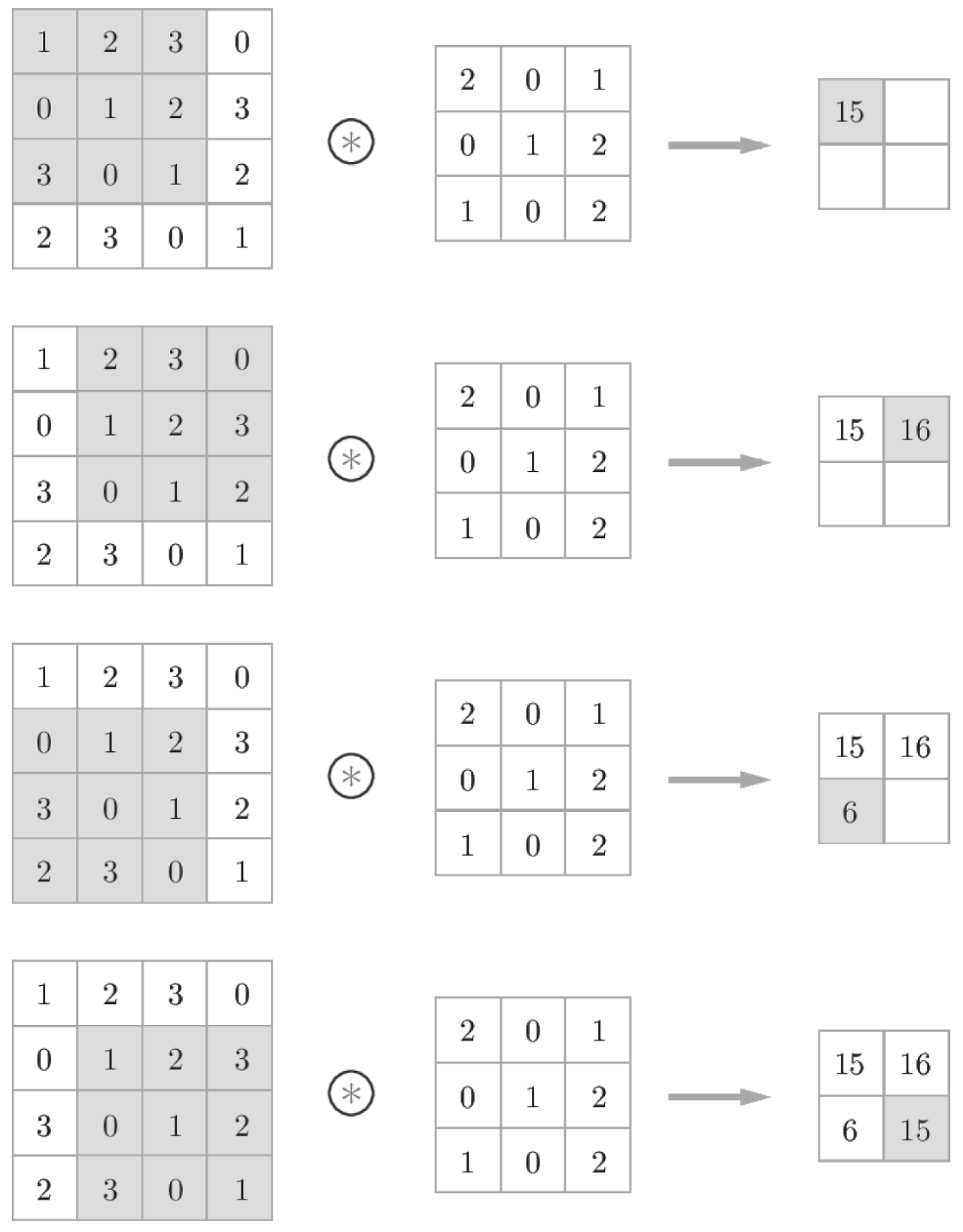
- 필터의 윈도우를 일정 간격으로 이동해가며 입력 데이터에 적용
- 회색의
3x3부분
- 회색의
- 입력과 필터에서 대응하는 원소끼리 곱한 후 그 총합을 구한다
- 단일 곱셈-누산
- 그리고 그 결과를 출력의 해당 장소에 저장한다.
이 과정을 모든 장소에서 수행하면 합성곱 연산의 출력이 완성된다.
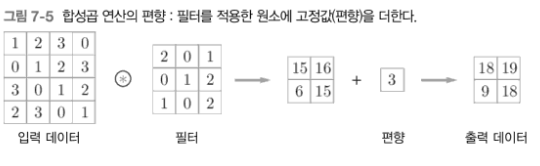
완전연결 신경망에서는 가중치 매개변수와 편향이 존재하는데, CNN에서는 필터의 매개변수가 그동안의 '가중치'에 해당한다.
- 그리고 CNN에서도 편향이 존재한다.
위 그림과 같이 편향은 필터를 적용한 후의 데이터에 더해진다.
- 편향은 항상 하나
(1x1)만 존재한다. - 그 하나의 값을 필터를 적용한 모든 원소에 더하는 것.
7.2.3 패딩
합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정 값(e.g. 0)으로 채우기도 하며, 이를 패딩이라 하며, 합성곱 연산에서 자주 이용하는 기법이다.
