
이미지출처
syntax 약속
본 포스팅은 KT 에이블스쿨 교육내용을 제 나름대로 정리하여 작성하였습니다.
머신러닝 vs 딥러닝
머신러닝이건 딥러닝이건 간에, 데이터를 이용해 예측을 하려 한다는 공통된 목적을 가지고 있다.
데이터를 통해 예측을 하기 위해서는 어떠한 요소가 예측하고 싶은 값에 얼마나 영향을 끼치는지 알아야 한다. 다양한 말로 부르지만 이 요소를 우리는 Feature 라고 한다.
데이터의 Feature 가 예측값에 끼치는 영향을 컴퓨터를 이용해 계산하는 행위가 머신러닝과 딥러닝이다.
머신러닝과 딥러닝은 Feature를 추출하는 행위에서 차이가 발생한다.
머신러닝은 예측을 용이하기 하기 위해 사람이 직접 Feature를 추출하는 행위를 한다. 이를 Feature engineering 이라고 한다.
딥러닝은 Feature를 추출하는 행위도 컴퓨터가 알아서 한다.
'와그럼 알아서 다 해주는 딥러닝이 머신러닝의 상위호환 아님? 개꿀 ㅋㅋ' 이라는 생각이 들 수도 있다.
하지만 아직은 컴퓨터의 Feature 추출이 인간의 통찰을 넘진 못했기에, 사람이 다룰 수 있을 정도의 숫자를 가진 Feature 들은 머신러닝으로 하는 것이 높은 정확도를 보이고 있다.
딥러닝은 자연어 처리, 객체인식 등 사람의 힘으로 Feature 의 특징을 다루기 힘든 분야에서 강점을 발휘하고 있다.
Keras란?
파이썬으로 작성되는 고급 신경망 API, 딥러닝에 이용됨. 본 포스팅은 Keras 를 이용하여 다룰 것이다.
딥러닝 과정
딥러닝 학습 절차
- 데이터 수집 및 전처리
- 모델 아키텍쳐 설계(dense, convolutional, 뉴런 수)
- 모델 컴파일 : 손실함수계산을 위한 평가메트릭, 옵티마이저 종류 설정
- 모델 학습
- 가중치 초기값 할당
- 예측
- 오차계산
- 가중치 조절(오차를 줄이는 방향으로, optimizer, 얼마만큼? learning_rate)
- 반복(epoch)
- 학습곡선
- 모델 평가
- 예측 밎 검증
머신러닝 프로세스와 딥러닝 프로세스 비교
| 머신러닝 | 딥러닝 | |
|---|---|---|
| 데이터 전처리 | 결측치 처리 가변수화 스케일링 (선택) | 결측치 처리 가변수화 스케일링 (필수) |
| 모델링 | 모델 선언 학습 예측 및 검증 | 모델구조 선언 및 컴파일 학습과 학습곡선 plot 예측 및 검증 |
모델선언부분에서 딥러닝은 신경망 구조 설계와 컴파일을 한다는 점과, 학습시 학습곡선을 이용해 모델의 학습을 관찰할 수 있다는 차이가 있다.
1. 환경준비
머신러닝에 필요한 각종 모듈을 import 해준다. 어떤 모듈인지는 주석참고
# 판다스와 넘파이 + 각종시각화
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 사이킷런, 데이터 전처리와 평가에 사용
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.preprocessing import MinMaxScaler
# 케라스
from keras.models import Sequential
from keras.layers import Dense
from keras.backend import clear_session
from keras.optimizers import Adam2. 데이터준비
머신러닝과 데이터 전처리과정이 같다. 딥러닝에서는 스케일링이 필수라는 것 정도?
링크참고
3. 모델설계
딥러닝 모델의 구조를 키워드만 나타내면 다음과 같다.
-
입력층 (Input Layer)
- 데이터 입력
- 특성 차원 정의
-
은닉층 (Hidden Layers)
-
완전 연결층 (Dense Layer)
- 뉴런 수 설정
- 활성화 함수 설정 (ReLU, Sigmoid 등)
-
합성곱층 (Convolutional Layer)
- 필터 수, 커널 크기 설정
- 패딩, 스트라이드 설정
- 활성화 함수 설정 (ReLU, Sigmoid 등)
-
순환층 (Recurrent Layer)
- 뉴런 수 설정
- 게이트 구조 설정 (LSTM, GRU 등)
-
드롭아웃층 (Dropout Layer)
- 드롭아웃 비율 설정
-
-
출력층 (Output Layer)
- 출력 뉴런 수 설정 (예측 클래스 수 또는 회귀 출력 수)
- 활성화 함수 설정 (Softmax, Sigmoid, Linear 등)
입력층과 은닉층과 출력층층만 기억하면 된다.
