CycleGAN
Image-to-Image Translation은 pair 형태의 train 이미지(ex. 흑백 - 컬러)를 이용해 input 이미지와 output 이미지를 매핑하는 것을 목표로 한다.
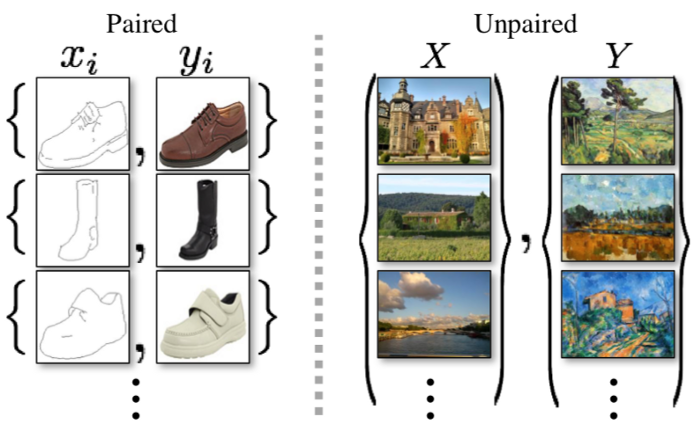
하지만 많은 task에 있어서 pair 형태의 train 데이터를 얻는 것은 어렵다. CycleGAN은 pair 형태의 이미지가 아니더라도, 도메인 X의 이미지를 타겟 도메인 Y로 바꾸는 방법을 제안한다. 따라서 앱 v2v의 "사용자의 사진을 고흐 또는 에곤실레가 그린 그림처럼 바꿔주는"기능을 제공하기 위해 CycleGAN 모델을 사용하였다.
데이터 준비
데이터는 크롤링 과정을 거쳐 다음과 같이 준비하였다.

고흐 그림 이미지 - 230장
풍경 이미지 - 230장
에곤 실레 그림 이미지 - 460장
사람 이미지 - 460장
위에서 말했던 것처럼 train 이미지는 pair 형태의 이미지가 아니다.
CycleGAN 구현
GitHub: https://github.com/LIMDANBI/v2v-model
1. library import
우선 필요한 라이브러리들을 import해주었다.
import os
import tqdm
import time
import random
import itertools
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torch # batch_size channel width height
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision.utils import save_image, make_grid2. GPU 확인
다음과 같이 했을 때 'cuda'가 출력되면 GPU 설정이 잘 된 것이다!
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)3. SEED 값 고정
실행마다 동일한 환경을 마련해주기 위해 seed 값을 고정해주었다.
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)
torch.backends.cudnn.deterministic = True4. Custom Dataset
이미지 데이터를 전처리하고, dataloader를 만들 때 이용할 ImageDataset class를 만들어주었다. 이미지 데이터 전처리로는
Resize(): 이미지 사이즈 조정
RandomCrop(): 256*256 이미지로 자르기
RandomHorizontalFlip(): 50% 확률로 좌우반전
ToTensor(): 0~1 사이 값을 가지는 텐서로 변환
Normalize(): 정규화
과정을 거쳐주었다.
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, A_dir, B_dir, img_size=256):
self.A_dir = photo_dir
self.B_dir = gogh_dir
self.A_imgs = [filename for filename in os.listdir(A_dir) if os.path.splitext(filename)[-1] in ('.jpg', '.png') ]
self.B_imgs = [filename for filename in os.listdir(B_dir) if os.path.splitext(filename)[-1] in ('.jpg', '.png') ]
self.transform = [ torchvision.transforms.Resize(int(img_size*1.15), Image.BICUBIC), # 이미지 크기를 조금 키우기
torchvision.transforms.RandomCrop(img_size),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(), # [0 - 255] --> [0 - 1.0]
torchvision.transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
self.transform = torchvision.transforms.Compose(self.transform)
def __getitem__(self, index):
A_img = self.transform(Image.open(os.path.join(self.A_dir,
self.A_imgs[index % len(self.A_imgs)])).convert('RGB'))
B_img = self.transform(Image.open(os.path.join(self.B_dir,
self.B_imgs[random.randint(0, len(self.B_imgs) - 1)])).convert('RGB')) # 랜덤 샘플링
return A_img, B_img
def __len__(self):
return max(len(self.A_dir), len(self.B_dir))5. Dataloader
앞서 정의해둔 ImageDataset을 이용하여 학습 시 사용할 dataloader를 만들어주었다.