예시 : (4,4)크기의 입력데이터에 폭이 1인 패딩 적용
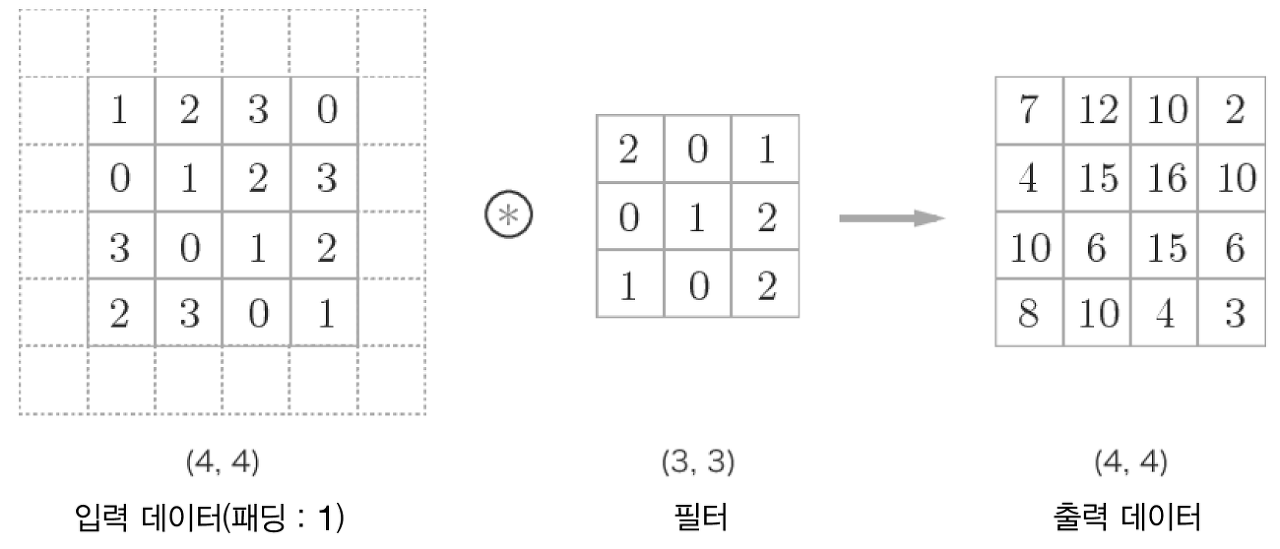
-
(4,4)입력데이터에 패딩 추가되어(6,6)이 됨- 이 입력에
(3,3)크기의 필터를 걸면(4,4)크기의 출력 데이터가 생성된다.
💡
패딩은 주로 출력 크기를 조정할 목적으로 사용된다.- 합성곱 연산을 거칠 때마다 출력의 크기가 작아지면 어느 시점에서는 출력 크기가
1이 되어버린다. - 더 이상은 합성곱 연산을 적용할 수 없다는 뜻
이러한 사태를 막기 위해서 패딩을 사용한다.
- 앞의 예에서 패딩의 폭을
1로 설정하니(4,4)입력에 대한 출력이 같은 크기인(4,4)로 유지되었음 - 입력 데이터의 공간적 크기를 고정한 채로 다음 계층에 전달할 수 있음
- 이 입력에
7.2.4 스트라이드
필터를 적용하는 위치의 간격을 스트라이드라고 한다.
- 스트라이드를
2로 하면 필터 적용 윈도우가두 칸씩 이동
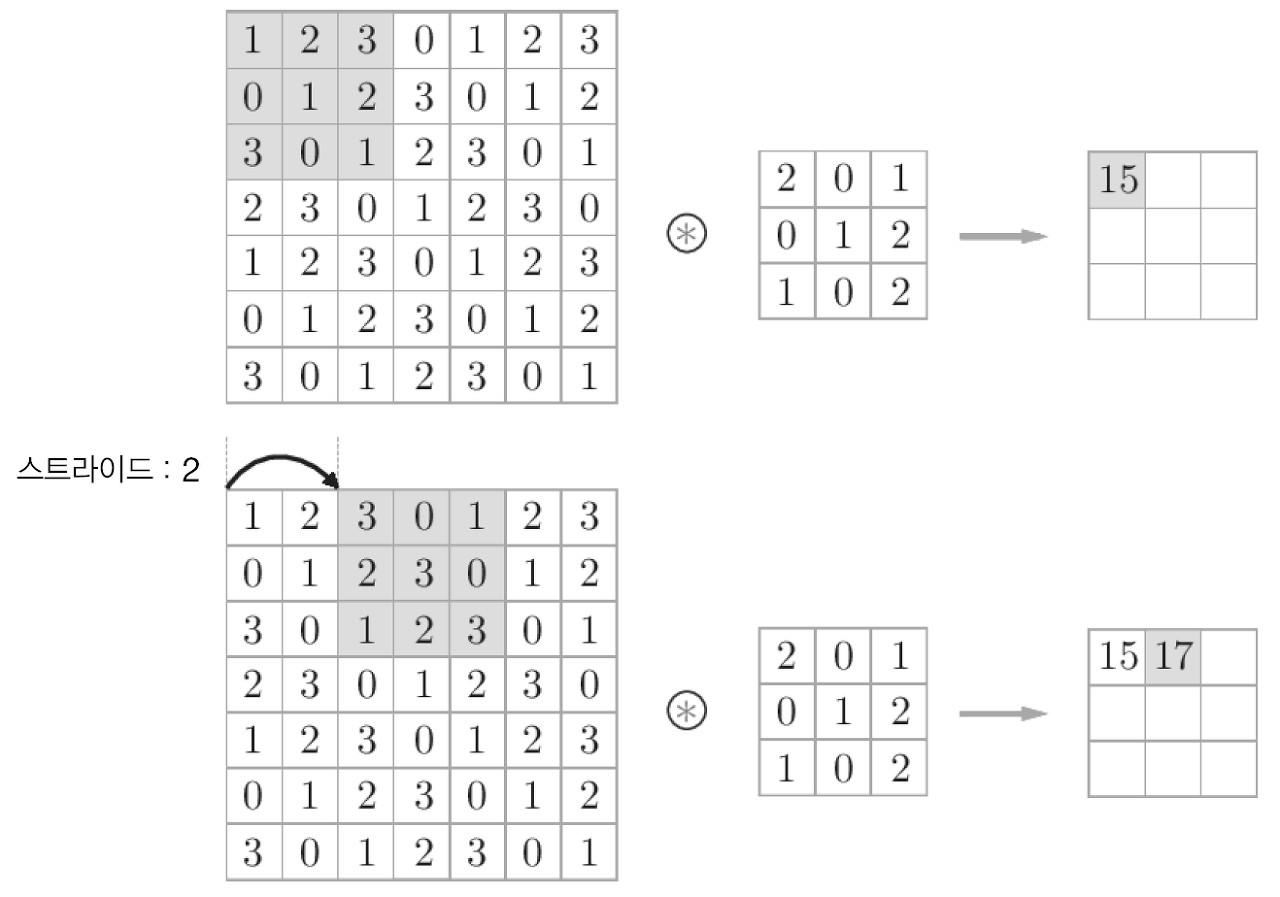
- 위 그림에서는 크기가
(7,7)인 입력 데이터에 스트라이드를2로 설정한 필터를 적용
스트라이드를 키우면 출력 크기는 작아진다.
