Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
✍ 핵심
어떤 테스크를 수행하는 Neural Network가 주어질 때, 모델 결과의 퀄리티와 학습 속도를 개선시켜주는 input embedding 방법론으로 Multiresolution hash encoding을 제시한다. 이는 기존의 input embedding들에 비해 적응성이 뛰어나고 효과적이며 테스크에 구애받지 않는다.
🔒 Prerequisites
필수는 아니지만 NeRF, Neural Sparse Voxel fields, ACORN등 Instant ngp 이전 논문들이 input embedding을 어떻게 했는지를 알면 해당 논문의 contribution을 더 잘 이해할 수 있다.
🤔 Motivation
Computer graphics primitives(mesh, sphere, SDF등)은 근본적으로 수학적인 함수로 표현이 되는데, 최근 딥러닝의 발전으로 MLP를 Neural graphics primitives로 이용하는 방법론들이 많이 소개 되고 있다. 이에 해당하는 대부분의 논문들은 NN의 input을 고차원 공간에 mapping 시켜 NN을 압축시킴과 동시에 성능을 향상시킨다. 이 중 가장 성공적인 방법론들은 해당 테스크에 알맞는 데이터 구조를 이용하여 encoding을 하는데 이는 pruning, merging등 heuristic한 조정과 복잡한 학습 과정을 동반하여 특정 테스크에서만 사용가능하며 GPU의 성능을 제한한다.
이에 저자 들은
-
적응성이 뛰어나고
- 학습중 구조 조정 X
-
효과적이며
- hash table look up :
- (GPU와 알맞지 않는)pointer chasing X
-
특정 task에 국한되지 않는
- Gigapixel image, SDF, NRC, NeRF etc
Multiresolution hash encoding을 제안한다.
🧾 Related Work
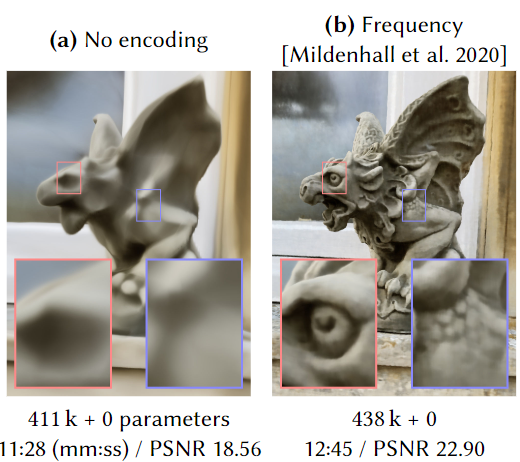
1. Frequency Encodings
[Vaswani et al. 2017]에서 소개된 스칼라 포지션 을 개의 sine, cosine 으로 이루어진 multiresolution sequence함수로 encoding하는 방법이다.
NeRF 논문에서도 이런 frequency encoding을 사용하여 더 선명한 이미지를 얻는다.
2. Parametric Encodings
Pakrametric encoding은 추가적인 학습가능한 parameter들을 보조적인 데이터 구조에 넣어 input vector에 따라 해당 parameter들을 look-up 하고 interpolate하는 encoding 방법이다.
MLP의 parameter들은 parameter가 늘어남에 따라 메모리보단 computational cost가 기하 급수적으로 증가하지만, parametric encoding의 parameter들은 MLP의 parameter들에 비해 compuational cost가 훨씬 덜 든다.
This arrangement trades a larger memory footprint for a smaller computational cost
이에 parametric encoding을 사용하면 (frequency encoding에 비해) MLP의 사이즈를 줄이며 생기는 퀄리티 손상을 방지하며 MLP를 빠르게 학습이 가능하다.
2-1. Coordinate Encoding
ACORN(Adaptive Coordinate Networks for Neural Scene Representation)[Martel er al.2021]에서는 큰 auxiliary coordinate encoder을 사용하여 dense feature grid를 구하고 interpolation을 한 값을 MLP에 input한다.
이는 다른 parametric encoding에 비해 적응성이 뛰어나지만 computational cost가 매우 크다는 단점이 있다.
2-2. Dense Grid
Dense Grid를 auxiliary data structure로 사용하여 parametric encoding을 하는 경우 Frecuency encoding에 비해 적은 MLP의 parameter와 적은 시간내에 좋은 결과를 얻을 수 있다. 뿐만 아니라 multi resolution dense grid를 사용할 경우 더 적은 parameter개수로 더 좋은 결과를 얻을 수 있는데, 중요도가 높은 표면 부분 외에 빈공간에도 같은 개수의 parameter를 배정하기 때문에 비효과적이다.