photo_dir = '../data/scenary/' # 풍경 이미지
gogh_dir = '../data/gogh/' # 고흐 그림 이미지
train_dataset = ImageDataset(photo_dir, gogh_dir)
valid_dataset = ImageDataset(photo_dir, gogh_dir)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(valid_dataset, batch_size=4, shuffle=True)6. Residual Block
Generator 구조를 이룰 ResidualBlock이다. 대표적으로 U-Net과 ResNet구조를 사용해보았을 때 ResNet이 depth도 있고, bottleneck이 없어서 detail을 간직할 수 있다고 한다. (U-Net의 경우 두 데이터 셋이 어느 정도 비슷한 경우 skip connection이 많이 사용되어 depth가 거의 적용되지 않는다고 한다.)
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
# 채널(channel) 크기는 그대로 유지
self.block = nn.Sequential(
nn.ReflectionPad2d(1), # Pads the input tensor using the reflection of the input boundary
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
)
def forward(self, x):
return x + self.block(x)7. Generator (G)
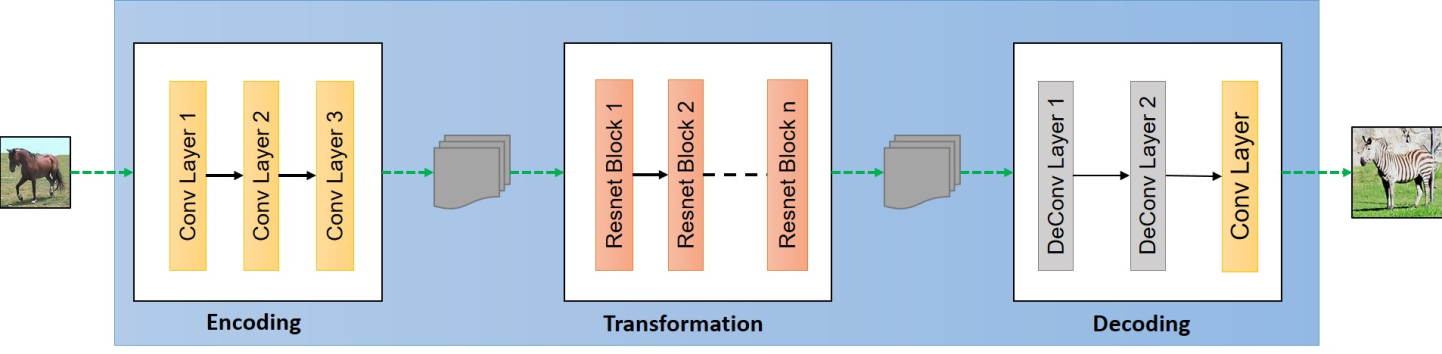
앞서 정의한 ResidualBlock을 이용한 Generator model 코드이다. Downsampling과 Upsampling과정을 거쳐 새로운 이미지를 생성한다.