한편, 패딩을 크게 하면 출력 크기가 커진다.
이러한 관계를 수식화하면 다음과 같다.
- 입력 크기:
- 필터 크기:
- 출력 크기:
- 패딩:
- 스트라이드:
수식들은 정수로 나눠떨어지는 값이어야 한다.
- 값이 딱 나눠떨어지지 않을 때는 가장 가까운 정수로 반올림하는 등의 방법을 사용
7.2.5 3차원 데이터의 합성곱 연산
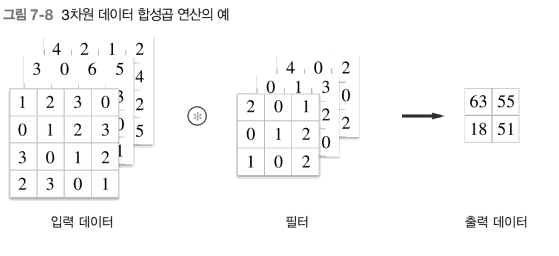
위 그림은 3차원 데이터의 합성곱 연산 예시이다.
2차원일 때와 비교하면, 길이 방향(채널 방향)으로 특징 맵이 늘어났다.
채널 쪽으로 특징 맵이 여러 개 있다면,
- 입력 데이터와 필터의 합성곱 연산을 채널마다 수행하고,
- 그 결과를 더해서 하나의 출력을 얻는다.
3차원 데이터 합성곱 연산의 계산 순서는 다음과 같다.
-
3차원의 합성곱 연산에서 주의할 점은 입력 데이터의 채널 수와 필터의 채널 수가 같아야 한다는 것이다.
-
필터의 채널 수는 입력 데이터의 채널 수와 같도록 설정해야 한다.
7.2.6 블록으로 생각하기
3차원의 합성곱 연산은 데이터와 필터를 직육면체 블록이라고 생각하면 쉽다.
3차원 데이터를 배열로 나타낼 때는 채널, 높이, 너비 순서 / 필터 이다.
출력데이터는 한 장의 특징 맵이다.
- 다수의 채널을 내보내려면 필터(
가중치)를 다수 사용
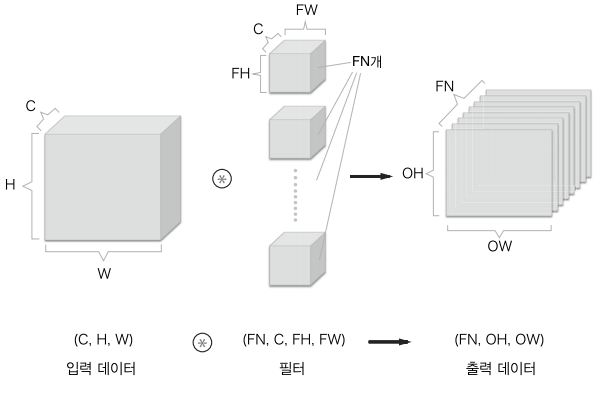
필터를 FN개 적용하면 출력 맵도 FN개 생성된다.
- 그리고 그
FN개의 맵을 모으면 인 블록이 완성됨 - 이 완성된 블록을 다음 계층으로 넘기겠다는 것이 CNN의 처리 흐름이다.
합성곱 연산에서는 필터의 수도 고려해야 한다.
- 그런 이유로 필터의 가중치 데이터는 4차원 데이터
(출력채널 수, 입력채널 수, 높이, 너비)순으로 쓴다.- 채널 수
3, 크기5x5, 필터20이 있다면(20, 3, 5, 5)
- 채널 수
합성곱 연산에도 (완전연결 계층과 마찬가지로) 편향을 추가한다.
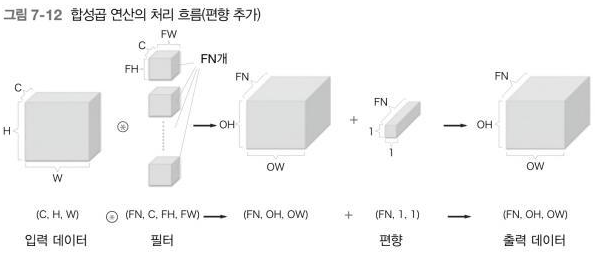
- 편향은 채널 하나에 값 하나씩으로 구성된다.
- 편향의 형상은
- 필터의 출력 결과의 형상은
위 두 블록을 더하면 편향의 각 값이 필터의 출력인 블록의 대응 채널의 원소 모두에 더해진다.
7.2.7 배치 처리
합성곱 연산에서도 배처 처리를 지원한다.
각 계층을 흐르는 데이터의 차원을 하나 늘려 4차원 데이터로 저장한다.
- 데이터를
(데이터 수, 채널 수, 높이, 너비)순으로 저장
데이터가 개 일때 데이터 형태는 다음과 같다.