2-3. Sparse Grid
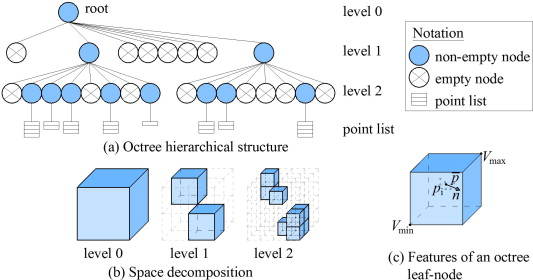
만약 특정 task에서 중요도가 높은 부분을 선험적으로 알고 있다면 octree혹은 sparse grid를 사용하여 dense grid의 필요 없는 부분을 제외하여 연산량과 메모리양을 줄일 수 있다.
그러나 NeRF의 경우 중요도가 높은 표면 부분이 학습 도중에만 나오기 때문에 이를 활용할 수 없다.
이에 NSVF등 논문에선 fine to coarse전략을 통해 feature grid를 점진적으로 정제해 나간다.
그러나 이는 주기적으로 데이터 구조를 업데이트를 해야하는 복잡한 학습 방식을 요구한다.
📌 Main Methods
Multiresolution Hash Encoding
Multiresolution Hash Encoding의 절차를 먼저 살펴보고 각각의 중요한 component들을 짚어보자.
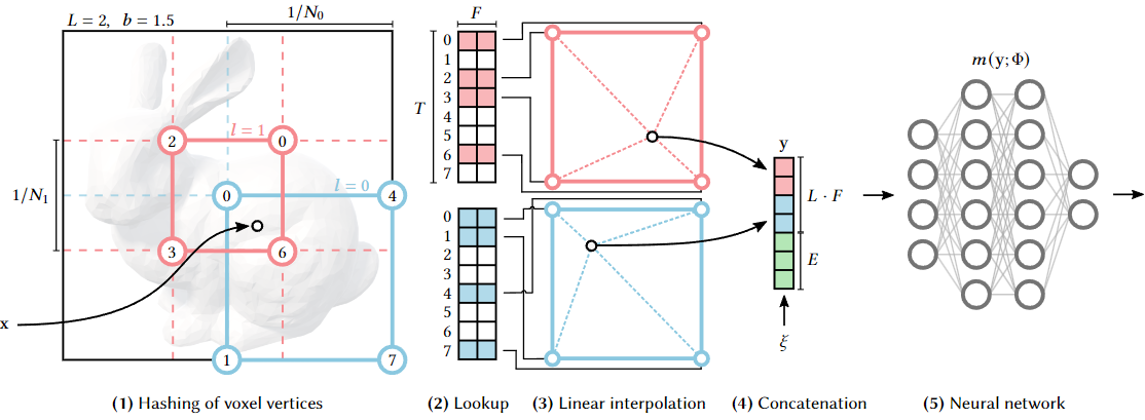
절차
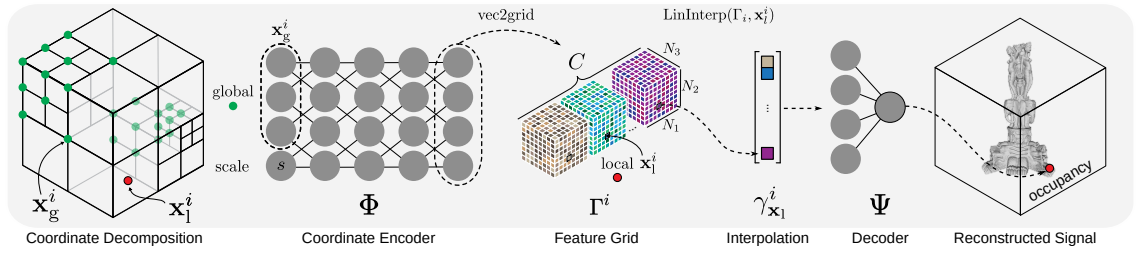
1. L개의 d 차원 grid를 정의한다.
각각의 grid는 한 Level이고 의 resolution을 갖으며, 차원수 는 task에 따라 달라진다.(Gigapixel : 2D, NeRF : 3D)
2. 각각의 level을 F차원의 T개의 feature vector에 지정한다.
