Train
이제 만들어 둔 csv 파일과 (이미지 경로 + label) 작성한 VGG Extractor 모델을 이용하여 학습을 시켜 보자!
필요한 library 선언
우선 만들어 둔 것을 custom dataset, model 등을 포함해서 필요한 library를 선언해 주었다.
import os
import torch
import torchsummary
from torch import nn
from torch import optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
from model.vgg import VGG
from custom_dataset import path_to_img파라미터 설정
다음으로는 모델 학습 시 사용할 파라미터들을 선언해주었다!
if __name__ == '__main__': # 인터프리터에서 직접 실행했을 경우에만 if문 내의 코드를 돌리라는 의미
# 전체 데이터를 몇 번이나 볼 것인지
start_epoch = 1
epoch_num = 10
# 학습 시 한번에 몇 개의 데이터를 볼 것인지
batch_size = 256
# 검증 데이터 비율
val_percent = 0.05
# 학습률
lr = 0.001
# 이미지 크기 조정
img_size = 32
# validation loss가 가장 좋은 model을 저장
min_loss = 0
# 학습 그래프 그릴 때 사용
train_loss_list = []
val_loss_list = []
gpu 설정
학교에서 제공해 주는 gpu 서버를 사용했다!!
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device) # 잘 설정 되었는지 확인! cuda가 출려되면 잘 설정 된 것
print()모델 선언
만들어 둔 vgg 모델을 선언해주었다. 이때 gpu 서버를 사용하기 때문에 model.to(device) 도 함께 선언해준다.
model = VGG(input_channel=3, num_class=2350) # 한글 완성형
model.to(device)
torchsummary.summary(model, (3, img_size, img_size)) # model 정보
print()최적화 기법 및 손실 함수
optimizer로는 Adam을 loss 함수로는 CrossEntropyLoss()를 사용했다.
optimizer = optim.Adam(params=model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss() # 다중 분류 (nn.LogSoftmax + nn.NLLLoss)
이미지 변형
들어오는 학습 이미지를 다음과 같이 transforms을 이용하여 모델 input size에 맞춰주고 tensor로 변형 시켜 주어야 한다!
transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.ToTensor()
])학습 테스트 데이터 분할
먼저 이미지와 레이블을 각각 저장해주고 train_test_split()을 이용하여 train data와 valid data를 분리해주었다.
train_data = pd.read_csv('./data/hangeul_2350.csv')
print('data size is', len(train_data))
print()
train_X = train_data['img_path'] # img_path
train_y = train_data['label'] # label
train_X, val_X, train_y, val_y = train_test_split(train_X, train_y, test_size=val_percent)
train_datasets = path_to_img(img_path=train_X, labels=train_y, transform=transform)
valid_datasets = path_to_img(img_path=val_X, labels=val_y, transform=transform)Data Loader
학습 시 편의를 위해 train dataset과 valid dataset을 데이터로더 형태로 만들어준다.
train_loader = DataLoader(dataset=train_datasets, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_datasets, batch_size=batch_size)train