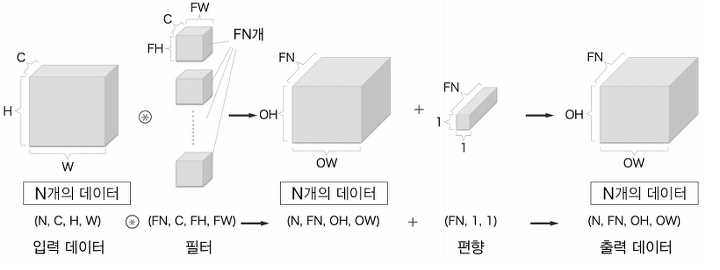
-
각 데이터의 선두에 배치용 차원을 추가했다.
- 데이터는
4차원 형상을 가진 채 각 계층을 타고 흐른다.
- 데이터는
-
주의할 점은 신경망에 4차원 데이터가
하나흐를 때마다, 데이터N개에 대한 합성곱 연산이 이뤄진다.
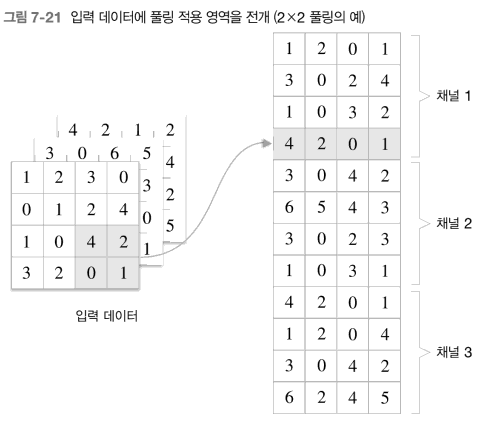
7.3 풀링 계층
풀링은 세로 가로 방향의 공간을 줄이는 연산이다.
아래 그림처럼 2x2 영역을 원소 하나로 집약하여 공간 크기를 줄인다.
- 2x2 최대 풀링을 스트라이드
2로 처리한다.
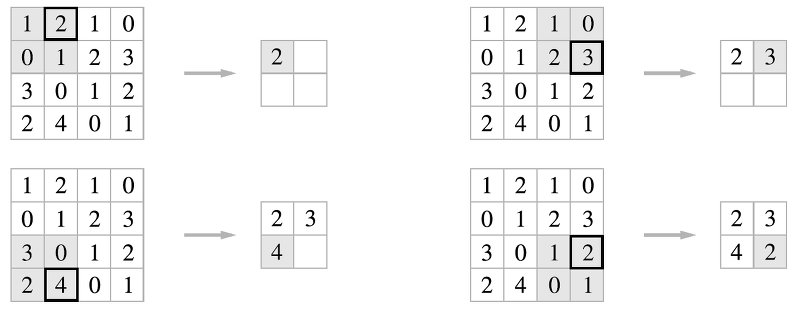
최대 풀링은 최댓값를 구하는 연산으로, 2x2는 대상 영역의 크기를 나타낸다.
- 즉 2x2 최대 풀링은 그림과 같이 2x2 크기의 영역에서 가장 큰 하나를 꺼낸다.
- 스트라이는
2로 설정했으므로 2x2 윈도우가 원소2칸 간격으로 이동한다.
풀링의 윈도우 크기와 스트라이드는 같은 값으로 설정하는 것이 보통이다.
💡
풀링은 최대 풀링 외에도 평균 풀링등이 있다.
- 최대 풀링은 대상 영역에서 최댓값을 취하는 연산인 반면,
- 평균 풀링은 대상 영역의 평균을 계산한다.
이미지 인식 분야에서는 주로 최대 풀링을 사용한다.
7.3.1 풀링 계층의 특징
학습해야 할 매개변수가 없다.
- 풀링 계층은 합성곱 계층과 달리 학습해야할 매개변수가 없다.
- 풀링은 대상 영역에서 최댓값이나 평균을 취하는 명확한 처리
채널 수가 변하지 않는다.
- 풀링 연산은 입력 데이터의 채널 수 그대로 출력 데이터로 내보낸다.
- 채널마다 독립적으로 계산하기 때문
입력의 변화에 영향을 적게 받는다(강건하다)
- 입력 데이터가 조금 변해도 풀링의 결과는 잘 변하지 않는다
- 입력 데이터의 차이를 풀링이 흡수해 사라지게 한다.
7.4 합성곱/풀링 계층 구현하기
7.4.1 4차원 배열
CNN에서 계층 사이를 흐르는 데이터는 4차원이다.
- 예를 들어 데이터의 형상이
(10, 1, 28, 28)이라면, 이는 높이28, 너비28, 채널1개인 데이터가10개라는 이야기
# 높이28, 너비28, 채널 1개인 데이터가 10개
import numpy as np
x = np.random.rand(10, 1, 28, 28) # 무작위로 데이터 생성
x.shape
>>> (10, 1, 28, 28)
# 데이터 인덱스를 통한 접근
print(x[0].shape)
print(x[1].shape)
>>>
(1, 28, 28)
(1, 28, 28)
# 첫번째 데이터의 첫 채널의 공간데이터에 접근
x[0, 0] # 또는 x[0][0]
>>>
array([[0.61206976, 0.84700886, 0.8283767 , 0.07469919, 0.65067234,
0.20880005, 0.76496379, 0.87379827, 0.04830922, 0.15357888,
0.97190819, 0.20289728, 0.82323917, 0.62009294, 0.5898003 ,
0.74319218, 0.91953033, 0.14464074, 0.88625752, 0.2942877 ,
0.99571249, 0.24535918, 0.02239101, 0.67893039, 0.51143285,
0.11055255, 0.61903003, 0.8351252 ],
...7.4.2 im2col로 데이터 전개하기
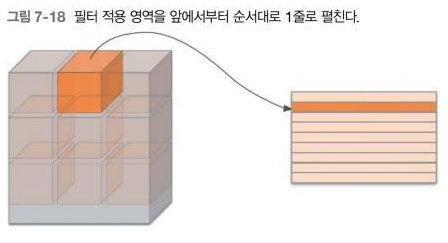
im2col은 입력 데이터를 필터링(가중치 계산)하기 좋게 전개하는(펼치는) 함수이다.