은닉층에서는 아마도 Dense Layer 만 다룰 예정이다.
도식화된 그림으로 나타내면 다음과 같다.
단일 레이어일 경우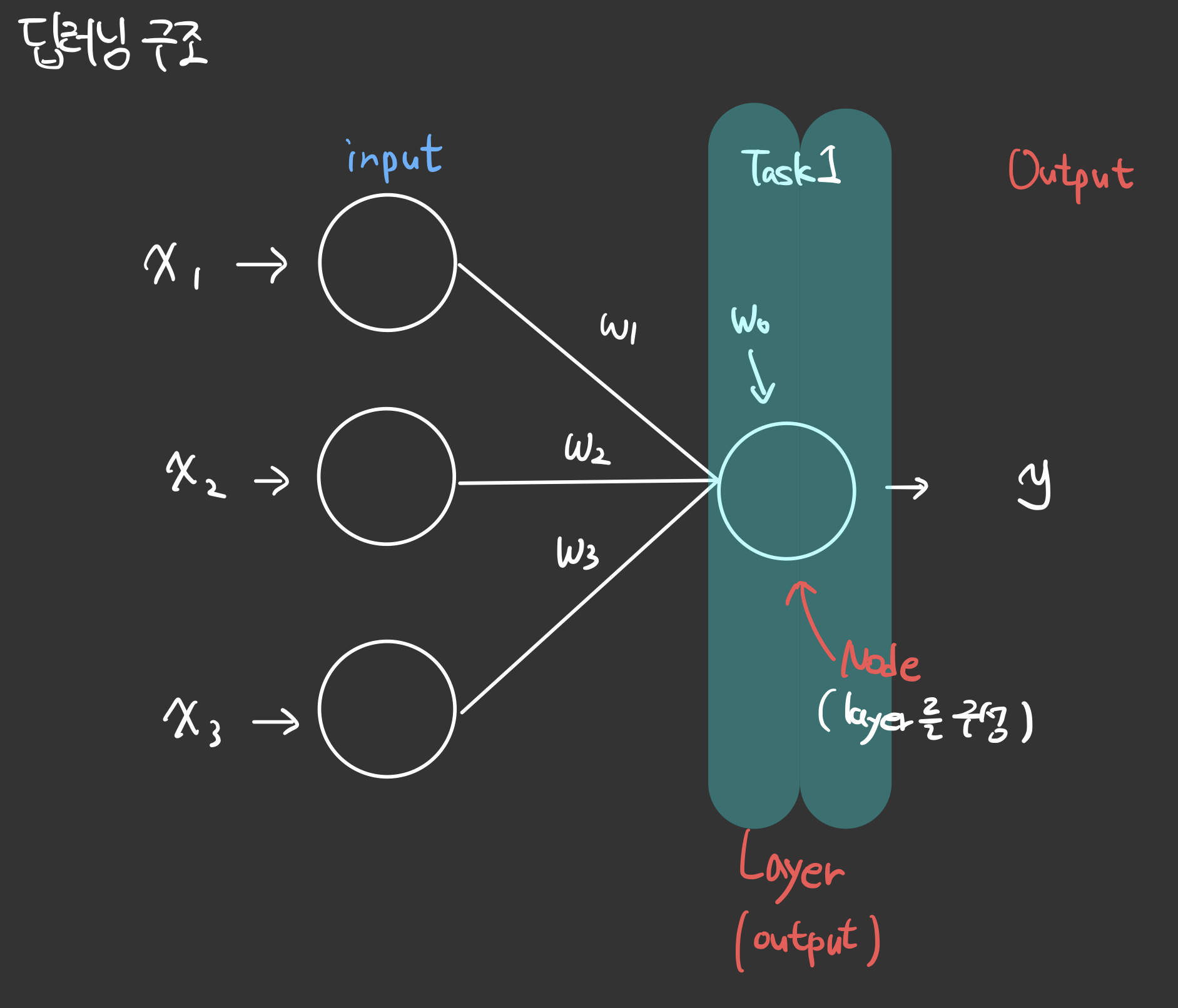
다중 레이어일 경우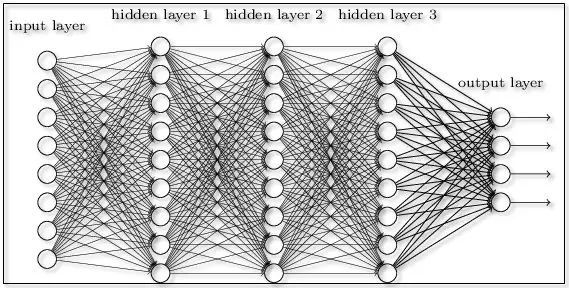
3. 1. feature 개수 추출
shape 속성을 이용한다. row 갯수와 column 갯수를 튜플로 반환시켜주므로, 1번 인덱스(2번째 값)을 적으면 column, 즉 feature 갯수를 추출할 수 있다.