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0] # 입력 이미지의 채널 수: 3
# 초기 Convolution layer
out_channels = 64
model = [nn.ReflectionPad2d(channels)]
model.append(nn.Conv2d(channels, out_channels, kernel_size=7))
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ReLU(inplace=True))
in_channels = out_channels
# Downsampling
for _ in range(2):
out_channels *= 2
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)) # 너비와 높이가 2배씩 감소
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ReLU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 감소한 높이) X (4배 감소한 너비)]
# 인코더와 디코더의 중간에서 Residual Blocks 사용 (차원 유지)
for _ in range(num_residual_blocks):
model.append(ResidualBlock(out_channels))
# Upsampling
for _ in range(2):
out_channels //= 2
model.append(nn.Upsample(scale_factor=2)) # 너비와 높이가 2배씩 증가
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)) # 너비와 높이는 그대로
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ReLU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 증가한 높이) X (4배 증가한 너비)]
# 출력 Convolution Block layer
model.append(nn.ReflectionPad2d(channels))
model.append(nn.Conv2d(out_channels, channels, kernel_size=7))
model.append(nn.Tanh())
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)8. Discriminator (D)
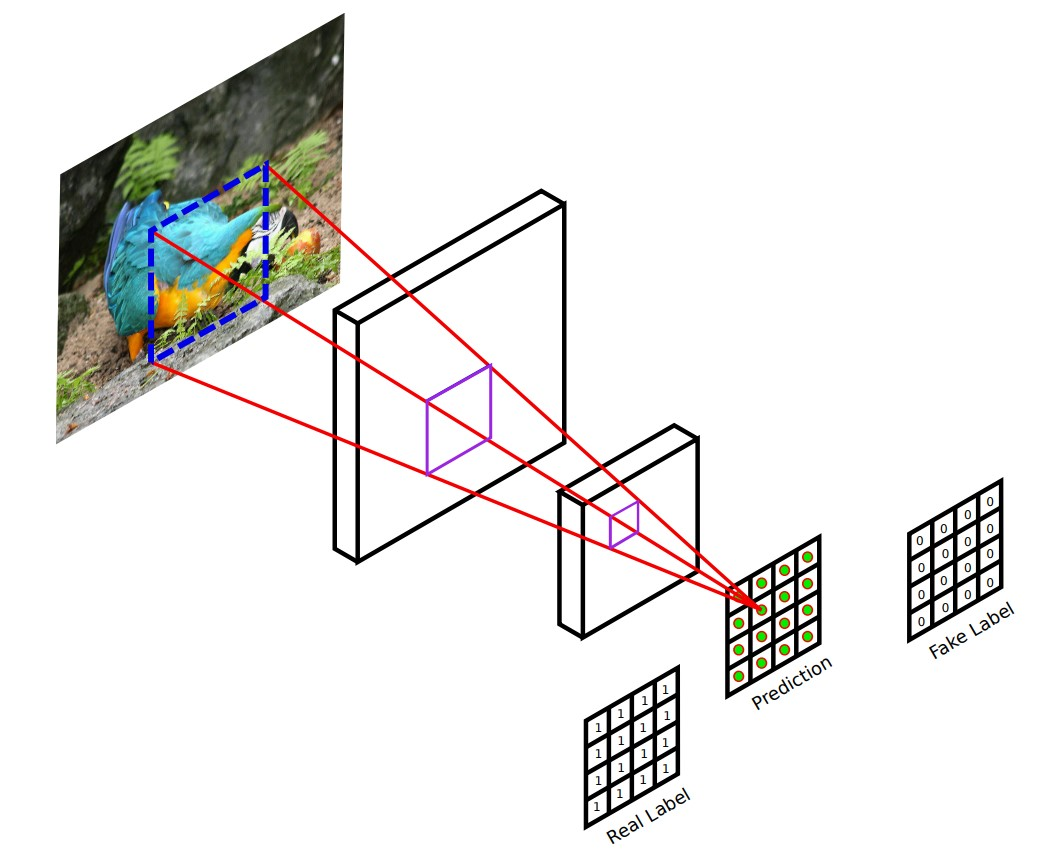
이미지가 진짜 이미지인지 Generator가 생성한 가짜 이미지인지 판별하는 Discriminator model 코드이다. (CycleGAN의 Discriminator는 PatchGAN을 이용한다. PatchGAN은 이미지의 전체 영역이 아닌 특정 크기의 patch 단위로 Generator가 생성한 이미지가 진짜인지 가짜인지 판단한다.)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Convolution Block
def discriminator_block(in_channels, out_channels, normalize=True):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1)] # 너비와 높이가 2배씩 감소
if normalize:
layers.append(nn.InstanceNorm2d(out_channels))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False), # 출력: [64 X 128 X 128]
*discriminator_block(64, 128), # 출력: [128 X 64 X 64]
*discriminator_block(128, 256), # 출력: [256 X 32 X 32]
*discriminator_block(256, 512), # 출력: [512 X 16 X 16]
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 3, kernel_size=4, padding=1) # 출력: [3 X 16 X 16]
)
# 최종 출력: [3 X (16배 감소한 높이) X (16배 감소한 너비)]
def forward(self, img):
return self.model(img)9. Replay Buffer
학습 시 모델의 불안정성을 개선하기 위해 Replay Buffer를 이용했다. 이전에 Generator가 생성했던 결과물을 주기적으로 다시 보여주며 학습시킴으로서 불안정성을 개선할 수 있다.