- 3차원 입력 데이터에
im2col을 적용하면 2차원 행렬로 바뀐다.- 정확히는 배치 안의 데이터 수까지 포함한
4차원 데이터를2차원으로 변환한다.
- 정확히는 배치 안의 데이터 수까지 포함한
실제 상황에서는 필터 적용 영역이 겹치는 경우가 대부분이다.
- 필터 적용 영역이 겹치게 되면
im2col로 전개한 후의 원소 수가 원래보다 많아짐 (메모리 더 많이 소비)
컴퓨터는 큰 행렬을 묶어 계산하는 데 탁월해서 효율 높일 수 있다.
- 문제를 행렬 계산으로 만들면 선형 대수 라이브러리를 활용해 효율을 높일 수 있다.
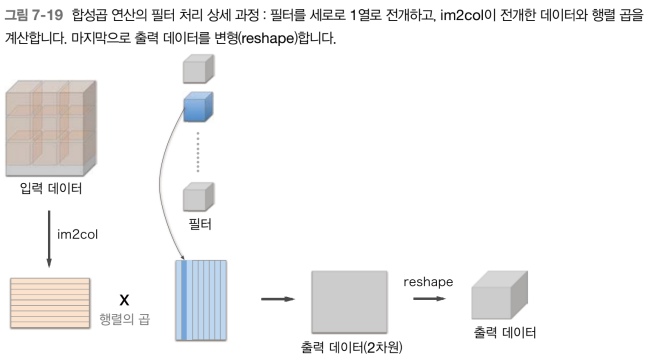
im2col 입력 데이터 전개 후, 합성곱 계층의 필터(가중치)를 1열로 전개하고 두 행렬의 곱을 계산
- 완전연결 계층의 Affine 계층에서 한 것과 같음
im2col 방식으로 출력한 결과는 2차원 행렬이다.
CNN은 데이터를 4차원 배열로 저장하므로 2차원인 출력 데이터를 4차원으로 변형한다.
7.4.3 합성곱 계층 구현하기
im2col의 인터페이스는 다음과 같다.
-
im2col(input_data, filter_h, filter_w, stride=1, pad=0)
-
input_data : (데이터 수, 채널 수, 높이, 너비)의 입력데이터
-
filter_h : 필터의 높이
-
filter_w : 필터의 너비
-
stride : 스트라이드
-
pad : 패딩
이 im2col은 필터 크기, 스트라이드, 패딩을 고려하여 입력 데이터를 2차원 배열로 전개한다.
# im2col 사용 구현
import sys, os
sys.path.append('/deep-learning-from-scratch')
from common.util import im2col
x1 = np.random.rand(1, 3, 7, 7) # 데이터 수, 채널 수, 높이, 너비
col1 = im2col(x1, 5, 5, stride=1, pad=0)
print(col1.shape)
>>>
(9, 75)
x2 = np.random.rand(10, 3, 7, 7) # 데이터 10개
col2 = im2col(x2, 5, 5, stride=1, pad=0)
print(col2.shape)
>>>
(90, 75)im2col 함수를 적용한 두 경우 모두 2번째 차원의 원소는 75개이다.
- 이 값은 필터의 원소 수와 같다. (
채널 3개,5x5데이터) - 배치크기가
1일 때는(9, 75),10일 때는 10배인(90, 75)이다.
im2col을 사용하여 합성곱 계층을 구현하면 다음과 같다.
# 합성곱 계층 구현 - Convolution 클래스
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
def forward(self, x):
# 필터 개수, 채널, 필터 높이, 필터 너비
FN, C, FH, FW = self.W.shape # 필터 4차원 형상
N, C, H, W = x.shape
out_h = int(1 + (H + 2*self.pad - FH) / self.stride)
out_w = int(1 + (W +2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad) # 입력데이터 전개
col_W = self.W.reshape(FN, -1).T # 필터 전개 (필터를 세로로 1열로 만듦)
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
return out-
reshape의 두 번째 인수를-1로 지정하면, 다차원 배열의 원소 수가 변환 후에도 똑같이 유지되도록 묶어준다.- (10, 3, 5, 5) 형상을 한 다차원 배열 의 원소 수가 총
750개이면,750개의 원소를10묶음으로, 형상이(10, 75)인 배열로 만들어줌.
- (10, 3, 5, 5) 형상을 한 다차원 배열 의 원소 수가 총
-
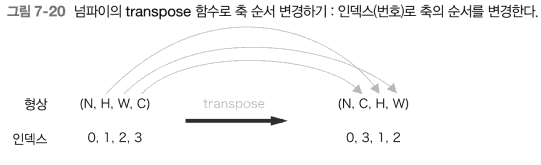
transpose함수를 이용해 출력데이터를 적절한 형상으로 바꾸어 줌.- 다차원 배열의 축 순서를 바꿔주는 함수
- 인덱스를 지정하여 축의 순서 변경
역전파에서는 im2col 대신 col2im 함수를 사용한다.
7.4.4 풀링 계층 구현하기
풀링 계층 구현도 im2col 함수를 사용해 입력 데이터를 전개하지만,
채널 쪽이 독립적이라는 점이 합성곱 계층 때와 다르다.