nfeatures = x_train.shape[1]3. 2. 메모리정리 및 모델 선언
clear_session() 을 이용하여 메모리를 정리할 수 있다.
필수는 아니긴한데 안하면 summary할때마다 dense 번호가 계속 늘어남 ㄷㄷ;
시퀀셜타입으로 선언, 다른 타입은 나중에 다른 포스팅으로 정리할까 함
# 회귀, input output 만 있는 경우
model = Seaquential( Dense(1, input_shape=(nfeatures,)) )
# 회귀, hidden layer 있는 경우
model = Seaquential([Dense(1, input_shape=(nfeatures,), activation = 'relu'),
Dense(n, activation = 'relu'),
Dense(1)])
# 이진분류, input output 만 있는 경우
model = Sequential([ Dense(1, input_shape = (nfeatures,), activation = 'sigmoid') ])
# 이진분류, hidden layer 있는 경우
model = Sequential( [Dense(n, input_shape=(nfeatures,), activation='relu'),
Dense(n, activation='relu'),
Dense(n, activation='relu'),
Dense(1, activation='sigmoid')] )
# 다중분류, input ouput 만 있는 경우
model = Sequential([Dense( classnum_y, input_shape = (nfeatures,), activation = 'softmax'),])
# 다중분류, hidden layer 있는 경우
model = Sequential([Dense( n, input_shape = (nfeatures,), activation = 'relu'),
Dense( n, activation = 'relu' ),
Dense( classnum_y, activation = 'softmax')
])Dense Layer 를 구성하기 위해 사용되는 Dense() 에는 3가지의 매개변수가 들어갈 수 있다. hidden layer가 있는 경우 위의 경우처럼 list 로 나타낸다.
n : 출력으로 나오는 노드의 갯수, output layer의 갯수는 모델마다 다르다.
input_shape : input으로 들어가는 node(feature)의 수, 위의 예시는 1차원의 데이터이기 때문에 (n, ) 형식임을 유의하자.
activation : 활성함수 지정, 회귀인지 분류인지에 따라, input인지 output인지에 따라 활성함수가 다르며, 위 코드를 참고하자.
3. 3. 1. 활성함수
3. 3. 선언한 모델의 요약
model.summary() 로 모델의 요약을 볼 수 있다.
레이어와 다음 레이어의 아웃풋의 모양 그리고 파라미터 갯수로 구성되어 있다.
파라미터 갯수는 (input 레이어의 노드 수+1) * output 레이어의 노드 수 이다.
+1을 하는 이유는 bias(편향) 때문이다!
밑의 Summary 를 예시로 들어보자
12개의 node(feature)를 가진 데이터를 input layer으로 넣었고, output 노드의 갯수는 8개 이므로 13x8 = 104 개이다.
그다음, 아웃풋노드의 개수인 8개가 input 으로 들어가고 4개가 output 으로 나오므로 9x4 = 36 개 이다.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 8) 104
dense_1 (Dense) (None, 4) 36
dense_2 (Dense) (None, 1) 5
=================================================================
Total params: 145
Trainable params: 145
Non-trainable params: 0
_________________________________________________________________4. 컴파일
optimizer 에는 다양한 것들이 있지만 Adam 을 쓰는게 국룰이라나 뭐라나... 깊게 들어가지 않으려 한다.