F와 T는 Hyperparameter이며 performance와 quality의 tradeoff가 존재한다
3. Input coordinates가 voxel들로 mapping된다.
4. Mapping된 Voxel의 꼭짓점(Vertices)들이 feature vector로 mapping된다.
이때, 만약 특정 level의 총 꼭짓점의 개수가() 차원 feature vector의 개수 보다 작으면() 1:1 mapping이 되지만 크면() spatial hash function을 사용하여 mapping.
5. D차원 linear Interpolation을 진행한다.
Interpolation을 하지 않으면 discrete해지기 때문에 interpolation을 통해 연속성을 보장한다()
6. Interpolate된 각 level의 vector들을 auxiliary input과 함께 concatenate한다.
e.g encoded view direction, textures etc
7. MLP에 input한다.
각각 Level의 Resolution 성정
를 정한 뒤, 이 사이의 geometric progression으로 중간 level resolution()을 구한다.
b는 대체적으로 이다.
Performance VS Quality
가 증가할 수록 메모리는 선형적으로 증가하지만 성능은 준선형적으로 증가하기 때문에 적당한 값을 정하는게 중요하다.
저자들은 다음과 같은 hyperparameter 값들을 사용했다.
| Parameter | Symbol | Value |
|---|---|---|
| Number of levels | 16 | |
| Max. entries per level(hash table size) | ||
| Number of feature dimensions per entry | 2 | |
| Coarest resolution | 16 | |
| Finest resolution | 512~524288 |
NN을 이용한 hash collision resolution
- 낮은 level
- Low resolution 해당 level의 총 꼭짓점의 개수가 보다 작음()
- 1:1 mapping
- 높은 level
- High resolution 해당 level의 총 꼭짓점의 개수가 보다 큼()
- Spatial hash function을 이용하여 mapping
- Collision이 일어날땐 gradient를 average함
높은 resolution을 가지는 level들은 해쉬 함수를 이용하여 mapping을 하게 되는데 서로 다른 꼭짓점이 한개의 feature vector에 mapping되는 hash collision이 발생하게 된다. Instant NGP에서는 이를 explicit하게 해결하기 보단 implicit하게 뒤따라 오는 Neural Network가 해결하기를 유도한다.
Collision이 일어날 때 gradient를 average하게 되면 학습 도중 중요도가 높은 표면이 큰 gradient를 갖게 되므로 adaptivity가 생긴다