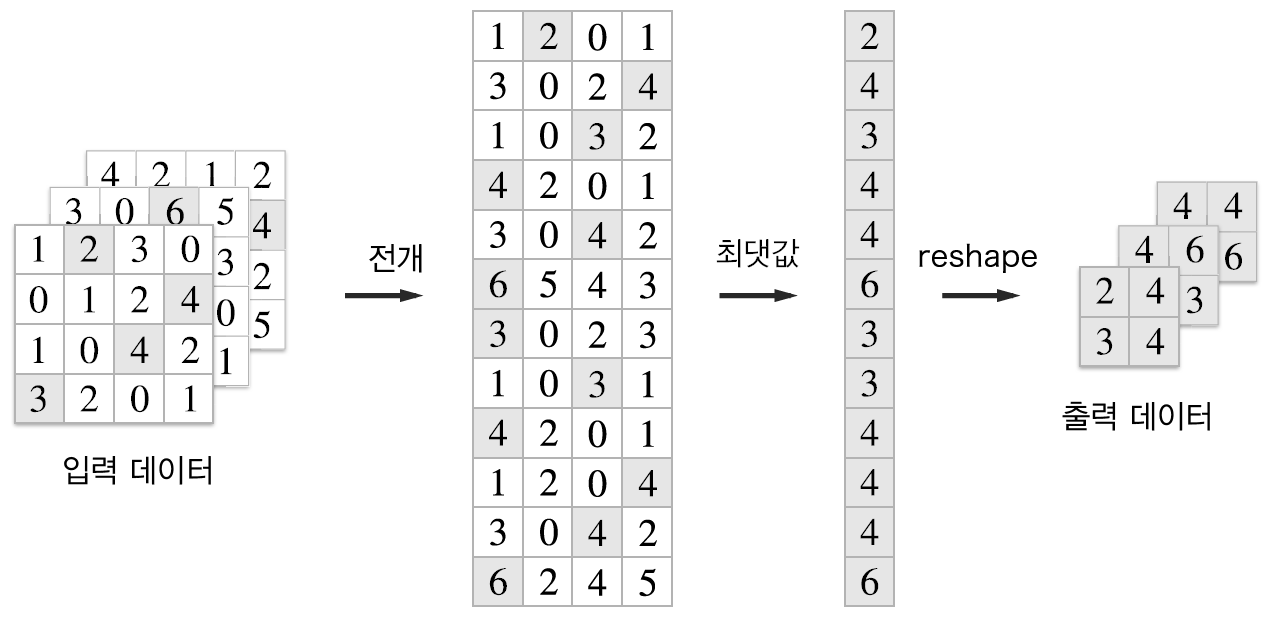
이렇게 전개한 후, 전개한 행렬에서 행별 최댓값을 구하고, 적절한 형상으로 만들어준다.

# 풀링 계층 구현
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
# 전개 (1)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
# 최댓값 (2)
# 2차원 배열일 때, axis=0: 열 방향, axis=1: 행 방향
out = np.max(col, axis=1) # 각 행마다 최댓값 도출
# 성형 (3)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
return out풀링 계층은 3단계로 진행이 된다.
- 입력 데이터를 전개한다.
- 행별 최댓값을 구한다.
- 적절한 모양으로 성형한다.
7.5 CNN 구현하기
Conv - ReLU - Pooling - Affine - ReLU - Affine - Softmax 형태이다.
초기화(__ init __)에서 받는 파라미터(인수)는 다음과 같다.
input_dim: 입력 데이터(채널 수, 높이, 너비)의 차원conv_param: 합성곱 계층의 하이퍼파라미터, 딕셔너리의 키는 다음과 같음filter_num: 필터 수filter_size: 필터 크기stride: 스트라이드
pad: 패딩hidden_size: 은닉층(완전연결)의 뉴런 수output_size: 출력층(완전연결)의 뉴런 수weight_init_std: 초기화 때의 가중치 표준편차
합성곱계층의 하이퍼파라미터는 딕셔너리 형태로 주어진다.
class SimpleConvNet:
"""단순한 합성곱 신경망
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 입력 크기(MNIST의 경우엔 784)
hidden_size_list : 각 은닉층의 뉴런 수를 담은 리스트(e.g. [100, 100, 100])
output_size : 출력 크기(MNIST의 경우엔 10)
activation : 활성화 함수 - 'relu' 혹은 'sigmoid'
weight_init_std : 가중치의 표준편차 지정(e.g. 0.01)
'relu'나 'he'로 지정하면 'He 초깃값'으로 설정
'sigmoid'나 'xavier'로 지정하면 'Xavier 초깃값'으로 설정
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))초기화 인수로 주어진 합성곱 계층의 하이퍼파라미터를 딕셔너리에서 꺼낸다.
그리고 합성곱 계층의 출력 크기를 계산한다
# 가중치 초기화
self.params = {}
# 합성곱
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
# 완전연결
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)학습에 필요한 매개변수는 1번째 층의 합성곱 계층과 나머지 두 완전연결 계층의 가중치 편향이다.
- 이 매개변수들을 인스턴수 변수 params 딕셔너리에 저장한다.
1번째 층의 합성곱 계층의 가중치를 W1, 편향을 b1이라는 키로 저장한다.
마찬가지로 2번째 층의 완전연결 계층의 가중치와 편향을 W2와 b2, 마지막 3번째 층의 완전연결 계층의 가중치와 편향을 W3와 b3라는 키로 각각 저장한다.
마지막으로 CNN을 구성하는 계층들을 생성한다.
# 계층 생성
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()순서가 있는 딕셔너리인 layers에 계층들을 차례로 추가한다.
마지막 SoftmaxWithLoss 계층은 last_layer라는 별도 변수에 저장해둔다.
초기화 한 이후에는 predict 메서드와 loss 메서드를 통해 추론을 수행하고 손실 함수의 값을 구한다.
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""손실 함수를 구한다.
Parameters
----------
x : 입력 데이터
t : 정답 레이블
"""
y = self.predict(x)
return self.last_layer.forward(y, t)인수 x는 입력 데이터, t는 정답 레이블이다.
predict 메서드는 초기화 때 layers에 추가한 계층을 맨 앞에서부터 차례로 forward 메서드를 호출하며 그 결과를 다음 계층에 전달한다.
loss 메서드는 predict 메서드의 결과를 인수로 마지막 층의 forward 메서드를 호출한다.