#1
model.compile(optimizer='adam', loss='')
#2
model.compile(optimizer=Adam(learning_rate=0.1), loss='')두 가지 방식으로 표현할 수 있는데, #1 은 learning_rate가 0.001로 고정되어있는 상태이다.
loss : 오차함수를 설정하는 매개변수
회귀모델은 보통 'mse'로 하고
이진분류모델은 'binary_crossentropy' 를 사용한다.
learning_rate : 학습률을 설정할 수 있는 매개변수, lr로도 쓸 수 있지만 풀네임이 권장된다.
4. 1. 학습률(learning_rate)
모델 가중치의 업데이트 속도.
너무 크면 값에 수렴하기가 힘들고, 너무 작으면 수렴하기도 전에 학습이 끝나기도 한다.(많은 학습횟수를 요함) 맨날 같은 말해서 입이 아프지만... 적절한 값을 찾는 게 중요하다.

5. 학습
history = model.fit(x_train, y_train,epochs=20,validation_split=0.2).historyepochs : 전체 데이터에 대한 학습 횟수를 의미한다. 원가 엄밀하게 말하면 좀 다른가 본데, 나중가면 좀 더 자세히 다루지 싶다.
validation_split : tain에서 검증용 데이터를 분리할 수 있는 비율이다. 미리 검증용으로 분리한 데이터 말고 따로 검증을 할 수 있는 샘이다.
history : 가중치가 업데이터 될 때 마다(epoch)가 늘어날 때 마다 오차를 기록한다.
다음과 같은 함수를 작성하여 학습곡선을 plot 할 수 있다.
def dl_history_plot(history):
plt.figure(figsize=(10,6))
plt.plot(history['loss'], label='train_err', marker = '.')
plt.plot(history['val_loss'], label='val_err', marker = '.')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
plt.show()
dl_history_plot(history)5. 1. 학습 곡선(learning curve)
바람직한 학습 곡선의 특징(지피티야 고맙다~)
-
수렴: 훈련 및 검증 손실은 시간이 지남에 따라 감소하여 결국 안정적인 값에 도달하거나 수렴해야 합니다. 이는 모델이 데이터에서 학습하고 손실 함수를 최소화하고 있음을 나타냅니다.
-
과적합 없음: 훈련 손실과 검증 손실 사이의 간격이 상대적으로 작아야 합니다. 훈련 손실이 검증 손실보다 훨씬 작은 경우 모델이 훈련 데이터에 과적합되어 있음을 나타냅니다. 즉, 훈련 세트의 노이즈 또는 특정 패턴을 학습했지만 보이지 않는 데이터에 잘 일반화되지 않는다는 의미입니다.
-
과소적합 없음: 교육 및 검증 손실이 모두 합리적으로 낮아야 합니다. 손실이 높으면 모델이 데이터를 잘 맞추지 못하고 데이터의 기본 패턴을 캡처할 수 없어 성능이 저하됨을 나타냅니다.
-
꾸준한 개선: 이상적으로 학습 곡선은 시간이 지남에 따라, 특히 초기 에포크 동안 꾸준한 성능 향상(손실 감소)을 보여야 합니다. 이는 모델이 데이터에서 효과적으로 학습하고 있음을 나타냅니다.
-
Plateau: 특정 수의 에포크 후에 유효성 검사 손실이 정체되어 더 이상 크게 개선되지 않을 수 있습니다. 이는 모델이 데이터에서 가능한 한 많은 것을 배웠다는 표시일 수 있으며 추가 교육으로 인해 상당한 개선이 이루어지지 않을 수 있습니다.
6. 예측및검증
회귀모델
pred2 = model2.predict(x_val)
print(f'RMSE : {mean_squared_error(y_val, pred2, squared=False)}')
print(f'MAE : {mean_absolute_error(y_val, pred2)}')
print(f'MAPE : {mean_absolute_percentage_error(y_val, pred2)}')이진분류 모델 예측 및 검증
pred = model.predict(x_val)
pred = np.where(pred>= 0.5, 1, 0)
print(confusion_matrix(y_val, pred))
print('-'*50)
print(classification_report(y_val, pred))7/7 [==============================] - 0s 2ms/step
[[155 14]
[ 10 21]]
--------------------------------------------------
precision recall f1-score support
0 0.94 0.92 0.93 169
1 0.60 0.68 0.64 31
accuracy 0.88 200
macro avg 0.77 0.80 0.78 200
weighted avg 0.89 0.88 0.88 2000과 1로 분류를 위해 np.where를 통해 0.5 이상인 값은 1 미만이면 0 으로 나누는 과정을 거쳐야 한다.