As a result, the gradients of the more important samples dominate the collision average and the aliased table entry will naturally be optimized in such a way that it reflects the needs of the higher-weighted point.
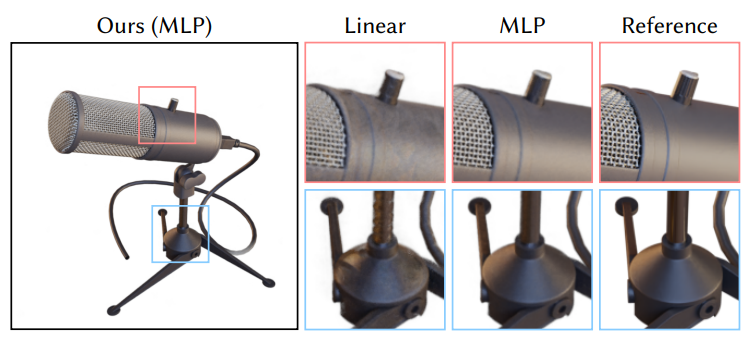
📑평가
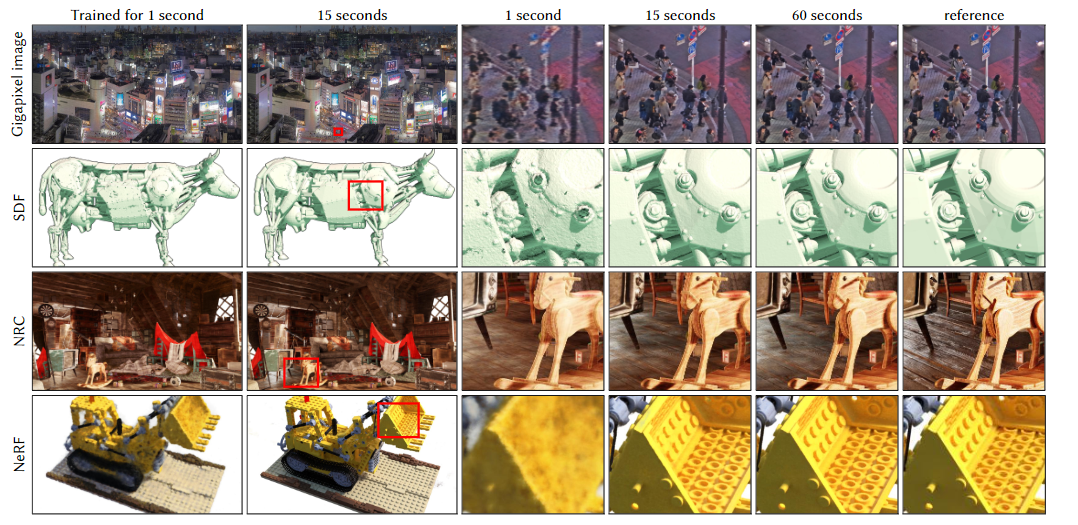
저자들은 Gigapixel image approximation task, SDF function task, NRC 그리고 NeRF에 대해 평가를 진행하는데 여기선 NeRF에 대한 결과만 살펴보자.
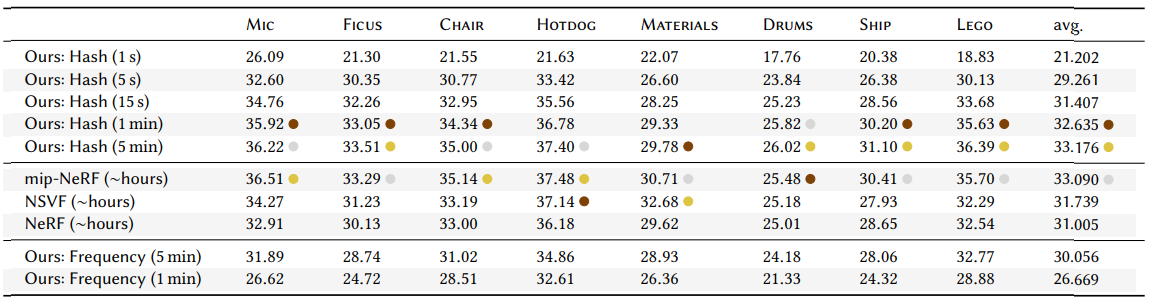
Multiresolution hash incoding을 사용하면 눈에 띄게 training 시간이 빨라진 것을 확인 할 수 있다. 속도가 매우 빨라졌지만 quality가 몇 시간씩 학습한 타 모델에 비해 전혀 뒤쳐지지 않고 대부분의 경우에 1등 혹은 2등 quality를 달생한 것을 확인 할 수 있다.
👻개인적인 의견
Encoding방법론 하나로 거의 모든 implicit representation task의 속도를 몇 배씩 가속한 건 매우 놀랍다...project page에 들어가 보면 학습하는 과정을 다른 모델들과 비교해 주는 데 타 모델들에 비해 터무니 없이 빠르다. 그러나 논문에서도 언급하듯이 hash function을 사용하는 이상 hash collision은 필연적이다. 때문에 결과에 미세한 artifacts가 생기게 되는데 이는 hash function을 사용하는 한 해결할 수 없는 문제이기 때문에 완벽한 퀄리티를 얻어야 하는 상황에서는 타 모델들이 더 유용할 것 같다는 생각이 들었다. 그러나 속도와 퀄리티의 tradeoff애서 퀄리티를 유지하며 속도를 20배, 30배씩 늘린 것은 정말 매우 놀랍다.
22.12.26 추가
Instant ngp의 한계점
[-] spatial coordinate feature 의 mapping이 랜덤이다(hash function)
이는 생각보다 많은 단점의 원인이 된다.
1. 필연적인 hash collision
microstructure artifacts
2. No spatial locality of features
다른 method들은 feature들을 coordinate space와 관련된 data structure에다 저장하여 feature들을 활용하기 용이하다.
3. Requires Bigger Codebook
Mapping을 잘하면 codebook이 작아도 준하는 성능을 보일 것
(Variable bitrate neural fields)
참고문헌
Müller et al. 2022
Instant NGP