첫 계층부터 마지막 계층까지 forward를 처리한다.
오차역전파법으로 기울기를 구하는 구현은 다음과 같다.
def gradient(self, x, t):
"""기울기를 구한다(오차역전파법).
Parameters
----------
x : 입력 데이터
t : 정답 레이블
Returns
-------
각 층의 기울기를 담은 사전(dictionary) 변수
grads['W1']、grads['W2']、... 각 층의 가중치
grads['b1']、grads['b2']、... 각 층의 편향
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads매개변수의 기울기는 오차역전파법으로 구한다. 이 과정은 순전파와 역전파를 반복한다.
마지막으로 grads라는 딕셔너리 변수에 각 가중치 매개변수의 기울기를 저장한다.
7.6 CNN 시각화하기
7.6.1 1번째 층의 가중치 시각화하기
MNIST 데이터 셋으로 CNN 학습을 해보면 1번째 층의 합성곱 계층의 가중치는 그 형상이 (30, 1, 5, 5)이다.
- 필터의 크기가
5x5이고 채널이1개라는 것은 이 필터를 1채널의 회색조 이미지로 시각화할 수 있다는 뜻이다.
합성곱 계층 필터를 이미지로 나타내면 다음과 같다.
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
# from simple_convnet import SimpleConvNet
def filter_show(filters, nx=8, margin=3, scale=10):
"""
c.f. https://gist.github.com/aidiary/07d530d5e08011832b12#file-draw_weight-py
"""
FN, C, FH, FW = filters.shape
ny = int(np.ceil(FN / nx))
fig = plt.figure()
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(FN):
ax = fig.add_subplot(ny, nx, i+1, xticks=[], yticks=[])
ax.imshow(filters[i, 0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
network = SimpleConvNet()
# 가중치 초기화(랜덤)
filter_show(network.params['W1'])
# 학습 후 가중치
network.load_params("/content/drive/MyDrive/deep-learning-from-scratch/ch07/params.pkl")
filter_show(network.params['W1'])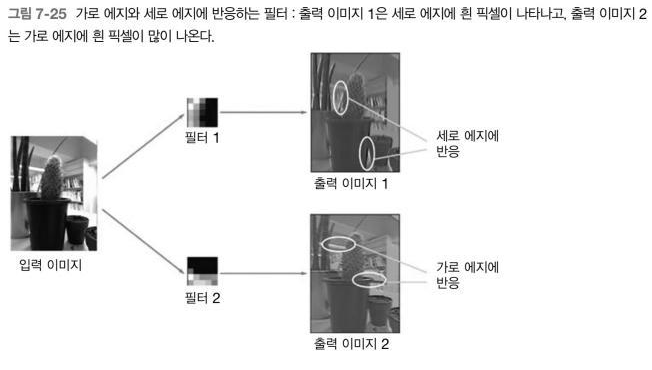
위의 사진이 학습 전, 학습 후의 필터이다.
- 학습 전 필터는 무작위로 초기화되고 있어 흑백의 정도에 규칙성이 없다.
- 학습을 마친 필터는 규칙성이 있는 이미지가 되었다.
- 흰색에서 검은색으로 점차 변화하는 필터와 덩어리(블롭)가 진 필터 등, 규칙을 띄는 필터로 바뀌었다.
규칙성있는 필터는 에지(색상이 바뀐 경계선)와 블롭(국소적으로 덩어리진 영역)` 등을 보고 있음
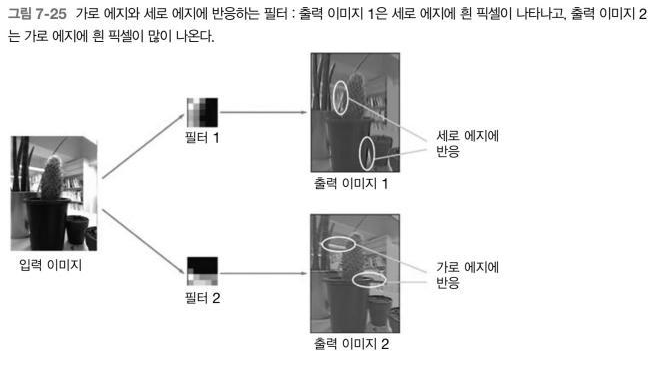
합성곱 계층의 필터는 에지나 블롭 등의 원시적인 정보 추출이 가능하고, 이런 정보가 뒷단 계층에 전달이 된다.
7.6.2 층 깊이에 따른 추출 정보 변화
위는 1번째 층의 합성곱 계층을 대상으로 한 것.
1번째 층의 합성곱 계층에서는 에지나 블롭 등의 저수준 정보가 추출된다.
반면, 계층이 깊어질 수록 추출되는 정보(정확히는 강하게 반응하는 뉴런)는 더 추상화 된다.