class ReplayBuffer:
def __init__(self, max_size=50):
self.max_size = max_size
self.data = []
# 새로운 이미지를 삽입하고, 이전에 삽입되었던 이미지를 반환하는 함수
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
# 아직 버퍼가 가득 차지 않았다면, 현재 삽입된 데이터를 반환
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
# 버퍼가 가득 찼다면, 이전에 삽입되었던 이미지를 랜덤하게 반환
else:
if random.uniform(0, 1) > 0.5: # 확률은 50%
i = random.randint(0, self.max_size - 1)
to_return.append(self.data[i].clone())
self.data[i] = element # 버퍼에 들어 있는 이미지 교체
else:
to_return.append(element)
return torch.cat(to_return)10. Learning Rate 조정
학습이 진행됨에 따라 learning rate를 점점 감소시켜주는 코드이다.
class LambdaLR:
def __init__(self, n_epochs, decay_start_epoch):
self.n_epochs = n_epochs # 전체 epoch
self.decay_start_epoch = decay_start_epoch # 학습률 감소가 시작되는 epoch
def step(self, epoch):
return 1.0 - max(0, epoch - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)11. 가중치 초기화
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)12. Generator와 Discriminator 초기화
Generator와 Discriminator model을 선언하고, 가중치를 초기화해준다.
# 생성자(generator)와 판별자(discriminator) 초기화
G_AB = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
G_BA = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
D_A = Discriminator(input_shape=(3, 256, 256))
D_B = Discriminator(input_shape=(3, 256, 256))
# gpu 설정
G_AB.cuda()
G_BA.cuda()
D_A.cuda()
D_B.cuda()
# 가중치(weights) 초기화
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)13. Loss Function
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()14. 파라미터 설정
n_epochs = 200 # 학습의 횟수(epoch) 설정
decay_epoch = 100
lr = 0.0002 # 학습률(learning rate) 설정
sample_interval = 50 # 몇 번의 배치(batch)마다 결과를 출력할 것인지 설정
lambda_cycle = 10 # Cycle 손실 가중치(weight) 파라미터
lambda_identity = 5 # Identity 손실 가중치(weight) 파라미터15. optimizer
optimizer_G = torch.optim.Adam(itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(0.5, 0.999))16. 학습률(learning rate) 업데이트 스케줄러 초기화
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)17. Train
# 이전에 생성된 이미지 데이터를 포함하고 있는 버퍼(buffer) 객체
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
start_time = time.time()
for epoch in range(n_epochs):
for i, batch in enumerate(train_loader):
# 모델의 입력(input) 데이터 불러오기
real_A, real_B = batch
real_A = real_A.cuda()
real_B = real_B.cuda()
# 진짜(real) 이미지와 가짜(fake) 이미지에 대한 정답 레이블 생성 (너바와 높이를 16씩 나눈 크기)
real = torch.cuda.FloatTensor(real_A.size(0), 1, 16, 16).fill_(1.0) # 진짜(real): 1
fake = torch.cuda.FloatTensor(real_A.size(0), 1, 16, 16).fill_(0.0) # 가짜(fake): 0
""" 생성자(generator)를 학습 """
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity 손실(loss) 값 계산
loss_identity_A = criterion_identity(G_BA(real_A), real_A)