train part이다. 만들어 둔 Train Data Loader에서 이미지와 label을 받아와서 model에 넣어 학습을 진행했다. train 진행 전에 model.train()을 선언해 주었다.
for epoch in range(start_epoch, epoch_num+1): # 에폭 한 번마다 전체 데이터를 봄
print('[epoch %d]' % epoch)
train_loss = 0.0
train_acc = 0.0
train_total = 0
valid_loss = 0.0
valid_acc = 0.0
valid_total = 0
# 학습
model.train()
for img, label in train_loader:
img = img.to(device)
label = label.to(device)
out = model(img)
_, predicted = torch.max(out, 1)
# loss 계산
loss = criterion(out, label)
train_loss = train_loss + loss.item()
train_total += out.size(0)
train_acc += (predicted == label).sum()
# 가중치 갱신
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc = train_acc / train_total
avg_train_loss = train_loss / len(train_loader)
train_loss_list.append(avg_train_loss)
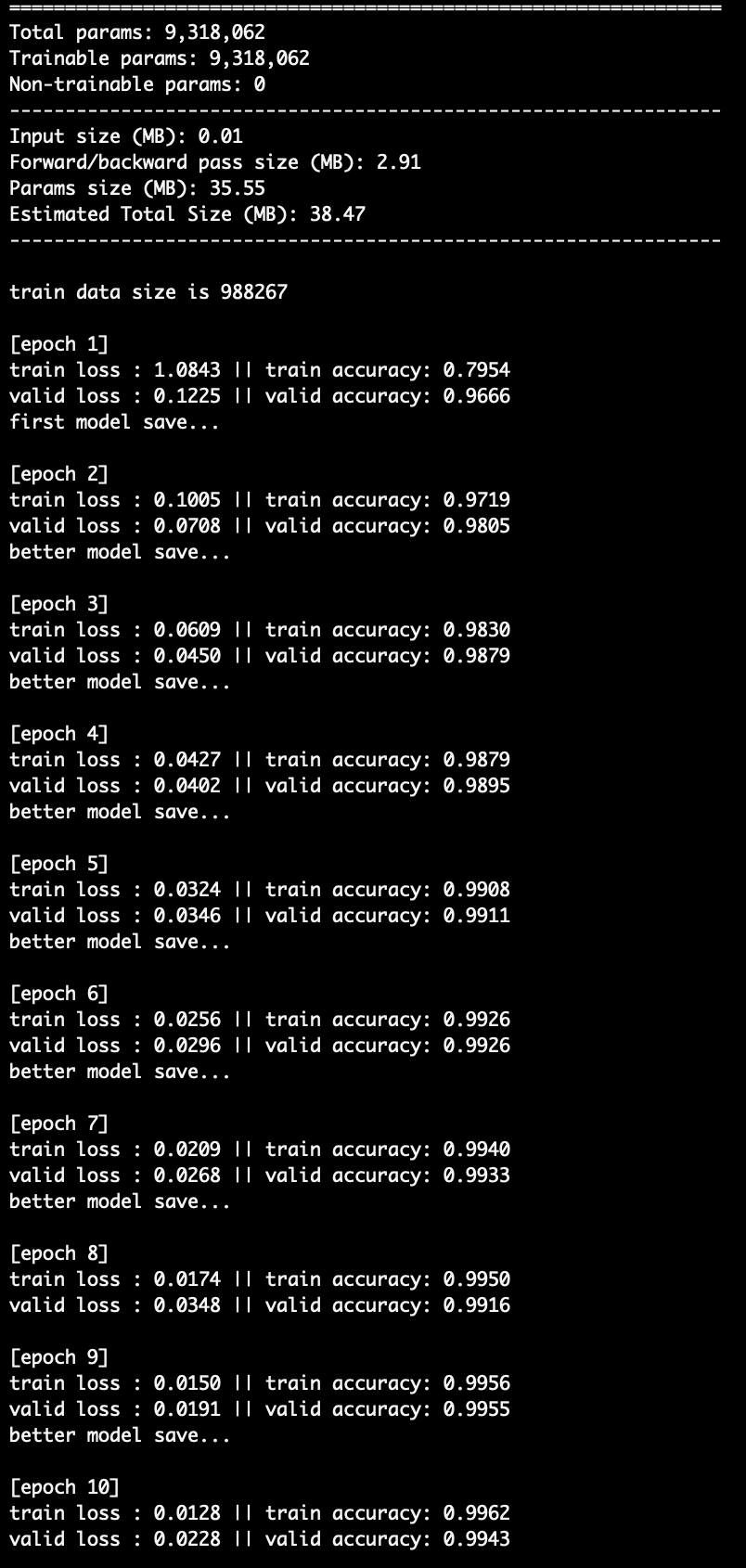
print('train loss : %.4f || train accuracy: %.4f' % (avg_train_loss, train_acc))
valid
Validation part이다. 만들어 둔 ValidData Loader에서 이미지와 label을 받아와서 model에 넣어 학습이 잘 진행되고 있는지 확인했다! 이 때 꼭 model.eval()을 써주자!
model.eval()
with torch.no_grad():
for img, label in valid_loader:
img = img.to(device)
label = label.to(device)
out = model(img)
_, predicted = torch.max(out, 1)
loss = criterion(out, label)
valid_loss = valid_loss + loss.item()
valid_total += out.size(0)
valid_acc += (predicted == label).sum()
valid_acc = valid_acc / valid_total
avg_val_loss = valid_loss / len(valid_loader)
val_loss_list.append(avg_val_loss)
print('valid loss : %.4f || valid accuracy: %.4f' % (avg_val_loss , valid_acc))
model 저장
과적합을 막기 위해서 validation loss가 감소하는 경우에만 모델 저장을 해주었다. early stopping을 해도 되는데 일단 이렇게 했다.
# 최적의 모델 저장
if epoch<2:
min_loss = val_loss_list[-1]
print('first model save...')
torch.save(model.state_dict(), '/home/danbibibi/jupyter/model/handwrite_recognition.pt')
else:
if val_loss_list[-1] < min_loss:
min_loss = val_loss_list[-1]
print('better model save...')
torch.save(model.state_dict(), '/home/danbibibi/jupyter/model/handwrite_recognition.pt')
print()학습 그래프 그리기
epoch에 따라 변하는 cost를 그래프로 찍는 코드이다.
plt.figure()
plt.subplot(1, 2, 1)
plt.title("train loss")
x1 = np.arange(0, len(train_loss_list))
plt.plot(x1, train_loss_list)
plt.subplot(1, 2, 2)
plt.title("validation loss")
x2 = np.arange(0, len(val_loss_list))
plt.plot(x2, val_loss_list)
plt.show()