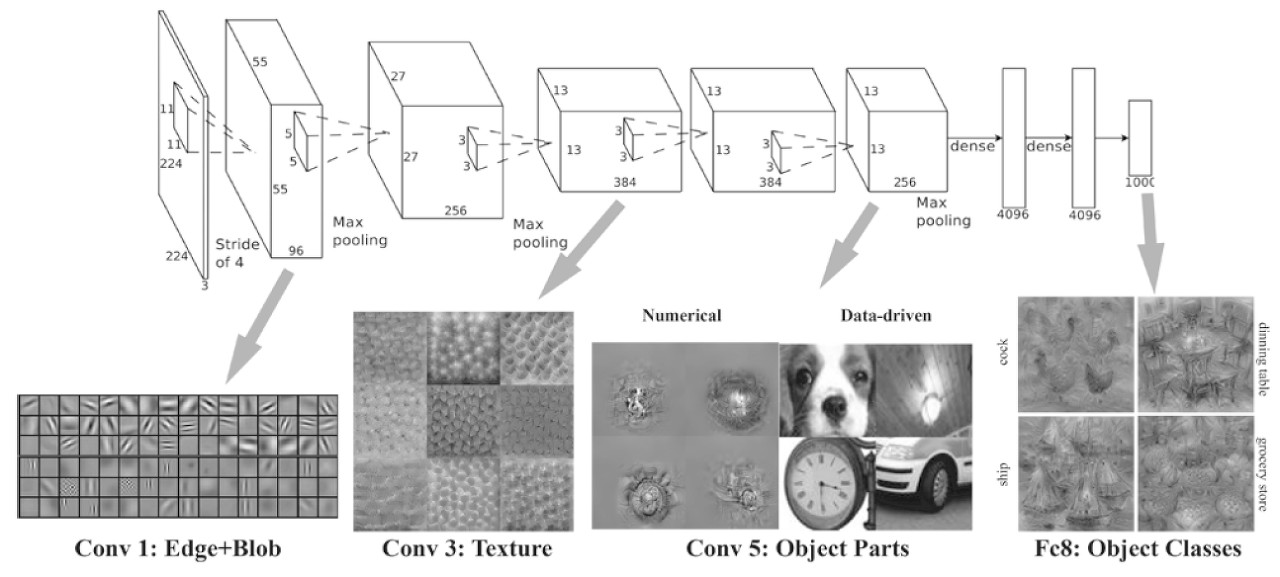
-
합성곱 계층을 여러 겹 쌓으면, 층이 깊어지면서 더 복잡하고
추상화된 정보가 추출된다. -
처음 층은
단순한 에지에 반응하고, 이어서텍스처에 반응하고, 더 복잡한사물의 일부에 반응하도록 변화한다. -
층이 깊어지면서 뉴런이 반응하는 대상이
단순한 모양에서고급 정보로 변화해간다.- 다시 말하면, 사물의 의미를 이해하도록 변화하는 것이다.
7.7 대표적인 CNN
- LeNet과 AlexNet
7.7.1 LeNet
LeNet은 손글씨 숫자를 인식하는 네트워크로,1998년에 제안되었다.
합성곱 계층과 풀링계층(정확히는 단순히 원소를 줄이기만 하는 서브샘플링 계층)을 반복하고, 마지막으로 완전연결 계층을 거치면서 결과 출력를 출력한다.
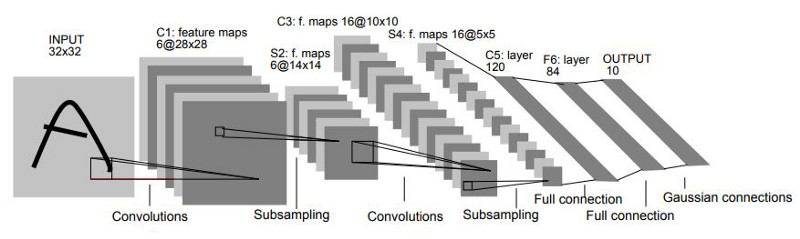
[LeNet과 현재 CNN 비교]
-
활성화 함수: LeNet(sigmoid) / 현재(ReLU) -
데이터 크기 줄이기: LeNet(서브샘플링, 중간데이터 크기 줄임) / 현재(MaxPooling)
7.7.2 AlexNet
2012년에 발표된 AlexNet은 딥러닝 열풍을 일으키는 데 큰 역할을 했다.
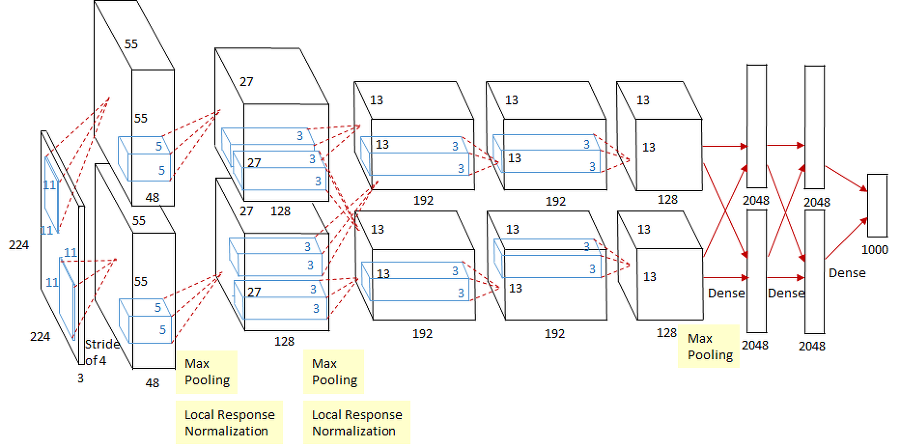
AlexNet은 합성곱 계층과 풀링 계층을 거듭하여 마지막으로 완전연결 계층을 거쳐 결과를 출력한다.
AlexNet에서는 다음과 같은 변화를 주었다.
- 활성화 함수로 ReLU를 이용한다
- LRN이라는 국소적 정규화를 실시하는 계층을 이용한다
- 드롭아웃을 사용한다
7.8 정리
- CNN은 지금까지의 완전연결 계층 네트워크에 합성곱 계층과 풀링 계층을 새로 추가한다.
- 합성곱 계층과 풀링 계층은
im2col (이미지를 행렬로 전개하는 함수)을 이용하면 간단하고 효율적으로 구현할 수 있다.- CNN을 시각화해보면 계층이 깊어질수록 고급 정보가 추출되는 모습을 확인할 수 있다.
- 대표적인 CNN에는 LeNet과 AlexNet이 있다.
- 딥러닝의 발전에는 빅데이터와 GPU가 크게 기여했다.