loss_identity_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_identity_A + loss_identity_B) / 2
# GAN 손실(loss) 값 계산
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
loss_GAN_AB = criterion_GAN(D_B(fake_B), real)
loss_GAN_BA = criterion_GAN(D_A(fake_A), real)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle 손실(loss) 값 계산
recover_A = G_BA(fake_B)
recover_B = G_AB(fake_A)
loss_cycle_A = criterion_cycle(recover_A, real_A)
loss_cycle_B = criterion_cycle(recover_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# 최종적인 손실(loss)
loss_G = loss_GAN + lambda_cycle * loss_cycle + lambda_identity * loss_identity
# 생성자(generator) 업데이트
loss_G.backward()
optimizer_G.step()
""" 판별자(discriminator) A를 학습 """
optimizer_D_A.zero_grad()
# Real 손실(loss): 원본 이미지를 원본으로 판별하도록
loss_real = criterion_GAN(D_A(real_A), real)
# Fake 손실(loss): 가짜 이미지를 가짜로 판별하도록
fake_A_ = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
# 최종적인 손실(loss)
loss_D_A = (loss_real + loss_fake) / 2
# 판별자(discriminator) 업데이트
loss_D_A.backward()
optimizer_D_A.step()
""" 판별자(discriminator) B를 학습 """
optimizer_D_B.zero_grad()
# Real 손실(loss): 원본 이미지를 원본으로 판별하도록
loss_real = criterion_GAN(D_B(real_B), real)
# Fake 손실(loss): 가짜 이미지를 가짜로 판별하도록
fake_B_ = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B_.detach()), fake)
# 최종적인 손실(loss)
loss_D_B = (loss_real + loss_fake) / 2
# 판별자(discriminator) 업데이트
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
done = epoch * len(train_loader) + i
if done % sample_interval == 0:
G_AB.eval()
G_BA.eval()
imgs = next(iter(val_loader)) # 5개의 이미지를 추출해 생성
real_A, real_B = batch
real_A = real_A.cuda()
real_B = real_B.cuda()
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
# X축을 따라 각각의 그리디 이미지 생성
real_A = make_grid(real_A, nrow=4, normalize=True)
real_B = make_grid(real_B, nrow=4, normalize=True)
fake_A = make_grid(fake_A, nrow=4, normalize=True)
fake_B = make_grid(fake_B, nrow=4, normalize=True)
# 각각의 격자 이미지를 높이(height)를 기준으로 연결하기
image_grid = torch.cat((real_A, fake_B, real_B, fake_A), 1)
save_image(image_grid, f"./generate_gogh/{done}.png", normalize=False)
print(f"[Done {i}/{len(train_loader)}] [Elapsed time: {time.time() - start_time:.2f}s]")
# 학습률(learning rate)
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
# 하나의 epoch이 끝날 때마다 로그(log) 출력
print(f"[Epoch {epoch}/{n_epochs}] [D loss: {loss_D.item():.6f}] [G identity loss: {loss_identity.item():.6f}, adv loss: {loss_GAN.item()}, cycle loss: {loss_cycle.item()}] [Elapsed time: {time.time() - start_time:.2f}s]")
# 하나의 epoch이 끝날 때마다 모델 파라미터 저장
torch.save(G_AB.state_dict(), "G_AB_gogh.pt")
torch.save(G_BA.state_dict(), "G_BA_gogh.pt")
print("Model saved!")