✔️ VGG model
처음에 기본 VGG16 모델을 이용하여 학습 시켰는데 loss가 정말 높게 나왔다,, 그래서 아래와 같이 layer를 간소화하고 batch normalization과 dropout을 적용한 VGG_Extractor 모델을 사용했다! 그랬더니 성능이 많이 좋아졌다!!
nn.Sequential 을 이용해서 VGG model을 이전에 작성했던 것보다 더 깔끔하게 작성할 수 있었다! image size는 32*32*3으로 resize해서 넣어주었다!
import torch
from torch import nn
class VGG(nn.Module):
def __init__(self, input_channel, num_class):
super().__init__()
self.conv = nn.Sequential(
# 32 32 3 (입력)
# 32 32 64
nn.Conv2d(in_channels=input_channel, out_channels=64, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 16 16 64
# 16 16 128
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 8 8 128
# 8 8 256
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256), nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 4 4 256
# 4 4 512
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=512), nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=512), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 2 2 512
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(in_features=2048, out_features=num_class)
)
def forward(self, x):
x = self.conv(x)
x = self.fc(x) # 256, 2350
return x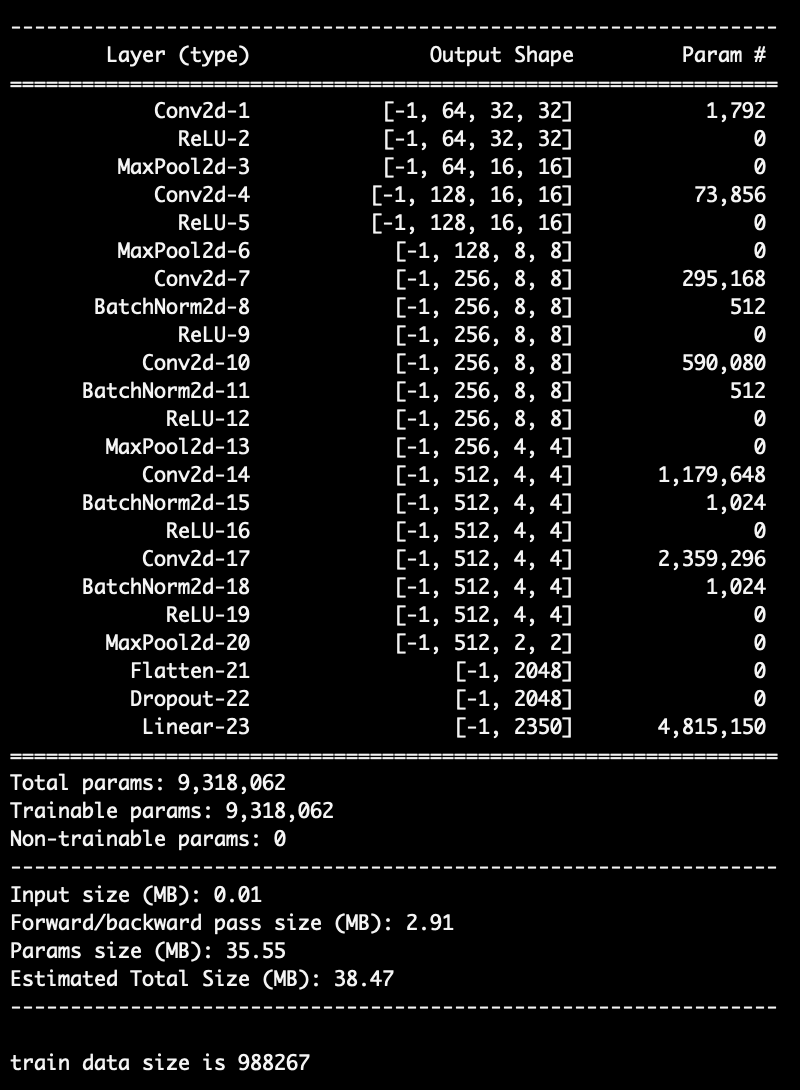

블로그 이전) https://danbibibi.tistory.com